↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current text-to-video (T2V) generation model evaluation methods primarily focus on temporal consistency and content continuity, neglecting the crucial aspect of video dynamics, which impacts visual vividness and honesty. This leads to models generating low-dynamic videos that ‘cheat’ existing metrics, achieving high scores despite lacking realism.
To tackle this, the paper proposes DEVIL, a novel evaluation protocol emphasizing video dynamics. DEVIL introduces a set of dynamics scores across various temporal granularities (inter-frame, inter-segment, video-level) and a new text prompt benchmark categorized into dynamics grades. DEVIL also improves existing metrics by incorporating the dynamics factor, showing high consistency (90%) with human ratings. The results highlight the limitations of existing models and benchmarks, paving the way for more dynamic and realistic T2V model development.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-video generation because it introduces a novel evaluation protocol, DEVIL, which addresses the shortcomings of existing methods by focusing on video dynamics. DEVIL provides a more comprehensive and human-aligned assessment, opening avenues for developing more realistic and engaging video generation models. It also inspires future work in improving existing benchmarks and developing better text prompts that reflect video dynamics.
Visual Insights#
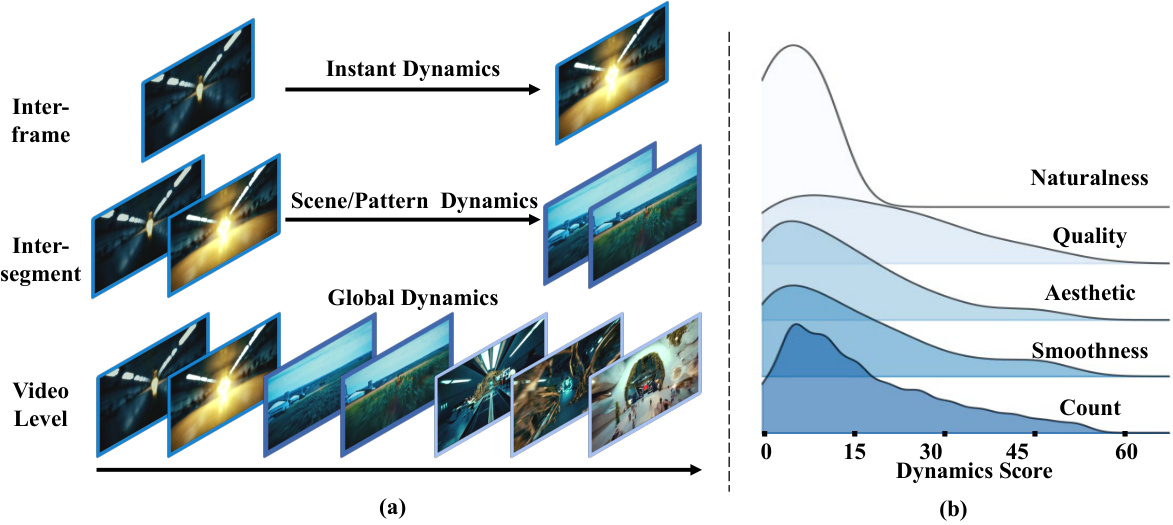
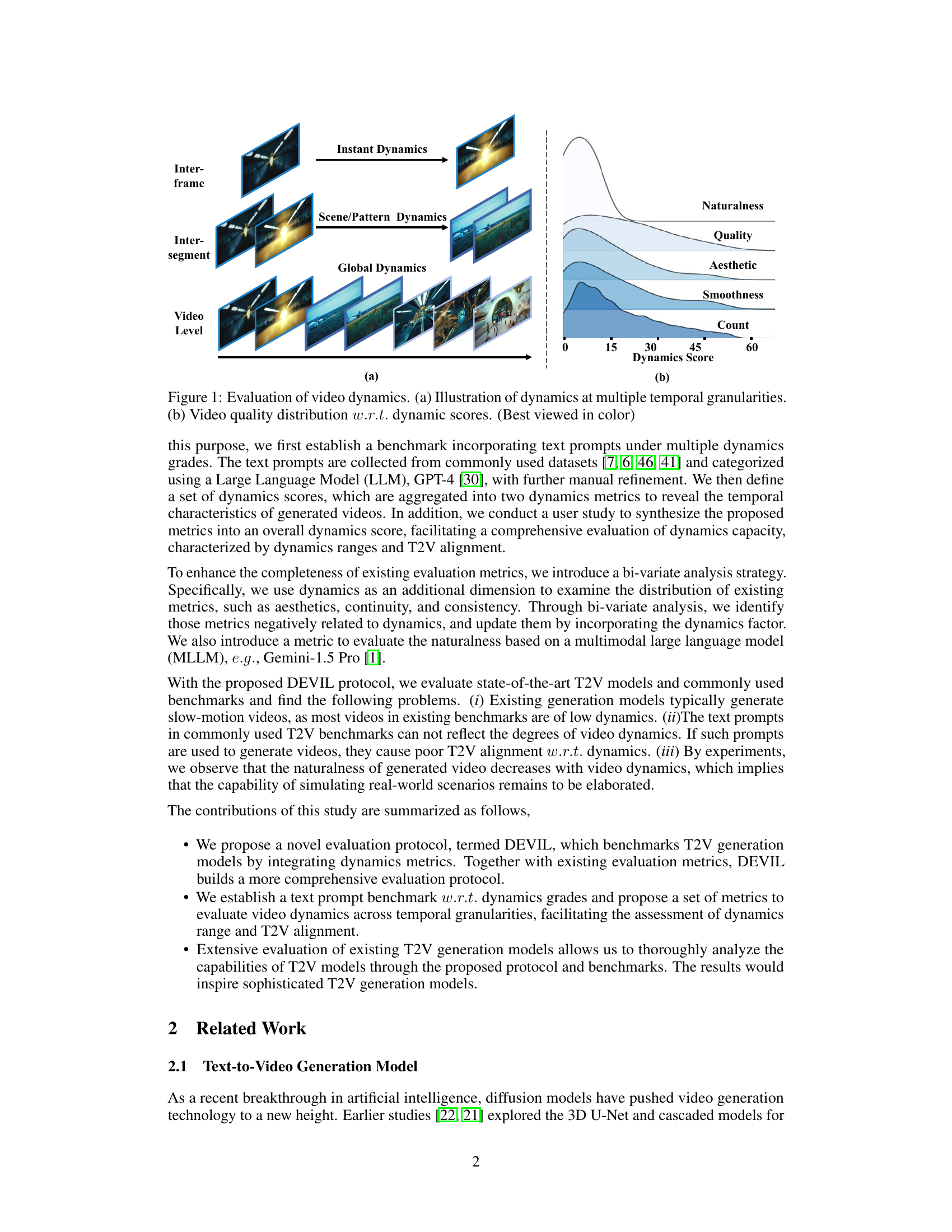
The figure illustrates the concept of video dynamics at multiple temporal granularities. Subfigure (a) shows how dynamics are categorized into three levels: inter-frame, inter-segment, and video-level. Each level represents different temporal scales of changes in the video content. Subfigure (b) demonstrates the relationship between video quality and dynamics scores. It shows how various quality aspects (naturalness, quality, aesthetic, smoothness) change according to different dynamics score values.
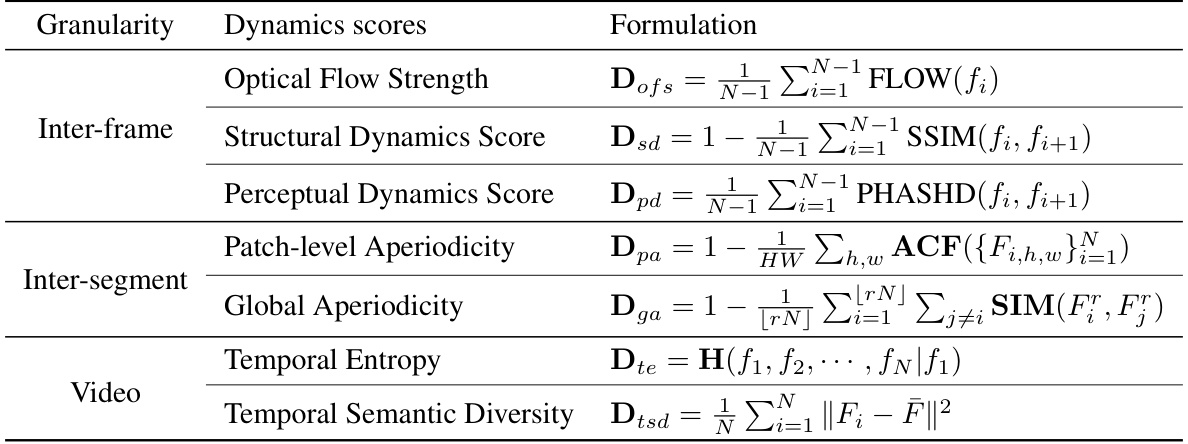
This table presents the mathematical formulas used to calculate dynamics scores at three different temporal granularities: inter-frame, inter-segment, and video-level. Each granularity has multiple dynamics scores, which are combined to provide a comprehensive evaluation of the video’s dynamic properties. The formulas involve metrics like optical flow strength, structural similarity index (SSIM), perceptual hash distance (PHASHD), autocorrelation factor (ACF), and temporal entropy. These scores capture various aspects of video dynamics, from low-level changes between consecutive frames to high-level changes in the overall content.
In-depth insights#
Dynamic Video Eval#
A hypothetical ‘Dynamic Video Eval’ section in a research paper would likely explore methods for assessing the dynamic qualities of videos, moving beyond simple metrics like frame rate. This could involve analyzing motion characteristics, such as speed, acceleration, and smoothness, perhaps using techniques like optical flow analysis. Temporal consistency and content continuity would be assessed, considering how well the visual narrative unfolds and maintains coherence across time. The evaluation might delve into perceptual aspects, examining whether the dynamics match viewer expectations based on context and scene understanding. A robust system would encompass multiple metrics, potentially including quantitative measures (e.g., average motion speed, frequency of significant changes) and qualitative measures (e.g., ratings of visual vividness or engagement). Comparison with human judgment would validate the accuracy and relevance of the proposed metrics. Finally, the discussion should consider the potential limitations of the methods and future directions for advancing dynamic video evaluation.
T2V Dynamics Metrics#
