↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Many AI models struggle with nuanced reasoning tasks like understanding sarcasm or making ethical judgements. These tasks aren’t easily expressed in programming code, limiting the applicability of existing program synthesis techniques. This research aims to bridge this gap.
The researchers introduce COGEX, a new framework that uses code generation and program emulation to solve these more complex tasks. The key innovation is using “pseudo-programs”, Python code with some undefined functions, allowing the model to leverage its existing knowledge to infer their execution. Further, to efficiently adapt the model to different tasks, they developed COTACS, a program search algorithm that finds optimal code with no parameter updates, outperforming existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances program synthesis with language models, expanding its application beyond algorithmic tasks to encompass soft reasoning. It introduces a novel approach, COGEX, and a program search method, COTACS, which show large improvements over existing methods on a variety of tasks. This opens up new avenues for research in bridging symbolic and soft reasoning, and for developing more robust and versatile AI systems.
Visual Insights#
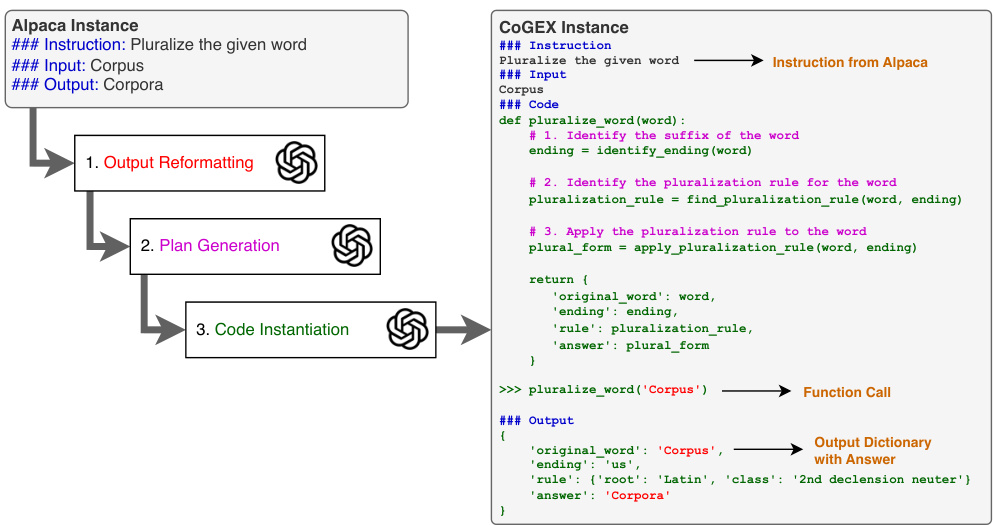
This figure illustrates the transformation of an Alpaca instance into a COGEX instance. An Alpaca instance consists of an instruction, input, and expected output. The COGEX instance expands this by generating a Python program designed to solve the problem, showing intermediate steps in a dictionary output. This demonstrates how COGEX utilizes program generation and emulation to address reasoning tasks.

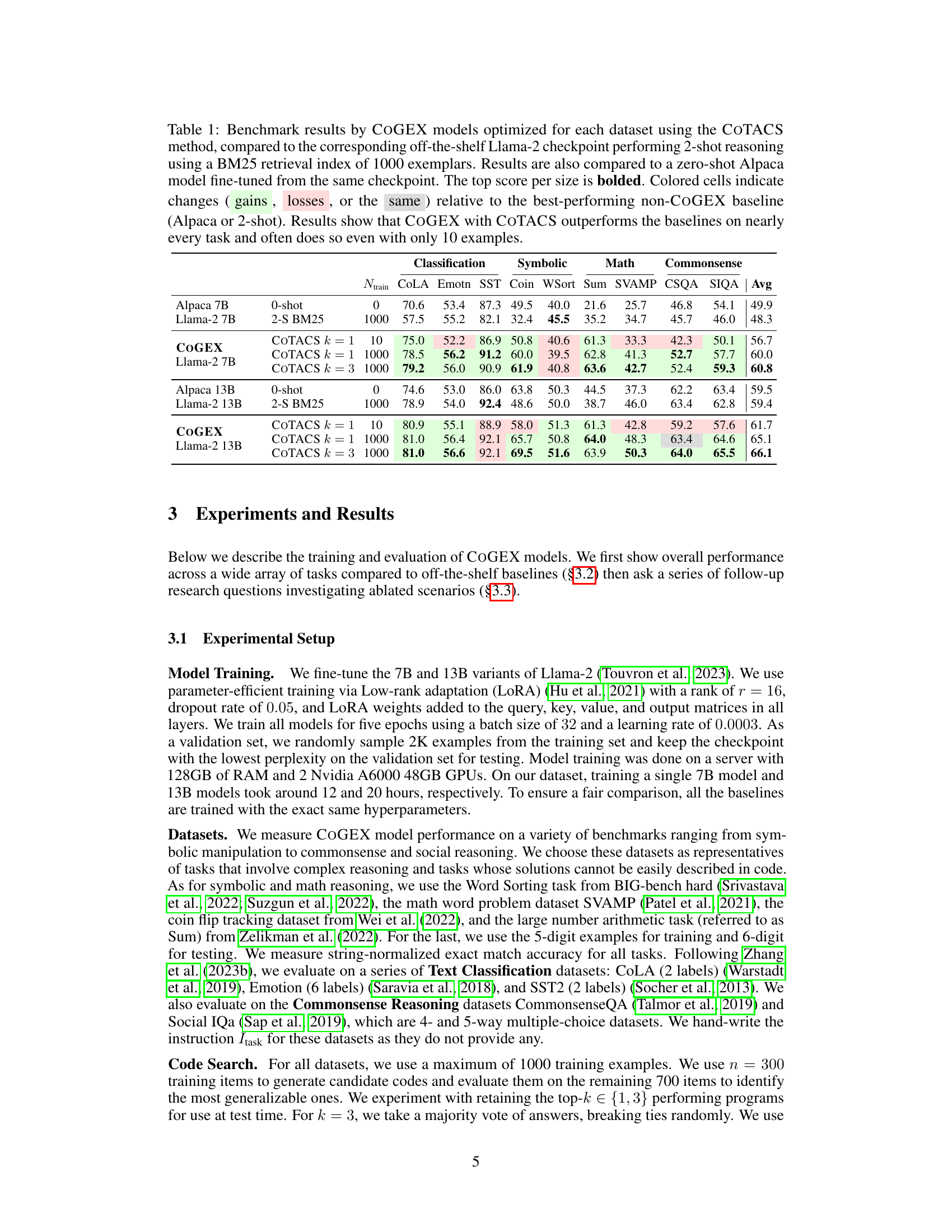
This table presents a comparison of the performance of COGEX models (with COTACS optimization) against Llama-2 (with BM25 and 2-shot prompting) and Alpaca (zero-shot) baselines across various reasoning tasks. It highlights the improvements achieved by COGEX, especially with a larger number of training examples, showcasing its superior performance in various task categories including classification, symbolic math, and commonsense reasoning.
In-depth insights#
Code as Reasoning#
