TL;DR#
Current vision models struggle with adapting state-space models (SSMs) from language to vision due to spatial locality and varying granularity of visual data. Existing solutions either flatten 2D data into 1D sequences, losing spatial information, or use fixed window partitions, limiting long-range modeling. This paper addresses these challenges.
The proposed QuadMamba model uses a learnable quadtree-based scan to partition images into quadrants of varying granularities. It then adaptively models local dependencies, capturing local detail in informative regions while maintaining efficiency. This end-to-end trainable system, using Gumbel-Softmax, significantly improves performance in image classification, object detection, and segmentation tasks compared to state-of-the-art vision models, demonstrating its effectiveness and efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and sequence modeling. It introduces QuadMamba, a novel vision model that outperforms existing approaches in various tasks. This advance is significant due to its efficient linear-time complexity and improved handling of visual data’s spatial characteristics. The model’s design and results open up new possibilities for SSMs in visual applications and inspire future research in adaptive scanning strategies for efficient visual processing.
Visual Insights#

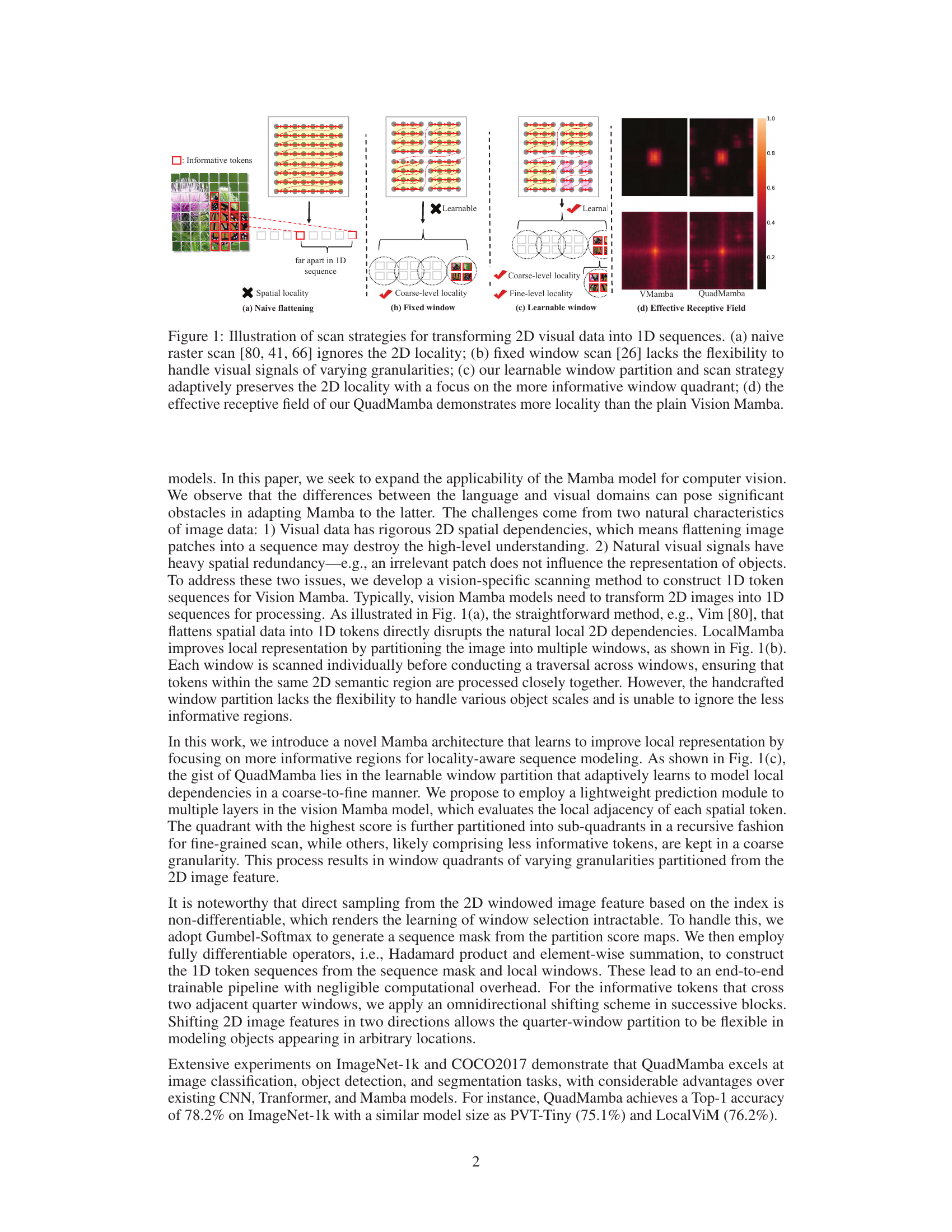
🔼 This figure illustrates different strategies for transforming 2D visual data into 1D sequences suitable for processing by the Mamba model. (a) shows a naive raster scan which loses spatial information. (b) demonstrates a fixed window scan which lacks flexibility for varying granularity in the image. (c) presents the authors’ proposed approach – learnable window partitioning and scanning – which adaptively preserves 2D locality by focusing on informative regions. (d) compares the effective receptive field, showing QuadMamba’s improved locality compared to Vision Mamba.
read the caption
Figure 1: Illustration of scan strategies for transforming 2D visual data into 1D sequences. (a) naive raster scan [80, 41, 66] ignores the 2D locality; (b) fixed window scan [26] lacks the flexibility to handle visual signals of varying granularities; (c) our learnable window partition and scan strategy adaptively preserves the 2D locality with a focus on the more informative window quadrant; (d) the effective receptive field of our QuadMamba demonstrates more locality than the plain Vision Mamba.

🔼 This table compares the performance of QuadMamba with other state-of-the-art models on the ImageNet-1k image classification benchmark. The metrics presented include the number of parameters, floating point operations (FLOPs), top-1 accuracy, and top-5 accuracy. Throughput, measured in images per second on a single V100 GPU, is also included. All models were trained and evaluated using 224x224 resolution images.
