↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Cloud-based speech understanding raises significant privacy concerns, especially for data from resource-limited devices. Existing privacy-preserving methods using disentanglement-based encoders are computationally expensive, making them unsuitable for these devices. This paper introduces SILENCE, a lightweight system that tackles this issue.
SILENCE employs a novel approach: it selectively masks short-term audio details based on an observation that speech understanding hinges on long-term dependencies, while privacy-sensitive information is typically short-term. A differential mask generator, derived from interpretable learning, automatically configures the masking process. Evaluated on a microcontroller, SILENCE achieves significant speedup and memory footprint reduction compared to previous approaches, with comparable accuracy and privacy protection.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in deploying speech understanding systems on resource-constrained devices while ensuring user privacy. This is highly relevant to the growing Internet of Things (IoT) domain and opens new avenues for research in lightweight privacy-preserving machine learning.
Visual Insights#

This figure illustrates three different approaches to offloaded speech understanding on resource-constrained devices. (a) shows a basic system where the raw audio signal is directly sent to a semi-honest cloud for processing. (b) shows a privacy-preserving approach using a resource-intensive disentangled encoder to remove sensitive information from the audio signal before sending it to the cloud. (c) shows the proposed SILENCE system, which uses a lightweight encoder to selectively obscure short-term details of the audio signal to protect privacy while preserving long-term dependencies necessary for speech understanding. The figure highlights the trade-off between resource usage and privacy protection in these different approaches.

