↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional time series forecasting struggles with sudden disruptions and doesn’t effectively incorporate real-world events. This paper introduces a novel approach that leverages Large Language Models (LLMs) and Generative Agents to integrate news data into forecasting models. The method addresses the limitations of traditional methods by using LLMs to analyze news articles, filter out irrelevant information, and reason across both text and time series data, resulting in more accurate and robust predictions.
The core contribution is a unified framework that dynamically integrates news into time series forecasting. LLM agents are used to automatically select and analyze relevant news, enhancing the model’s responsiveness to real-world events. The framework demonstrates improvements in forecasting accuracy across diverse domains, suggesting a potential paradigm shift in how we approach time series forecasting.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in time series forecasting and NLP. It bridges the gap between traditional statistical methods and the potential of large language models (LLMs), opening new avenues for research by demonstrating how unstructured news data can significantly enhance forecasting accuracy. The methodology is innovative and offers a paradigm shift, providing a solid foundation for future work in integrating multi-modal data for improved prediction.
Visual Insights#

This figure illustrates the overall framework of the proposed method which integrates textual information into time series forecasting. It consists of five stages: 1) Information Retrieval: relevant news and supplementary information are retrieved from a database based on the prediction task; 2) Reasoning Agent: LLM-based agents filter and select relevant news for different forecasting horizons; 3) Prompt Integration for Data Preparation: selected news and contextual information are combined with time series data for data preparation; 4) LLM Finetune: an LLM is fine-tuned to predict time series based on the prepared data; 5) Evaluation Agent: discrepancies between predictions and ground truth trigger a review of news and data to refine the reasoning logic. This framework is an iterative process that continues until the final prediction is made.
