↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing methods for 3D scene reconstruction from images often struggle with sparse views, large-scale scenes, and runtime efficiency. Techniques like Neural Radiance Fields (NeRFs) are often slow and require many images, while lower-resolution methods result in blurry reconstructions. This paper addresses these challenges.
The proposed method, SCube, employs a novel representation called VoxSplats to encode 3D scenes efficiently and accurately. It uses a hierarchical voxel latent diffusion model conditioned on input images to generate high-resolution grids, followed by an appearance prediction network. SCube demonstrates significantly faster reconstruction times and superior visual quality compared to existing methods, particularly when dealing with sparse image data. This makes it suitable for applications such as LiDAR simulation and text-to-scene generation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SCube, a novel and efficient method for large-scale 3D scene reconstruction using a new representation called VoxSplats. This significantly advances the field by enabling high-quality 3D scene reconstruction from sparse images, overcoming limitations of existing methods. The applications presented, such as LiDAR simulation and text-to-scene generation, show its potential impact across various domains. Its feed-forward approach makes it faster than many existing methods and could potentially accelerate research in areas such as autonomous driving and virtual/augmented reality.
Visual Insights#

This figure shows the overall pipeline of SCube. Given a set of sparse input images (with little to no overlap), SCube reconstructs a high-resolution and large-scale 3D scene. This 3D scene is represented using VoxSplats, a novel representation combining sparse voxel grids with Gaussian splats for efficient rendering. The reconstructed scene can then be used for various downstream tasks, such as novel view synthesis (generating images from unseen viewpoints) and LiDAR simulation (creating realistic LiDAR point clouds).
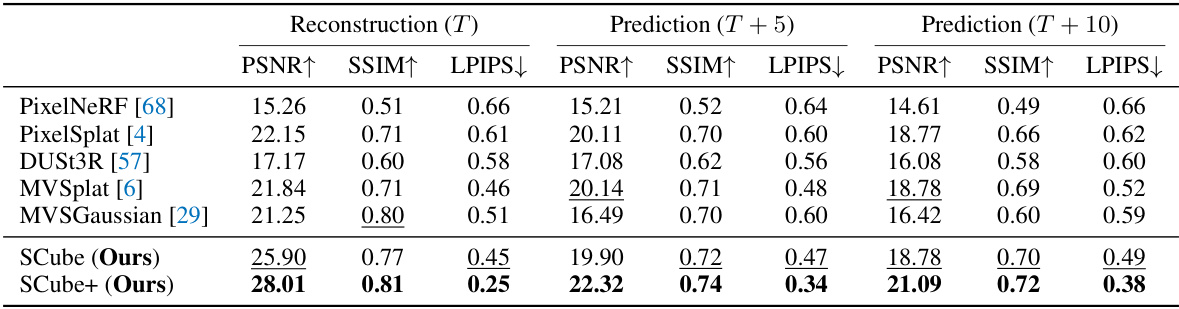
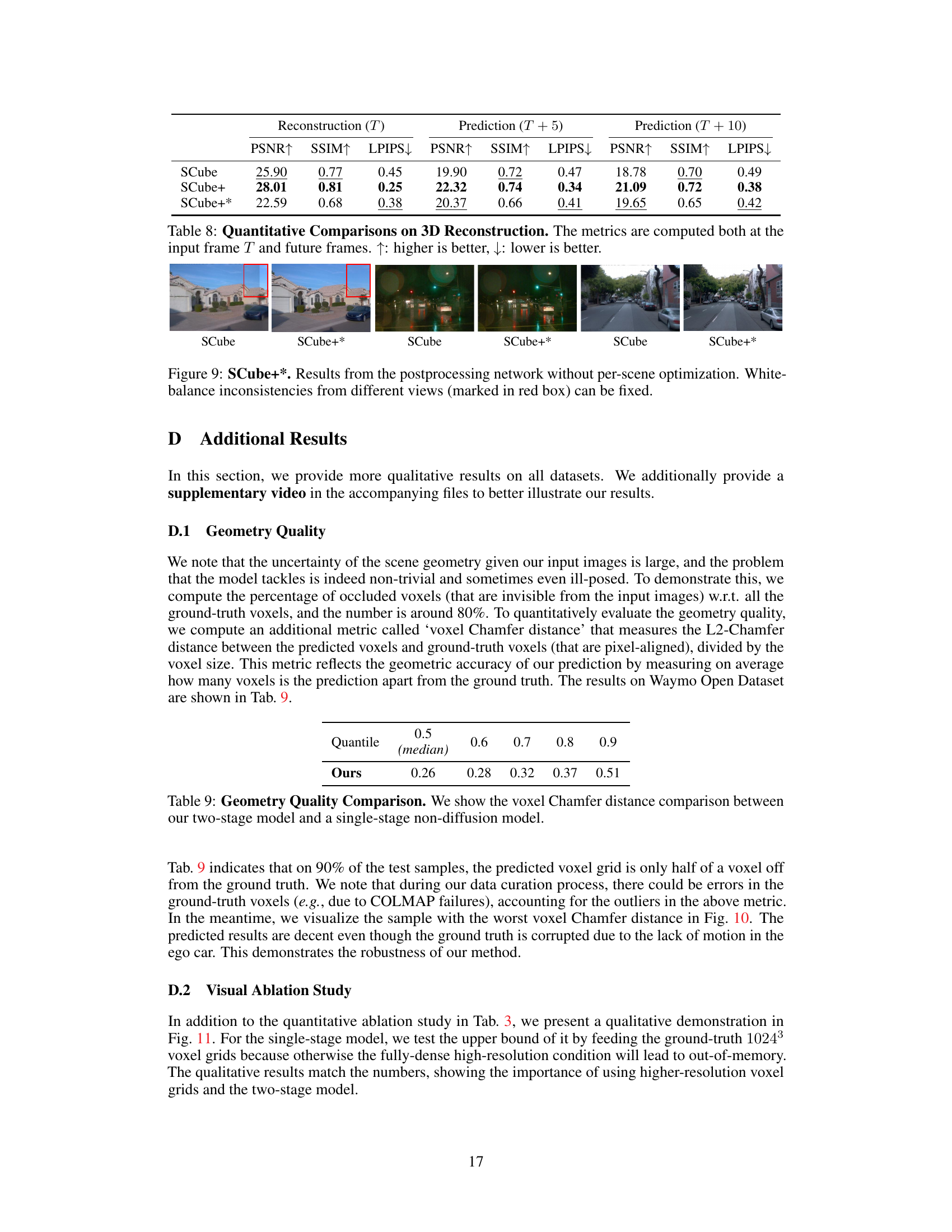
This table presents a quantitative comparison of the proposed SCube method against several baselines for 3D scene reconstruction. The metrics used are Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The evaluation is performed on both the input frame (T) and predicted future frames (T+5 and T+10). Higher PSNR and SSIM values, along with lower LPIPS values, indicate better reconstruction quality. The table demonstrates that SCube+ significantly outperforms all the baselines across all metrics and time frames, indicating the effectiveness of the proposed approach.
