↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Vision-language models, while powerful, struggle to generalize well to new domains significantly different from their training data. This paper addresses this limitation by highlighting the existence of a wide array of expert models specializing in different modalities, tasks, and datasets; however, integrating their knowledge effectively remains a challenge.
The proposed TransAgent framework tackles this by introducing a unified method to transfer knowledge from these isolated expert models to the main vision-language model. This is achieved through multi-source knowledge distillation, enabling flexible collaboration with various agents without impacting the inference speed. Experiments show that TransAgent achieves state-of-the-art performance on multiple visual recognition datasets, particularly excelling in low-shot learning scenarios where data is scarce.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in vision-language models as it introduces a novel framework, TransAgent, for enhancing model generalization. This approach leverages the power of heterogeneous agents, addressing a key challenge in the field. The improved generalization performance and deployment efficiency offer significant advancements, opening up exciting avenues for further research into multi-agent collaboration and knowledge distillation techniques, particularly under low-shot learning scenarios.
Visual Insights#

This figure provides a high-level overview of the TransAgent framework. (a) illustrates the framework’s architecture, showing how it integrates knowledge from various heterogeneous agents (vision, language, and multi-modal) to improve the performance of vision-language foundation models. It highlights the framework’s key features: knowledge versatility, transfer flexibility, and deployment efficiency. (b) presents a comparison of TransAgent’s performance against state-of-the-art (SOTA) methods on 11 visual recognition benchmarks, demonstrating its superior generalization ability, especially in diverse target domains.

This table compares the performance of TransAgent against other state-of-the-art methods on 11 visual recognition datasets using a base-to-novel generalization setting. The results show the base accuracy, novel accuracy, and harmonic mean (HM) for each method on each dataset, demonstrating TransAgent’s superior performance and strong generalization capabilities.
In-depth insights#
Multi-agent synergy#
Multi-agent synergy, in the context of vision-language foundation models, refers to the cooperative interaction of diverse specialized models (agents) to enhance the performance of a core model (e.g., CLIP). Heterogeneity is key—agents possess varied architectures and knowledge bases, trained on different modalities and datasets. Synergy arises from their complementary strengths, where the combined knowledge exceeds the capabilities of any individual agent. The challenge lies in effectively integrating this diverse knowledge, often requiring novel knowledge transfer and ensemble methods that account for the heterogeneous nature of the agents. The paper’s TransAgent framework tackles this by using multi-source knowledge distillation and a mixture-of-agents gating mechanism to adaptively weigh the contributions of various agents, leading to improved generalization in low-shot learning scenarios. Efficient deployment is also crucial, as the synergy shouldn’t come at the cost of increased inference time or computational burden; the proposed method aims to achieve this through the integration of the additional models during training.
Knowledge distillation#
Knowledge distillation, a crucial technique in the paper, focuses on transferring knowledge from multiple heterogeneous agents (specialized models) to a core vision-language foundation model (like CLIP). Instead of direct model fusion, which can be computationally expensive and inflexible, the paper adopts a more efficient strategy. The knowledge is extracted from each agent in a modality-specific manner and then distilled into the foundation model using a soft-weighting mechanism. This approach allows for flexible collaboration and adaptability, as the model learns to effectively leverage the strengths of different agents depending on the task. This distillation technique is particularly useful in low-shot settings, where the foundation model can benefit from the vast knowledge of the expert agents to achieve better generalization on a diverse range of visual recognition tasks. The deployment efficiency is notably enhanced as the expert agents are not needed during inference, keeping the final model lightweight and fast.
Low-shot learning#
Low-shot learning tackles the challenge of training machine learning models effectively with limited labeled data. It’s particularly relevant in scenarios where obtaining large labeled datasets is expensive, time-consuming, or simply impossible. The core idea revolves around leveraging prior knowledge, whether through transfer learning from related tasks or by incorporating techniques like data augmentation or meta-learning, to improve generalization on new, sparsely represented categories. Approaches often focus on maximizing the information extracted from available examples and promoting robustness to unseen data. This is critical for real-world applications where acquiring abundant training data isn’t always feasible. The success of low-shot learning is measured by how well a model trained on a small number of samples performs on new instances from the same category or even related but distinct categories. Recent advancements often involve sophisticated methods combining deep learning models, data augmentation, and meta-learning strategies. This interdisciplinary area offers exciting potential for enabling broader applications of AI in various domains where data is scarce.
Transfer efficiency#
The concept of ’transfer efficiency’ in the context of vision-language foundation models centers on the balance between the improvements in downstream task performance achieved through knowledge transfer from heterogeneous agents and the computational cost incurred. Effective transfer efficiency implies substantial performance gains without significantly increasing inference time or model size. The paper’s TransAgent framework addresses this by employing a multi-source knowledge distillation strategy. By freezing the pre-trained weights of the heterogeneous agents, it avoids the computational overhead of model ensembling during inference, thereby enhancing efficiency. This approach contrasts with methods that rely on cascading or ensembling multiple models, which often lead to significant increases in the computational demands of the inference phase. TransAgent’s ability to achieve state-of-the-art performance with minimal increase in inference time is a key demonstration of its transfer efficiency. The efficiency is further improved by unloading the external agents after the knowledge distillation process, keeping the inference pipeline lean and fast. The results clearly show the effectiveness of this approach compared to others, especially in low-shot learning scenarios where data scarcity makes efficient knowledge utilization crucial.