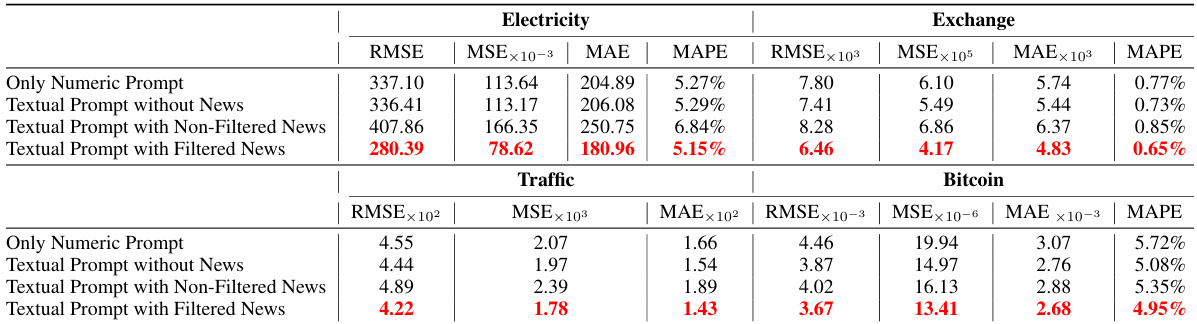
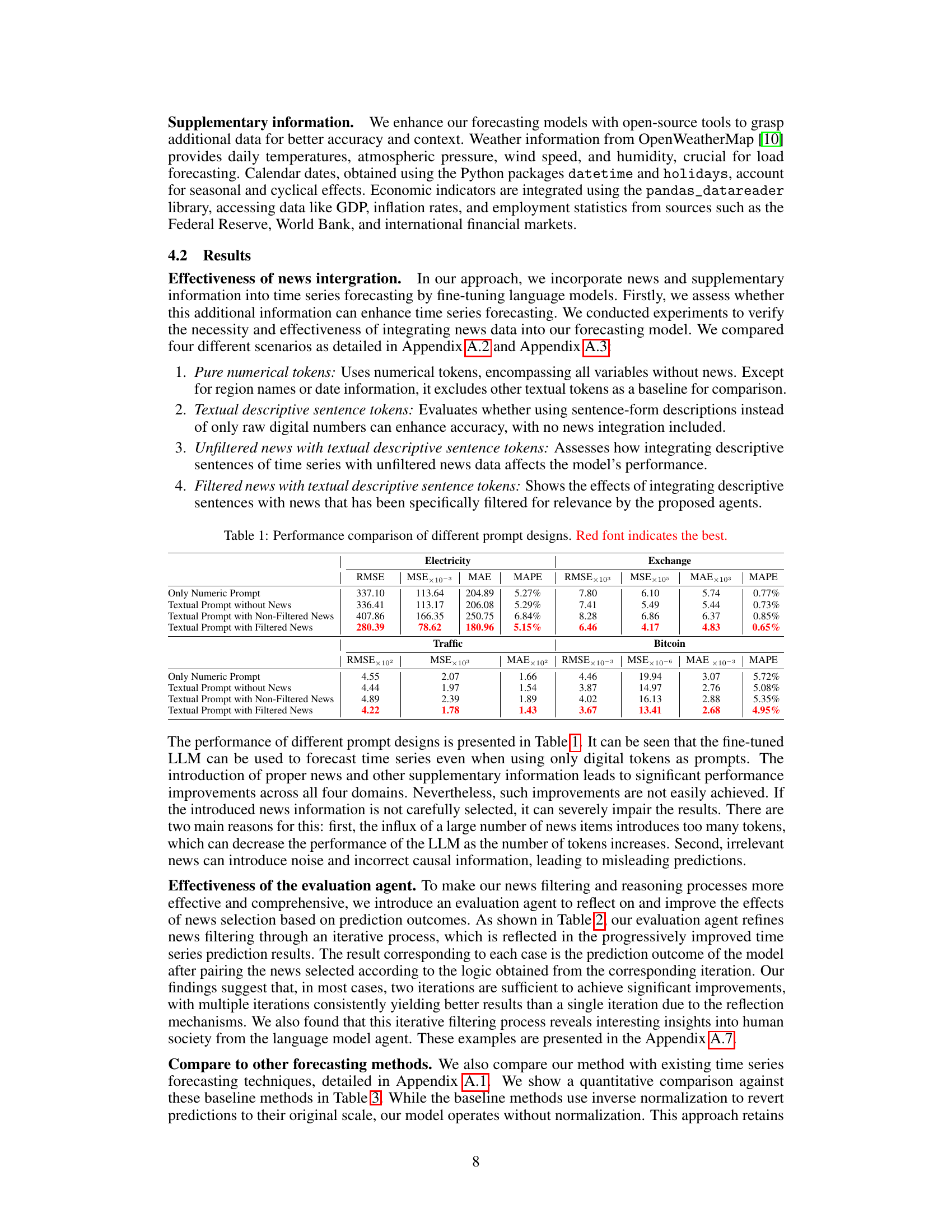
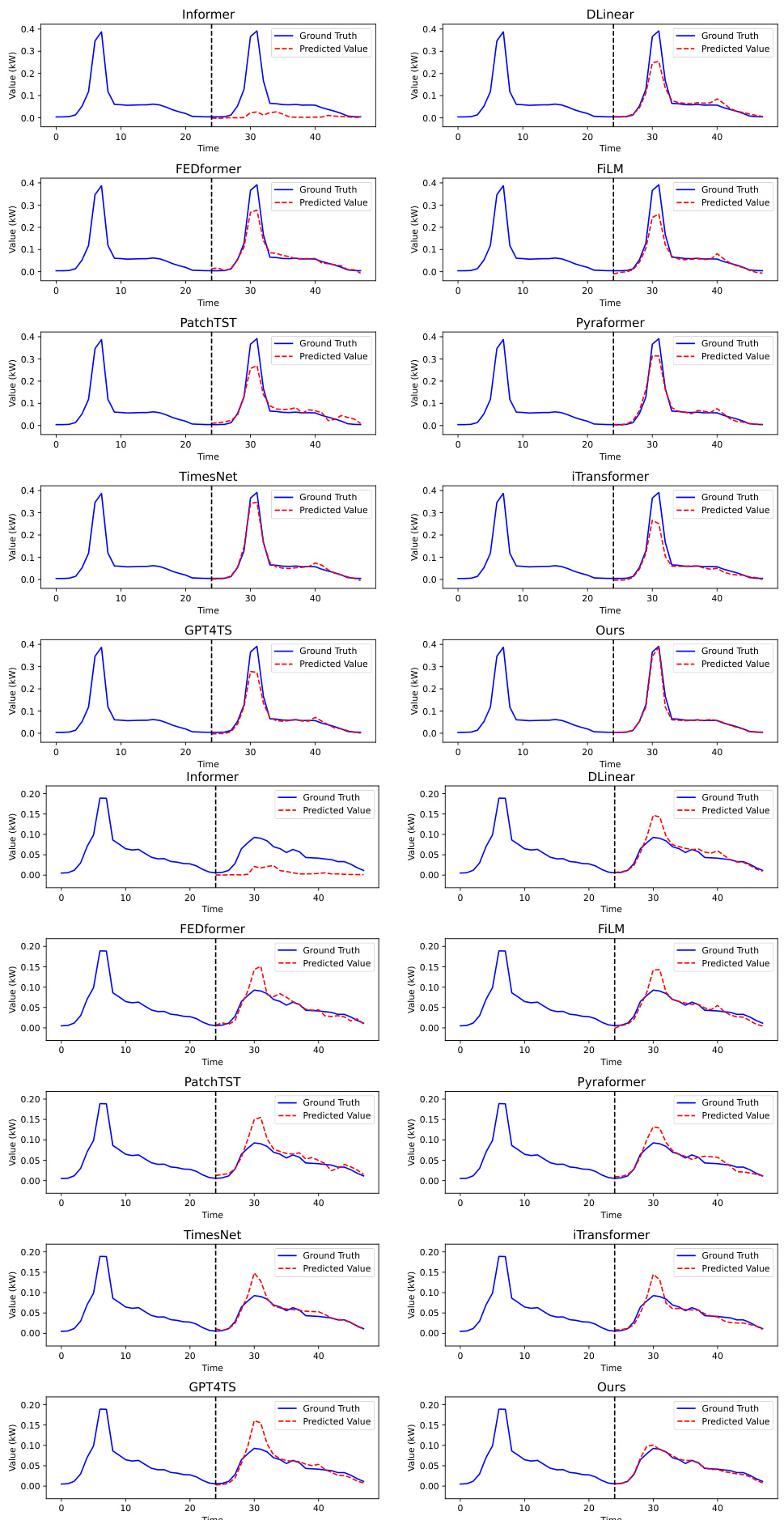
This table presents a comparison of the Mean Squared Error (MSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Squared Error (RMSE) for four different prompt designs across four different time series forecasting domains: Electricity, Exchange, Traffic, and Bitcoin. The four prompt designs are: 1) Using only numeric tokens; 2) Using textual descriptive sentence tokens without news; 3) Using textual descriptive sentence tokens with unfiltered news; and 4) Using textual descriptive sentence tokens with filtered news. The table allows for the comparison of the effects of adding textual information and the impact of news filtering on forecasting accuracy.
In-depth insights#
LLM-Event Fusion#
LLM-Event Fusion represents a novel approach to time series forecasting, integrating the power of large language models (LLMs) with real-world event data. LLMs provide the ability to contextualize numerical time series data with unstructured textual information from news articles, offering richer insights into the underlying dynamics. This fusion goes beyond simple keyword extraction, leveraging the advanced reasoning capabilities of LLMs to selectively filter relevant news and discern causal relationships between events and time series fluctuations. The iterative process of LLM-based analysis and reflection allows for dynamic refinement, adapting to changing conditions and improving forecasting accuracy. A key strength of this approach lies in its ability to handle complex, unexpected events that traditional forecasting methods often struggle to capture, enhancing the model’s responsiveness and reliability. The integration of external information significantly enhances the predictive power, particularly in domains influenced by human behavior and societal changes. However, challenges may arise from the need for effective news filtering techniques to avoid introducing noise or bias and rigorous evaluation to ensure accuracy and reliability.