In-depth insights#
VoxSplat Encoding#
The novel VoxSplat encoding scheme is a key contribution, representing 3D scenes as a collection of 3D Gaussians positioned on a sparse voxel grid. This hybrid approach cleverly combines the strengths of both Gaussian splatting (efficient rendering) and sparse voxel hierarchies (scalable 3D scene modeling). The sparse grid allows for efficient processing of large-scale scenes, avoiding the memory limitations of dense representations. The embedding of Gaussians within each voxel provides a powerful way to capture detailed appearance information, significantly enhancing the quality of reconstructions. This representation is particularly effective for reconstructing scenes from sparse views, a challenging problem in 3D reconstruction. By learning from images a hybrid representation comprising a sparse voxel grid alongside attributes for the Gaussians, the authors enable sharp and detailed reconstructions. The framework’s effectiveness relies heavily on the efficiency of sparse convolutional networks, enabling fast inference speeds and reducing memory demands. The design directly addresses the need for computationally efficient and high-quality large-scale 3D scene representation, particularly beneficial for applications like novel-view synthesis and LiDAR simulation.
Sparse-View Recon#
Sparse-view 3D reconstruction is a challenging problem because limited viewpoints hinder accurate scene capture. Traditional methods often fail due to insufficient correspondences. Learning-based approaches offer a promising solution, utilizing deep learning models to predict 3D geometry and appearance. However, existing methods struggle with 3D inconsistencies and low resolutions. They may also not generalize well to diverse scenes or handle sparse views effectively. The key to success lies in incorporating effective data priors and robust 3D representations. High-resolution sparse voxel grids combined with splatting techniques offer a good balance of detail and efficiency, enabling faster processing and better quality reconstructions. Methods leveraging conditional generative models or feed-forward networks for direct scene reconstruction show potential, but require careful design of network architecture and loss functions for optimization. Future research could focus on more advanced representations, better priors, improved model training techniques, and tackling the problem of extrapolating scene information beyond the input views. Overall, significant advancements are needed to achieve robust, high-resolution, large-scale reconstruction from sparse viewpoints.
Generative Models#
