↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs), while showing impressive performance in various reasoning tasks, often struggle with abstract reasoning—applying general principles to specific situations. This limitation raises questions about their true understanding versus memorization. The current methods, like chain-of-thought prompting, lack the controlled step-by-step guidance necessary for effective learning.
To address this, the researchers developed a novel learning paradigm, “Meaningful Learning,” coupled with a new abstract reasoning dataset (AbsR). AbsR contains generic facts with guided explanations, enabling a more effective learning process. Meaningful Learning uses K-examples and R-examples to train LLMs to implicitly learn and apply generic facts like humans. The results demonstrate that this approach substantially enhances LLMs’ abstract reasoning capabilities, surpassing existing methods on multiple benchmarks and suggesting a more nuanced understanding of generic facts.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a critical gap in large language model (LLM) research: the ability to perform abstract reasoning. By introducing a novel learning paradigm and dataset, it offers a significant contribution to improving LLMs’ higher-order thinking capabilities, thereby advancing the field and opening new avenues for research. This work is particularly timely given the increasing interest in LLMs’ reasoning skills and their potential applications in diverse domains.
Visual Insights#

This figure compares how humans and large language models (LLMs) respond to two simple questions that share a common underlying generic fact: ‘Acid is corrosive’. The first question is about adding rock to hydrochloric acid, and the second is about acid touching human skin. Humans correctly answer both questions, demonstrating an understanding of the generic fact and its application to different scenarios. LLMs, however, struggle to consistently apply this generic fact, highlighting a potential weakness in their ability to abstract and reason.
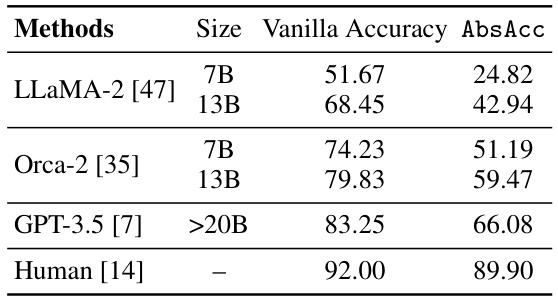
This table presents the vanilla accuracy and abstract reasoning accuracy (AbsAcc) for several large language models (LLMs) and humans on the e-CARE dataset. Vanilla accuracy represents the overall accuracy on the dataset, while AbsAcc measures the ability of the models to abstract and apply generic facts to answer questions consistently. The significant difference between the vanilla accuracy and AbsAcc for LLMs highlights their limitations in abstract reasoning compared to humans.
In-depth insights#
Generic Fact Impact#
The concept of ‘Generic Fact Impact’ in the context of a research paper likely explores how readily and effectively large language models (LLMs) utilize general knowledge to enhance reasoning abilities. A key question is whether LLMs truly understand and apply generic facts or simply memorize associations. The impact assessment would investigate if providing generic facts improves the LLM’s performance on abstract reasoning tasks, particularly in scenarios demanding the transfer of knowledge across diverse situations. The analysis would likely compare LLM performance with and without generic facts, potentially measuring accuracy and evaluating the sophistication of reasoning employed. Significant findings could demonstrate LLMs’ capacity to learn and abstract from generic facts, thus advancing our comprehension of LLMs’ cognitive capabilities. Conversely, limited improvements might suggest LLMs rely heavily on pattern recognition rather than true conceptual understanding. This analysis holds importance for the broader AI community, indicating whether current LLMs genuinely reason like humans or primarily perform advanced pattern matching.
MeanLearn Approach#