The heading ‘T2V Dynamics Metrics’ suggests an exploration of how to quantify the dynamic aspects of videos generated from text prompts. This is a crucial area because existing metrics often focus on static aspects like visual quality or semantic similarity, neglecting the temporal evolution and motion characteristics inherent in video. Effective T2V models should not only create visually appealing videos but also capture the dynamic nuances expressed in the text prompt. This requires metrics that can assess the speed, smoothness, and variety of motion, as well as the temporal coherence of the narrative. Such metrics could involve analyzing optical flow, motion patterns, temporal changes in scene content, or even higher-level features like the perceived energy or excitement of the video. A robust set of T2V dynamics metrics would likely encompass multiple levels of granularity, analyzing dynamics at the frame level, scene level, and overall video level. This allows for a more comprehensive evaluation of the model’s ability to generate dynamic content and enables a deeper understanding of how different model architectures and training methods affect the generation of dynamic video content. Finally, the development of such metrics would need careful consideration of human perception, ensuring that the metrics correlate well with human judgments of dynamism.
Human Alignment#
The concept of ‘Human Alignment’ in the context of evaluating text-to-video generation models is crucial. It speaks to the closeness between automated evaluation metrics and human perception. The authors acknowledge that existing metrics often fail to capture the nuanced aspects of video quality as perceived by humans, particularly concerning video dynamics. Therefore, a critical component of their proposed methodology, DEVIL, is to calibrate automated scores against human ratings. This is achieved through a user study that establishes a correspondence between the generated videos’ dynamic scores and human assessments of those videos. This human-in-the-loop approach is key to ensuring that the automated evaluation doesn’t merely measure technical performance, but truly reflects the perceptual experience of a viewer. The success of this human alignment process, reflected in high consistency with human judgements, significantly enhances the validity and reliability of the DEVIL evaluation protocol.
Benchmarking T2V#
Benchmarking text-to-video (T2V) models presents unique challenges due to the complexity of video data and the subjective nature of video quality. A robust benchmark needs diverse and representative datasets encompassing various video styles, lengths, and levels of dynamic action. Metrics should go beyond simple visual fidelity and consider temporal consistency, semantic coherence, and the accuracy of video content relative to the text prompt. Human evaluation is crucial for establishing ground truth, but it’s expensive and time-consuming, so automated metrics that correlate well with human perception are essential. Addressing bias in existing datasets is also key, as many datasets over-represent certain video types, leading to skewed evaluation results. Ideally, a strong benchmark would enable objective comparison across models, identify areas for improvement in different aspects of video generation, and ultimately drive the development of more effective and versatile T2V models.
Future of T2V#
The future of text-to-video (T2V) generation is brimming with potential. Improved evaluation metrics, like those focusing on video dynamics, are crucial for advancing model capabilities beyond simple content accuracy and temporal consistency. More sophisticated benchmarks incorporating diverse prompt types and dynamic ranges will drive development of models that generate richer, more realistic videos. Addressing inherent biases in existing datasets, such as an overrepresentation of low-dynamic videos, is essential for unbiased model training. The integration of advanced large language models and multimodal AI will enable more nuanced and context-aware video generation, bridging the gap between textual descriptions and visually compelling output. Further research into long-form video synthesis, higher resolutions, and efficient inference methods will likely lead to broader applications and wider accessibility of T2V technologies.
More visual insights#
More on figures

