↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual Simultaneous Localization and Mapping (SLAM) is crucial for autonomous navigation but faces significant challenges in dynamic environments due to inconsistent observations. Existing methods struggle to maintain accuracy and fidelity in such scenarios, often failing to separate dynamic objects from the static environment. Many recent methods integrate Gaussian splatting into SLAM, but they still assume static scenes.
This paper introduces DG-SLAM, a novel dynamic visual SLAM system that leverages 3D Gaussians. It uses motion mask generation to filter dynamic objects, adaptive Gaussian point management for efficient map representation, and a hybrid camera tracking algorithm for robust pose estimation. This innovative approach dramatically improves the accuracy, robustness, and fidelity of SLAM, outperforming existing techniques while maintaining real-time performance.
Key Takeaways#
Why does it matter?#
This paper is important because it presents DG-SLAM, the first robust dynamic visual SLAM system grounded in 3D Gaussians. This addresses a critical challenge in robotics and autonomous driving by enabling precise pose estimation and high-fidelity reconstruction even in dynamic environments. The proposed motion mask generation, adaptive Gaussian point management, and hybrid camera tracking significantly improve accuracy and robustness. This opens avenues for more reliable and versatile SLAM systems in real-world applications.
Visual Insights#
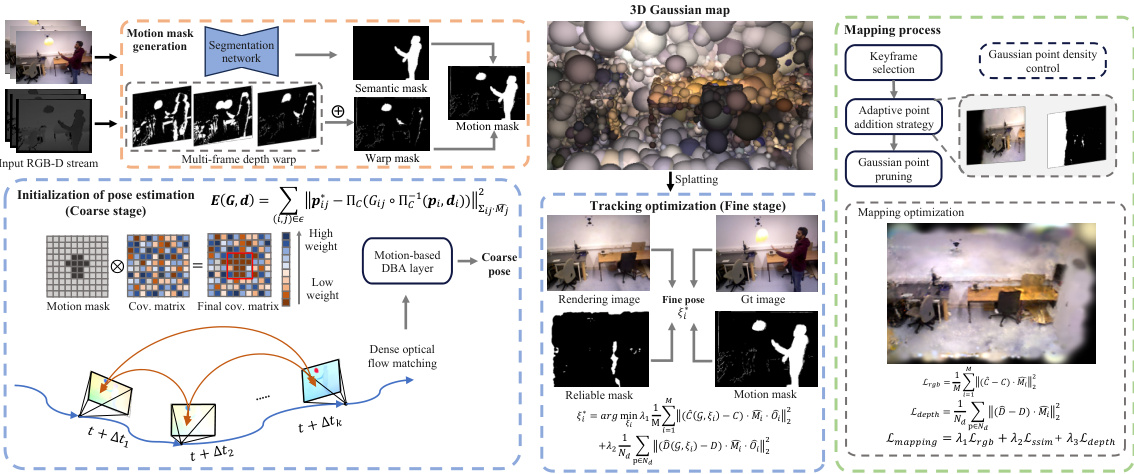
This figure provides a detailed overview of the DG-SLAM system. It illustrates the process flow, starting from the input RGB-D stream and culminating in the final 3D Gaussian map and optimized camera poses. Key components such as motion mask generation, hybrid pose optimization (coarse and fine stages), adaptive Gaussian point management, and mapping optimization are visually represented. The figure highlights the interplay between different modules and their contributions to achieving robust and accurate SLAM in dynamic environments.