The MeanLearn approach, designed to enhance abstract reasoning in LLMs, is a unique paradigm that leverages generic facts and their guided explanations. Unlike traditional chain-of-thought methods, it aims for implicit knowledge learning, teaching LLMs to subconsciously utilize generic facts rather than relying on explicit, step-by-step reasoning. This is achieved by a two-pronged approach: a tailored dataset (AbsR) provides examples coupled with fact-guided explanations, and the MeanLearn training paradigm facilitates the implicit learning of these patterns. The results demonstrate a significant improvement in both general reasoning and, critically, abstract reasoning capabilities, showcasing the effectiveness of this nuanced approach. A key strength lies in its ability to move LLMs beyond simple memorization towards a more nuanced understanding and application of generic facts.
AbsR Dataset#
The AbsR dataset, central to enhancing abstract reasoning in LLMs, is a thoughtfully constructed resource addressing a crucial limitation in current models. Its design directly tackles the challenge of enabling LLMs to generalize from generic facts to diverse scenarios, moving beyond rote memorization. The dataset includes not just generic facts, but also carefully crafted question-answer pairs with explanations that explicitly link the answer to the provided generic fact. This guided approach facilitates meaningful learning, enabling the model to implicitly grasp the underlying principles rather than simply memorizing isolated examples. This methodology of including explanations represents a significant departure from existing approaches and aims to bridge the gap between LLM performance and human-like abstract reasoning abilities. The meticulous construction of AbsR, including the human evaluation to ensure both diversity and quality, highlights a commitment to creating a robust benchmark dataset that will likely advance research and understanding in this field.
Benchmark Results#
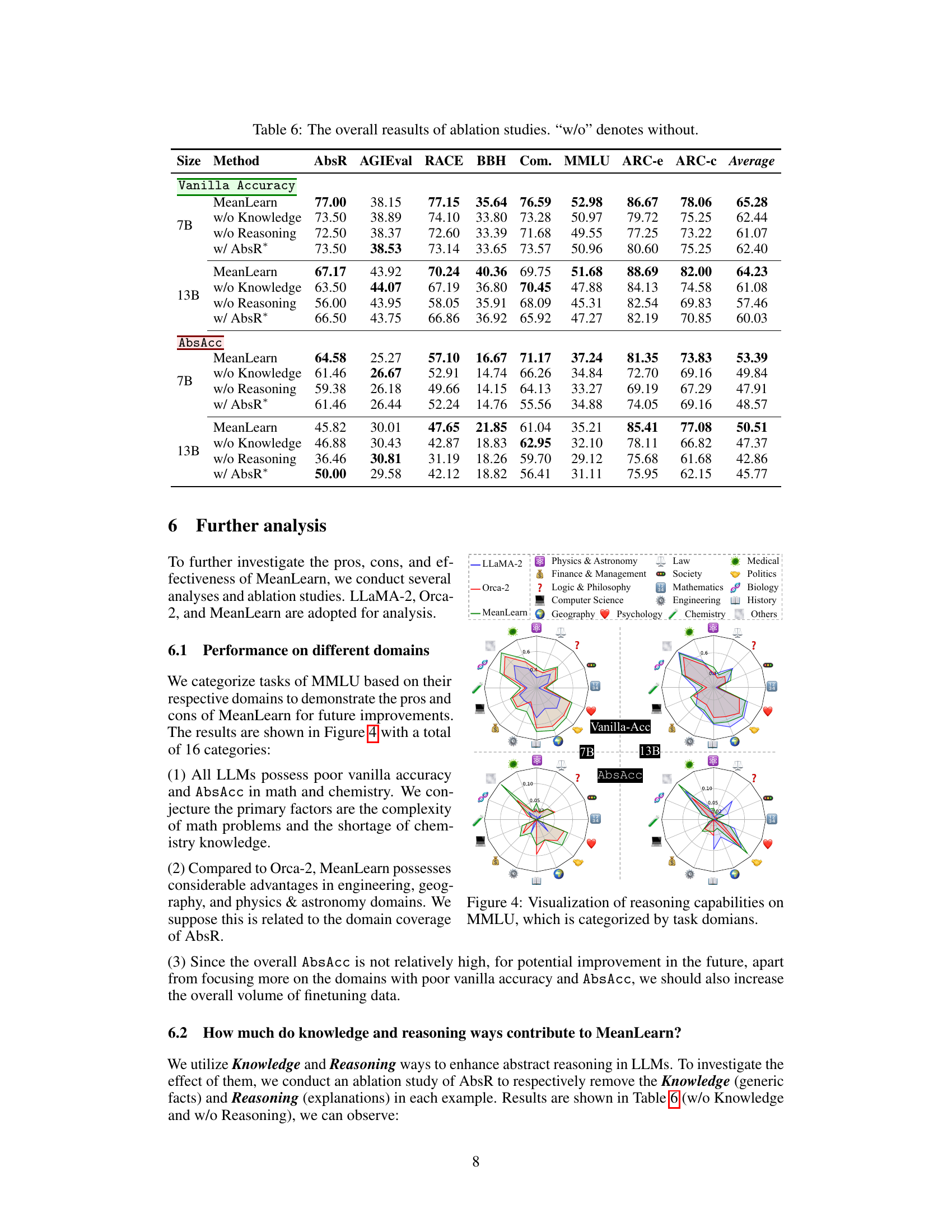
A dedicated ‘Benchmark Results’ section would ideally present a multifaceted analysis comparing the model’s performance against established baselines across various reasoning tasks. Quantitative metrics, such as accuracy, precision, recall, and F1-score, should be reported for both general and abstract reasoning benchmarks. Statistical significance testing is crucial to demonstrate the reliability of any performance gains. The results should be broken down by task type to identify areas of strength and weakness. A thoughtful discussion interpreting the results is necessary, considering the limitations of the benchmarks and exploring potential explanations for observed trends. Visualizations, such as bar charts or radar plots, can effectively convey the model’s performance across multiple benchmarks and facilitate comparison. Furthermore, the discussion should address any unexpected or noteworthy findings and explain the significance of the results in the context of the broader research goals.
Future Research#
Future research directions stemming from this work on enhancing abstract reasoning in LLMs could explore several promising avenues. Expanding the AbsR dataset with more diverse generic facts and complex reasoning scenarios is crucial. This would allow for a more robust evaluation of models and a more nuanced understanding of their abstract reasoning capabilities. Investigating alternative learning paradigms beyond MeanLearn, perhaps incorporating techniques from cognitive psychology or incorporating external knowledge sources, could significantly improve LLM performance. A thorough investigation into the interplay between model size and abstract reasoning ability is warranted. Does scaling alone sufficiently improve abstract reasoning, or are architectural modifications needed? Finally, it would be valuable to analyze the generalizability of these findings to other LLM architectures beyond the LLaMA series to determine the universality of this approach. Addressing these points would enhance the field’s understanding and unlock significant advancements in the development of truly intelligent AI systems.
More visual insights#
More on figures

