↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Weakly supervised object detection (WSOD) methods often struggle with the problem of image-to-box label mismatch, where image-level labels lack the precision needed for accurate object localization. Existing approaches often rely on heuristic label assignment strategies or self-training, but these methods can be noisy and lead to performance limitations. This also creates a challenge for creating generalizable object detectors that perform well across different datasets and object categories.
This paper introduces a new method called Language Hierarchical Self-training (LHST) to improve WSOD. LHST addresses the limitations of existing methods by incorporating language hierarchy (using WordNet) to expand image-level labels and improve supervision. It also employs a co-regularization strategy that combines the expanded labels with self-training, which helps to filter noisy pseudo labels and improve the reliability of the learning process. The resulting object detector, called DetLH, achieves superior generalization performance on a wide range of benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical issue of generalization in object detection, a significant challenge in computer vision. By leveraging language hierarchy and self-training, it offers a novel approach to address the image-to-box label mismatch problem, paving the way for more robust and generalizable object detectors. This work is highly relevant to the current trend of weakly-supervised learning and opens new avenues for research in open-vocabulary object detection.
Visual Insights#

This figure illustrates the limitations of existing weakly supervised object detection methods and introduces the proposed Language Hierarchical Self-Training (LHST) method. (a) shows how current label-to-box assignment strategies struggle with the imprecision of image-level labels. (b) demonstrates the issue with self-training, where generated pseudo-labels can be inaccurate due to a lack of supervision. (c) presents the LHST approach, which uses a language hierarchy (WordNet) to expand image-level labels and co-regularizes them with self-training for more accurate pseudo-labels, mitigating the image-to-box mismatch problem.
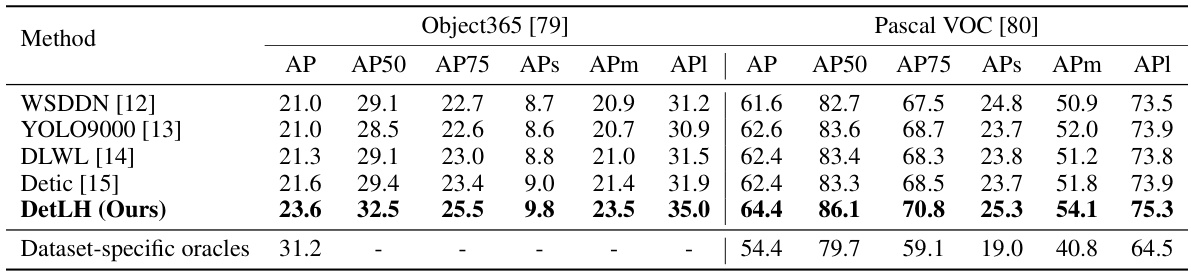
This table presents the results of a zero-shot cross-dataset object detection experiment. Four different object detection methods (WSDDN, YOLO9000, DLWL, Detic) and the proposed method (DetLH) were evaluated on two target datasets (Object365 and Pascal VOC). The models were trained on the LVIS and ImageNet-21K datasets, and then tested on the target datasets without further fine-tuning. A ‘dataset-specific oracle’ is included as a baseline representing the performance achievable if the model is trained specifically on the target dataset’s data.
In-depth insights#
LHST Self-Training#
Language Hierarchical Self-training (LHST) is a novel approach to weakly supervised object detection that leverages WordNet’s language hierarchy to address the image-to-box label mismatch problem. LHST expands the limited image-level labels with richer hierarchical information, providing more flexible and comprehensive supervision for the self-training process. This mitigates the ambiguity inherent in image-level labels, as a single high-level label can encompass many different object instances. The reliability of these expanded labels is assessed using predicted confidence scores, allowing the model to adaptively weight the contributions of different labels. This co-regularization between expanded labels and self-training enhances the quality of generated pseudo-labels. By incorporating this hierarchical structure, LHST effectively bridges the gap between weak image-level supervision and the need for precise object localization, leading to more robust and generalizable object detectors.
LHPG Prompt Gen#
