↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional anomaly detection (AD) heavily relies on extensive normal data. Recent advancements leverage pre-trained models for few-shot AD, but accuracy remains limited by direct feature comparison between query and normal images. This direct comparison neglects subtle differences and hinders adaptation to complex domains.
This paper introduces ‘anomaly personalization,’ using a customized generation model to transform query images into anomaly-free counterparts, closely aligning them with the normal data manifold. A novel triplet contrastive inference strategy enhances robustness through comprehensive comparison between query, personalized, and anomaly-free data. Experiments on 11 datasets demonstrate the superior performance and flexible transferability of the proposed method compared to state-of-the-art AD techniques. The generated anomaly-free data significantly improves other AD methods’ accuracy.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses limitations in existing few-shot anomaly detection methods by introducing a novel anomaly personalization technique. This significantly improves accuracy and robustness, particularly in complex domains. The proposed method also exhibits flexibility, enhancing other AD methods. Its comprehensive evaluation across multiple datasets demonstrates practical value and opens new avenues for personalized anomaly detection research.
Visual Insights#
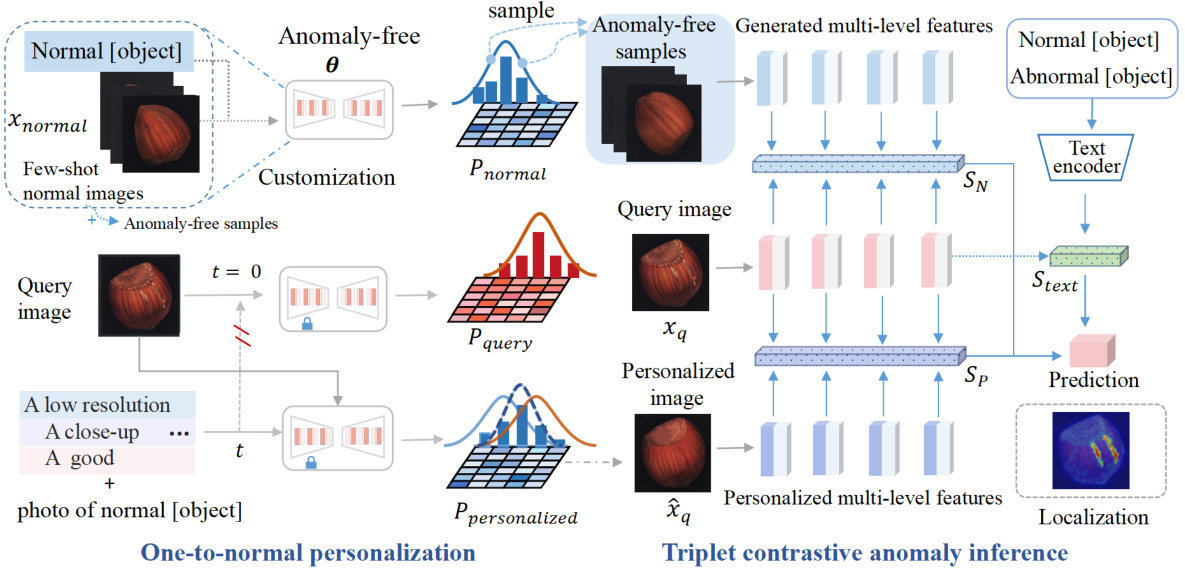
This figure illustrates the proposed anomaly personalization method’s workflow. It starts by using few-shot normal images to customize a diffusion model that generates anomaly-free images. Then, a query image undergoes a one-to-normal personalization, transforming it to resemble a normal image using the customized model. Finally, a triplet contrastive anomaly inference compares the query image, its personalized version, and a pool of anomaly-free images (and text prompts) to obtain a final anomaly score and localization map. The three comparisons provide complementary perspectives.