read the caption
Table 1: Image classification results on ImageNet-1k. Throughput (images / s) is measured on a single V100 GPU. All models are trained and evaluated on 224x224 resolution.
In-depth insights#
Quadtree Scanning#
Quadtree scanning offers a novel approach to processing 2D image data for state space models (SSMs). Unlike traditional raster scans that destroy spatial locality, or fixed-window methods that lack adaptability, quadtree scanning dynamically partitions the image into variable-sized quadrants. This approach is particularly beneficial for vision tasks due to the inherent spatial dependencies in visual data and the varying granularity of information across different image regions. By learning to prioritize informative regions, quadtree scanning enhances the model’s ability to capture both local and global dependencies, leading to improved performance in vision tasks. The recursive nature of the quadtree allows for multi-scale feature extraction, while the learnable aspect enables end-to-end training, avoiding the limitations of hand-crafted partitioning schemes. Adaptability is a key advantage, as the scanning process can focus on areas of high information density while ignoring less relevant regions, improving efficiency and effectiveness.
Mamba Vision#
Mamba Vision, a hypothetical term based on the ‘Mamba’ State Space Model, likely refers to a novel approach in computer vision that leverages the efficiency and scalability of SSMs. The core idea would likely involve representing visual data as a sequence of states, moving away from traditional methods like raster scans that ignore spatial dependencies. Instead, a Mamba Vision system would focus on capturing the essential information of an image using a dynamic, learned scan pathway. This pathway might selectively attend to relevant image regions, dynamically adjusting the resolution based on the content and the need for information. Consequently, Mamba Vision promises to improve upon existing vision models by addressing inherent issues of computational complexity and inefficient data representation, especially in high-resolution images. The model’s adaptability and potential for parallel processing could lead to advancements in various vision tasks, including object detection, segmentation, and image classification, ultimately making it a powerful and efficient alternative to traditional vision transformers and CNNs. Learned scan pathways offer a new paradigm for vision tasks, which could prove to be beneficial for processing images of varying granularities and local dependencies.
