↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Real-world image super-resolution (Real-ISR) aims to enhance low-quality images, but existing methods using diffusion models are computationally expensive and generate uncertain outputs. The challenge lies in efficiently restoring high-quality images from real-world, complex degradations while maintaining image naturalness. Current methods often start from random noise and require multiple steps, increasing computation.
This paper introduces OSEDiff, a one-step effective diffusion network for Real-ISR. OSEDiff directly uses the low-quality image as input, eliminating uncertainty from random noise and greatly reducing computational costs. It also employs variational score distillation in the latent space, ensuring that the single-step diffusion produces high-quality and natural-looking images. Experiments demonstrate that OSEDiff matches or surpasses the performance of multi-step methods while being significantly faster.
Key Takeaways#
Why does it matter?#
This paper is important because it presents OSEDiff, a novel one-step diffusion model for real-world image super-resolution that outperforms existing methods in terms of speed and quality. This is a significant advance in the field, as it addresses the computational cost and uncertainty issues associated with traditional multi-step diffusion models. The approach of directly using the low-quality image as the starting point for diffusion is a significant contribution. The research also introduces valuable techniques like variational score distillation to improve the quality of the generated images.
Visual Insights#
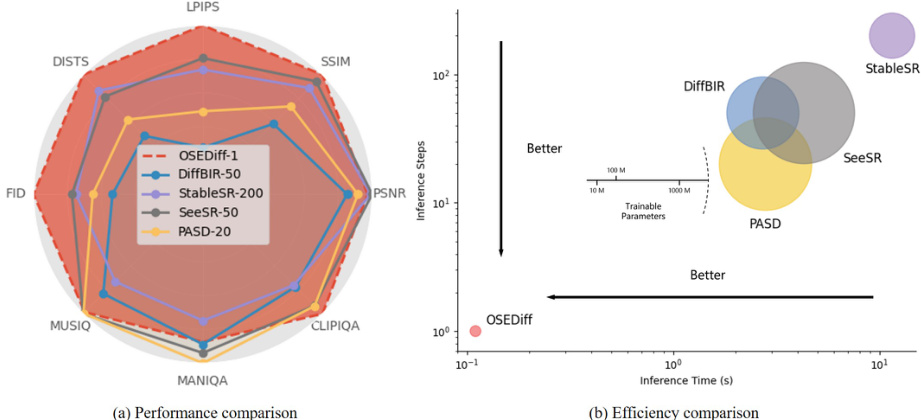
This figure compares the performance and efficiency of OSEDiff against other state-of-the-art real-world image super-resolution (Real-ISR) methods based on Stable Diffusion (SD). The left panel (a) shows a radar chart comparing various image quality metrics, demonstrating that OSEDiff achieves top performance using only one diffusion step, unlike other methods needing dozens or hundreds of steps. The right panel (b) presents a comparison in terms of model size, trainable parameters, and inference time, showing that OSEDiff is substantially more efficient than other methods.
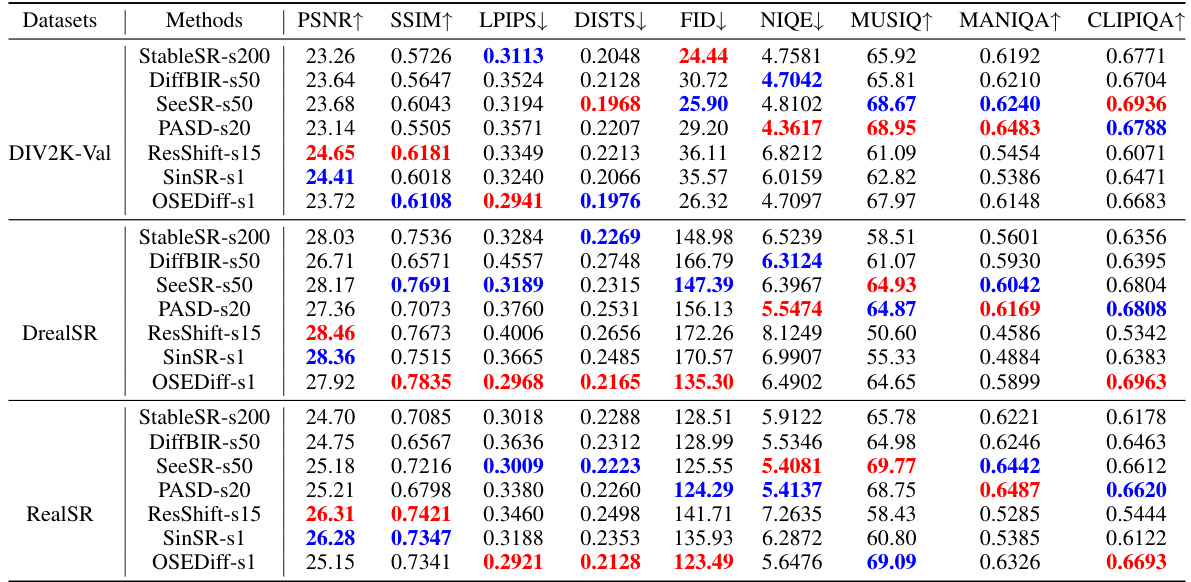
This table presents a quantitative comparison of the proposed OSEDiff model against several state-of-the-art real-world image super-resolution (Real-ISR) methods. The comparison is done across multiple metrics (PSNR, SSIM, LPIPS, DISTS, FID, NIQE, MUSIQ, MANIQA, CLIPIQA) on three benchmark datasets (DIV2K-Val, DrealSR, RealSR). The number of diffusion steps used by each method is also indicated. The best and second-best results for each metric are highlighted to easily identify the top performers.
In-depth insights#
One-Step Diffusions#