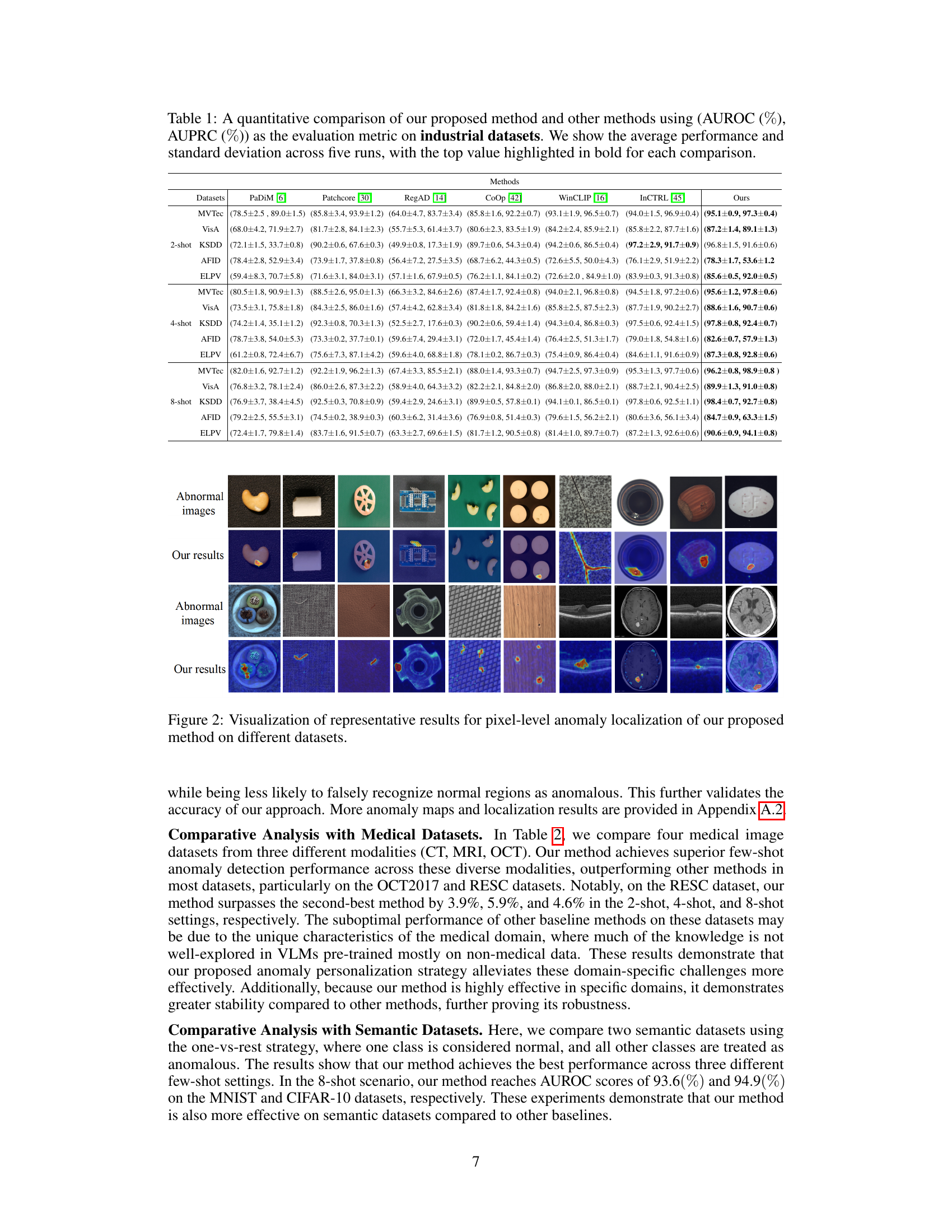
This table presents a quantitative comparison of the proposed anomaly detection method against other state-of-the-art methods on five industrial datasets. The evaluation metrics used are AUROC and AUPRC, calculated as the average across five runs, with standard deviation included. The best-performing method for each dataset and experimental setting (2-shot, 4-shot, 8-shot) is highlighted in bold.
In-depth insights#
Anomaly Personalization#
The concept of “Anomaly Personalization” in anomaly detection is a novel approach that focuses on adapting the analysis to the specific characteristics of each query image. Instead of generic comparisons with a pool of normal samples, this method aims to create a personalized, one-to-one comparison. This involves transforming the query image into a representation that is more closely aligned with the normal manifold, effectively generating a personalized version of the query image, free from anomalies. This process of personalization enhances precision by facilitating a more nuanced feature-level comparison. The method’s strength lies in its ability to address limitations of direct feature comparison techniques, improving robustness and accuracy, particularly in complex domains with subtle anomaly patterns. The addition of triplet contrastive anomaly inference further enhances the stability of predictions through the comprehensive comparison of the personalized image with both normal examples and text prompts, representing diverse yet complementary sources of information.
Triplet Inference#
The proposed “Triplet Inference” strategy is a key innovation enhancing the robustness and accuracy of anomaly detection. By comparing a query image with its personalized, anomaly-free version, and relevant text prompts, it leverages a multifaceted approach. This contrasts with simpler methods that rely solely on direct feature comparisons, which are susceptible to noise and instability. The triplet comparison enables a more comprehensive analysis capturing diverse aspects of the anomaly, thereby improving the model’s reliability and reducing the impact of minor variations. This method exhibits strong generalizability and performs well across various domains and datasets. The integration of text prompts adds another layer of semantic understanding further enhancing the system’s accuracy and ability to handle complex scenarios.
