↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current visual policy learning methods often treat image prediction and robot action as separate tasks. This separation limits performance because these processes share underlying physical dynamics. The inability to fully leverage large-scale video datasets for robot training further hinders progress.
The paper introduces PAD, which tackles this limitation by unifying image prediction and robot action into a joint denoising process. Using Diffusion Transformers, PAD seamlessly integrates visual and robot state information, enabling simultaneous prediction of future images and actions. This approach leads to significant performance improvements on established benchmarks like Metaworld and better generalization to unseen tasks in real-world robotic manipulation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between image prediction and robot action, two seemingly distinct but highly related areas in AI. By unifying these processes, it enables more robust and generalizable robotic control, opening exciting new avenues for research in visual policy learning and data-efficient imitation learning. Its real-world applicability and strong performance gains make it particularly relevant to current research trends focusing on bridging the sim-to-real gap and developing more capable AI systems for robotics.
Visual Insights#

This figure compares the success rates of different methods across multiple robotic manipulation tasks. The methods include Diffusion Policy, SuSIE, RT-1, RT-2*, GR-1, and PAD (the authors’ method). The tasks are categorized into two domains: simulated Metaworld tasks (all tasks) and real-world Panda robot tasks (seen and unseen tasks). PAD shows consistently high success rates across both domains, especially on unseen tasks, highlighting its strong generalization capabilities.
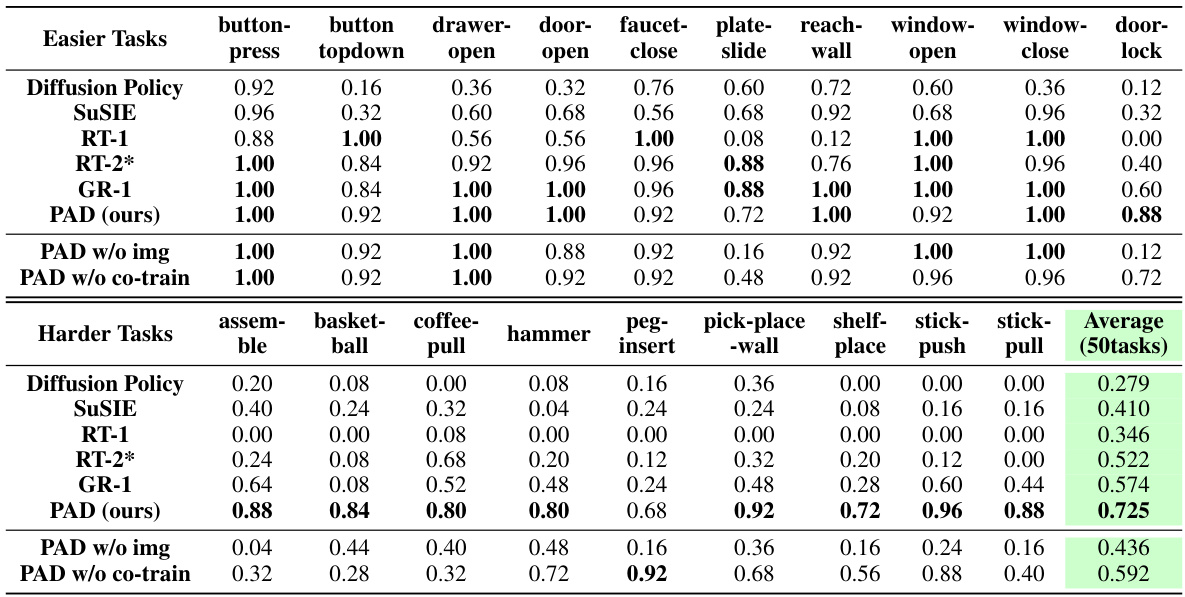
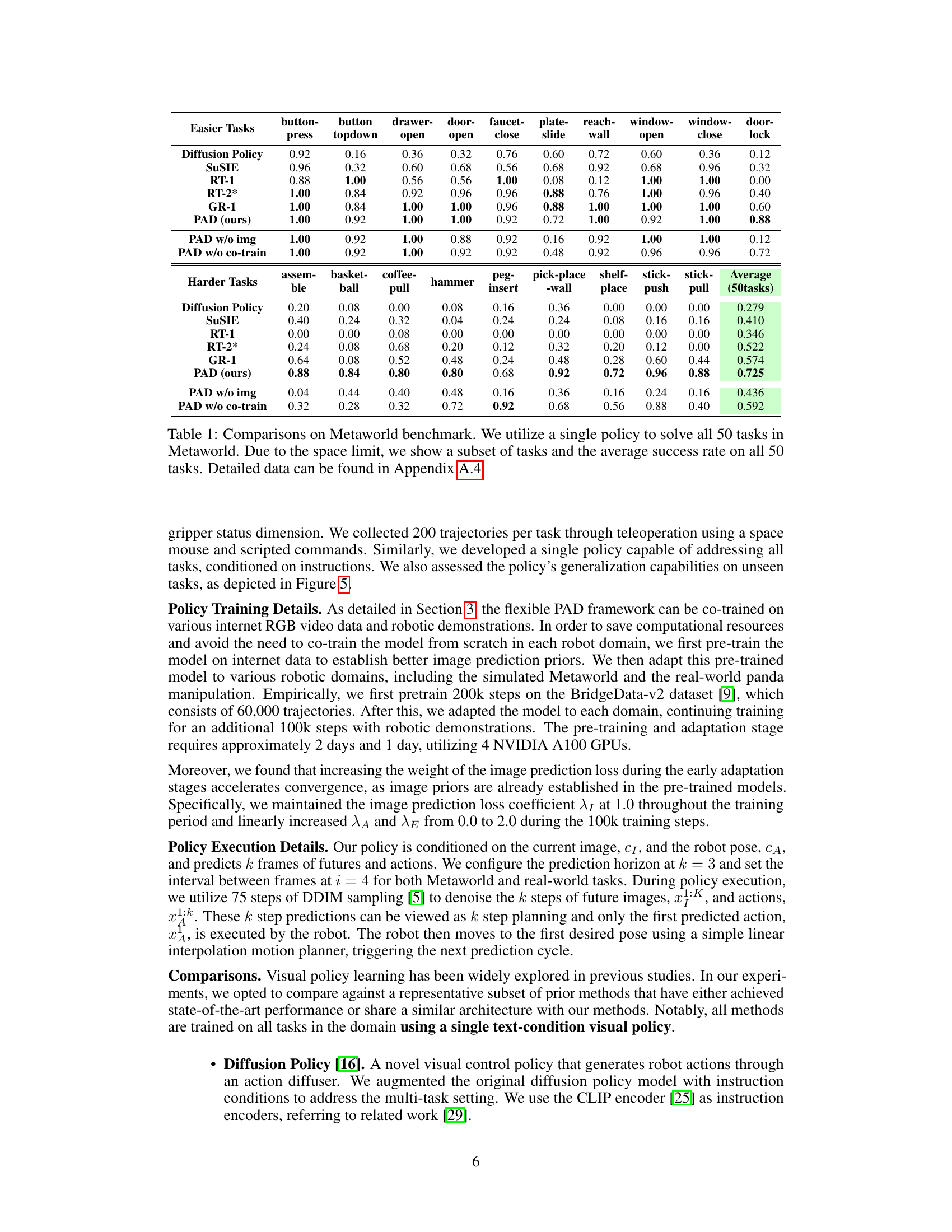
This table presents a comparison of different methods on the Metaworld benchmark, focusing on multi-task performance. It shows the success rate of each method on a selection of tasks and the average success rate across all 50 tasks. The table also includes results for ablated versions of the PAD model (PAD w/o img and PAD w/o co-train) to demonstrate the impact of using image data and co-training on both robotic data and video data.
