↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Autonomous systems require safe and reliable controllers, but verifying the safety of learned controllers, especially in complex nonlinear systems, is a significant challenge. Existing approaches often struggle to scale to longer safety horizons or complex dynamics. This is due to limitations in verification techniques and the difficulty of learning a single universal controller that works across all possible initial states.
The proposed method, VSRL, addresses these limitations by introducing three key innovations: a novel curriculum learning scheme to gradually increase the verification horizon; incremental verification to reuse information from previous steps, and learning multiple controllers customized for different initial states. VSRL demonstrates significant improvements in verified safety over existing state-of-the-art methods, achieving an order of magnitude longer safety horizons while maintaining high reward. Experiments on multiple complex control problems confirm this improvement, showcasing the effectiveness of the proposed approach.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel approach to learning safe control policies in complex systems by combining reinforcement learning with formal verification. This addresses a critical challenge in autonomous systems, paving the way for more reliable and trustworthy AI applications. The techniques introduced, such as curriculum learning and incremental verification, offer significant improvements in both efficiency and scalability, opening up new avenues for research in verified safe reinforcement learning.
Visual Insights#
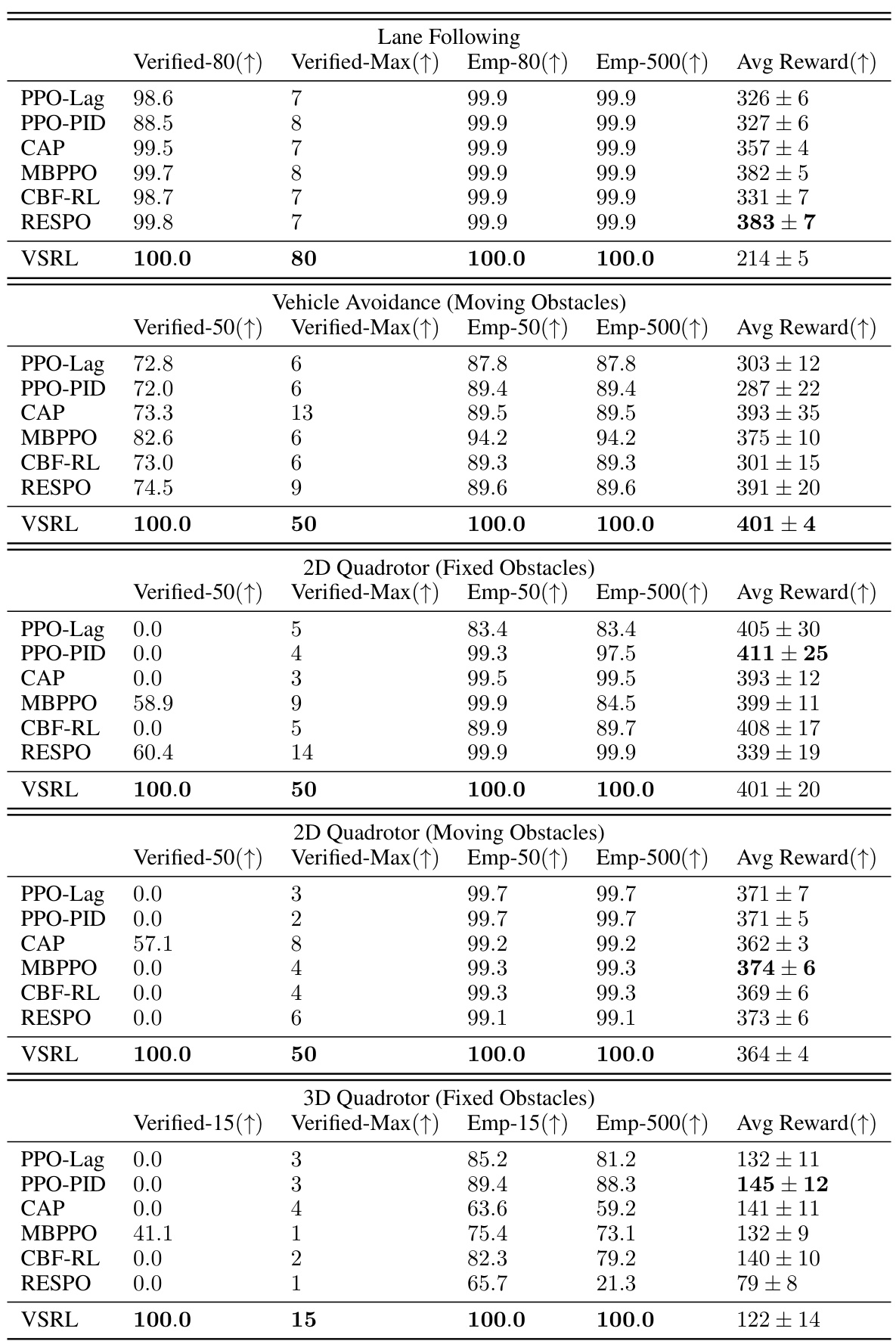
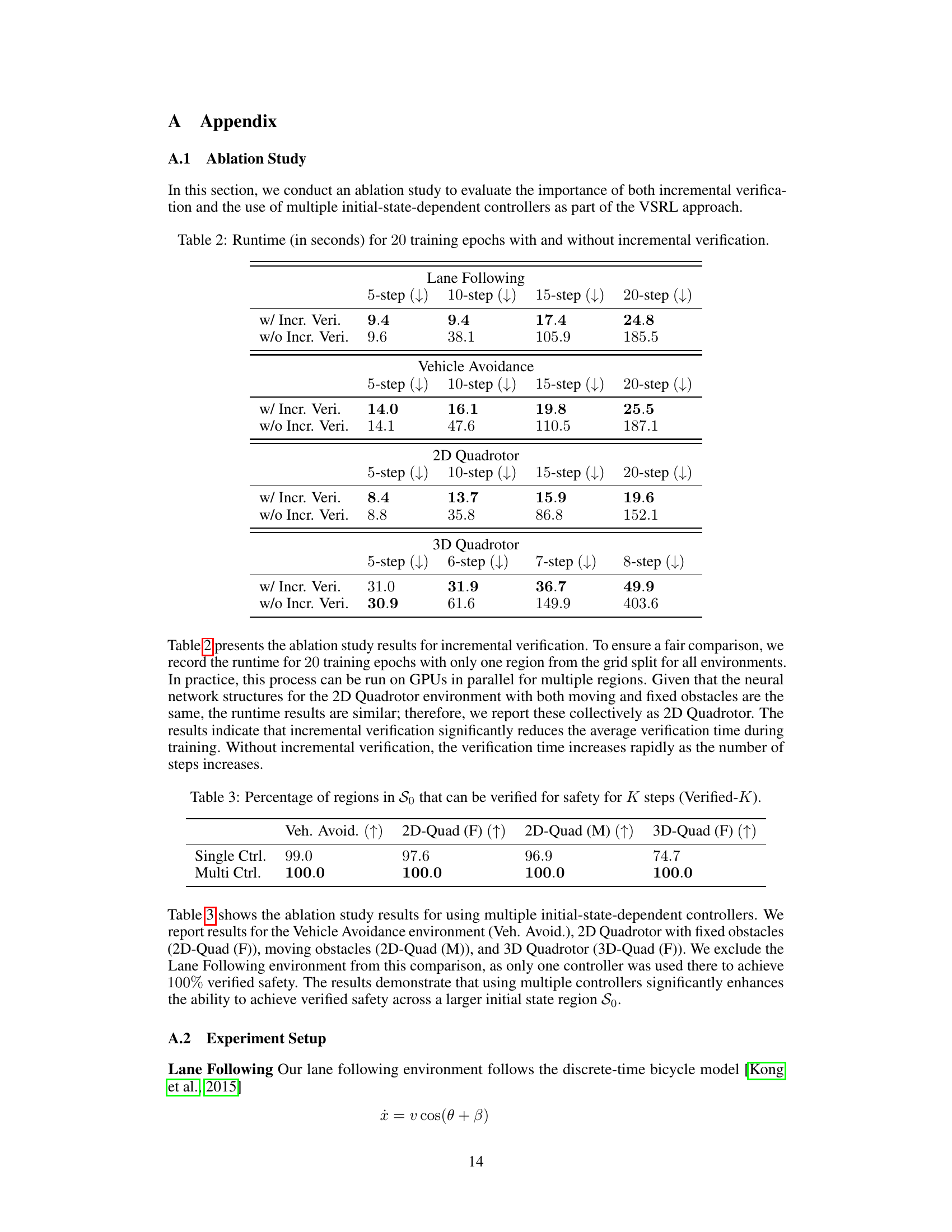
This table presents a comparison of the proposed VSRL approach against six baseline methods across five different control tasks. For each task, it reports the percentage of initial states for which safety is verified over a given horizon (Verified-K), the maximum horizon for which safety is verified for all initial states (Verified-Max), the percentage of initial states for which safety is empirically achieved over given horizons (Emp-K), and the average reward achieved. The results illustrate the superior performance of the VSRL approach in terms of both verified and empirical safety, while also maintaining high reward in most scenarios.
In-depth insights#
Verified Safe RL#
Verified Safe Reinforcement Learning (RL) represents a crucial advancement in AI safety. Traditional RL methods often prioritize reward maximization, potentially overlooking safety concerns. Verified Safe RL addresses this by incorporating formal verification techniques, ensuring that learned policies adhere to predefined safety constraints. This verification step moves beyond empirical testing, providing mathematical guarantees of safety. The key challenge lies in balancing safety with performance, which often involves trade-offs. Methods like curriculum