The heading ‘LHPG Prompt Gen’ suggests a method for generating prompts, likely within the context of a language model or a system that interacts with language. The ‘LHPG’ acronym likely refers to a specific technique or framework, possibly incorporating a language hierarchy (as suggested by ‘LH’). This implies that the system doesn’t generate random prompts but instead structures them based on a hierarchical organization of concepts. This hierarchical structure could significantly improve prompt quality and efficiency by guiding the system toward more relevant and specific prompts. The use of a hierarchy likely enhances the ability of the system to handle open-vocabulary scenarios, where it needs to generate prompts for concepts that were not explicitly seen during training. This is important because using a pre-defined vocabulary often limits the generalizability of a language-based system. The hierarchical organization helps bridge the gap between training and testing data, allowing the system to generate appropriate prompts even for unseen concepts by utilizing its knowledge of higher-level and more general concepts. This approach is likely designed to enhance the robustness and overall effectiveness of a downstream process such as open-vocabulary object detection (as might be suggested by the context). Therefore, ‘LHPG Prompt Gen’ is more than just a simple prompt generation technique; it likely represents a sophisticated method leveraging linguistic structure to greatly improve a system’s ability to handle diverse and complex language tasks.
Open Vocabulary Det#
An open vocabulary object detector is a system capable of identifying objects from a vast and potentially unlimited set of categories, without the need for explicit training on each specific class. This differs significantly from traditional detectors that rely on predefined, closed vocabularies. The challenge lies in enabling the detector to generalize to unseen classes, leveraging transferable knowledge learned from a broader training dataset, often incorporating language embeddings or other representations to bridge the semantic gap. Key approaches involve utilizing large-scale image-level datasets with associated text descriptions and employing techniques like self-training or knowledge distillation from powerful pre-trained models, such as CLIP. The resulting system exhibits improved generalization capabilities, enhancing performance on open-ended tasks while simultaneously addressing the limitations associated with limited labeled data. Success hinges on effective techniques for managing a large and diverse vocabulary, ensuring robustness against noisy pseudo-labels generated during self-training, and efficiently bridging the vocabulary gap between training and inference.
Cross-Dataset Eval#
Cross-dataset evaluation is crucial for assessing the generalizability of object detection models. It moves beyond the limitations of within-dataset testing by evaluating a model’s performance on datasets unseen during training. This approach helps uncover biases present in the training data and reveals how well the model can adapt to different data distributions. A robust model should demonstrate consistent performance across multiple datasets, highlighting its ability to generalize learned features to novel scenarios. The selection of diverse datasets for cross-dataset evaluation is vital for obtaining a comprehensive assessment. These datasets need to vary in aspects like image quality, object diversity, annotation style, and overall data distribution. The results of a comprehensive cross-dataset evaluation are key to establishing a model’s true capabilities and potential real-world applicability, which goes beyond the high performance numbers obtained using within-dataset validation alone.
Future Works#
Future work could explore several promising avenues. Extending LHST to encompass a broader range of language hierarchies beyond WordNet would enhance its versatility and applicability to diverse datasets. Investigating the impact of different self-training strategies, including alternative pseudo-label generation methods and reliability assessment techniques, could further refine the model’s performance. A thorough analysis of the trade-off between computational cost and performance gains is crucial, especially given the scale of datasets used. Moreover, exploring the use of additional modalities, such as video or multispectral data in conjunction with LHST, could unlock new possibilities for improved generalization. Finally, a deeper investigation into the robustness of DetLH in the presence of noisy or incomplete data is vital to assess its practical applicability in real-world scenarios.
More visual insights#
More on figures
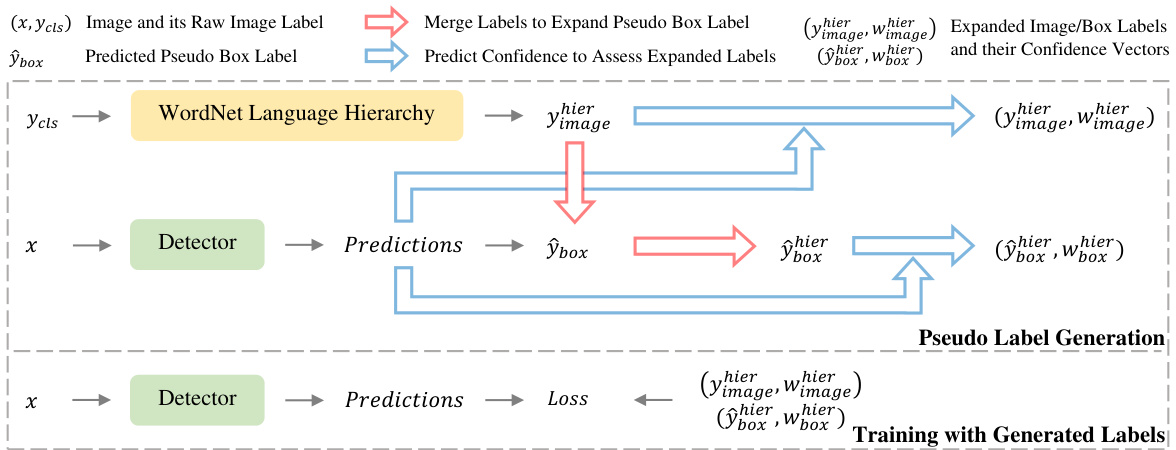
This figure illustrates the Language Hierarchical Self-training (LHST) process. LHST uses WordNet to expand image-level labels, merges them with predicted pseudo-box labels, and uses predicted confidence scores to weight the expanded labels. This improves self-training by providing richer supervision and mitigating the image-to-box label mismatch problem.