Generative models are transforming 3D scene reconstruction by offering a powerful approach to synthesize realistic and complex 3D environments from limited data. Unlike traditional methods that rely heavily on explicit geometric priors or dense view coverage, generative models learn implicit representations that capture intricate scene details and semantics. This allows for novel view synthesis, scene completion from sparse views, and even text-to-3D scene generation, pushing the boundaries of what’s possible in 3D reconstruction. The use of deep learning architectures, such as diffusion models and neural networks, has been key to the advancements in this area. However, challenges remain. Generating high-resolution, consistent scenes remains computationally demanding, and many models are trained on specific datasets which can limit generalization. Ensuring accurate representation of both geometry and appearance remains a significant hurdle, and effective methods for incorporating semantic information are still under active research. Despite these challenges, the potential of generative models to revolutionize 3D scene reconstruction is undeniable. Future research promises more efficient architectures, enhanced data augmentation strategies, and improved methods for handling complex scene characteristics, which will lead to even more impressive results.
LiDAR Simulation#
The research paper explores LiDAR simulation as a key application of its novel 3D scene reconstruction method. This is a crucial aspect because accurate and efficient LiDAR data generation is essential for training and validating autonomous driving systems. The approach leverages the high-resolution Gaussian splat representation of the reconstructed scene, allowing for direct ray-tracing to simulate LiDAR point clouds. This method is particularly advantageous in scenarios with limited or sparse camera views because it can generate consistent point clouds even where sensor coverage is incomplete. Furthermore, the inherent structure of the voxel scaffold in the scene representation ensures a high level of geometric consistency, reducing artifacts and floaters that are common in other LiDAR simulation techniques. The paper highlights the method’s ability to produce temporally consistent LiDAR scans, which is critical for autonomous driving applications requiring accurate trajectory predictions and motion estimations. The seamless integration of this functionality with the proposed reconstruction framework demonstrates its practical value in real-world applications beyond novel view synthesis, suggesting a broader impact for both computer vision and autonomous driving research.
Future Directions#
