↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Fine-tuning large language models (LLMs) is computationally expensive, especially in federated learning (FL) where data resides on multiple clients’ devices. Existing methods like FedIT try to mitigate this via low-rank adaptations (LoRA), but they suffer from mathematically inaccurate aggregation of local LoRA updates which introduces noise and hinders efficiency, particularly with heterogeneous resources. This is further complicated by heterogeneous data distribution and resource limitations in real-world FL deployments.
The paper introduces FLORA, a novel approach that addresses these limitations. FLORA employs a stacking-based aggregation method for local LoRA updates, eliminating the aggregation noise. This approach seamlessly handles heterogeneous LoRA adaptations across clients. Extensive experiments demonstrate FLORA’s superior performance over existing methods, especially in scenarios with heterogeneous client resources, significantly improving the efficiency and accuracy of federated LLM fine-tuning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and large language models. It addresses the critical issue of efficient and privacy-preserving fine-tuning of LLMs in decentralized settings, a major challenge in deploying LLMs in real-world applications. The proposed FLORA method offers a significant advancement with its noise-free aggregation and support for heterogeneous low-rank adaptations, paving the way for more efficient and robust federated LLM training. The findings will be highly relevant to researchers working on privacy-preserving AI, model efficiency, and federated learning.
Visual Insights#
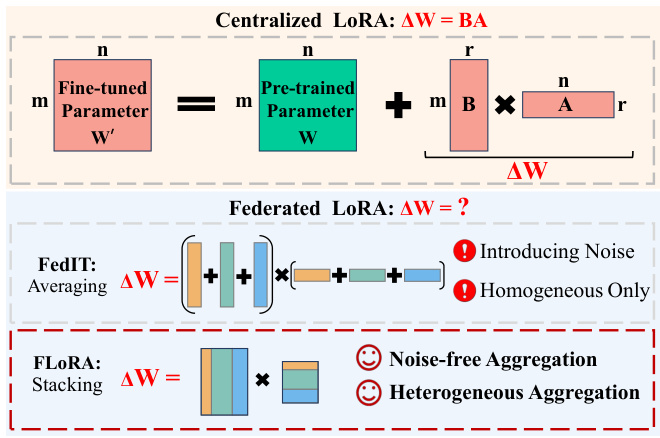
This figure illustrates the difference between the centralized LoRA, FedIT, and the proposed FLORA method for updating large language models (LLMs). The top row shows how LoRA (Low-Rank Adaptation) works in a centralized setting, adding low-rank matrices A and B to the pre-trained parameters W to compute the update AW=BA. The middle row depicts FedIT’s federated learning approach, which averages the local LoRA updates from multiple clients, leading to inaccurate aggregation and noise. The bottom row shows FLORA’s novel stacking-based aggregation method, which avoids noise and supports heterogeneous LoRA adapters, enabling more efficient and accurate federated fine-tuning.
