↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-viewpoint object-centric learning aims to create comprehensive representations of scenes by observing them from multiple angles. Existing methods often rely on random or sequential viewpoint selection, which can be inefficient and may miss crucial information. This limits the quality of object segmentation and image generation.
The paper introduces AVS (Active Viewpoint Selection), a new method that intelligently chooses the next viewpoint to observe based on the predicted information gain. This active selection process improves efficiency by using fewer images and substantially improves the accuracy of object segmentation and scene reconstruction compared to methods using random viewpoint selection. The system also demonstrates improved performance in generating images from unseen angles and even creating entirely new viewpoints.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AVS, a novel approach to multi-viewpoint object-centric learning that significantly improves performance in object segmentation and image generation. It addresses limitations of existing methods by employing an active viewpoint selection strategy, which focuses on obtaining the most informative views. This improves efficiency and quality, making it highly relevant to researchers working on scene understanding, visual reasoning and other related areas. The introduced active selection strategy opens new avenues for research into more efficient and effective multi-viewpoint learning.
Visual Insights#

This figure illustrates the active viewpoint selection framework proposed in the paper. The process starts with a multi-viewpoint dataset divided into an observation set (known viewpoints) and an unknown set (unknown viewpoints). The model predicts images from the unknown set based on the known images in the observation set. A selection strategy compares the object-centric representations of known and predicted images, choosing the viewpoint with the highest information gain (largest disparity). This chosen viewpoint’s image is added to the observation set, and the process repeats until a sufficient number of viewpoints are included in the observation set, improving the model’s training effectiveness and efficiency.