Diffusion Model Use#
The utilization of diffusion models in the research paper is a crucial aspect warranting in-depth analysis. These models are leveraged for the generation of anomaly-free images, a technique vital to the proposed anomaly personalization method. This innovative approach contrasts with existing methods that directly compare query images to normal samples. By generating personalized, anomaly-free versions of query images, the method facilitates a more precise comparison, enhancing the accuracy of anomaly detection. The customization of the diffusion model itself is also noteworthy. Training is performed on a limited dataset of normal images, augmented through various techniques to maximize diversity and representativeness. This customization ensures the generated images closely align with the normal manifold for accurate anomaly identification. Overall, the choice of diffusion models for image generation is a strategically important element that significantly improves the precision and efficiency of few-shot anomaly detection.
Few-Shot AD Advance#
Few-shot anomaly detection (AD) has seen significant advancements, largely due to the integration of large pre-trained vision-language models. Early methods relied heavily on unsupervised learning from extensive normal data, limiting their effectiveness in scenarios with limited labeled examples. The advent of models like CLIP has enabled few-shot learning capabilities, allowing for more accurate anomaly detection with fewer training samples. However, direct feature comparisons between query images and a small set of normal images still present challenges, often leading to imprecision and difficulty in scaling to complex domains. Current research focuses on refining these approaches, exploring more sophisticated techniques such as anomaly personalization and triplet contrastive anomaly inference to enhance both accuracy and robustness. These improvements aim to create more stable and generalized methods capable of handling diverse anomaly detection tasks efficiently.