This figure illustrates the limitations of using image-level labels for object detection. It compares three approaches: (a) standard label-to-box assignment, which suffers from mismatch; (b) self-training, which generates inaccurate pseudo labels; and (c) the proposed LHST method, which uses language hierarchy to improve pseudo label accuracy.

This figure shows a qualitative comparison of the object detection results obtained by Detic [15] and the proposed DetLH method on the autonomous driving dataset. The top row displays results from Detic [15], while the bottom row showcases results from DetLH (Ours). Each column represents a different image from the dataset. The images illustrate that DetLH improves upon Detic’s performance, particularly in terms of object localization and accuracy. The details shown in the zoomed-in view highlight these improvements.

This figure shows qualitative results of DetLH and Detic [15] on common object detection datasets. Each column represents a different image from a different dataset and shows the detection results using Detic [15] (top row) and DetLH (bottom row). The results demonstrate the performance of both methods on various common objects and challenging conditions, allowing for a visual comparison of their detection accuracy and localization ability.

This figure shows a qualitative comparison of the object detection results of the proposed DetLH method and the Detic method on the autonomous driving dataset. The top row displays the results from the Detic method, while the bottom row displays the results from the DetLH method. Each column represents a different image from the dataset, and the results show the detected objects with bounding boxes and class labels. The comparison highlights the improved accuracy and robustness of the DetLH method in detecting objects in challenging autonomous driving scenarios.

This figure shows qualitative comparisons of object detection results between Detic and the proposed DetLH method on the African Wildlife dataset. Both methods are tested in a zero-shot cross-dataset setting. The top row displays Detic’s detections, while the bottom row displays DetLH’s detections. The figure highlights the improved accuracy and robustness of DetLH, especially in accurately identifying and localizing wildlife objects within their respective bounding boxes.
More on tables
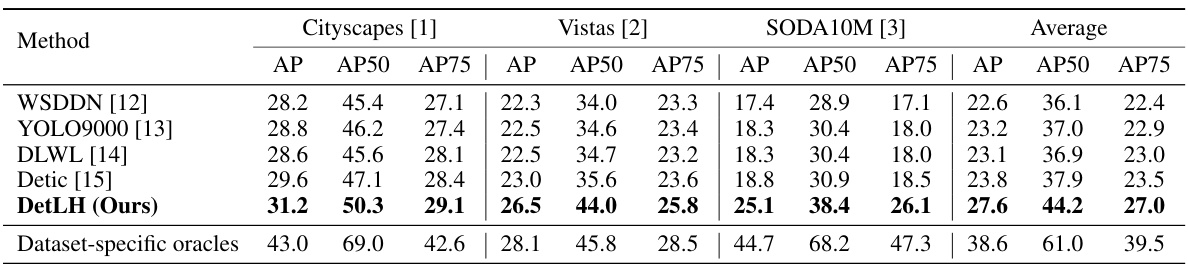
This table presents the results of a zero-shot cross-dataset object detection experiment focusing on autonomous driving. Four different object detection methods (WSDDN, YOLO9000, DLWL, Detic) and the proposed DetLH method were evaluated on three autonomous driving datasets: Cityscapes, Vistas, and SODA10M. The models were trained on the LVIS and ImageNet-21K datasets but not fine-tuned on the autonomous driving datasets. The table shows the average precision (AP) and average precision at different Intersection over Union (IoU) thresholds (AP50 and AP75) for each method on each dataset, along with the average performance across all three datasets. Dataset-specific oracles (fully supervised detectors trained on each dataset) are included as a performance baseline.