This flowchart illustrates the DEVIL evaluation protocol. It shows how text prompts are used to generate videos using various T2V models. The generated videos are then analyzed using the defined dynamics scores (inter-frame, inter-segment, and video-level). Finally, these scores are used to calculate the overall dynamics metrics: dynamics range and dynamics controllability. These metrics provide a comprehensive evaluation of the T2V models’ performance, focusing on the dynamics of video generation.

This figure shows a comparison of the distribution of dynamics grades in three different text prompt benchmarks: DEVIL, VBench, and EvalCrafter. Subfigure (a) is a bar chart illustrating the number of prompts categorized into five dynamic grades (Static, Low, Medium, High, Very High) for each benchmark. It visually represents the relative proportions of various dynamic levels in each dataset. Subfigure (b) is a word cloud visualization of the text prompts from the DEVIL benchmark, where the size of each word represents its frequency. This provides an overview of the types of language used to describe different levels of dynamics.
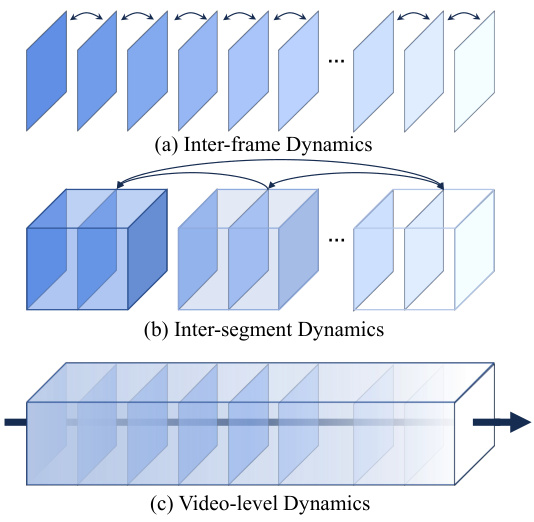
This figure illustrates the three levels of video dynamics considered in the DEVIL evaluation protocol. (a) Inter-frame dynamics focuses on the changes between consecutive frames, capturing fast and prominent content variations. (b) Inter-segment dynamics analyzes the changes between video segments (each containing K frames), reflecting mid-speed transitions and motion patterns. (c) Video-level dynamics considers the overall content diversity and the frequency of changes throughout the video, encompassing the overall content diversity and frequency of changes.