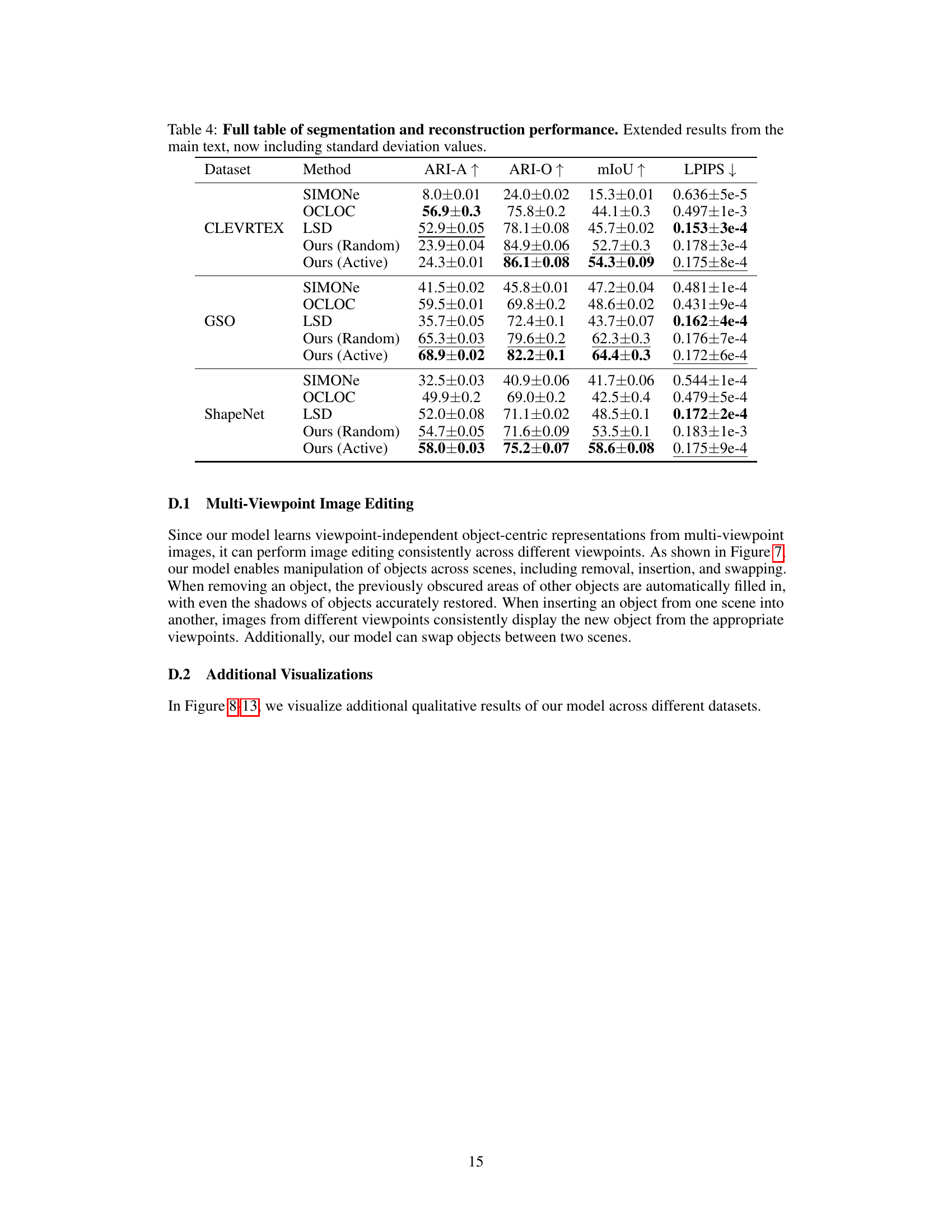
This table presents a quantitative comparison of the proposed AVS model against several baseline methods across three datasets (CLEVRTEX, GSO, ShapeNet) and four evaluation metrics (ARI-A, ARI-O, mIoU, LPIPS, FID). ARI-A and ARI-O measure the quality of unsupervised object segmentation, considering both objects and background (ARI-A) or only objects (ARI-O). mIoU represents the mean Intersection over Union, a common segmentation metric. LPIPS measures the perceptual image reconstruction quality, and FID assesses the diversity and quality of generated images. The results demonstrate that AVS achieves superior or comparable performance across all datasets and metrics compared to baselines, particularly in segmentation and generation.
In-depth insights#
Active Viewpoint#
Active viewpoint selection is a crucial aspect of multi-viewpoint object-centric learning, aiming to overcome limitations of random or sequential viewpoint selection strategies. The core idea is to strategically choose viewpoints that maximize information gain, rather than relying on arbitrary or predefined sequences. This involves predicting object representations from unseen viewpoints, comparing them to existing observations, and selecting the viewpoint that yields the largest difference in information. This approach is particularly valuable in complex scenes with occlusion or viewpoints sensitive to specific object details. By selectively choosing informative viewpoints, active viewpoint selection improves both the efficiency and effectiveness of object-centric representation learning, leading to better segmentation and reconstruction performance. The integration of a diffusion model further enhances image decoding quality by leveraging its generative capabilities to create more informative predicted images. In essence, active viewpoint selection represents a significant step towards more efficient and effective multi-viewpoint object-centric learning, achieving improved model training and object understanding in visually complex scenarios.
Multi-View Learning#
Multi-view learning tackles the challenge of integrating information from multiple, potentially disparate, sources to build a more robust and comprehensive representation. It’s particularly valuable when single views are insufficient or ambiguous, for example, due to occlusion or noise. The core idea is to leverage the complementary nature of different views to overcome individual limitations. Successful strategies depend on how effectively the algorithm fuses information, handling inconsistencies and redundancies. Different fusion techniques exist, including early fusion (combining views before feature extraction), intermediate fusion (combining features after extraction), and late fusion (combining predictions from individual models). The choice of fusion method significantly impacts performance and is often task-specific. Furthermore, viewpoint selection strategies are crucial, as not all views contribute equally. Active selection methods, for instance, aim to strategically sample informative viewpoints, optimizing data acquisition and improving efficiency. Multi-view learning has numerous applications, from image classification and object recognition to medical image analysis and social network analysis, where multiple data sources offer a richer understanding than a single one.
Diffusion Decoder#
A diffusion decoder is a type of neural network architecture used in generative models, particularly those based on diffusion processes. It leverages the powerful image generation capabilities of diffusion models to produce high-quality, realistic images from a given input, typically a latent representation learned by another part of the model. The key advantage of a diffusion decoder lies in its ability to generate diverse and high-resolution images, exceeding the capabilities of more traditional decoders. It accomplishes this by reversing a diffusion process, which gradually adds noise to an image until it becomes pure noise, thus learning