↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Vision-Language Models (LVLMs) often struggle with In-Context Learning (ICL), where their performance is highly sensitive to the configuration of in-context demonstrations. Existing methods for optimizing these demonstrations are often inefficient and suboptimal, especially in vision-language tasks. This necessitates the need for more effective approaches to configure in-context demonstrations for enhanced ICL performance in LVLMs.
This paper introduces Lever-LM, a small language model trained to generate effective in-context demonstration sequences for LVLMs. Lever-LM learns the statistical patterns in successful demonstrations and uses these patterns to generate novel sequences for new queries. Experiments show that Lever-LM significantly improves the ICL performance of two LVLMs compared to existing methods in both visual question answering and image captioning. This demonstrates Lever-LM’s ability to capture and leverage statistical patterns for improving the effectiveness of ICL in LVLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to improve the performance of large vision-language models (LVLMs) using a small language model. This is highly relevant to current research trends in efficient and effective ICL and opens new avenues for research in leveraging smaller models to enhance larger ones. The findings could significantly impact future LVLMs’ development, leading to more efficient and effective AI systems.
Visual Insights#
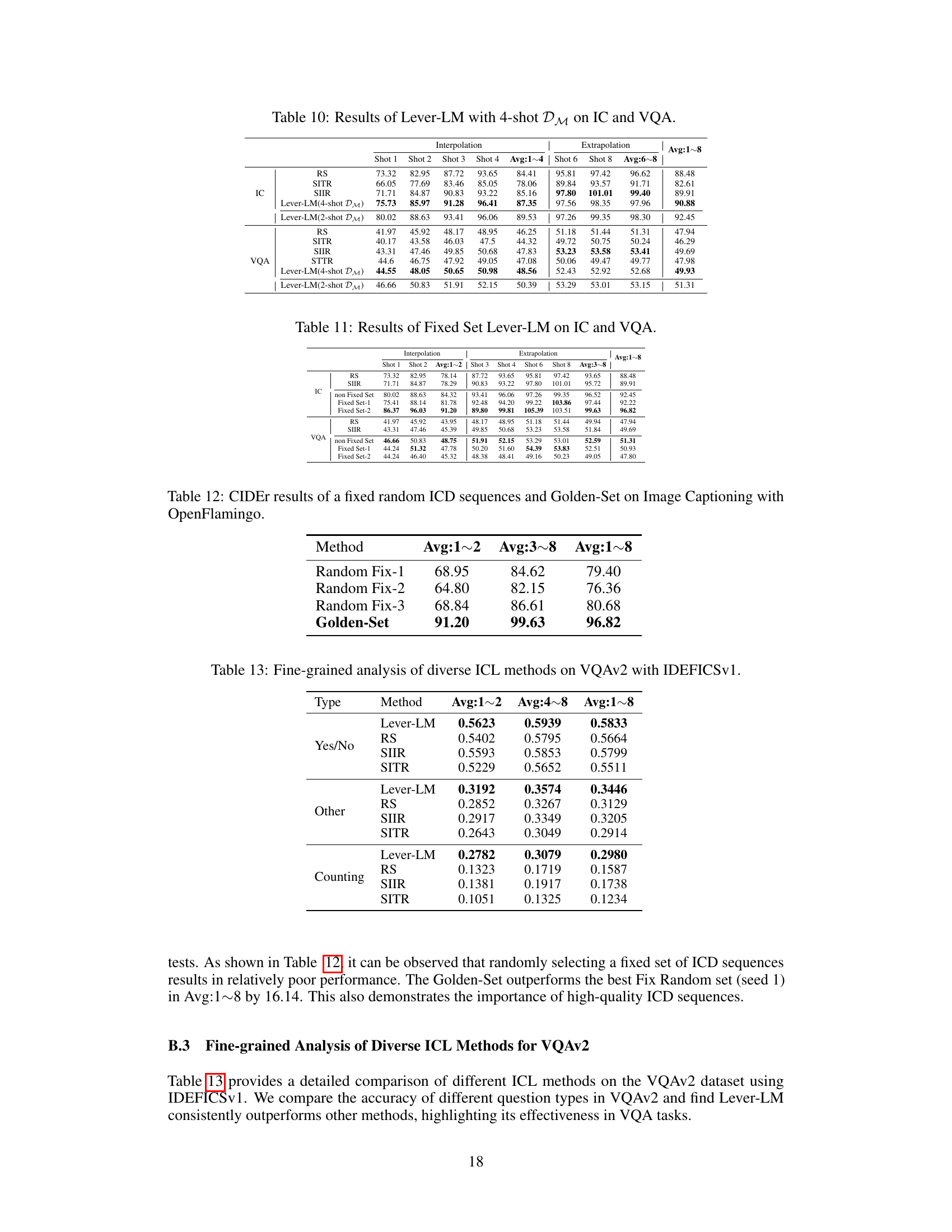
This figure compares the traditional two-step approach for configuring in-context demonstrations (ICDs) with the proposed Lever-LM approach. The traditional method involves separate selection and re-ordering of ICDs, often leading to suboptimal results. In contrast, Lever-LM generates ICD sequences step-by-step, considering both selection and ordering simultaneously, leading to improved performance.