Agent-Based Filtering#
Agent-based filtering, in the context of a research paper on time series forecasting enhanced by news data, presents a novel approach to handling the influx of unstructured information. Instead of relying on simple keyword matching or rule-based systems, an AI agent is employed to intelligently sift through and select relevant news articles. This approach is crucial because using all available news is computationally expensive and introduces noise into the model. The agent’s decision-making process is likely sophisticated, potentially incorporating elements of natural language processing (NLP), machine learning (ML), and knowledge representation. Key factors determining relevance will include temporal proximity to the time series event, geographic location, and the semantic relationship between the news and the forecast target. Furthermore, the paper may detail how the agent’s performance is evaluated and refined, potentially through iterative feedback loops or by comparing the forecast accuracy with and without the agent’s filtered news. This sophisticated filtering system represents a significant improvement over simpler techniques, enhancing the model’s efficiency and accuracy, and addressing the challenge of integrating qualitative data effectively into a quantitative forecasting model. The agent’s decision-making process is likely adaptable and dynamic, learning and improving its selection criteria over time.
Iterative Refinement#
Iterative refinement, in the context of a research paper, often describes a process of cyclical improvement. It suggests a feedback loop where initial results are analyzed, shortcomings identified, and adjustments made to the methodology or model. This cycle repeats, leading to progressively better outcomes. The core idea is to leverage previous iterations’ learnings to inform and refine subsequent steps, rather than relying on a single, static approach. This iterative process is particularly valuable when dealing with complex systems or problems where a complete understanding is initially lacking. Each iteration builds upon the previous one, progressively converging towards a more accurate or optimal solution. The iterative nature often reveals subtle or unexpected insights that might be missed in a one-off approach, thus increasing the robustness of the final results. The explicit inclusion of iterative refinement highlights the importance of adaptive and continuous improvement in the research process.
Forecast Accuracy#
Assessing forecast accuracy is crucial for evaluating the effectiveness of any time series forecasting model. This involves comparing predicted values against actual observed values using various metrics such as Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and Mean Absolute Percentage Error (MAPE). Lower values indicate better accuracy. The choice of metric depends on the specific application and the relative importance of different types of errors. For instance, RMSE penalizes larger errors more heavily than MAE. Analyzing accuracy across different time horizons (short-term, long-term) provides insights into the model’s ability to capture both short-term fluctuations and long-term trends. Furthermore, it’s essential to consider forecast accuracy across various domains, as model performance may vary significantly based on the specific characteristics of the time series data (e.g., seasonality, noise levels, and underlying data generating processes). Robustness checks, such as sensitivity analysis and out-of-sample testing, are needed to ensure reliability and generalizability. Finally, evaluating the model’s accuracy in relation to existing benchmarks and state-of-the-art methods provides valuable context for interpretation of results. All in all, a multifaceted approach is necessary for a robust and meaningful assessment of forecast accuracy.
Future Extensions#
Future research directions for this innovative time series forecasting framework could explore several promising avenues. Integrating more sophisticated natural language processing techniques to better understand nuanced information within news articles would enhance accuracy and context. Developing more robust methods for handling missing or incomplete data in both time series and news sources is crucial. This could involve advanced imputation techniques or the development of more resilient model architectures. Furthermore, exploring the use of explainable AI (XAI) methods would increase transparency and trust in the model’s predictions by providing insights into the reasoning behind its forecasts. Finally, extending the framework to handle diverse data types beyond numerical time series and textual news, such as incorporating image or audio data, could lead to more comprehensive and accurate models. A deeper investigation into the potential biases within news sources and the mitigation of these biases in the model is also vital for fairness and reliability. The scalability and efficiency of the approach for large-scale applications and real-time forecasting also need further evaluation and optimization.
More visual insights#
More on figures
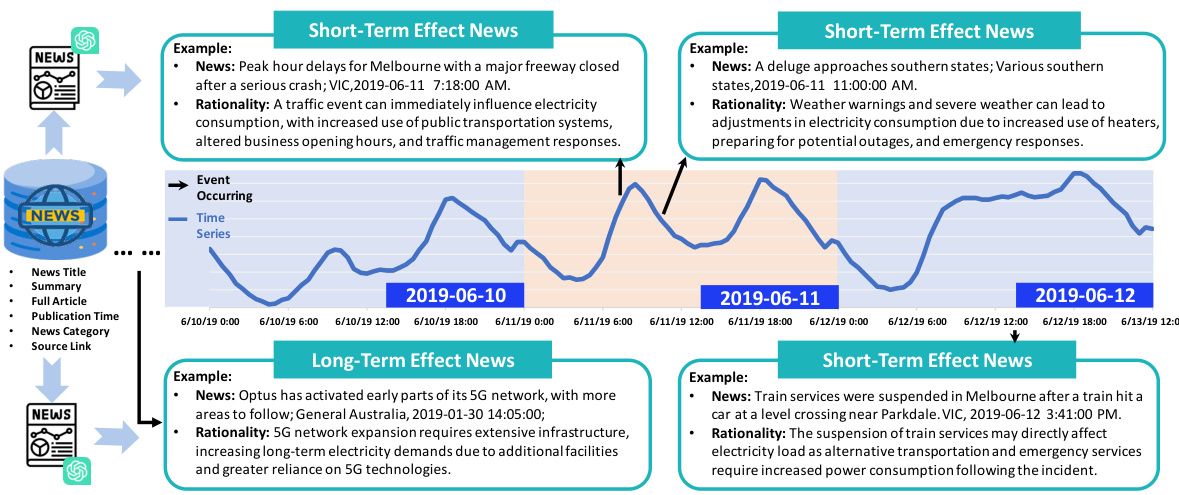
This figure illustrates the overall workflow of the proposed time series forecasting framework. It shows how the system retrieves relevant news and supplementary information (A), utilizes LLM-based agents to filter and select relevant news based on the forecasting horizon (B), integrates the selected news and contextual information with time series data for fine-tuning an LLM forecasting model (C, D), and uses an evaluation agent to analyze prediction errors and refine the news selection and reasoning logic (E).
