↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many applications need LLMs to handle graph-structured information within text. While LLMs excel in various tasks, their ability to accurately recall graphs described in text remains understudied. This paper addresses this gap by systematically examining LLM’s graph recall accuracy and identifying biases in the microstructures (local subgraph patterns) of their recalled graphs.
This study used ERGM (Exponential Random Graph Model) to analyze the statistical significance of microstructural patterns. The results show that LLMs not only underperform in graph recall but also exhibit unique biases, such as favoring triangles, compared to human behavior. Interestingly, the accuracy of advanced LLMs improved significantly when the narrative style of the graph description matched the graph’s domain, highlighting the influence of context in LLM’s graph reasoning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals LLMs’ limitations in a fundamental graph reasoning task (recall), highlighting biases and underperformance. This opens avenues for improving LLMs’ graph reasoning capabilities and designing more effective graph-encoding methods. It also provides a foundation for cross-disciplinary research, bridging AI and cognitive science.
Visual Insights#
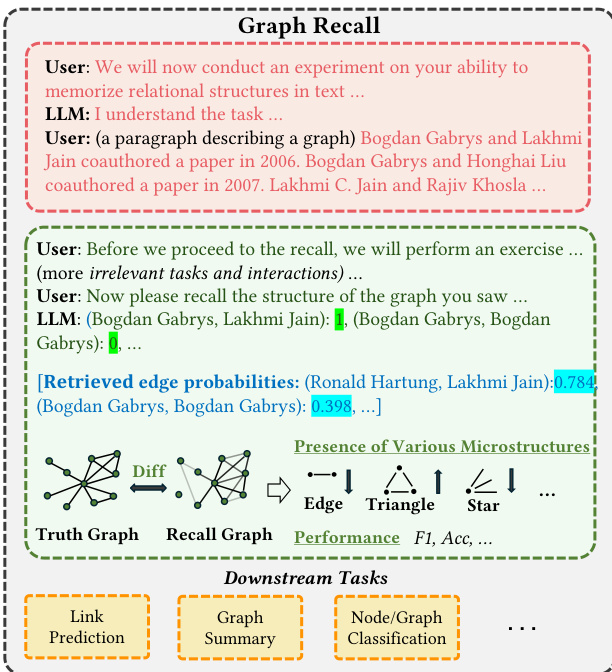
This figure illustrates the graph recall task, which involves presenting a graph to a subject (human or LLM) through a textual description, and then asking them to recall and describe the graph structure. The figure highlights that accurate graph recall is crucial for success in downstream graph reasoning tasks, such as link prediction, graph summarization, and node/graph classification. If the LLM cannot recall the graph accurately, its performance in these downstream tasks will likely be hindered.