the reverse process that transforms noise into a meaningful image. The process involves learning a series of denoising steps, each progressively removing some of the noise, guided by latent representations (e.g., slots) or other model outputs. This method can generate nuanced details and intricate structures often missed by simpler decoder architectures. Crucially, the quality of the generated image is greatly influenced by the quality and the information content of the input representation given to the decoder. However, diffusion decoders can be computationally expensive, requiring significant resources for training and inference. Further research could explore techniques to optimize this process, improving its efficiency while maintaining high-quality image generation.
Object Segmentation#
The provided text focuses on multi-viewpoint object-centric learning, emphasizing the improvement of viewpoint-independent object-centric representations through active viewpoint selection. Object segmentation is a crucial component of the evaluation, demonstrating the model’s ability to accurately delineate individual objects within complex scenes, especially those with occlusions or challenging viewpoints. The superior performance of the active viewpoint selection strategy compared to random selection highlights the importance of strategically choosing viewpoints for optimal object segmentation. Unsupervised learning is key, as the model does not rely on manual object annotations. Furthermore, the results suggest that using a diffusion-based decoder significantly enhances object segmentation accuracy, producing more precise and detailed segmentations compared to traditional methods. The model’s success in predicting images from unknown viewpoints further strengthens the overall object segmentation quality. Finally, the paper showcases strong quantitative results using metrics such as ARI and mIoU, which confirms the effectiveness of this approach. The integration of viewpoint selection and diffusion models is a critical innovation.
Novel View Synth#
The concept of “Novel View Synthesis” within the context of a research paper likely focuses on generating new viewpoints of a scene that were not originally captured. This is a significant challenge in computer vision, requiring the system to understand the 3D structure of the scene and the relationships between objects. The approach likely leverages learned object-centric representations, combining information from multiple known views to predict the appearance from a novel perspective. This necessitates viewpoint-independent representations that are robust to occlusion and variations in lighting and viewpoint. The success of the approach hinges on its ability to accurately predict both the object appearance and the overall scene geometry. A key aspect to explore would be the evaluation metrics used, whether focusing on visual fidelity (e.g., LPIPS, FID scores) or the accuracy of the predicted scene’s 3D structure. Furthermore, understanding the computational demands and limitations of the method, particularly concerning the scale of scenes handled, is important. The active viewpoint selection strategy is likely a key innovation here, as it might intelligently choose which viewpoints provide the most information for synthesizing novel perspectives efficiently.
More visual insights#
More on figures
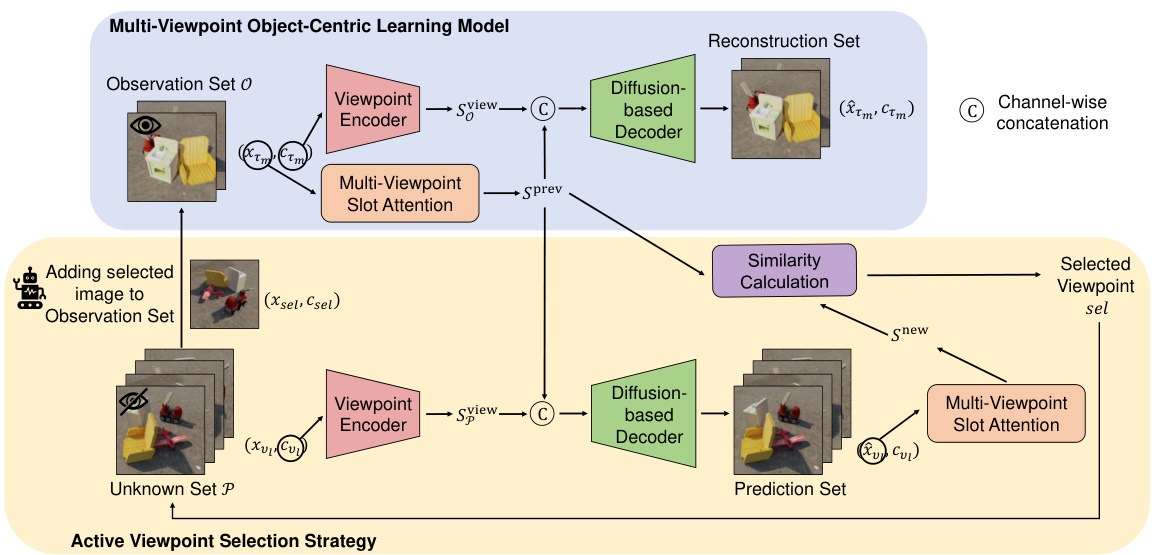
This figure illustrates the architecture of the proposed AVS model, which consists of a Multi-Viewpoint Object-Centric Learning Model and an Active Viewpoint Selection Strategy. The model learns viewpoint-independent object-centric representations from an observation set of images and uses these representations to predict images from an unknown set. The active viewpoint selection strategy iteratively selects viewpoints from the unknown set that maximize the information gain, adding them to the observation set to improve the model’s performance. The process continues until a predefined number of viewpoints are in the observation set.