Future work#
The paper’s success in leveraging heterogeneous agents for vision-language model enhancement opens exciting avenues for future research. A crucial next step is to investigate methods for handling the inherent diversity and potential irrelevance of knowledge from various agents. This could involve more sophisticated gating mechanisms or novel distillation strategies that selectively incorporate beneficial information while filtering out noise or conflicting knowledge. Further exploration is needed into scenarios with even more limited data or entirely unsupervised settings. Scaling to larger models and datasets is vital to further unlock the potential of heterogeneous agent collaboration, possibly requiring more efficient training techniques and parallel processing. Finally, assessing the robustness of TransAgent across different visual tasks and language domains would greatly enhance the model’s generalizability and applicability.
More visual insights#
More on figures

This figure illustrates the methods used for vision and language agent collaboration in the TransAgent framework. (a) shows how visual knowledge from various vision agents (DINO, MAE, ViTDet, SAM) is combined using a Mixture-of-Agents (MoA) gating mechanism to create gated visual tokens, which are then used in layer-wise feature distillation to enhance CLIP’s vision encoder. (b) shows how textual knowledge from language agents (GPT-3, Vicuna, BERT) is integrated using MoA gating, generating gated textual tokens that undergo class-specific feature distillation with CLIP’s textual features to improve CLIP’s textual representation.
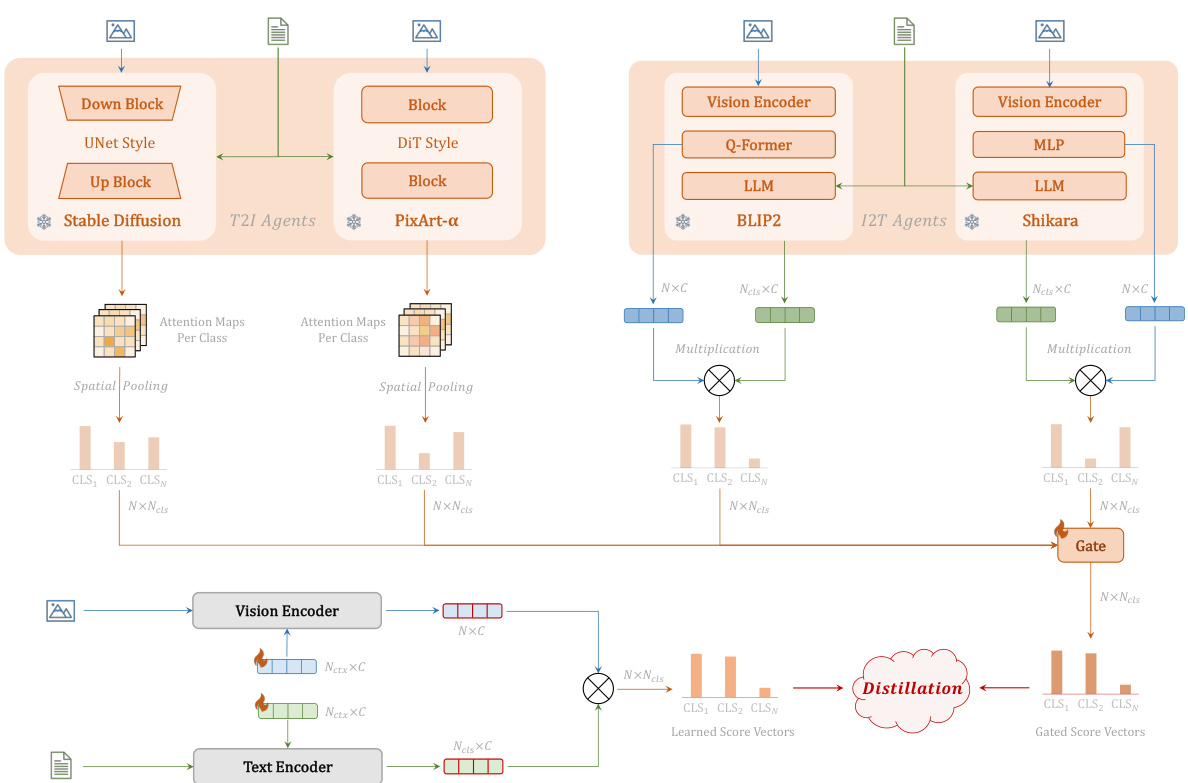
This figure illustrates the Multi-modal Agent Collaboration (MAC) part of the TransAgent framework. It shows how knowledge is extracted from both Text-to-Image (T2I) and Image-to-Text (I2T) models. For T2I models, cross-attention maps are extracted and processed via LogSumExp (LSE) pooling to get score vectors. For I2T models, cosine similarity between projected visual features and LLM textual features generates score vectors. These score vectors from different multi-modal agents are then gated and used in score distillation with CLIP’s learned score vectors to better align the learnable prompts.