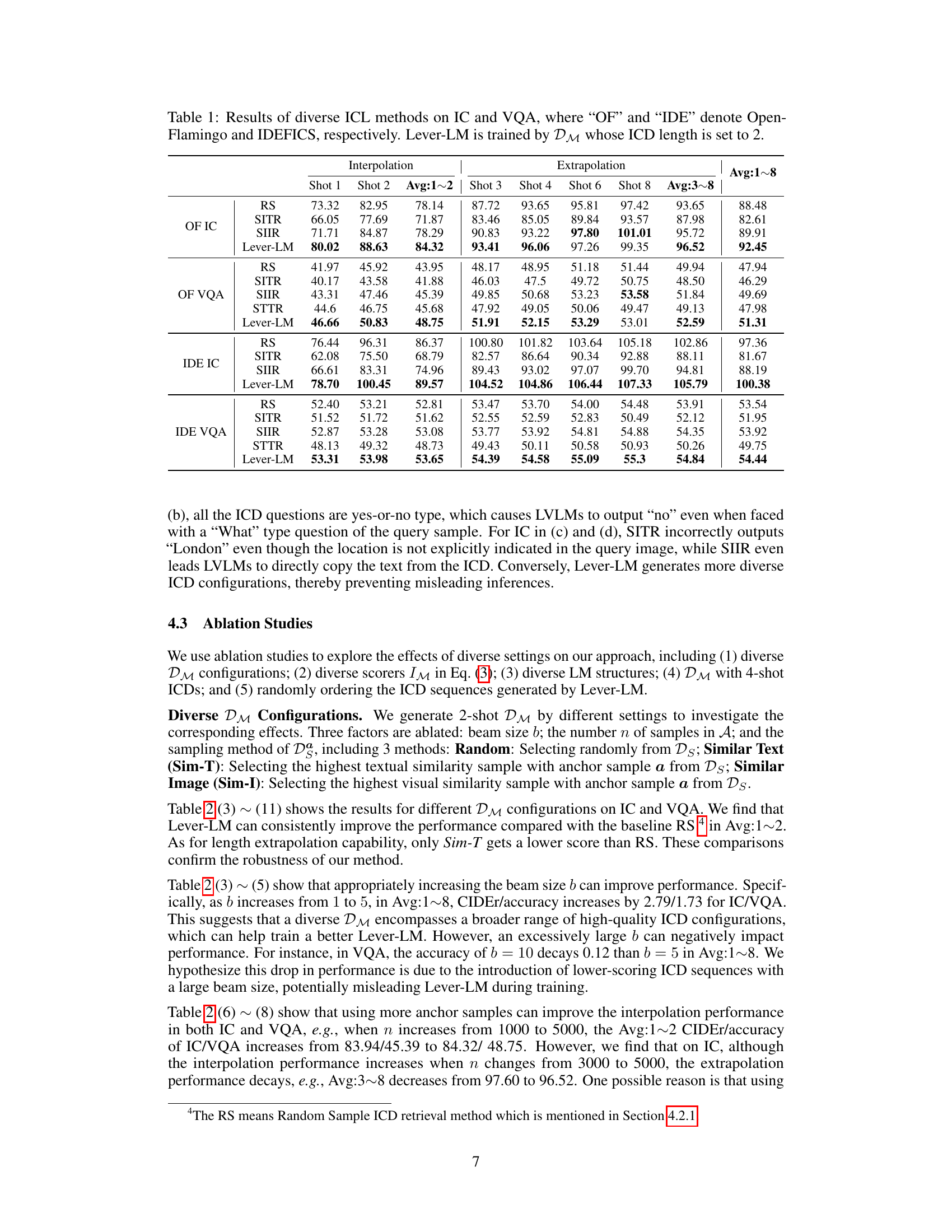
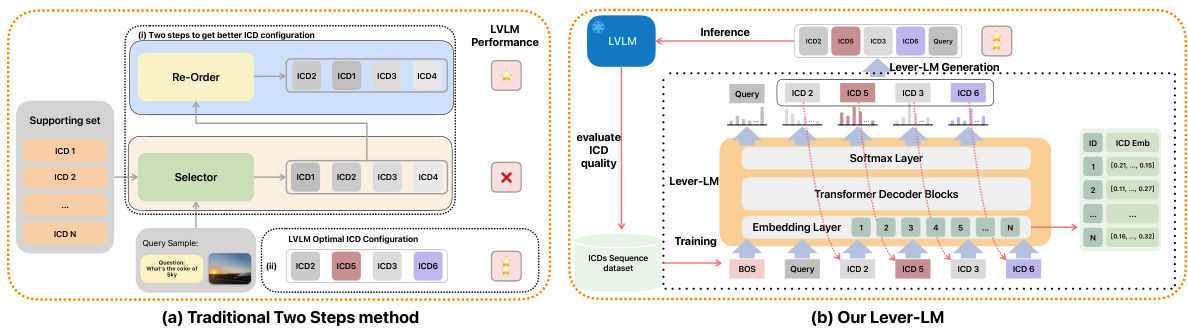
This table presents a comparison of different in-context learning (ICL) methods for image captioning (IC) and visual question answering (VQA) tasks. It compares the performance of Random Sample (RS), Similarity-based Retrieval methods (SITR, SIIR, STTR), and the proposed Lever-LM approach. The results are shown for different shot numbers (1-shot to 8-shot) and are broken down into interpolation (shorter shot numbers than training data) and extrapolation (longer shot numbers than training data). The comparison highlights Lever-LM’s superior performance across various scenarios and model types (OpenFlamingo and IDEFICS).
In-depth insights#
Lever-LM Intro#
A hypothetical ‘Lever-LM Intro’ section would likely introduce the core concept of Lever-LM, a lightweight language model designed to enhance larger Vision-Language Models (LVLMs). It would highlight the inefficiency of traditional methods for configuring in-context demonstrations (ICDs) in LVLMs, which often involve separate selection and ordering steps. The introduction would then position Lever-LM as a novel solution, framing it as a tool to efficiently generate effective ICD sequences by learning statistical patterns from a dataset of successful ICDs. This approach leverages the power of smaller LMs to optimize the performance of significantly larger models, emphasizing efficiency and improved in-context learning. The introduction would likely also briefly mention the experimental validation planned, foreshadowing the results showing enhanced performance on Visual Question Answering and Image Captioning tasks compared to existing baselines.