Method Limitations#
A hypothetical ‘Method Limitations’ section for a computer vision research paper might begin by acknowledging the reliance on large pre-trained models. This raises concerns about bias and fairness, as the model’s performance is directly linked to the data it was trained on, and this data might not represent all populations equally. The method’s effectiveness in few-shot scenarios, while promising, should be carefully contextualized; its generalizability across diverse, real-world datasets remains to be fully validated. Furthermore, computational cost is a crucial limitation, particularly concerning the personalization step, which could hinder the practical application, especially with resource-constrained scenarios. Finally, the paper should discuss the need for further research to explore the limits of the model’s personalization abilities, especially regarding robustness to noisy or incomplete data and the potential for adversarial attacks exploiting the personalized nature of the approach. Ethical implications surrounding data usage and model deployment are essential to address comprehensively.
More visual insights#
More on figures

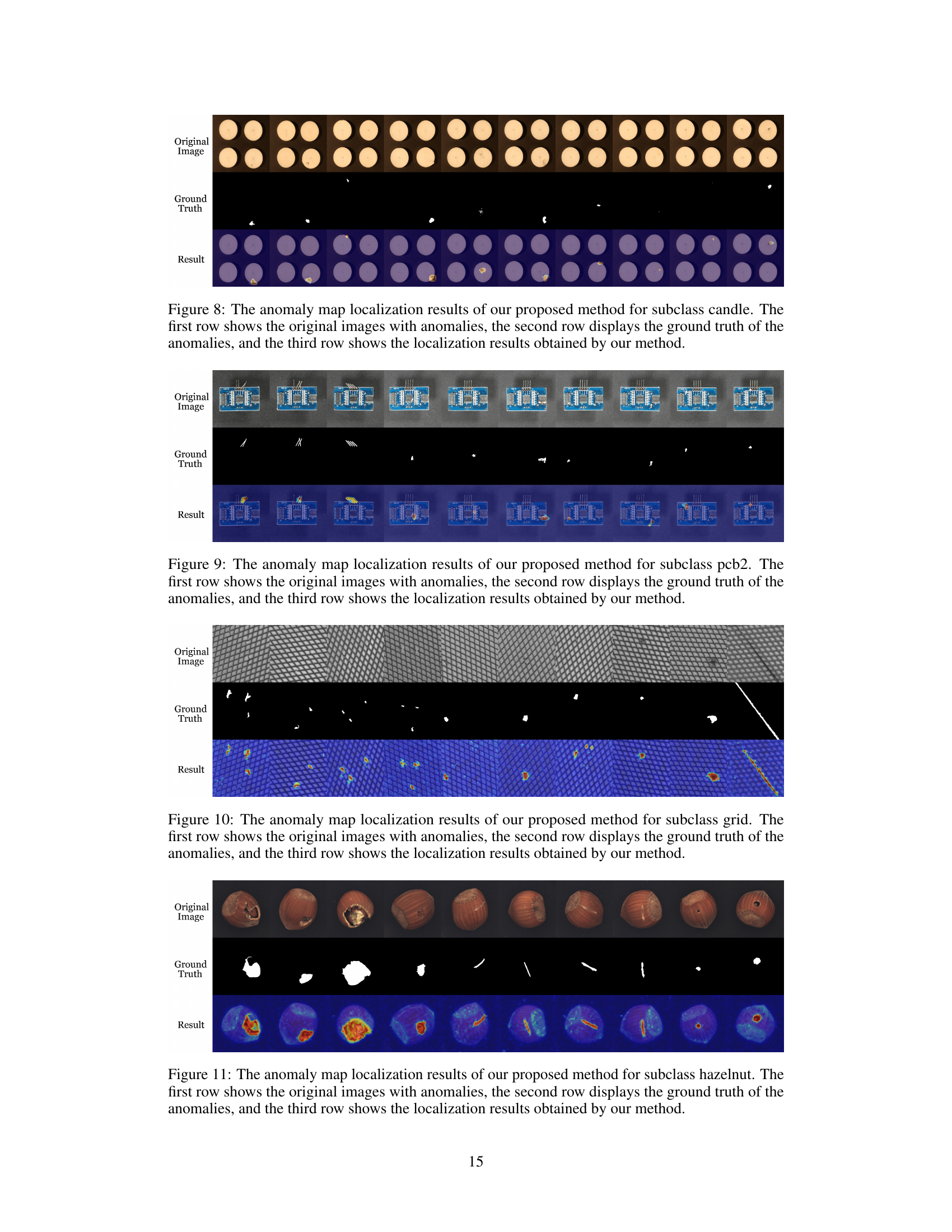
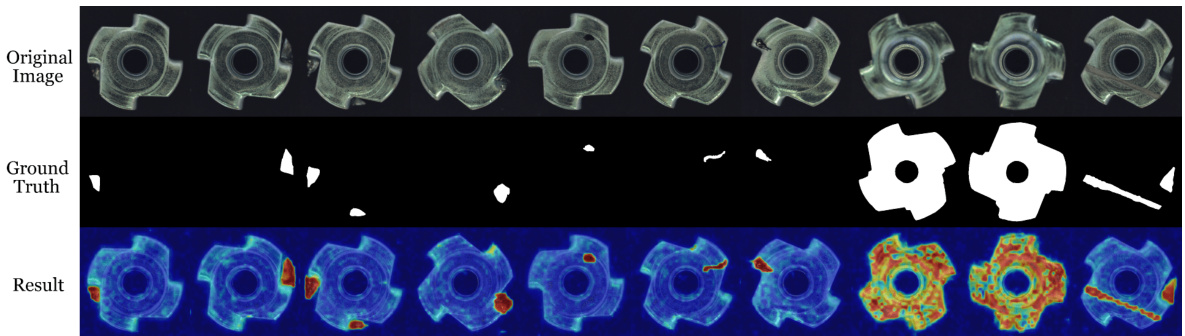
This figure visualizes the results of pixel-level anomaly localization using the proposed method. It presents a comparison between abnormal images and the anomaly localization maps generated by the model. The results are shown for multiple datasets spanning diverse domains, including industrial and medical imagery. Each pair of images shows an abnormal image (left) alongside the corresponding heatmap generated by the model highlighting the detected anomalies (right). The heatmaps effectively pinpoint the locations of abnormalities within the images.