The paradigm of ‘Code as Reasoning’ presents a compelling shift in how we approach artificial intelligence, particularly in tackling complex reasoning tasks. Instead of relying solely on natural language processing, it leverages the power of code generation and execution to model reasoning processes more explicitly. This approach offers several advantages: it provides a structured, formal representation of thought, enabling easier debugging and analysis of reasoning steps, and it can potentially handle tasks beyond the scope of traditional natural language methods. The use of ‘pseudo-programs’, with some functions left undefined, allows the model to incorporate external knowledge and commonsense reasoning, addressing a significant limitation of purely algorithmic approaches. However, challenges remain, including the need for robust code generation techniques, efficient emulation of code execution, and methods to effectively search the vast space of possible program solutions. The success of this approach depends on carefully designed training datasets and the ability of the language model to not only generate code but also accurately simulate its execution, correctly interpreting the meanings of undefined functions. Ultimately, ‘Code as Reasoning’ presents a promising path towards building more robust and interpretable AI systems capable of complex problem-solving.
COGEX Framework#
The COGEX framework presents a novel approach to enhance language models’ reasoning capabilities by leveraging program generation, emulation, and search. It moves beyond traditional code-generation methods by introducing the concept of ‘pseudo-programs,’ allowing for the incorporation of less precisely defined reasoning steps alongside algorithmic operations. The framework involves three key steps: (1) training an LM to generate pseudo-programs in Python, (2) training the model to emulate the execution of these programs, including simulating undefined leaf functions based on its inherent knowledge, and (3) employing a search algorithm (COTACS) to identify an optimal pseudo-program for a given task from a set of candidates. This approach allows COGEX to tackle problems not easily expressible as pure code, bridging the gap between algorithmic and soft reasoning tasks. A core strength lies in the ability of COTACS to adapt a single COGEX model to diverse tasks by searching for the best-performing program without needing to retrain the model’s parameters. This adaptive search process significantly enhances the model’s efficiency and generalizability. The framework’s versatility is demonstrated across various datasets encompassing algorithmic and soft reasoning tasks, showcasing a significant improvement over existing in-context learning methods.