This figure visualizes the qualitative results of unsupervised object segmentation on two datasets, CLEVRTEX and GSO. It compares the ground truth segmentation with the results produced by different methods including SIMONe, OCLOC, LSD, and the proposed AVS model with both random and active viewpoint selection strategies. The visualization helps in understanding the performance of each method in terms of accuracy and detail in segmenting objects within complex scenes.

This figure visualizes the scene reconstruction results on three different datasets: CLEVRTEX, GSO, and ShapeNet. For each dataset, it shows ground truth images and reconstruction results from four different methods: SIMONe, OCLOC, LSD, and the proposed AVS (Active Viewpoint Selection) model. The figure demonstrates the superior reconstruction quality of the AVS model compared to baseline methods, particularly in capturing fine details and producing clearer, more realistic images.

This figure visualizes the results of compositional generation and interpolation using the proposed model. The top row shows multi-viewpoint generation, demonstrating the model’s ability to generate images of the same scene from multiple viewpoints using different timesteps as viewpoint annotations. The bottom row shows interpolation, expanding the range of timesteps to generate a smoother sequence of images representing novel viewpoints between the initial set of viewpoints.

This figure visualizes the novel viewpoint synthesis results of the proposed AVS model on two datasets, CLEVRTEX and GSO. For each dataset, the top row shows the ground truth images from multiple viewpoints. The middle row shows the reconstruction images generated by the model, and the bottom row displays the segmentation masks predicted by the model for the synthesized images. Red boxes highlight the newly predicted viewpoints by the model.

This figure shows the results of image editing experiments using the proposed multi-viewpoint object-centric learning model. The model demonstrates its ability to manipulate objects across multiple viewpoints (removal, insertion, and swapping) while maintaining consistency and accurately rendering occluded areas and object shadows. The arrows indicate the manipulation actions.

This figure visualizes the qualitative results of unsupervised object segmentation on the CLEVRTEX and GSO datasets. It compares the ground truth segmentations (GT) to the segmentations produced by various methods: SIMONe, OCLOC, LSD, and the authors’ proposed method (both random and active viewpoint selection). The visualization shows that the authors’ active viewpoint selection method produces segmentations that are more accurate and detailed than the other methods, especially in capturing the fine-grained textures and details of objects.

This figure visualizes the qualitative results of unsupervised object segmentation on the CLEVRTEX and GSO datasets. It shows ground truth segmentations alongside the results produced by different methods, including SIMONe, OCLOC, LSD, and the proposed AVS model (both with random and active viewpoint selection). The visualizations allow for a direct comparison of the segmentation accuracy and quality of the different approaches.

This figure visualizes the qualitative results of unsupervised object segmentation on two datasets: CLEVRTEX and GSO. For each dataset, it shows the ground truth segmentation (GT) and the segmentation results produced by several methods (SIMONE, OCLOC, LSD, Ours (Random), Ours (Active)). The visualization allows for a visual comparison of the different methods’ performance in terms of accuracy and detail in segmenting objects within complex scenes.

This figure visualizes the novel viewpoint synthesis results of the proposed model, AVS, on the CLEVRTEX dataset. The top row shows the ground truth images from various viewpoints (timesteps t=1 to 12), followed by the reconstruction results. The bottom row displays the segmentation results from the predicted images. Red boxes highlight the predicted images from unknown viewpoints. The figure demonstrates the model’s ability to accurately predict images and segment objects from novel viewpoints, showcasing its capacity for viewpoint synthesis.