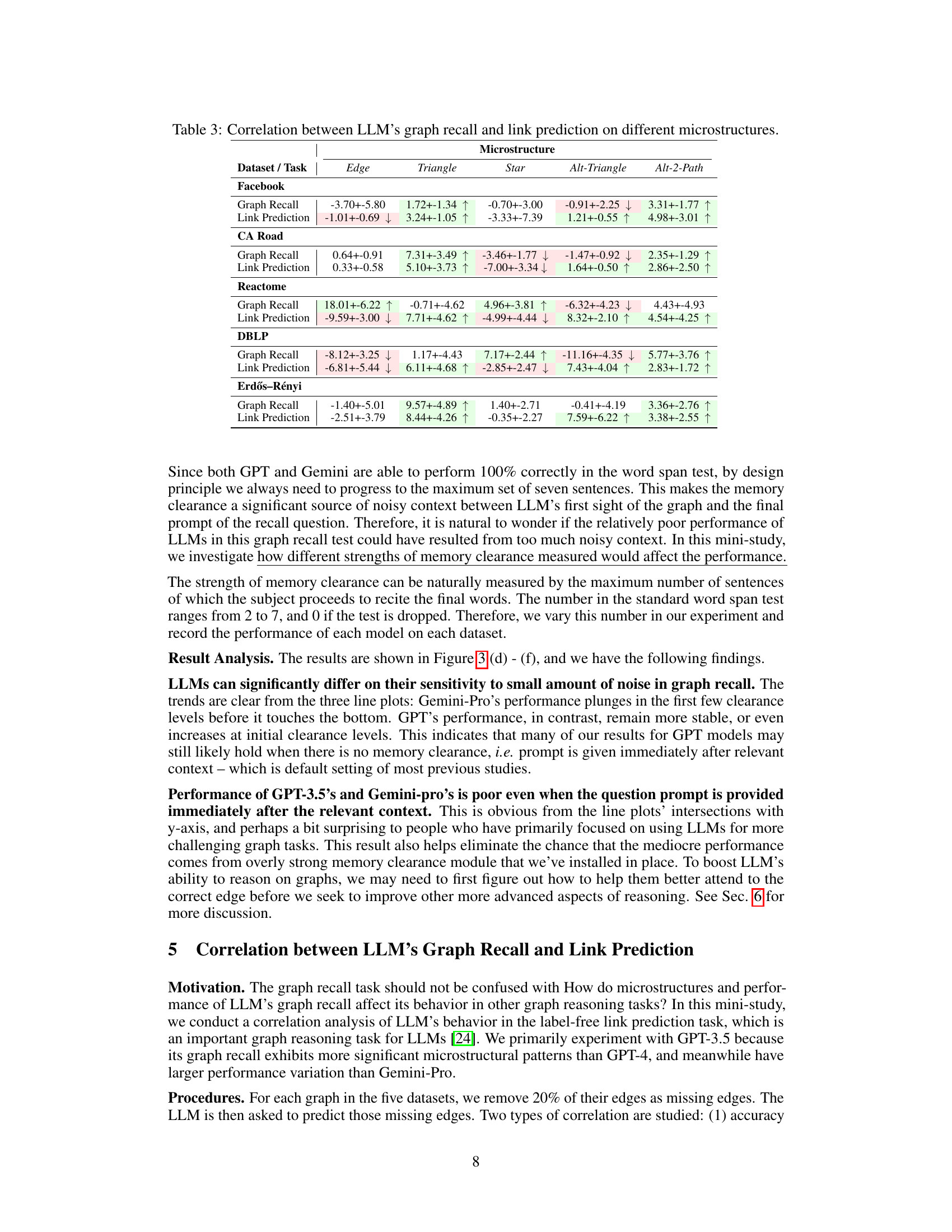
This table presents the results of an experiment that evaluated the accuracy and microstructural patterns of Large Language Models (LLMs) in recalling graphs from various domains. The microstructural patterns (e.g., triangles, stars, alternating 2-paths) represent the local subgraph structures within the recalled graphs. The statistical significance of these patterns was assessed using the Exponential Random Graph Model (ERGM). The table shows the mean and 95% confidence interval for each microstructural pattern, indicating whether the LLMs were biased towards or against specific patterns. It also shows the accuracy and F1 scores for each LLM’s performance on the graph recall task across different domains (Facebook, CA Road, Reactome, DBLP, and Erdős-Rényi).
In-depth insights#
LLM Graph Recall#
The concept of “LLM Graph Recall” explores the ability of large language models (LLMs) to accurately remember and represent graph-structured information previously presented in text. This is a fundamental capability underlying more complex graph reasoning tasks. Research in this area reveals that LLMs often underperform in graph recall, exhibiting biases in the microstructures (local subgraph patterns) of their recalled graphs, such as favoring triangles and alternating 2-paths. These biases differ from those observed in human graph recall, suggesting that LLMs use different mechanisms for processing and storing relational information. Narrative style and the domain of the graph significantly impact LLM recall accuracy, emphasizing the importance of contextual factors in LLM performance. This research highlights the need to understand and mitigate these biases to improve LLM’s graph reasoning capabilities and offers potential avenues for future investigation.
Microstructure Bias#
Microstructure bias in graph recall by LLMs reveals a fascinating interplay between model architecture and human cognitive patterns. LLMs, despite their advanced capabilities, exhibit systematic biases in reconstructing graph structures from textual descriptions. These biases manifest as a disproportionate tendency to recall certain subgraph patterns (motifs), such as triangles and alternating 2-paths, over others. This divergence from accurate representation highlights limitations in LLM’s ability to faithfully capture relational information. The presence of these biases