ICD Seq Gen#
The heading ‘ICD Seq Gen,’ likely referring to In-Context Demonstration Sequence Generation, points to a crucial aspect of leveraging large vision-language models (LVLMs). The core idea revolves around automatically creating effective sequences of demonstration examples (ICDs) for improved in-context learning (ICL). This contrasts with traditional methods that manually select and order ICDs, which are often suboptimal. Leveraging a smaller language model (Lever-LM) to predict these sequences offers an automated and efficient alternative. The effectiveness of this approach rests on the Lever-LM’s ability to learn the statistical patterns underlying successful ICD configurations. This implicitly suggests that the order and choice of examples matter significantly in guiding the LVLMs’ learning, and that these patterns are learnable via machine learning. Successfully automating this process is key to unlocking the full potential of LVLMs, making them more practical for various real-world vision and language tasks.
Leveraging VLMs#
Leveraging Vision-Language Models (VLMs) presents a significant opportunity to advance AI, particularly in tasks requiring understanding of both visual and textual data. Effective VLM utilization hinges on several key factors, including the architecture of the model itself, the quality and diversity of training data, and the methods used for prompt engineering and in-context learning. Careful consideration of data biases within training datasets is crucial to mitigate potential issues of unfairness or inaccuracy in the model’s output. Research efforts are increasingly focused on developing techniques to enhance VLM performance, such as prompt optimization strategies, better methods for few-shot learning, and the exploration of more efficient architectures. The potential applications of VLMs are vast, spanning image captioning, visual question answering, and more complex tasks that demand a deep understanding of the visual world. Future research will likely focus on improving the robustness, efficiency, and explainability of VLMs, while also addressing ethical considerations that arise from their use.
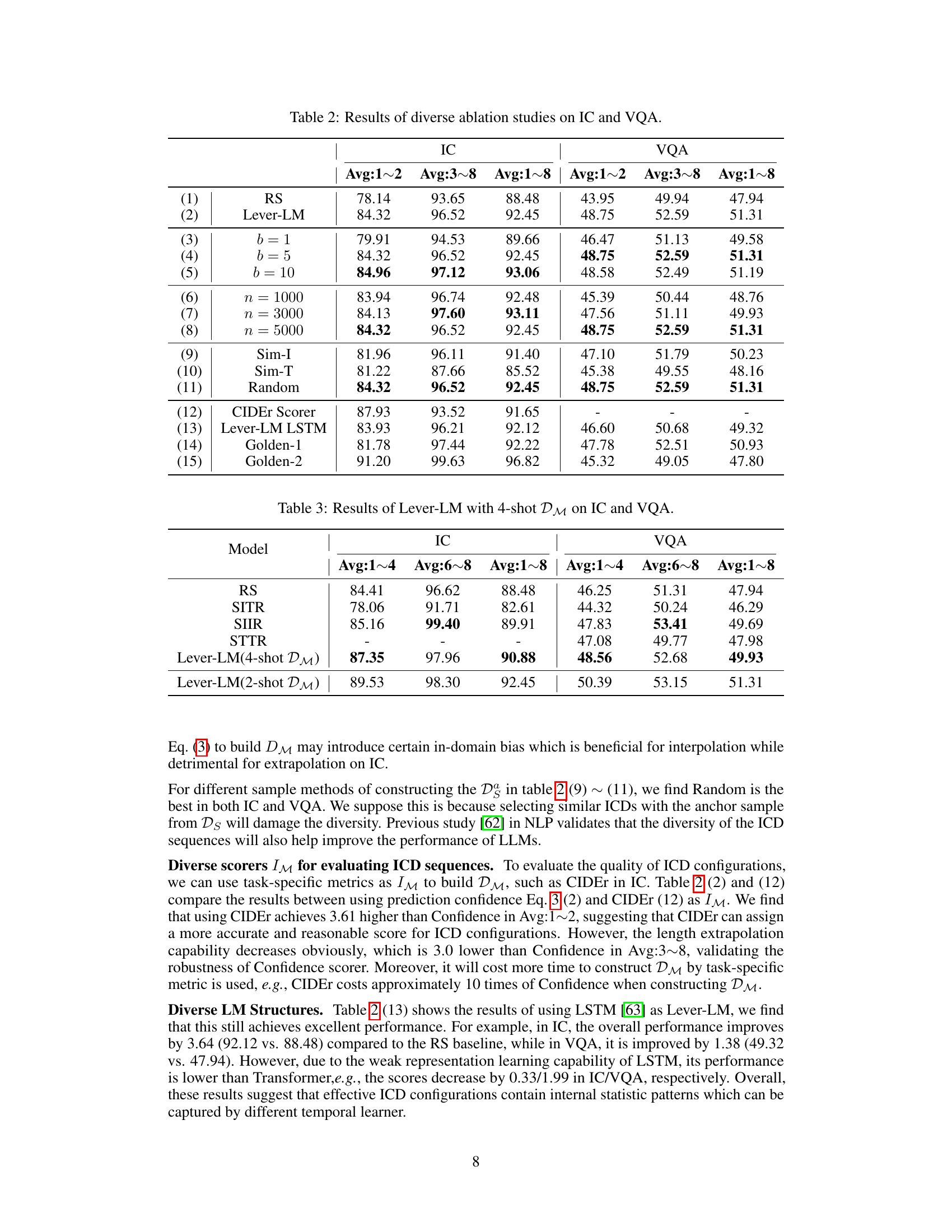
Ablation Studies#
Ablation studies systematically assess the impact of individual components within a model or system. In the context of a research paper, an ablation study section would likely present experiments where parts of the proposed method are removed or altered to determine their contribution to the overall performance. The key goal is to isolate and quantify the effects of specific features, allowing researchers to demonstrate the necessity and effectiveness of each component. For instance, if the paper introduces a novel method for improving the in-context learning capabilities of large vision-language models, ablation studies might involve removing certain modules or modifying key hyperparameters. By observing the performance changes resulting from these controlled alterations, the authors can validate their design choices and provide a more compelling argument for the overall approach. Analyzing these results will reveal whether a particular component significantly benefits performance, which features are essential, and where further improvements could be made. This section often involves a series of carefully designed experiments showing both quantitative (e.g., performance metrics) and qualitative (e.g., visualizations) findings, providing a detailed understanding of how the different model parts work together. Strong ablation studies contribute significantly to establishing the credibility and robustness of the proposed method.
