↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-image models struggle with accurately personalizing multiple subjects simultaneously, often resulting in mixed identities or missing subjects. This is mainly due to the models’ difficulty in disentangling the individual characteristics of different subjects when generating a composite image. Existing methods, such as Cut-Mix or DreamBooth, often fail to address this issue effectively, either producing unnatural-looking images or failing to properly represent all subjects.
MuDI is proposed as a novel method to resolve this problem. By using a foundation model for image segmentation to separate individual subjects, MuDI effectively creates a training strategy that disentangles the subjects’ identities. Moreover, the use of segmented subjects as an initialization step provides additional information which avoids generating images of missing subjects. Experiments demonstrated that MuDI significantly outperforms other baselines, achieving a notably higher success rate in identity separation. The introduction of a new evaluation metric, D&C, further enhances the ability to evaluate the performance of methods for multi-subject personalization.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multi-subject personalization in text-to-image models. It addresses a significant challenge in the field—identity mixing—offering a novel solution with substantial implications for various applications. The proposed method, MuDI, and its new evaluation metric, D&C, offer valuable tools and a new direction for future research in this domain. Furthermore, the work’s exploration of LLM-guided initialization and iterative training opens up exciting avenues for enhancement and exploration.
Visual Insights#

This figure shows the results of MuDI, a multi-subject personalization method for text-to-image models. Given a small number of images of different subjects (shown in red boxes), MuDI can generate new images of those subjects in various settings without mixing their identities. The example shows the model generating images of subjects in contexts not present in the training data (Cloud Man and Blue Alien).

This table presents the results of ablation studies conducted on the MuDI model. It shows the impact of removing key components of the model, such as the Seg-Mix augmentation, the initialization method, and the use of descriptive classes. The D&C-DS and D&C-DINO metrics measure multi-subject fidelity, showing the performance drop when each component is removed. The results highlight the importance of each component for achieving high multi-subject fidelity.
In-depth insights#
Identity Decoupling#
The concept of ‘Identity Decoupling’ in the context of multi-subject personalization for text-to-image models presents a crucial challenge and an important contribution. Current methods often struggle when generating images with multiple subjects simultaneously, leading to a mixing of identities and attributes. Identity decoupling aims to solve this by separating the individual identities of each subject within the model’s representation, ensuring that each subject is rendered distinctly. This is achieved by effectively disentangling the unique features of each subject from the combined image representation. The proposed approach often leverages techniques like image segmentation to isolate individual subjects before feeding them into the model, creating a cleaner input that reduces identity mixing. This decoupling is particularly critical when dealing with subjects that share visual similarities, making it harder for the model to differentiate them without dedicated strategies. The success of identity decoupling relies heavily on both the quality of the input segmentation and the model’s capacity to learn independent representations. Effective identity decoupling is not just an improvement in image quality but enhances the model’s understanding of individual subjects within a complex scene, which is important for a wide variety of applications, such as creating customized avatars or generating diverse scenes with multiple characters.
SegMix Augmentation#
SegMix augmentation, a novel data augmentation strategy, tackles identity mixing in multi-subject image personalization. It leverages a foundation model for image segmentation to isolate individual subjects from their backgrounds, creating segmented images. These segmented subjects are then randomly composed and recombined, effectively decoupling identities and preventing the blending of attributes during training. This process differs significantly from prior techniques like CutMix, which merely stitches images together, resulting in unnatural artifacts. SegMix provides a more sophisticated approach to identity disentanglement, resulting in improved personalization of multiple subjects simultaneously. The core benefit is the avoidance of identity mixing, a common problem that plagues other methods. By independently training on separated identities, the model learns to generate images of multiple subjects without merging their characteristics.
Multi-Subject Fidelity#
The concept of “Multi-Subject Fidelity” in a research paper would delve into the accuracy and effectiveness of a model in handling multiple subjects simultaneously. A high multi-subject fidelity suggests the model can successfully differentiate between subjects, avoid identity mixing (where features of one subject bleed into another), and accurately represent each subject’s unique characteristics in the generated output. Conversely, low fidelity indicates the model struggles with this task, leading to blurry, indistinct results, or combinations of subject features that don’t reflect reality. The evaluation of multi-subject fidelity would likely involve a multifaceted approach, employing both quantitative metrics (like precision, recall, and F1-score tailored to multi-subject scenarios) and qualitative assessments (human evaluation comparing generated images to ground truth). Human evaluation is particularly crucial because it can uncover subtle issues that quantitative metrics might miss, such as unnatural-looking combinations of features or a lack of overall realism. A robust methodology for measuring multi-subject fidelity would need to account for factors like subject similarity (more similar subjects pose a greater challenge), image quality, and the complexity of the generation task. Therefore, exploring this concept necessitates designing novel metrics and evaluation strategies beyond those used for single-subject scenarios.
Ablation Study#
An ablation study systematically removes components of a model or system to assess their individual contributions. In the context of a research paper, this would involve a series of experiments where parts of the proposed method are disabled or altered, one at a time. The goal is to isolate the impact of each component and demonstrate its necessity for achieving the overall performance. For example, if a model relies on multiple modules, an ablation study might remove each module individually to determine if the overall performance drops significantly. The results of ablation studies are usually presented in a table or graph, showing the performance metrics with and without each component. By carefully designing and executing an ablation study, researchers can gain valuable insights into how different parts of their system interact and identify which components are most crucial for success. Well-designed ablation studies improve the robustness of the claims made in the paper and help readers understand the mechanisms behind the model’s effectiveness. They demonstrate not only what works, but also why it works, leading to more trustworthy and informative results.
Future Directions#
Future research could explore more sophisticated methods for decoupling identities, especially when dealing with semantically similar subjects. Improving the robustness of the model to variations in pose, lighting, and background is crucial for real-world applications. Another area for development involves handling a larger number of subjects simultaneously, potentially through hierarchical or modular approaches. Investigating the impact of different pre-trained models and exploring alternative architectural designs could improve performance and generalization. Finally, thorough ethical considerations are paramount. Addressing potential biases, ensuring privacy and preventing misuse of the technology should be a central focus of future development.
More visual insights#
More on figures