This figure illustrates the calculation of the abstract reasoning accuracy (AbsAcc) metric. It shows three generic facts (r1, r2, r3), each supporting multiple examples (s1, s2, s3,…). For each example, the ‘Label’ indicates the correct answer, and ‘Prediction’ shows the model’s prediction. A green checkmark signifies a correct prediction, and a red cross indicates an incorrect prediction. The ‘Vanilla’ accuracy is the overall accuracy calculated considering all examples, while ‘AbsAcc’ focuses only on whether the model correctly predicts all examples for a given generic fact. It highlights that AbsAcc offers a more nuanced assessment of abstract reasoning ability than vanilla accuracy.

This figure shows a comparison of how humans and LLMs respond to questions that rely on a shared generic fact. Panel (a) demonstrates human reasoning, illustrating the consistent application of the generic fact (‘acid is corrosive’) to different scenarios (adding rock to acid, acid touching skin). In contrast, panel (b) highlights the inconsistent responses of LLMs, suggesting a deficit in abstract reasoning abilities. The figure visually represents the core problem addressed in the paper: LLMs struggle to abstract and apply generic facts consistently, unlike humans.

This radar chart visualizes the performance of different LLMs (LLaMA-2, Orca-2, and MeanLearn) across various sub-domains of the MMLU benchmark. The chart is split into two main sections: Vanilla Accuracy and Abstract Reasoning Accuracy (AbsAcc). Each section contains two charts, one for 7B parameter models and another for 13B parameter models. Each chart shows the performance of each LLM in various domains (Physics & Astronomy, Law, Medical, Finance & Management, Society, Politics, Logic & Philosophy, Mathematics, Biology, Computer Science, Engineering, History, Geography, Psychology, and Chemistry). The chart allows for comparison of both general reasoning ability and abstract reasoning skills of LLMs across different model sizes and domains.

This figure compares how humans and large language models (LLMs) respond to two questions that rely on the same underlying generic fact. Panel (a) shows that humans consistently and correctly use the generic fact to answer both questions. Panel (b) shows that LLMs fail to do this consistently, highlighting a shortcoming in their abstract reasoning abilities.

This figure shows a comparison of how humans and LLMs respond to two questions that rely on the same generic fact. Panel (a) illustrates human reasoning, showing consistent and accurate deductions based on understanding the underlying principle. Panel (b) shows LLM responses, highlighting inconsistencies and a lack of flexible application of the generic fact, suggesting a deficit in abstract reasoning ability.