One-step diffusion models offer a compelling alternative to their multi-step counterparts for image generation tasks. The core idea is to significantly reduce computational cost and latency by achieving high-quality results in a single diffusion step, eliminating the iterative refinement process inherent in traditional methods. This approach necessitates careful design choices, such as choosing an appropriate starting point other than random noise to leverage prior information and employing advanced techniques, like score distillation, to ensure the generated outputs align with natural image distributions. Although simplifying the process, one-step diffusions demand more sophisticated regularization strategies to compensate for the lack of iterative refinement’s error correction. Careful design of the network architecture and loss functions is crucial for success, potentially employing techniques like trainable layers in pre-trained models to adapt them to the specific task while retaining their power. The trade-offs between computational efficiency and output quality must be carefully considered and balanced. Successfully addressing this challenge could lead to significant advancements in real-time applications requiring high-fidelity image synthesis.
VSD Regularization#
Variational Score Distillation (VSD) regularization, as applied in the context of image generation, is a powerful technique to enhance the quality and realism of generated images. It leverages the inherent strengths of pre-trained diffusion models, which have learned rich representations of natural image distributions from vast datasets. By employing VSD, the authors aim to align the distribution of the generated images (from their one-step diffusion model) with that of the high-quality natural images learned by the pre-trained model. This is achieved by minimizing the KL-divergence between the two distributions in the latent space. The effectiveness of VSD lies in its ability to guide the generation process towards more natural-looking outputs, mitigating issues such as artifacts or unnatural textures that often arise from direct optimization methods. The use of latent space enhances computational efficiency and stabilizes the training process, making VSD a computationally efficient and effective regularization method for one-step image super-resolution tasks. In essence, VSD serves as a bridge, transferring the learned knowledge of natural image distribution from a powerful pre-trained model to a more efficient one-step model, significantly improving the quality of the resultant images.
Real-ISR Efficiency#
Real-world image super-resolution (Real-ISR) efficiency is paramount, balancing high-quality results with computational feasibility. Existing methods often prioritize quality, employing multiple diffusion steps or complex GAN architectures, leading to high computational costs and slow inference times. This is a significant drawback, hindering real-time or resource-constrained applications. One-step approaches aim to improve efficiency by reducing the number of iterations required, but may sacrifice image quality. The trade-off between speed and accuracy is a critical design consideration, requiring careful optimization of network architecture, loss functions, and training strategies. Evaluating efficiency involves not just inference speed, but also model size and the number of trainable parameters. Smaller, more efficient models can drastically reduce the memory footprint and computational demands. Achieving Real-ISR efficiency without compromising image quality remains a key challenge, necessitating further research into novel network architectures, efficient training techniques, and effective loss functions that can effectively guide the model with limited computation.