This figure visualizes the novel viewpoint synthesis capabilities of the proposed AVS model on two datasets, CLEVRTEX and GSO. It demonstrates the model’s ability to generate images from viewpoints not included in the training data. The top row shows the ground truth images for each viewpoint. The middle row displays the model’s reconstruction of these images. The bottom row presents the generated images from novel viewpoints. Red boxes highlight the generated images. The results indicate that the model successfully synthesizes images and segmentation masks from novel viewpoints, showing a good grasp of object relationships and scene context.

This figure shows the results of novel viewpoint synthesis on two datasets, CLEVRTEX and GSO. For each dataset, there are two rows of images. The top row shows the ground truth images from various viewpoints, with corresponding segmentation masks below. The bottom row displays the images generated by the model from viewpoints not included in the training data. Red boxes highlight the predicted segmentation mask for each image. The experiment aims to demonstrate the model’s ability to accurately predict and segment images from novel viewpoints, using only object-centric representations from known viewpoints.
More on tables

This table presents the configurations used for the three datasets: CLEVRTEX, GSO, and ShapeNet. For each dataset, it details the number of images in the training, validation, and testing splits; the range of the number of objects present in each scene; the number of viewpoints captured for each scene; the image size (resolution); and the range of values used for the spherical coordinates (distance ρ, elevation θ, and azimuth φ) defining the camera positions for capturing the different viewpoints. These parameters are crucial for understanding the characteristics of the datasets used in the experiments and for reproducing the results.
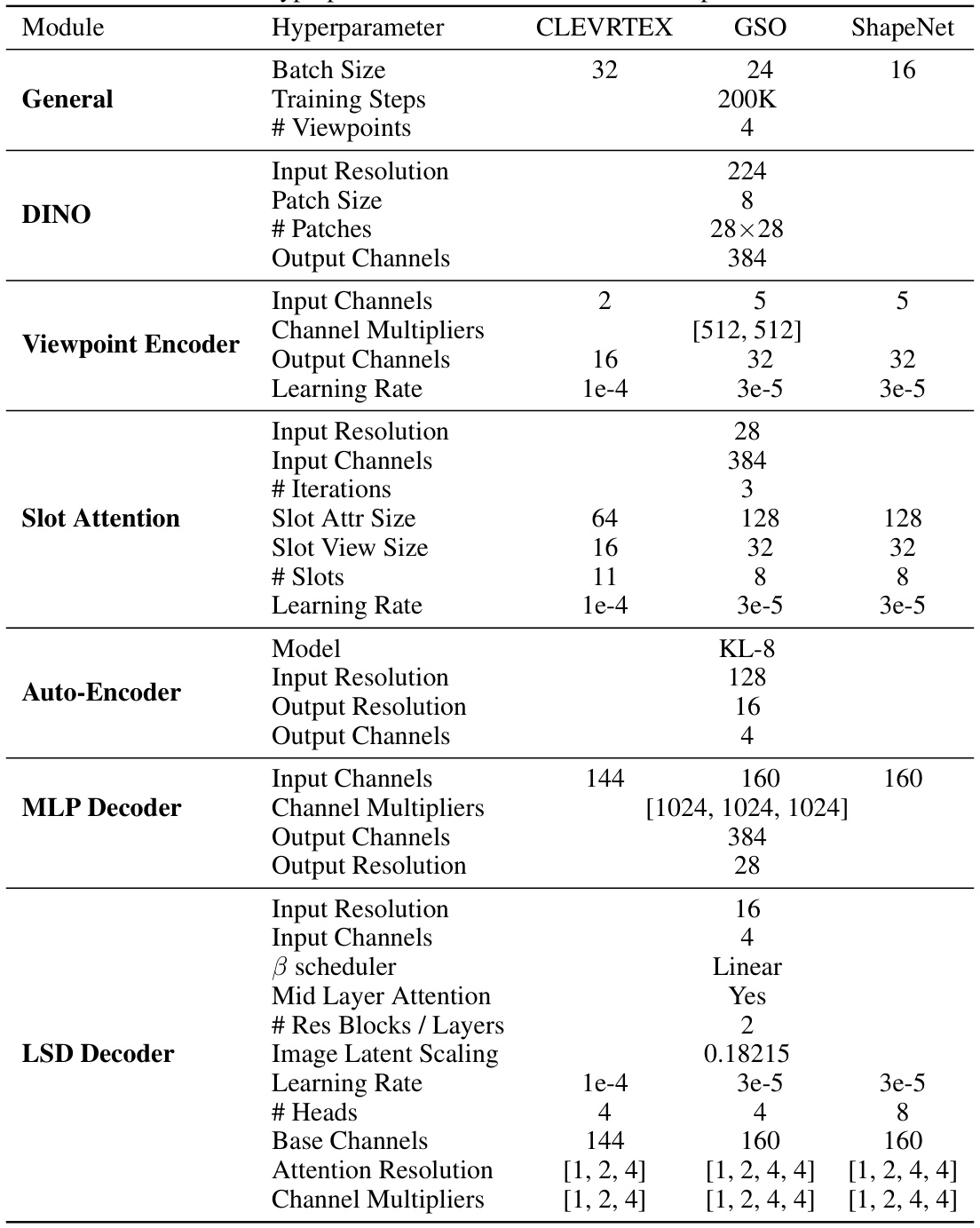
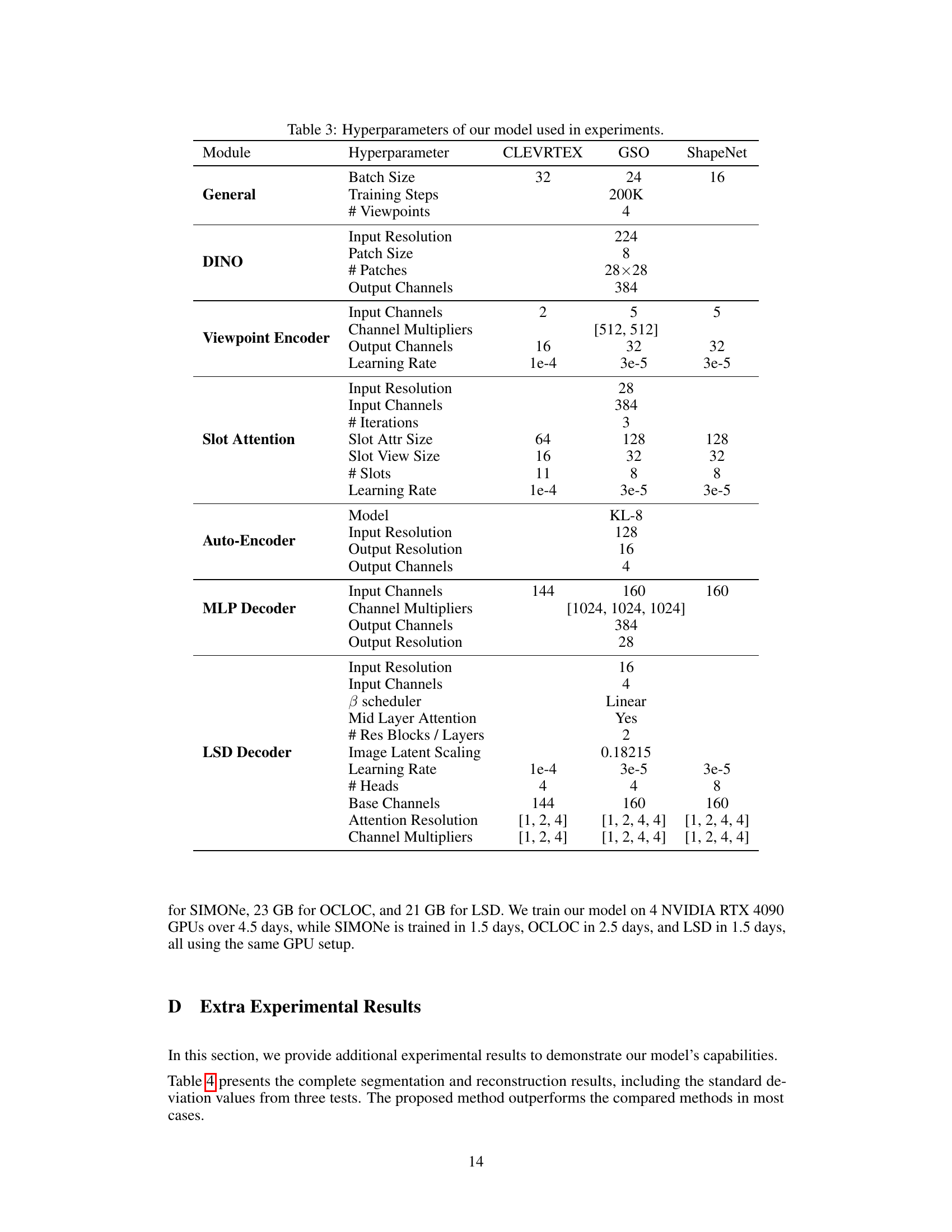