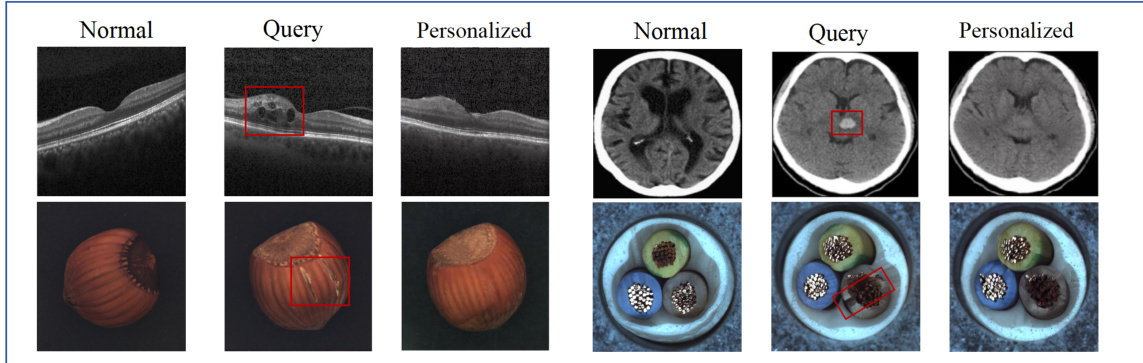
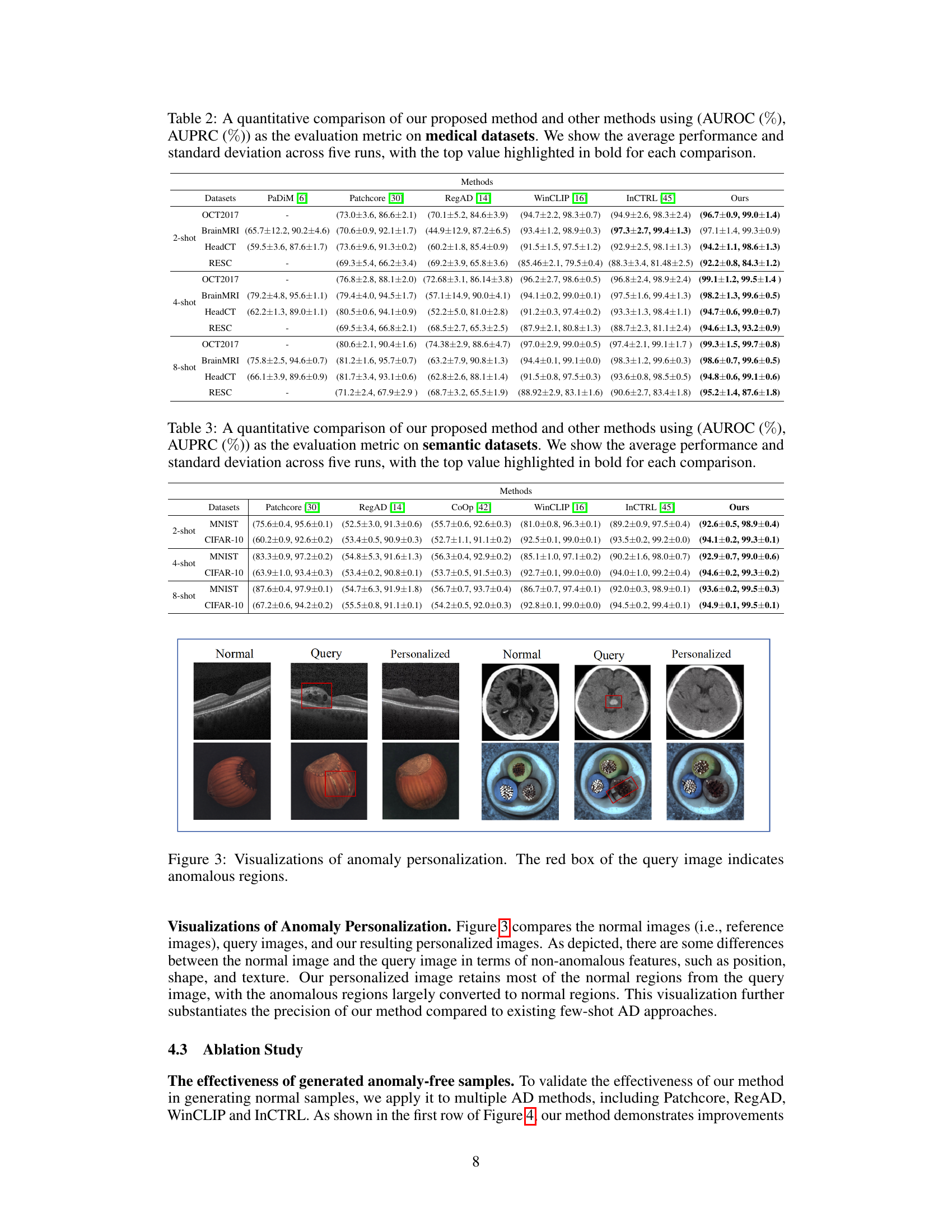
This figure shows examples of anomaly personalization in three different domains. Each row represents a different dataset and shows three images for each sample: the original normal image, a query image with anomalies (red box), and the personalized image generated by the proposed method. The figure demonstrates that the model successfully transforms the query image into a personalized version that is more similar to the normal distribution, reducing the impact of anomalies while preserving the original image characteristics.