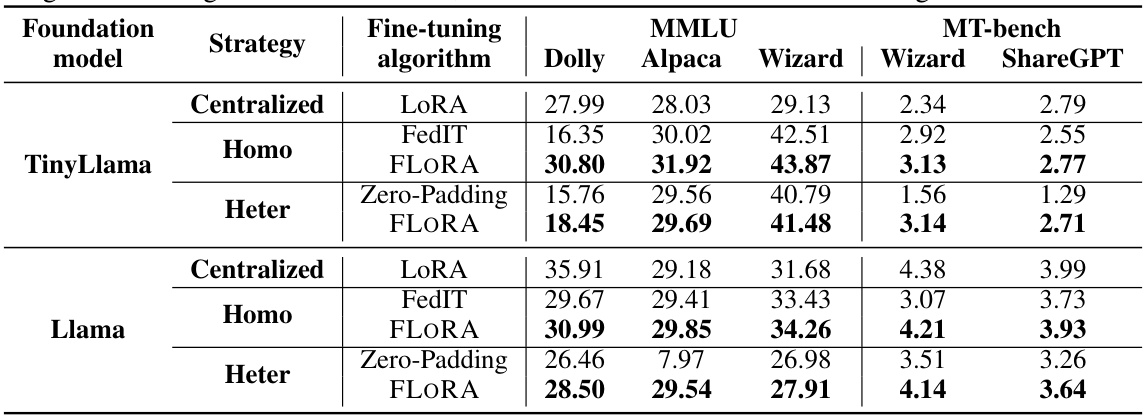
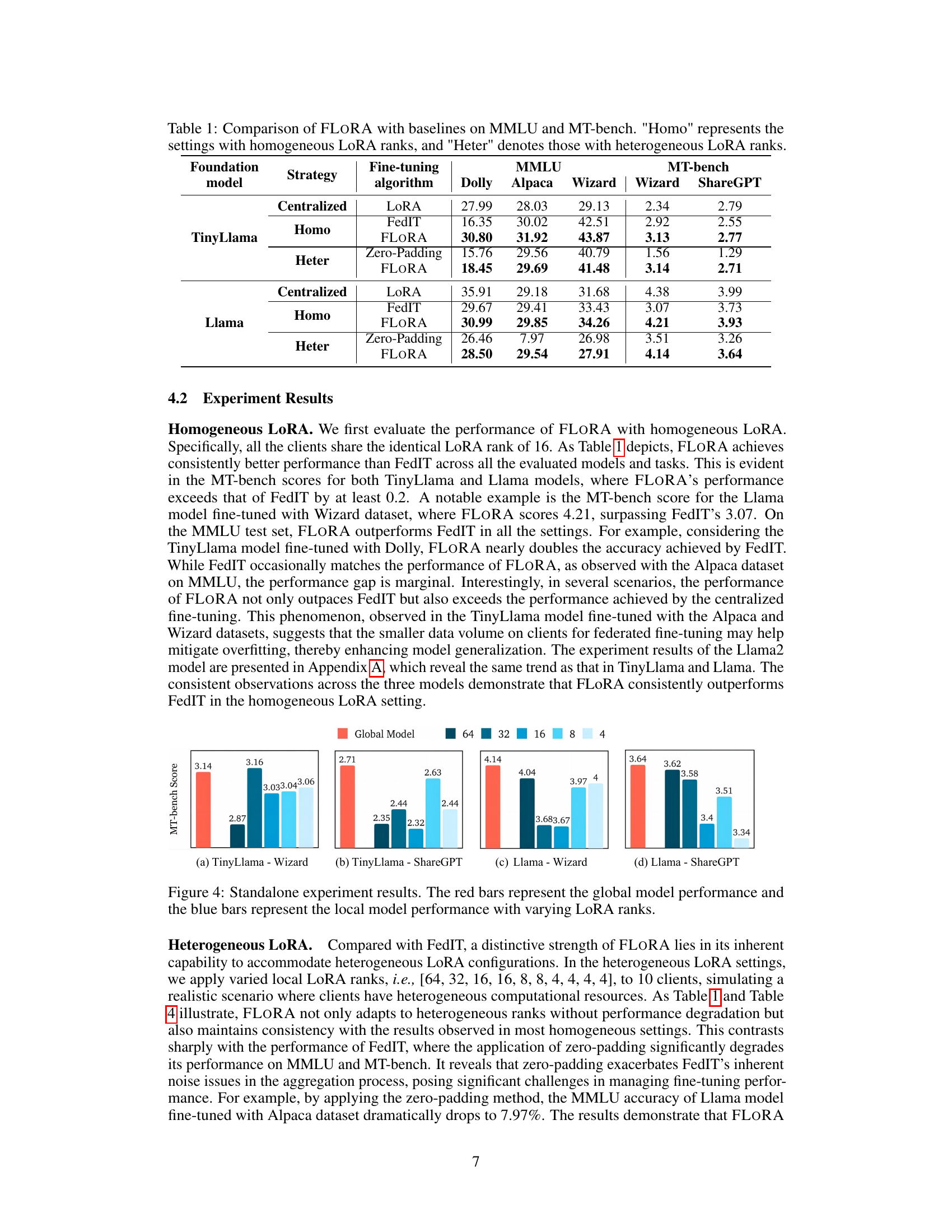
This table presents the results of experiments comparing FLORA’s performance against several baseline methods on two downstream tasks: MMLU and MT-bench. It shows the performance of different models (TinyLlama and Llama) using various fine-tuning algorithms (FLORA, FedIT, Zero-Padding, Centralized LoRA) under both homogeneous (Homo) and heterogeneous (Heter) LoRA rank settings. The results are presented as scores for each task and model, illustrating FLORA’s superior performance in various scenarios.