is not random; rather, it reflects underlying limitations in how LLMs process and encode relational data. Further investigation is needed to uncover the mechanisms responsible for these biases and to explore potential mitigation strategies. Comparing LLM biases to established human biases in graph recall offers a unique opportunity to bridge the gap between artificial and human intelligence. It shows that while LLMs may employ different underlying processes, they still exhibit similar structural preferences. This understanding is critical for improving LLM graph reasoning and developing methods for correcting or mitigating such biases.
Narrative Effects#
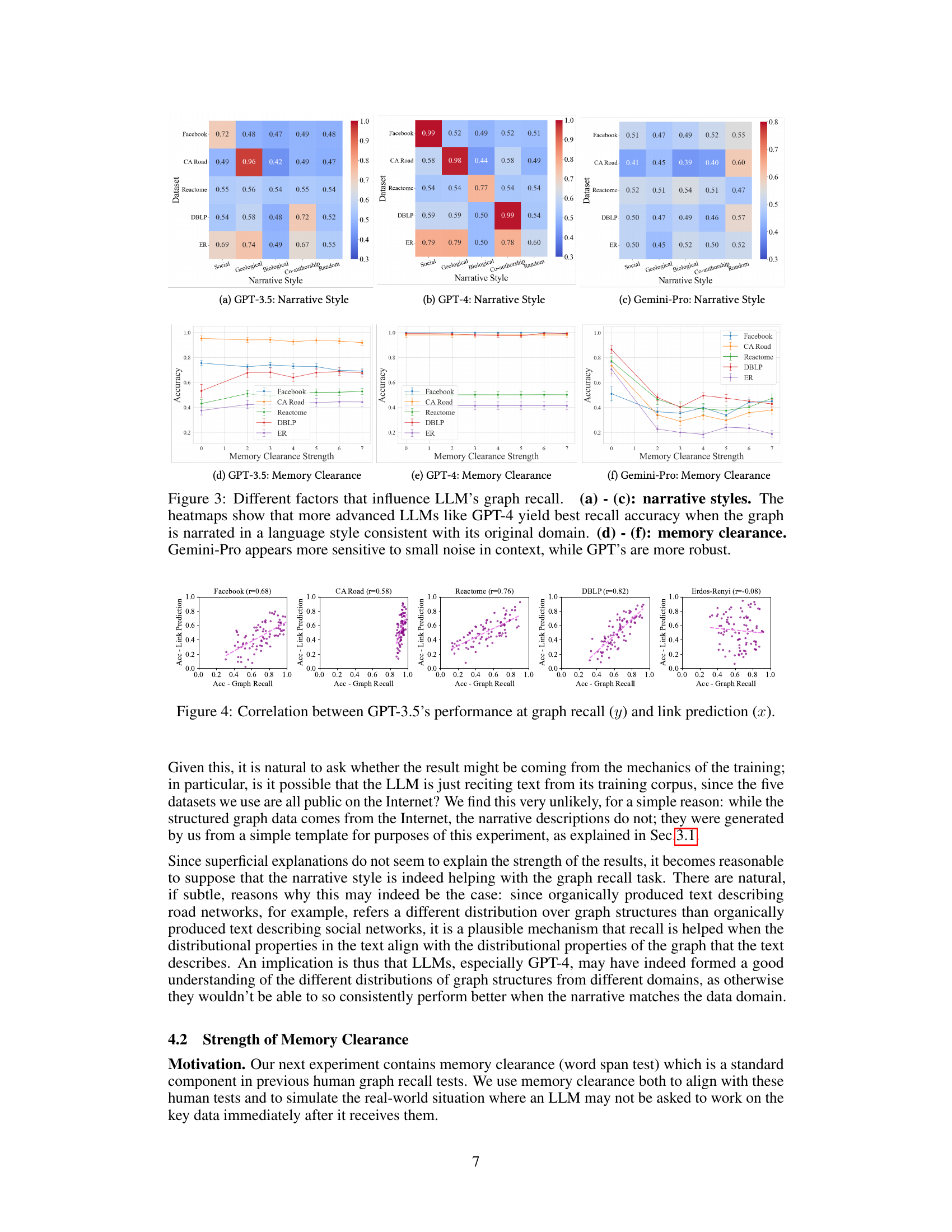
The concept of “Narrative Effects” in the context of LLMs and graph reasoning is fascinating. Different narrative styles, used to describe the same graph, significantly impact an LLM’s ability to recall and encode that graph’s structure. This suggests that LLMs are sensitive to how information is presented, not just the information itself. The choice of words and the structure of the narrative (e.g., using geographical terms for road networks vs. relational descriptions for social networks) act as strong contextual cues for the LLM. This highlights the importance of considering the role of language in influencing the performance of LLMs on knowledge representation and reasoning tasks. Matching the narrative style to the original domain of the graph leads to significantly better recall accuracy. This finding implies that LLMs are learning domain-specific associations between language and graph structure, indicating a potential avenue for improving their performance by tailoring the narrative to the specific graph domain.
Memory Influence#
The concept of ‘Memory Influence’ in the context of a research paper likely explores how memory, whether short-term or long-term, impacts various cognitive processes and behaviors. A thoughtful analysis would delve into several aspects. Firstly, it would examine how the duration of time between encoding information and retrieval affects accuracy. Does a longer retention interval lead to more errors and biases? Secondly, it might investigate the influence of prior knowledge and context on memory recall, examining how existing schemas and expectations shape what is remembered and how. Thirdly, the role of interference from other information presented or