Program Search#
The ‘Program Search’ aspect of the research paper presents a novel approach to task adaptation in language models. Instead of traditional parameter updates via fine-tuning, a search algorithm, COTACS, is introduced to identify the single program that optimizes a COGEX model’s performance on a given dataset. This is achieved by evaluating many program candidates generated by the model and selecting the optimal one based on performance on a training set. The use of pseudo-programs—programs with undefined leaf functions—is critical, allowing the LM’s knowledge to fill in execution gaps, thereby making the search effective for both algorithmic and soft reasoning tasks. COTACS offers a lightweight alternative to fine-tuning, especially valuable when training data is scarce, showcasing the power of program search for adapting language models to new tasks with minimal resource consumption. The effectiveness of COTACS is demonstrated across various benchmarks, indicating its potential to significantly enhance the adaptability and versatility of language models for numerous applications. The trade-off between the flexibility of generating a new program for each instance versus the efficiency of using a single, optimal program for the entire dataset is a key consideration highlighted by this approach. Further research could explore the impact of different search strategies and program representation schemes on the performance and efficiency of COTACS. The robustness and generalizability of COTACS across diverse datasets also warrant further investigation.
Empirical Results#
An effective ‘Empirical Results’ section should begin with a clear overview of the experimental setup, including datasets used, evaluation metrics, and baselines for comparison. It needs to present the key findings in a concise and easily understandable manner, possibly using tables and figures to visualize the results. Statistical significance should be clearly reported, and any limitations of the experiments acknowledged. A deeper dive into the results would analyze trends and patterns, comparing different model variants and their performance on various tasks. The discussion should then connect these results to the paper’s main claims, explaining whether the findings support or challenge the hypotheses presented, and exploring any unexpected observations. Qualitative analysis, supplementing the quantitative data with concrete examples, can significantly strengthen the ‘Empirical Results’ section. Finally, it’s essential to discuss the implications of the empirical findings and their broader context, relating the results to prior work and indicating directions for future research. Robustness analysis, showing results under various settings and potential limitations, is crucial for a credible empirical evaluation.
Future of COGEX#
The future of COGEX lies in scaling its capabilities to handle more complex reasoning tasks and larger datasets. Improving the efficiency of the program search algorithm (COTACS) is crucial, potentially through exploring more advanced search techniques or incorporating reinforcement learning. Expanding the range of programming languages beyond Python could unlock new possibilities, enabling the system to leverage specialized languages for particular reasoning domains. Addressing the limitations of the current program emulation system is also vital; research into improved program understanding and execution within the LM could significantly enhance accuracy and reliability. Finally, exploring the integration of COGEX with other AI paradigms, such as symbolic reasoning systems, may enable the development of more robust and powerful hybrid reasoning models. Further research on robustness and fairness is necessary to address potential biases and ensure ethical application. These enhancements can broaden COGEX’s applicability across diverse fields, opening doors for more sophisticated reasoning capabilities in various AI applications.