In-depth insights#
FLORA: Noise-Free Fed Tuning#
FLORA: Noise-Free Fed Tuning presents a novel approach to federated learning (FL) for large language models (LLMs), addressing the limitations of existing methods. The core innovation is a stacking-based aggregation technique for Low-Rank Adaptation (LoRA) modules, eliminating the mathematical inaccuracies and noise introduced by naive averaging in prior work. This noise-free aggregation significantly improves convergence speed and overall accuracy. Furthermore, FLORA seamlessly handles heterogeneous LoRA configurations across clients, adapting to diverse resource constraints and data distributions, a significant advantage over existing approaches. This adaptability makes FLORA robust and efficient, promoting wider participation in federated LLM fine-tuning. The theoretical analysis and experimental results demonstrate FLORA’s superior performance in both homogeneous and heterogeneous settings, establishing it as a significant step toward more practical and efficient privacy-preserving LLM training.
Heterogeneous LoRA#
The concept of “Heterogeneous LoRA” in the context of federated learning for large language models (LLMs) introduces a significant advancement. It addresses the limitations of existing methods that struggle with the diverse computational resources and data distributions across clients. Traditional approaches often assume homogeneous settings, which is unrealistic in federated learning. Heterogeneous LoRA tackles this by allowing each client to use a LoRA adapter with a rank tailored to its specific capabilities and data characteristics. This flexibility is crucial for practical applicability, as it enables participation of devices with varying resources, preventing marginalization of clients with limited computational power. This approach enhances overall model accuracy by incorporating information from a wider range of clients, while also maintaining privacy through decentralized training. However, challenges arise in aggregating these heterogeneous updates, which the paper appears to address with a novel stacking-based method that maintains accuracy and avoids introducing noise into the aggregated model. The effectiveness of this technique for noise-free aggregation and heterogeneous LoRA adaptation is a key contribution and represents a major step towards practical and efficient federated LLM fine-tuning.
Stacking-Based Aggregation#
The proposed ‘Stacking-Based Aggregation’ method offers a novel approach to aggregating local Low-Rank Adaptation (LoRA) modules in federated learning, addressing limitations of previous averaging methods. Instead of averaging local LoRA matrices independently, which introduces noise and mathematical inaccuracies, this method stacks the matrices. This stacking approach is theoretically sound, ensuring accurate global model updates. A significant advantage is its inherent support for heterogeneous LoRA ranks across clients, accommodating diverse data distributions and computational resources. This eliminates the need for techniques like zero-padding which can compromise model performance. The stacking procedure ensures noise-free aggregation. Overall, stacking-based aggregation provides a mathematically correct and efficient approach to federated LoRA fine-tuning, leading to improved performance and scalability in heterogeneous settings.