This figure shows the ability of the MuDI model to personalize a text-to-image model to generate images of multiple subjects without mixing their identities. The red boxes highlight the input images of multiple subjects used for personalization. The model successfully generates new images of these subjects in various poses and contexts, demonstrating the effectiveness of MuDI in handling multi-subject personalization.

This figure shows the overall architecture of the MuDI model. It consists of three stages: preprocessing, training, and inference. In the preprocessing stage, the model uses SAM and OWLv2 to automatically obtain segmented subjects. In the training stage, the model uses a data augmentation method called Seg-Mix to augment the training data. Seg-Mix randomly positions segmented subjects with controllable scales to train the diffusion model. In the inference stage, the model initializes the generation process with mean-shifted noise created from segmented subjects. This provides a signal for separating identities without missing.

This figure illustrates the Detect-and-Compare (D&C) method for evaluating multi-subject fidelity. The left panel shows a schematic of the D&C process: it uses a pre-trained object detector (OWLv2) to locate subjects in generated images and reference images; then it calculates pairwise similarity scores between detected and reference subjects using either DreamSim or DINOv2; finally, it compares the ground truth similarity matrix (SGT) to the calculated similarity matrix (SDC) using a difference metric to quantify identity mixing. The right panel presents the correlation between D&C (using DreamSim and DINOv2) and human evaluation scores. It shows that the D&C metric correlates well with human judgments of multi-subject image quality.