Future Work#
Future research directions stemming from this Lever-LM work could explore several promising avenues. Extending Lever-LM’s capabilities to handle more complex vision-language tasks beyond Visual Question Answering and image captioning is crucial. This would involve testing on tasks requiring deeper reasoning or more nuanced understanding of visual and linguistic contexts. Investigating the effect of different LM architectures on Lever-LM’s performance is warranted. The current work primarily employs Transformers; experimenting with other architectures could reveal further performance improvements or potentially reveal a more efficient underlying mechanism. A more in-depth exploration of the dataset creation process is highly recommended. The current greedy sampling method for constructing the training data might be refined to yield a higher quality dataset leading to greater performance. A more robust evaluation methodology, perhaps involving rigorous statistical testing or a larger-scale evaluation across diverse datasets, would also strengthen the conclusions. Finally, exploring applications of Lever-LM in other domains outside of vision-language models would showcase its generalizability and utility.
More visual insights#
More on figures
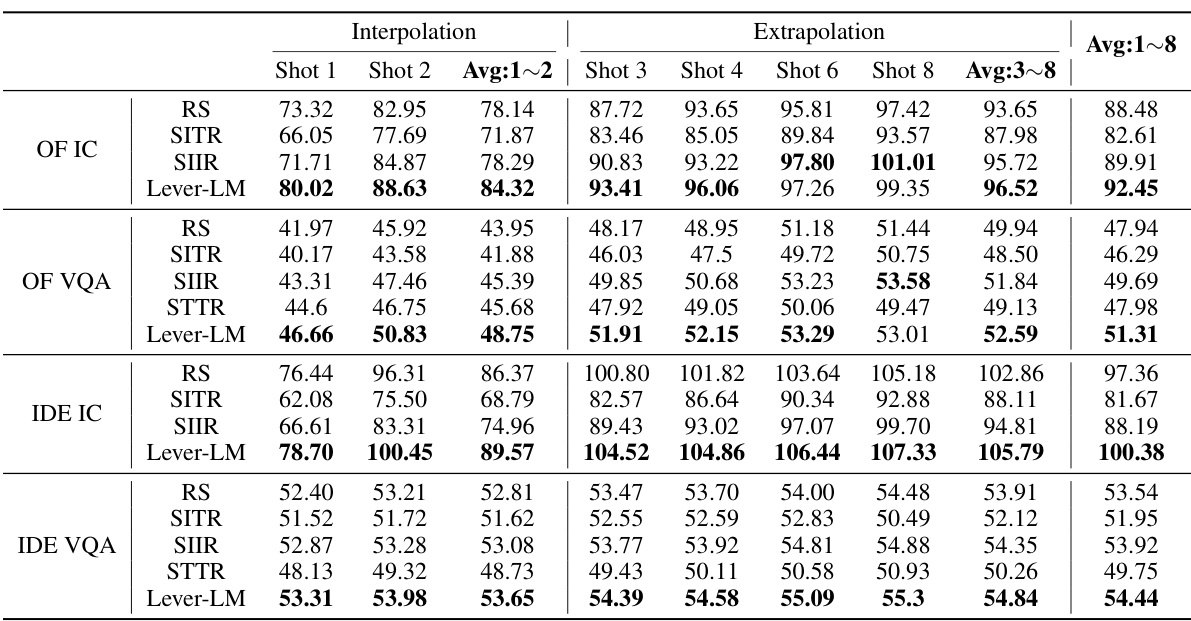
The figure illustrates the process of constructing the training dataset DM and the architecture of Lever-LM. Panel (a) details the construction pipeline, highlighting the selection of anchor samples, generation of K-shot in-context sequences, and the use of a scorer to evaluate the quality of these sequences. The darker shading of SK represents higher scores according to Equation 2. Panel (b) displays the Lever-LM architecture, which consists of a two-layer Transformer. The input embeddings are a combination of learnable embeddings, image embeddings, and text embeddings extracted using CLIP. This shows how Lever-LM takes in queries and corresponding ICDs to learn patterns for effective ICD sequence generation.

This figure illustrates the difference between traditional methods for configuring in-context demonstrations (ICDs) and the proposed Lever-LM approach. Traditional methods (a) involve separate selection and ordering of ICDs, leading to suboptimal results. Lever-LM (b) generates ICD configurations step-by-step, considering selection and ordering simultaneously for improved performance.