This table presents the results of a zero-shot cross-dataset object detection experiment. The experiment evaluates the performance of several object detectors under varying weather and time-of-day conditions. The detectors were trained on the LVIS and ImageNet-21K datasets and tested on the BDD100K and DAWN datasets without any fine-tuning. The AP50 metric is used to evaluate the performance.

This table presents the results of a zero-shot cross-dataset object detection experiment focusing on intelligent surveillance. Four different surveillance datasets (MIO-TCD, BAAI-VANJEE, DETRAC, and UAVDT) were used to evaluate the performance of several object detection models (WSDDN, YOLO9000, DLWL, Detic, and the proposed DetLH). The models were all trained on the same training datasets (LVIS and ImageNet-21K) without any fine-tuning on the test datasets, demonstrating their generalization abilities. The table shows the average precision (AP), AP at 50% IoU (AP50), and AP at 75% IoU (AP75) for each model across the four datasets.
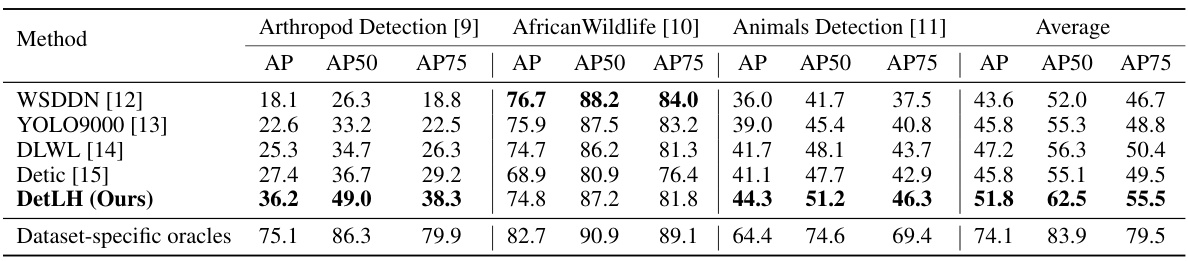
This table presents the results of a zero-shot cross-dataset object detection experiment on three wildlife detection datasets: Arthropod Detection, African Wildlife, and Animals Detection. The detectors were trained on a combination of LVIS and ImageNet-21K datasets but were not fine-tuned on the target wildlife datasets. The table shows the average precision (AP), AP at 50% IoU (AP50), and AP at 75% IoU (AP75) for each method (WSDDN, YOLO9000, DLWL, Detic, and the proposed DetLH) and a dataset-specific oracle.