This figure provides a comprehensive overview of the TransAgent framework. Panel (a) illustrates the architecture, showing how multiple heterogeneous agents (vision, language, and multi-modal) contribute their knowledge to a vision-language foundation model (like CLIP). Panel (b) presents a comparison of TransAgent’s performance against state-of-the-art (SOTA) methods on eleven visual recognition datasets, highlighting its superior generalization capabilities, particularly in scenarios with significant domain shifts.
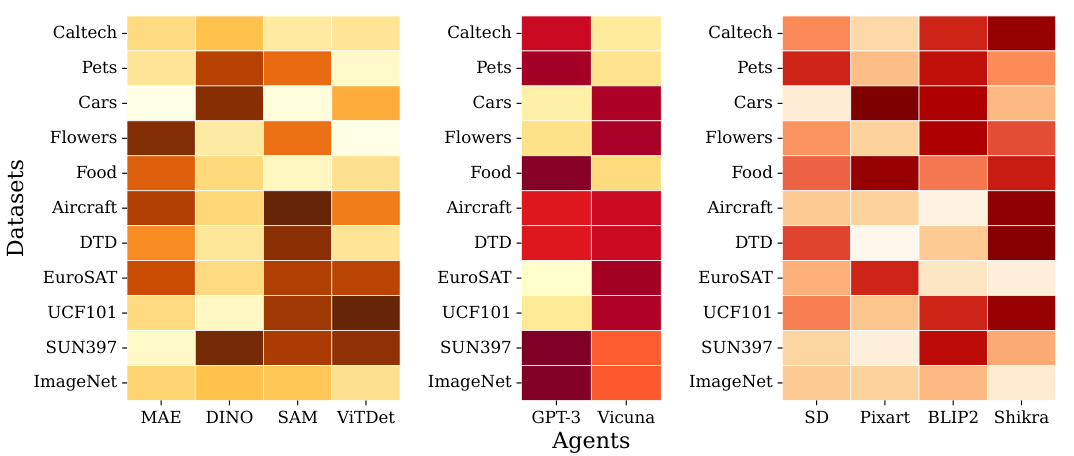
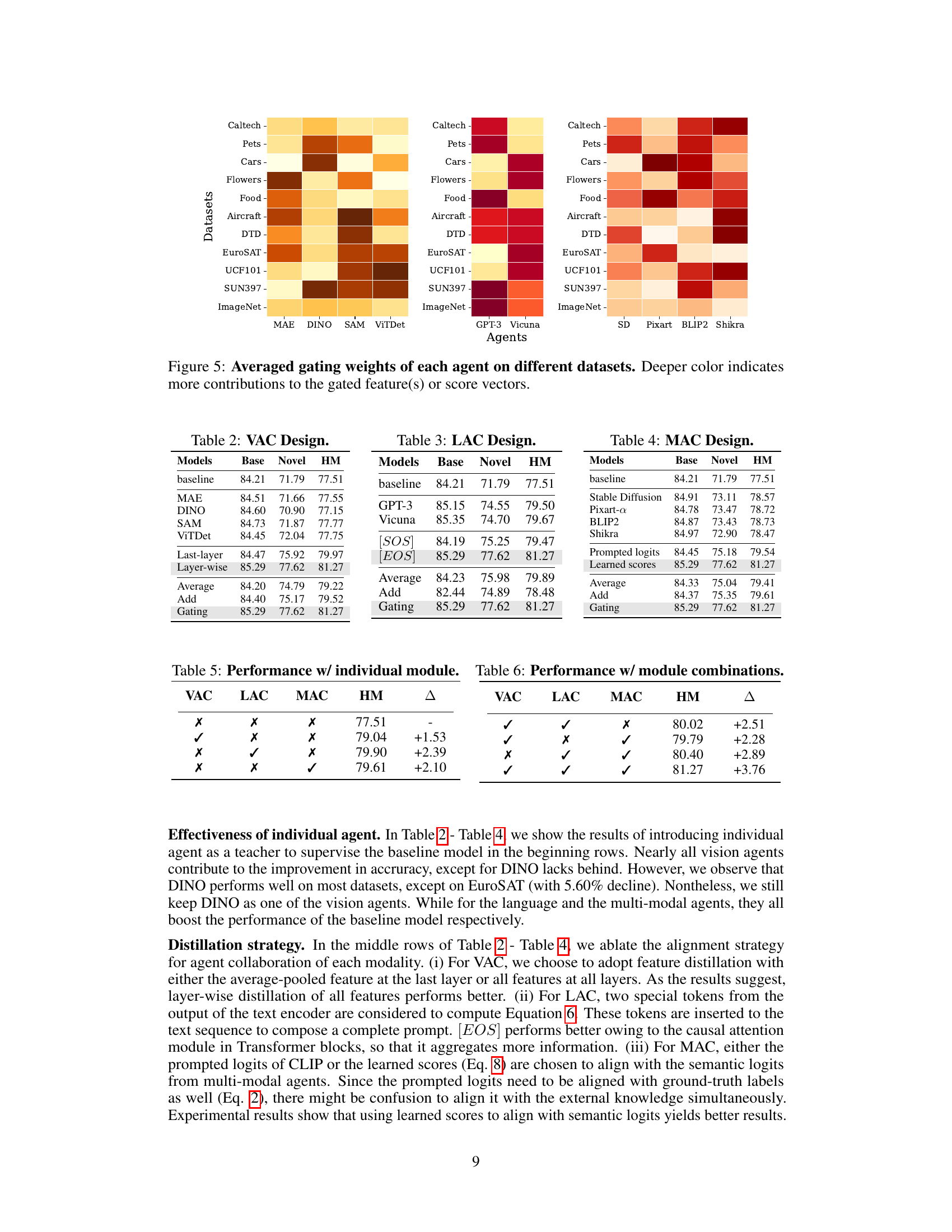
This figure visualizes the contribution of each agent (Vision, Language, and Multimodal agents) in the TransAgent framework across different datasets. The heatmap shows the average gating weights, where darker colors represent a stronger influence of a particular agent on the gated features or score vectors within each dataset. This highlights the adaptive nature of TransAgent, which automatically selects agents based on their relevance to the specific dataset.
