↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current image generation models often rely on 2D image tokenization methods like VQGAN, which are computationally expensive and struggle with inherent image redundancies. These methods often require a large number of tokens to represent an image, increasing computational cost and limiting scalability to higher resolutions. Additionally, the fixed grid structure of 2D tokenization restricts efficient exploitation of the redundancy present in natural images.
This paper proposes TiTok, a Transformer-based 1D tokenizer, to overcome these limitations. TiTok converts images into 1D latent sequences, resulting in a significantly more compact representation (only 32 tokens for a 256x256 image). Despite its compact nature, TiTok achieves state-of-the-art performance in image generation, outperforming existing methods with substantially reduced computational costs. The 1D approach allows for flexible representation learning, better leveraging image redundancy.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel 1D image tokenization method (TiTok), which significantly improves the efficiency and effectiveness of image generation models. Its compact representation and speed advantages are highly relevant to current trends in generative AI, paving the way for faster and more efficient models capable of handling higher resolution images. The innovative approach of 1D tokenization opens new avenues for research in efficient image compression and generation.
Visual Insights#

This figure demonstrates the core idea of the TiTok model. It visually compares image reconstruction and generation results using different numbers of tokens. The top row shows the results using TiTok (32 tokens), showcasing high-quality reconstruction and generation. The middle row shows results using the VQGAN (256 tokens), illustrating a noticeable reduction in quality. The bottom row is of the original images, highlighting the significant compression achieved by TiTok. The figure highlights TiTok’s ability to effectively represent images using just 32 tokens, in contrast to existing methods requiring significantly more.
This table compares the performance of various image generation models on the ImageNet 256x256 dataset, evaluated using the ADM metric. It includes both diffusion-based and transformer-based models, showing the FID score, model size (parameters), sampling steps, and throughput. The table highlights the superior performance of the proposed TiTok model in terms of both FID and speed.
In-depth insights#
1D Image Tokens#
The concept of “1D Image Tokens” presents a significant departure from traditional 2D tokenization methods in image processing. Instead of a 2D grid representing image patches, a 1D sequence captures the image’s essence. This approach leverages the inherent redundancy within images, allowing for a much more compact representation. The advantages are clear: reduced computational demands, faster processing, and the potential for significantly smaller model