Locality Modeling#
Effective locality modeling in visual state space models is crucial for capturing spatial relationships within images. Approaches like naive flattening, which converts 2D image data into a 1D sequence, fail to preserve critical spatial dependencies, hindering performance. In contrast, QuadMamba employs a quadtree-based strategy for adaptive window partitioning, which allows for the dynamic capture of fine-grained local relationships, particularly within regions of high visual importance. This adaptable approach, coupled with an omnidirectional window shift mechanism, excels at handling various object scales and diverse image content by addressing issues of varying information granularity, significantly improving model performance in visual tasks. The utilization of Gumbel-Softmax ensures the end-to-end trainability of this partition process, enhancing the learning efficiency and model robustness. The QuadMamba’s locality-aware modeling is a key innovation, demonstrating how strategic attention to spatial relationships enhances the performance of state-space models in computer vision.
End-to-End Training#
End-to-end training, a cornerstone of modern deep learning, presents both advantages and challenges. Its primary benefit lies in the seamless integration of multiple stages of a process, eliminating the need for intermediate manual data manipulation or handcrafted feature engineering. This leads to improved performance by optimizing the entire pipeline jointly. However, the complexity increases significantly. Debugging becomes more difficult, as errors can arise from any component in the integrated system. Additionally, data requirements are more demanding as the model needs sufficient data to learn all aspects simultaneously. Careful architectural design and optimization strategies such as regularization and appropriate loss functions are crucial for successful end-to-end training. Despite these challenges, the advantages frequently outweigh the difficulties, leading to powerful models that achieve superior results compared to methods involving modular training.
Future Vision#
A future vision for this research would involve exploring more sophisticated and adaptive scanning methods that go beyond the quadtree approach. This might involve incorporating machine learning techniques to dynamically determine the optimal scanning path based on the image content and task requirements. Additionally, research could focus on extending the model’s capabilities to handle more complex visual data such as videos and 3D point clouds. Improving the model’s efficiency and scalability to handle very high-resolution images and extremely large datasets is another important area for future work. Finally, investigating the model’s robustness to various noise and artifacts present in real-world images would enhance its applicability in practical scenarios. The ultimate goal is to create a highly flexible and adaptable visual state space model capable of handling a vast range of visual data types and complex visual reasoning tasks.
More visual insights#
More on figures
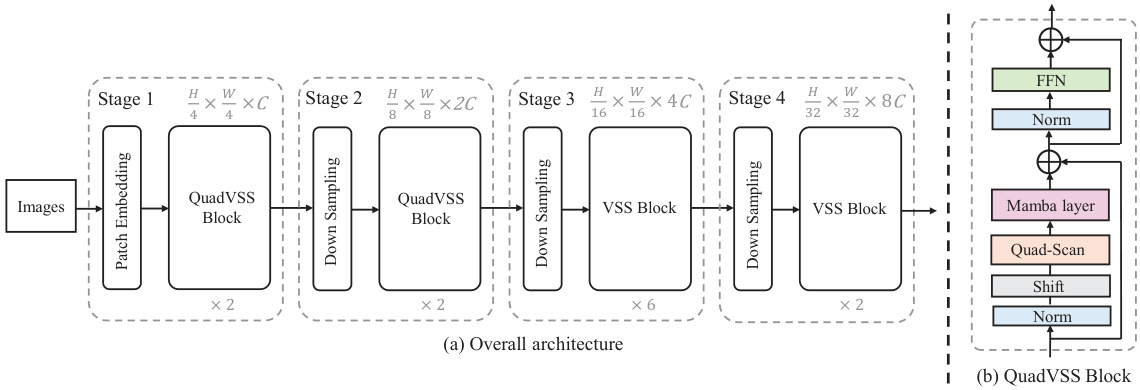
🔼 This figure illustrates the overall architecture of QuadMamba and a detailed breakdown of its core building block, the QuadVSS block. QuadMamba follows a hierarchical structure similar to vision transformers, with multiple stages each containing several QuadVSS blocks. Each stage progressively reduces the spatial resolution while increasing the channel dimension of the feature maps. The QuadVSS block incorporates a learnable quadtree-based scanning mechanism for efficient feature extraction and modeling of local dependencies.
read the caption
Figure 2: The pipeline of the proposed QuadMamba (a) and its building block: QuadVSS block (b). Similar to the hierarchical vision Transformer, QuadMamba builds stages with multiple blocks, making it flexible to serve as the backbone for vision tasks.