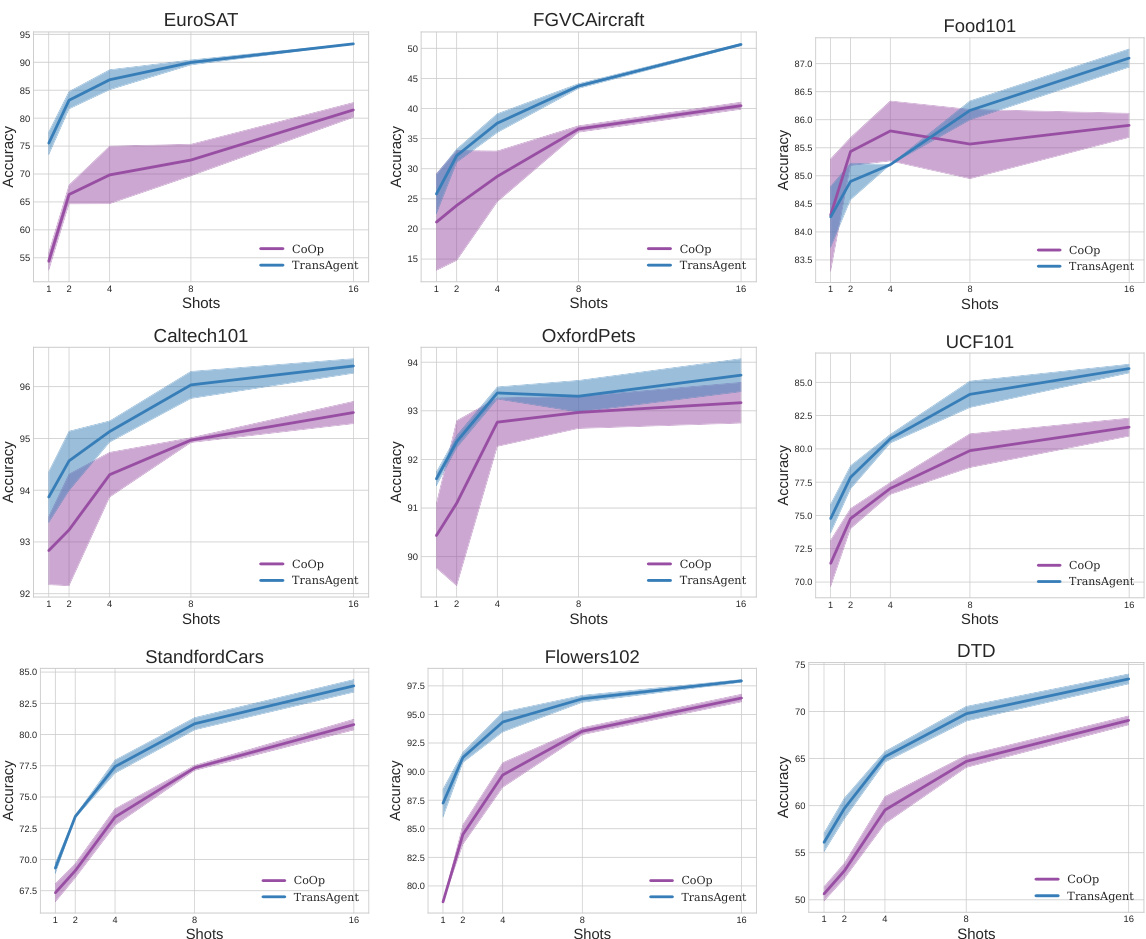
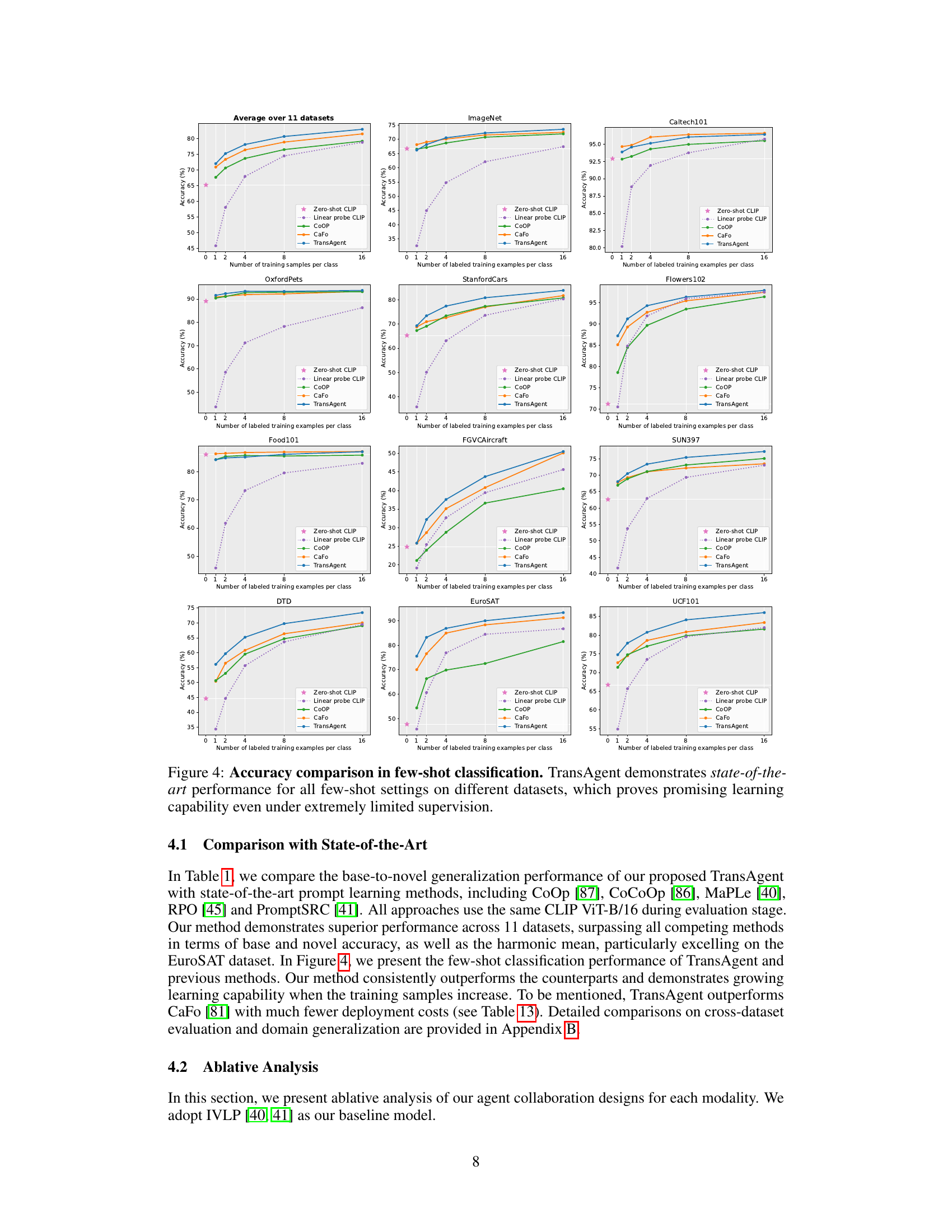
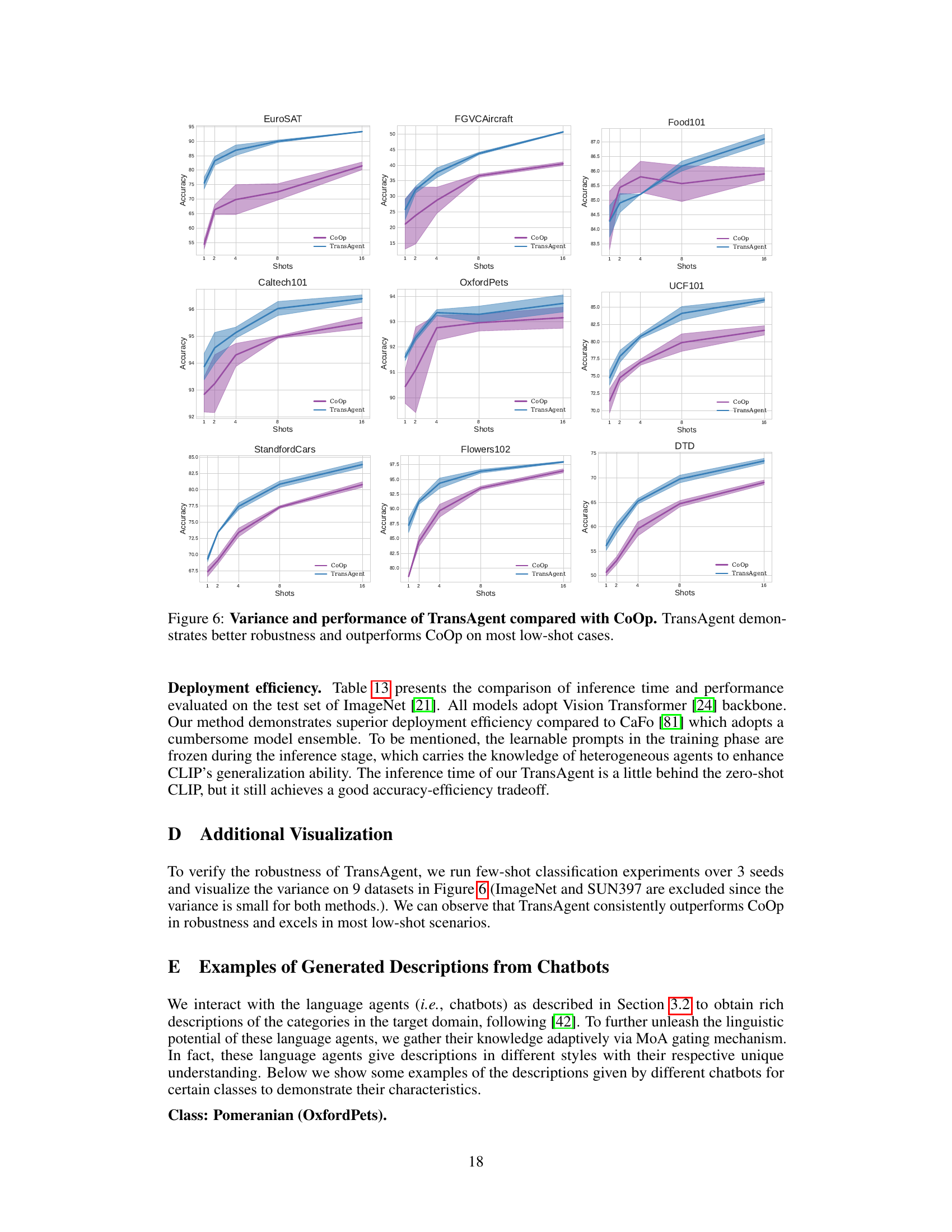
This figure compares the performance of TransAgent and CoOp on eleven visual recognition datasets under low-shot learning scenarios. Each subplot represents a dataset, showing the accuracy with varying numbers of training samples (shots) per class. The shaded areas represent the variance across multiple runs. The results demonstrate that TransAgent consistently outperforms CoOp across different