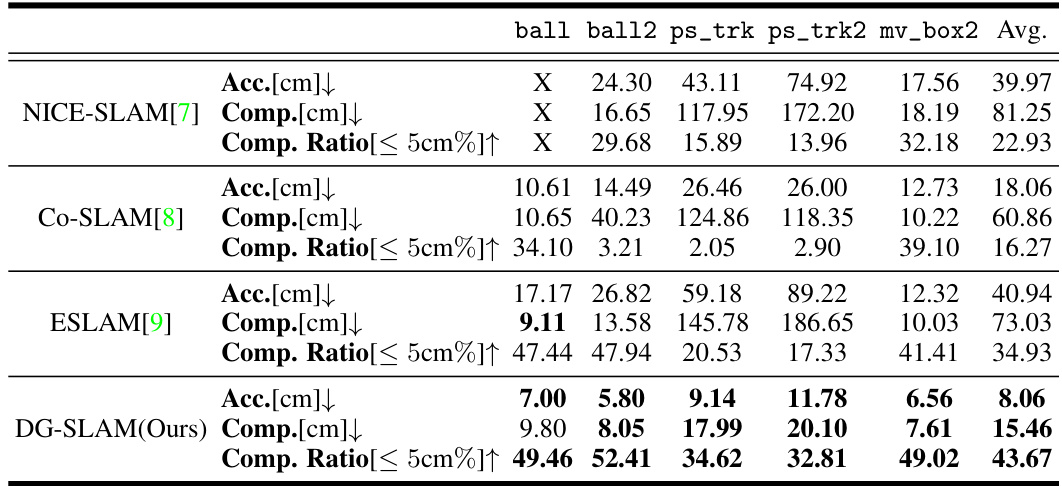
This table presents a comparison of reconstruction results on dynamic scenes from the BONN dataset. Several state-of-the-art RGB-D SLAM methods are evaluated using metrics such as Accuracy (in cm), Completion (in cm), and Completion Ratio (percentage of points within 5cm). The table highlights the superior performance of the proposed DG-SLAM method.
In-depth insights#
Hybrid Pose Opt#
The concept of “Hybrid Pose Optimization” in a visual SLAM system suggests a synergistic combination of methods to robustly estimate camera poses. It likely involves a coarse initial pose estimation, possibly using a lightweight and fast method like visual odometry, followed by a refined optimization, leveraging a more computationally intensive but accurate technique such as bundle adjustment. This approach balances speed and precision. The hybrid strategy is particularly beneficial in dynamic environments, where a fast initial estimate helps to handle motion blur and inconsistencies, while the refinement stage improves accuracy by incorporating more data and constraints. Motion masking, intelligently filtering out dynamic regions, would likely play a crucial role in enabling accurate pose optimization in such scenarios. A well-designed hybrid approach promises to achieve real-time performance with high-quality pose estimation and map reconstruction.
Dynamic SLAM#
Dynamic SLAM presents a significant challenge in robotics and computer vision, demanding robust solutions to handle the complexities of moving objects within a scene. Accurate pose estimation becomes difficult due to inconsistent observations caused by dynamic elements. Existing approaches often rely on assumptions of static environments or employ computationally intensive techniques like filtering out moving objects or incorporating scene flow estimations. However, these methods often fail in scenarios with rapid or unpredictable movement, continuous object interactions, or occlusion. A key focus for advanced Dynamic SLAM systems involves motion segmentation, effectively discerning dynamic objects from static surroundings to improve accuracy. Additionally, data association, correctly matching observations across time steps, is crucial but problematic in dynamic scenes due to perceptual aliasing. Sophisticated approaches leverage deep learning or advanced filtering to achieve robust motion estimation and map reconstruction in real-time scenarios, highlighting the importance of efficient algorithms and appropriate representations for handling dynamic environments.
Motion Mask#
The concept of a ‘Motion Mask’ in the context of dynamic scene analysis within a visual SLAM system is crucial for robust performance. It aims to intelligently differentiate between static and dynamic regions in an image sequence. This is achieved by employing various techniques, possibly including depth warping, semantic segmentation, and temporal consistency checks. Depth warping compares depth maps across consecutive frames to identify pixels exhibiting significant displacement indicative of motion. Semantic segmentation provides object class labels, enabling the identification of moving objects. Temporal consistency filters out spurious motion by considering motion across multiple frames. These methods, combined effectively, generate a mask which isolates static scene elements for reliable 3D reconstruction, while ignoring dynamic elements to prevent errors in pose estimation and mapping. The mask generation process is critical for ensuring the robustness and accuracy of the SLAM system in complex, real-world scenarios. A well-designed motion mask is key to achieving accurate and robust visual SLAM in dynamic environments.
Gaussian Splatting#
Gaussian splatting, a novel technique in 3D scene representation, offers significant advantages for visual simultaneous localization and mapping (SLAM) systems. It represents the scene as a collection of 3D Gaussian ellipsoids, each encoding geometric and appearance properties. This explicit representation facilitates high-fidelity reconstruction and, unlike implicit methods, allows for efficient real-time rendering via splatting rasterization. The smooth, continuous, and differentiable nature of Gaussian splatting enables robust optimization during the SLAM pipeline. However, handling dynamic environments remains a challenge, requiring sophisticated motion mask generation and adaptive Gaussian point management to distinguish static and dynamic elements accurately for reliable pose estimation. Integrating Gaussian splatting into SLAM presents a compelling trade-off between reconstruction quality and computational efficiency, making it a promising approach for achieving high-quality results in real-time applications.