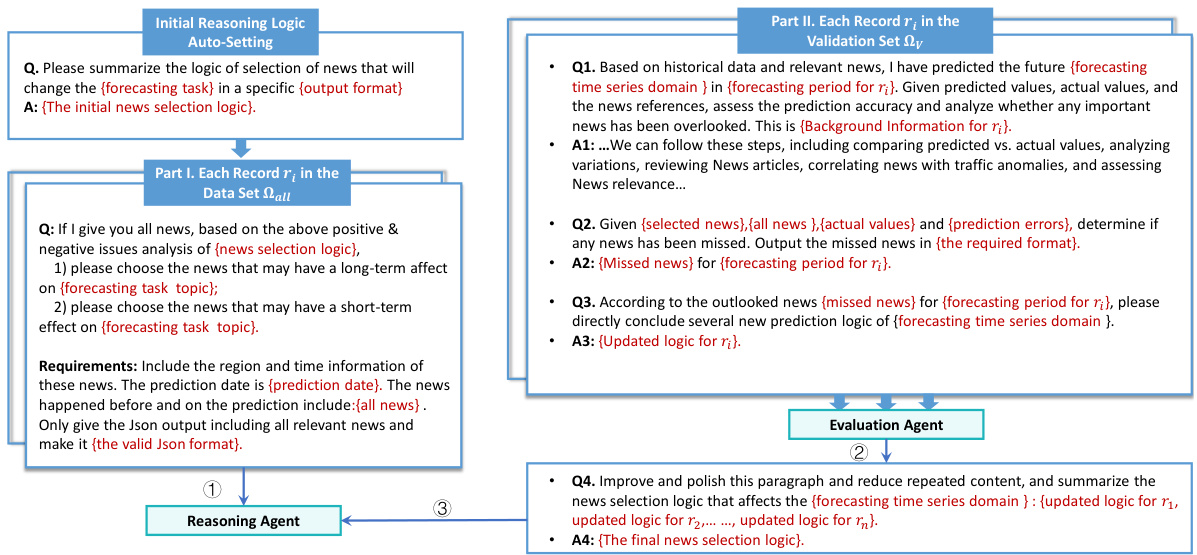
This figure illustrates the overall framework of the proposed method which integrates textual information into time series forecasting. It shows five stages: 1) Information Retrieval; 2) Reasoning Agent; 3) Prompt Integration for Data Preparation; 4) LLM Finetune; 5) Evaluation Agent. Each stage is described in detail in the caption, highlighting the use of LLMs and generative agents to select relevant news, integrate it with time series data, fine-tune a forecasting model, and iteratively refine the process based on prediction accuracy.
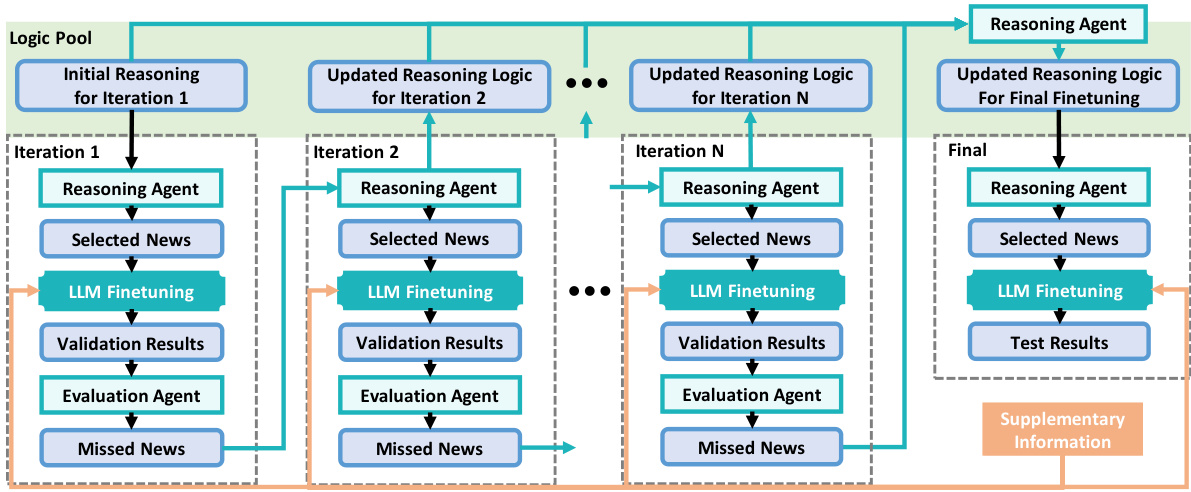