sizes. By breaking free from the 2D grid constraint, the model can better learn higher-level semantic information, leading to improved performance in both image reconstruction and generation tasks. However, challenges remain in effectively capturing both high-level and low-level image details using this reduced dimensionality. The success of this approach highlights the potential of exploring alternative latent space organizations beyond the typical 2D grid, opening new avenues for efficient and effective image processing.
VQ-VAE in TiTok#
The paper leverages Vector Quantized-Variational Autoencoders (VQ-VAEs) within its novel Transformer-based 1D Tokenizer (TiTok) framework. Instead of the typical 2D grid-based latent representations found in VQGAN and other related models, TiTok utilizes a 1D sequence for image representation, significantly impacting efficiency and compactness. This 1D approach allows TiTok to efficiently capture image redundancy, achieving comparable performance to state-of-the-art methods while using significantly fewer tokens (as low as 32). The VQ-VAE component in TiTok is crucial for converting the 1D tokenized image representation into a discrete latent space and back again, forming the core image encoding and decoding process. The inherent efficiency of the 1D structure coupled with the VQ-VAE’s compression capabilities results in substantial speed improvements during both training and inference, making it particularly advantageous for high-resolution image generation.
Two-Stage Training#
The paper proposes a two-stage training approach for its novel 1D image tokenizer, TiTok, which significantly improves performance. The first stage, a “warm-up” phase, uses proxy codes generated from a pre-trained MaskGIT-VQGAN model. This bypasses complex loss functions and GAN training, focusing on optimizing TiTok’s 1D tokenization. This clever strategy stabilizes training and allows TiTok to learn more effectively. The second stage fine-tunes only the decoder on actual RGB values, leveraging the knowledge acquired in the first stage. This setup offers a practical solution to the challenges of training high-performing compact 1D image tokenizers, effectively balancing performance and training efficiency. The results demonstrate that the two-stage training approach surpasses single-stage training by a considerable margin, highlighting the method’s efficacy and robustness in high-resolution image generation.
Compact Image Rep#
The concept of ‘Compact Image Rep’ in a research paper likely revolves around efficient image encoding and representation for tasks like image generation, reconstruction, and compression. A key aspect is reducing the dimensionality of image data while preserving essential information. This might involve techniques like vector quantization, where images are converted into a lower-dimensional latent space using discrete codebooks. The choice of tokenizer architecture (e.g., 1D or 2D transformers) significantly impacts efficiency and performance. Innovative 1D tokenization