FedAvg Limitations#
Federated Averaging (FedAvg) is a foundational algorithm in federated learning, but its application to large language model (LLM) fine-tuning using low-rank adaptation (LoRA) reveals critical limitations. Naive averaging of local LoRA updates (A and B matrices) introduces significant noise, hindering convergence and reducing the effectiveness of the fine-tuning. This noise stems from the mathematical inaccuracy of averaging A and B independently; the correct aggregation should consider the product BA. FedAvg also struggles with heterogeneous LoRA settings, where different clients use varying ranks for their LoRA adapters. Simple methods like zero-padding to homogenize ranks are ineffective and inefficient. These limitations highlight the need for a more sophisticated aggregation strategy in federated LLM fine-tuning that handles both the mathematical inaccuracies of LoRA averaging and the realities of heterogeneous client resource capabilities.
Future of Federated LLMs#
The future of federated LLMs hinges on addressing current limitations and exploring new opportunities. Improving efficiency is crucial; reducing communication overhead and computational cost at the client-side are key priorities. Enhanced privacy preservation mechanisms, such as advanced cryptographic techniques and differential privacy, are essential for wider adoption. Addressing data heterogeneity remains a challenge, requiring robust aggregation methods that can handle varying data distributions and model architectures across clients. Furthermore, research into novel federated learning algorithms tailored specifically for LLMs, beyond simple adaptations of existing methods, is needed. Finally, exploring the potential of decentralized model architectures and hybrid approaches that combine centralized and federated learning could unlock further scalability and performance improvements. These developments will drive wider adoption of federated LLMs, enabling more effective and private large language model training and deployment.
More visual insights#
More on figures