learning and incremental verification are employed to efficiently train safe and effective controllers. By combining RL’s learning capacity with verification’s rigor, Verified Safe RL creates trustworthy autonomous systems, particularly in complex domains where human safety is paramount. However, scalability and the computational cost of verification remain active research areas, especially for intricate neural network models. Future work will focus on addressing these limitations to expand the scope and applicability of this important field.
Curriculum Learning#
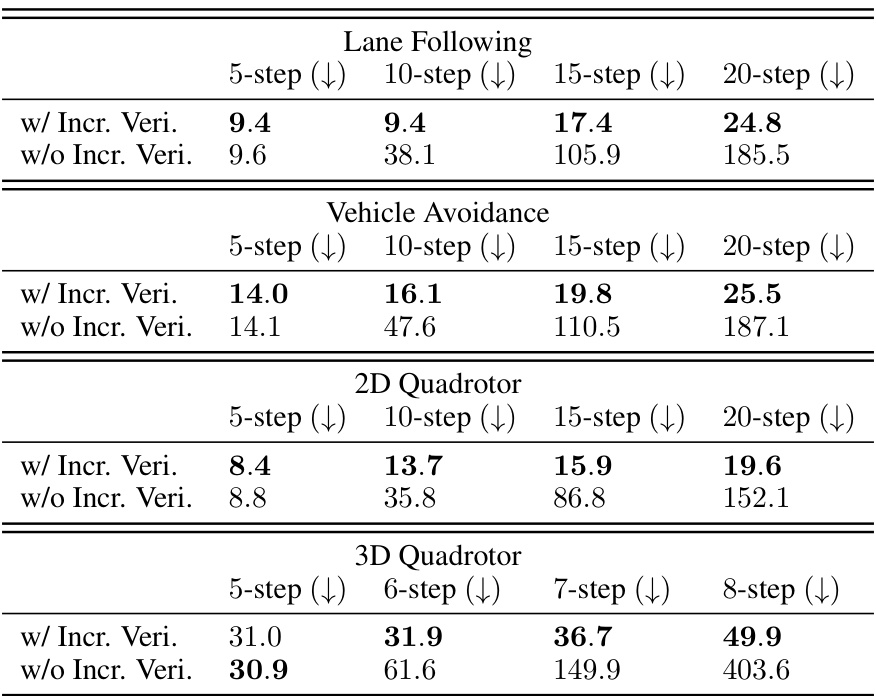
Curriculum learning, in the context of safe reinforcement learning, is a powerful technique for incrementally training controllers that achieve verified safety over increasingly longer horizons. The iterative nature of the approach allows for the reuse of information from previous verification runs, improving efficiency. The core idea is to start with easier tasks (shorter safety horizons) and gradually increase the difficulty. This iterative approach is crucial because verifying safety over long horizons becomes exponentially harder as the horizon length increases. The paper highlights the value of memorizing states that nearly violated safety constraints during the curriculum, feeding this information back into the training process to further improve robustness. This technique not only enhances the safety of the learned policies but also contributes to their overall performance.