In-depth insights#
Joint Denoising#
The concept of “Joint Denoising” in the context of visual policy learning, as described in the provided text, represents a significant advancement. It elegantly unifies the processes of image prediction and action generation within a single diffusion model. This joint approach leverages the inherent correlation between predicting future images and generating corresponding robot actions, recognizing that both tasks share underlying physical dynamics of the environment. The model, by jointly denoising image and action latent representations, implicitly learns a richer understanding of the world’s physical interactions. The simultaneous prediction significantly improves efficiency and enhances the overall accuracy because the model can leverage the contextual information from both modalities for better decision making. This integration also facilitates co-training on diverse datasets (robotic demonstrations and large-scale video datasets), enriching the model’s understanding of complex scenarios and enhancing its generalization capabilities to unseen tasks. The ability to incorporate multiple modalities (RGB, depth, etc.) through a flexible architecture further underscores the adaptability and robustness of this approach, potentially leading to more versatile and intelligent robotic systems.
PAD Framework#
The PAD framework, as described in the research paper, presents a novel approach to visual policy learning by unifying image prediction and robot action within a joint denoising process. This joint approach is a key innovation, leveraging the inherent correlation between predicting future images and generating appropriate robot actions. By using Diffusion Transformers, PAD seamlessly integrates various modalities (RGB images, robot poses, depth images, etc.), enabling simultaneous predictions. A significant advantage is PAD’s ability to support co-training on both robotic demonstrations and large-scale video datasets, addressing the limited availability of robotic data. This approach enhances the model’s generalization capabilities and leads to improved performance across various tasks. The flexibility of the DiT backbone allows PAD to seamlessly adapt to different modalities. Overall, the PAD framework is a data-efficient and highly generalizable approach to visual policy learning, demonstrating superior performance compared to existing methods. The unified denoising process is particularly effective in scenarios requiring precise predictions and actions.
Multi-modal Fusion#
Multi-modal fusion in this context likely refers to the method of combining data from various sources such as RGB images, depth sensors, and robot states to create a richer, more comprehensive representation of the environment and task. Effective multi-modal fusion is crucial for robust and generalizable robot learning, enabling robots to handle complex real-world scenarios where information is often incomplete or noisy. The choice of fusion method will significantly impact performance. Simple concatenation might lead to dimensionality issues and difficulties in learning meaningful relationships, whereas more sophisticated techniques, like attention mechanisms, could be much more effective at capturing relevant interactions between different modalities. The success of a multi-modal fusion approach will also heavily depend on proper data preprocessing and feature engineering to ensure consistency and relevance across different input streams. Careful consideration must be given to how well the different modalities complement one another, ideally leading to synergistic improvements. For instance, depth data could provide critical distance information unavailable in RGB images alone. The ability to seamlessly integrate diverse sources is a key challenge in robotic research, promising major advances in autonomy and adaptability.
Generalization#
The concept of generalization in machine learning, specifically within the context of robotic control, is crucial. A model’s ability to generalize to unseen tasks or environments is a key indicator of its robustness and practical applicability. The paper investigates generalization through real-world experiments, evaluating the model’s performance on unseen objects and scenarios. This approach moves beyond simple simulation, offering a more realistic assessment of the model’s capacity to handle unexpected situations. The results indicate superior generalization compared to existing approaches, highlighting the effectiveness of the proposed PAD framework. This enhanced generalization is attributed to the model’s ability to leverage diverse data sources and effectively learn underlying physical dynamics through a joint prediction and action process. However, further research is needed to fully explore the limits of this generalization and its performance under a wider variety of complex, real-world scenarios. The experiments provide a strong initial evaluation but more extensive testing and analysis will be crucial to fully understand the boundaries of generalization in this model.