This figure illustrates the proposed anomaly personalization approach for few-shot anomaly detection. It starts with customizing an anomaly-free diffusion model using few-shot normal images. The query image undergoes a one-to-one personalization transformation, aligning it with the normal manifold. A triplet contrastive anomaly inference then integrates comparisons of the query image, its personalized version, anomaly-free samples, and text prompts to generate a final anomaly score. The three inference processes (SN, SP, Stext) represent different comparison aspects.

This figure displays the pixel-level anomaly localization results of the proposed method on various datasets. It visually demonstrates the model’s ability to accurately pinpoint anomalous regions within images from diverse domains, highlighting its effectiveness in identifying subtle defects or irregularities. The figure is organized to show the original image with anomalies, the ground truth for the anomalies, and the results generated by the proposed method, allowing for a direct comparison of performance.

This figure illustrates the proposed anomaly personalization method which consists of three stages: 1) customizing an anomaly-free diffusion model using few-shot normal images; 2) performing one-to-normal personalization of the query image using the customized model to obtain a personalized image that aligns closely with the normal manifold; and 3) employing a triplet contrastive anomaly inference strategy to synthesize predictions from diverse perspectives (one-to-one personalized comparison, anomaly-free sample comparison, and text prompt comparison) for the final anomaly score. The figure highlights the flow of the process and the components involved in each stage.

This figure illustrates the proposed anomaly personalization method. It shows how few-shot normal images are used to train a customized anomaly-free diffusion model. This model then personalizes a query image, transforming it to align with the normal manifold. Finally, a triplet contrastive anomaly inference method combines results from comparing the query image, its personalized version, and a pool of anomaly-free samples, along with prompt information, to arrive at a final anomaly score.

This figure illustrates the three main stages of the proposed anomaly detection method: 1) An anomaly-free diffusion model is customized using few-shot normal images. 2) One-to-normal personalization transforms the query image into a normal-like version. 3) A triplet contrastive anomaly inference compares the query image, its personalized version, and anomaly-free samples with text prompts, combining their scores for the final anomaly prediction.

This figure illustrates the three main steps of the proposed anomaly personalization method: 1) Customizing an anomaly-free diffusion model using few-shot normal images. 2) Performing one-to-normal personalization of the query image to align it with the normal manifold. 3) Utilizing a triplet contrastive anomaly inference strategy that incorporates comparisons between the query image, personalized image, and anomaly-free samples to generate the final anomaly score.

This figure shows the overall architecture of the proposed anomaly personalization method. It consists of three main stages: 1) anomaly-free customized model generation using few-shot normal images, 2) one-to-normal personalization of the query image using the generated model, and 3) triplet contrastive anomaly inference by comparing the personalized image with anomaly-free samples and text prompts. The final anomaly score is obtained by integrating the results from these three comparisons.
This figure illustrates the proposed anomaly personalization method, which consists of three main stages: 1) customizing an anomaly-free diffusion model using few-shot normal images; 2) performing one-to-normal personalization of the query image to align it with the normal manifold; and 3) employing a triplet contrastive anomaly inference strategy to obtain the final anomaly score by integrating results from one-to-one personalized comparison, anomaly-free sample comparison, and text prompt comparison.

This figure illustrates the three main steps of the proposed anomaly detection method. First, an anomaly-free diffusion model is customized using few-shot normal images. Second, a query image is personalized by transforming it towards the normal manifold using this model. Finally, a triplet contrastive anomaly inference strategy combines anomaly scores from three sources: the personalized image, anomaly-free samples, and text prompts, generating the final anomaly score.

This figure shows the results of pixel-level anomaly localization using the proposed method on various datasets. It visually demonstrates the accuracy of the model in identifying anomalous regions within different types of images (industrial, medical, and semantic). Each row presents a series of images: the original image on the top row and the resulting anomaly map generated by the method on the bottom row. The anomaly maps highlight the detected anomalies with varying intensities, providing a visual representation of the model’s performance in localizing anomalies within the images. The comparison allows for a visual assessment of the algorithm’s effectiveness in various scenarios.

This figure visualizes the pixel-level anomaly localization results of the proposed method on several datasets. It demonstrates the effectiveness of the method in identifying and highlighting anomalous regions within images from various domains. The top row shows the original images containing anomalies, while the bottom row displays the anomaly maps generated by the proposed method, showcasing its ability to accurately pinpoint the location of anomalies.

This figure visualizes the process of anomaly personalization. It shows three columns of images: normal image, query image (with anomalies highlighted by red boxes), and personalized images. Each column consists of multiple examples to illustrate how the model transforms the query images into their corresponding normal-like images. The red boxes are used to locate the anomalies, helping readers to see how the method works on different image types.