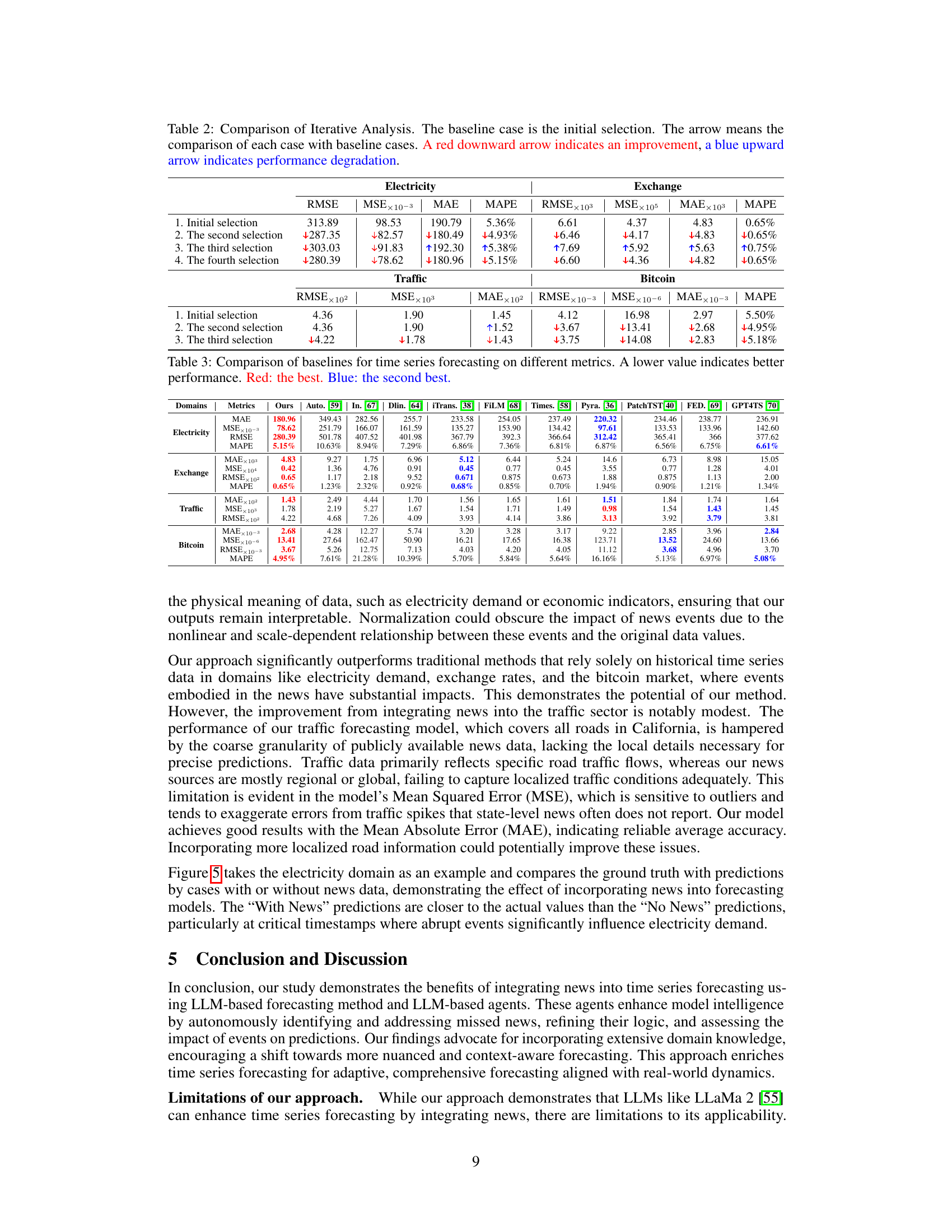
This figure illustrates the iterative process of integrating news into time series forecasting. It starts with an initial reasoning logic, which guides the reasoning agent to select relevant news for the first iteration. This selected news is then used to fine-tune the LLM forecasting model. The model’s predictions are evaluated using a validation set, and the evaluation agent identifies any missed news. Based on this feedback, the reasoning logic is updated, and the process is repeated for subsequent iterations. This cycle continues until the final iteration, where the final reasoning logic and fine-tuned model are used to generate test results.