LoRA Finetuning#
LoRA (Low-Rank Adaptation) finetuning is a powerful technique for adapting large pre-trained models like Stable Diffusion to downstream tasks with limited computational resources. Instead of training the entire model, LoRA modifies only a small subset of parameters, significantly reducing memory footprint and training time. This is particularly beneficial for adapting large image generation models to specialized image super-resolution tasks as described in the paper, where training an entire model from scratch is often infeasible. By adding trainable rank decomposition matrices to the original weight matrices, LoRA allows for fine-grained control over the model’s behavior, enhancing performance while preserving the knowledge encoded in the original weights. This approach is particularly relevant when dealing with limited training data, as LoRA’s reduced parameter count reduces the risk of overfitting and enhances the model’s ability to generalize. The effectiveness of LoRA finetuning in this context is demonstrated by the paper’s results, which show comparable or superior performance to full model finetuning while significantly improving efficiency. The key is the balance between the expressiveness of the adapted parameters and the stability of the pre-trained model; this balance is crucial for achieving both high accuracy and efficient inference.
Future Enhancements#
The ‘Future Enhancements’ section of a research paper would ideally delve into potential improvements and extensions of the presented work. This might involve exploring alternative network architectures, potentially beyond the current UNet backbone, to see if performance can be further optimized or different architectural properties explored. A critical aspect would be investigating methods for enhancing the model’s handling of diverse and complex real-world degradations. The current model’s success is partially reliant on a specific training pipeline, and expanding its robustness to unforeseen degradation types would be important. Further research might involve exploring different loss functions and their impact on the generated image quality and fidelity. A comparative analysis of different regularization techniques would also be insightful. Finally, scaling the model to handle higher-resolution images more efficiently is a necessary future direction, possibly requiring optimization techniques or architectural adjustments to manage computational demands.
More visual insights#
More on figures

This figure illustrates the training framework of the OSEDiff model. It shows how the low-quality (LQ) image is processed through an encoder, a finetuned diffusion network, and a decoder to generate a high-quality (HQ) image. The process includes text prompt extraction, variational score distillation (VSD) in the latent space, and the use of both a frozen pre-trained regularizer and a fine-tuned regularizer. The diagram clearly shows the flow of data and gradients throughout the network, explaining the key components of the OSEDiff model’s training process.