This figure uses two subfigures to compare how humans and large language models (LLMs) respond to questions that are based on the same generic fact. Subfigure (a) shows the human responses, demonstrating their ability to apply the generic fact consistently and accurately to different questions. In contrast, subfigure (b) shows the LLM’s responses, highlighting their inconsistent and less accurate application of the generic fact. This visual comparison demonstrates the gap between human abstract reasoning capabilities and those of current LLMs.

This figure compares how humans and LLMs respond to two questions based on a shared generic fact. Panel (a) shows the human responses, correctly identifying that both adding rock to acid and acid touching skin cause a corrosive effect due to the generic fact that ‘acid is corrosive’. Panel (b) illustrates LLM responses which reveal inconsistencies in their ability to apply this generic fact across different scenarios, highlighting a deficiency in abstract reasoning.

This figure shows a comparison of how humans and LLMs respond to two questions that share a common underlying generic fact. Panel (a) illustrates the human responses, demonstrating consistent and accurate answers based on understanding the general principle. Panel (b) depicts the LLM responses, showcasing a lack of consistent application of the generic fact and revealing a gap in abstract reasoning abilities. The difference highlights the key challenge that the paper addresses: teaching LLMs to effectively utilize generic facts for abstract reasoning.

This figure compares how humans and large language models (LLMs) respond to two questions that rely on the same generic fact (‘acid is corrosive’). Panel (a) shows the human responses, demonstrating accurate and consistent application of the generic fact to both scenarios (rock in acid, acid on skin). Panel (b) illustrates that LLMs often fail to consistently apply the generic fact, showcasing a deficiency in abstract reasoning abilities. The responses show that while LLMs can sometimes answer correctly, they struggle to generalize and apply the underlying principle across different situations.
More on tables
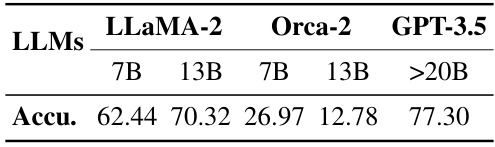
This table presents the accuracy of generic fact probing for different LLMs (LLaMA-2, Orca-2, and GPT-3.5) with varying model sizes. The accuracy reflects the percentage of generic facts that the LLMs correctly identified as known to them. It provides insights into the extent of generic fact mastery by different LLMs.
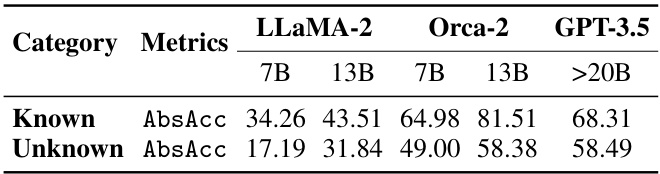
This table presents the abstract reasoning accuracy (AbsAcc) categorized by whether the LLMs (LLaMA-2, Orca-2, GPT-3.5) already know the generic facts. The ‘Known’ category shows AbsAcc when the LLM has prior knowledge of the generic fact, while ‘Unknown’ represents cases where the generic fact is new to the LLM. The results are further broken down by the model size (7B, 13B, >20B). This allows for a nuanced understanding of how prior knowledge of generic facts influences the ability of LLMs to perform abstract reasoning.

