TL;DR#
Large Language Models (LLMs) are powerful but expensive to use, especially with long prompts. Existing prompt compression techniques aim to reduce costs but lack a unified theoretical framework and often underperform. This paper tackles this by presenting a novel framework that considers the rate-distortion trade-off for prompt compression in LLMs.
The paper formalizes prompt compression as a rate-distortion problem, deriving the optimal trade-off as a linear program. It introduces a new efficient algorithm to compute this limit and evaluates existing methods against this optimal baseline. A new algorithm, Adaptive QuerySelect, is proposed, and is shown to achieve significantly better performance by utilizing query information and variable-rate compression.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs). It provides a novel framework for prompt compression, addressing the high cost of LLM inference. The framework’s theoretical analysis and proposed algorithm can significantly improve efficiency and reduce costs, making LLMs more accessible and practical for various applications. It also opens new avenues for research in prompt compression techniques and its theoretical limits.
Visual Insights#
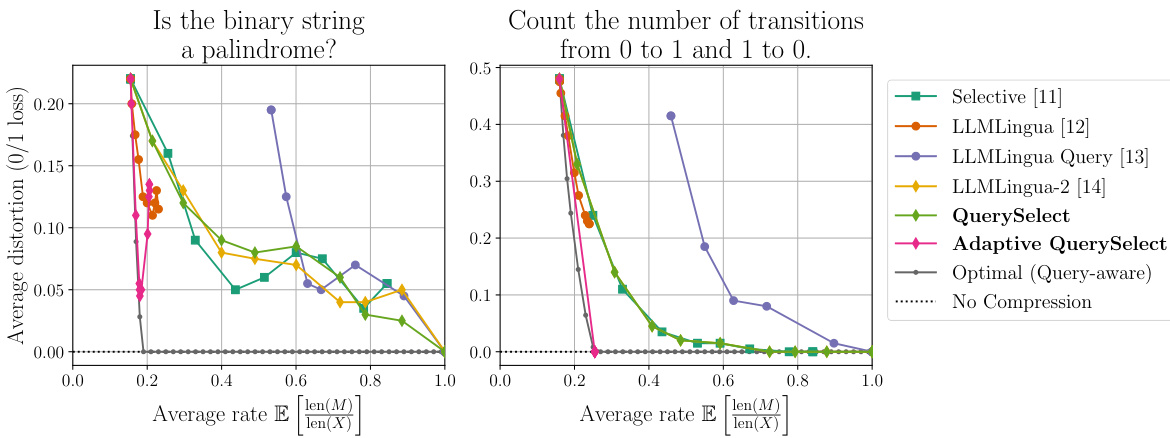
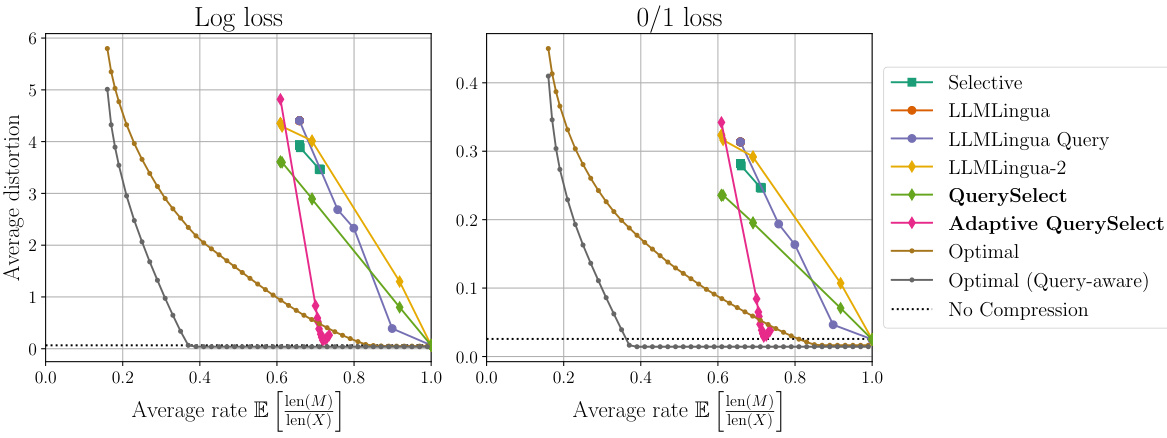
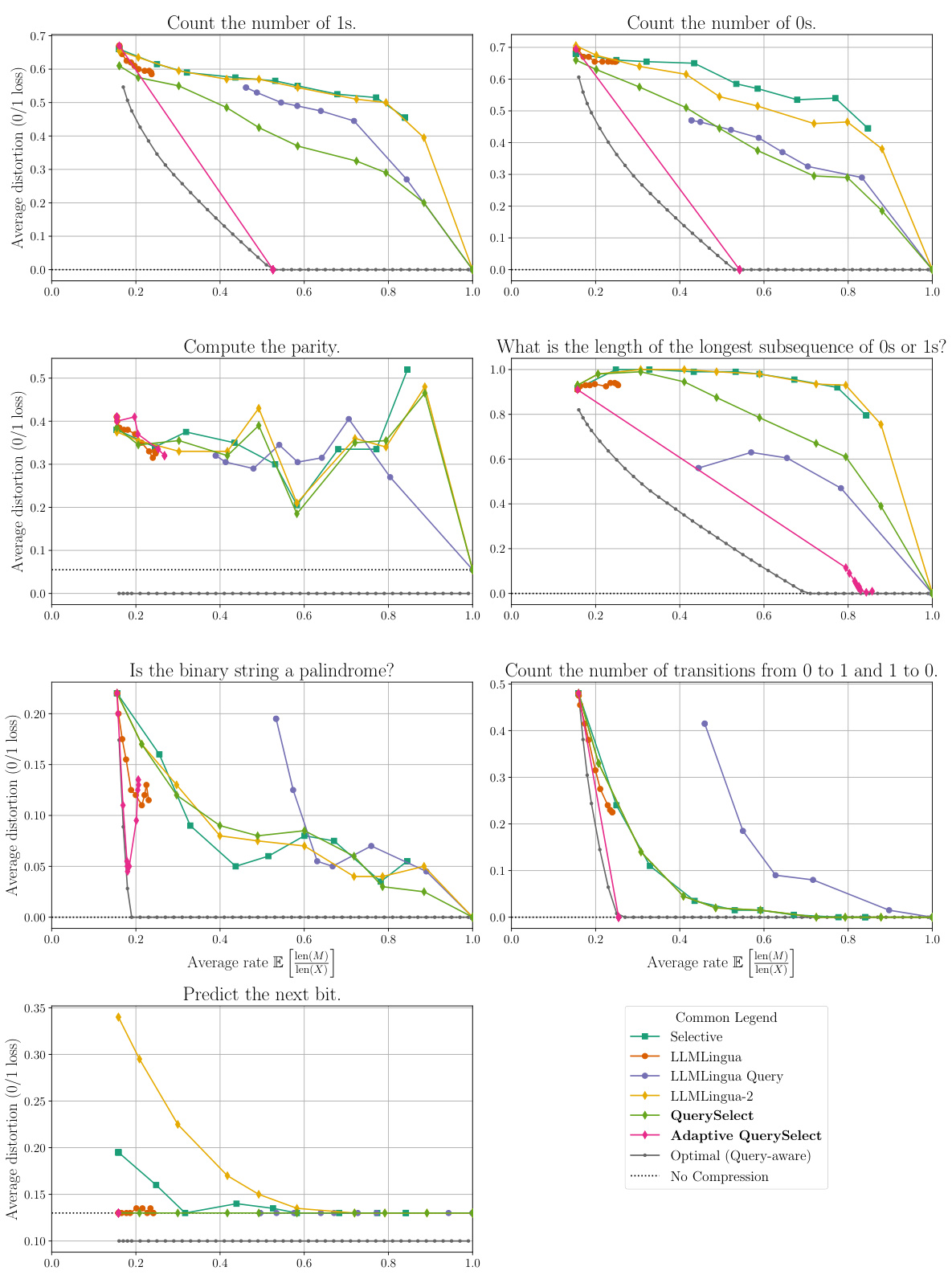
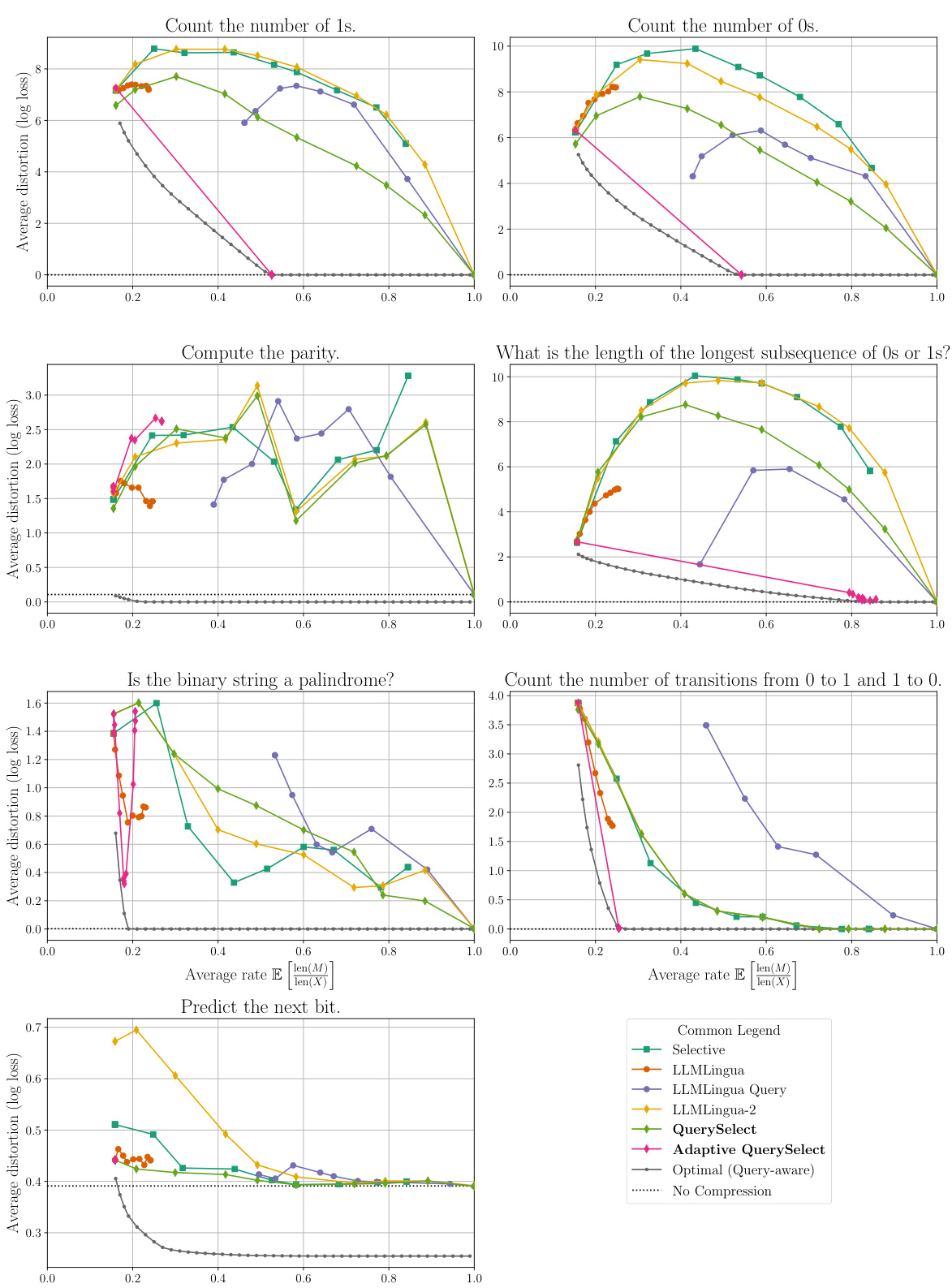
🔼 This figure shows the performance of various prompt compression methods against theoretical optimal performance (both query-aware and query-agnostic). It highlights that existing methods significantly underperform the optimal strategies, particularly the query-agnostic ones. The authors’ proposed method, Adaptive QuerySelect, demonstrates a substantial performance improvement, achieving the best result and surpassing even the optimal query-agnostic approach. The results are presented using two different distortion metrics (log loss and 0/1 loss).
read the caption
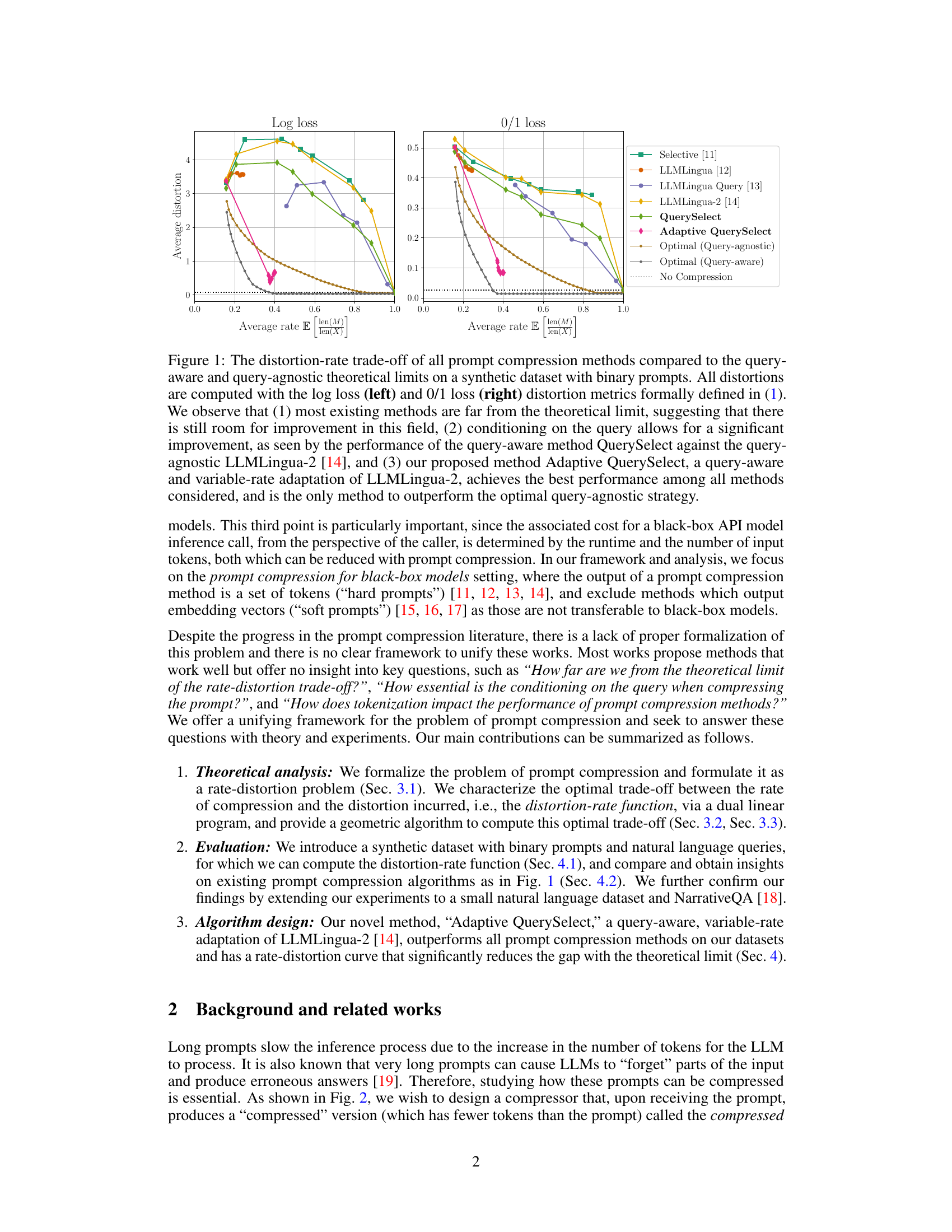
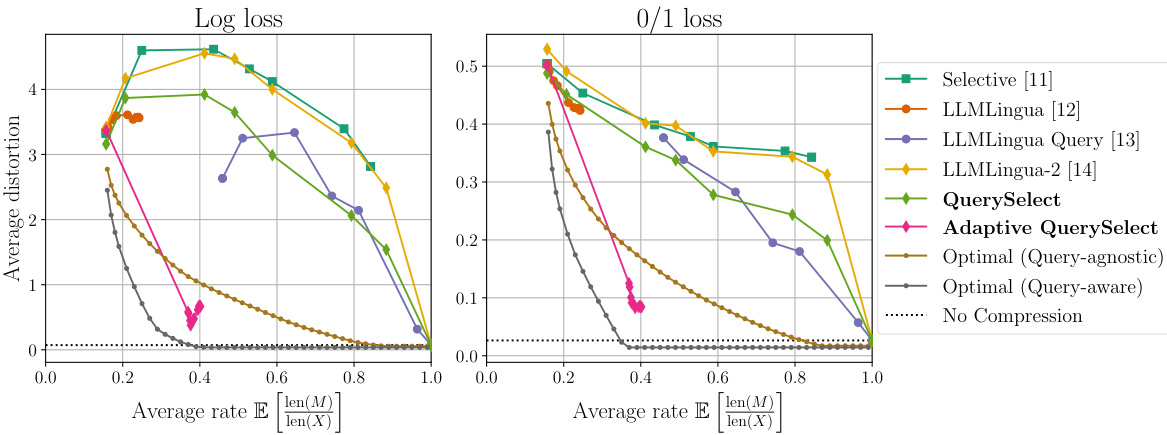
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.