Future research could explore several promising avenues. Improving the handling of dynamic objects and challenging weather conditions is crucial for real-world applicability. The current method struggles with moving elements and variations in lighting, limiting its performance in dynamic outdoor scenes. Further research into incorporating temporal consistency and robust motion modeling would significantly enhance scene reconstruction capabilities. Improving the model’s ability to extrapolate beyond the input views is also vital. While the paper shows progress, the quality of reconstructions tends to degrade in regions further away from observed viewpoints. Developing methods to better leverage data priors, potentially through integrating semantic information or other context-rich data sources, could greatly enhance extrapolation capacity. Finally, exploring more efficient sparse representations and network architectures would be beneficial for processing even larger-scale datasets and achieving faster reconstruction times. The current model’s efficiency, while impressive, could benefit from further optimization.
More visual insights#
More on figures
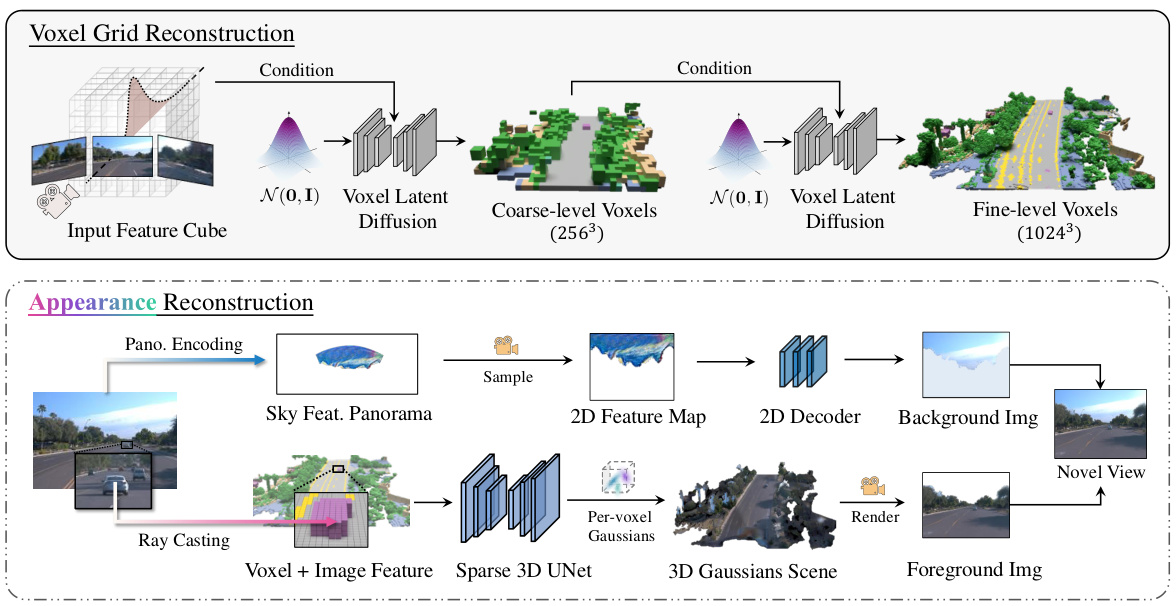
This figure illustrates the two-stage framework of SCube. The first stage reconstructs a sparse voxel grid using a conditional latent diffusion model, conditioned on input images. This model progressively generates high-resolution grids in a coarse-to-fine manner, leveraging a hierarchical voxel latent diffusion model and incorporating semantic information. The second stage predicts the appearance of the scene, represented as VoxSplats (a novel representation combining Gaussian splats and a sparse voxel hierarchy), and a sky panorama using a feedforward network. This combination allows for fast and accurate novel view synthesis, as well as other applications. The figure visually depicts the process and different components at each stage.
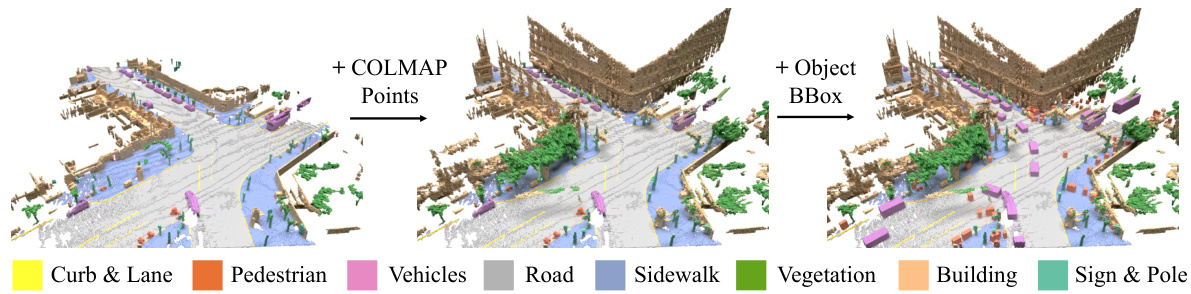
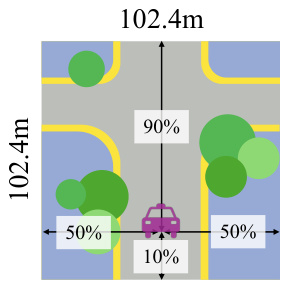
This figure illustrates the data processing pipeline used to create a more complete and accurate 3D geometry dataset for training the model. It shows three stages: 1. Accumulating LiDAR points, removing points within bounding boxes of dynamic objects. 2. Adding dense 3D points from COLMAP multi-view stereo (MVS) reconstruction, and obtaining semantic labels. 3. Adding point samples for dynamic objects (according to bounding boxes). This results in static and accumulated ground truths for training, with each sample being a 102.4m x 102.4m cropped chunk centered around a random ego-vehicle pose, with more space allocated for the forward direction.