This table presents the ablation study results of the proposed DetLH model. It shows the impact of the two main components, LHST and LHPG, on the model’s performance (AP50) using the Swin-B based Center-Net2 architecture. The baseline uses only box-level supervision. The results demonstrate that both LHST and LHPG contribute to improved performance, with the combination achieving the best AP50 score.
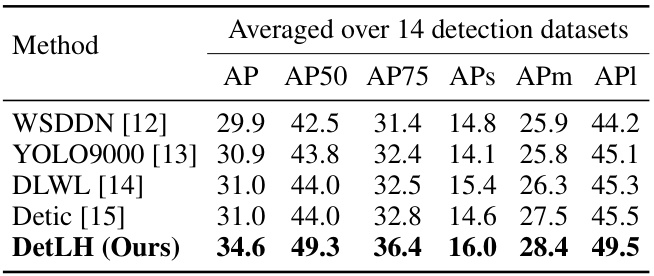
This table presents a comparison of the proposed DetLH method against existing state-of-the-art methods (WSDDN, YOLO9000, DLWL, and Detic) on 14 different object detection datasets. The results, averaged across these datasets, are reported in terms of Average Precision (AP) and its variants (AP50, AP75, APS, APm, and API). The table showcases the superior generalization performance of DetLH across diverse datasets.
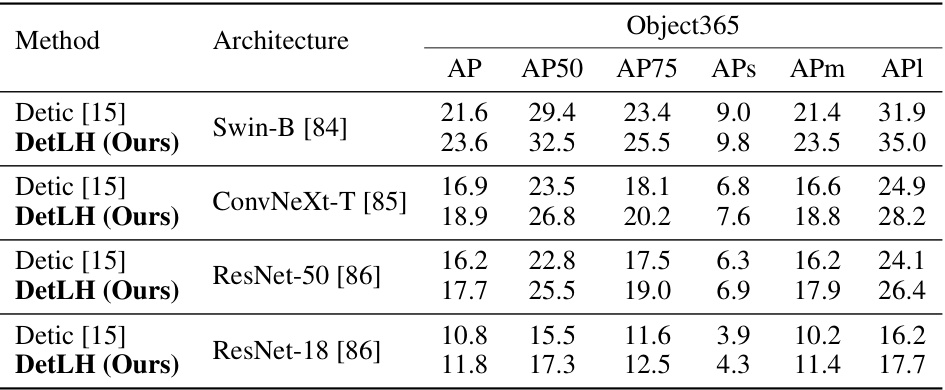
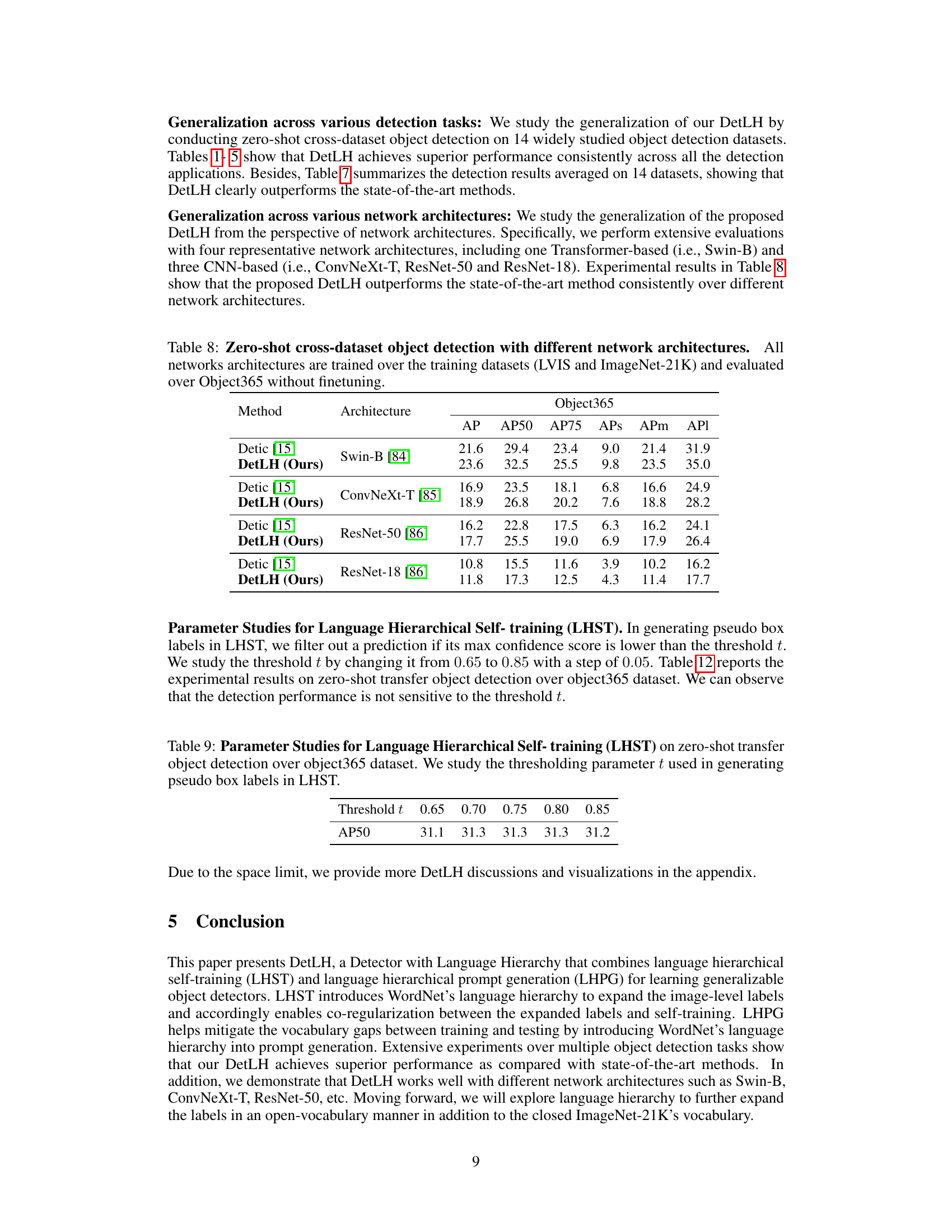
This table presents the results of a zero-shot cross-dataset object detection experiment on the Object365 dataset. The experiment evaluates the generalization performance of the DetLH model across four different network architectures: Swin-B, ConvNeXt-T, ResNet-50, and ResNet-18. Each architecture was trained on the LVIS and ImageNet-21K datasets and then evaluated on Object365 without any fine-tuning. The table shows the average precision (AP) and its variations (AP50, AP75, APs, APm, APl) for each architecture and method.

