TL;DR#
Non-autoregressive Transformers (NATs) offer faster speech-to-speech translation but often produce incoherent results due to complex speech data distributions. This paper addresses this problem by focusing on direct speech-to-speech translation without intermediate text. Current methods struggle with the inherent multi-modality in speech data, leading to low-quality translations.
The paper proposes DIFFNORM, which uses a diffusion model for self-supervised speech normalization, simplifying the data distribution for training NATs. Additionally, it incorporates classifier-free guidance to regularize the model, enhancing its robustness and generalizability. Experiments show significant improvements (+7 ASR-BLEU for English-Spanish and +2 ASR-BLEU for English-French) compared to previous systems, along with substantial speedups (14x for En-Es and 5x for En-Fr).
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenge of incoherent and repetitive outputs in non-autoregressive speech-to-speech translation (S2ST), a critical issue limiting the widespread adoption of faster, non-autoregressive models. By introducing DIFFNORM, a novel diffusion-based normalization strategy, and classifier-free guidance, the research significantly improves translation quality and offers a new avenue for enhancing the robustness of NAT models. These findings are relevant to researchers working on S2ST, non-autoregressive models, and speech normalization techniques.
Visual Insights#
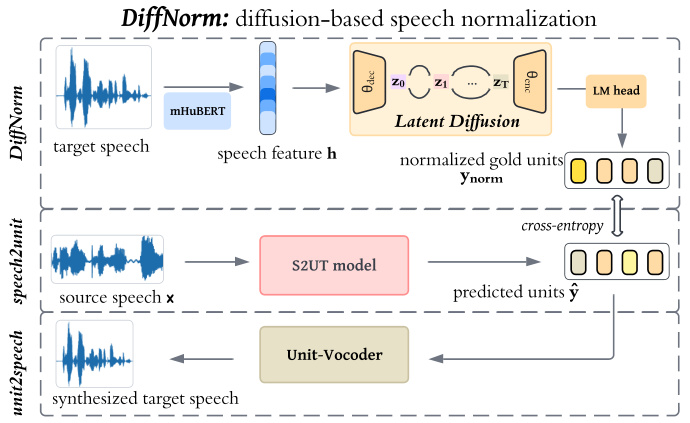
🔼 This figure illustrates the architecture of the proposed speech-to-speech translation system. It shows how the target speech is first normalized using a diffusion model, then processed by a speech-to-unit (S2UT) translation model, and finally converted to synthesized speech via a unit vocoder. The system uses a multi-stage pipeline to improve translation quality by simplifying the target data distribution and incorporating a regularization strategy to improve model robustness.
read the caption
Figure 1: Overview of our proposed system. We first normalize the target speech units with the denoising process from the latent diffusion model. Then speech-to-unit (S2UT) model is trained to predict normalized units, which are converted into waveform from an off-the-shelf unit-vocoder.

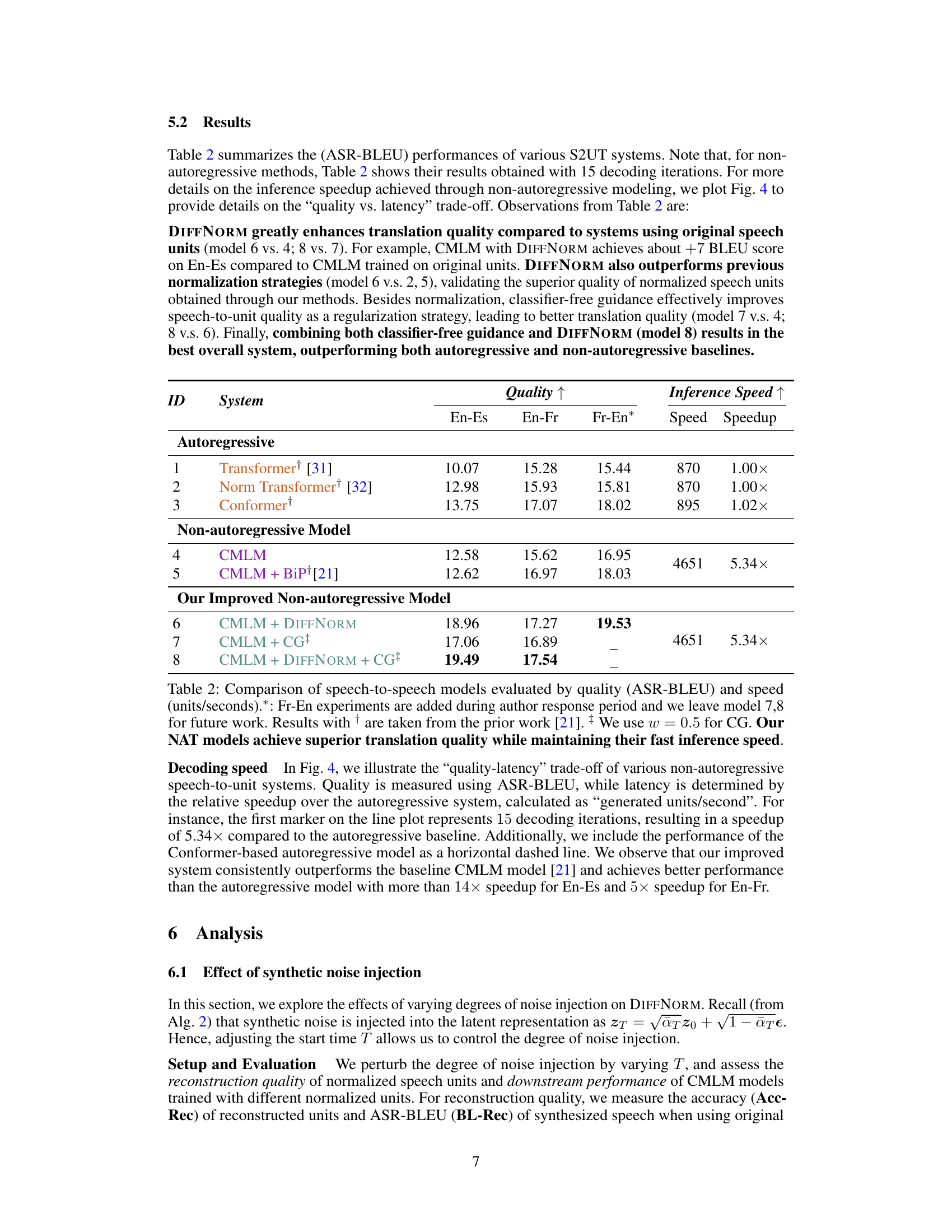
🔼 This table compares different speech-to-speech translation models in terms of their translation quality (measured by ASR-BLEU score) and inference speed (units per second). It shows a comparison between autoregressive and non-autoregressive models, highlighting the improved performance and speed achieved by the proposed models (CMLM + DIFFNORM and CMLM + DIFFNORM + CG). The table also shows the speedup achieved by the non-autoregressive models compared to the autoregressive baseline.