This figure compares traditional methods for configuring in-context demonstrations (ICDs) with the proposed Lever-LM approach. Traditional methods involve separate selection and ordering steps, often leading to suboptimal performance. In contrast, Lever-LM generates ICD configurations step-by-step, holistically considering both selection and ordering, aiming for improved in-context learning (ICL).

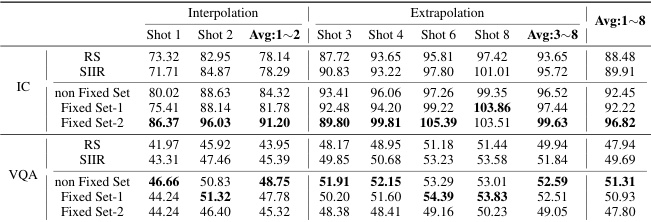
This figure visualizes two sets of 8-shot in-context demonstrations (ICDs) for the Visual Question Answering (VQA) task. Each set, labeled ‘Fixed Set-1: VQA’ and ‘Fixed Set-2: VQA,’ shows a series of images paired with questions and answers, representing examples provided to the large vision-language model (LVLM) to solve VQA tasks. The figure highlights the diversity of visual examples selected and demonstrates a different pattern of ICD arrangement, which aims to illustrate Lever-LM’s ability to generate various and effective ICD configurations.
More on tables
This table presents a comparison of various in-context learning (ICL) methods for image captioning (IC) and visual question answering (VQA) tasks. The methods are evaluated using two large vision-language models (LVLMs): Open-Flamingo (OF) and IDEFICS (IDE). The results show the performance of each method across different numbers of in-context demonstrations (shots). The table includes results for the proposed Lever-LM method, trained on a dataset of 2-shot in-context demonstrations, as well as several baseline methods including random sampling (RS) and similarity-based retrieval methods. Lever-LM consistently outperforms other methods across various scenarios.
This table presents the results of various In-context learning (ICL) methods on two vision-language tasks: Image Captioning (IC) and Visual Question Answering (VQA). It compares the performance of Random Sample (RS), Similarity-based Image-Image Retrieval (SIIR), Similarity-based Text-Text Retrieval (STTR), Similarity-based Image-Text Retrieval (SITR), and the proposed Lever-LM method. The results are shown separately for different numbers of shots (1-8) for both short (interpolation) and long (extrapolation) ICD sequences, and are broken down by model used (OpenFlamingo and IDEFICS). The Lever-LM model was trained using a dataset with a 2-shot In-context demonstration (ICD).
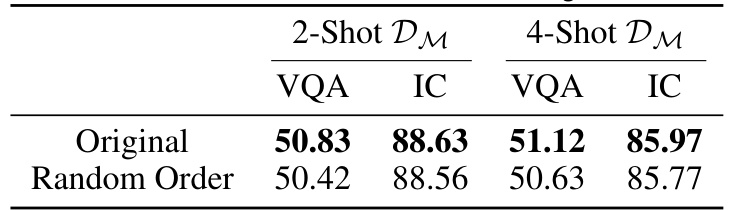
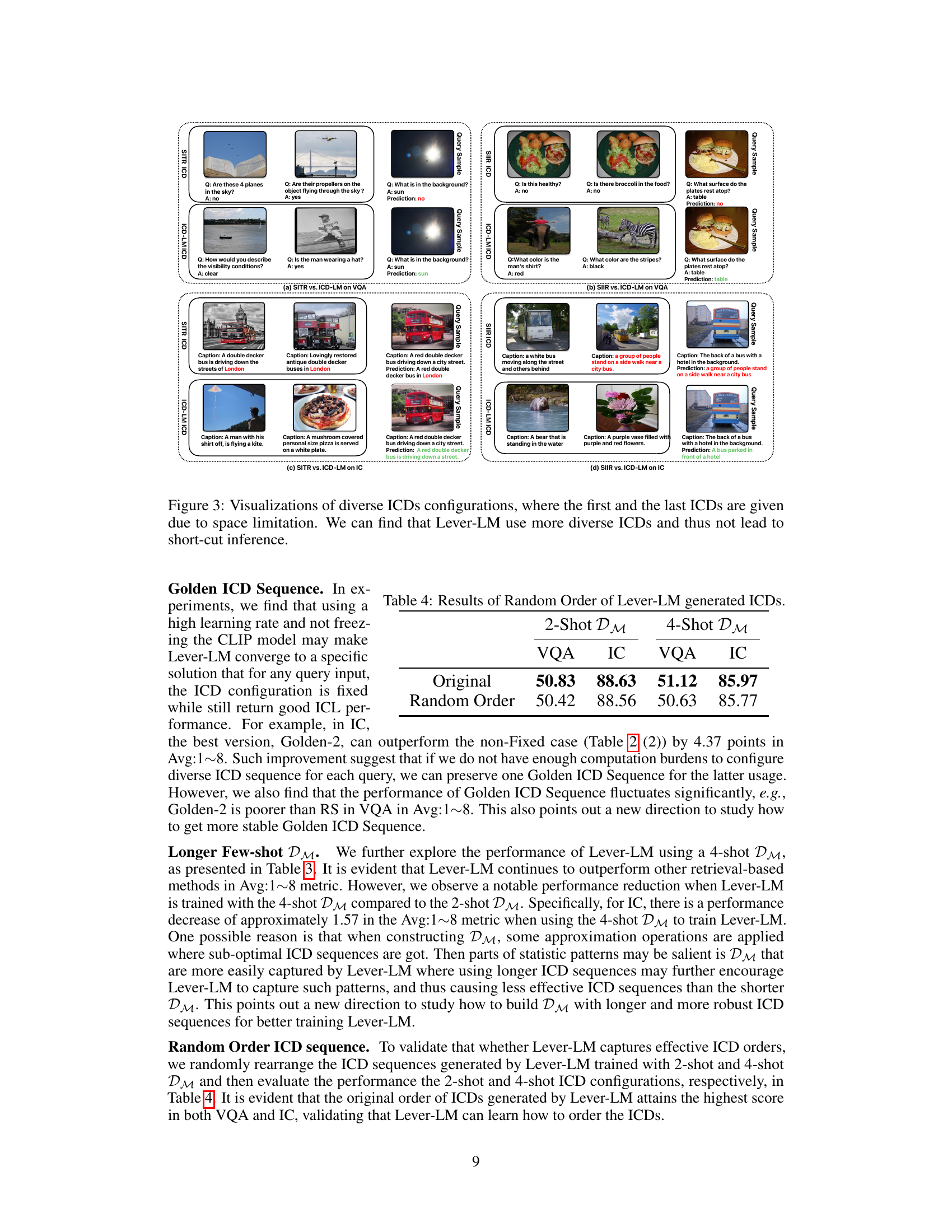
This table presents the results of an experiment where the order of In-context demonstrations (ICDs) generated by Lever-LM was randomized. It compares the performance of the original, ordered ICDs to those with a randomized order, using both 2-shot and 4-shot demonstration settings on Visual Question Answering (VQA) and Image Captioning (IC) tasks. The results highlight the impact of ICD ordering on the performance of Lever-LM.