recalled could be analyzed. How does competition for cognitive resources impact the accuracy and detail of memory retrieval? Finally, an in-depth exploration could investigate the stability and malleability of memories over time. Do certain types of memories decay more rapidly than others? Are specific recall strategies more effective at mitigating memory decay? These are only some of the lines of inquiry an exploration of memory influence might reveal.
Future Research#
The research paper’s “Future Research” section would ideally delve into several crucial areas. Improving LLM graph reasoning ability is paramount, focusing on why current models underperform on simple graph recall tasks and exploring novel architectural designs and training methods to address these shortcomings. Bias mitigation strategies are crucial given the identified biases in LLMs’ graph recall, particularly regarding the overrepresentation of triangles and alternating 2-paths. Strategies might involve adjusting training data distributions or developing more sophisticated models capable of handling such biases. Investigating the influence of narrative style and memory clearance on LLM graph recall performance should be prioritized, given the observed dependence of advanced LLMs on a narrative style consistent with the graph’s original domain. Finally, integrating LLM graph analysis into social science applications requires further study, potentially involving a larger-scale comparative study of human vs. LLM graph recall alongside investigating the causal mechanisms behind observed biases to understand their broader implications. This section should conclude by emphasizing the necessity of future research integrating all of these points and building on this foundational work to advance the state of the art of LLM graph reasoning.
More visual insights#
More on figures
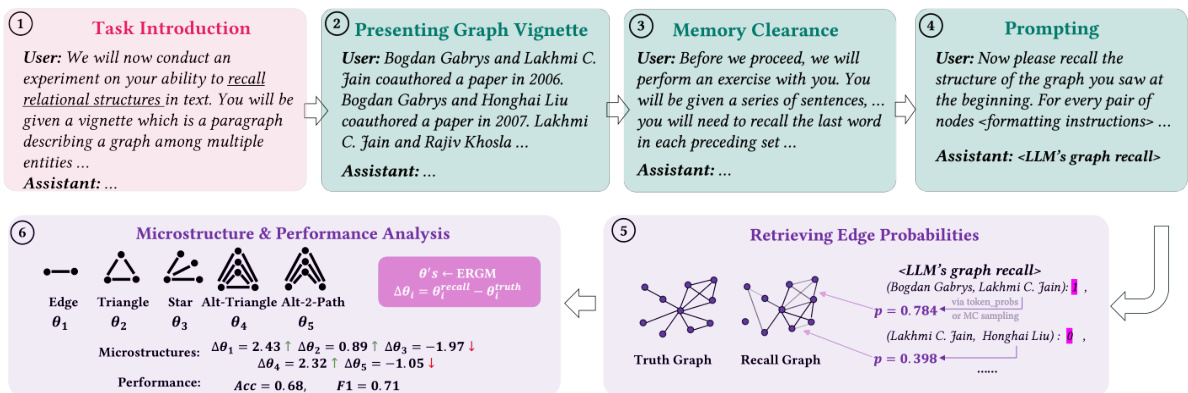
This figure illustrates the graph recall task, a fundamental step for more advanced graph reasoning tasks. It shows how a user provides a textual description of a graph, the LLM processes this information, and then is prompted to recall the structure of the graph. The recalled graph is then compared to the ground truth. The figure emphasizes that the ability to accurately recall a graph is crucial for downstream graph reasoning tasks such as link prediction, graph summary, and node/graph classification.