read the caption
Table 2: Comparison of speech-to-speech models evaluated by quality (ASR-BLEU) and speed (units/seconds). *: Fr-En experiments are added during author response period and we leave model 7,8 for future work. + We use w = 0.5 for CG. Our NAT models achieve superior translation quality while maintaining their fast inference speed.
In-depth insights#
DiffuNorm’s Power#
DiffuNorm demonstrates significant power in addressing the multi-modality challenge inherent in non-autoregressive speech-to-speech translation. By employing a diffusion-based denoising approach, it effectively simplifies complex speech data distributions, leading to more coherent and less repetitive model outputs. This self-supervised normalization strategy avoids reliance on transcription data or manually designed perturbation functions, enhancing training efficiency and reducing data dependency. Coupled with classifier-free guidance, DiffuNorm boosts model robustness and achieves notable improvements in translation quality, as measured by ASR-BLEU scores, exceeding autoregressive baselines while maintaining a substantial speed advantage. The method’s effectiveness is further highlighted by its adaptability and ability to improve performance across multiple language pairs. Overall, DiffuNorm represents a powerful technique to improve the accuracy and efficiency of non-autoregressive speech-to-speech translation systems.
NAT Regularization#
Non-autoregressive Transformers (NATs) present a promising approach to speech-to-speech translation, offering speed advantages over autoregressive models. However, they often suffer from issues like incoherence and repetitiveness in their output. NAT regularization techniques aim to mitigate these problems by enhancing model robustness and generalization ability. This might involve methods such as classifier-free guidance, which encourages the model to generate coherent outputs even without direct conditioning on the source data, thereby improving the quality of translations. Other methods might focus on data normalization to simplify the complex acoustic and linguistic variations inherent in speech data. Successfully regularizing NATs is key to unlocking their full potential in efficient and high-quality speech-to-speech translation. The choice of regularization technique depends on many factors and the research continues to explore innovative solutions in this space.