More on tables
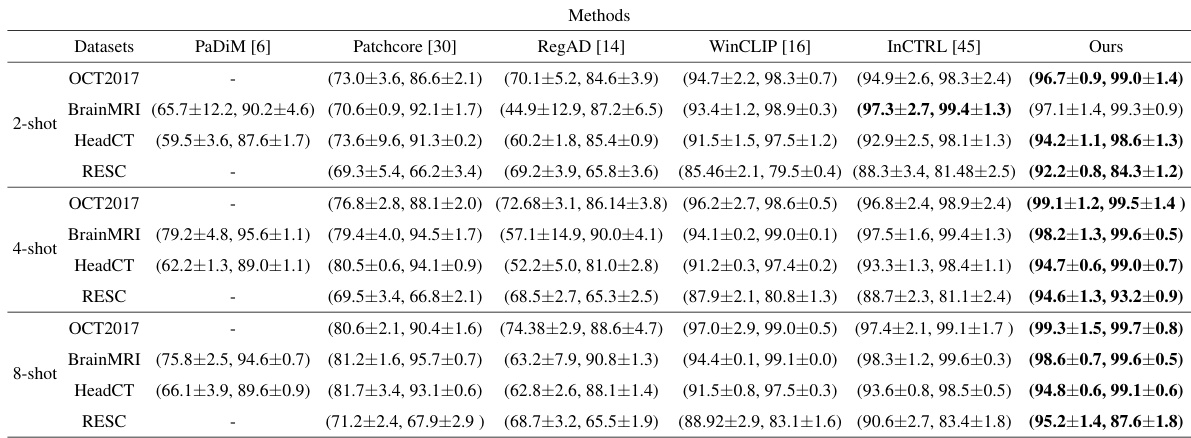
This table presents a quantitative comparison of the proposed anomaly detection method against several other methods on four medical image datasets. The evaluation metrics used are AUROC and AUPRC, and the results are averaged over five runs, with the best-performing method in each comparison highlighted in bold. The datasets used cover three different imaging modalities (CT, MRI, OCT) and various few-shot scenarios (2-shot, 4-shot, 8-shot).
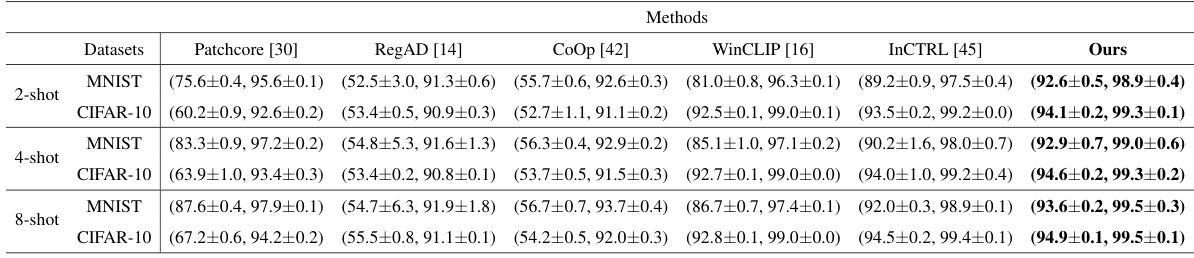
This table presents a quantitative comparison of the proposed anomaly detection method against several other methods across five industrial datasets. The metrics used are AUROC and AUPRC, calculated as averages across five runs for each method and dataset combination. Results are presented for 2-shot, 4-shot, and 8-shot settings, indicating the number of normal samples used for each evaluation.
This table presents a quantitative comparison of the proposed anomaly detection method against several other methods on five industrial datasets. The evaluation metrics used are AUROC and AUPRC, both calculated as averages across five runs. The best performing method for each dataset and shot setting (2-shot, 4-shot, 8-shot) is highlighted in bold.