datasets and exhibits greater robustness (smaller variance) in most cases, highlighting its superior performance under low-shot learning conditions.
More on tables
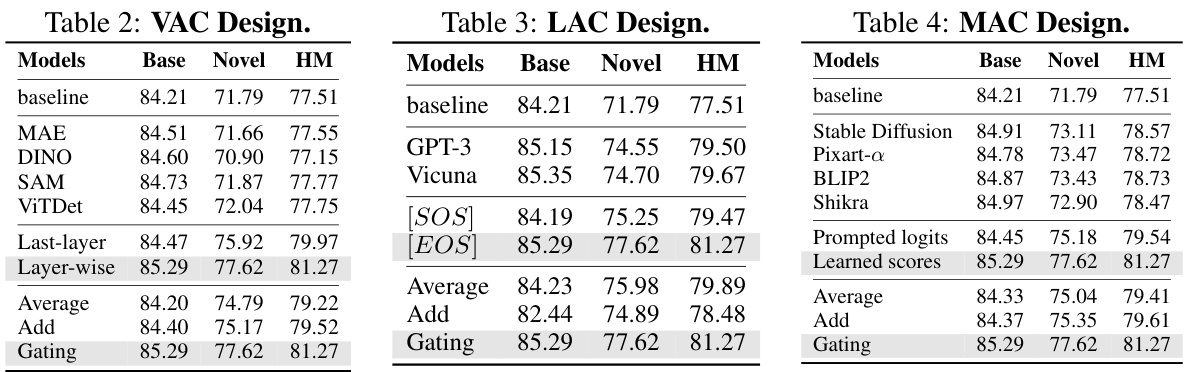
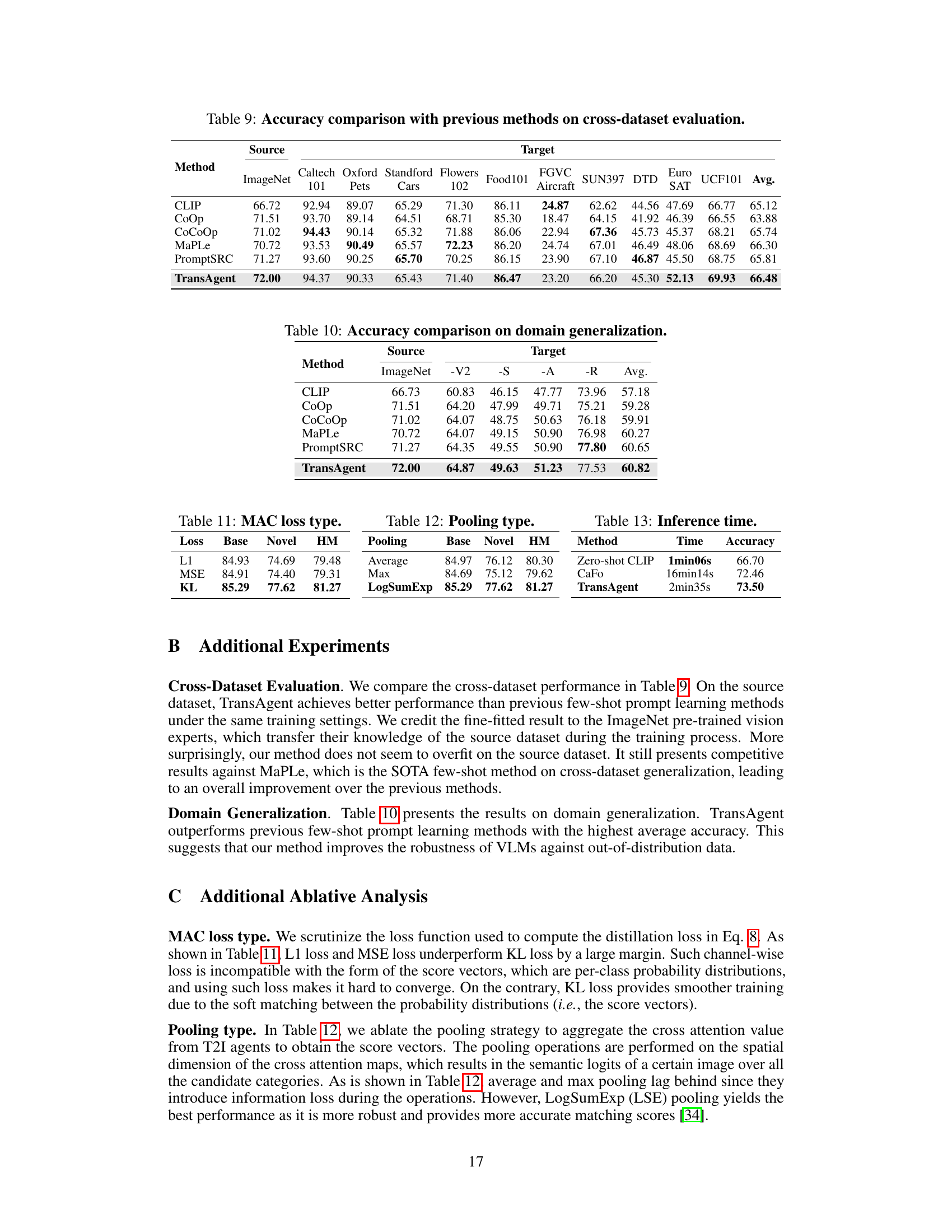
This table compares the performance of TransAgent against other state-of-the-art methods on eleven visual recognition datasets. The comparison focuses on ‘base-to-novel’ generalization, where models are trained on a subset of classes and evaluated on both the training and unseen classes. The results show the base accuracy, novel accuracy, and harmonic mean (HM) across various datasets, highlighting TransAgent’s superior performance and generalization capabilities.

This table compares the performance of TransAgent against other state-of-the-art methods on base-to-novel generalization across 11 datasets. The table shows base accuracy, novel accuracy, and harmonic mean (HM) for each method on each dataset. TransAgent consistently outperforms other methods, highlighting its strong generalization capabilities.