Speed vs. Quality#
The inherent trade-off between speed and quality in non-autoregressive speech-to-speech translation is a central theme. Faster non-autoregressive models, while efficient, often sacrifice translation accuracy. The paper investigates strategies to improve quality without significantly impacting speed. DIFFNORM, a diffusion-based normalization technique, and classifier-free guidance are key approaches used to enhance the quality of non-autoregressive translations. The results show a substantial improvement in ASR-BLEU scores, suggesting a meaningful enhancement in translation accuracy. However, the improvement is not without cost: the self-supervised nature of DIFFNORM necessitates preprocessing steps, potentially impacting latency. The overall effect is a promising balance of higher quality translations with a significant speedup compared to autoregressive baselines, though the tradeoff remains a consideration for different application scenarios. A clear quantitative evaluation is provided through detailed experiments and figures, showcasing the achievable speed improvements alongside the quality gains, allowing for a nuanced understanding of the balance.
Dataset Dependence#
Dataset dependence is a crucial consideration in evaluating the generalizability and robustness of machine learning models. A model showing excellent performance on a specific dataset might fail dramatically when applied to a different one, even if the datasets appear similar. This is because model performance is heavily influenced by the statistical properties and biases inherent in the training data. A thorough analysis should explore the characteristics of the dataset used, including its size, diversity, and potential biases. Furthermore, evaluating the model’s performance on multiple, diverse datasets is essential to assess its true capability and potential limitations. Over-reliance on a single dataset may lead to misleading conclusions about model effectiveness. Careful selection and evaluation on multiple representative datasets are critical for building reliable and robust machine learning systems.
Future S2ST#
Future speech-to-speech translation (S2ST) research should prioritize robustness and generalization across diverse acoustic conditions and languages. This includes developing methods that are less sensitive to noise and speaker variations. Improving the coherence and fluency of non-autoregressive models, which offer faster inference, remains crucial. Investigating new speech representations and normalization techniques that better capture linguistic and acoustic information could significantly improve translation quality. Furthermore, exploring multimodal approaches that incorporate visual or textual cues could enhance contextual understanding and improve the overall translation experience. Finally, research into low-resource S2ST and developing methods that leverage limited data more effectively is essential for broader accessibility.
More visual insights#
More on figures

🔼 This figure illustrates the process of speech normalization using a latent diffusion model. The process begins with encoding speech features (h) into a latent representation (z0). Noise is then injected into this representation (zT). The core of the model is the denoising process, which iteratively removes the injected noise through multiple steps, ultimately recovering a denoised latent representation (z0). This denoised representation is then decoded back into speech features (ĥ), which are finally processed by a language modeling head to produce normalized speech units (ynorm).
read the caption
Figure 2: Visualization of our latent diffusion model's denoising process for speech normalization. The clean latent z0 is synthetically noised (into zT) and the reverse diffusion process gradually denoise it to generate normalized speech units.

🔼 This figure illustrates the architecture of the Conditional Masked Language Model (CMLM) used for speech-to-unit translation. The model takes source speech as input, encodes it using a Conformer subsampler and encoder, and then uses a decoder with classifier-free guidance to predict normalized target speech units (ynorm). The classifier-free guidance involves randomly replacing the encoded source speech with a ’null’ representation, forcing the model to generate coherent units without direct conditioning on the source. The predicted units are then fed into a separate diffusion model (DIFFNORM) to further refine them and generate the final normalized speech units.
read the caption
Figure 3: Visualization of CMLM for speech-to-unit translation where the model is trained with the unmasking objective to recover ynorm. When classifier-free guidance is used, with probability pdrop, we replace the encoded source speech g by a 'null' representation g∅.