Future Work#
The ‘Future Work’ section of a research paper on visual policy learning, such as the one described, would naturally explore avenues for improvement and expansion. Extending PAD to incorporate additional modalities beyond RGB images and robot poses (e.g., tactile sensors, force feedback, or point cloud data) would be a significant step, enriching the model’s understanding of the environment. Investigating more efficient methods for handling the computational demands of joint prediction, perhaps through improved model architectures or more efficient training techniques, is crucial for real-time applications. Furthermore, exploring different prediction horizons and action granularities could enhance the adaptability of the approach to diverse robotic tasks. A key area would be analyzing the model’s robustness to noisy or incomplete sensory data, which is inevitable in real-world scenarios. The section might also suggest developing a deeper theoretical understanding of how the joint denoising process facilitates both prediction and action, potentially through a more rigorous mathematical framework. Finally, evaluating the efficacy of PAD across a wider range of robotic manipulation tasks and even expanding to different types of robots could demonstrate its general applicability and broaden its impact.
More visual insights#
More on figures

This figure illustrates the core idea behind the PAD framework. It shows how diffusion models are used in image generation (a) and visual policy learning (b), highlighting the shared underlying physical dynamics. PAD integrates both image prediction and action generation into a unified joint denoising process (c), leveraging the correlation between image prediction and robot actions for improved performance.

This figure visualizes the PAD (Prediction with Action Diffuser) framework. It shows how current observations (RGB image, robot pose, and other modalities) are encoded into a latent space, combined with noise, tokenized, and processed through multiple Diffusion Transformer blocks to jointly denoise and predict both future images and robot actions. The architecture highlights the framework’s ability to handle missing modalities using a masked multi-head attention mechanism.

This figure shows three different experimental setups used to evaluate the proposed PAD (Prediction with Action Diffuser) model. The first shows Bridge video data used for pretraining, demonstrating the model’s ability to learn from large-scale unlabeled video data. The second shows the Metaworld benchmark, which contains 50 robotic manipulation tasks for testing the model’s ability to generalize to diverse tasks and environments. The third shows the real-world robot manipulation setting with a Panda robot arm where the tasks are divided into seen and unseen tasks to evaluate generalization performance on unseen situations and objects. The figure highlights the model’s capability to handle both simulated and real-world scenarios, showcasing its learning potential from diverse data sources and its generalization to unseen tasks.

This figure demonstrates the generalization capabilities of the proposed PAD (Prediction with Action Diffuser) framework on unseen tasks. It shows the results of tests performed at three difficulty levels: easy, medium, and hard. Each level presents a different level of complexity in terms of the number and types of objects to manipulate. The yellow bounding boxes highlight the target objects the robot needs to interact with. The results indicate that PAD outperforms other methods in its ability to generalize to tasks it hasn’t encountered during training.

This figure compares the predicted future images generated by PAD and GR-1, alongside the ground truth future images. The comparison highlights PAD’s superior ability to generate precise future images, suggesting its potential to contribute to improved accuracy in robot control action predictions. The enhanced image precision from PAD is visually evident when zooming in on the images.

This figure shows two examples of PAD’s predictions on the Bridge dataset, a large-scale internet video dataset. Each example shows three image frames: the current observation, the ground truth future, and PAD’s predicted future. The caption highlights that while PAD’s predictions generally align with the instruction given (e.g., ‘Put corn in bowl sink’), there is some uncertainty. In the first example, PAD incorrectly predicts a yellow pear instead of a banana. In the second, PAD predicts the action faster than in the ground truth.