This figure compares the aggregation methods of FLORA and FedIT for Low-Rank Adaptation (LoRA) modules. FedIT averages the local LoRA modules independently, leading to inaccurate aggregation and noise in the global model update. In contrast, FLORA stacks the local LoRA modules, resulting in a noise-free aggregation. The figure visually illustrates the difference between the two methods, showing how FedIT’s averaging introduces an intermediate term that causes errors and how FLORA’s stacking method avoids this error. The diagram uses color-coded blocks to represent the matrices of local LoRA modules and the aggregation process, making the comparison clear.

This figure illustrates the workflow of the FLORA algorithm. Each client initializes and optimizes its own local LoRA modules. These modules are then sent to the server, where they are stacked together to form global LoRA modules using the stacking-based aggregation method. The server then sends the global modules back to each client, which uses them to update their local models. This process is repeated for each round of federated learning, leading to a noise-free and efficient fine-tuning of the LLM.

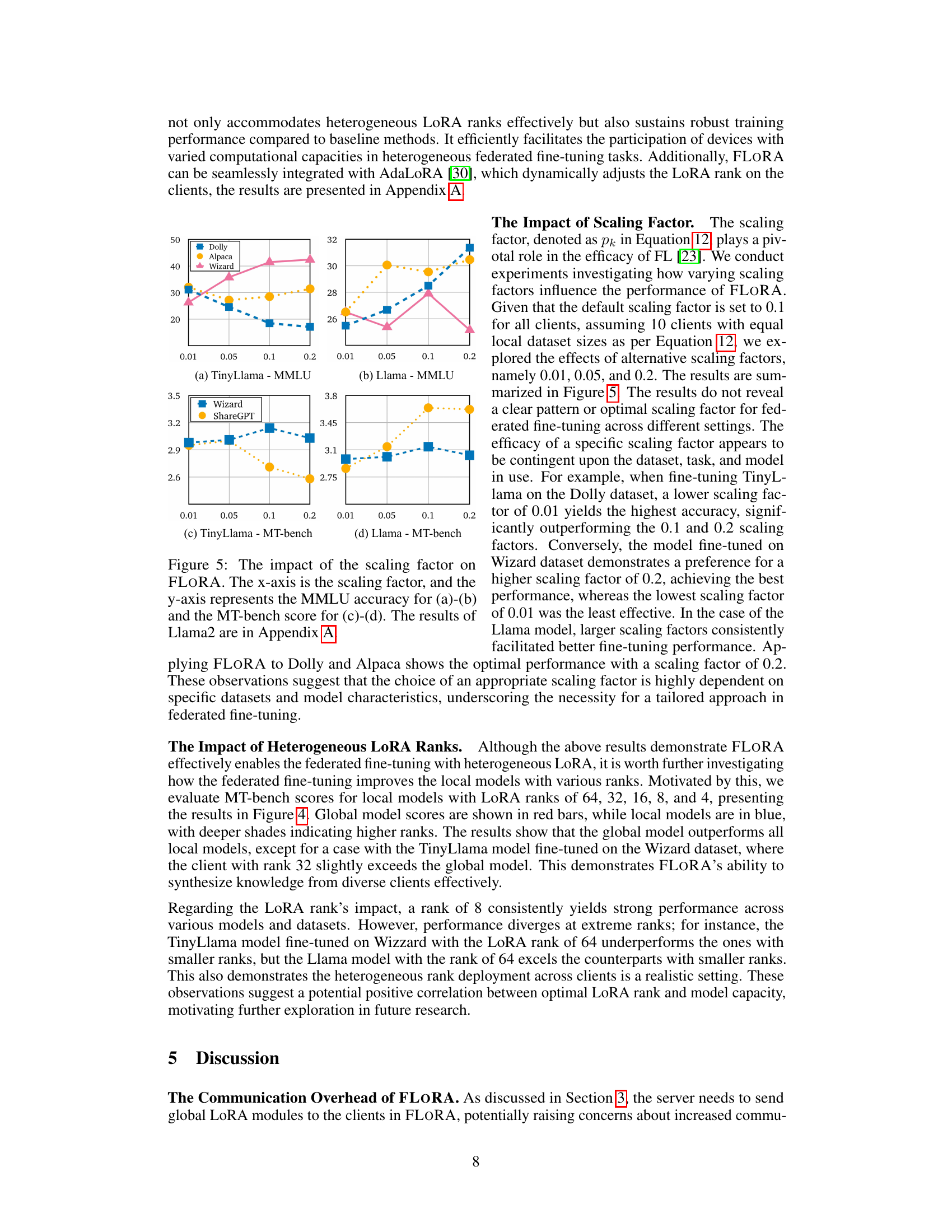
This figure shows the results of a standalone experiment, where each client trains the model locally without any federated learning. The red bars represent the performance of the global model, while the blue bars represent the performance of each client’s local model using different LoRA ranks (64, 32, 16, 8, and 4). The results help to understand how different LoRA rank settings affect performance in a non-federated setting, and they also provide a benchmark against which the performance of federated learning methods can be compared.
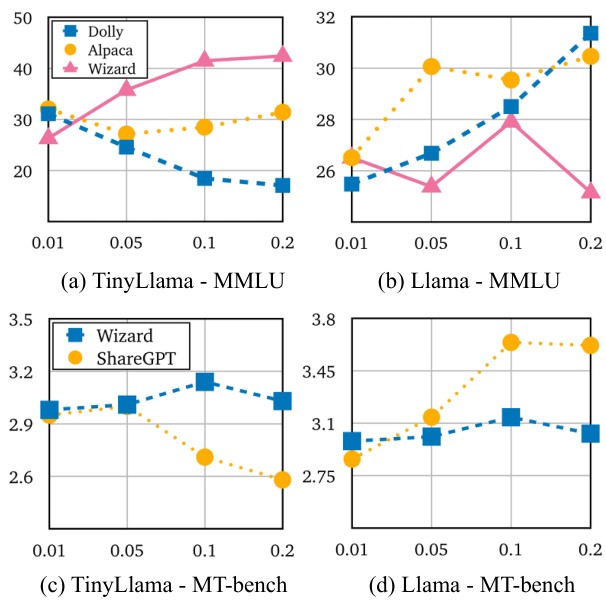
This figure shows the results of standalone experiments, where each client trains the model locally without any federation. The red bars represent the global model performance, and the blue bars represent the local model performance with varying LORA ranks. The experiment is conducted to compare the performance of local and global models, and how varying LORA ranks affects the performance of the local model.