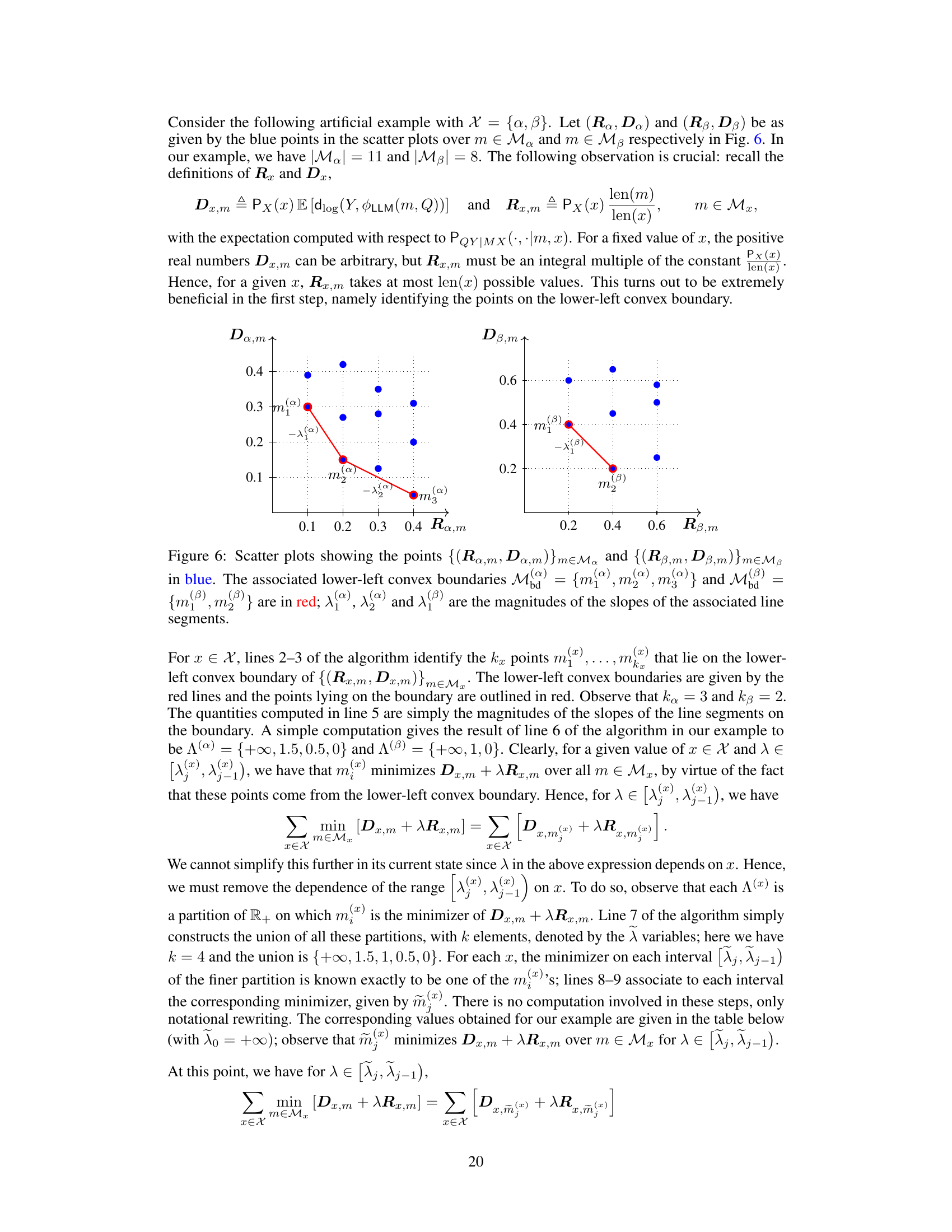
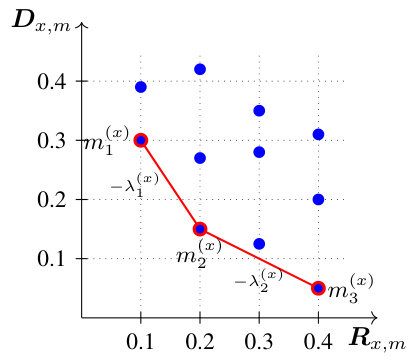
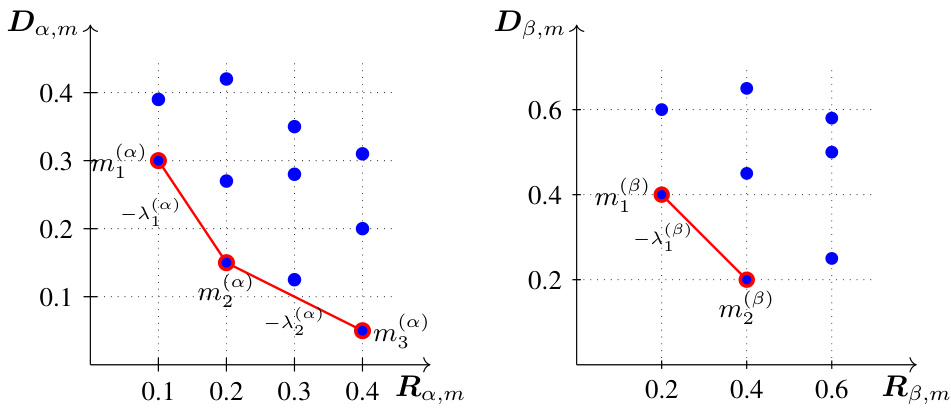
🔼 This table shows the output of lines 7-9 of Algorithm 1 which is used to compute the distortion-rate function via the dual linear program. The table is used as an example in the paper for demonstrating how the algorithm works. The table shows the values of lambda (λ), and the minimizers m(x) for each x ∈ X (where X is a set containing two elements, alpha and beta in this case), and for each range of lambda values defined by lines 5-6 of Algorithm 1.
read the caption
Table 1: The outputs produced by lines 7–9 of Algorithm 1 with (Ra, Da) and (Rβ, Dβ) as given in Fig. 6.