This figure compares the results of five different multi-subject personalization methods: Textual Inversion, DreamBooth, DreamBooth with region control, Cut-Mix, and the proposed MuDI method. Each column shows the results of a given method applied to the same set of reference images and prompt. The results demonstrate MuDI’s superior ability to personalize multiple subjects without mixing identities, unlike the other methods.
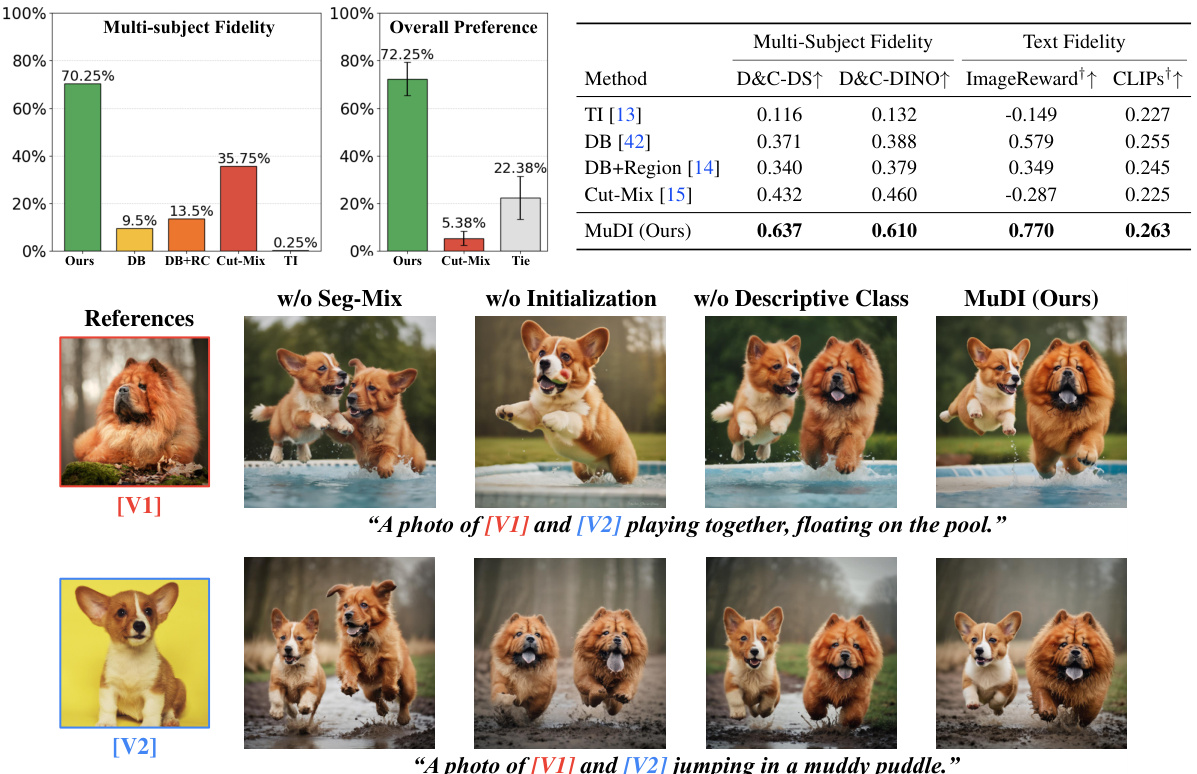
The figure presents the results of human evaluation and quantitative metrics to assess the performance of the proposed MuDI model on multi-subject image generation. The left panel shows the results of human evaluation on multi-subject fidelity and overall preference, comparing MuDI with other methods. The right panel provides quantitative results using metrics like D&C-DS, D&C-DINO, ImageReward+, and CLIPs+ for multi-subject fidelity and text fidelity. The results demonstrate MuDI’s superiority in producing high-quality personalized images of multiple subjects without identity mixing.

This figure demonstrates MuDI’s ability to personalize more than two subjects simultaneously without mixing their identities. The left panel (a) shows qualitative examples of MuDI successfully personalizing multiple subjects in different scenes. The right panel (b) presents a graph illustrating the success rate of MuDI (and comparison baselines) as the number of subjects to be personalized increases. It visually demonstrates the effectiveness of MuDI in handling multiple subjects, even with increasing complexity.

This figure compares the results of five different multi-subject personalization methods on the same set of reference images and prompts. It visually demonstrates how each method handles the task of generating images of multiple subjects simultaneously, highlighting differences in identity mixing, artifact generation, and overall image quality. MuDI is shown to produce superior results compared to the other methods.