More visual insights#
More on figures
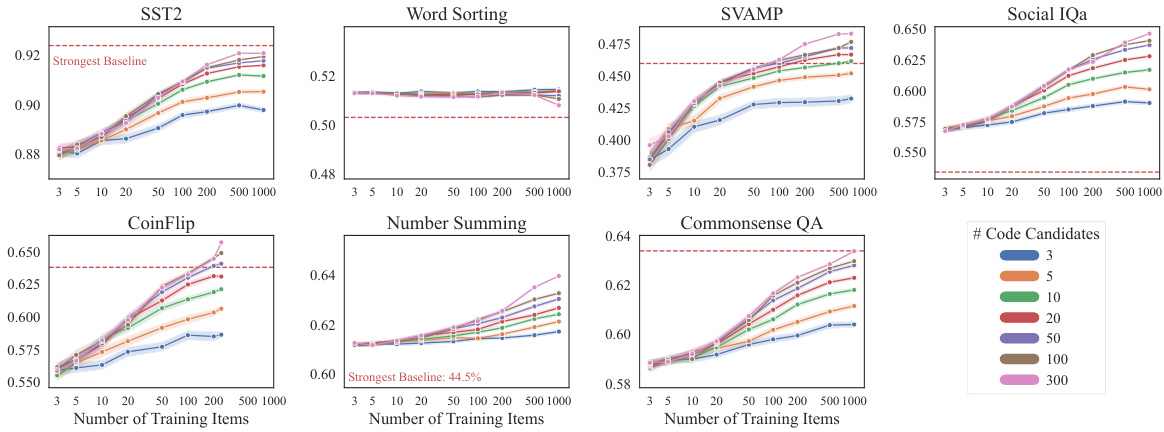
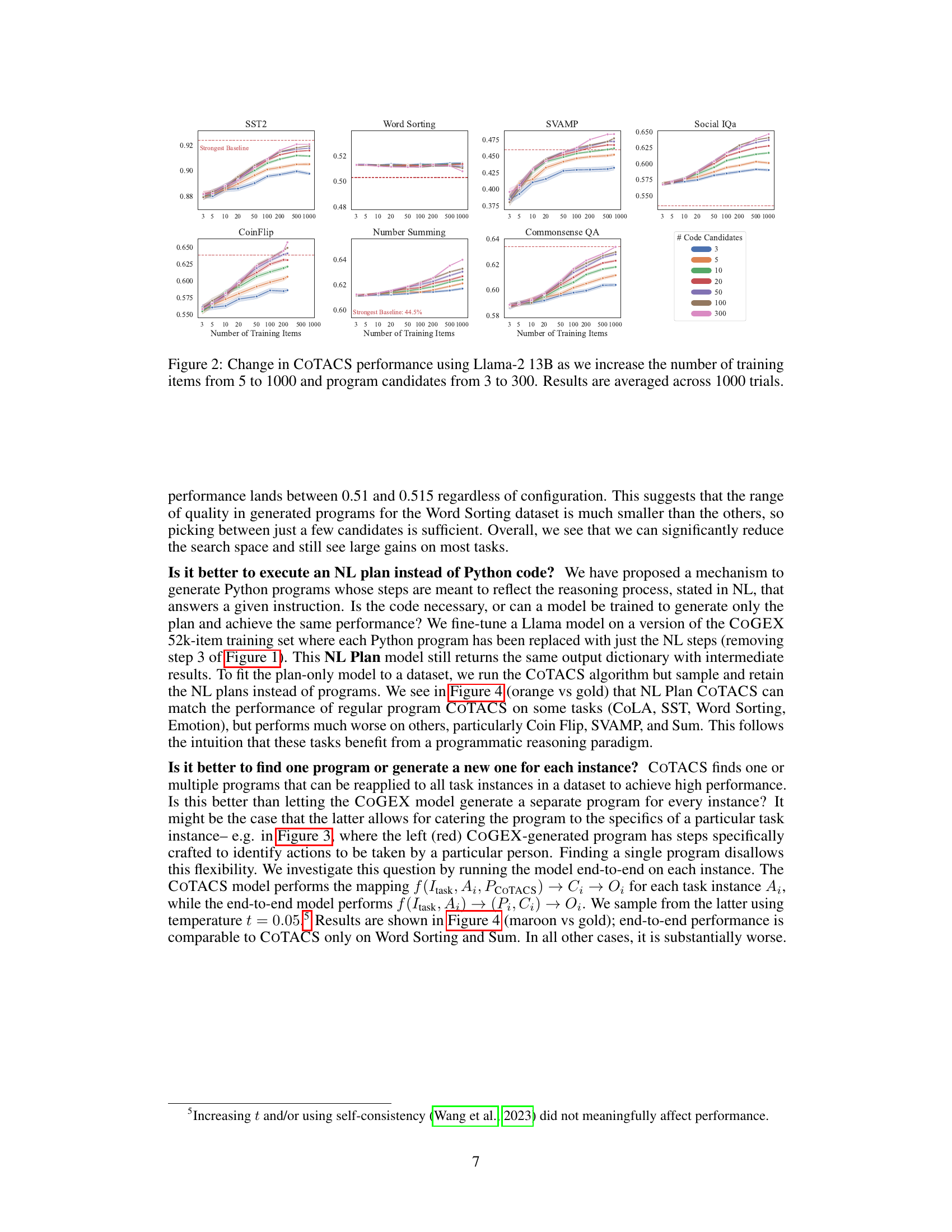
This figure displays the results of an ablation study on the COTACS algorithm, showing how the number of training examples and program candidates impact performance. The results are presented across seven different tasks and averaged over 1000 trials. The x-axis represents the number of training items, while the y-axis represents the performance metric (likely accuracy). Different colored lines represent different numbers of code candidates considered during the search phase of the COTACS algorithm. The figure helps to understand the trade-off between computational cost and model performance in relation to training data and program search space.