This figure presents visual comparisons of different Real-ISR methods on two real-world image examples (a face and a leaf). It showcases the differences in detail preservation and realism between the various methods, highlighting OSEDiff’s ability to reproduce high-quality and realistic details even with only one diffusion step. The figure emphasizes OSEDiff’s competitive results against multi-step methods such as StableSR, DiffBIR, SeeSR, PASD, ResShift, and SinSR.

This figure compares the results of using three different text prompt extraction methods with the OSEDiff model on a real-world LQ image. The first method uses no text prompt, the second method uses DAPE (degradation-aware prompt extraction), and the third method uses LLaVA-v1.5. The image shows that using a text prompt significantly improves the quality of the generated HQ images, especially using LLaVA-v1.5 that provides a more detailed description of the image resulting in a more rich and detailed output.

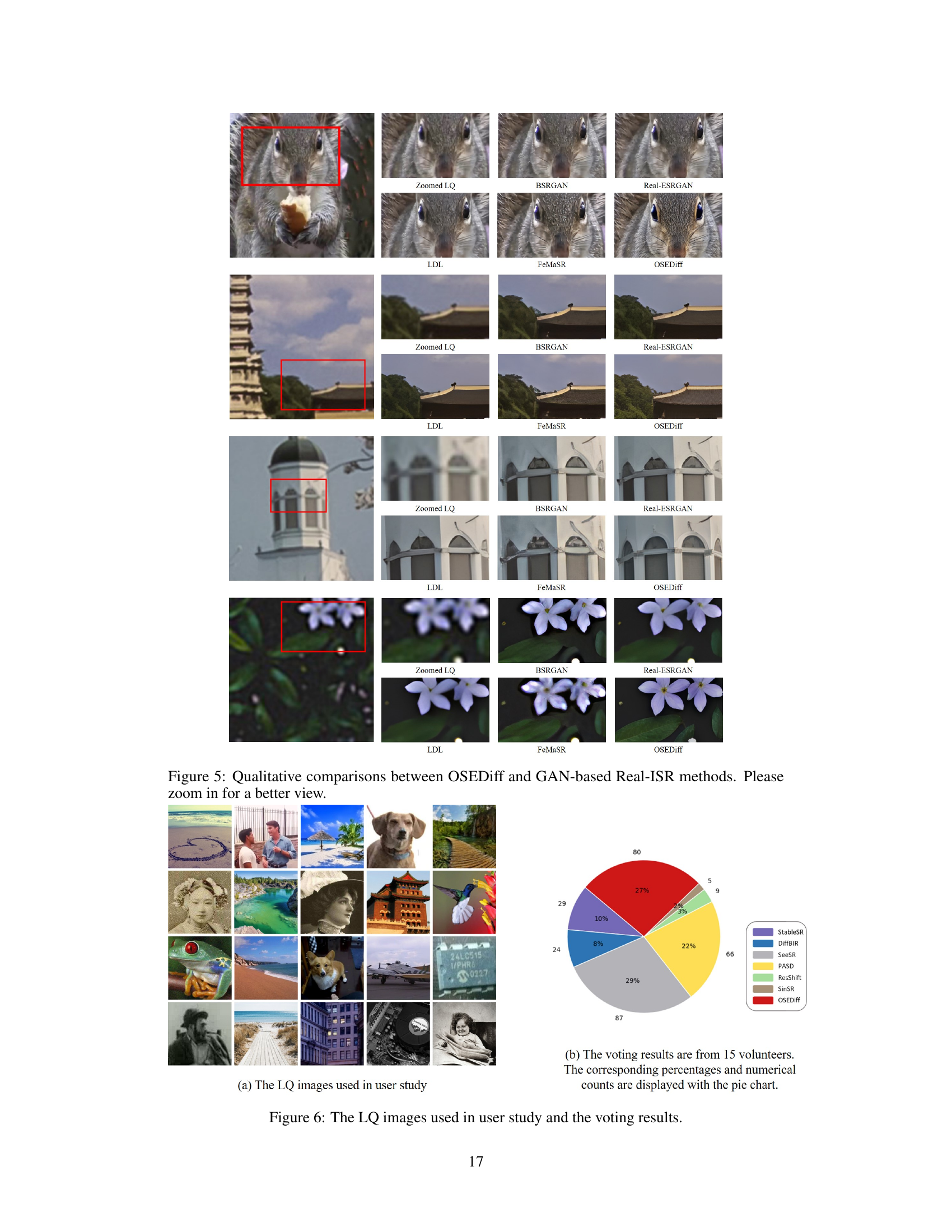
This figure presents a qualitative comparison of image super-resolution results generated by OSEDiff and four other GAN-based methods (BSRGAN, Real-ESRGAN, LDL, and FeMaSR). Each row shows a zoomed-in low-quality (LQ) image and the corresponding high-quality (HQ) images produced by each method. The purpose is to visually demonstrate that OSEDiff produces images with finer details and better visual quality compared to these GAN-based methods.
This figure compares OSEDiff against other state-of-the-art SD-based Real-ISR methods in terms of both performance and efficiency. The left panel (a) shows that OSEDiff achieves the best performance across most metrics on the DrealSR benchmark, using only a single diffusion step. The right panel (b) illustrates OSEDiff’s significant efficiency advantage, exhibiting the fewest trainable parameters and an over 100x speed improvement compared to StableSR.

This figure presents a comparison of the performance and efficiency of OSEDiff against other state-of-the-art SD-based Real-ISR methods. Subfigure (a) shows a performance comparison using the DrealSR benchmark, highlighting OSEDiff’s superior performance across multiple metrics, achieved with only one diffusion step. Subfigure (b) compares the efficiency of the models, demonstrating that OSEDiff is significantly faster and requires fewer trainable parameters than competing methods.
More on tables

This table compares the computational complexity of various Real-ISR methods. It presents the number of inference steps required, the inference time on an A100 GPU, the number of Multiply-Accumulate operations (MACs) representing computational cost, the total number of parameters, and the number of trainable parameters. This allows for a comparison of model efficiency across different approaches.