approaches could offer a more flexible and potentially more compact representation than traditional 2D methods by exploiting inherent image redundancies. The effectiveness of the method is usually evaluated based on the balance between compaction rate, reconstruction fidelity, and the generative performance of any subsequent model. Ultimately, a successful ‘Compact Image Rep’ method minimizes computational costs and storage needs while maximizing the quality of image synthesis or retrieval.
Future Work#
Future research directions stemming from this 1D image tokenization work are plentiful. Extending TiTok to other modalities, such as video, is a natural progression, leveraging the inherent temporal redundancy for improved compression and generation. Exploring alternative tokenization methods, beyond the VQ-VAE framework, like using learned hash tables or other quantization techniques, could further improve efficiency and quality. The interplay between tokenizer size and generative model size also merits further investigation; the study suggests a synergistic relationship, but a more systematic analysis would be beneficial. Finally, addressing potential ethical concerns arising from the generation of high-quality images at speed is crucial. This could involve developing strategies for detecting and mitigating the misuse of this technology for creating deepfakes or other forms of misinformation.
More visual insights#
More on figures
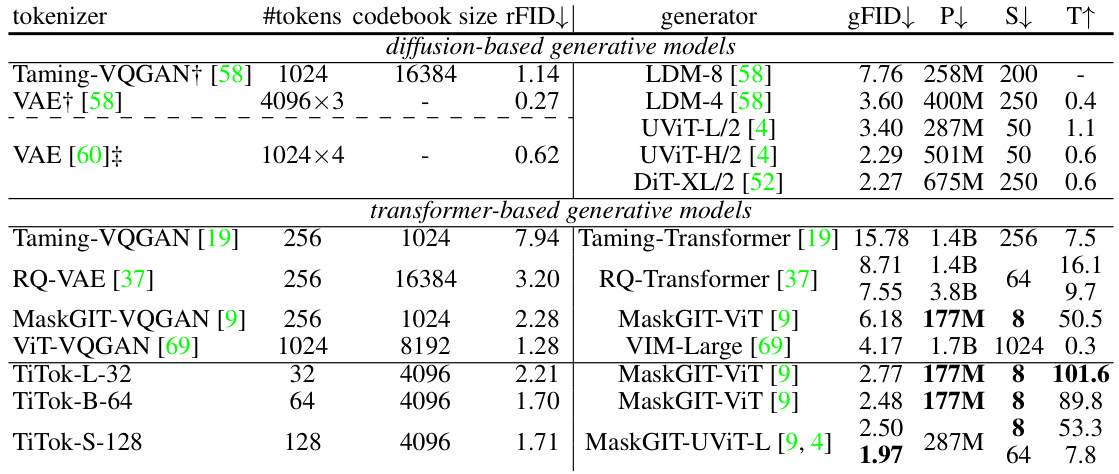
This figure compares the speed and image quality (measured by FID score) of the proposed TiTok model against several state-of-the-art image generation models on ImageNet datasets with resolutions of 256x256 and 512x512. The speed-up is calculated relative to the DiT-XL/2 model, and all speed measurements are done using an A100 GPU. The figure demonstrates that TiTok achieves competitive or superior image quality with significantly faster generation times.
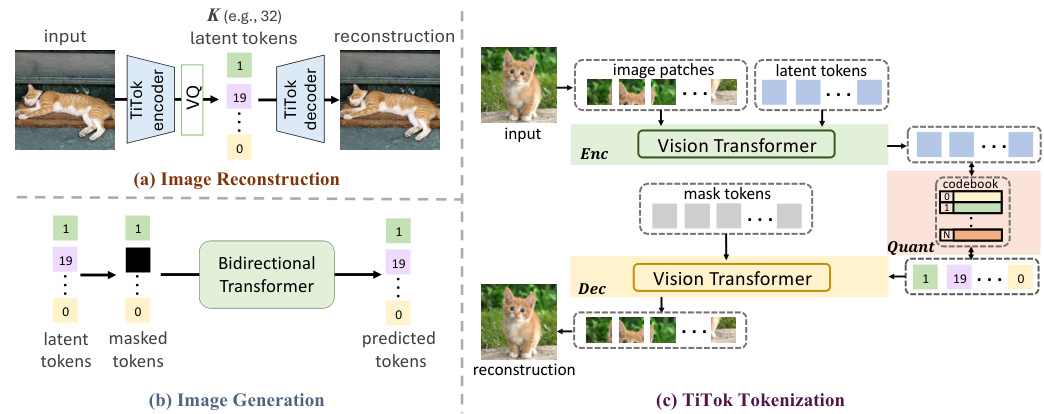
This figure illustrates the TiTok framework for image reconstruction and generation. It shows the process of encoding image patches and latent tokens using a Vision Transformer (ViT) encoder, vector quantization of latent tokens, and decoding using a ViT decoder to reconstruct the image. The generation process involves masking tokens and using a bidirectional transformer to predict masked tokens, which are then decoded into an image. The figure also demonstrates the overall architecture of TiTok, which includes an encoder, quantizer, and decoder.
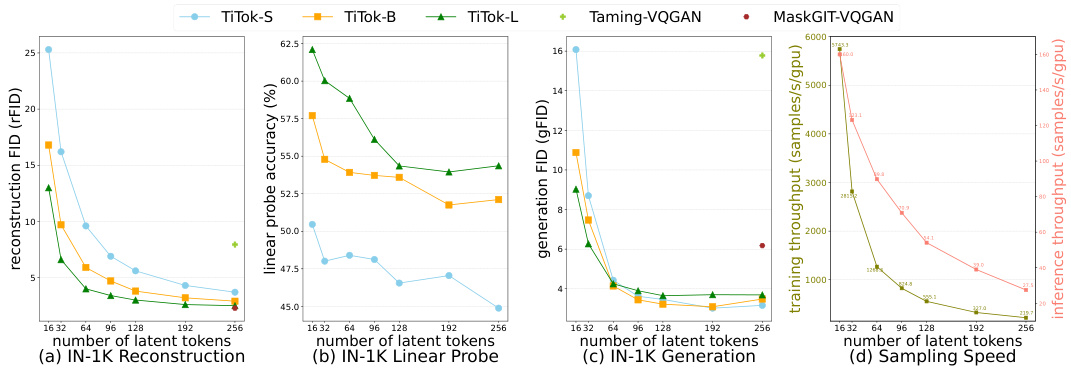
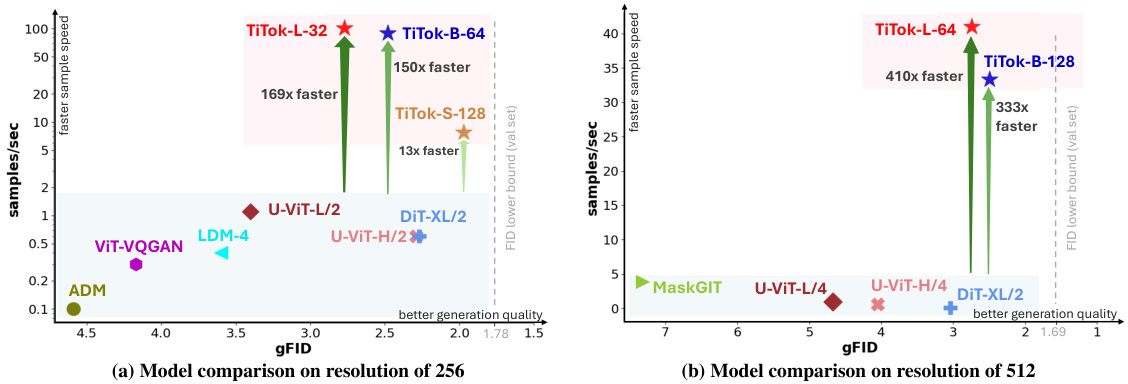
This figure presents the results of preliminary experiments conducted to analyze the impact of various factors on TiTok’s performance. It displays four sub-figures: (a) Reconstruction FID on ImageNet-1K; (b) Linear probe accuracy on ImageNet-1K; (c) Generation FID on ImageNet-1K; and (d) Sampling speed. Each sub-figure shows how different variants of TiTok perform with different numbers of latent tokens (from 16 to 256).