This figure compares the communication overhead of three different fine-tuning methods: full fine-tuning, FedIT, and FLORA. The ratio of communicated parameters to the total number of parameters in full fine-tuning is shown for each method across three communication rounds. Full fine-tuning has a ratio of 1.000, indicating that all parameters are communicated. FedIT has a much lower ratio (0.177) because it only communicates the updated LoRA parameters. FLORA has a slightly higher ratio than FedIT (0.215), because it transmits both stacked LoRA parameters; however, it still maintains a significantly lower communication overhead compared to full fine-tuning.
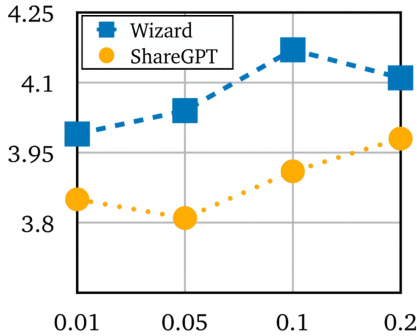
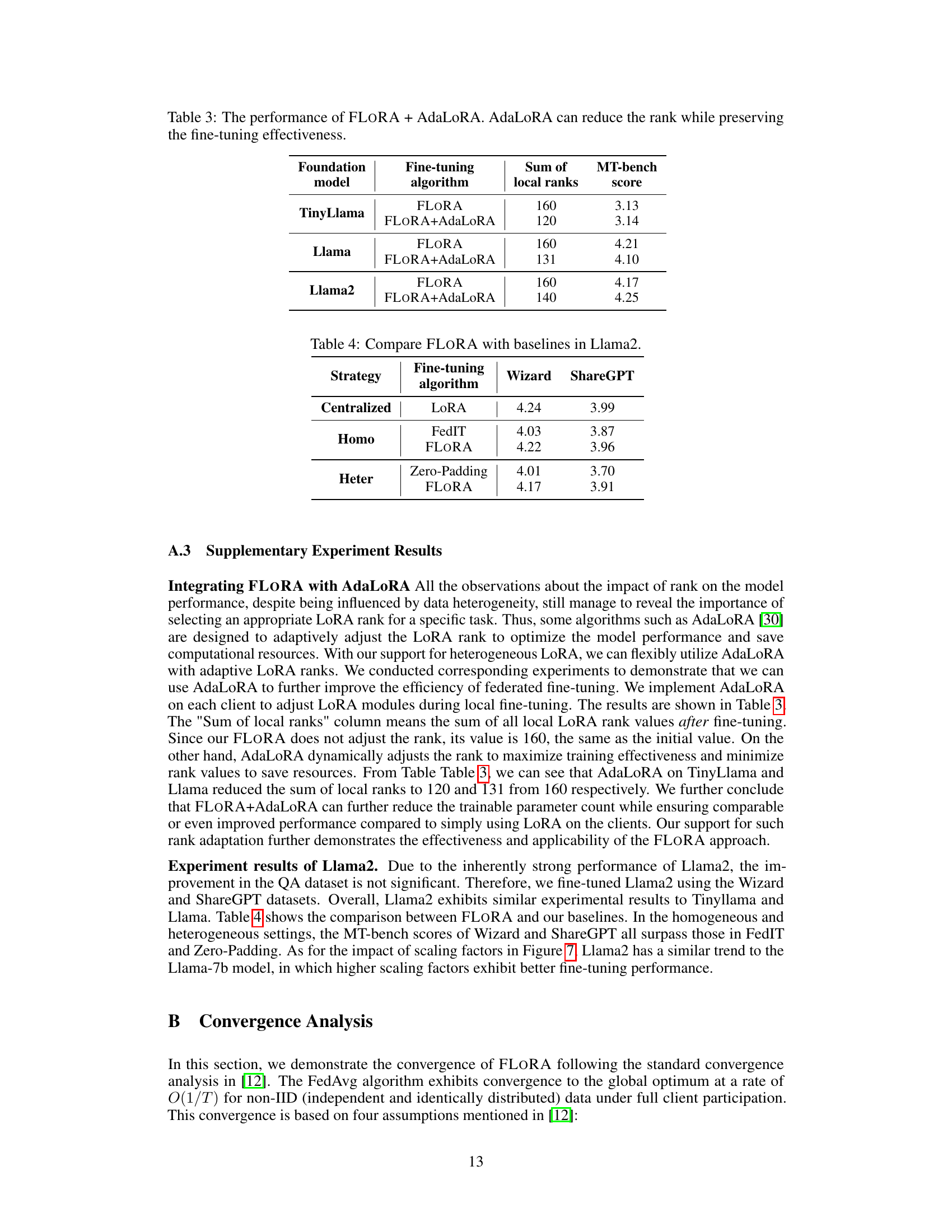
This figure shows the impact of varying scaling factors on the performance of the Llama2 model when fine-tuned using FLORA on the Wizard and ShareGPT datasets. The x-axis represents the scaling factor (pk), and the y-axis represents the MT-bench score. The results indicate that there is not a consistent optimal scaling factor across different datasets; the best scaling factor is data-dependent.
More on tables