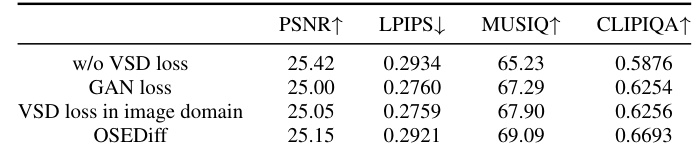
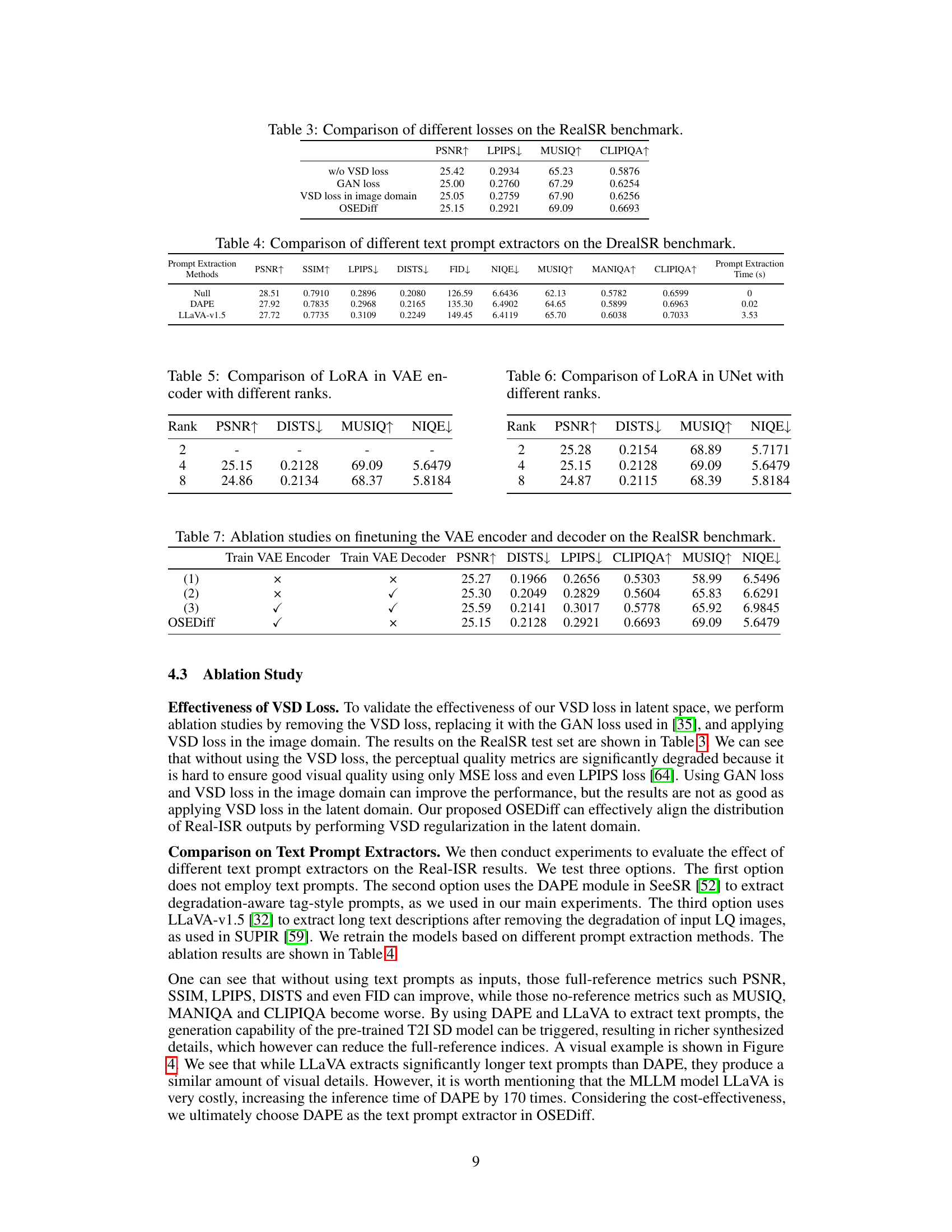
This table presents an ablation study comparing the performance of OSEDiff using different loss functions on the RealSR benchmark. It shows that using Variational Score Distillation (VSD) loss in the latent space produces superior results compared to not using a VSD loss, using GAN loss, or using VSD loss in the image domain. The metrics compared are PSNR, LPIPS, MUSIQ, and CLIPIQA, indicating improvements in perceptual quality and overall image fidelity when using the proposed VSD loss in the latent space.

This table presents a comparison of different text prompt extraction methods used in the OSEDiff model for real-world image super-resolution. The comparison is performed on the DrealSR benchmark, which evaluates performance on various metrics such as PSNR, SSIM, LPIPS, DISTS, FID, NIQE, MUSIQ, MANIQA, and CLIPIQA. The results show that the choice of text prompt extraction method significantly impacts the performance of the Real-ISR model.