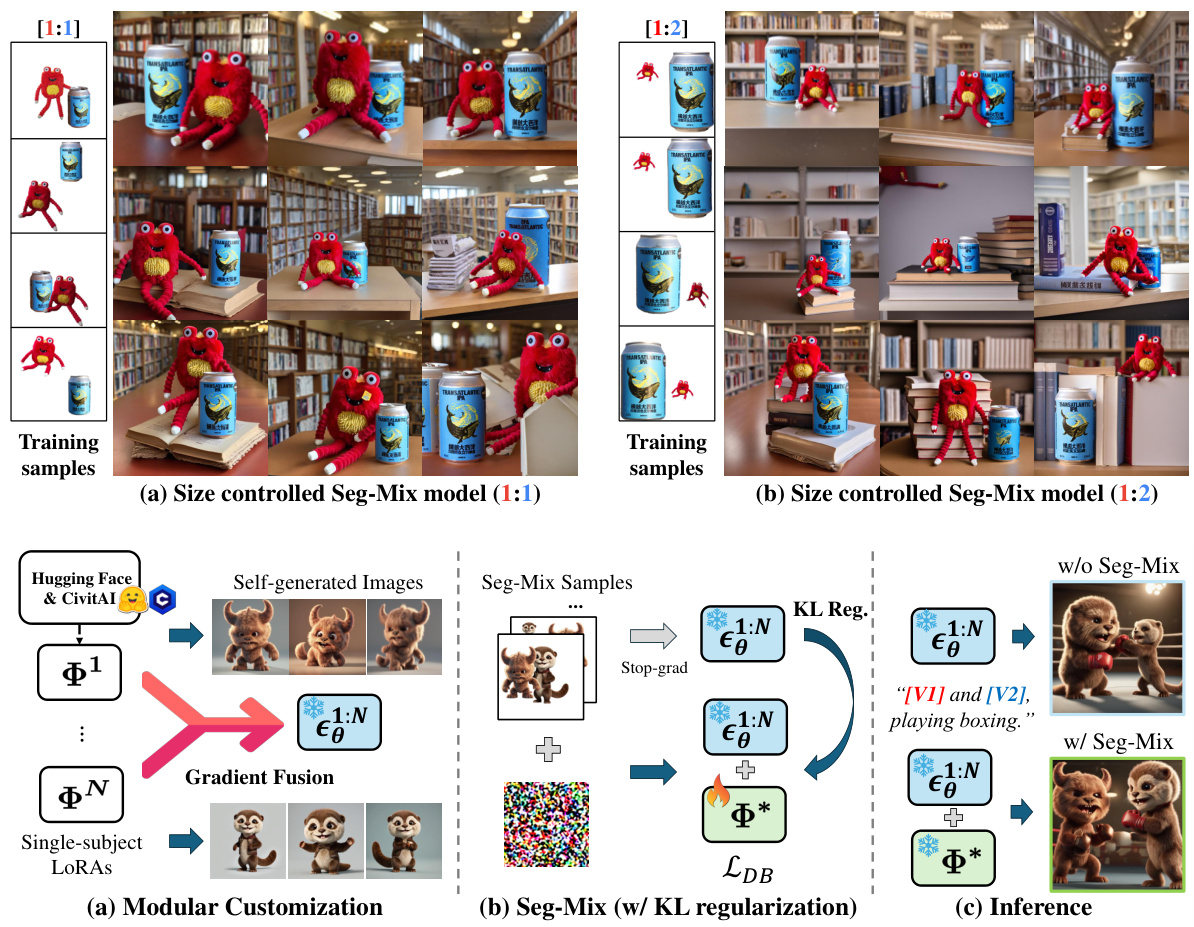
This figure shows two examples of additional use cases for the MuDI model. The first (a) demonstrates controlling the relative size of subjects during image generation by resizing segmented subjects before input to the model. The second (b) shows how MuDI can be applied to a modular customization approach, where pre-trained models are combined before fine-tuning with Seg-Mix to achieve better identity separation.

The figure shows a comparison of images generated using the Cut-Mix method with and without a negative prompt. The top row shows images generated with the negative prompt ‘A dog and a dog’, which reduces artifacts but leads to over-saturation. The bottom row shows images generated without the negative prompt.

This figure shows eight pairs of similar subjects used to evaluate the performance of MuDI and other multi-subject personalization methods. Each pair includes a few reference images and three images generated by a baseline method (DreamBooth), showcasing the challenge of distinguishing between similar subjects. The DreamSim scores below indicate the level of similarity between subjects within each pair.

This figure illustrates the Detect-and-Compare (D&C) method, which is a novel metric for evaluating the fidelity of multi-subject image generation. The left panel shows a schematic diagram of D&C, which involves calculating the similarity between detected subjects in a generated image and the reference images, and then comparing this similarity to a ground truth similarity. This comparison is used to produce a D&C score representing the overall fidelity. The right panel shows the correlation between the D&C score and human evaluation results, indicating a strong positive correlation.

This figure shows the screenshots of the questionnaires used in the human evaluation process. The evaluation focused on two aspects: multi-subject fidelity and overall preference. The multi-subject fidelity section asked raters to determine if subjects from reference images appeared and closely resembled those in a generated image. The overall preference section presented raters with two images (one from MuDI and one from a competing method), and asked them to choose a preferred image based on criteria of similarity to reference subjects, alignment with a given text prompt, and image naturalness. This evaluation process is intended to assess MuDI’s ability to accurately generate images with multiple subjects without mixing identities.