In-depth insights#
Prompt Compression Limits#
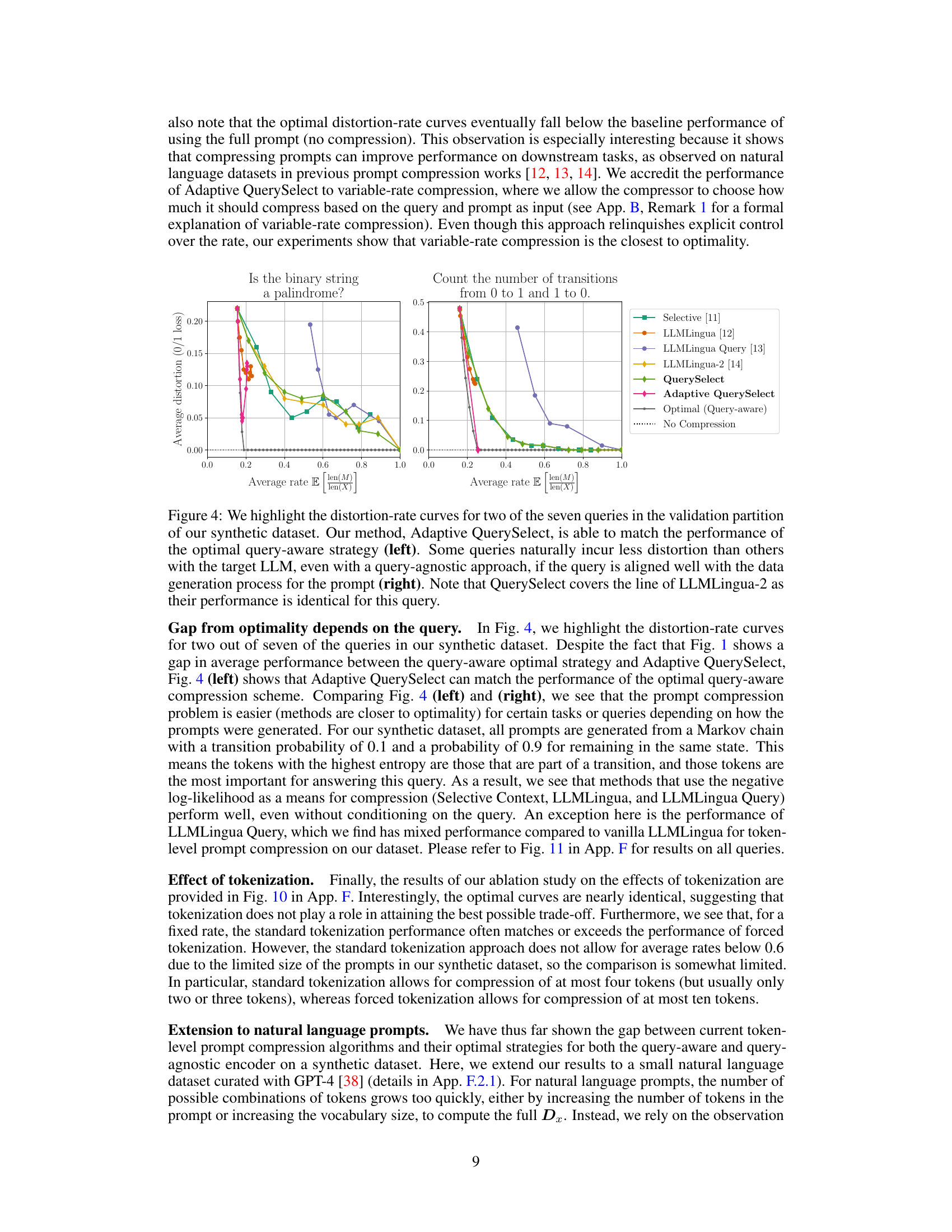
Prompt compression, aiming to reduce the input length for large language models (LLMs), faces inherent limitations. The core challenge lies in balancing compression rate and information loss (distortion). A theoretical framework, often involving rate-distortion theory, helps establish the fundamental limits of how much compression is possible before unacceptable distortion occurs. This framework often models the LLM as a black box, focusing on the input-output relationship without needing to know the model’s internals. Practical prompt compression methods frequently fall short of these theoretical limits, highlighting the need for more sophisticated algorithms. The impact of query awareness, where the compression strategy considers the downstream task, is significant, showing substantial performance gains compared to query-agnostic approaches. Tokenization, the process of converting text to numerical tokens, also influences compression effectiveness, and its inherent lossiness must be considered. In summary, prompt compression is a complex trade-off, and while theoretical limits provide a benchmark for progress, there’s still substantial room for improvement in practical algorithms.
Rate-Distortion Analysis#
Rate-distortion analysis in the context of prompt compression for large language models (LLMs) offers a powerful framework for understanding the fundamental limits of compression. It provides a theoretical baseline against which the performance of practical algorithms can be measured, revealing potential improvements. This approach elegantly quantifies the trade-off between compression rate (the reduction in prompt length) and distortion (the loss of information or semantic meaning). By formulating the problem as a rate-distortion optimization, the analysis identifies the optimal achievable compression for various distortion levels, showcasing the gap between theoretical limits and state-of-the-art methods. This gap highlights areas for future research focusing on algorithms that better approach the theoretical optimal. The analysis usually involves defining appropriate distortion metrics (e.g., log-loss or 0/1 loss) that capture the relevant notion of semantic similarity. The key insight here is that the rate-distortion analysis provides a principled way to evaluate and improve LLM prompt compression techniques.
Adaptive QuerySelect#
The proposed method, Adaptive QuerySelect, represents a significant advancement in prompt compression techniques for large language models (LLMs). It builds upon prior work, notably LLMLingua-2, by incorporating query-awareness and variable-rate compression. This dual approach allows the algorithm to dynamically adjust its compression strategy based on the specific query and the content of the prompt, unlike earlier methods which used fixed compression rates. The key innovation is in its ability to achieve a more optimal balance between rate (compression level) and distortion (loss of semantic meaning), thereby leading to substantial performance improvements over existing state-of-the-art methods. This is highlighted by its ability to sometimes achieve performance comparable to theoretically optimal prompt compression, demonstrating the effectiveness of its adaptive approach and the limitations of fixed-rate techniques. Adaptive QuerySelect effectively bridges the gap between existing methods and the theoretical optimum, offering a more practical and efficient solution for prompt compression in real-world LLM applications.
Tokenization Effects#
The effects of tokenization on prompt compression are significant and warrant deeper investigation. Different tokenization schemes lead to varying levels of compression effectiveness. A crucial aspect is that tokenization itself introduces a lossy transformation; grouping words into tokens inherently discards information about the individual word order and internal structure, which can be critical for retaining semantic meaning in the prompt. Consequently, the choice of tokenizer can significantly affect the performance of prompt compression methods. A key insight is the trade-off between lossy compression (achieved through aggressive tokenization) and preservation of semantic information. Optimally balancing this trade-off is crucial for achieving high compression rates without sacrificing the LLM’s ability to accurately respond to the compressed prompt.. Further research should explore the interaction of diverse tokenizers, exploring whether sub-word tokenizers, character-level tokenizers, or other strategies offer superior performance depending on prompt characteristics and downstream tasks. Investigating the impact of different tokenization strategies on various downstream tasks (like question answering, text generation etc) is also important to truly understand the implications.