This figure shows the distribution of dynamics scores in the WebVid-2M dataset. The x-axis represents the dynamics score, ranging from 0 to 1, and the y-axis represents the density of videos with that particular dynamics score. The distribution is heavily skewed towards lower dynamics scores, indicating that the majority of videos in this dataset have relatively low dynamic content. This observation highlights the bias in existing datasets, where videos with high dynamic content are under-represented.

This figure shows the distribution of video quantity and quality scores across different dynamics scores for six video generation models. Subfigure (a) displays the number of videos generated at each dynamics score. Subfigure (b) presents the distributions of quality scores (Video Quality, Background Consistency, Motion Smoothness, and Naturalness) for each dynamics level. The results illustrate how the quality of generated videos and their quantity relate to the dynamics levels present in the videos.

This flowchart illustrates the process of calculating dynamics metrics using DEVIL. It starts with text prompts, which are used to generate videos using various T2V models. These videos are then analyzed to extract dynamics scores at different temporal granularities (inter-frame, inter-segment, and video-level). These scores, along with the original text prompts, are used to calculate the final dynamics metrics, which assess the model’s ability to generate videos with appropriate dynamics and align them with the textual descriptions.

This flowchart illustrates the DEVIL (Dynamics Evaluation protocol for Video and Language) framework. It shows how text prompts are used to generate videos using various T2V (text-to-video) models. The generated videos then undergo analysis to extract dynamics scores at multiple temporal granularities (inter-frame, inter-segment, and video-level). These dynamics scores, combined with the original text prompts, are used to calculate overall dynamics metrics (e.g., dynamics range and controllability), providing a comprehensive evaluation of the T2V model’s ability to generate videos with dynamic content aligned to the input text.