This figure compares the results of five different multi-subject personalization methods: Textual Inversion, DreamBooth, DreamBooth with region control, Cut-Mix, and MuDI. Each method is applied to generate images of two subjects (a Corgi and a Chow Chow) based on a set of reference images and prompts describing different scenarios, such as the dogs playing in a garden, at the beach, or on a hill. The results show that MuDI is significantly better at separating the identities of the two subjects and preventing identity mixing than other methods.

This figure provides a visual overview of the MuDI framework, showing the preprocessing, training, and inference stages. Preprocessing involves segmenting subjects from images using SAM and OWLv2. During training, a data augmentation technique called Seg-Mix randomly positions and scales segmented subjects to train the diffusion model and prevent identity mixing. Finally, inference initializes the generation process with mean-shifted noise derived from segmented subjects, facilitating identity separation during image generation.

This figure compares the results of several multi-subject image personalization methods on two dog breeds: Corgi and Chow Chow, using the SDXL model. It demonstrates that DreamBooth generates images with mixed breed characteristics, Cut-Mix produces images with noticeable artifacts, and region control is ineffective in preventing mixed identities. In contrast, the proposed MuDI method successfully generates images of each dog breed separately without mixing identities or artifacts.

This figure compares several multi-subject image personalization methods using two similar dog breeds: Corgi and Chow Chow. It highlights the issues of identity mixing and artifacts produced by existing techniques like DreamBooth and Cut-Mix, showcasing how the proposed MuDI method effectively personalizes both dogs without blending their features or producing unwanted visual distortions.

This figure compares the results of five different multi-subject image generation methods using the same prompts and random seed to highlight the differences in their ability to generate images without identity mixing and other artifacts. The methods compared are Textual Inversion, DreamBooth, DreamBooth with region control, Cut-Mix, and the proposed MuDI method. MuDI is shown to produce the most realistic and artifact-free results.

This figure compares the results of five different multi-subject image personalization methods using SDXL. Each row represents a different method (Textual Inversion, DreamBooth, DreamBooth with region control, CutMix, and MuDI), and each column shows images generated from the same prompt and random seed. This allows for a direct visual comparison of the strengths and weaknesses of each method in terms of subject identity preservation, generation quality, and the presence of artifacts.