Future Research#
Future research directions stemming from this prompt compression work could explore several avenues. Extending the theoretical framework to handle more complex prompt structures, such as those containing nested or conditional elements, is crucial for broader applicability. Further investigation into query-aware compression methods is needed, potentially involving machine learning techniques to learn optimal compression strategies for diverse query types and contexts. Empirical evaluations should focus on larger-scale datasets and more diverse tasks to robustly assess performance and generalization capabilities. Investigating the interplay between prompt compression and model architecture could reveal synergistic optimization strategies. Finally, exploring alternative compression paradigms, such as those based on semantic or contextual embeddings, could further improve compression ratios while minimizing information loss. Developing practical guidelines and best practices for prompt compression across diverse LLMs would also significantly enhance the field’s impact.
More visual insights#
More on figures
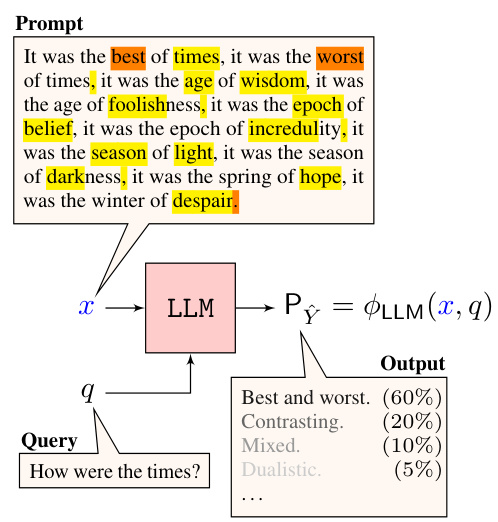
🔼 This figure illustrates the prompt compression process in LLMs. Panel (a) shows a standard LLM inference call using a long prompt and query. Panels (b) and (c) illustrate query-agnostic and query-aware prompt compression, respectively. The key difference is that the query-aware compressor (c) uses knowledge of the downstream task (the query) to select which tokens to keep in the compressed prompt. The goal is to create a shorter prompt that preserves the meaning of the original, leading to reduced inference costs.
read the caption
Figure 2: Model for prompt compression in LLMs. (a): Without prompt compression, the LLM takes a long Prompt and Query as input, and produces an Output distribution. (b) and (c): The prompt is passed through a compressor to obtain a shorter Compressed prompt and the LLM takes this compressed prompt and query as input instead. (b) The compressor does not have access to the query, and preserves all highlighted tokens. (c) The compressor has access to the query, and preserves only the tokens highlighted in orange.
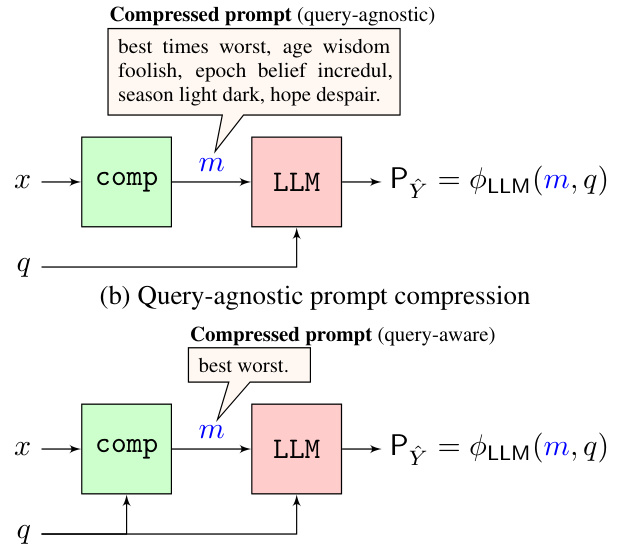
🔼 This figure illustrates the concept of prompt compression in LLMs. Panel (a) shows a standard LLM inference with a long prompt and a query. Panels (b) and (c) show how a prompt compressor reduces the input prompt length before providing it to the LLM. Panel (b) demonstrates query-agnostic compression (compressor doesn’t use the query information), while panel (c) shows query-aware compression (compressor uses the query). The highlighted tokens illustrate which parts of the original prompt are preserved in each compression method.
read the caption
Figure 2: Model for prompt compression in LLMs. (a): Without prompt compression, the LLM takes a long Prompt and Query as input, and produces an Output distribution. (b) and (c): The prompt is passed through a compressor to obtain a shorter Compressed prompt and the LLM takes this compressed prompt and query as input instead. (b) The compressor does not have access to the query, and preserves all highlighted tokens. (c) The compressor has access to the query, and preserves only the tokens highlighted in orange.
🔼 This figure shows the rate-distortion curves for various prompt compression methods on a synthetic dataset. It compares their performance against theoretical optimal curves for both query-aware (considering the downstream task) and query-agnostic (ignoring the task) approaches. Key observations highlight the significant performance gap between existing methods and the theoretical optimum, the benefits of query-aware compression, and the superior performance of the proposed Adaptive QuerySelect method.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.