This table presents the hyperparameters used in the Lever-LM experiments. It shows various configurations used for training, including the learning rate, weight decay, number of epochs, whether CLIP model was frozen, and if an adapter was used. It also shows the parameters of the DM dataset for the different configurations, such as the number of anchor samples, beam size, and length of the ICD configurations. The table is divided into two sections based on the task: Image Captioning (IC) and Visual Question Answering (VQA). Each row represents a different experimental setup for Lever-LM training and evaluation.

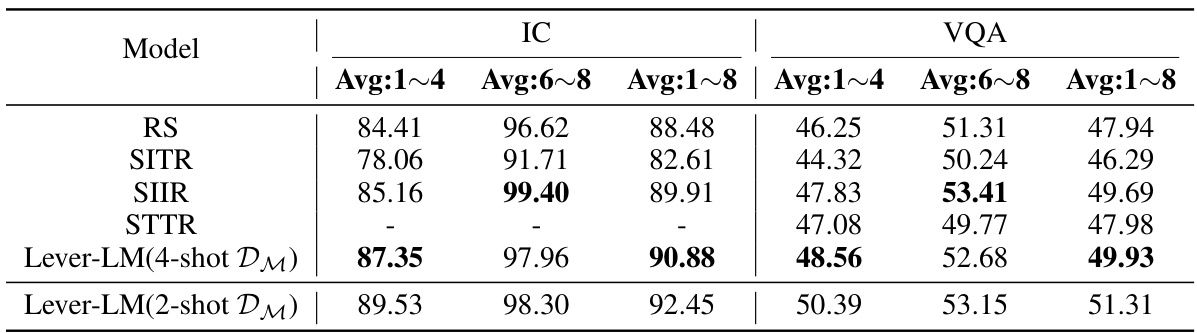
This table compares the performance of different in-context learning (ICL) methods on Image Captioning (IC) and Visual Question Answering (VQA) tasks. The methods compared include Random Sample (RS), Similarity-based Image-Image Retrieval (SIIR), Similarity-based Text-Text Retrieval (STTR), Similarity-based Image-Text Retrieval (SITR), and the proposed Lever-LM. The results are shown separately for two different large vision-language models (LVLMs): OpenFlamingo (OF) and IDEFICS (IDE). The table presents results for different numbers of in-context demonstrations (1-shot, 2-shot, 3-shot, 4-shot, 6-shot, and 8-shot), categorized as interpolation (shorter than training data), extrapolation (longer than training data) and average performance. Lever-LM is trained using in-context demonstrations of length 2.
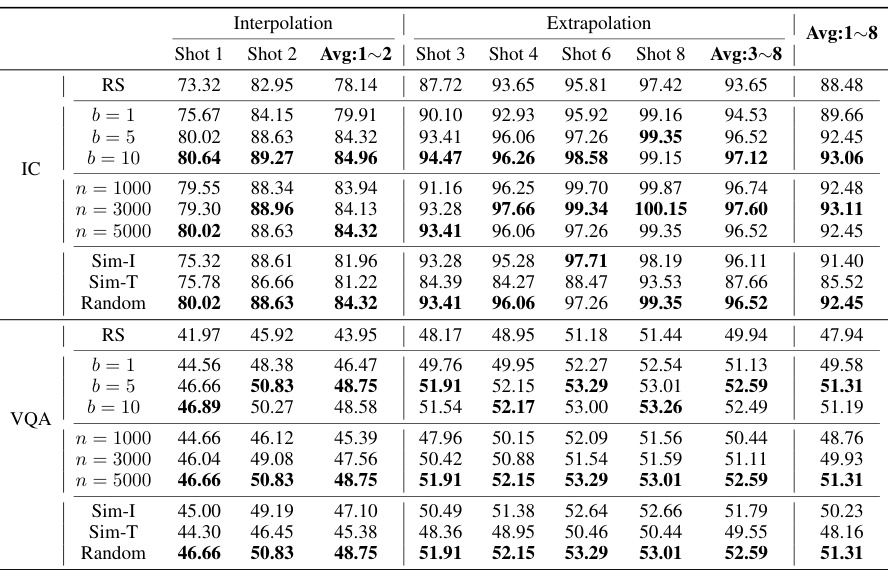
This table presents a comparison of different In-Context Learning (ICL) methods for Image Captioning (IC) and Visual Question Answering (VQA) tasks. It compares the performance of Random Sample (RS), Similarity-based Image-Image Retrieval (SIIR), Similarity-based Text-Text Retrieval (STTR), Similarity-based Image-Text Retrieval (SITR), and the proposed Lever-LM method. The results are broken down by the number of shots (1-8) and show the performance of each method on both OpenFlamingo (OF) and IDEFICS (IDE) Large Vision Language Models (LVLMs). Lever-LM uses a smaller language model to generate effective in-context demonstration (ICD) sequences to improve the LVLMs’ performance. The table shows interpolation (shorter ICDs than training data) and extrapolation (longer ICDs than training data) abilities of Lever-LM.