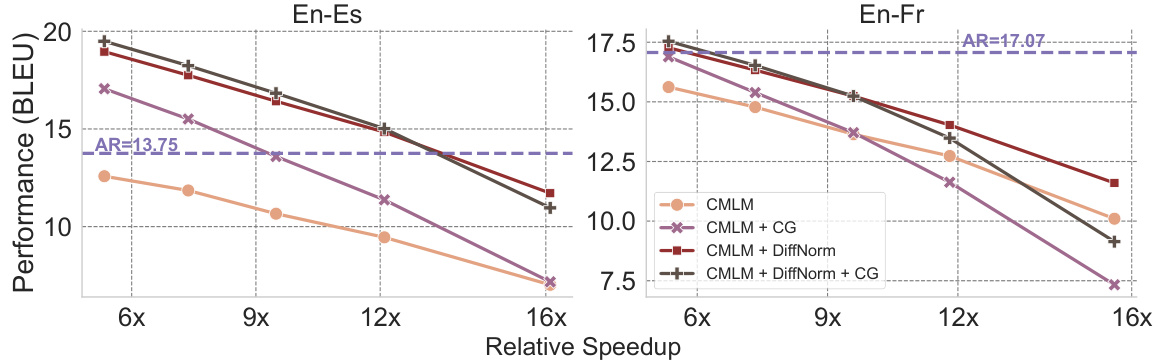
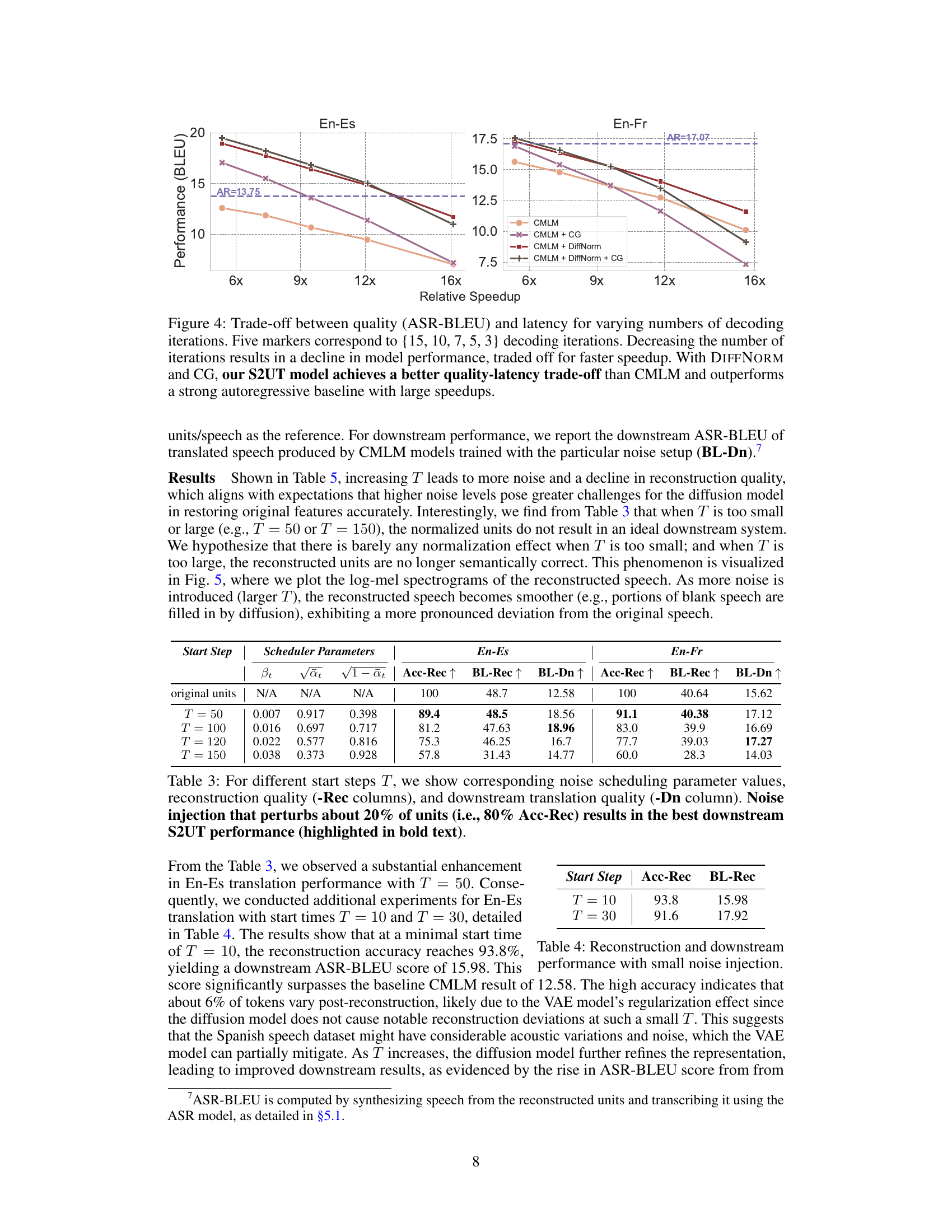
🔼 This figure shows the trade-off between the translation quality (measured by ASR-BLEU) and the inference speed (relative speedup compared to the autoregressive baseline) for different numbers of decoding iterations in the non-autoregressive speech-to-unit translation models. It compares the performance of four models: CMLM (baseline), CMLM+CG (with classifier-free guidance), CMLM+DIFFNORM (with diffusion-based normalization), and CMLM+DIFFNORM+CG (combining both techniques). As the number of iterations decreases, the speed increases, but the translation quality also decreases. The combined DIFFNORM and CG model demonstrates a better balance between speed and accuracy compared to the other models and even surpasses the autoregressive baseline at high speedups.