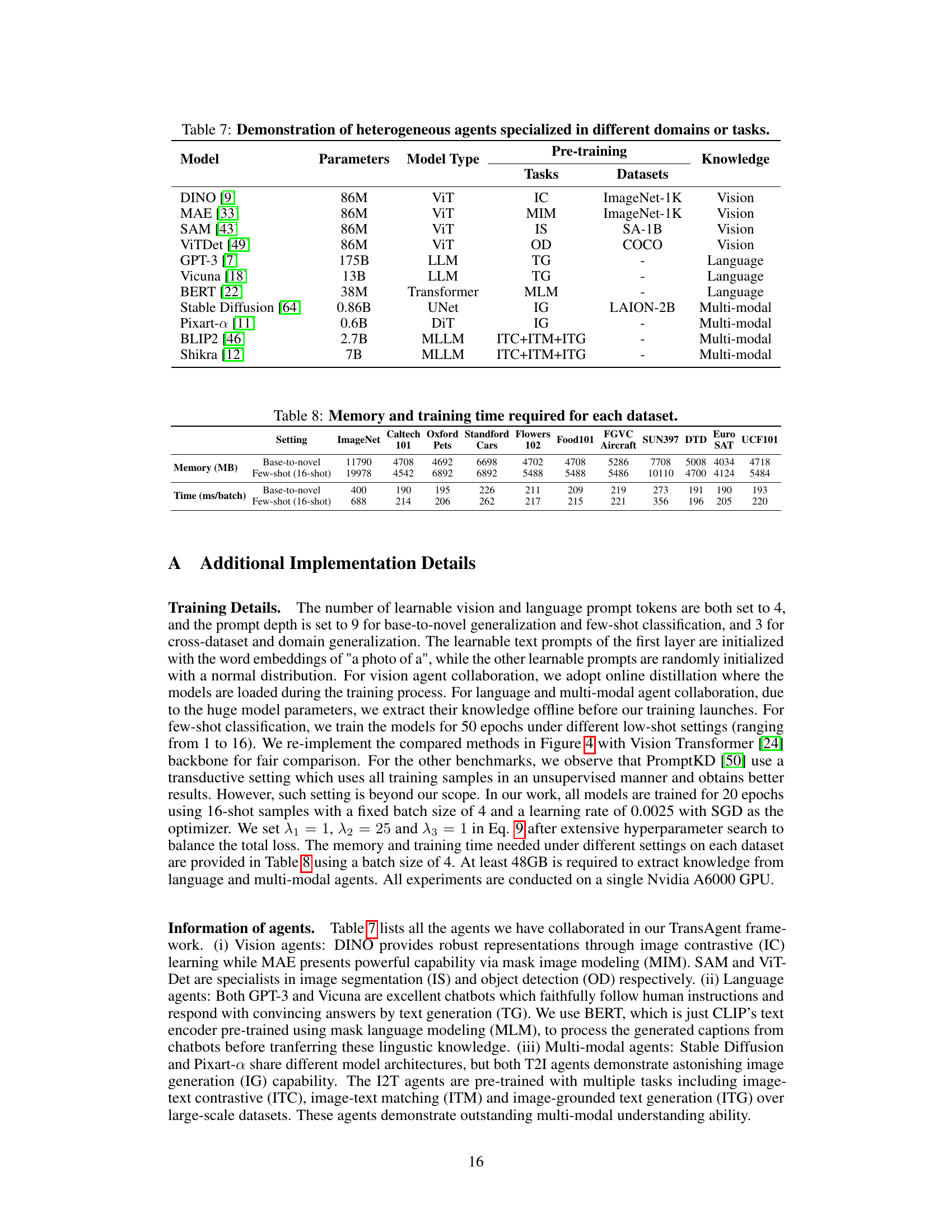
This table lists the eleven heterogeneous agents used in the TransAgent framework. For each agent, it provides the number of parameters, model type, pre-training tasks, and the datasets used for pre-training. The agents are categorized into vision, language, and multi-modal agents based on their specialization.

This table shows the memory usage (in MB) and training time per batch (in milliseconds) needed for each dataset used in the experiments. The experiments were performed under two different settings: base-to-novel generalization and few-shot (16-shot) classification. The table lists the memory and time requirements for each of the 11 datasets used in the paper.

This table compares the performance of the proposed TransAgent model against other state-of-the-art methods on 11 visual recognition datasets. The comparison focuses on base-to-novel generalization, meaning the models are trained on a subset of classes and tested on both the training classes and new classes. The results show the base accuracy, novel accuracy, and harmonic mean (HM) across these datasets. The table highlights that TransAgent consistently outperforms the existing state-of-the-art models.
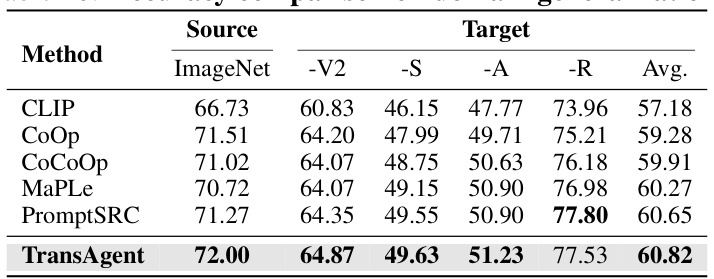
This table compares the performance of TransAgent against other state-of-the-art methods on eleven visual recognition datasets. The comparison is done using a base-to-novel generalization setting (where the model trains on a subset of classes and is tested on both the training and a novel set of classes). All methods utilize the same vision encoder (CLIP’s ViT-B/16). The table highlights TransAgent’s superior performance and strong generalization capabilities by showing that it achieves the best accuracy across all datasets.

This table compares the performance of TransAgent against other state-of-the-art methods on 11 visual recognition datasets using a base-to-novel generalization setting. The results show the base accuracy, novel accuracy, and harmonic mean (HM) for each method on each dataset. TransAgent consistently outperforms the other methods.
Full paper#