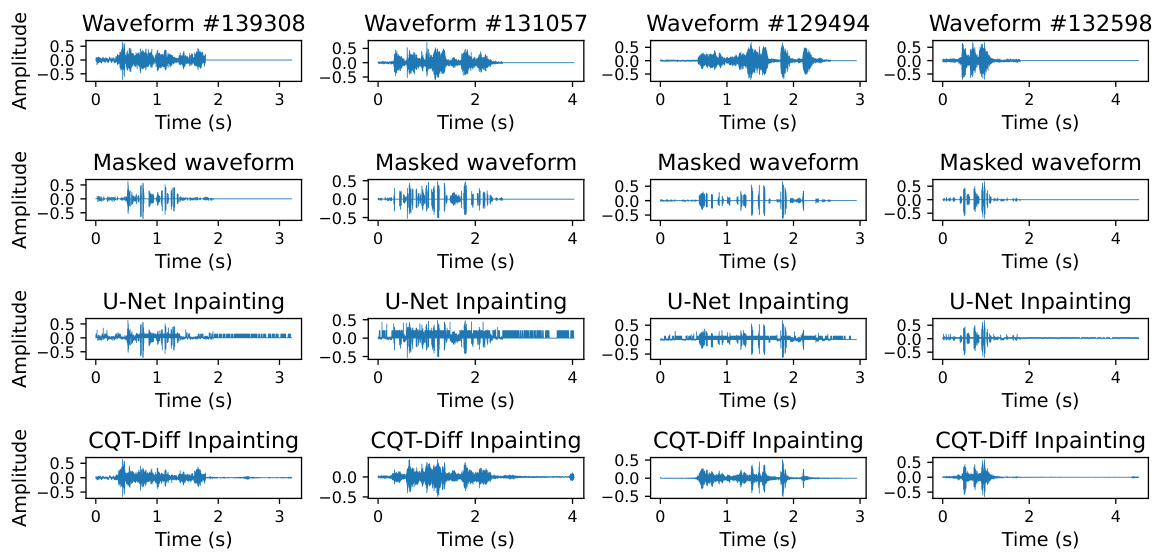
This table presents the word error rates (WER) achieved by different attack models against the SILENCE system. The attacks are categorized as passive (Azure, Naive Whisper) and active (U-Net, CQT-Diff, Whisper predict (white box)). The WER-SLU represents the error rate on the SLU task itself, and WER-ASR represents the error rate on the ASR task, aiming to transcribe the audio. A lower WER indicates better protection against the attack. The ‘Whisper predict (white box)’ attack is particularly significant as it represents a strong white-box attack where the attacker has full knowledge of the SILENCE system’s architecture and weights.
In-depth insights#
Asymmetric Dependency#
The concept of “Asymmetric Dependency” in the context of speech understanding is a crucial observation. It highlights the different ways in which Automatic Speech Recognition (ASR) and Speech Language Understanding (SLU) tasks rely on temporal information within speech signals. ASR, focused on phonetic detail, exhibits a short-term dependency, relying heavily on immediate acoustic context for accurate phoneme recognition. In contrast, SLU, aiming to grasp utterance meaning, shows a long-term dependency, integrating information across the entire utterance to infer the overall intent. This asymmetry is key to the proposed system’s efficiency and efficacy. By strategically obscuring short-term details (masking) that are crucial to ASR but not essential to SLU, the system successfully protects sensitive information while maintaining high SLU accuracy. This approach leverages the inherent difference in temporal dependencies between the tasks for effective privacy-preserving speech understanding, offering a lightweight and resource-efficient solution for resource-constrained devices. The system design cleverly exploits the differences to enhance both privacy and utility.
Lightweight Encoder#
A lightweight encoder for speech processing is crucial for resource-constrained devices. Reducing computational complexity and memory footprint are key objectives. This often involves simplifying the model architecture (e.g., fewer layers, smaller parameter count) or employing efficient techniques like pruning or quantization. Maintaining speech understanding accuracy while achieving this reduction is a significant challenge. A successful lightweight encoder would strike a balance between model size/complexity and performance, enabling real-time speech processing on devices with limited resources. Techniques such as knowledge distillation, selective masking, or asymmetric dependency exploitation could prove valuable in creating lightweight encoders that preserve the essential features of the input signal. The trade-off between model size, speed, and accuracy is a critical consideration, and the success will depend on the specific application and available resources.
Interpretable Learning#
Interpretable learning, a crucial aspect of machine learning, focuses on developing models whose decision-making processes are easily understood by humans. This contrasts with “black box” models where the internal workings remain opaque. The paper’s use of interpretable learning is particularly noteworthy because it allows for the creation of a lightweight, privacy-preserving system. By leveraging an interpretable learning-based differential mask generator, the system can selectively mask sensitive information in audio signals without compromising speech understanding performance. This approach is highly efficient, offering speed and memory improvements compared to existing methods and therefore enabling deployment on resource-constrained devices. Furthermore, the interpretability aspect is key to understanding how and why the system protects privacy, which enhances its reliability and trustworthiness, and offers a path for refining the masking process. The focus on interpretability is a significant contribution as it moves beyond simply achieving privacy and accuracy goals towards providing transparent and explainable AI.
Privacy-Preserving SLU#
Privacy-preserving spoken language understanding (SLU) tackles the critical challenge of safeguarding user privacy in cloud-based speech processing. Current cloud-based SLU solutions often expose sensitive user data, raising serious privacy concerns. Disentanglement-based approaches attempt to address this by separating sensitive information from speech content before cloud processing, but they are computationally expensive and memory intensive, making them unsuitable for resource-constrained devices. A key challenge is to develop methods that effectively protect privacy without significantly compromising accuracy and that are efficient enough to run on low-power devices. This demands innovative techniques, such as selective masking of less critical data or using lightweight encoders, to achieve a practical balance between privacy and usability. Future research should focus on improving the efficiency and robustness of privacy-preserving SLU methods, especially for resource-constrained environments. Additionally, exploring the trade-offs between different privacy-enhancing techniques and their impact on specific SLU tasks is crucial.
Resource Efficiency#
The research paper highlights the crucial aspect of resource efficiency in the context of privacy-preserving speech understanding. SILENCE, the proposed system, demonstrates a significant improvement by achieving up to 53.3x speedup and 134.1x reduction in memory footprint compared to existing approaches. This is achieved through a novel asymmetric dependency-based encoder and a lightweight differential mask generator. The system’s efficiency is particularly vital for resource-constrained devices, such as embedded mobile systems, expanding the applicability of privacy-preserving speech processing. The low memory usage (394.9KB) and fast encoding speed (912.0ms) of SILENCE open the door for real-time applications on devices with limited resources, making the privacy-preserving capabilities accessible to a broader range of platforms.
More visual insights#
More on figures

This figure shows a bar chart comparing the cost (memory usage and inference time) of using disentanglement-based encoders for privacy-preserving speech understanding on three different platforms: Raspberry Pi 4B (RPI-4B), Jetson TX2 (TX2), and an OnDevice approach (directly on the device). It highlights that disentanglement-based methods require significant resources (648.7MB memory and 12.8s on RPI-4B), making them impractical for resource-constrained devices. The OnDevice approach is included as a baseline, showing the tradeoff between offloading to the cloud and local execution time. The figure supports the paper’s argument that these methods are unsuitable for resource-constrained devices.