This figure displays sample images generated using the MaskGIT framework with different TiTok variants (TiTok-L-32, TiTok-B-64, TiTok-S-128). Each row represents a different TiTok variant, and each column shows a generated image corresponding to a specific ImageNet class (macaw, lion, jack-o’-lantern, orange, daisy, bubble, valley). The figure demonstrates the ability of TiTok to generate images at different levels of detail and quality based on the number of tokens used and the model size. The ImageNet class name is displayed below each column of images.

This figure shows a diverse set of images generated using the TiTok-L-32 model in conjunction with the MaskGIT framework. The images represent a wide range of ImageNet classes, highlighting the model’s ability to generate varied and high-quality samples across different visual concepts and styles. The diversity showcased demonstrates the model’s robustness and capacity to generalize well to unseen data.

This figure shows the reconstruction results obtained using different model sizes (S, B, L) and numbers of latent tokens (16, 32, 64, 128, 256). Each row represents a different class of images, and each column represents a different number of latent tokens. The results demonstrate that larger model sizes lead to better image quality, even with fewer latent tokens. This is because larger models are able to learn more complex representations of the images, which allows them to reconstruct the images more accurately even when the number of latent tokens is limited.

This figure displays a collection of 256x256 images generated using the TiTok-L-32 model in an uncurated fashion, meaning the images were not specially selected or filtered. The caption indicates the model variant used (TiTok-L-32), the image resolution (256x256), and lists the ImageNet class labels for each row of images from left to right and top to bottom. This provides a visual representation of the model’s ability to generate diverse and realistic-looking images from random class labels.

This figure shows the results of image reconstruction experiments using different model sizes and numbers of tokens. The top row demonstrates how increasing the number of tokens improves reconstruction quality, but this improvement plateaus after a certain number of tokens. The subsequent rows show how increasing the model size allows for comparable or better reconstruction quality even with fewer tokens. This indicates that a larger model can better utilize image redundancy and achieve high-quality results even with very compact latent representations.
More on tables

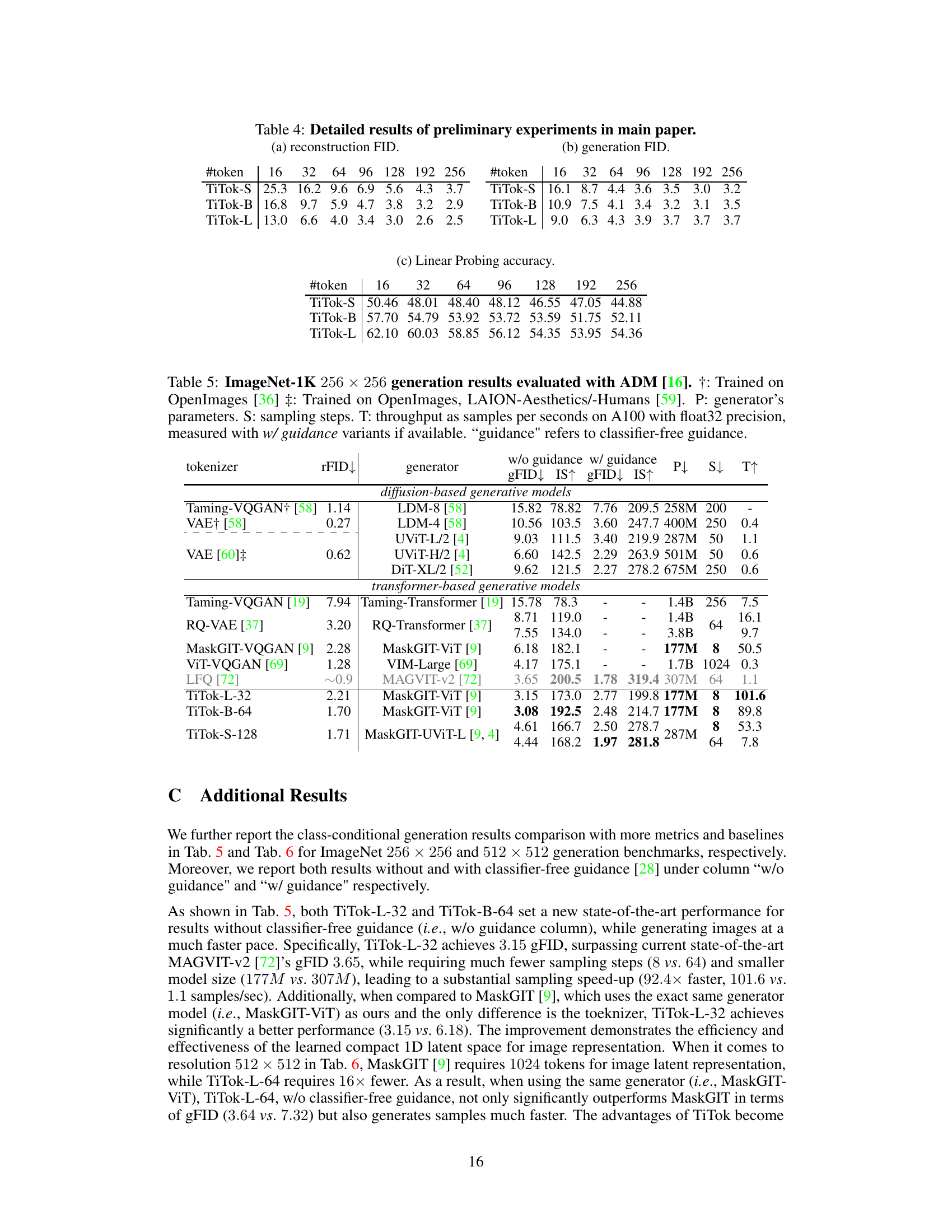
This table presents a comparison of various image generation models on the ImageNet dataset at 512x512 resolution. It specifically focuses on the generative fidelity (gFID), model parameters (P), sampling steps (S), and throughput (T). The models are categorized into diffusion-based and transformer-based methods. The table highlights the performance of TiTok variants against state-of-the-art models, showcasing their efficiency and effectiveness.