🔼 This figure shows the rate-distortion curves for various prompt compression methods on a synthetic dataset with binary prompts. It compares the performance of existing methods against theoretically optimal query-aware and query-agnostic compression strategies, using two different distortion metrics (log loss and 0/1 loss). The results highlight that most existing methods significantly underperform the optimal strategies, underscoring the need for improved techniques. Notably, the proposed Adaptive QuerySelect method shows superior performance, even surpassing the optimal query-agnostic approach.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.
🔼 This figure shows the rate-distortion curves for various prompt compression methods on a synthetic dataset. The x-axis represents the compression rate (ratio of compressed prompt length to original prompt length), and the y-axis represents the distortion (measured using log loss and 0/1 loss). The figure highlights the gap between the performance of existing methods and the theoretical optimal performance, demonstrating the potential for improvement in prompt compression techniques. It also shows that query-aware methods (those that consider the downstream task/query) significantly outperform query-agnostic methods.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.
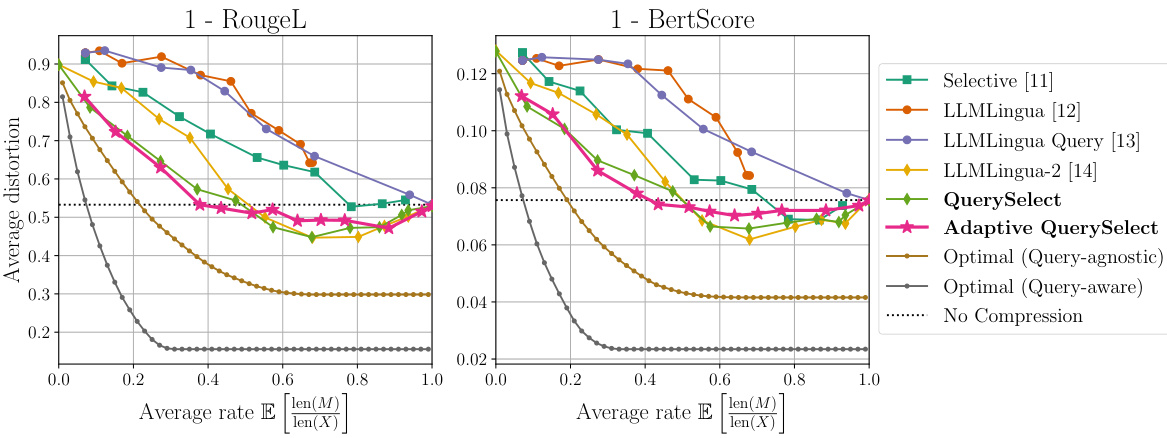
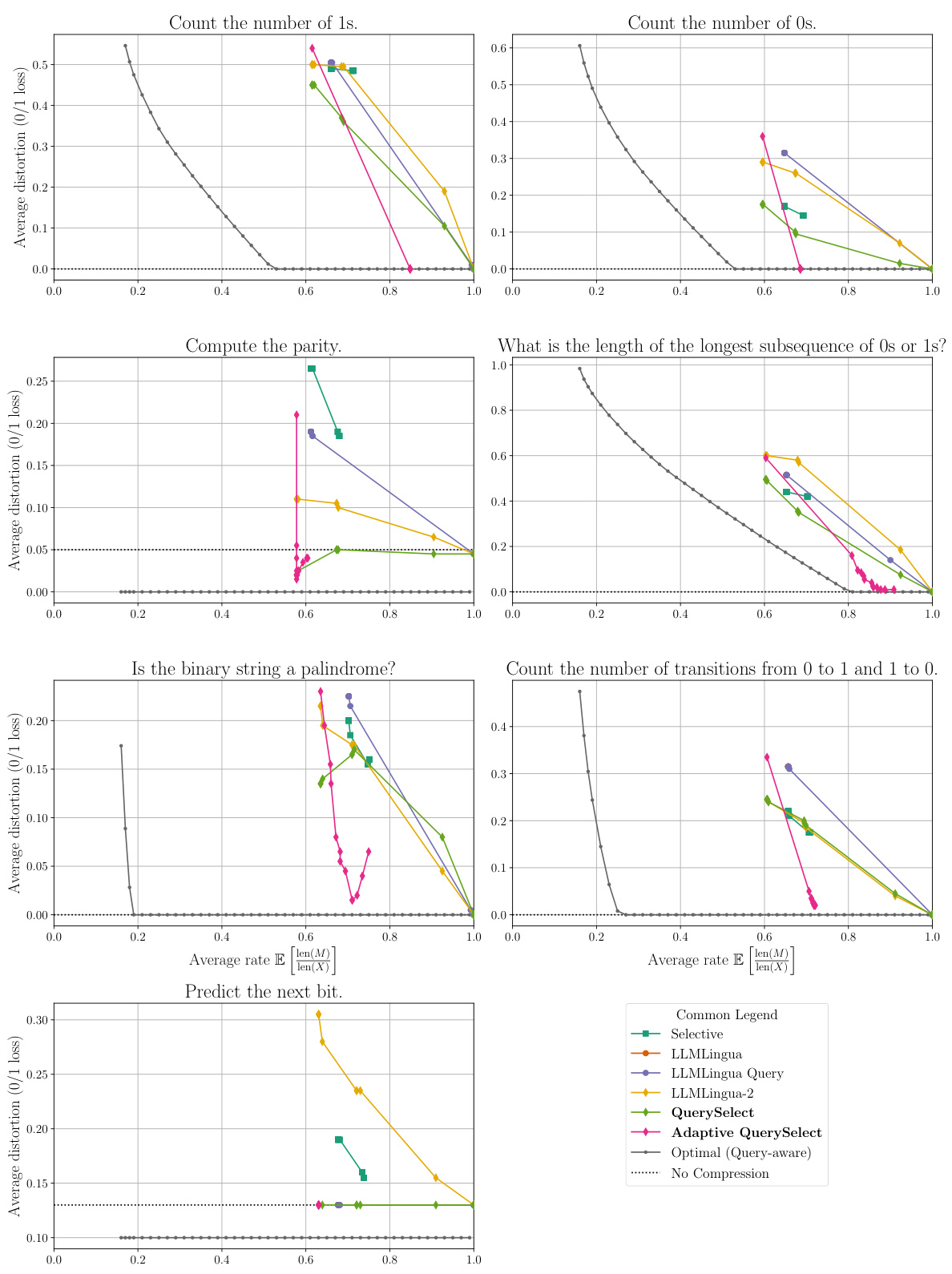
🔼 This figure compares various prompt compression methods on a natural language dataset using two different metrics: RougeL and BertScore. It shows the trade-off between compression rate (x-axis) and distortion (y-axis). Lower distortion indicates better performance. Because higher RougeL and BertScore scores are better, the y-axis shows 1 minus the distortion to represent this inversely.
read the caption
Figure 5: Comparison among all prompt compression methods on our natural language dataset. We show the rate-distortion trade-off for RougeL [23] (left) and BertScore [45] (right). Since a higher RougeL and BertScore metric is better, we plot '1- the computed average distortion' so that a higher rate should yield a lower loss.
🔼 This figure shows the distortion-rate curves for various prompt compression methods compared to the theoretical optimal performance (both query-aware and query-agnostic). It highlights the significant performance gap between existing methods and the optimal, emphasizing the potential for improvement. The figure uses two distortion metrics (log loss and 0/1 loss) and demonstrates the advantage of query-aware compression.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.
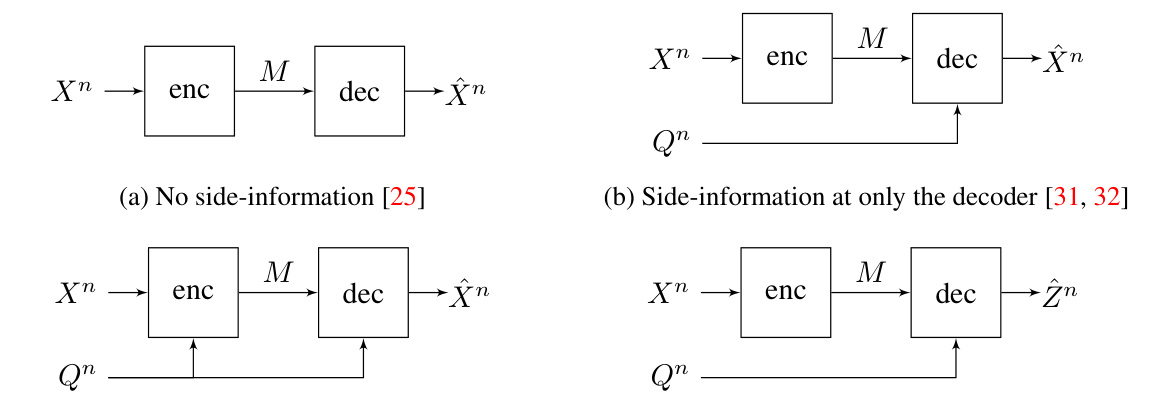
🔼 This figure shows four different rate-distortion models. (a) No side-information: This is the basic rate-distortion model where the encoder and decoder do not have access to any side information. (b) Side-information at only the decoder: In this model, the decoder has access to side information, which is correlated with the source data, but the encoder does not. (c) Side-information at the encoder and decoder: This is a more general model than (b), where both the encoder and decoder have access to the side information. (d) For function computation, Z = f(X, Q): In this model, the goal is to reconstruct a function of the source data and side information. Each model has different properties and is useful in different situations.
read the caption
Figure 7: Rate-distortion models of compression.