This table shows the number of examples, questions, and generic facts in the AbsR dataset. The dataset is split into training and testing sets. The training set contains 18,020 examples, 9,010 questions, and 4,613 generic facts. The test set contains 200 examples, 200 questions, and 104 generic facts.
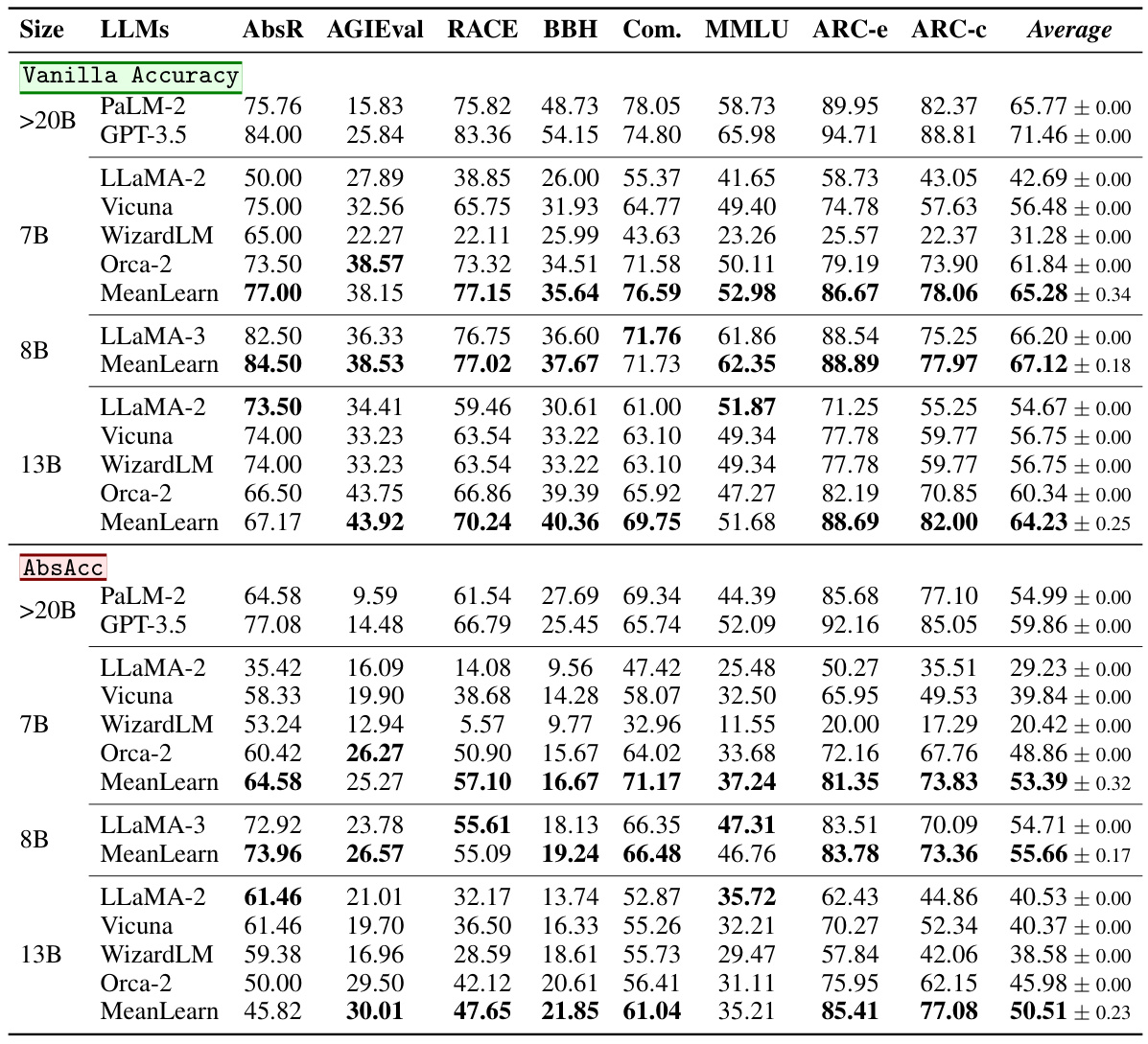
This table presents the vanilla accuracy and abstract reasoning accuracy (AbsAcc) for various large language models (LLMs) across multiple benchmarks. The LLMs include different sizes and architectures and encompass both open-access and limited-access models. Benchmarks cover diverse reasoning and language understanding tasks. The results show the performance of each model in terms of vanilla accuracy (overall accuracy) and AbsAcc (abstract reasoning accuracy) across each benchmark, highlighting the relative strengths and weaknesses of different approaches.
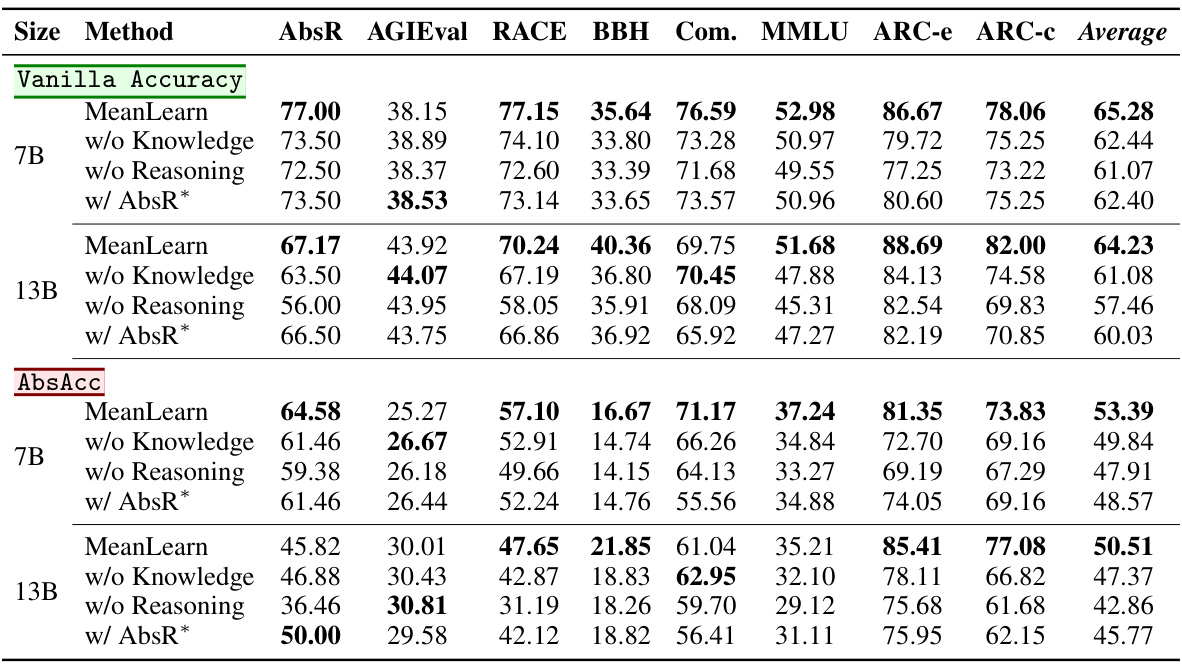