This figure illustrates the process of categorizing dynamics grades using GPT-4. The process involves providing GPT-4 with text prompts and asking it to classify them based on the level of dynamic content. To enhance accuracy, detailed criteria and examples are provided. After the initial GPT-4 classification, human annotators refine the classifications to ensure high accuracy. The end result is a benchmark of approximately 800 text prompts with dynamics grades.

This figure shows how the Gemini-1.5 Pro model evaluates the naturalness of generated videos. It presents two example video sequences. The first example shows a video of apples on a tree, which is rated as ‘Almost Realistic.’ The second video shows a dog running in traffic, which is rated as ‘Clearly Unrealistic.’ The model identifies and highlights anomalies (e.g. the dog’s legs appearing unnatural in the second example), which directly influence its realism classification. The figure visually demonstrates the key aspects of how the model’s naturalness score is determined, combining both visual analysis and behavioral assessment.

This flowchart illustrates the DEVIL evaluation protocol, showing how dynamics metrics are calculated. It starts with text prompts that are categorized into different dynamics levels. These prompts are then used to generate videos using various T2V models. The generated videos are then processed to extract dynamics scores across multiple temporal granularities (inter-frame, inter-segment, and video-level). Finally, these dynamics scores, along with the initial text prompts, are used to calculate the final dynamics metrics, enabling a comprehensive evaluation of the T2V models based on their ability to generate videos with various dynamics levels.

This figure illustrates the three levels of dynamics considered in the paper: inter-frame, inter-segment, and video-level. Inter-frame dynamics focuses on changes between consecutive frames. Inter-segment dynamics looks at changes between larger segments of the video. Video-level dynamics considers the overall dynamic variation across the entire video. Each level is visually represented to show different granularities of motion and change.

This figure shows two aspects of video dynamics. (a) illustrates the concept of dynamics at three different temporal granularities: inter-frame, inter-segment, and video-level. Each granularity represents a different scale of temporal change, from instantaneous changes between frames to longer-term variations across segments and overall video. (b) shows how video quality correlates with the dynamics scores. The distribution demonstrates that video quality (measured by aspects such as naturalness, quality, aesthetics, smoothness) is influenced by the level of dynamics present in the video.

This figure illustrates the three levels of video dynamics introduced in the paper: inter-frame, inter-segment, and video-level. Each level captures dynamics at a different temporal granularity. Inter-frame dynamics focuses on changes between consecutive frames, inter-segment dynamics considers changes across longer video segments, and video-level dynamics encompasses overall content diversity and change frequency throughout the entire video.

This figure shows the distribution of dynamics grades across different datasets (DEVIL, Vbench, and EvalCrafter). Subfigure (a) uses bar charts to compare the frequency of prompts categorized by five dynamics grades (Static, Low, Medium, High, Very High) in each dataset. This visually demonstrates how the relative emphasis on dynamics varies across existing benchmarks. Subfigure (b) presents a word cloud of the text prompts used in the DEVIL benchmark, illustrating the nature of language used to prompt for videos with varying levels of dynamic content.

This figure illustrates the three levels of video dynamics considered in the DEVIL evaluation protocol. (a) Inter-frame dynamics focuses on changes between consecutive frames, such as optical flow or perceptual hash differences. (b) Inter-segment dynamics analyzes changes between video segments composed of multiple frames, using metrics like patch-level aperiodicity and global aperiodicity. (c) Video-level dynamics considers the overall diversity and frequency of changes throughout the entire video using metrics like temporal entropy and temporal semantic diversity. Each level represents a different temporal granularity for assessing video dynamism.

This figure shows the distribution of video quantity and quality scores for six different video generation models across various dynamics scores. The top panel (a) displays the number of videos generated at different dynamics levels. The bottom panels (b) show the distribution of quality scores (background consistency, motion smoothness, and naturalness) at different dynamics levels for each model. The results illustrate the relationship between video dynamics and the quality of generated videos, demonstrating how common metrics often show negative correlation with dynamics.