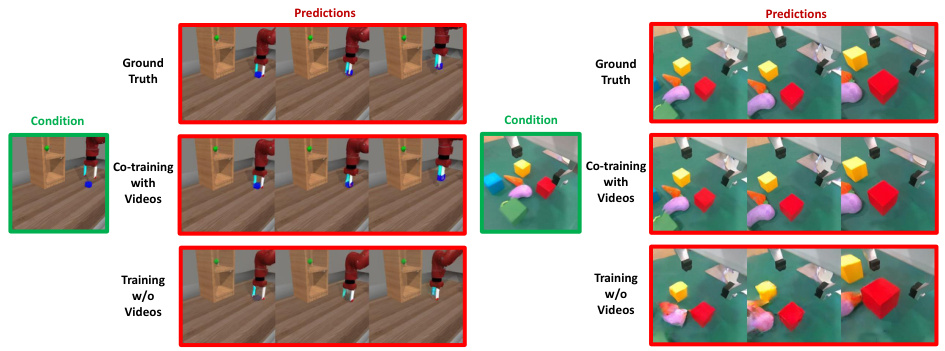
This figure shows a comparison of image predictions from three different training methods: using only robotic data, using robotic data and internet video data, and a ground truth. The left-hand side shows a robotic arm moving blocks, with the right-hand side showing a robotic arm manipulating various objects. In both examples, the co-training method with videos produces better quality image predictions than training only on robotic data, showcasing the benefits of incorporating diverse datasets in visual policy learning.
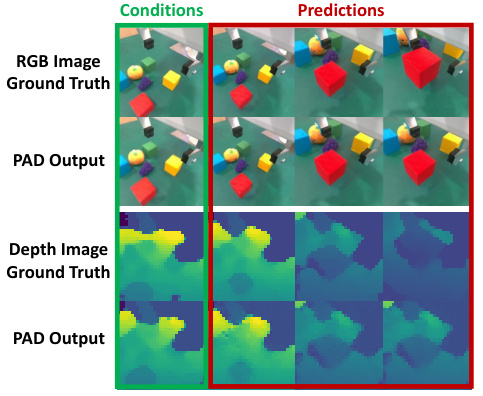
This figure demonstrates PAD’s ability to incorporate additional modalities beyond RGB images and robot poses. Specifically, it shows the results when depth images are included as a condition for prediction. The left side shows the ground truth conditions (RGB and Depth images) and the right side shows the corresponding predictions generated by PAD for future time steps. The figure highlights that PAD can effectively integrate multiple input modalities to accurately predict both future RGB images and depth maps, indicating a robust and versatile approach to visual policy learning.

This figure shows the correlation between the computational cost (measured in Transformer GFLOPS) and the success rate of the learned policy in the Metaworld benchmark. It visually demonstrates that higher computational resources generally lead to better performance.

This figure shows the experimental setup of the PAD model. The left side shows the bridge video data used for pre-training. The middle shows the simulated MetaWorld environment with 50 tasks. The right side shows the real-world robot manipulation experiment with both seen and unseen tasks. The figure illustrates the PAD model’s ability to learn a single policy that can generalize to unseen tasks in both simulated and real-world environments.

This figure shows the results of a generalization test conducted to evaluate the ability of the PAD model to handle unseen tasks. The test was performed across three difficulty levels, each presenting increasing challenges (easy, medium, hard). The yellow bounding boxes indicate the target positions for the robot manipulation tasks. The success rate of PAD is compared to several baseline methods across these difficulty levels, demonstrating PAD’s superior performance in generalizing to novel, unseen tasks.
More on tables
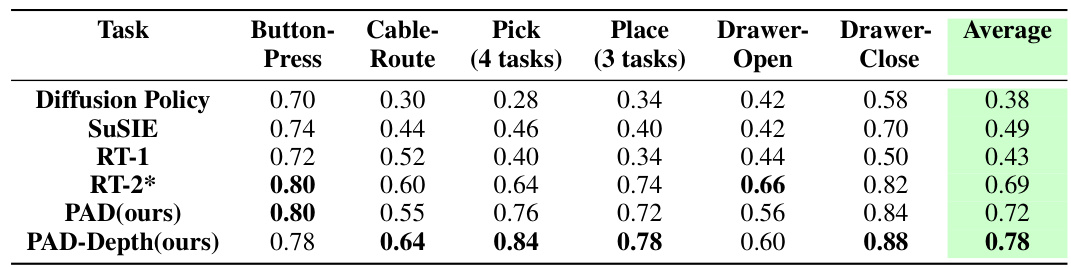
This table presents the success rates of different robotic manipulation methods on real-world in-distribution tasks. It compares PAD’s performance with several baselines (Diffusion Policy, SuSIE, RT-1, RT-2*), showing PAD’s superior performance across multiple tasks. It also demonstrates the beneficial effect of incorporating depth information into PAD (PAD-Depth). Each result is an average of 50 trials per task.