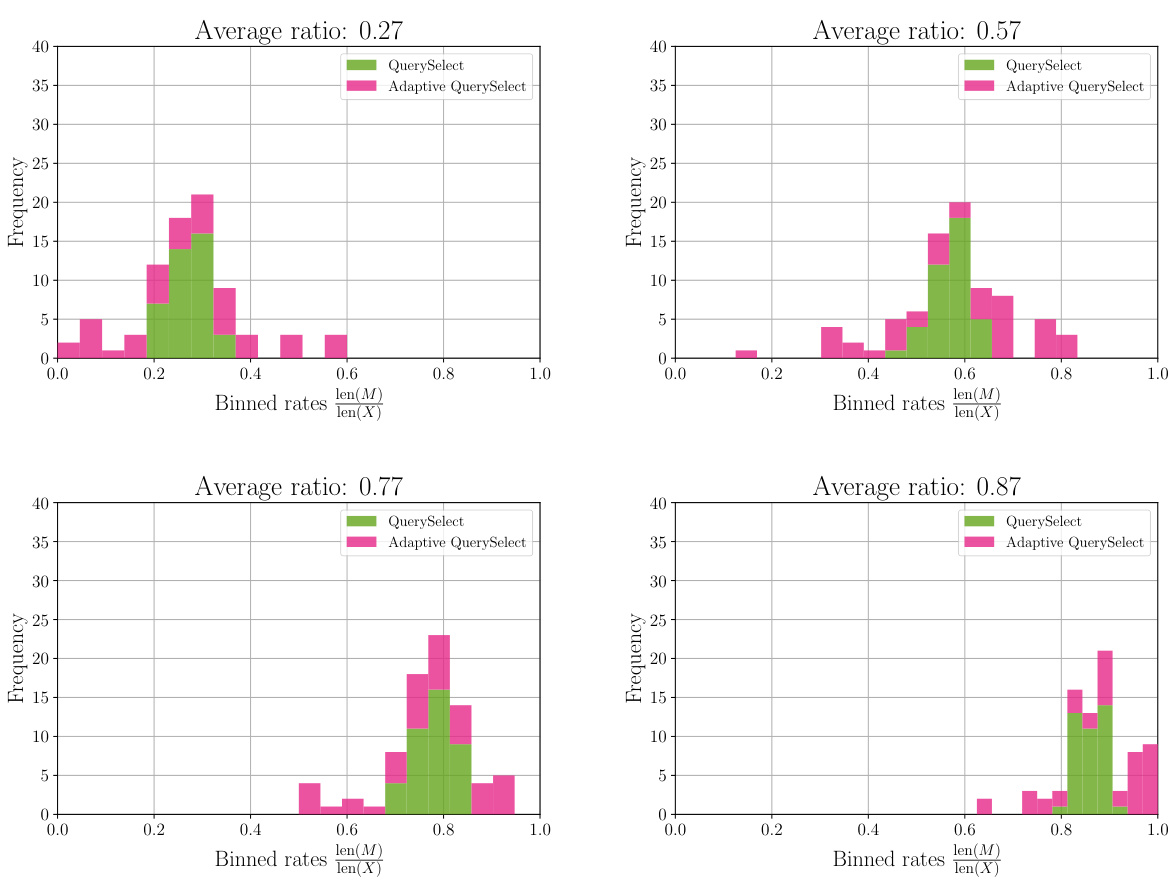
🔼 This figure compares the distortion-rate curves obtained using all possible shorter sequences versus only those obtained by pruning tokens from the original prompt. The near-identical results suggest that focusing on pruned prompts provides a sufficiently accurate approximation of the optimal distortion-rate curve.
read the caption
Figure 8: Query-agnostic distortion-rate curves plotted for log loss and 0/1 loss distortion measures. The curves marked with a ‘diamond’ are computed using all possible shorter sequences, while those marked with an ‘x’ are computed using only pruned versions of the original prompt. They are nearly identical, which suggests that a good approximation to the optimal distortion-rate curve can be obtained by considering pruned prompts only.
🔼 The figure shows the rate-distortion curves for various prompt compression methods on a synthetic dataset. It compares their performance against theoretical limits (query-aware and query-agnostic). Key observations are that existing methods fall short of the optimal performance, query-awareness significantly improves results, and the proposed Adaptive QuerySelect method outperforms existing methods and even surpasses the optimal query-agnostic strategy.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.

🔼 The figure shows the performance of various prompt compression methods on a synthetic dataset of binary prompts. It compares their rate-distortion trade-offs (compression rate vs. distortion) against the theoretical optimal performance for both query-aware (where the compressor knows the downstream task/query) and query-agnostic (where it does not) scenarios. The results highlight that existing methods significantly underperform the theoretical optimum and that query-aware methods are better than query-agnostic ones. Adaptive QuerySelect, a new variable-rate compression method proposed in the paper, achieves the best performance.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.
🔼 The figure shows the performance of various prompt compression methods compared to theoretical optimal performance on a synthetic dataset. The x-axis represents the compression rate, and the y-axis represents the distortion. The plot highlights that most existing methods fall short of the optimal performance, emphasizing the need for improved methods. It also demonstrates the significant improvement achievable by using query-aware methods, which consider the downstream task when compressing the prompt. Finally, it showcases the superior performance of the proposed Adaptive QuerySelect method, surpassing even the optimal query-agnostic approach.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.
🔼 This figure shows the performance of different prompt compression methods against the theoretical limits (both query-aware and query-agnostic) on a synthetic dataset. The x-axis represents the compression rate, and the y-axis shows the distortion. The results demonstrate that existing methods are far from optimal, highlighting the potential for improvement, especially with query-aware approaches. The proposed method, Adaptive QuerySelect, outperforms existing methods and achieves results closer to the theoretical limits.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.
🔼 This figure displays the rate-distortion curves for various prompt compression methods, comparing their performance against theoretical limits (query-aware and query-agnostic) on a synthetic dataset. It shows that current methods significantly underperform the optimal strategies and highlights the importance of query-aware approaches. Adaptive QuerySelect, the authors’ proposed method, outperforms existing techniques and even surpasses the optimal query-agnostic strategy.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.

🔼 This figure shows the performance of various prompt compression methods on a synthetic dataset. The left plot uses log loss, and the right plot uses 0/1 loss to measure the distortion. It highlights that query-aware methods significantly outperform query-agnostic methods, and that the proposed method, Adaptive QuerySelect, achieves the best performance, even exceeding the optimal query-agnostic strategy.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.
🔼 This figure shows the distortion-rate curves for various prompt compression methods on a synthetic dataset. The left panel uses log loss as the distortion metric, while the right uses 0/1 loss. The curves demonstrate that most existing methods perform far from the theoretical optimum. The figure highlights that query-aware methods (those that use the downstream query when compressing the prompt) significantly outperform query-agnostic methods. Importantly, the proposed Adaptive QuerySelect method outperforms all others and even surpasses the optimal query-agnostic strategy.
read the caption
Figure 1: The distortion-rate trade-off of all prompt compression methods compared to the query-aware and query-agnostic theoretical limits on a synthetic dataset with binary prompts. All distortions are computed with the log loss (left) and 0/1 loss (right) distortion metrics formally defined in (1). We observe that (1) most existing methods are far from the theoretical limit, suggesting that there is still room for improvement in this field, (2) conditioning on the query allows for a significant improvement, as seen by the performance of the query-aware method QuerySelect against the query-agnostic LLMLingua-2 [14], and (3) our proposed method Adaptive QuerySelect, a query-aware and variable-rate adaptation of LLMLingua-2, achieves the best performance among all methods considered, and is the only method to outperform the optimal query-agnostic strategy.
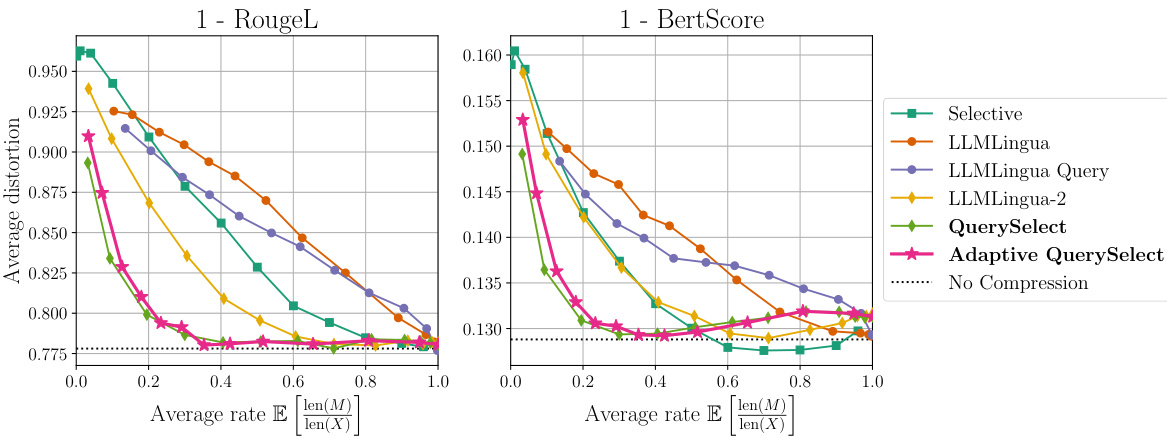
🔼 This figure compares various prompt compression methods’ performance on a natural language dataset using RougeL and BertScore as metrics. It displays the trade-off between compression rate (x-axis) and distortion (y-axis). Higher rates correspond to more compression, while lower distortions indicate better preservation of meaning. The plot uses 1 - metric score to represent the distortion, resulting in lower values indicating better compression. The optimal strategy for both query-aware and query-agnostic settings are displayed for comparison.
read the caption
Figure 5: Comparison among all prompt compression methods on our natural language dataset. We show the rate-distortion trade-off for RougeL [23] (left) and BertScore [45] (right). Since a higher RougeL and BertScore metric is better, we plot \'1- the computed average distortion\' so that a higher rate should yield a lower loss. We discuss the choice of our metrics in App. F.2.2.