This figure illustrates the SILENCE system’s workflow. The user’s speech is processed by the SILENCE system, which utilizes a mask generator to selectively obscure short-term dependencies in the audio signal. This masked audio is then sent to the cloud for intent classification, preserving privacy while maintaining accuracy. The red lines highlight the long-term dependencies crucial for intent recognition, while the green lines show short-term dependencies that are masked to protect privacy.
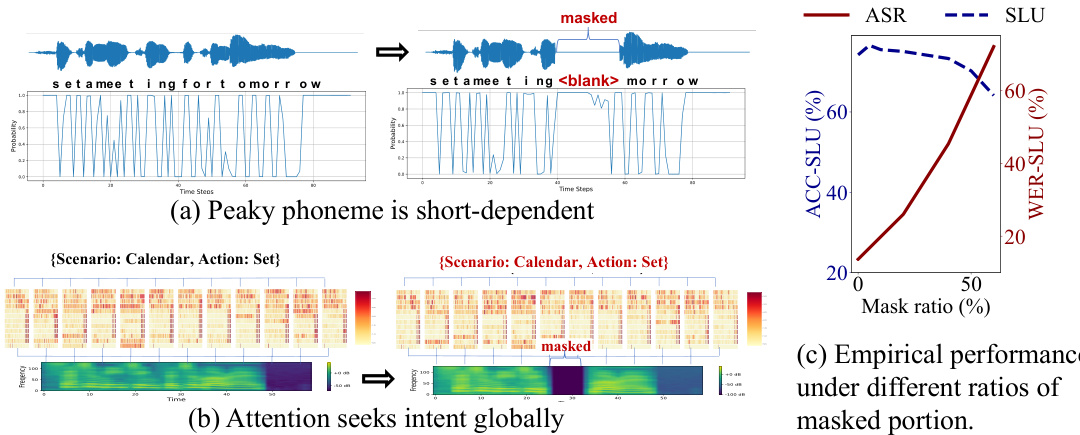
This figure demonstrates the core idea behind SILENCE, highlighting the asymmetrical dependency between Automatic Speech Recognition (ASR) and Spoken Language Understanding (SLU) tasks. (a) shows that ASR heavily relies on short-term dependencies, focusing on individual phonemes. (b) illustrates that SLU leverages long-term dependencies across the whole utterance to understand intent. (c) presents empirical results showing the SLU accuracy and ASR word error rate under varying levels of masked audio segments, demonstrating that selectively masking portions of the audio doesn’t significantly affect SLU performance but greatly improves privacy protection.

This figure illustrates the two phases of the SILENCE workflow for privacy-preserving speech understanding. The offline phase involves training a mask generator (1a) to selectively obscure sensitive information in the audio and adapting the cloud-based SLU model to handle the masked audio (1b). The online phase uses the trained mask generator to process new audio and sends the masked version to the cloud for intent classification.
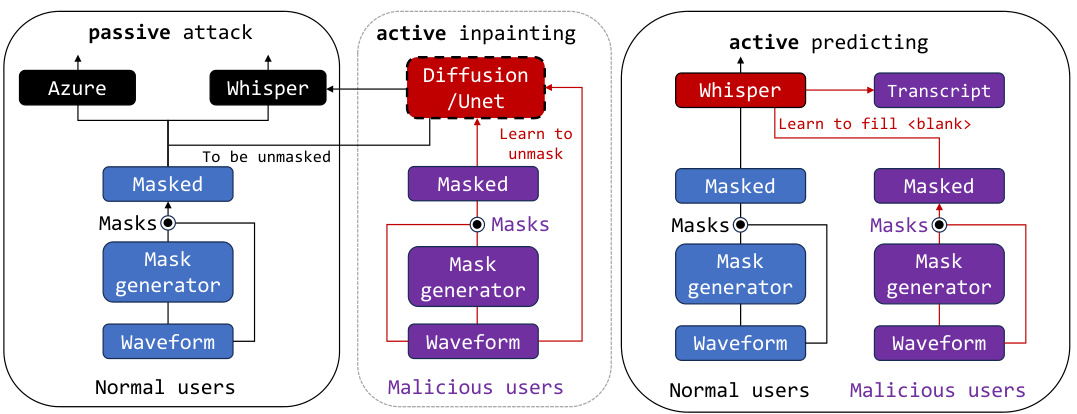
This figure illustrates the system architecture of SILENCE and various attack scenarios. It showcases three attack types: passive attacks, active inpainting attacks, and active predicting attacks. Passive attacks utilize pre-trained models like Azure and Whisper to transcribe the masked audio. Active inpainting attacks leverage models like Diffusion or U-Net to reconstruct the masked portions of the audio before transcription. Active predicting attacks use a model like Whisper to predict and fill in the masked sections of the audio, before transcription. The figure highlights how the system’s mask generator is used in each scenario, and it shows the involvement of both normal and malicious users.