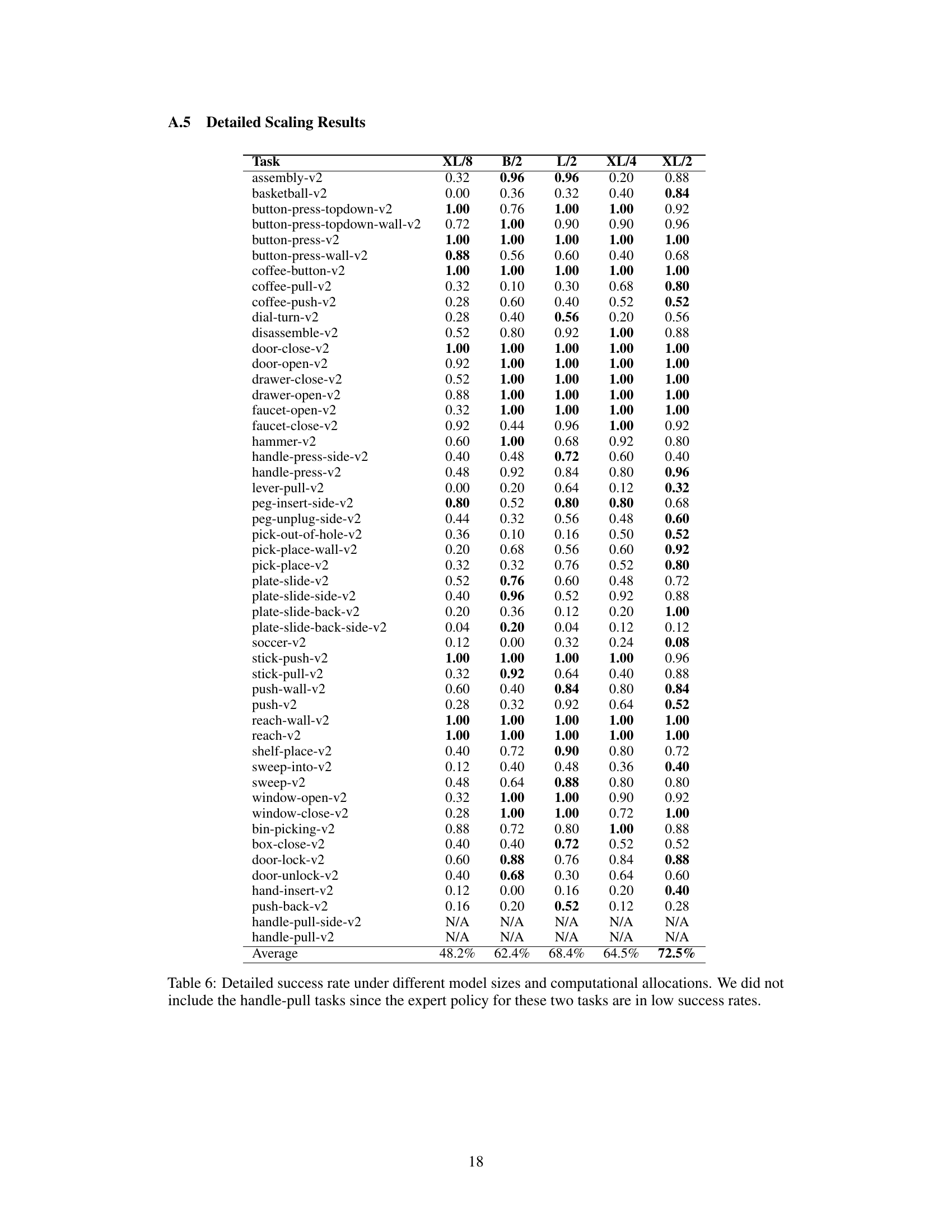
This table presents the performance of the PAD model with different sizes and computational costs. It shows the effect of varying model parameters (layers, hidden size, heads, token length) and computational resources (parameters and GFlops) on the average success rate (SR) across various tasks. The results indicate a strong correlation between computational resources and performance.