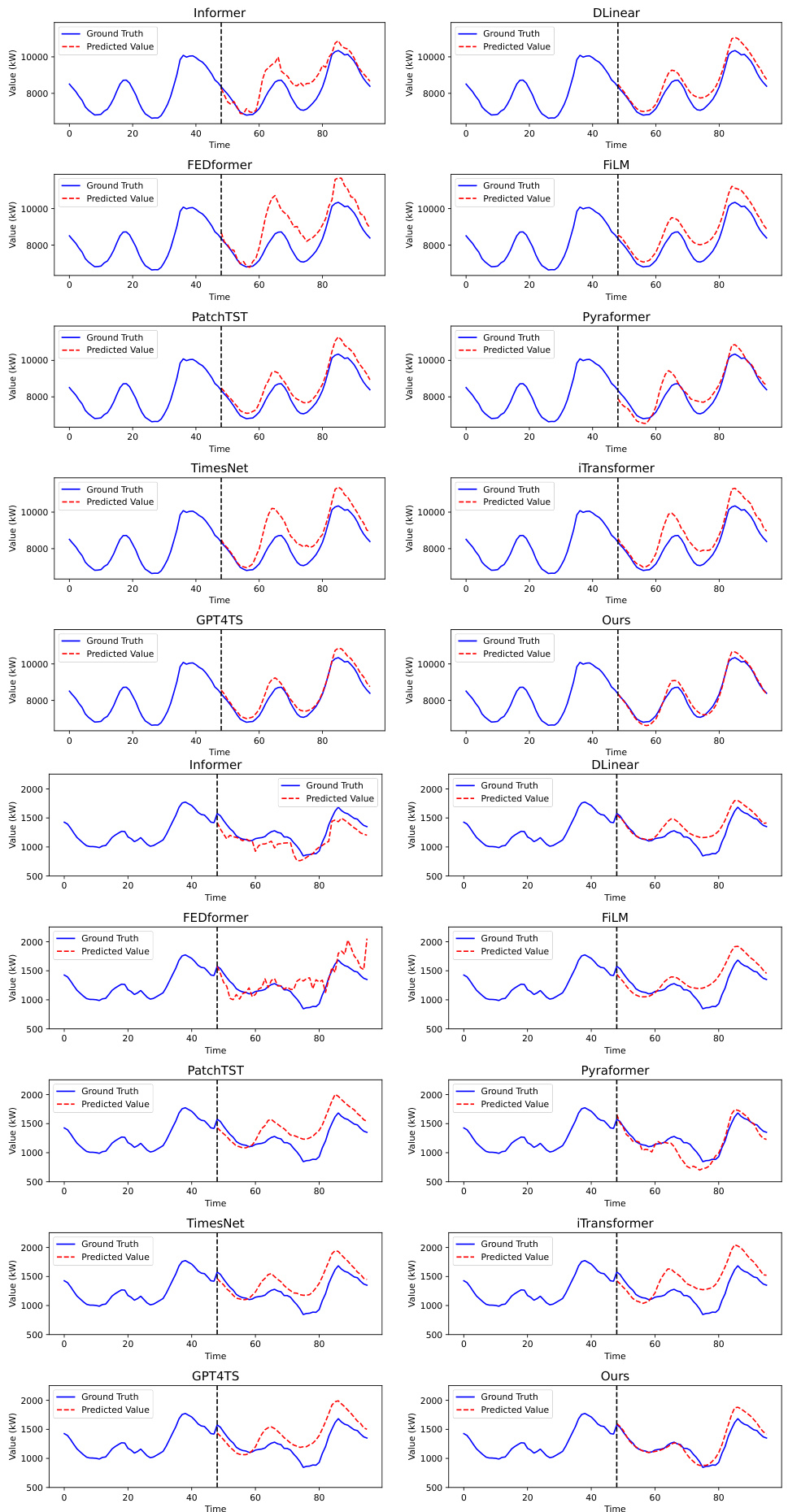
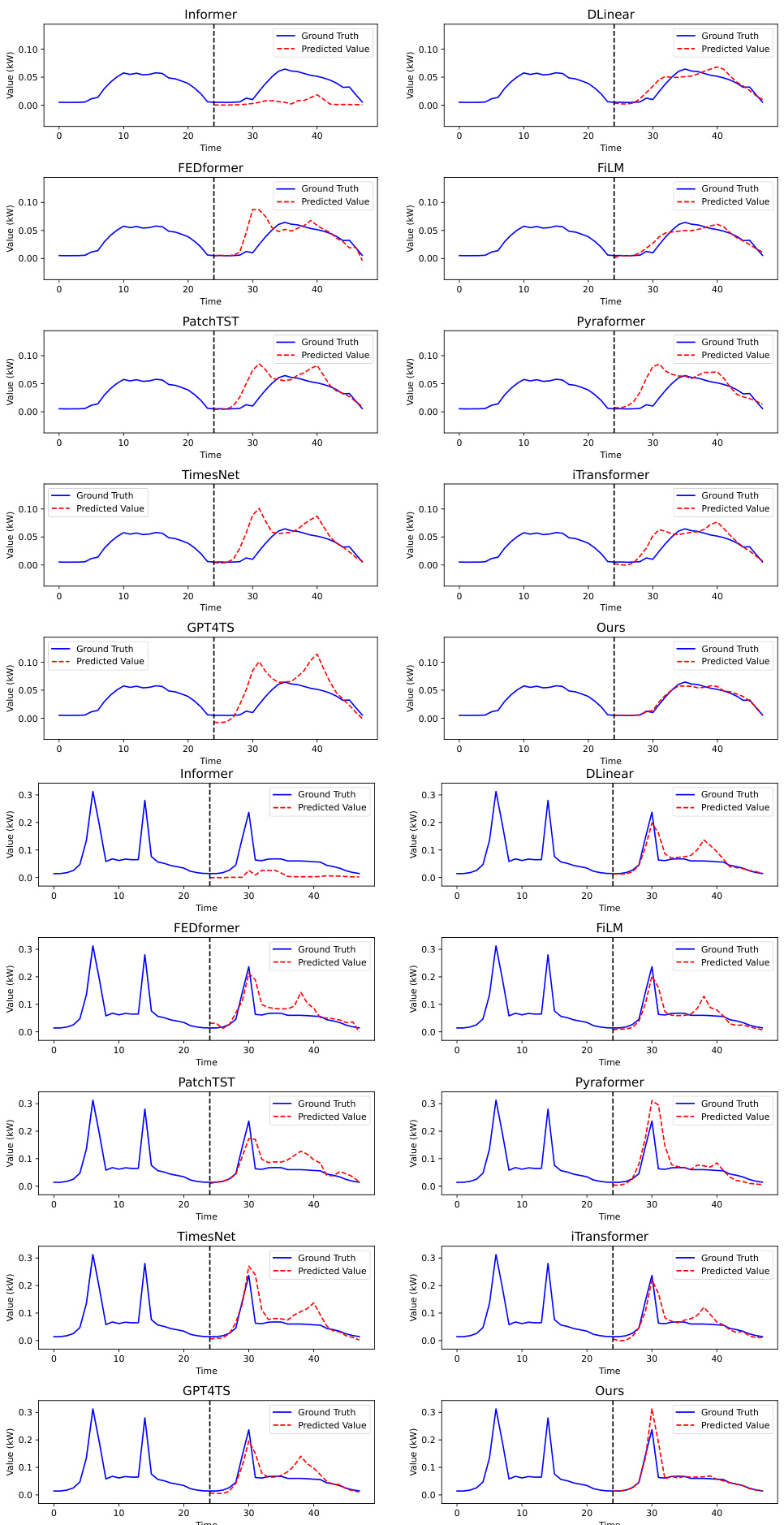
This figure shows the day-ahead electricity demand forecasting results for Australia, comparing the actual values against predictions made with and without incorporating news data. The graph displays three cases: (a) shows impact of Sydney’s lockdown, (b) shows impact of increased residential electricity use, and (c) shows impact of an anticipated power outage. Each case demonstrates how including news data leads to more accurate predictions, especially during periods of significant change in electricity demand.