This figure compares the novel view synthesis capabilities of the SCube+ method with several baseline methods. It presents synthesized views from different perspectives (front-left, front, front-right) at timestamps T+5 and T+10, showing how well each method reconstructs the scene and generates novel views. The insets provide a top-down perspective for each image, highlighting the differences in 3D scene reconstruction accuracy and completeness.
This figure compares the novel view synthesis capabilities of the proposed SCube+ method against several baseline methods. It shows the rendered novel views from three different perspectives (front-left, front, and front-right) for both the proposed method and the baselines, along with a top-down view of the reconstructed 3D scene to illustrate the model’s ability to generate extreme novel viewpoints.

This figure compares the 3D scene reconstruction results of the proposed SCube method against the Metric3Dv2 method, using sparse input views. The top row shows input images from two different scenes. The bottom row displays the 3D point clouds generated by each method for the respective scenes. The color-coding represents semantic information obtained from Segformer [64]. The visualization highlights the differences in geometry reconstruction accuracy and completeness between the two methods. SCube demonstrates superior performance in reconstructing the scene geometry accurately and completely, especially in regions where views are sparse.

This figure shows the results of LiDAR simulation using the SCube model. Two examples are presented, each consisting of a single input front view image and a sequence of simulated LiDAR point clouds generated by moving the camera 60 meters forward. The LiDAR point clouds accurately reflect the underlying 3D geometry of the scene, demonstrating the ability of SCube to produce consistent and temporally coherent LiDAR sequences. This capability is crucial for the training and verification of autonomous driving systems.

This figure shows the overall pipeline of SCube, which reconstructs a high-resolution large-scale 3D scene from sparse input images with minimal overlap. The left side shows the input images, and the right side shows the 3D reconstruction rendered from novel viewpoints. This demonstrates the ability of SCube to generate novel views and simulate LiDAR data from limited input.

This figure compares novel view synthesis results from SCube+ with several baseline methods. It shows renderings from three standard viewpoints (front-left, front, front-right) as well as an extreme viewpoint (top-down view) for a better understanding of the 3D scene reconstruction. This comparison highlights the quality and completeness of SCube+’s scene representation and its ability to synthesize novel views.

This figure shows the results of applying an optional GAN-based post-processing step to the novel view synthesis results. The leftmost column shows results from the SCube model without post-processing. The rightmost column shows the results after applying the post-processing step. This post-processing step addresses some artifacts and inconsistencies in the rendered images that may result from the main reconstruction method. The red boxes highlight regions where the post-processing step successfully corrects for white-balance inconsistencies present in the original render.
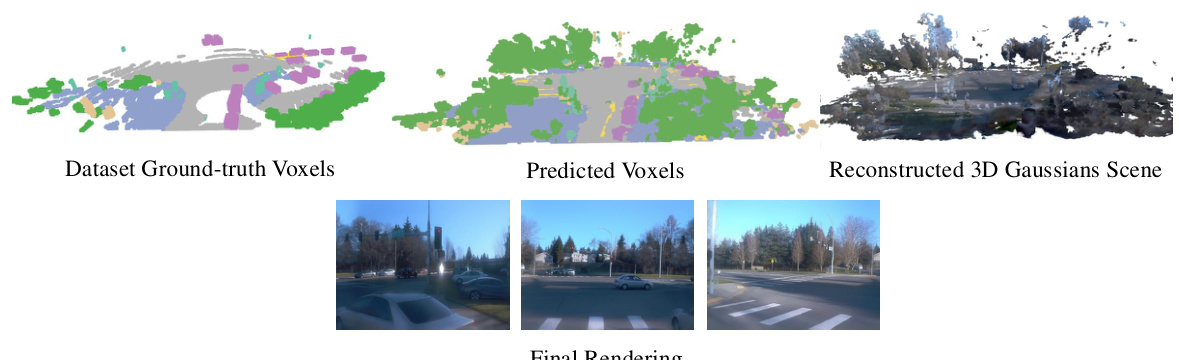
This figure displays the results for the data sample with the highest voxel Chamfer distance, which measures the geometric difference between the predicted and ground truth voxels. It shows the ground truth voxels, predicted voxels, the reconstructed 3D Gaussian scene, and finally the rendered images from different viewpoints. The visualization helps illustrate the accuracy of the method despite challenging conditions.

This figure compares the novel view synthesis capabilities of SCube+ with several baseline methods. It shows the rendered images from three different viewpoints (front-left, front, front-right) for both the input views and newly synthesized views at two future time steps. The insets provide a top-down view of the reconstructed 3D scene, demonstrating the model’s ability to generate views from unusual perspectives.

This figure shows the overall pipeline of SCube. Given a set of sparse input images with minimal overlap, the SCube model reconstructs a high-resolution, large-scale 3D scene. The scene is represented using VoxSplats, a novel representation based on 3D Gaussians. The reconstructed scene can be used for various applications, including novel view synthesis (generating images from unseen viewpoints) and LiDAR simulation (creating simulated LiDAR point clouds).

This figure showcases the SCube model’s ability to reconstruct a high-resolution, large-scale 3D scene from only a few sparse input images, even with minimal overlap. The reconstructed scene is represented using VoxSplats, a novel representation that makes it efficient to generate novel views or simulate LiDAR data.