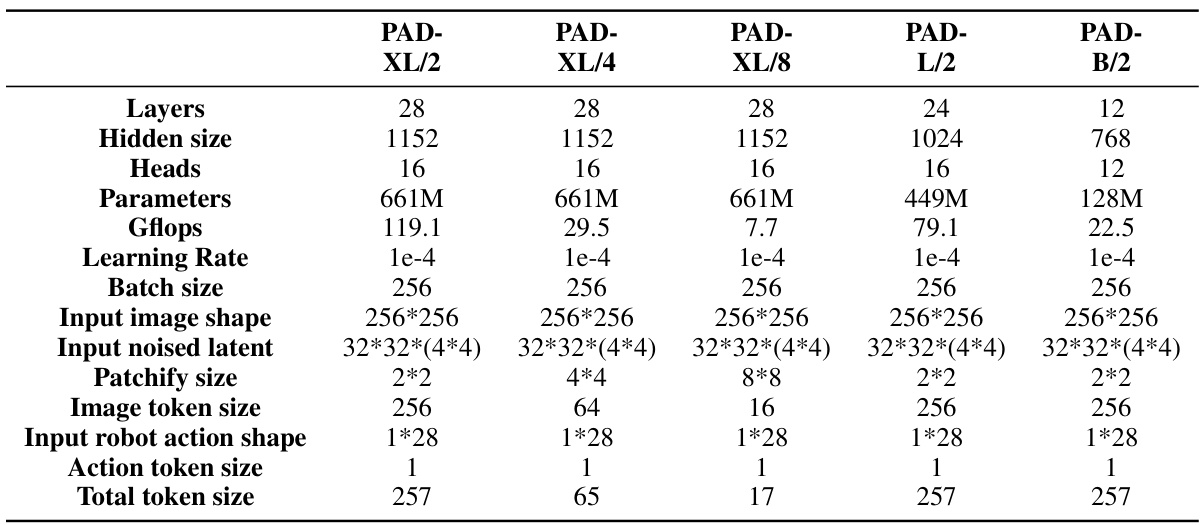
This table presents the results of experiments evaluating the performance of the PAD model with different model sizes and computational costs. It shows that varying the model’s size and architecture significantly impacts performance, as measured by success rate. The table details the specific configurations used, including the number of layers, hidden size, number of heads, number of parameters, Gflops, learning rate, batch size, input image shape, input noised latent, patchify size, image token size, input robot action shape, action token size, and total token size, for each model variation.

This table compares the performance of PAD against several baselines on the Metaworld benchmark. It shows success rates for various tasks, highlighting PAD’s superior performance and the impact of removing certain components (image prediction and co-training) on the model. The table focuses on multi-task learning with a single visual-language conditioned policy.