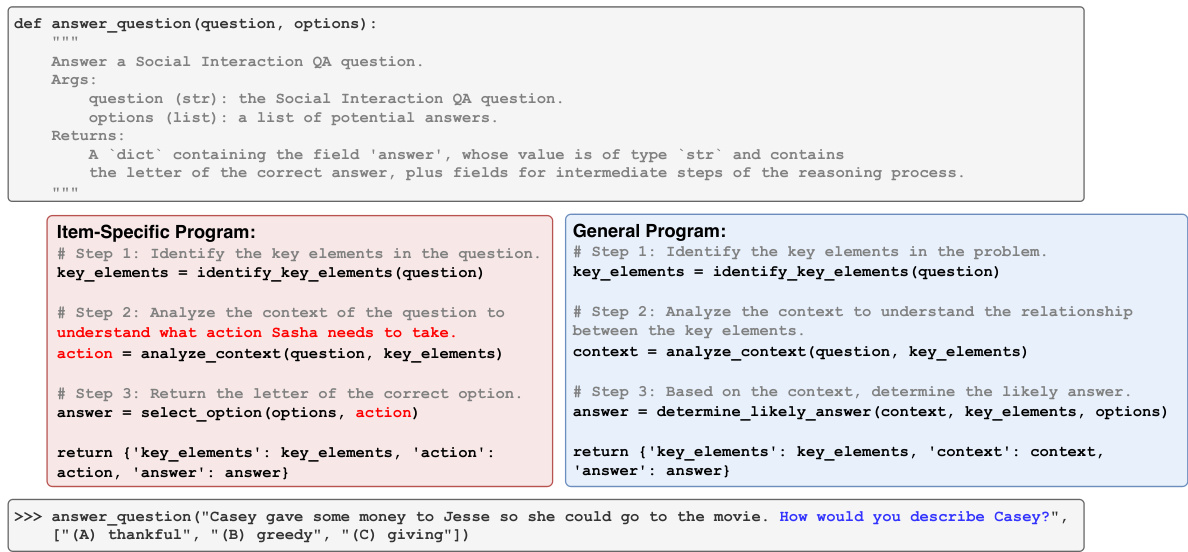
This figure shows two example programs generated by the COGEX model for the Social IQa dataset. The left program is very specific to the example question, while the right program is more general and applicable to a wider range of questions. The figure highlights the benefit of using the COTACS algorithm to select a single, generalizable program, improving overall accuracy compared to using question-specific programs.
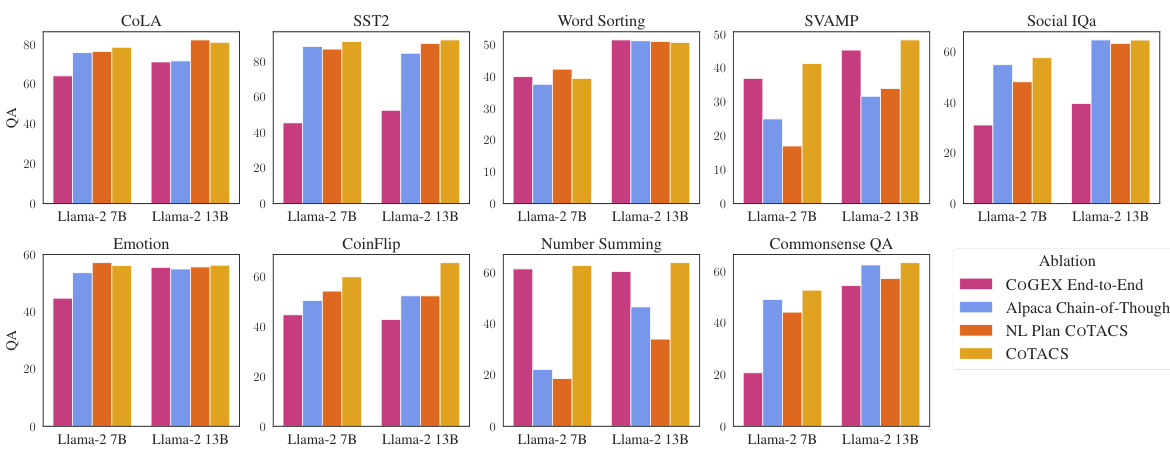
This figure compares the performance of COTACS (a program search method) and fine-tuning on various tasks with different numbers of training examples. It shows that while fine-tuning generally achieves higher accuracy with more data, COTACS offers a competitive advantage, particularly when training data is limited. COTACS’s advantage lies in its lightweight nature, requiring only a program string to be saved, unlike fine-tuning which demands saving an entire checkpoint.