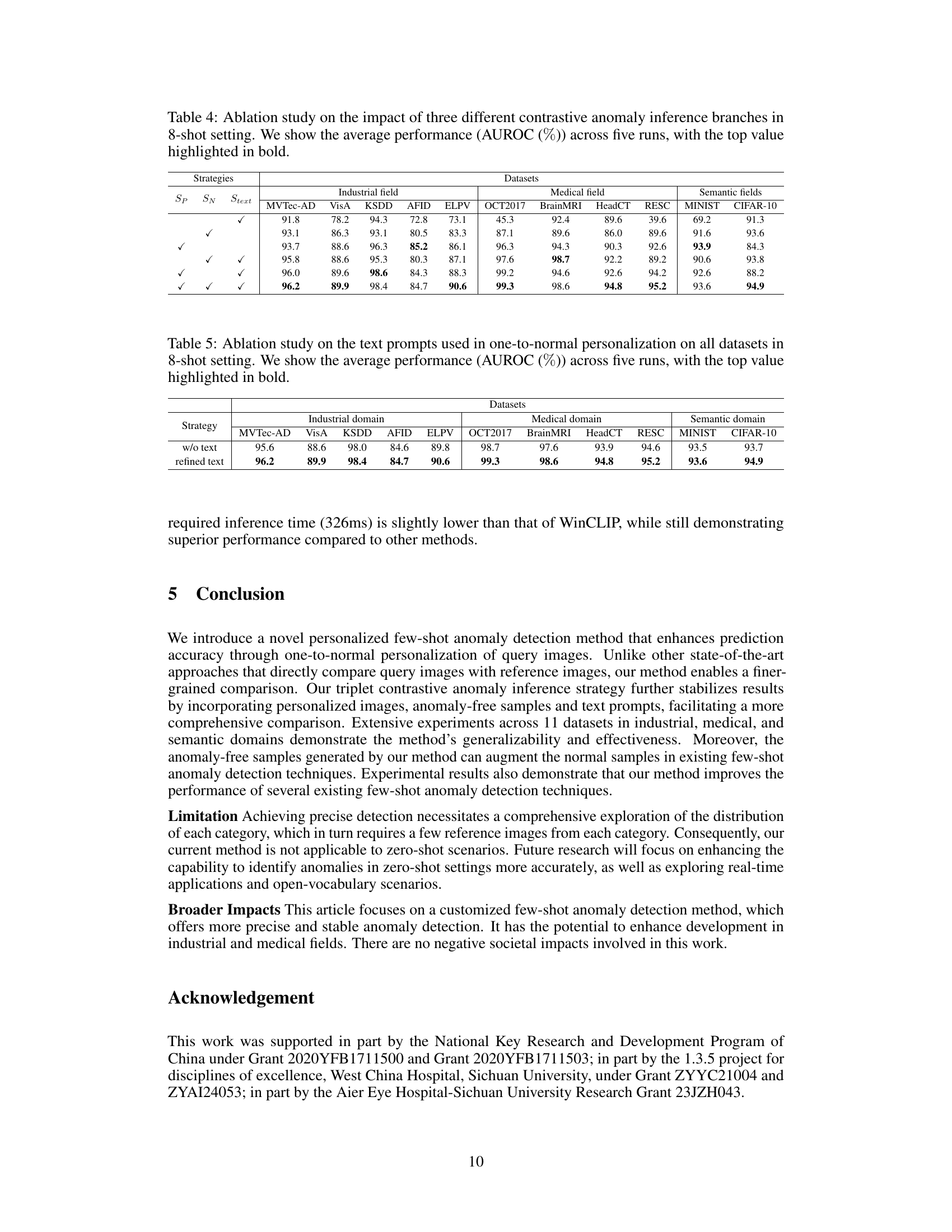
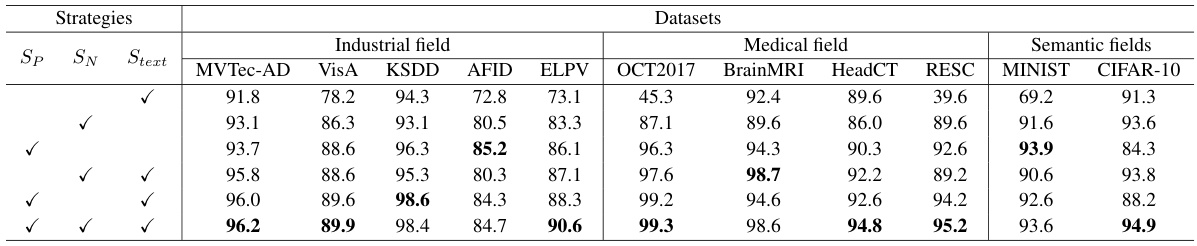
This table presents the results of an ablation study on the impact of using different text prompts in the one-to-normal personalization stage of the proposed anomaly detection method. It shows the AUROC scores across 11 datasets, categorized into industrial, medical and semantic domains, achieved with and without refined text prompts in the 8-shot setting. The goal is to evaluate the effectiveness of the carefully designed text prompts in improving the accuracy of the personalization step and the overall performance of the model.
Full paper#