This figure shows the overall pipeline of SCube. Given a small number of input images (even with little to no overlap), the model reconstructs a large-scale, high-resolution 3D scene. This 3D scene is encoded using a novel representation called VoxSplats, a combination of Gaussian splats on a sparse voxel grid. The reconstructed scene can be used to generate novel views or simulate LiDAR data.

This figure shows the overall pipeline of SCube. Given a set of sparse input images (with little or no overlap), SCube reconstructs a high-resolution and large-scale 3D scene. The reconstructed scene is represented using a novel representation called VoxSplats. VoxSplats are ready to be used for various downstream tasks such as novel view synthesis (generating images from viewpoints not present in the input) and LiDAR simulation (simulating LiDAR scans of the scene from new locations). The figure visually demonstrates the input images, the reconstruction process, and the resulting novel views.

This figure demonstrates the overall pipeline of SCube. Given a set of sparse input images with minimal overlap, the model reconstructs a high-resolution, large-scale 3D scene. This 3D representation, called VoxSplat, is a combination of Gaussian splats on a sparse voxel hierarchy. The reconstructed scene is shown to be useful for novel view synthesis and LiDAR simulation.

This figure shows additional results of LiDAR simulation using the proposed SCube method. It demonstrates the generation of consistent LiDAR point cloud sequences from input front views. The sequences show the simulated LiDAR scan as the virtual camera moves forward.

This figure shows the overall pipeline of SCube. Given a sparse set of input images, SCube reconstructs a high-resolution, large-scale 3D scene using a novel representation called VoxSplats. The reconstructed scene can then be used for various applications such as novel view synthesis and LiDAR simulation. The figure visually demonstrates the input images, the reconstruction process, and the resulting novel views.
More on tables

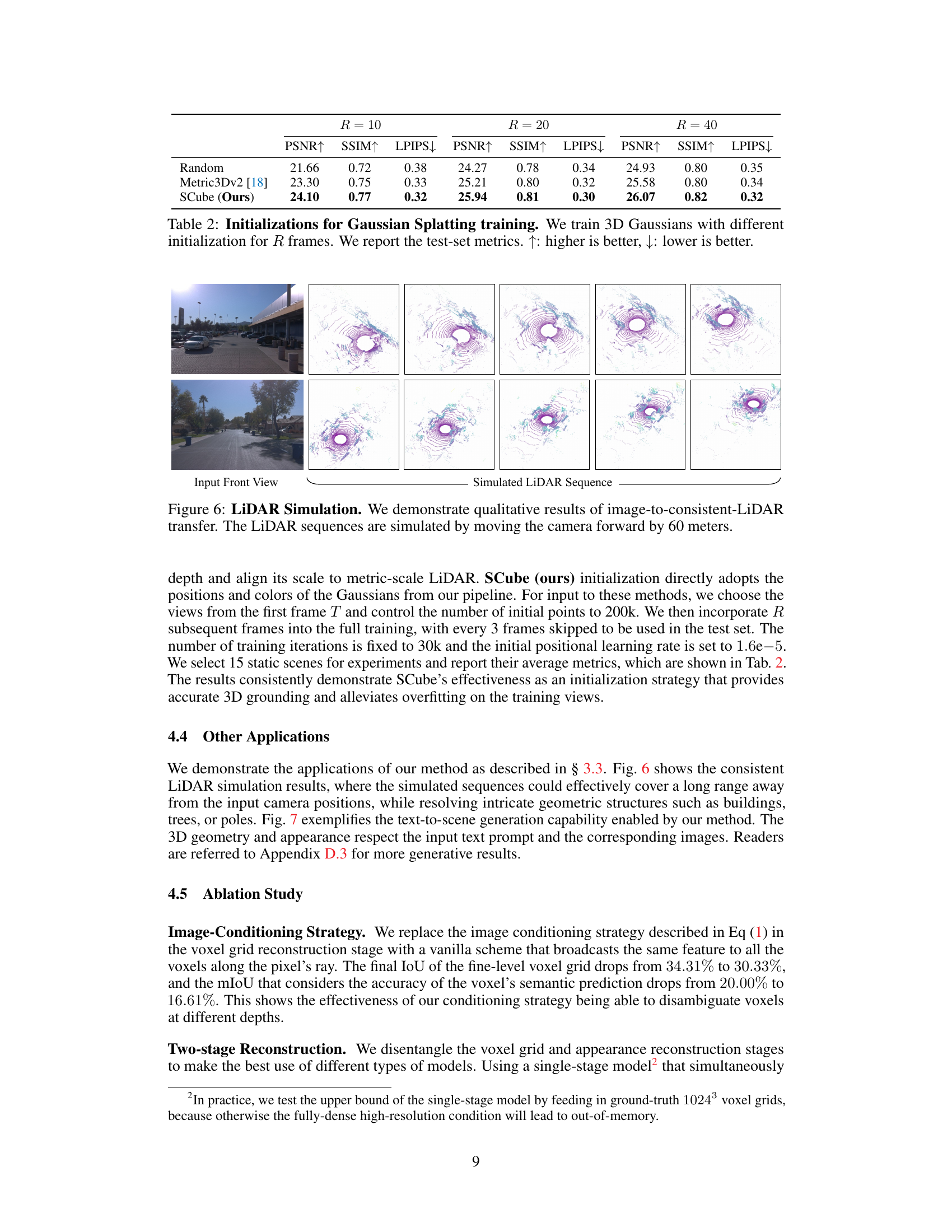
This table compares the performance of three different initialization methods for training 3D Gaussians using Gaussian splatting. The methods are: Random initialization (randomly sampled points), Metric3Dv2 initialization (using depth estimates from the Metric3Dv2 model), and SCube initialization (using the Gaussian splat predictions from the SCube model). The table shows the PSNR, SSIM, and LPIPS metrics for each initialization method, evaluated on test data after training for 10, 20, and 40 frames. Higher PSNR and SSIM values indicate better reconstruction quality, while lower LPIPS indicates better perceptual similarity to the ground truth.
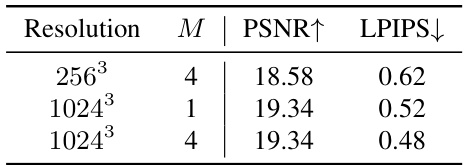
This ablation study investigates the impact of different voxel grid resolutions and the number of Gaussians per voxel (M) on the performance of the appearance reconstruction stage. It shows how these hyperparameters affect PSNR (Peak Signal-to-Noise Ratio) and LPIPS (Learned Perceptual Image Patch Similarity) scores, which measure the quality of novel view synthesis. Higher PSNR values indicate better reconstruction quality, while lower LPIPS scores signify that the synthesized images are more perceptually similar to the ground truth.