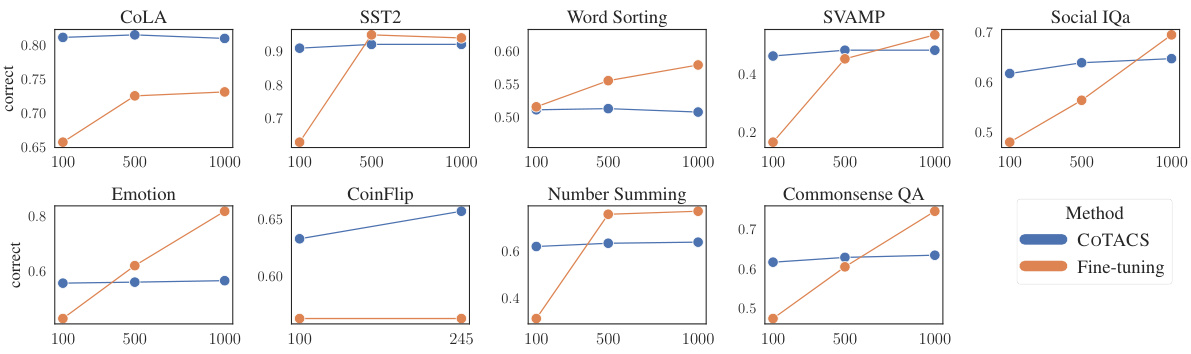
This figure compares the performance of COTACS and fine-tuning across multiple datasets as the number of training examples increases. It shows that fine-tuning generally outperforms COTACS with larger datasets, while COTACS is a more lightweight and effective alternative for smaller to medium sized datasets.

This figure shows an example of how an Alpaca instance is converted into a COGEX instance. The Alpaca instance contains an instruction and input. The COGEX instance shows the process of generating a Python program and function call, emulating the execution, and finally outputting a dictionary containing the answer and intermediate reasoning steps. This illustrates the core functionality of the COGEX approach, which involves using language models to generate and execute pseudo-programs to solve reasoning tasks.
More on tables
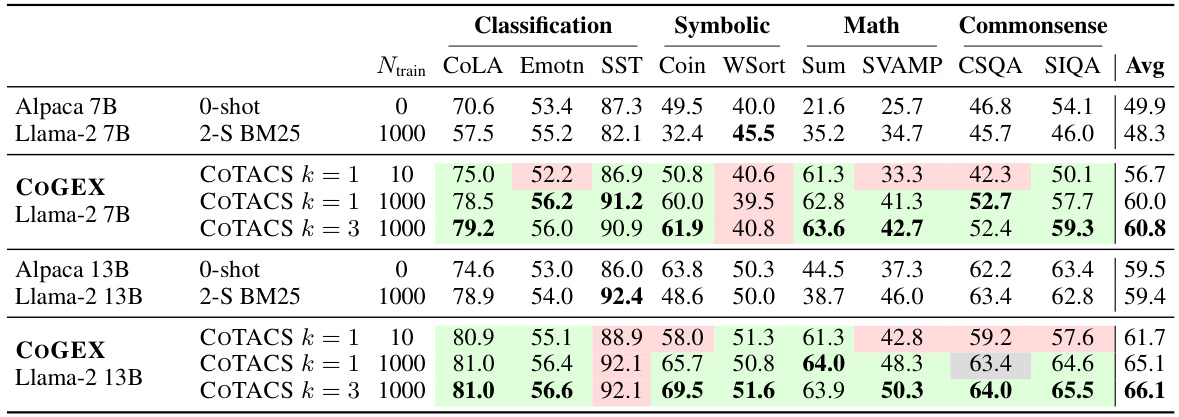
This table compares the performance of COGEX models (fine-tuned using the COTACS algorithm) against baseline models (Llama-2 with BM25 and zero-shot Alpaca) across various reasoning tasks. It shows the improvement achieved by COGEX, particularly when using 1000 training examples. Colored cells highlight performance differences compared to the best-performing baseline.