This figure details the six steps involved in the experimental protocol for evaluating LLMs’ graph recall capabilities. Step 1 introduces the task to the LLM, Step 2 presents the graph vignette (a short paragraph describing the graph), Step 3 involves a memory clearance task (a word span test), Step 4 prompts the LLM to recall the graph, Step 5 retrieves edge probabilities from the LLM’s response using token probabilities or Monte Carlo sampling, and finally, Step 6 analyzes the microstructures and performance using the Exponential Random Graph Model (ERGM).

The figure shows the correlation between the accuracy of GPT-3.5 in graph recall and link prediction tasks across five different real-world graph datasets (Facebook, CA Road, Reactome, DBLP, and Erdos-Renyi). Each point represents a single graph, with the x-axis showing the accuracy of graph recall and the y-axis showing the accuracy of link prediction. The correlation coefficient (r) is displayed for each dataset, indicating the strength and direction of the linear relationship between the two tasks. The plots visually demonstrate the positive correlation observed in four of the datasets, with a higher recall accuracy generally leading to higher link prediction accuracy. The Erdos-Renyi dataset, being a synthetic random graph, shows very little correlation as expected.

This figure illustrates the experimental setup used to evaluate LLMs’ graph recall abilities. It outlines a six-step process: 1. Task introduction, where the LLM is made aware of the graph recall task. 2. Presentation of a graph vignette (a short descriptive story encoding the graph structure). 3. Memory clearance (a word span test to clear short-term memory). 4. Prompting the LLM to recall the graph structure. 5. Retrieving edge probabilities from the LLM’s response (using token probabilities or Monte Carlo sampling). 6. Microstructure analysis and performance measurement using ERGM (Exponential Random Graph Model) to analyze the recalled graph and compare it to the ground truth graph. The figure also shows examples of microstructures analyzed (edge, triangle, star, alt-triangle, alt-2-path).

This figure illustrates the six steps involved in the experiment to analyze the microstructures and accuracy of LLMs’ graph recall. Step 1 is task introduction; Step 2 is presenting a graph vignette; Step 3 involves memory clearance (a word span test); Step 4 is prompting the LLM to recall the graph; Step 5 focuses on retrieving edge probabilities using token probabilities or Monte Carlo sampling; Step 6 involves microstructure analysis using ERGM to identify statistical significance of various microstructural patterns and measure performance (accuracy and F1 score).

This figure illustrates the six steps involved in the LLM graph recall experiment. Step 1 introduces the task to the LLM. Step 2 presents a paragraph describing a graph. Step 3 involves a memory clearance task using a word span test to simulate delayed queries in real-world scenarios. Step 4 prompts the LLM to recall the graph structure. Step 5 retrieves edge probabilities from the LLM’s responses. Finally, Step 6 analyzes microstructures and performance using the Exponential Random Graph Model (ERGM). The figure also includes a visual representation of the five microstructural patterns (edge, triangle, star, alternating triangle, alternating 2-path) used in the analysis.

The figure illustrates the graph recall task, which serves as a foundational step for more complex graph reasoning tasks. The process begins with a user providing a paragraph describing a graph, followed by irrelevant tasks to clear the LLM’s short-term memory. Finally, the LLM is prompted to recall the graph structure. The recalled graph is then compared to the original graph, evaluating accuracy and identifying biased microstructural patterns (local subgraph patterns). These patterns and accuracy metrics are then used to assess the LLM’s graph reasoning ability and its connection to other downstream tasks like link prediction, graph summarization, and node/graph classification.