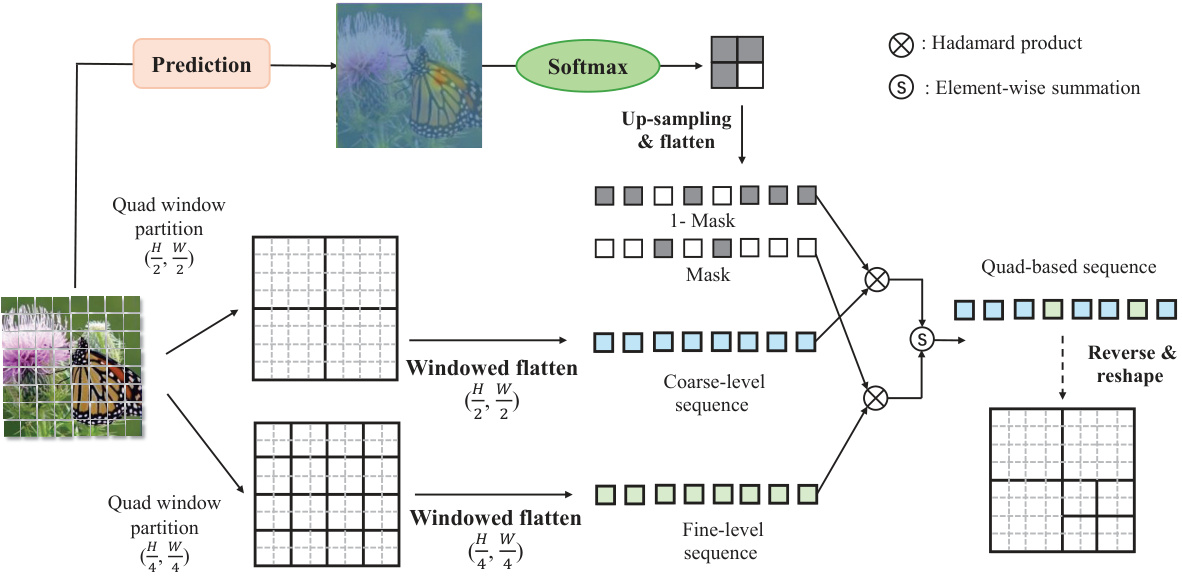
🔼 This figure illustrates the Quadtree-based selective scan method used in QuadMamba. It shows how image tokens are divided into quadrants, initially at a coarse level (larger quadrants) and then recursively at a finer level (smaller quadrants) based on a learned prediction of their importance. A differentiable mask is created to select tokens from these quadrants, and these selected tokens are then flattened into a 1D sequence to be processed by the state space model. This approach allows for capturing both local (within quadrants) and global (across quadrants) dependencies efficiently and in a differentiable manner.
read the caption
Figure 3: Quadtree-based selective scan with prediction modules. Image tokens are partitioned into bi-level window quadrants from coarse to fine. A fully differentiable partition mask is then applied to generate the 1D sequence with negligible computational overhead.
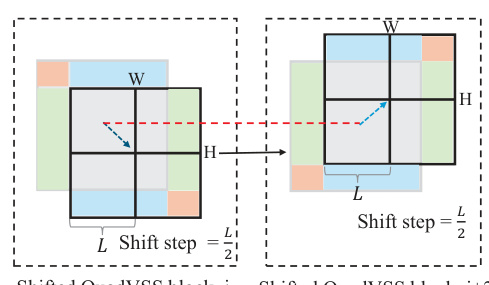
🔼 This figure illustrates the omnidirectional window shifting scheme used in QuadMamba. The scheme addresses the issue of informative tokens spanning across adjacent window quadrants. By shifting the window in two directions (horizontal and vertical), the model can capture more complete and informative features across different local regions, improving the flexibility and accuracy of the quadtree-based partitioning.
read the caption
Figure 4: Omnidirectional window shifting scheme.