This figure illustrates the overall framework of the proposed method for integrating textual information into time series forecasting. It shows five main stages: (A) Information Retrieval, (B) Reasoning Agent, (C) Prompt Integration for Data Preparation, (D) LLM Finetune, and (E) Evaluation Agent. Each stage is briefly described, illustrating the flow of information and how the model incorporates news data and contextual information to improve forecasting accuracy.

This figure illustrates the overall framework of the proposed method, which integrates textual information into time series forecasting. It shows five stages: (A) Information Retrieval, (B) Reasoning Agent, (C) Prompt Integration for Data Preparation, (D) LLM Finetune, and (E) Evaluation Agent. The framework iteratively refines the news selection logic and improves the forecasting accuracy by incorporating news and supplementary information into the LLM forecasting model.

This figure illustrates the overall workflow of integrating textual information into time series forecasting. It shows five main stages: (A) Information Retrieval, where relevant news and supplementary data are gathered; (B) Reasoning Agent, where an LLM-based agent filters and selects relevant news; (C & D) LLM Finetuning, where the selected news and time series data are used to fine-tune an LLM forecasting model; and (E) Evaluation Agent, where the model’s predictions are evaluated, and the reasoning logic is refined based on the results. This iterative process aims to improve forecasting accuracy by leveraging both structured and unstructured data.

This figure illustrates the overall framework of the proposed method. It shows how relevant news and supplementary information are retrieved and integrated with time series data for improved forecasting. The process involves an information retrieval module, a reasoning agent for news selection, prompt integration for data preparation, LLM fine-tuning, and an evaluation agent to continuously refine the process.

This figure illustrates the overall framework of the proposed method. It shows how relevant news and supplementary information are retrieved and integrated with time series data to improve forecasting accuracy. The framework consists of five stages: information retrieval, reasoning agent for news selection, prompt integration for data preparation, LLM fine-tuning, and evaluation agent for model refinement. Each stage is described briefly in the caption, showing the flow of information and the interaction between different components.
This figure illustrates the overall framework of the proposed method, which integrates textual information (news and supplementary data) into an LLM-based time series forecasting model. It shows five stages: (A) Information retrieval from various sources; (B) News filtering and selection by LLM-based reasoning agents; (C & D) Data preparation and LLM fine-tuning using both time series and selected news data; and (E) Model evaluation and refinement based on prediction errors, leading to iterative improvements. The framework highlights the dynamic interaction between LLM agents, news data, and the forecasting model, showcasing the adaptive and iterative nature of the approach.
This figure illustrates the overall framework of the proposed method for integrating textual information into time series forecasting. It shows five main modules: information retrieval, reasoning agent, prompt integration, LLM finetuning, and evaluation agent. Each module is described with a brief explanation of its function in the context of the entire framework. The interactions between modules are shown using arrows, demonstrating the iterative process of refining news selection logic and improving forecasting accuracy. The figure clearly illustrates how the model uses textual information (news and supplementary information) along with time series data to improve forecasting accuracy.
This figure illustrates the overall framework of the proposed method which integrates news and supplementary information into time series forecasting. It shows the different stages of the process, from information retrieval and filtering (using LLMs) to model fine-tuning and evaluation. The feedback loop ensures continuous refinement of the model by analyzing prediction errors and adjusting the news selection logic. This system uses LLM-based agents to analyze and select the most relevant information from a large volume of data.
More on tables
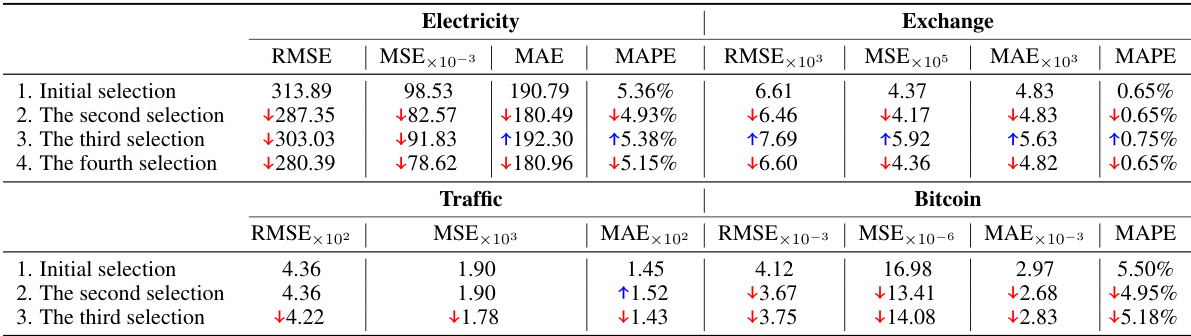
This table compares the performance of four different prompt designs for time series forecasting across four domains (Electricity, Exchange, Traffic, and Bitcoin). The designs vary in the inclusion of news data (filtered and unfiltered) and textual descriptions alongside numerical data. The metrics used for comparison are Mean Squared Error (MSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Squared Error (RMSE). The best-performing design for each domain is highlighted in red.