This figure shows an ablation study on the effect of the scaling factor (γ) used in the inference initialization of the MuDI model. The left panel (a) displays generated images with different γ values, demonstrating how increasing γ preserves more information from the initial latent, leading to better composition of multiple subjects. The right panel (b) shows the denoising process (x_0-prediction) over inference steps, highlighting that the model generates the main structure of the image within the first 10 steps. This visualization emphasizes that the initial latent, enriched with subject information, guides the generation process effectively from the very start, achieving higher quality multi-subject outputs.
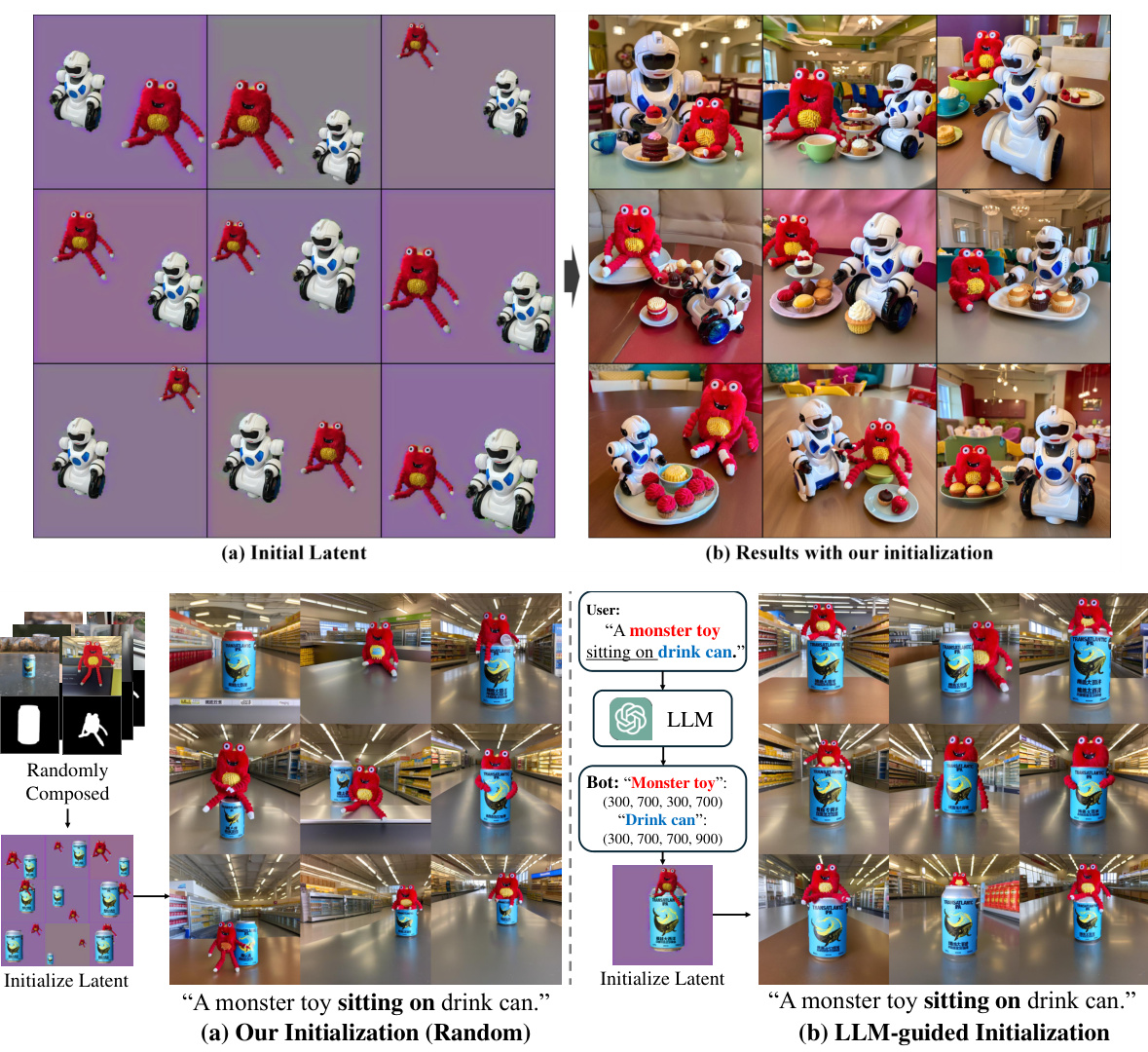
This figure shows the comparison between randomly initialized latent space and LLM-guided initialization for generating images with interactions between objects. The random initialization sometimes fails to reflect the interaction described in the prompt, whereas the LLM-guided initialization successfully generates images according to the prompt, showing a clear improvement in the interaction between the objects.

This figure shows a comparison of the results obtained from DreamBooth and Cut-Mix, both using ControlNet, when generating images with multiple subjects. Both methods fail to effectively decouple the identities of similar subjects, resulting in images where subjects have mixed features or attributes.

This figure shows the results of applying the proposed inference initialization method to pre-trained text-to-image models. Two scenarios are shown: (a) unseen subjects (where the model has not been trained on the subjects) and (b) known subjects (where the model has been trained on the subjects). The results demonstrate that the proposed initialization is effective for improving the quality of generated images for unseen subjects and mitigating identity mixing for known subjects.

This figure shows an analysis of the success rate of MuDI when personalizing different numbers of subjects and provides qualitative examples of images generated with 4 and 5 subjects. Part (a) is a graph comparing MuDI’s success rate with a baseline method (DreamBooth) for 2 to 5 subjects. Part (b) showcases example images generated by MuDI, successfully showing 4 and 5 distinct subjects without any identity mixing issues.

This figure provides a visual overview of the MuDI framework, illustrating the preprocessing, training, and inference stages. The preprocessing stage uses SAM and OWLv2 to segment individual subjects from input images. The training stage employs a data augmentation technique called Seg-Mix, which involves randomly composing segmented subjects with varied scales to help the model learn to decouple identities. The inference stage uses a mean-shifted noise initialization based on the segmented subjects, thus preventing identity mixing and ensuring the subjects are generated separately.