This table presents the ablation study results, showing the impact of different design choices on the performance of the TiTok model for image reconstruction and generation. It compares different configurations, including tokenizer architecture choices and masking schedules used in the MaskGIT framework. The baseline is TiTok-L-32, and each subsequent row shows the results of a specific modification to this baseline. The final configurations are highlighted in grey. Note that the generation results are measured without decoder fine-tuning for these experiments.

This table presents a comprehensive overview of the preliminary experimental results obtained using different TiTok variants. It includes three sections, showing the reconstruction FID (a), generation FID (b), and linear probe accuracy (c) for each variant. The results are broken down by the model size (TiTok-S, TiTok-B, TiTok-L) and the number of latent tokens (16, 32, 64, 96, 128, 192, 256). This provides a detailed analysis of the impact of different hyperparameters on the model’s performance across different evaluation metrics.

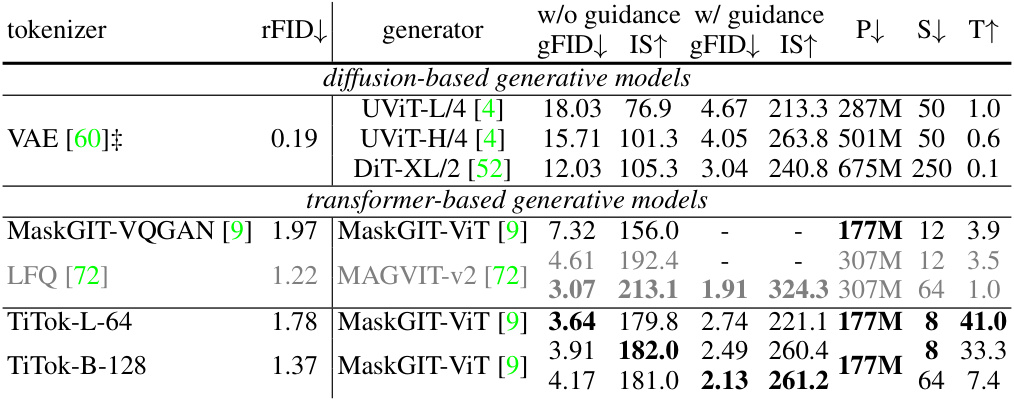
This table presents a comparison of various image generation models on the ImageNet-1K dataset at 256x256 resolution, using the ADM evaluation metric. It shows the reconstruction FID (rFID), generation FID (gFID), Inception Score (IS), model parameters (P), number of sampling steps (S), and throughput (T) for different models, including those based on diffusion and transformer architectures. The table highlights the performance of the proposed TiTok model against other state-of-the-art models, showing its competitive performance and significant speed advantages.
This table presents the results of image generation experiments on the ImageNet-1K dataset at 512x512 resolution. It compares various models, including TiTok variants, in terms of reconstruction FID (rFID), generation FID (gFID), Inception Score (IS), the number of parameters (P), sampling steps (S), and throughput (T). The models are evaluated using the ADM [16] framework, trained on OpenImages, LAION-Aesthetics, and LAION-Humans datasets [59], with throughput measured in samples per second on an A100 GPU at float32 precision. The table highlights the performance of TiTok variants against state-of-the-art diffusion and transformer-based generative models.
Full paper#