This figure illustrates the concept of video dynamics across three temporal granularities. (a) shows inter-frame dynamics, focusing on changes between consecutive frames. (b) illustrates inter-segment dynamics, analyzing changes between video segments. Finally, (c) depicts video-level dynamics, which examines the overall dynamics of the entire video.
More on tables
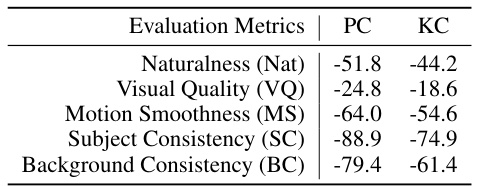
This table presents the correlation coefficients between the proposed dynamics metric and five existing metrics: Naturalness, Visual Quality, Motion Smoothness, Subject Consistency, and Background Consistency. Pearson’s and Kendall’s correlation coefficients are provided to assess the strength and direction of the relationships. The negative correlations suggest an inverse relationship between dynamics and existing metrics, indicating a potential issue where models may ‘cheat’ by generating low-dynamic videos to achieve high scores on these traditional metrics.

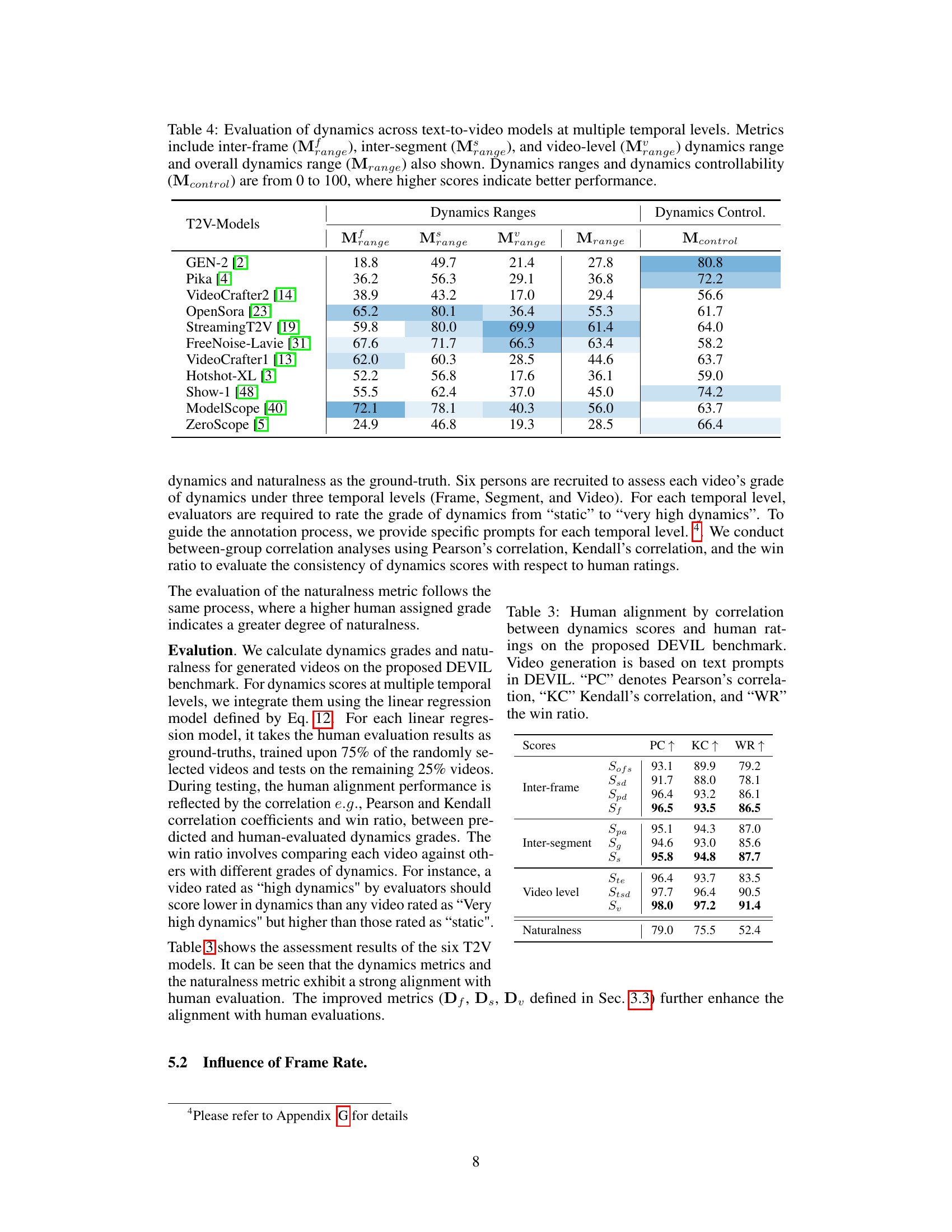
This table presents a quantitative evaluation of various text-to-video (T2V) models based on their performance across different temporal granularities. It assesses the models’ ability to generate videos with diverse dynamics, measuring their performance in terms of dynamics range (across inter-frame, inter-segment, video-level and overall) and the controllability of the generated video’s dynamic properties. Higher scores indicate superior performance in generating dynamic videos that align with the intended dynamics level.
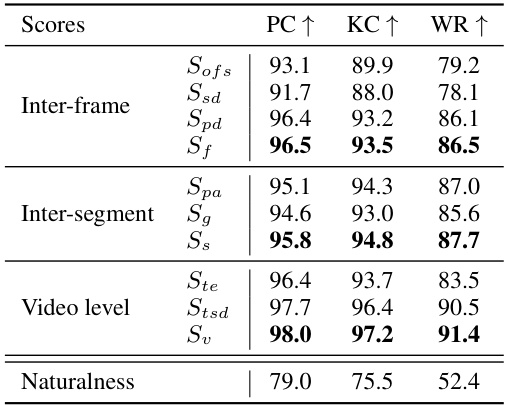
This table presents the results of a human alignment assessment. It shows the correlation (Pearson’s, Kendall’s, and Win Ratio) between the automatically calculated dynamics scores (at various temporal granularities: Inter-frame, Inter-segment, and Video level) and human ratings for those same dynamics. Higher correlation values indicate better alignment between automated and human assessments of video dynamics.