This figure shows a qualitative comparison of images generated by four different multi-subject personalization methods using Stable Diffusion v2. The methods compared are Custom Diffusion, Cones2, Mix-of-Show (with and without ControlNet), and MuDI. Each method’s output is shown for six different prompts, allowing for a visual comparison of the models’ abilities to generate images of multiple subjects without mixing identities. The table below the image provides quantitative results for each model, including multi-subject fidelity scores, text fidelity scores and generation speed.

This figure provides a visual overview of the MuDI framework. Panel (a) shows the preprocessing step where the Segment Anything Model (SAM) and OWLv2 are used to segment individual subjects from input images. Panel (b) illustrates the Seg-Mix data augmentation technique, where segmented subjects are randomly positioned and scaled to create diverse training examples. Panel (c) details the inference stage, showcasing how MuDI initializes the image generation process with mean-shifted noise derived from the segmented subjects. This initialization method helps prevent identity mixing during the generation of multi-subject images.
This figure provides a visual overview of the MuDI framework’s three main stages: preprocessing, training, and inference. The preprocessing stage uses SAM and OWLv2 to segment subjects from input images. The training stage leverages a novel data augmentation technique called Seg-Mix to improve identity decoupling. The inference stage initializes the generation process using mean-shifted noise derived from the segmented subjects to further enhance identity separation during image generation.
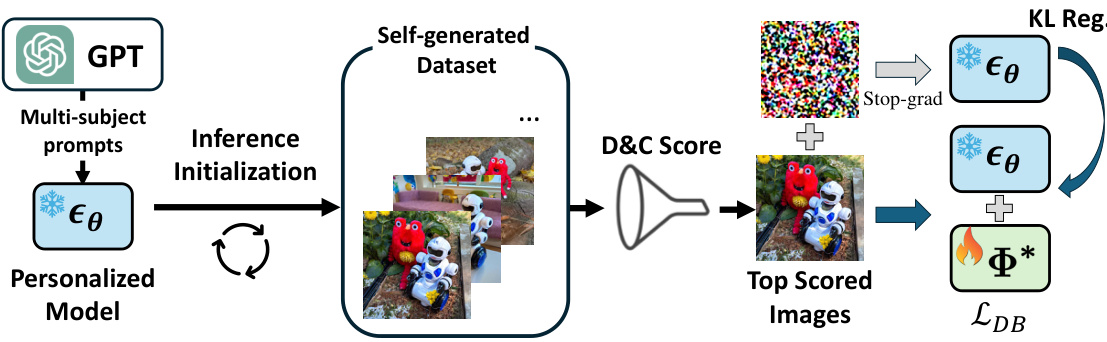
This figure illustrates the MuDI framework’s three main stages: preprocessing, training, and inference. Preprocessing uses SAM and OWLv2 to segment individual subjects from input images. Training employs a novel data augmentation technique called Seg-Mix, which randomly composes these segmented subjects at various scales, effectively decoupling identities. Inference initializes the generation process not with random noise, but with a mean-shifted noise derived from the segmented subjects, further assisting identity separation.

This figure shows a comparison of four different methods for multi-subject image generation: Seg-Mix (baseline), Seg-Mix with iterative training (IT), MuDI (Seg-Mix + Initialization), and MuDI with IT. The results demonstrate the improvements in identity separation and subject fidelity achieved through iterative training and the use of MuDI’s initialization method. The images generated show the different methods’ success or failure at avoiding identity mixing and missing subjects.

This figure shows the results of personalizing 11 different subjects (dogs and cats) simultaneously using MuDI and a single LoRA. The use of descriptive class names for each animal (like ‘Weimaraner’ instead of just ‘dog’) helps the model distinguish between similar-looking subjects. The image demonstrates MuDI’s ability to handle a large number of subjects without identity mixing, even when the subjects are visually similar.

This figure provides a visual overview of the MuDI framework. It shows the preprocessing stage where subjects are segmented, the training stage where a data augmentation technique called Seg-Mix is used, and the inference stage where a mean-shifted noise based on subject segmentation is used for initialization. This approach helps separate identities during image generation.

This figure shows the limitations of the MuDI model. The first subfigure shows that very similar subjects are hard to distinguish, leading to identity mixing. The second subfigure demonstrates that complex prompts can lead to the model ignoring some subjects. The third subfigure illustrates that when dealing with more than three subjects, MuDI sometimes duplicates subjects in the generated image while still mitigating identity mixing.
Full paper#



