read the caption
Figure 4: Trade-off between quality (ASR-BLEU) and latency for varying numbers of decoding iterations. Five markers correspond to {15, 10, 7, 5, 3} decoding iterations. Decreasing the number of iterations results in a decline in model performance, traded off for faster speedup. With DIFFNORM and CG, our S2UT model achieves a better quality-latency trade-off than CMLM and outperforms a strong autoregressive baseline with large speedups.
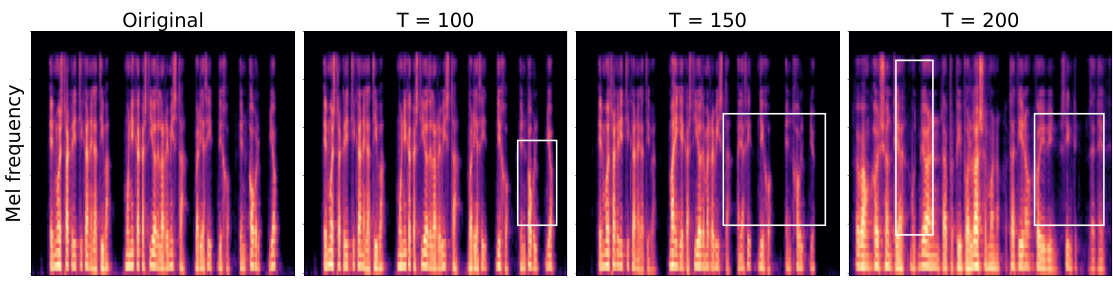
🔼 This figure visualizes the log-mel spectrograms of reconstructed speech for various noise injection levels (different start times T in the diffusion model). The original spectrogram is compared to spectrograms with increasing noise. White boxes highlight regions where significant differences between the original and reconstructed spectrograms are apparent. This demonstrates how the amount of noise injected affects the quality of the reconstructed speech.
read the caption
Figure 5: Visualization of reconstructed speech's log-mel spectrograms. Noticeable divergence from the original speech is highlighted in the white bounding boxes.
More on tables

🔼 The table shows the data statistics for the Cross-Lingual Speech-to-Speech Translation (CVSS) benchmark used in the paper’s experiments. It presents the number of samples and average length of target speech (in units) for both English-Spanish (En-Es) and English-French (En-Fr) language pairs, broken down by training, validation, and test sets. This data informs the scale and characteristics of the datasets used to train and evaluate the proposed models.
read the caption
Table 1: Data statistics for CVSS benchmarks.
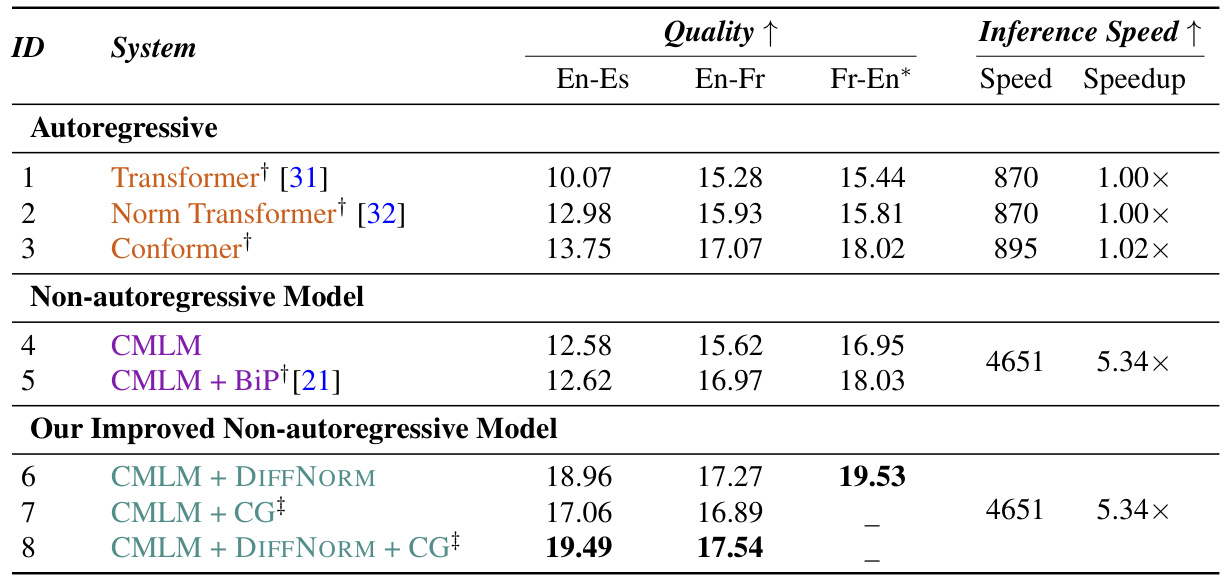
🔼 This table compares various speech-to-speech translation models, both autoregressive and non-autoregressive, based on their performance metrics (ASR-BLEU score, which measures the quality of the translation) and inference speed (measured as units per second, reflecting how quickly they produce results). It showcases the improvement achieved by incorporating DIFFNORM and classifier-free guidance in the non-autoregressive models, especially model 8, which significantly outperforms both autoregressive and baseline non-autoregressive models.