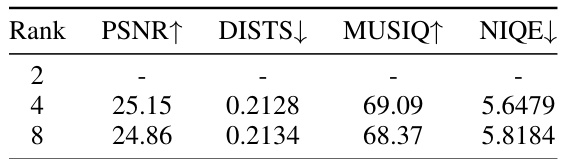
This table presents the results of ablation studies conducted on the RealSR benchmark to evaluate the impact of fine-tuning the VAE encoder and decoder within the OSEDiff model. It shows how different combinations of fine-tuning (training the encoder, training the decoder, training both, or training neither) affect performance metrics such as PSNR, DISTS, LPIPS, CLIPIQA, MUSIQ, and NIQE. The results help to determine the optimal configuration for the VAE components in the OSEDiff model, aiming to strike a balance between performance gains and potential overfitting or instability.

This table presents an ablation study on the impact of varying the rank of LoRA layers in the VAE encoder of the OSEDiff model. It shows how different ranks affect the performance metrics PSNR (higher is better), DISTS (lower is better), MUSIQ (higher is better), and NIQE (lower is better) on the RealSR benchmark. The results indicate that a rank of 4 provides a good balance between performance and stability.

This table presents the results of ablation studies performed on the RealSR benchmark to evaluate the impact of fine-tuning the VAE encoder and decoder in the OSEDiff model. Four different training scenarios are compared: (1) neither the encoder nor decoder is fine-tuned; (2) only the decoder is fine-tuned; (3) both the encoder and decoder are fine-tuned; and (4) OSEDiff’s approach, where only the encoder is fine-tuned. The table shows the performance metrics (PSNR, DISTS, LPIPS, CLIPIQA, MUSIQ, NIQE) achieved in each scenario. This helps to determine which components of the model contribute most significantly to the overall performance and the effectiveness of OSEDiff’s approach.
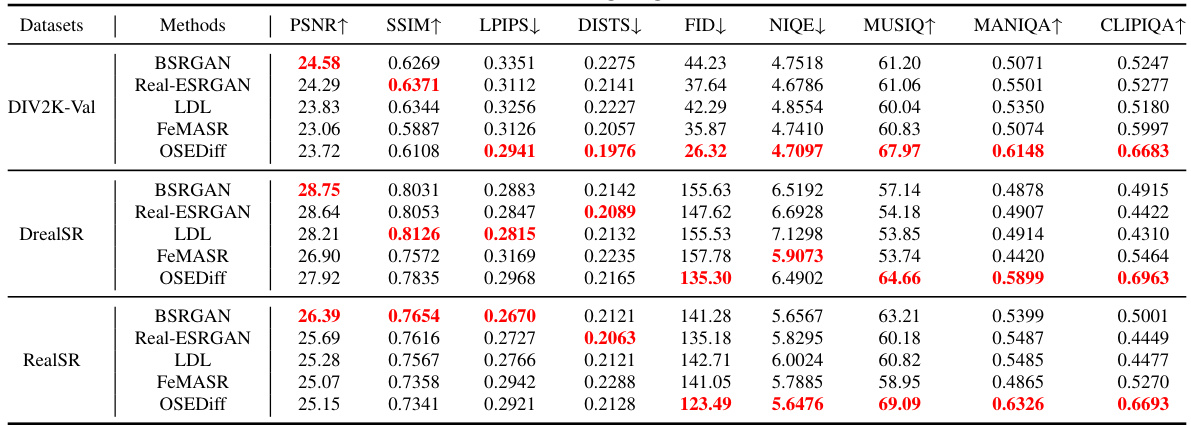
This table presents a quantitative comparison of the proposed OSEDiff method with several state-of-the-art Real-ISR methods on three benchmark datasets: DIV2K-Val, DrealSR, and RealSR. For each method and dataset, the table shows performance metrics including PSNR, SSIM, LPIPS, DISTS, FID, NIQE, MUSIQ, MANIQA, and CLIPIQA. The number of diffusion steps used by each method is also indicated. The best and second-best performing methods for each metric are highlighted in red and blue, respectively. This allows for a direct comparison of OSEDiff’s performance against existing methods in terms of both quantitative metrics and efficiency (number of steps).
Full paper#