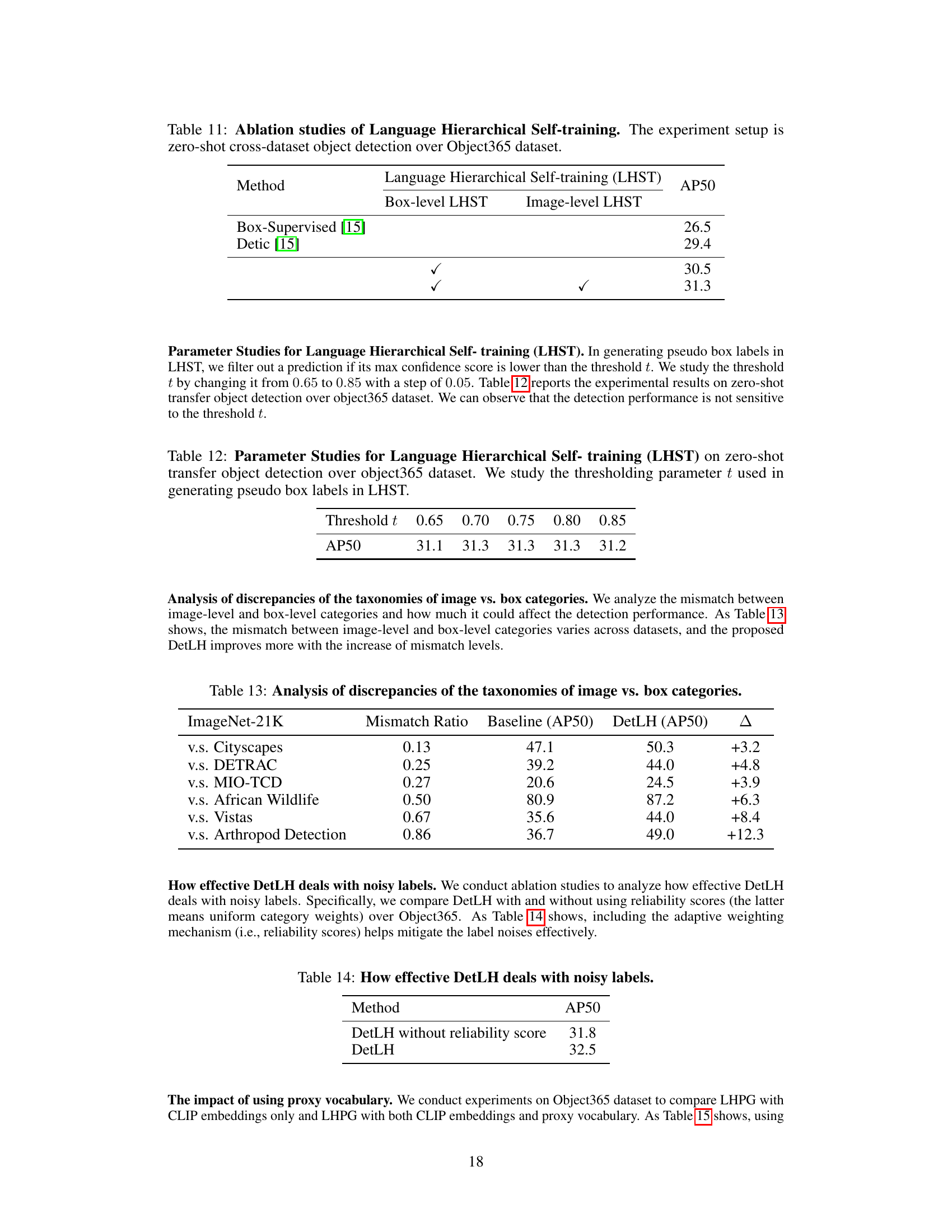
This table shows the result of ablation study on the threshold parameter t used in generating pseudo box labels in LHST. The result shows that the detection performance is not sensitive to the threshold t.