read the caption
Table 2: Comparison of speech-to-speech models evaluated by quality (ASR-BLEU) and speed (units/seconds). *: Fr-En experiments are added during author response period and we leave model 7,8 for future work. + We use w = 0.5 for CG. Our NAT models achieve superior translation quality while maintaining their fast inference speed.
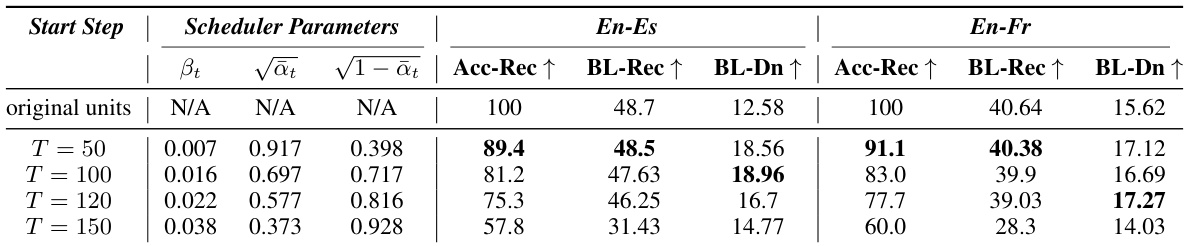
🔼 This table shows the impact of varying the start step (T) in the DIFFNORM process on reconstruction quality and downstream S2UT performance. Different values of T correspond to different levels of noise injection during the diffusion process. The table presents the scheduling parameters (βt, √αt, √1−αt) for each T, along with metrics for reconstruction quality (Acc-Rec, BL-Rec) and downstream translation quality (BL-Dn). The best downstream performance is observed when the noise injection perturbs approximately 20% of the units.
read the caption
Table 3: For different start steps T, we show corresponding noise scheduling parameter values, reconstruction quality (-Rec columns), and downstream translation quality (-Dn column). Noise injection that perturbs about 20% of units (i.e., 80% Acc-Rec) results in the best downstream S2UT performance (highlighted in bold text).

🔼 This table shows the reconstruction accuracy (Acc-Rec) and downstream ASR-BLEU score (BL-Rec) for different start times (T) in the diffusion model during speech normalization. A smaller start time implies less noise injection. The results demonstrate the impact of noise level on the quality of reconstructed speech units and their subsequent performance in a downstream speech-to-text translation task.
read the caption
Table 4: Reconstruction and downstream performance with small noise injection.
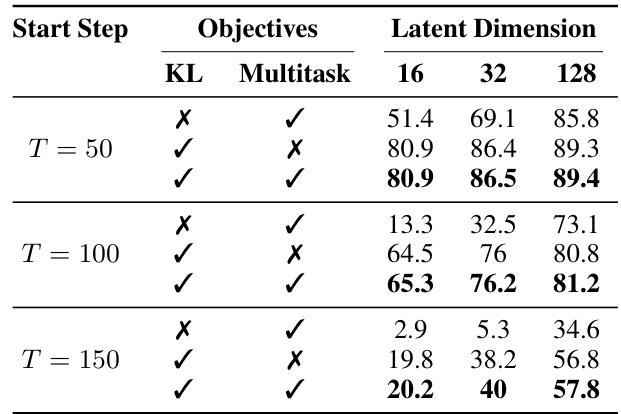
🔼 This table presents the results of ablation experiments on the training objectives for the DIFFNORM model. It shows the impact of using different latent dimensions (16, 32, and 128), the inclusion or exclusion of KL divergence regularization, and the use of a multitask objective (combining noise estimation, reconstruction loss, and negative log-likelihood loss) versus only a noise estimation objective, on the reconstruction accuracy of speech units at different noise levels (start steps).
read the caption
Table 5: Accuray of reconstructed speech units. KL: when applied, the latent space is regularized to be Gaussian [27]. Multitask: when not applied, the latent diffusion model is trained only with Lnoise.