Future Works#
Future research directions stemming from this robust dynamic Gaussian splatting SLAM system (DG-SLAM) could focus on several key areas. Improving the handling of highly dynamic scenes remains a challenge, as the current motion mask generation strategy may struggle with extremely fast or unpredictable movements. Exploring alternative methods such as incorporating temporal consistency across longer sequences or leveraging more sophisticated motion segmentation techniques could significantly enhance performance. Addressing the computational cost associated with real-time processing and high-fidelity rendering is also crucial for broader applicability, particularly on resource-constrained platforms. Optimizations to the Gaussian splatting rendering method, as well as exploration of more efficient data structures, could be explored. Furthermore, extending the system to other sensor modalities, such as inertial measurement units (IMUs) or LiDAR, could enhance robustness and accuracy, paving the way for a truly multi-sensor fusion approach. Finally, investigating loop closure detection and global optimization strategies within dynamic environments is critical for addressing long-term consistency issues. Advanced methods could leverage semantic segmentation or other high-level scene understanding techniques to achieve more robust loop closure detection and reduce drift.
More visual insights#
More on figures
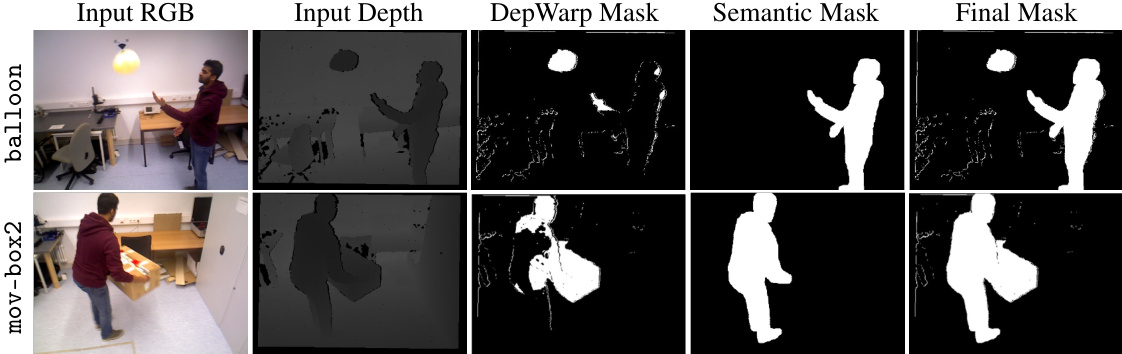
This figure shows the qualitative results of the motion mask generation process. It displays two rows, each depicting a different scene from the dataset. Each row has five columns: Input RGB, Input Depth, DepWarp Mask, Semantic Mask, and Final Mask. The input RGB and depth images show the raw data. The DepWarp Mask highlights regions identified as moving based on depth differences between frames. The Semantic Mask shows the segmentation of moving objects from the input image. Finally, the Final Mask combines the depth and semantic masks, providing a more accurate representation of the moving parts of the scene. The fusion of depth information and semantic segmentation refines the mask to accurately identify and separate dynamic objects, improving the accuracy of the motion mask. This is crucial for robust pose estimation in dynamic environments.