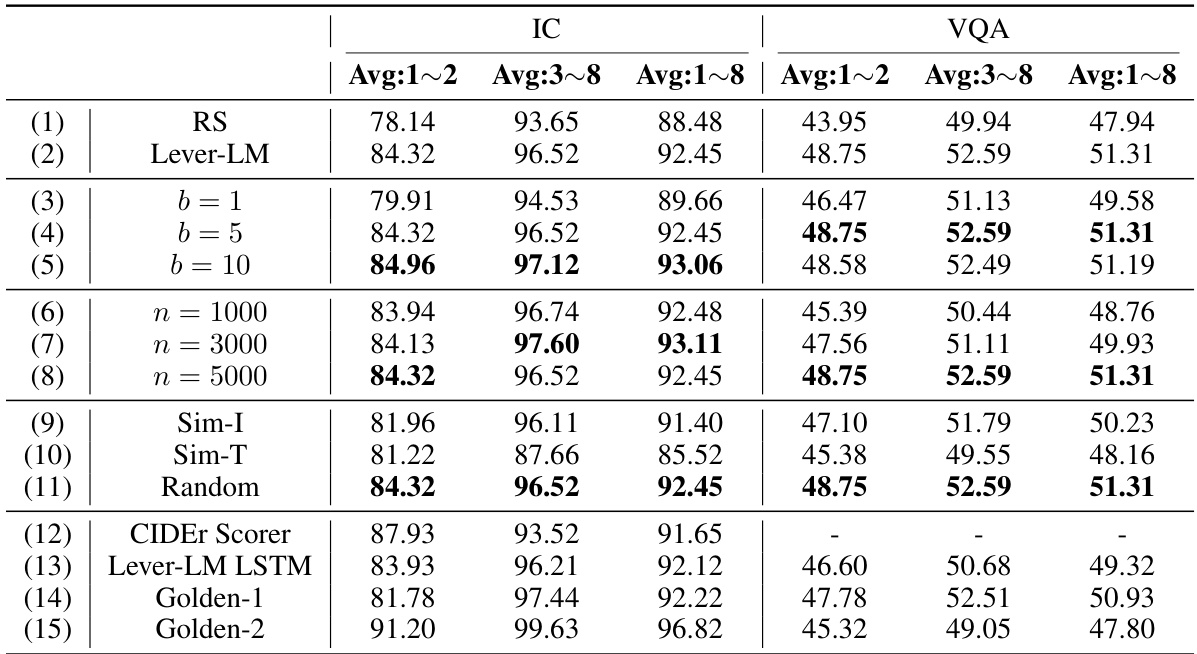
This table presents the results of various methods for constructing the training dataset (DM) for Lever-LM. The methods are compared on Image Captioning (IC) and Visual Question Answering (VQA) tasks, with different configurations of the number of samples (n), beam size (b), and the length of ICD sequences (l). The comparison metric is the average CIDEr score across 1 to 8 shots (Avg:1
8) for IC and the average accuracy across 1 to 8 shots (Avg:18) for VQA. The results show the performance of Lever-LM under different DM configurations, including interpolation (Avg:12) and extrapolation (Avg:38) capabilities.

This table presents the performance comparison of different In-Context Learning (ICL) methods on Image Captioning (IC) and Visual Question Answering (VQA) tasks. The methods include Random Sampling (RS), Similarity-based Image-Image Retrieval (SIIR), Similarity-based Text-Text Retrieval (STTR), Similarity-based Image-Text Retrieval (SITR), and the proposed Lever-LM. Results are shown for different numbers of shots (1-8), with separate results for interpolation (using fewer shots than the Lever-LM training data) and extrapolation (using more shots than the training data). The table highlights the superior performance of Lever-LM across both tasks and various shot configurations.
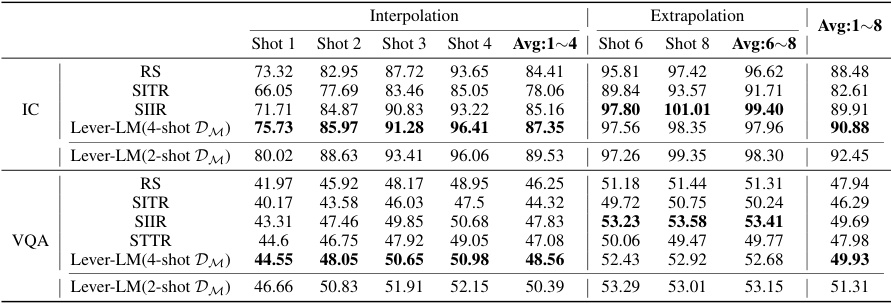
This table presents a comparison of different in-context learning (ICL) methods for image captioning (IC) and visual question answering (VQA) tasks. The methods compared are Random Sample (RS), Similarity-based Image-Image Retrieval (SIIR), Similarity-based Text-Text Retrieval (STTR), Similarity-based Image-Text Retrieval (SITR), and Lever-LM. Results are shown for both OpenFlamingo (OF) and IDEFICS (IDE) large vision-language models (LVLMs). The table shows performance across different numbers of in-context demonstrations (shots), highlighting both interpolation (using fewer shots than in training) and extrapolation (using more shots than in training) capabilities. Lever-LM is trained on a dataset with 2-shot in-context demonstrations.