This table lists the hyperparameters used for training the proposed model (AVS) and baseline models (SIMONE, OCLOC, LSD) on three different datasets (CLEVRTEX, GSO, ShapeNet). The hyperparameters are categorized by model modules (General, DINO, Viewpoint Encoder, Slot Attention, Auto-Encoder, MLP Decoder, LSD Decoder). For each module and dataset, different hyperparameters such as batch size, number of training steps, input/output resolution and channels, learning rate, number of iterations, number of slots, and others are specified. This detailed breakdown provides complete information for reproducibility.
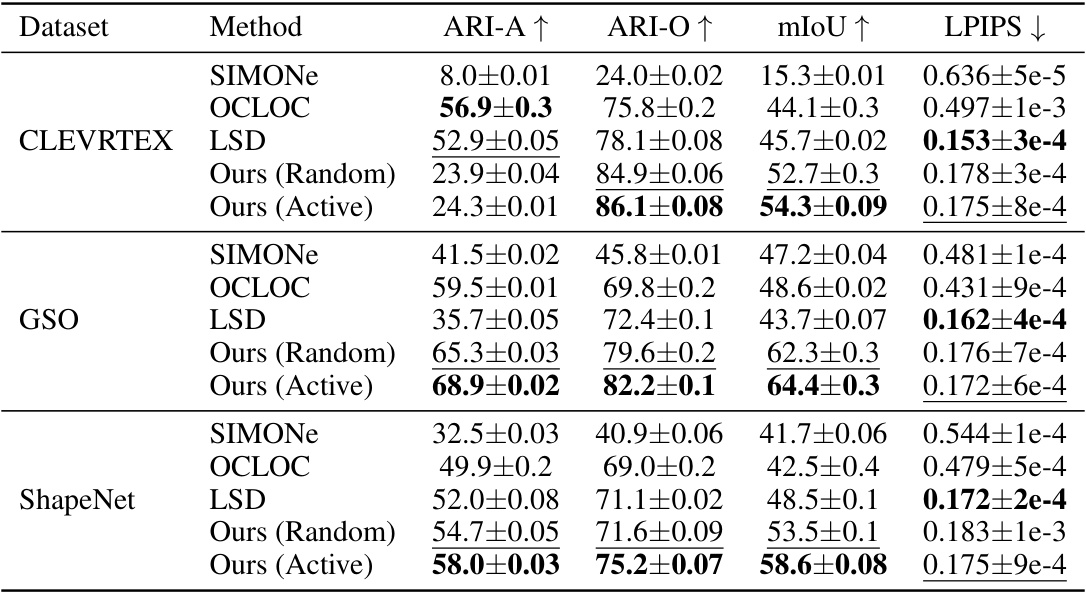
This table compares the performance of different methods across three datasets (CLEVRTEX, GSO, ShapeNet) on four tasks: unsupervised object segmentation (ARI-A, ARI-O, mIoU), scene reconstruction (LPIPS), and image generation (FID). For each dataset and task, the table shows the mean performance of three trials for several methods, including SIMONe, OCLOC, LSD, and the authors’ model with both random and active viewpoint selection strategies. The best and second-best scores for each metric are highlighted.
Full paper#