This figure compares the performance of different privacy-preserving spoken language understanding (SLU) systems, including SILENCE, VAE, PPSLU, and others. It shows a Pareto-like tradeoff between accuracy (ACC-SLU) and privacy protection (WER-ASR). The results indicate that SILENCE achieves comparable accuracy to other methods while offering significantly better privacy protection, particularly in multi-task settings. It also shows a low entity error rate (EER), further demonstrating that SILENCE is effective at protecting sensitive information within the speech.

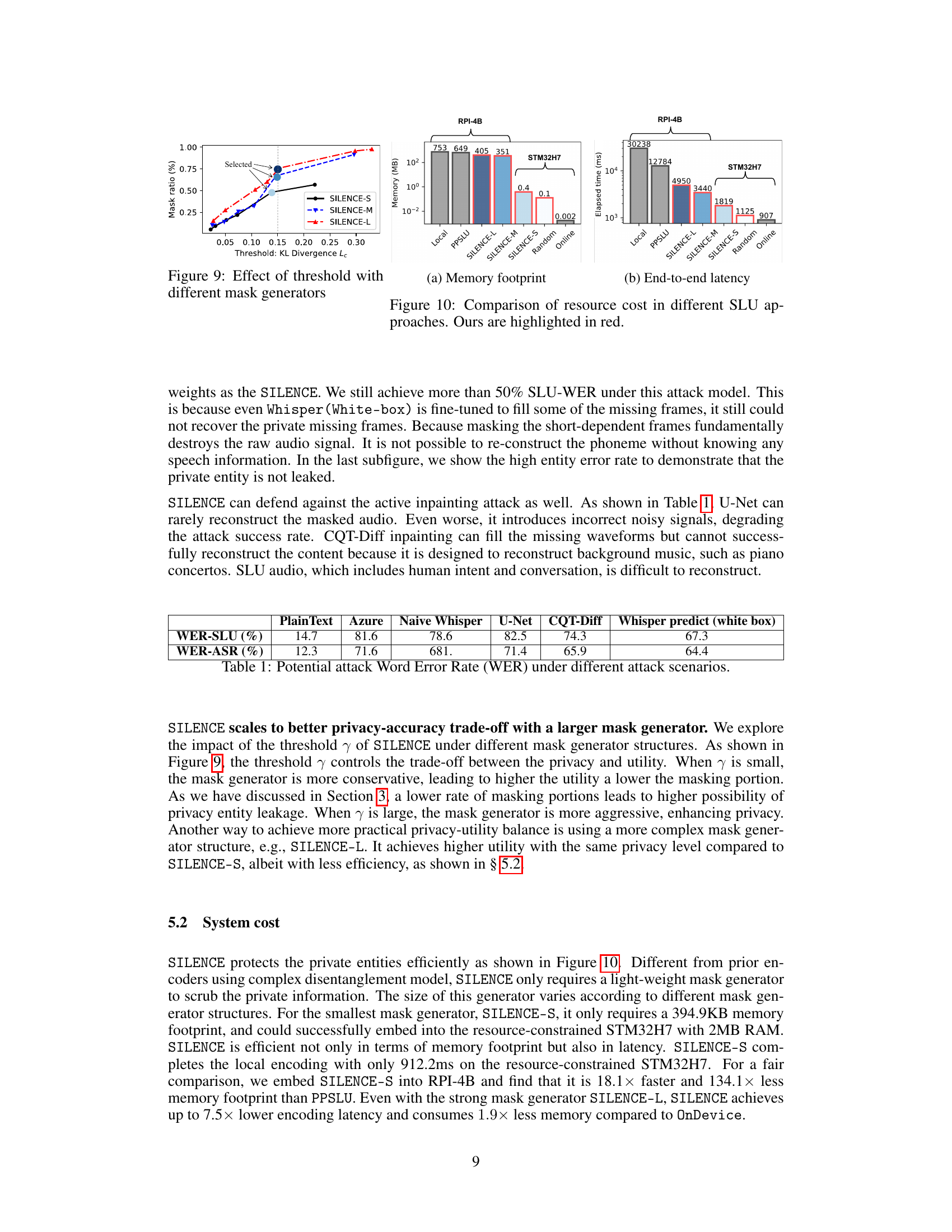
This figure shows the effect of the threshold (KL Divergence Lc) on the mask ratio for different mask generator structures (SILENCE-S, SILENCE-M, SILENCE-L). As the threshold increases, indicating a stronger emphasis on privacy, the mask ratio also increases. The figure demonstrates that more complex mask generators (SILENCE-M and SILENCE-L) achieve a higher mask ratio for the same threshold value, suggesting better privacy protection compared to SILENCE-S. The arrow indicates the selected parameters that lead to a good trade-off between privacy and utility.
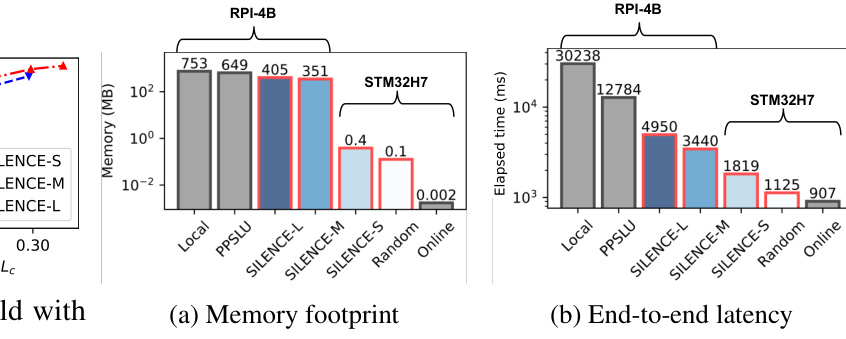
This figure compares the memory footprint and end-to-end latency of different SLU (spoken language understanding) approaches on two devices, RPI-4B and STM32H7. The approaches compared include: * Local: Running the SLU model entirely on the device. * PPSLU: A state-of-the-art privacy-preserving SLU system that uses disentanglement-based encoders. * SILENCE (S, M, L): Variants of the proposed SILENCE model with varying complexities (S - small, M - medium, L - large). * Random: A baseline approach using a random masking strategy. * Online: Running the model online and uploading audio. The figure clearly demonstrates that SILENCE offers significantly reduced memory footprint and latency compared to other methods, especially PPSLU, while still maintaining reasonable performance. The STM32H7 results show the suitability for resource-constrained devices.