This figure illustrates the experimental procedures used to analyze the microstructures and accuracy of LLMs in graph recall tasks. It outlines six key steps: 1) Task introduction, where the LLM is informed about the task. 2) Presenting graph vignette, where the LLM is given a textual description of a graph. 3) Memory clearance, where a word span test is used to clear short-term memory. 4) Prompting, where the LLM is asked to recall the graph structure. 5) Retrieving edge probabilities, detailing how edge probabilities are extracted from the LLM’s responses. 6) Microstructure analysis & performance measurement, which shows how ERGM is used to analyze the recalled graphs. The diagram shows the flow of information between each step and highlights the methods used for data collection and analysis.
More on tables
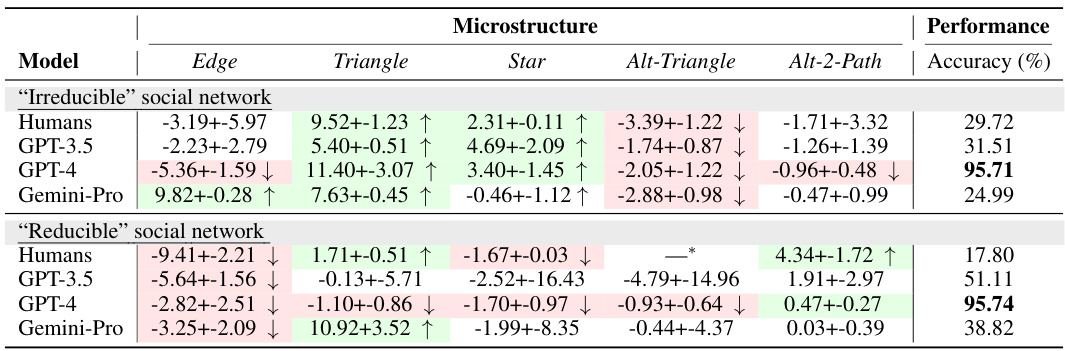
This table presents the results of an experiment evaluating the performance of different Large Language Models (LLMs) in recalling graph structures. It shows the accuracy and F1 scores of each LLM across various datasets, along with the statistical significance of microstructural patterns (triangles, stars, etc.) in their recalled graphs. A positive value indicates a bias toward that pattern, while a negative value indicates a bias against it. The ERGM model is used to assess statistical significance of the microstructures. The full table is available in Appendix C.

This table presents the results of an experiment evaluating the performance of three large language models (LLMs) in recalling graph structures. It shows the statistical significance of several microstructural patterns (network motifs) found in the graphs recalled by the LLMs. These patterns are compared to the ground truth. The table also reports accuracy and F1 scores, which measure the performance of each LLM. Positive values indicate a bias towards that pattern, while negative values indicate a bias against it.

This table presents the results of a graph recall experiment conducted on various LLMs. It shows the microstructural patterns (local subgraph structures) in the graphs recalled by the LLMs, and how these patterns differ from the ground truth. The statistical significance of these differences is measured using an Exponential Random Graph Model (ERGM), with positive values indicating a bias toward the pattern and negative values indicating a bias away from it. The table also includes performance metrics (accuracy and F1 score) for each LLM on each dataset.

This table presents the results of an experiment evaluating the accuracy and microstructural patterns of Large Language Models (LLMs) in recalling graphs. It shows the mean and 95% confidence intervals for several microstructural patterns (edge, triangle, star, alt-triangle, alt-2-path) in graphs recalled by different LLMs across five datasets from various domains. Positive values indicate a bias towards the pattern, while negative values indicate a bias against it. The table also includes the accuracy and F1 scores for each LLM and dataset, providing a comprehensive performance evaluation. The full table is available in Appendix C.

This table presents the results of a graph recall experiment conducted on several LLMs using graphs sampled from various domains. It shows the statistical significance of five microstructural patterns (edge, triangle, star, alternating triangle, alternating 2-path) in the recalled graphs compared to the true graphs. Positive values indicate a bias towards the pattern in the recalled graphs, while negative values indicate a bias against the pattern. The table also reports the accuracy and F1 score of each LLM’s recall performance for each dataset. The ERGM model is used to calculate the significance of these patterns.

This table presents the results of a graph recall experiment conducted on Large Language Models (LLMs). It shows the accuracy and microstructural patterns (local subgraph patterns) in the graphs recalled by different LLMs across various datasets representing different real-world domains. The microstructural patterns are analyzed using the Exponential Random Graph Model (ERGM), with positive values indicating a bias towards that pattern and negative values indicating a bias against it. The table also provides the accuracy and F1 score for each LLM’s recall performance on each dataset. Appendix C contains the full table.
Full paper#