This table presents a quantitative comparison of the proposed SCube model with several baseline methods for 3D reconstruction. The metrics used for comparison are Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The results are shown for both the input frame (T) and future frames (T+5 and T+10), demonstrating the model’s ability to reconstruct scenes and predict novel views. Higher PSNR and SSIM scores, and lower LPIPS scores indicate better reconstruction quality.

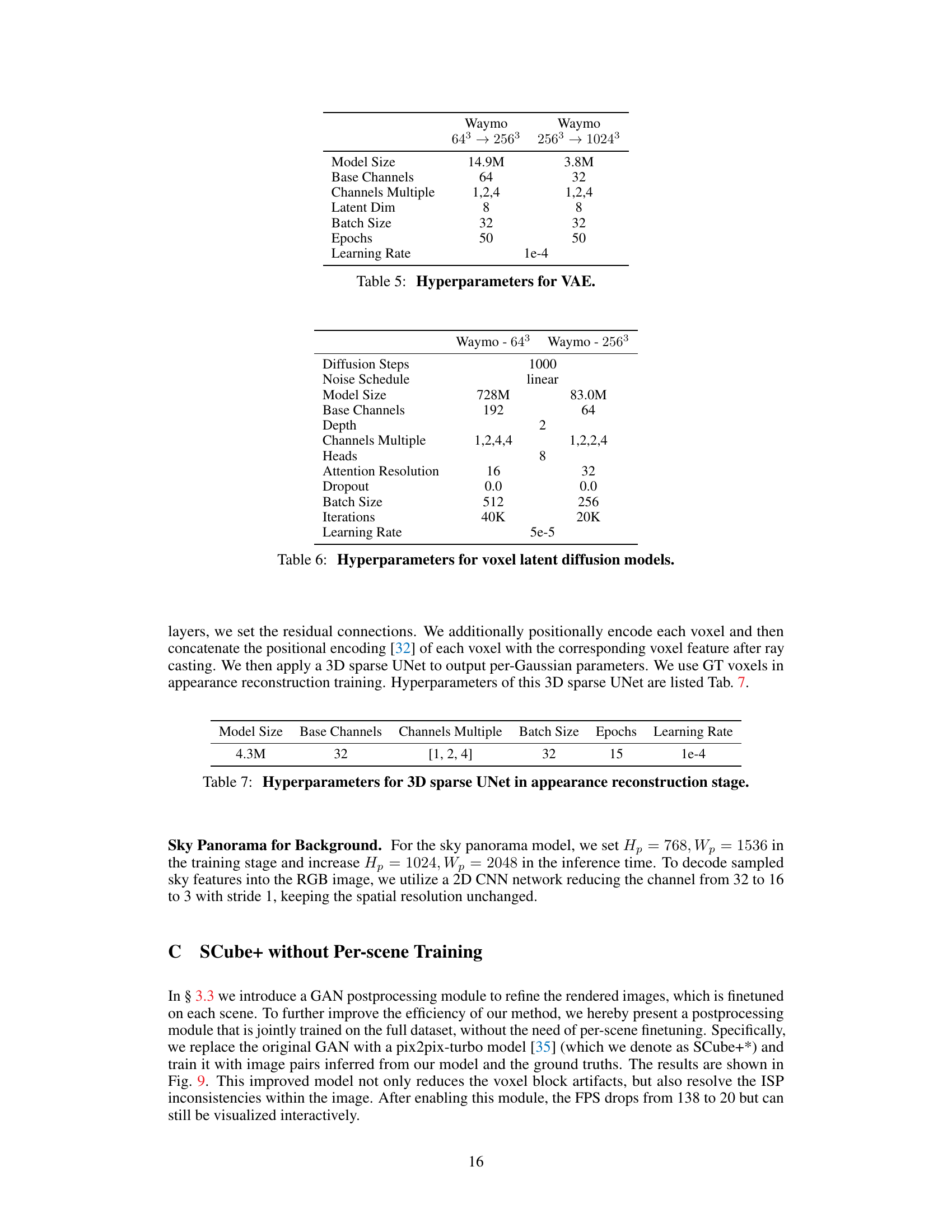
This table presents the hyperparameters used for training the Variational Autoencoder (VAE) in the Voxel Grid Reconstruction stage of the SCube model. It shows the values for different settings on the Waymo dataset, specifically for two different resolutions: 64³ → 256³ and 256³ → 1024³. The hyperparameters include Model Size, Base Channels, Channels Multiple, Latent Dim, Batch Size, Epochs, and Learning Rate.
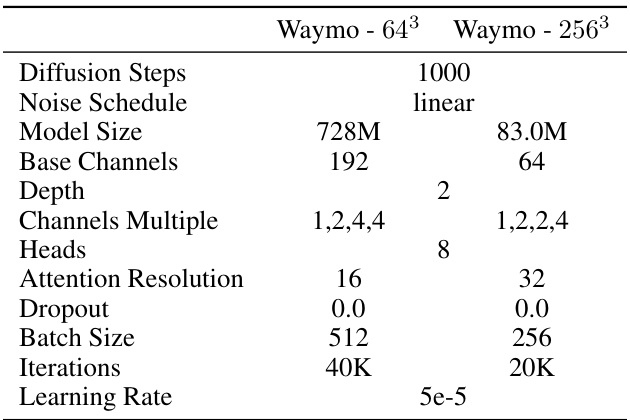
This table lists the hyperparameters used for training the voxel latent diffusion models in the SCube architecture. It breaks down the settings for both the 64³ and 256³ voxel grid resolutions, specifying parameters such as the number of diffusion steps, the noise schedule, model size, base channels, depth, channels multiple, number of heads in the attention mechanism, attention resolution, dropout rate, batch size, number of iterations, and learning rate. These settings are crucial for controlling the generation process and achieving high-quality 3D scene reconstructions.

This table shows the hyperparameters used for training the 3D sparse UNet in the appearance reconstruction stage of the SCube model. It lists the model size, base channels, channels multiple, batch size, number of epochs, and learning rate used during training. These parameters are crucial for controlling the model’s capacity, complexity, and training process, ultimately impacting the quality of the generated appearance.

This table presents a quantitative comparison of the proposed SCube method against several baseline methods for 3D scene reconstruction. The comparison is based on metrics calculated at the input frame (T) and two future frames (T+5 and T+10), evaluating the accuracy of novel view synthesis. Higher PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index Measure) values and lower LPIPS (Learned Perceptual Image Patch Similarity) values indicate better reconstruction quality.

This table presents a quantitative comparison of the proposed SCube model with several baseline methods for 3D reconstruction. The comparison is based on the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS) metrics. Results are shown for both the input frame (T) and for predicted future frames (T+5 and T+10). Higher PSNR and SSIM values, and lower LPIPS values indicate better reconstruction quality.
Full paper#