🔼 This table compares various speech-to-speech translation models, including autoregressive and non-autoregressive models, based on their ASR-BLEU scores and inference speed (units per second). It highlights the improvements achieved by the proposed DIFFNORM and classifier-free guidance methods in terms of both translation quality and inference speed. The asterisk indicates that Fr-En results were added later, and the plus sign indicates the specific hyperparameter setting used for classifier-free guidance.
read the caption
Table 2: Comparison of speech-to-speech models evaluated by quality (ASR-BLEU) and speed (units/seconds). *: Fr-En experiments are added during author response period and we leave model 7,8 for future work. + We use w = 0.5 for CG. Our NAT models achieve superior translation quality while maintaining their fast inference speed.

🔼 This table compares the performance of various speech-to-speech translation models, both autoregressive and non-autoregressive. It shows the ASR-BLEU scores (a measure of translation quality) and the decoding speed (units per second) for each model. The table highlights the significant improvements achieved by the proposed methods (DIFFNORM and Classifier-free guidance) in terms of both translation quality and speed.
read the caption
Table 2: Comparison of speech-to-speech models evaluated by quality (ASR-BLEU) and speed (units/seconds). *: Fr-En experiments are added during author response period and we leave model 7,8 for future work. + We use w = 0.5 for CG. Our NAT models achieve superior translation quality while maintaining their fast inference speed.

🔼 This table compares different speech-to-speech translation models, evaluating both their quality (measured by ASR-BLEU score) and inference speed (measured in units per second). It includes autoregressive and non-autoregressive models, with and without the proposed DIFFNORM and classifier-free guidance techniques. The table highlights the significant quality improvements and speedups achieved by the proposed models compared to baselines.
read the caption
Table 2: Comparison of speech-to-speech models evaluated by quality (ASR-BLEU) and speed (units/seconds). *: Fr-En experiments are added during author response period and we leave model 7,8 for future work. + We use w = 0.5 for CG. Our NAT models achieve superior translation quality while maintaining their fast inference speed.

🔼 This table compares the performance of various speech-to-speech translation models, broken down by whether they are autoregressive or non-autoregressive. It shows the ASR-BLEU scores (a measure of translation quality) and the speed in units per second. The table highlights that the non-autoregressive models using the proposed DIFFNORM and classifier-free guidance techniques achieve superior translation quality with significantly faster inference speeds compared to autoregressive baselines.
read the caption
Table 2: Comparison of speech-to-speech models evaluated by quality (ASR-BLEU) and speed (units/seconds). *: Fr-En experiments are added during author response period and we leave model 7,8 for future work. + We use w = 0.5 for CG. Our NAT models achieve superior translation quality while maintaining their fast inference speed.