🔼 This figure visualizes the partition maps generated by the QuadMamba model across different layers (from shallow to deep). It demonstrates how the model focuses on different regions of the input image at various levels of the network. This adaptive focus on different regions is a key aspect of QuadMamba’s ability to capture both local and global context in images.
read the caption
Figure 6: Visualization of partition maps that focus on different regions from shallow to deep blocks.

🔼 The figure shows the overall architecture of QuadMamba and a detailed illustration of its building block, the QuadVSS block. QuadMamba’s architecture is hierarchical, similar to vision transformers, consisting of multiple stages with QuadVSS blocks. Each stage reduces spatial size and increases channel dimensions. The QuadVSS block is composed of several components: a token operator, a feed-forward network (FFN), and two residual connections. The token operator includes a learnable quadtree-based scan to capture local dependencies at different granularities and a Mamba layer for sequence modeling.
read the caption
Figure 2: The pipeline of the proposed QuadMamba (a) and its building block: QuadVSS block (b). Similar to the hierarchical vision Transformer, QuadMamba builds stages with multiple blocks, making it flexible to serve as the backbone for vision tasks.

🔼 The figure illustrates the omnidirectional window shifting scheme used in QuadMamba. It shows how the model handles informative tokens that might cross the boundaries of adjacent quadrants during the quadtree-based partitioning. By shifting the windows in two directions, the model ensures that it captures more intact and informative features, improving the flexibility and accuracy of the model’s understanding of local contexts within the image.
read the caption
Figure 4: Omnidirectional window shifting scheme.
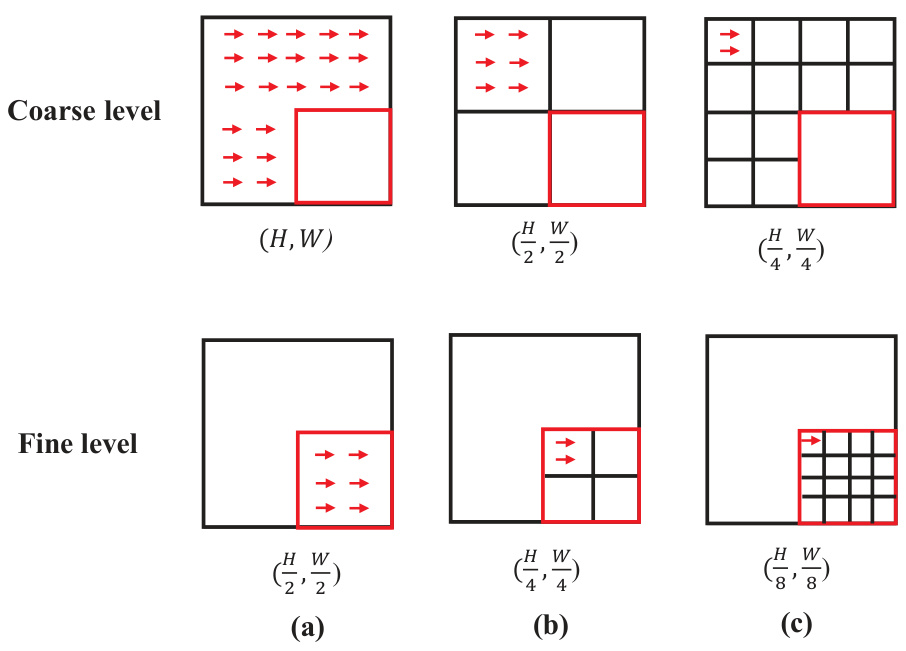
🔼 This figure illustrates the different window partition resolution configurations used in the QuadMamba model. It shows three scenarios at both coarse and fine levels. In each scenario, the image is partitioned into quadrants (or windows) of varying sizes to capture local dependencies at different granularities. The sizes of the quadrants are shown in the figure, with (H, W) representing the original image height and width. The red arrows represent the scanning direction for each level.
read the caption
Figure 9: Details of the three different local window partition resolution configurations.