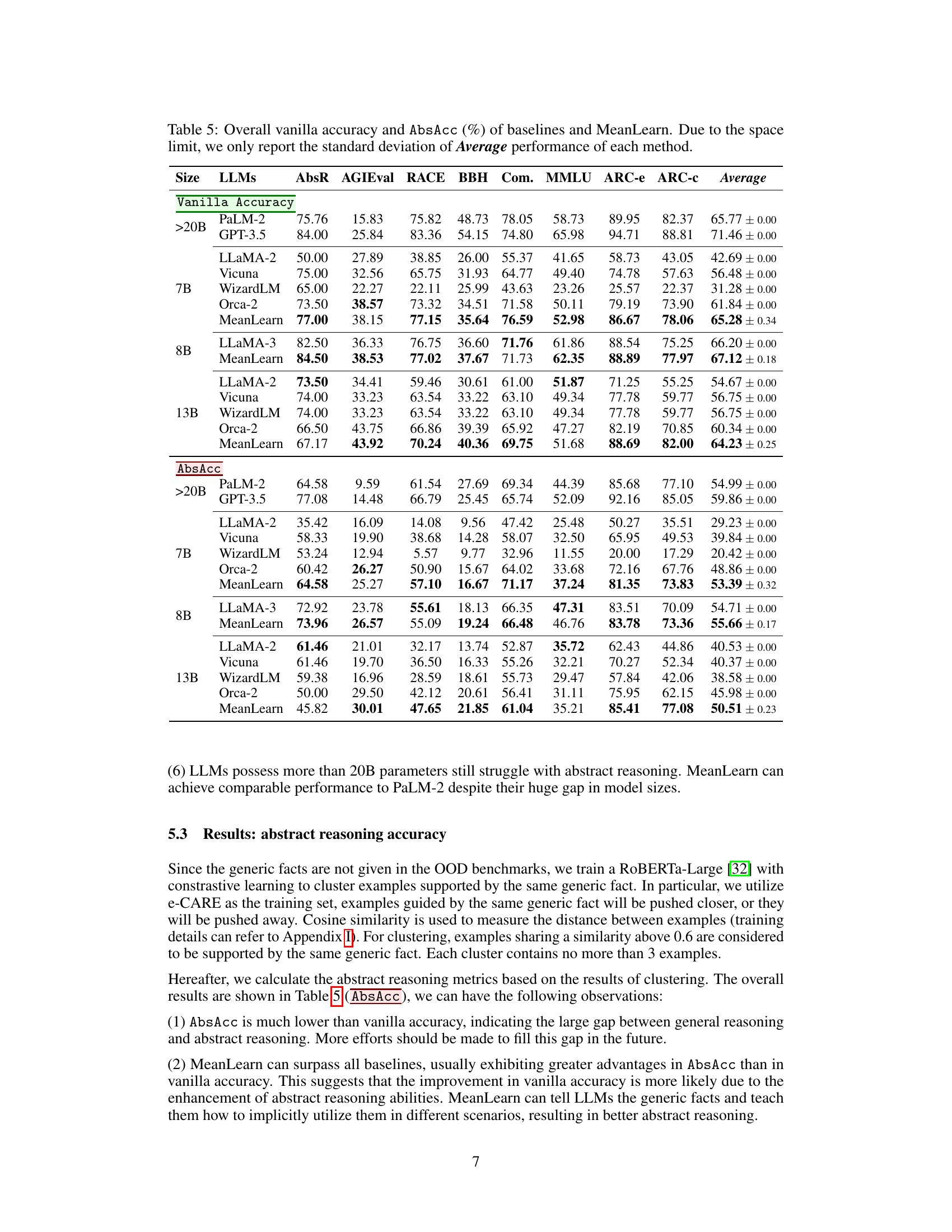
This table presents the vanilla accuracy and abstract reasoning accuracy (AbsAcc) achieved by various Large Language Models (LLMs) across multiple benchmarks. The LLMs are categorized by size (7B, 8B, 13B, >20B parameters), and the results showcase the performance of both standard LLMs and the MeanLearn approach. The table highlights the improvements offered by the MeanLearn method, particularly regarding the substantial gap often observed between general reasoning and abstract reasoning capabilities in large language models.
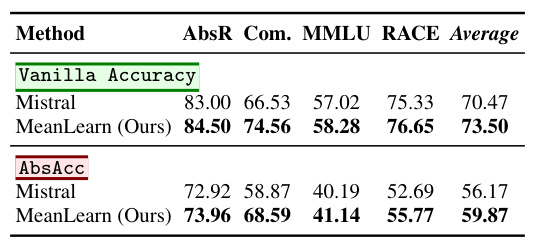
This table presents the performance comparison between Mistral and MeanLearn (trained on Mistral) on various benchmarks including AbsR, Com, MMLU, and RACE. Both vanilla accuracy and abstract reasoning accuracy (AbsAcc) are reported, showcasing the improvement achieved by MeanLearn across different metrics.