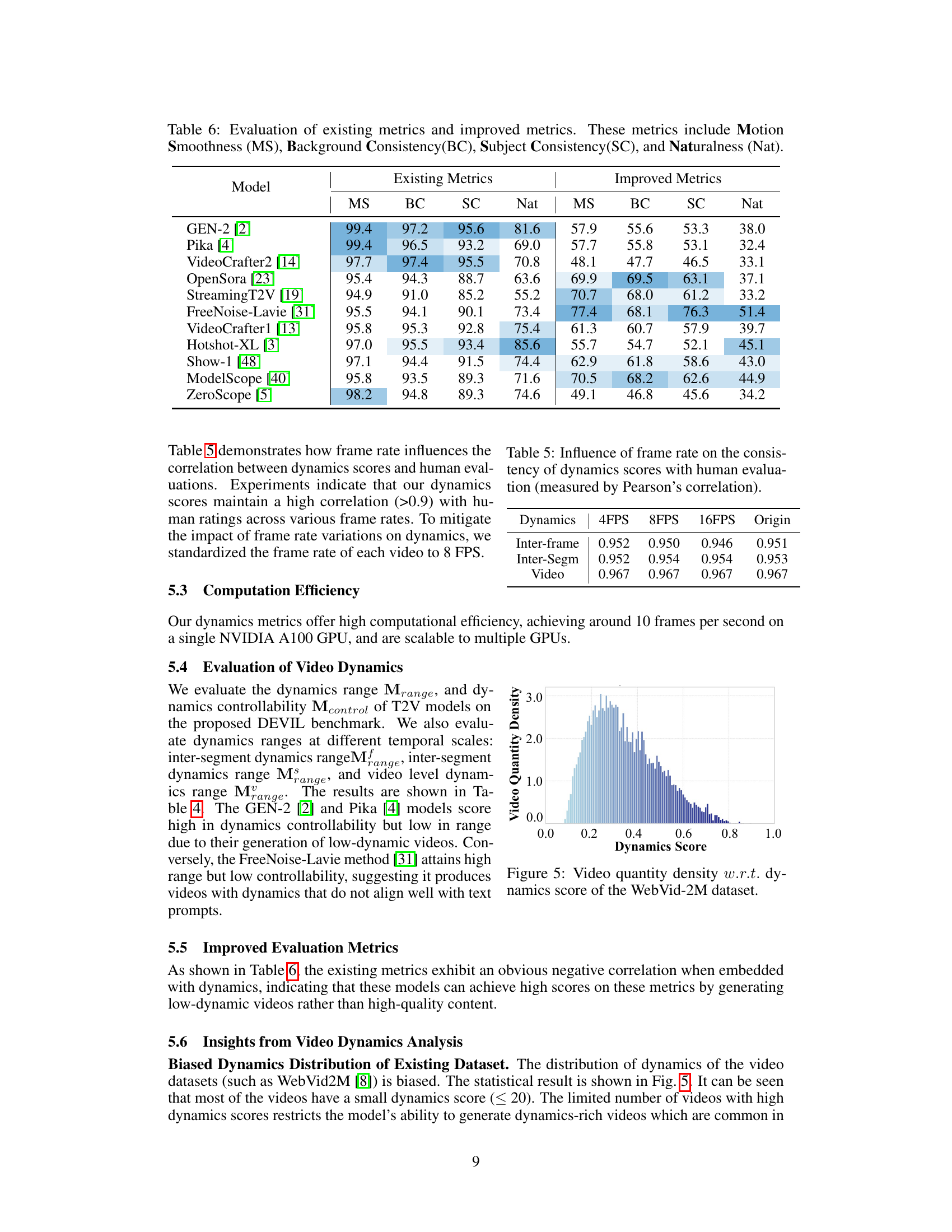
This table presents a comparison of existing and improved metrics for evaluating text-to-video (T2V) generation models. The existing metrics are Motion Smoothness (MS), Background Consistency (BC), Subject Consistency (SC), and Naturalness (Nat). The improved metrics are also MS, BC, SC, and Nat but have been enhanced by incorporating the human-aligned dynamics score. The table shows the scores for each metric for several state-of-the-art T2V models. The purpose is to demonstrate how incorporating dynamic considerations improves the evaluation metrics.
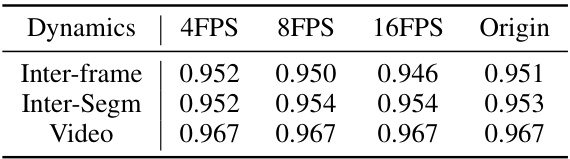
This table presents the Pearson correlation coefficients between dynamics scores and human evaluations at various frame rates (4 FPS, 8 FPS, 16 FPS) across three temporal granularities: Inter-frame, Inter-segment, and Video. The ‘Origin’ column shows the correlation coefficients using the original frame rates of the videos, demonstrating the robustness and consistency of the dynamics scores regardless of frame rate variations. High correlation values indicate strong agreement between the automatically calculated dynamics scores and human judgments.