This table presents a comparison of different training strategies for Language Hierarchical Self-training (LHST). It shows the AP50 (average precision at 50% IoU) achieved by different methods on the Object365 dataset using a zero-shot cross-dataset object detection setup. The methods compared include Detic [15] as a baseline, Self-training [21], Direct WordNet Hierarchy Labeling [21], a combination of Self-training and Direct WordNet Hierarchy Labeling, and the proposed Language Hierarchical Self-training (LHST). The results demonstrate the superior performance of LHST in this setting.

This table presents the ablation study of the Language Hierarchical Self-training (LHST) method proposed in the paper. It shows the impact of using box-level LHST and image-level LHST on the performance of zero-shot cross-dataset object detection on the Object365 dataset. The results demonstrate that both box-level and image-level LHST contribute to improved performance, with the combined use of both yielding the best results.

This table presents the ablation study on the threshold parameter t used in the Language Hierarchical Self-training (LHST) method. The threshold t determines whether a prediction is filtered out based on its confidence score. The table shows the AP50 (average precision at 50% intersection over union) values for different threshold values, ranging from 0.65 to 0.85. The results indicate that the model’s performance is not highly sensitive to variations in this threshold parameter.

This table shows the mismatch ratio between ImageNet-21K and other datasets for different object detection tasks. The mismatch ratio indicates the proportion of image-level labels that do not have corresponding box-level labels. The table also provides the AP50 scores of the baseline method and the proposed DetLH method, demonstrating how the DetLH method improves performance as the mismatch ratio increases. The Δ column shows the improvement gained by DetLH over the baseline.

This table presents ablation study results comparing the performance of DetLH with and without reliability scores when dealing with noisy labels in the Object365 dataset. The results demonstrate that incorporating reliability scores improves performance, suggesting that DetLH effectively handles noisy pseudo-labels generated during self-training.

This table presents the ablation study results on using proxy vocabulary in LHPG. The results show that using proxy vocabulary significantly improves the performance compared to using only CLIP embeddings.

This table compares the performance of the proposed DetLH method with other state-of-the-art semi-supervised weakly supervised object detection (WSOD) methods on the Object365 dataset using the AP50 metric. The results show that DetLH outperforms the other methods, highlighting its effectiveness.

This table presents the results of a zero-shot cross-dataset object detection experiment. The experiment evaluated various object detection methods on two datasets, Object365 and Pascal VOC, using only data from LVIS and ImageNet-21K for training. The performance of each method is measured using Average Precision (AP) and its variants (AP50, AP75, APs, APm, APl). A ‘Dataset-specific oracle’ row provides a baseline representing the best possible performance achievable when training and testing on the same dataset. This allows for a comparison of the generalizability of the tested models.

This table presents the results of a zero-shot cross-dataset object detection experiment. Four different object detection methods (WSDDN, YOLO9000, DLWL, Detic) and the proposed method (DetLH) were evaluated on the Object365 and Pascal VOC datasets. The detectors were trained on the LVIS and ImageNet-21K datasets, but not fine-tuned on the target datasets. A ‘dataset-specific oracle’ result is also provided as a benchmark to compare performance against a fully supervised model trained on each target dataset.

This table presents the results of a zero-shot cross-dataset object detection experiment. The experiment evaluated several different object detection models on the Object365 and Pascal VOC datasets. All models were trained on the LVIS and ImageNet-21K datasets, but not fine-tuned on the target datasets (Object365 and Pascal VOC). The table shows the average precision (AP) scores for each model, along with a comparison to fully supervised models trained specifically for each target dataset (Dataset-specific oracles). This provides a measure of how well the models generalize to unseen datasets.

This table presents the results of a zero-shot cross-dataset object detection experiment. Four different object detection methods (WSDDN, YOLO9000, DLWL, Detic) and the proposed method (DetLH) were evaluated on two target datasets (Object365 and Pascal VOC). The evaluation focused on common object classes found in both training and test sets. For comparison, results from fully supervised detectors trained only on the target dataset are also included.

This table presents a comparison of the proposed DetLH method against several other state-of-the-art object detection methods on 14 benchmark datasets. The results are averaged across the datasets for a comprehensive comparison of performance in terms of Average Precision (AP), AP50, AP75, APs (small object AP), APm (medium object AP), and APl (large object AP).
Full paper#