This table presents the results of evaluating various LLMs on mathematical reasoning tasks from the MMLU benchmark. It compares the vanilla accuracy (correct answers without considering abstract reasoning) and abstract reasoning accuracy (AbsAcc, a metric focusing on the ability to apply general principles to different scenarios) of Orca-2, Mistral, and MeanLearn models of different sizes (7B parameter count). The table shows performance across five specific mathematical reasoning sub-tasks (AA, CM, EM, HSS, HSM) within MMLU and the average performance across all five sub-tasks. The results highlight the improvements achieved using the MeanLearn approach in both vanilla accuracy and especially abstract reasoning accuracy.

This table presents the baseline performance of various LLMs on the e-CARE dataset. It compares the standard accuracy (Vanilla Accuracy) with a newly defined metric, AbsAcc (Abstract Reasoning Accuracy), which assesses the model’s ability to abstract and apply generic facts to answer questions consistently. The size of each LLM is also shown. Human performance is included for comparison.

This table presents the accuracy of generic fact probing for different LLMs (LLaMA-2, Orca-2, and GPT-3.5) with varying model sizes (7B, 13B, and >20B parameters). The accuracy reflects the models’ ability to correctly identify whether they possess knowledge of specific general facts. Higher accuracy indicates a stronger grasp of general knowledge.
This table presents the vanilla accuracy and abstract reasoning accuracy (AbsAcc) achieved by various LLMs (LLaMA-2, Orca-2, GPT-3.5) and humans on the e-CARE dataset. Vanilla accuracy represents the overall accuracy of the models on the questions, while AbsAcc measures the ability of the models to abstract and apply a generic fact to answer multiple related questions consistently. The table highlights a significant difference in performance between LLMs and humans, demonstrating the challenge LLMs face with abstract reasoning.
Full paper#