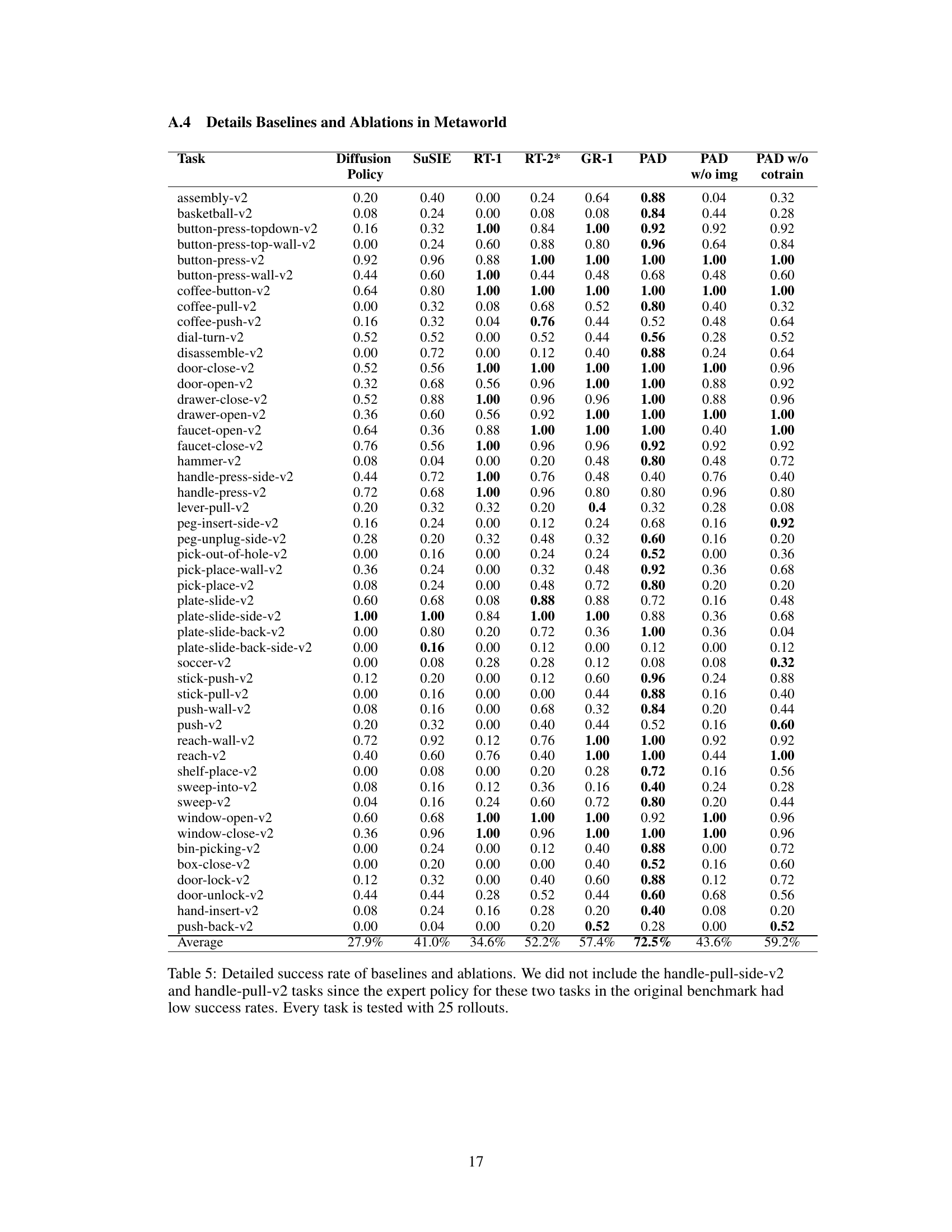
This table presents a detailed breakdown of the success rates achieved by different methods (PAD, diffusion policy, SuSIE, RT-1, RT-2*, GR-1) across various tasks within the Metaworld benchmark. It highlights PAD’s superior performance and shows the impact of ablations (removing image prediction, removing video co-training) on PAD’s results. Each task’s success rate is based on 25 trials.

This table presents the multi-task performance comparison of PAD against several state-of-the-art baselines on the Metaworld benchmark. It shows success rates for a subset of the 50 tasks in Metaworld, and the average success rate across all 50 tasks. It highlights PAD’s superior performance using a single, text-conditioned visual policy, compared to baselines that often employ separate policies for each task or a two-stage approach.. Additional results for all 50 tasks are available in the appendix.
Full paper#