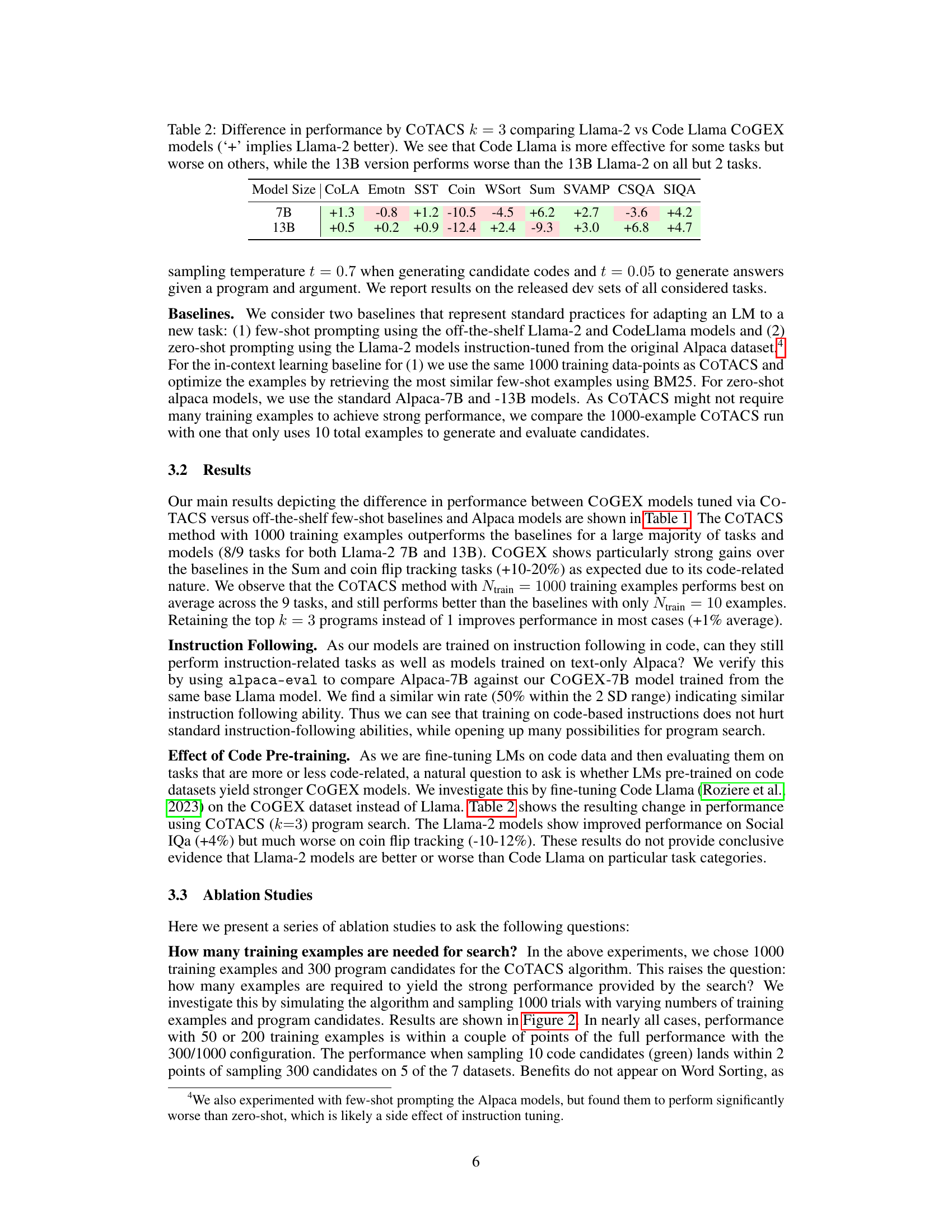
This table compares the performance difference between Llama-2 and Code Llama models when using COTACS (k=3) across various tasks. It shows that Code Llama sometimes outperforms Llama-2 but not always, highlighting the task-specific nature of model effectiveness and indicating that the 13B Code Llama model is generally underperforming in comparison to its Llama-2 counterpart.
Full paper#