This figure illustrates three different approaches to offloaded speech understanding on resource-constrained devices. (a) shows the basic setup where raw audio is sent to the cloud for processing. (b) shows a previous approach using disentangled encoders to remove sensitive information before sending to the cloud. (c) shows the proposed SILENCE method, which selectively obscures short-term details in the audio signal before sending it to the cloud for processing. The goal is to protect user privacy while maintaining the accuracy of speech understanding.
This figure illustrates the architecture of the SILENCE system. It shows how the system processes an audio input, selectively masking portions of the audio based on the observation that speech understanding (SLU) relies heavily on long-term dependencies in the utterance while privacy-sensitive aspects tend to be localized in shorter timeframes. A mask generator determines which segments of the audio to mask before forwarding it to the cloud for intent extraction. The red line signifies long-term dependencies important for SLU, while the green dotted line depicts shorter-term dependencies that might contain privacy-sensitive data and are selectively masked.
More on tables

This table presents a comparison of different privacy-preserving techniques for spoken language understanding (SLU) on the Fluent Speech Commands (FSC) dataset. It shows the accuracy of SLU (ACC-SLU) and the word error rate of an automatic speech recognition (ASR) attack (WER-ASR) for several methods: AllOffloaded (no privacy protection), VAE (variational autoencoder), PPSLU (a prior state-of-the-art method), Local (on-device processing), Random (random masking), and SILENCE (the proposed method). The results demonstrate the effectiveness of SILENCE in balancing privacy and utility.

This table presents the performance of different privacy-preserving SLU approaches on a conventional modularized SLU system. It compares the intent classification accuracy (SLU-ACC) achieved by different methods, including the plaintext approach (no privacy preservation), VAE, PPSLU, and three versions of the proposed SILENCE method. The different versions of SILENCE correspond to using the NLU only, a decoupled SLU architecture, and an end-to-end SLU architecture, demonstrating the impact of different levels of integration with the existing SLU model. The results show that even with a modularized approach, SILENCE achieves competitive results.

This table compares the performance of different privacy-preserving SLU approaches across various speech granularities (scenario, action, intent). It shows the accuracy of each approach in correctly identifying the scenario, action, and intent, as well as the word error rate (WER) for SLU and ASR tasks. The ‘/’ indicates that a specific granularity is not supported by that method. Notably, the ‘Local’ approach achieves perfect privacy (WER = 100%) as no data is uploaded to the cloud, but it does not preserve speech understanding performance compared to others. This table highlights the effectiveness of the proposed approach (‘Ours’) in achieving a good balance between privacy and SLU performance across different granularities.
Full paper#