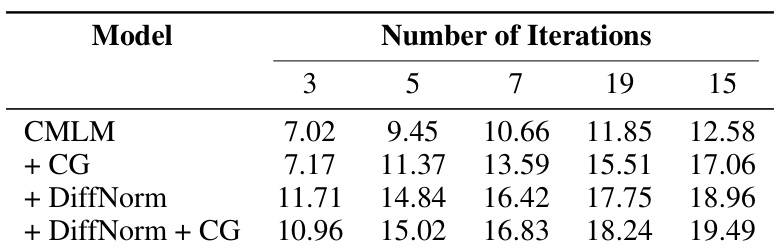
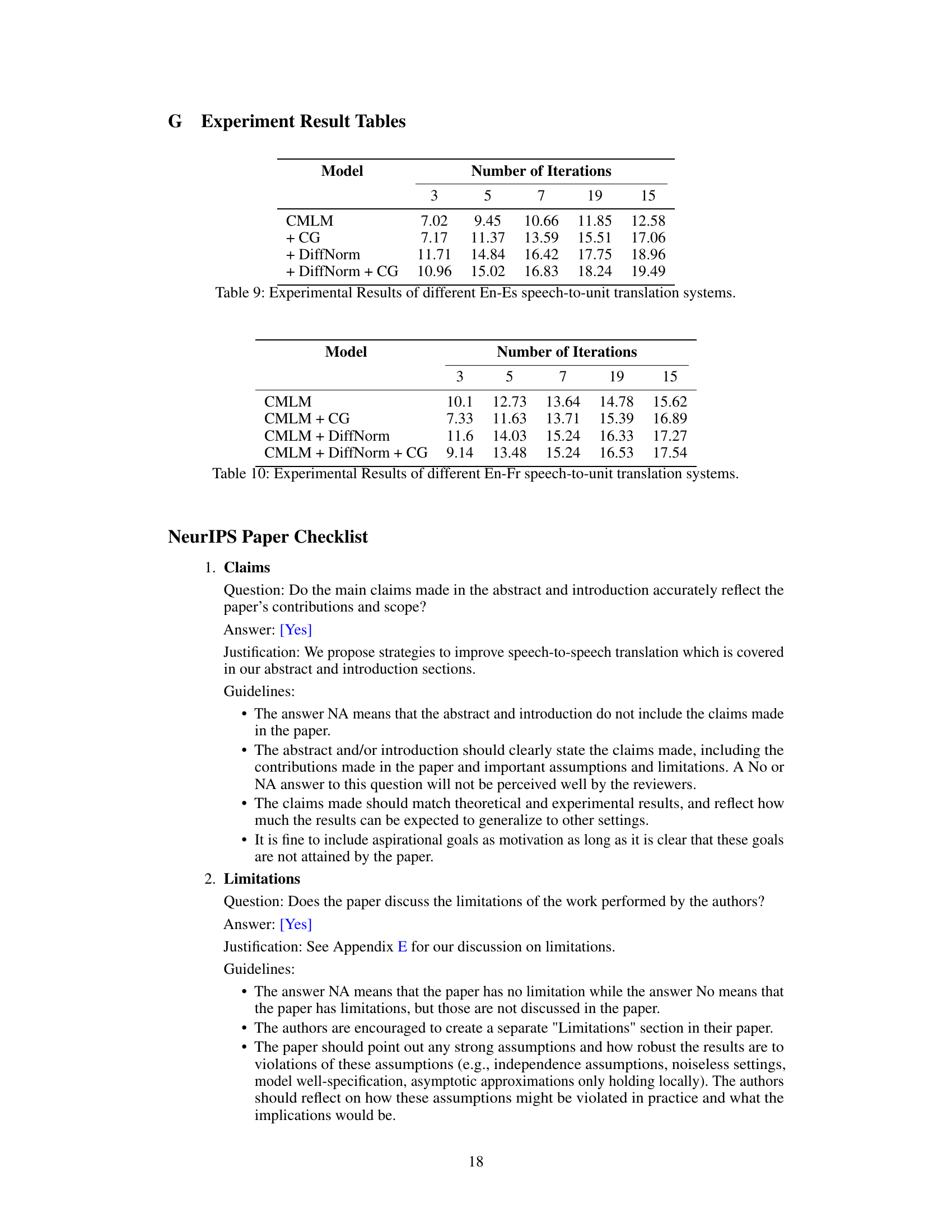
🔼 This table presents the ASR-BLEU scores achieved by four different speech-to-unit translation models on the English-to-Spanish (En-Es) dataset of the CVSS benchmark. The models tested include a baseline CMLM model and variations incorporating classifier-free guidance (CG) and DIFFNORM normalization. The results are shown for different numbers of decoding iterations (3, 5, 7, 19, and 15), highlighting the performance improvements with the addition of DIFFNORM and CG.
read the caption
Table 9: Experimental Results of different En-Es speech-to-unit translation systems.

🔼 This table presents the experimental results comparing four different speech-to-unit translation models on English-French (En-Fr) data. The models are: CMLM (Conditional Masked Language Model), CMLM + CG (CMLM with Classifier-Free Guidance), CMLM + DiffNorm (CMLM with the DIFFNORM normalization strategy), and CMLM + DiffNorm + CG (CMLM with both DIFFNORM and Classifier-Free Guidance). The results are shown for different numbers of decoding iterations (3, 5, 7, 19, and 15) and measured as ASR-BLEU scores. The table helps evaluate the impact of each method (DIFFNORM and CG) on the translation quality and the effect of the number of decoding iterations on performance.
read the caption
Table 10: Experimental Results of different En-Fr speech-to-unit translation systems.
Full paper#