This table shows the hyperparameters used in the experiments. Specifically, it details the number of communication rounds and the number of local epochs for each combination of foundation model (TinyLlama, Llama, Llama2) and dataset (Dolly, Alpaca, Wizard, ShareGPT). These settings were chosen to balance computational resource constraints with the need for sufficient data to observe meaningful results.
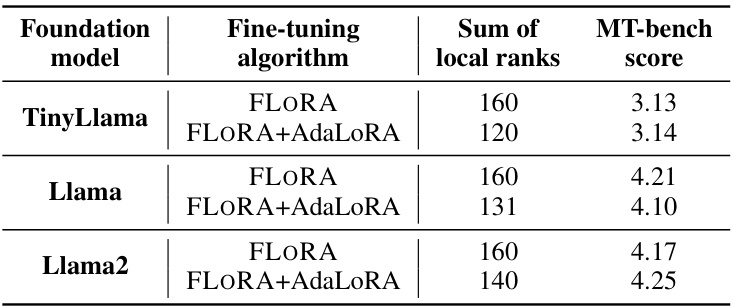
This table presents the results of experiments comparing the performance of FLORA alone and FLORA combined with AdaLoRA. AdaLoRA is a technique that dynamically adjusts the rank of LoRA adapters during fine-tuning. The table shows that using AdaLoRA with FLORA reduces the sum of local ranks (indicating reduced model size) while maintaining comparable or even slightly improved performance on the MT-bench benchmark across different foundation models (TinyLlama, Llama, and Llama2). This demonstrates the effectiveness of AdaLoRA in enhancing FLORA’s efficiency.
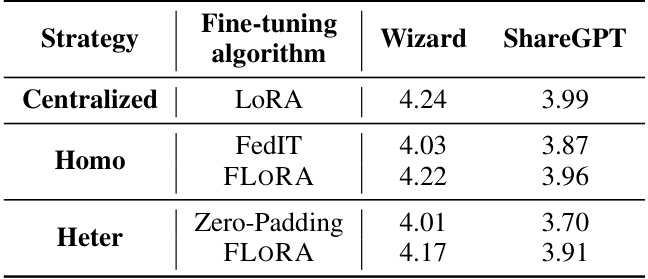
This table compares the performance of FLORA against three baseline methods (Centralized LoRA, FedIT, and Zero-Padding) when fine-tuning the Llama2 model on two downstream tasks (Wizard and ShareGPT). The results show FLORA’s performance compared to others under both homogeneous (all clients use same LoRA rank) and heterogeneous (clients use different LoRA ranks) settings. It highlights FLORA’s ability to achieve better results, especially in the heterogeneous setting, where other methods struggle.
Full paper#