🔼 This figure compares the performance of various prompt compression methods on a natural language dataset using two different distortion metrics: RougeL and BertScore. It shows the trade-off between the compression rate (x-axis) and the distortion (y-axis). Because higher RougeL and BertScore values indicate better performance, the y-axis is inverted to show a lower distortion (better performance) with a higher compression rate. The optimal strategies (with and without query awareness) are also included as baselines for comparison.
read the caption
Figure 5: Comparison among all prompt compression methods on our natural language dataset. We show the rate-distortion trade-off for RougeL [23] (left) and BertScore [45] (right). Since a higher RougeL and BertScore metric is better, we plot '1- the computed average distortion' so that a higher rate should yield a lower loss. We discuss the choice of our metrics in App. F.2.2.
More on tables

🔼 This table shows example prompts and queries from the validation set of the synthetic dataset used in the paper’s experiments. The prompts are binary strings, and the queries are natural language questions designed to elicit specific information about those strings. The corresponding answers are also provided.
read the caption
Table 2: One example of each query from the validation set of our synthetic dataset

🔼 This table provides four examples of prompts and their associated queries and answers from a small natural language dataset used in the paper’s experiments. Each row represents a prompt (a short text passage), a query (a question related to the prompt), and the corresponding answer. The dataset is used to evaluate the performance of prompt compression methods on natural language data.
read the caption
Table 3: One example of each prompt from our natural language dataset.
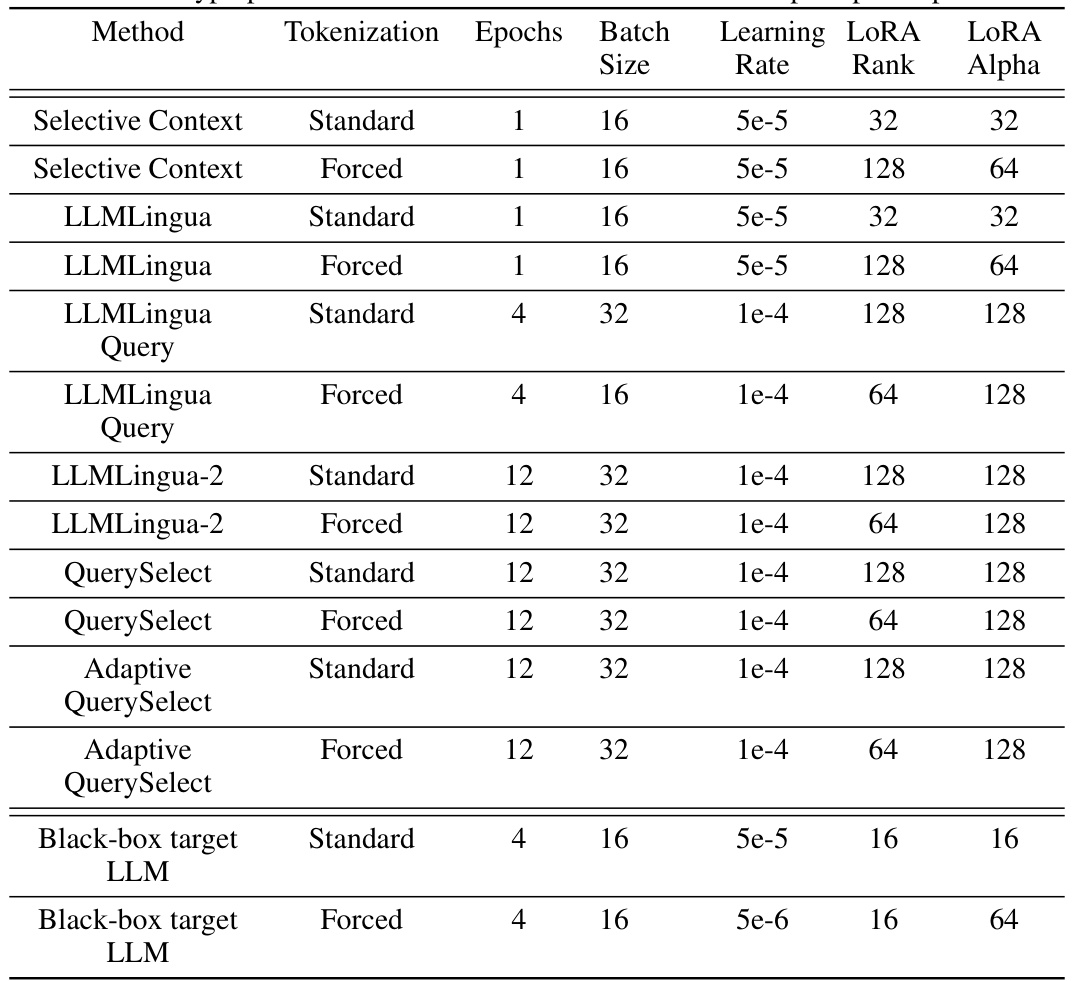
🔼 This table lists the hyperparameters used for fine-tuning LLMs in each prompt compression method. It includes tokenization type (standard or forced), number of epochs, batch size, learning rate, LoRA rank and LoRA alpha. The hyperparameters were determined through a grid search process, choosing the best performing set on a test dataset. The methods are: Selective Context, LLMLingua (with and without query), LLMLingua-2 (with and without query), QuerySelect, Adaptive QuerySelect, and the black-box target LLM.
read the caption
Table 4: Final set of hyperparameters used to train the LLM used in each prompt compression method.

🔼 This table shows the hyperparameters used for fine-tuning the language models used in each prompt compression method. It lists the tokenization method (standard or forced), number of epochs, batch size, learning rate, LoRA rank, and LoRA alpha for each method: Selective Context, LLMLingua (standard and forced), LLMLingua Query (standard and forced), LLMLingua-2 (standard and forced), QuerySelect (standard and forced), Adaptive QuerySelect (standard and forced), and the black-box target LLM (standard and forced).
read the caption
Table 4: Final set of hyperparameters used to train the LLM used in each prompt compression method.
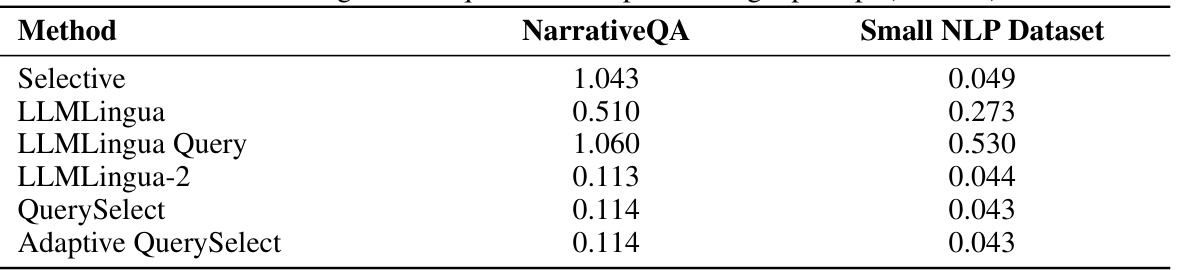
🔼 This table presents the average time taken to compress a single prompt, in seconds, for different prompt compression methods. The timings are broken down for two datasets: NarrativeQA and a smaller natural language processing (NLP) dataset. The table allows for a comparison of the computational efficiency of the various methods.
read the caption
Table 6: Average time required to compress a single prompt (seconds).
Full paper#