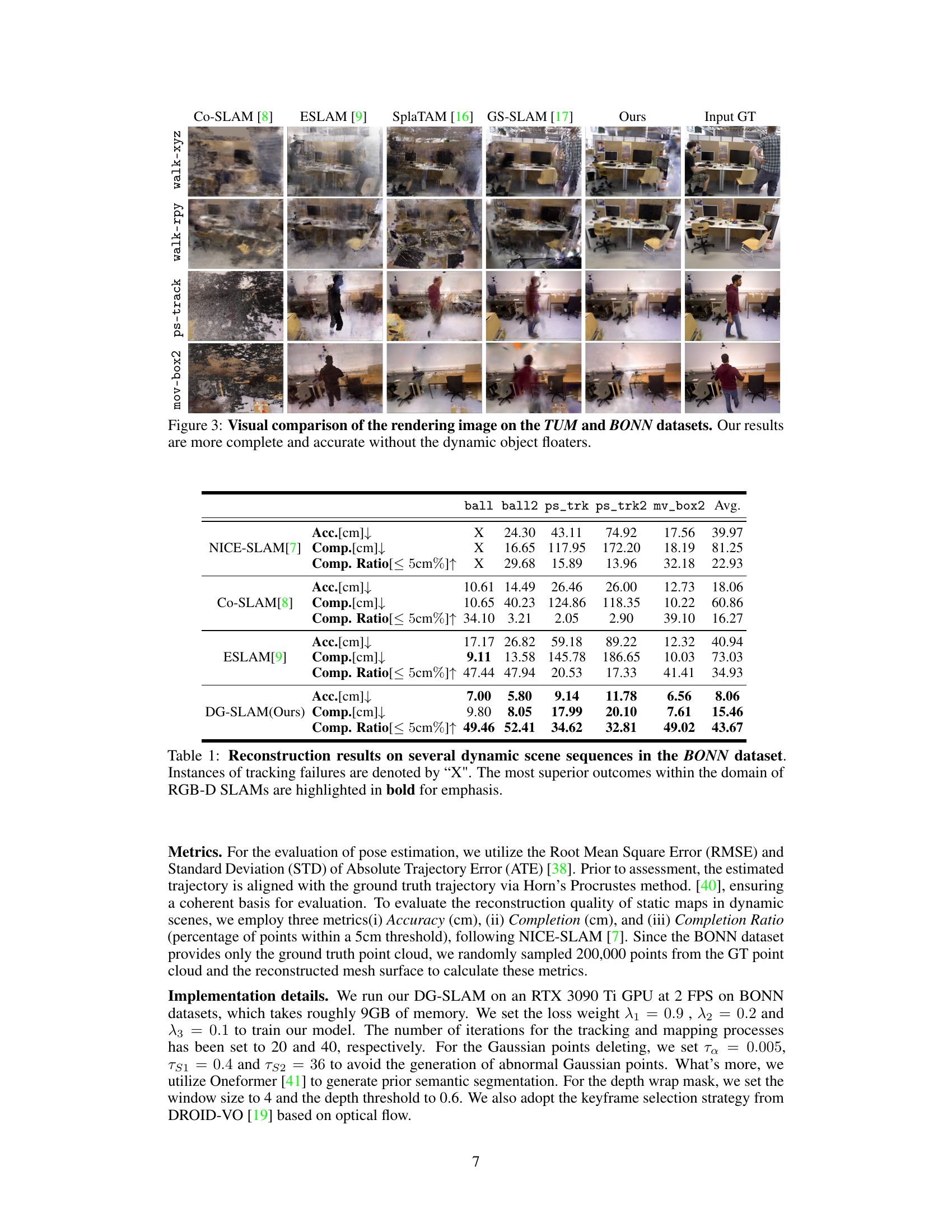
This figure compares the visual results of several state-of-the-art visual SLAM systems on the TUM and BONN datasets. It showcases the rendering quality of each system when dealing with dynamic scenes containing moving objects. The results highlight DG-SLAM’s ability to produce more accurate and detailed 3D reconstructions by effectively filtering out dynamic objects. This leads to clearer and more visually appealing reconstructions compared to the other methods.