This table presents a comparison of different in-context learning (ICL) methods for image captioning (IC) and visual question answering (VQA) tasks using two large vision-language models (LVLMs): OpenFlamingo and IDEFICS. The methods compared include random sampling (RS), similarity-based retrieval methods (SITR, SIIR, STTR), and the proposed Lever-LM method. Results are shown for various numbers of shots (1-8), broken into interpolation and extrapolation. The Lever-LM model utilizes a smaller language model to generate effective in-context demonstration (ICD) sequences, and the table shows the performance gains achieved by this approach compared to the baseline methods.
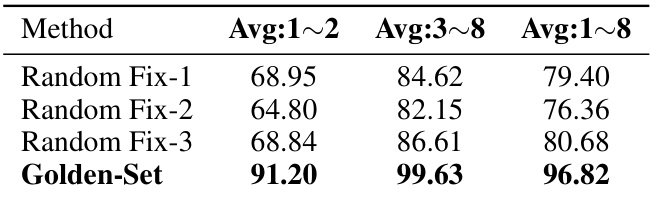
This table presents the CIDEr scores achieved by different methods for image captioning using the OpenFlamingo model. It compares the performance of three randomly generated fixed sets of in-context demonstrations (ICDs) against a ‘Golden-Set’ of ICDs, which is an optimal sequence identified by the Lever-LM. The results are separated into interpolation (Avg:1
2), extrapolation (Avg:38), and overall (Avg:1~8) scores, showing the Golden-Set’s superior performance across all metrics. This highlights the effectiveness of the Lever-LM in generating high-quality ICD sequences for improved image captioning.

This table presents a comparison of various In-Context Learning (ICL) methods’ performance on Image Captioning (IC) and Visual Question Answering (VQA) tasks. The methods compared include Random Sample (RS), Similarity-based Image-Image Retrieval (SIIR), Similarity-based Text-Text Retrieval (STTR), Similarity-based Image-Text Retrieval (SITR), and the proposed Lever-LM. Performance is measured across different numbers of in-context demonstrations (shots) for both interpolation (fewer shots than training) and extrapolation (more shots than training). OpenFlamingo (OF) and IDEFICS (IDE) are the two large vision-language models (LVLMs) used for evaluation.
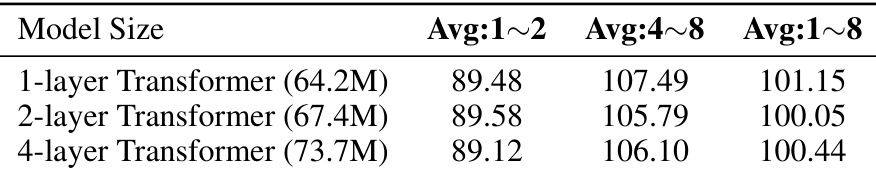
This table presents the CIDEr scores achieved by Lever-LM models of varying sizes (1-layer, 2-layer, and 4-layer Transformers) on the image captioning task using the IDEFICSv1 model. The results are categorized by the average number of shots (Avg:1
2, Avg:48, and Avg:1~8), indicating the performance across different in-context learning scenarios.

This table presents the accuracy results of different in-context learning (ICL) methods on the SST2 dataset using the Qwen1.5-1.8B model. The methods compared are Random Sample (RS), Similarity-based Text-Text Retrieval (STTR), and the proposed Lever-LM. The accuracy is shown for different shot numbers (Avg:1
2 represents the average accuracy for one and two-shot settings, Avg:48 is the average accuracy for four to eight shots, and Avg:1~8 is the average accuracy for one to eight shots). This table demonstrates the performance of Lever-LM compared to other approaches, particularly its ability to maintain high accuracy with a greater number of shots.

This table presents the inference time taken by different In-context Learning (ICL) methods when using the IDEFICSv1 model. It compares the time taken by Similarity-based Image-Image Retrieval (SIIR) and Lever-LM, showing that Lever-LM’s improvement in performance does not come at a significant cost in terms of inference time. The values represent the retrieval time in seconds for each method.

This table presents the results of different In-context Learning (ICL) methods on two tasks from the VL-ICL benchmark using the IDEFICSv1 model. The methods compared include Random Sample (RS), Similarity-based Image-based Retrieval (SIIR), and the proposed Lever-LM. The results are shown for average performance across 1-2 shots and 4-8 shots, as well as the overall average across all shots. The tasks are VL-ICL CLEVR and VL-ICL OCRText.

This table shows the CIDEr scores achieved by different in-context learning (ICL) methods on the image captioning task using the IDEFICSv2-8B model. The methods compared include Random Sampling (RS), Similarity-based Image-Image Retrieval (SIIR), and the proposed Lever-LM approach. The scores are presented for different shot settings (Avg:1
2 and Avg:34) to evaluate performance with varying numbers of in-context demonstrations. Lever-LM consistently outperforms other methods across different shot settings, demonstrating its ability to effectively configure in-context demonstrations for improved performance.
Full paper#