Incremental Verif#
Incremental verification, in the context of neural network safety verification for controllers, addresses the computational cost of verifying safety over long horizons. Standard verification methods often struggle with the exponential increase in complexity as the time horizon expands. Incremental verification mitigates this by breaking down the verification task into smaller, more manageable steps. This allows for reusing information from previous steps, thereby significantly reducing the overall computational burden. The key advantage is the improved scalability, allowing for verification of safety over significantly longer horizons than traditional methods would permit, leading to more robust and trustworthy autonomous systems. The trade-off is that incremental approaches introduce some approximation error which is carefully managed and controlled within a safe bound. This strategy effectively combines efficiency gains with a reasonable level of accuracy to ensure both computational feasibility and high-confidence safety verification.
Initial-State Ctrl#
The concept of ‘Initial-State Ctrl’ in the context of verified safe reinforcement learning suggests a paradigm shift from traditional approaches. Instead of seeking a single universal controller applicable to all initial states, this method proposes training multiple controllers, each specialized for a subset of initial states. This is particularly crucial in complex domains where a universal controller might prove elusive or computationally expensive to verify. By partitioning the state space and assigning dedicated controllers, the approach significantly simplifies the verification process and increases the likelihood of achieving verified safety over longer horizons. This strategy leverages the fact that verifying safety for subsets of initial states is computationally less demanding than for the entire state space. The resulting controllers, though state-dependent, offer improved performance in terms of both safety and reward, exceeding state-of-the-art baselines. The incremental nature of this approach, refining controllers based on previously verified regions, further enhances efficiency and scalability. This technique is particularly important for high-dimensional systems where exhaustive verification is impractical.
Future Works#
Future work should explore extending the approach to handle stochasticity and partial observability, which are prevalent in real-world scenarios. Improving scalability for higher-dimensional state and action spaces is also crucial. Addressing the computational cost of verification through more efficient algorithms or approximations would significantly impact real-time applicability. Investigating different verification techniques beyond α,β-CROWN to enhance robustness and accuracy is another important direction. Finally, exploring the theoretical guarantees of the proposed curriculum learning scheme and its convergence properties would provide a stronger foundation for the method. Applying this framework to more complex control problems in robotics and autonomous systems would showcase its potential and highlight limitations in diverse contexts. The impact of different hyperparameter choices on the overall performance also requires a more thorough investigation.
More visual insights#
More on tables
This table presents the performance comparison of the proposed VSRL approach against five baseline methods across five different control tasks. For each task and method, it shows the percentage of initial states for which safety was verified for a given horizon (Verified-K), the maximum horizon for which all initial states were verified safe (Verified-Max), the empirical safety rate at the verified horizon and at a much longer horizon (Emp-K), and the average reward achieved during the experiment. The results demonstrate the superiority of VSRL in achieving both verified and empirical safety.

This table presents the performance comparison of the proposed VSRL approach against five state-of-the-art safe reinforcement learning baselines across five different control tasks. For each task and method, the table shows the percentage of initial states for which safety can be verified for a given number of steps (Verified-K), the maximum number of steps for which safety could be verified for all initial states (Verified-Max), the empirical safety rate for K steps (Emp-K) and the full episode (Emp-500), and the average reward achieved.
Full paper#