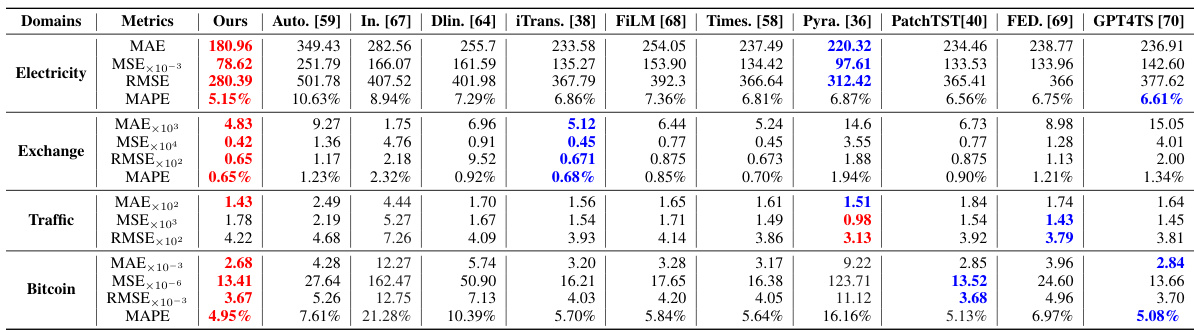
This table presents a comparison of the Mean Squared Error (MSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Squared Error (RMSE) for four different prompt designs used in electricity, exchange rate, traffic, and Bitcoin forecasting. The four designs are: 1. Only Numeric Prompt: Uses only numerical tokens. 2. Textual Prompt without News: Uses textual descriptive sentence tokens, but no news data. 3. Textual Prompt with Non-Filtered News: Uses textual descriptions and unfiltered news data. 4. Textual Prompt with Filtered News: Uses textual descriptions and news data filtered by the proposed agents. The table helps to demonstrate the impact of integrating news data and the effectiveness of the proposed news filtering method on forecasting accuracy across different domains.

This table presents a comparison of the Mean Squared Error (MSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Squared Error (RMSE) for four different prompt designs across four different domains: Electricity, Exchange, Traffic, and Bitcoin. The four designs represent different levels of integration of news and supplementary information into the forecasting model. This allows for an evaluation of the impact of different levels of news integration on forecasting accuracy. The best-performing approach for each metric is highlighted in red.

This table presents a comparison of the mean squared error (MSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and root mean squared error (RMSE) for four different prompt designs across four domains: Electricity, Exchange, Traffic, and Bitcoin. The four designs represent different levels of news integration: (1) only numerical data, (2) textual descriptions without news, (3) textual descriptions with unfiltered news, and (4) textual descriptions with filtered news. The table helps to illustrate the impact of news integration and the effectiveness of the proposed news filtering method on forecasting accuracy. The best performing method for each metric is highlighted in red.

This table presents a comparison of the Mean Squared Error (MSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Squared Error (RMSE) for four different prompt designs used in electricity, exchange rate, traffic, and Bitcoin forecasting. The prompt designs vary in whether they include numerical tokens only, textual descriptions, unfiltered news, and filtered news. The table helps to demonstrate the impact of incorporating news data, particularly when filtered using the proposed method, on improving forecasting accuracy.
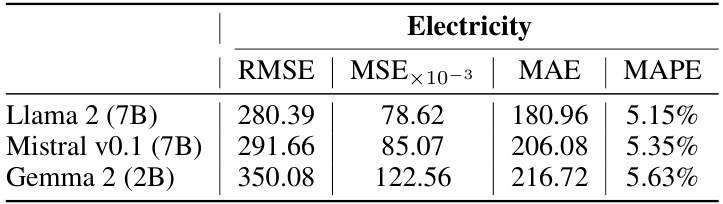
This table presents a comparison of the performance of four different prompt designs used for electricity, exchange rate, traffic, and Bitcoin time series forecasting. Each design varies in the type of data included (pure numerical, textual descriptions only, unfiltered news with descriptions, and filtered news with descriptions). The table displays the MSE, MAE, MAPE, and RMSE for each prompt design in each domain, allowing for comparison and highlighting which prompt design is most effective for time series forecasting in the tested domains.
This table presents a comparison of the performance of four different prompt designs used in time series forecasting. The prompt designs vary in how they incorporate news data (filtered vs. unfiltered) and textual information (numerical tokens only vs. including descriptive sentences). The metrics used for comparison are Mean Squared Error (MSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Squared Error (RMSE). The results show that incorporating filtered news and descriptive text leads to the best forecasting performance across all four domains (Electricity, Exchange, Traffic, Bitcoin).
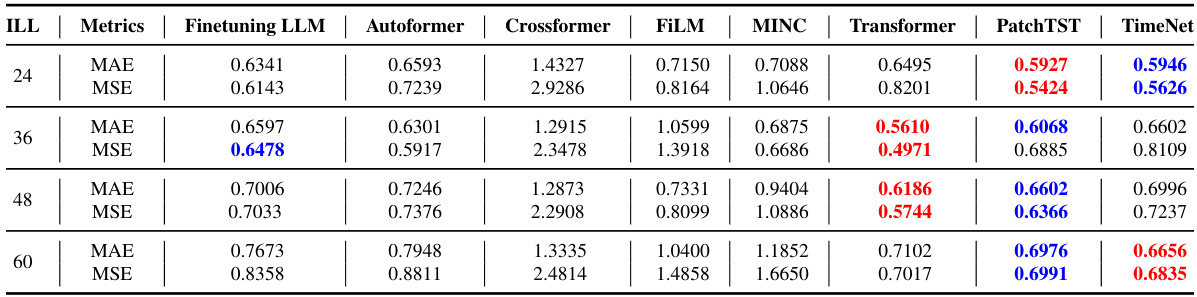
This table presents a comparison of the mean squared error (MSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and root mean squared error (RMSE) achieved by four different prompt designs for forecasting electricity demand, exchange rates, traffic, and Bitcoin prices. The four designs represent varying degrees of news integration: only numerical data, numerical data with descriptive text, numerical data with unfiltered news, and numerical data with news filtered by the proposed agents. The best performing method for each metric is highlighted in red.
Full paper#