This table compares the performance of two video segmentation methods: keyframe-based and proportional, in the context of inter-segment dynamics. It shows the Pearson’s and Kendall’s correlation coefficients between the dynamics scores obtained using each segmentation method and human evaluations, as well as the Win Ratio. The results indicate that both methods achieve comparable levels of correlation with human evaluations.

This table presents the results of an experiment evaluating the impact of the proportion factor (r) used in the inter-segment dynamics calculation on the correlation between the calculated dynamics scores and human evaluations. The proportion factor determines how the video is segmented for analysis. Three different values of r (1/8, 1/4, 1/2) were tested, and the table shows Pearson’s and Kendall’s correlation coefficients for each. Higher correlation coefficients indicate better agreement between the automated metric and human judgment.

This table shows the correlation between human evaluation scores and inter-segment dynamics scores for videos of different lengths (2, 4, and 8 seconds). It demonstrates the robustness of the inter-segment dynamics metric across varying video durations, maintaining high correlation regardless of video length.

This table shows the weights assigned to each dynamics score (calculated at different temporal granularities: inter-frame, inter-segment, and video-level) during the human alignment module. These weights are used to combine the empirically defined dynamics scores and create a more human-aligned overall dynamics score. The ‘Typical Value’ column provides a sense of the typical magnitude for each score, which helps interpret the weight’s influence in the aggregation process.

This table compares the performance of existing evaluation metrics (Motion Smoothness, Background Consistency, Subject Consistency, and Naturalness) with improved metrics incorporating the dynamics scores. It shows the scores for each metric across several text-to-video generation models. The improved metrics demonstrate better performance by addressing the negative correlation between existing metrics and video dynamics.

This table presents a quantitative evaluation of various text-to-video (T2V) models across different temporal granularities (inter-frame, inter-segment, video-level). The metrics used are dynamics range, reflecting the variety of movement and change within the generated video, and dynamics controllability, which measures how well the model aligns the dynamics of the video to the dynamics implied by the input text. Higher scores in both indicate better model performance. The table facilitates comparison between different models in terms of their ability to generate videos with appropriate and diverse dynamics.

This table presents the correlation analysis results to evaluate the consistency between human-assigned scores and the automatically generated dynamics scores from different temporal granularities, including inter-frame, inter-segment, and video-level. The correlations were measured using Pearson’s correlation, Kendall’s correlation, and win ratio (WR). High correlation values suggest high consistency, indicating that the dynamics metrics accurately reflect human perception of video dynamics.
Full paper#