More on tables
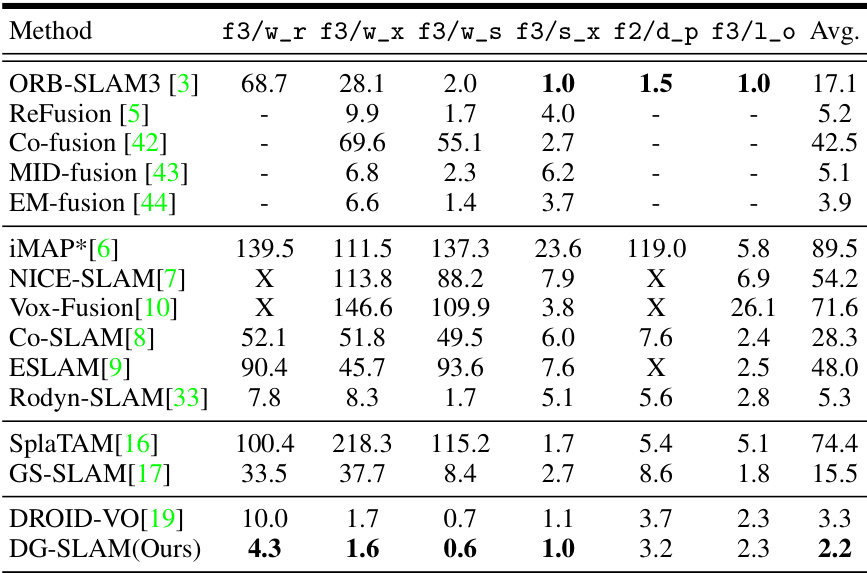
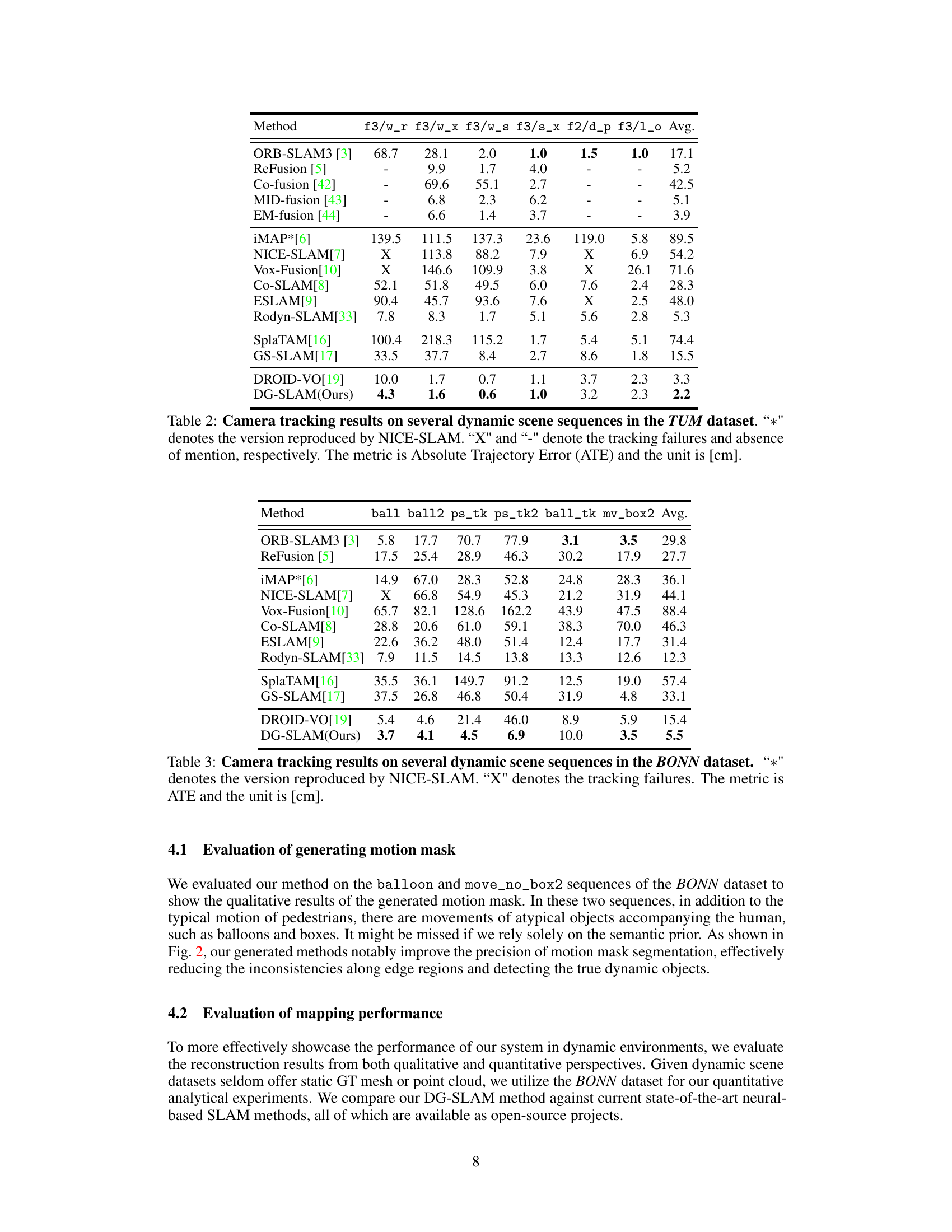
This table presents the camera tracking results of different SLAM methods on TUM dataset sequences with varying levels of dynamic content. The metric used is Absolute Trajectory Error (ATE) in centimeters. The table highlights the performance differences among various approaches, particularly in handling dynamic scenes, by comparing ATE values and indicating tracking failures with ‘X’ and missing results with ‘-’. NICE-SLAM’s reproduced version is marked with *.
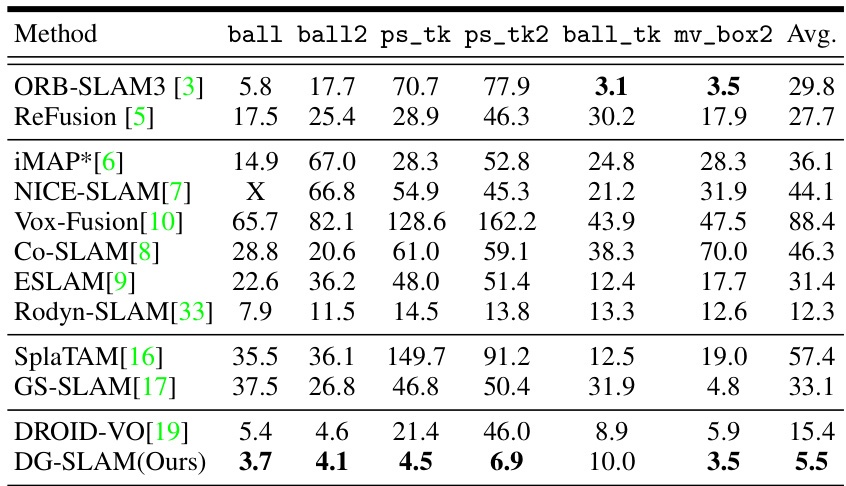
This table presents the camera tracking results on several dynamic sequences from the BONN dataset. It compares the proposed DG-SLAM method against other state-of-the-art methods, including ORB-SLAM3, ReFusion, iMAP, NICE-SLAM, Vox-Fusion, Co-SLAM, ESLAM, Rodyn-SLAM, SplaTAM, GS-SLAM, and DROID-VO. The metric used is Absolute Trajectory Error (ATE) in centimeters. ‘*’ indicates results reproduced from the NICE-SLAM paper. ‘X’ signifies tracking failures. The average ATE across different sequences is also provided for each method.
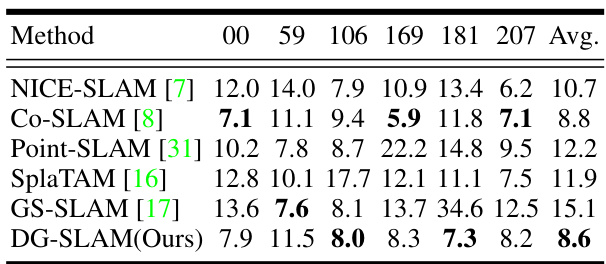
This table presents the results of camera tracking experiments conducted on the ScanNet dataset. The metric used to evaluate the performance is Absolute Trajectory Error (ATE), measured in centimeters. The table shows the ATE for different sequences (00, 59, 106, 169, 181, 207) within the ScanNet dataset, and also provides an average ATE across all sequences. This allows for a comparison of the proposed DG-SLAM method against several other state-of-the-art SLAM techniques.
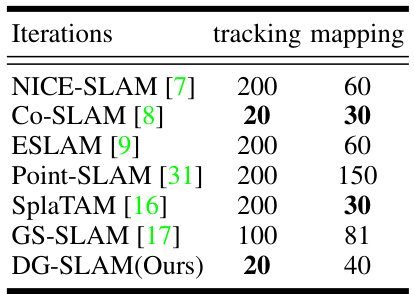
This table compares the number of iterations used for tracking and mapping by various SLAM methods on the TUM dataset. It shows that DG-SLAM uses significantly fewer iterations than most other methods, suggesting higher efficiency.

This table presents the results of an ablation study conducted on the BONN dataset to evaluate the impact of different components of the proposed DG-SLAM system on the Absolute Trajectory Error (ATE) and its standard deviation (STD). The rows show the performance when removing key aspects of the system (adaptive point adding, adaptive point pruning, depth warping, semantic segmentation, and fine camera tracking). The final row shows the performance of the complete DG-SLAM system, highlighting the individual contributions of each component.

This table compares the average run time of different SLAM systems on the TUM f3/w_s sequence. The run time is divided into tracking and mapping time, and the average run time is also shown. The results show that DG-SLAM achieves faster tracking time than other methods, but has a slower mapping time.
Full paper#