🔼 This figure visualizes how the quadtree-based partition strategy focuses on different image regions at various depths (layers) of the QuadMamba model. The first column displays example images. Each row shows the evolution of partition maps (black representing masked-out regions, white/beige representing the selected regions) across eight layers. The second column displays the initial partition score maps in the first layer, guiding the partitioning process. This illustrates the model’s ability to progressively refine attention to increasingly fine-grained relevant portions of the image as the network gets deeper.
read the caption
Figure 10: Visualization of partition maps that focus on different regions from shallow to deep blocks. The second column shows the partition score maps in the 1st block.

🔼 This figure illustrates different strategies for converting 2D image data into 1D sequences for processing by a State Space Model. (a) shows a naive flattening approach that ignores spatial relationships. (b) uses fixed-size windows, limiting adaptability to varying image granularity. (c) presents the authors’ proposed method, which uses a learnable quadtree to partition the image and adaptively select informative regions. (d) compares the receptive fields of the authors’ model (QuadMamba) and a standard vision Mamba model, highlighting the improved locality preservation in QuadMamba.
read the caption
Figure 1: Illustration of scan strategies for transforming 2D visual data into 1D sequences. (a) naive raster scan [80, 41, 66] ignores the 2D locality; (b) fixed window scan [26] lacks the flexibility to handle visual signals of varying granularities; (c) our learnable window partition and scan strategy adaptively preserves the 2D locality with a focus on the more informative window quadrant; (d) the effective receptive field of our QuadMamba demonstrates more locality than the plain Vision Mamba.
More on tables
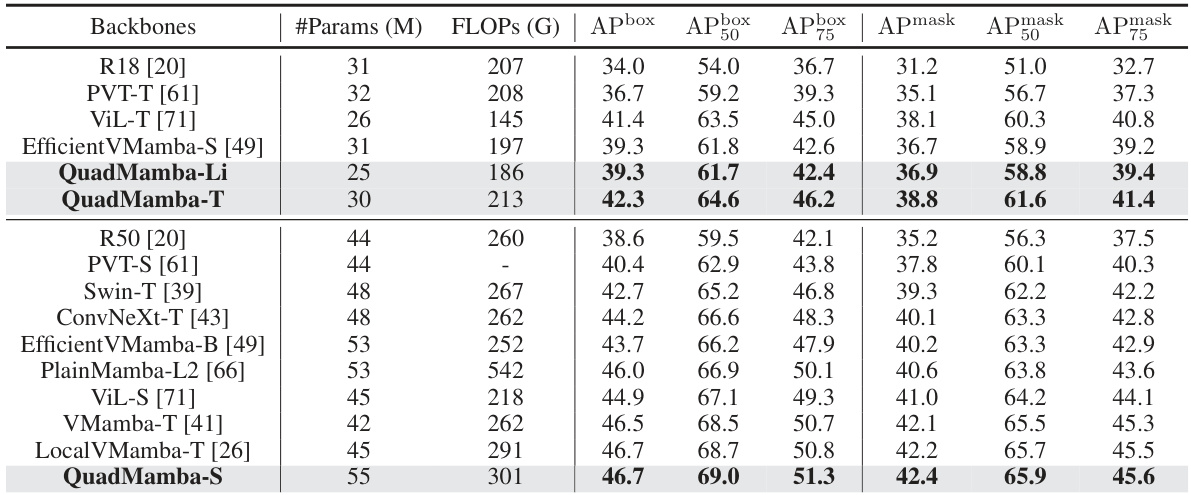
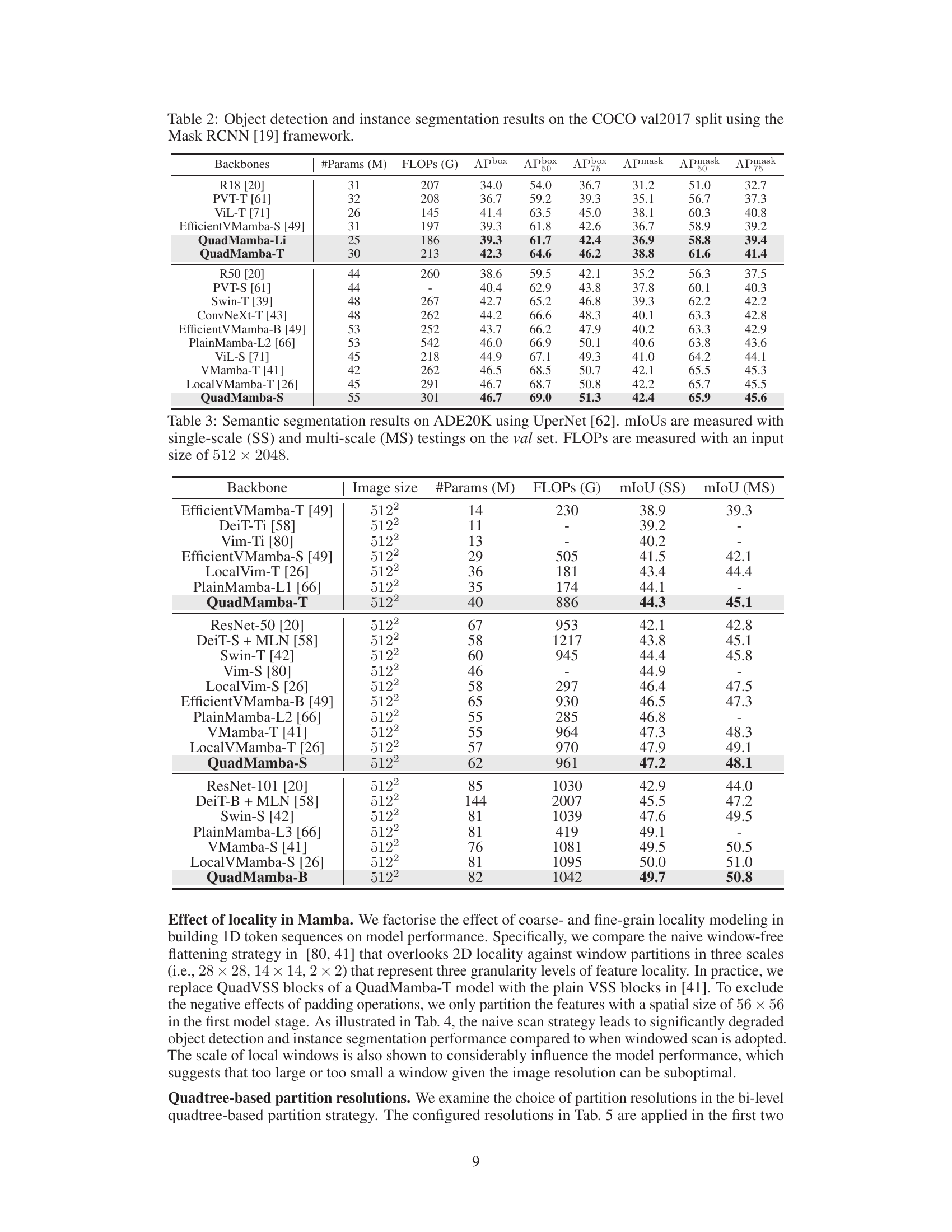
🔼 This table presents the performance comparison of various vision backbones on object detection and instance segmentation tasks using the COCO val2017 dataset and the Mask RCNN framework. Metrics include APbox (average precision for bounding boxes) and Apmask (average precision for masks) at different IoU thresholds (50 and 75). The table highlights the performance of QuadMamba models compared to other state-of-the-art methods.
read the caption
Table 2: Object detection and instance segmentation results on the COCO val2017 split using the Mask RCNN [19] framework.
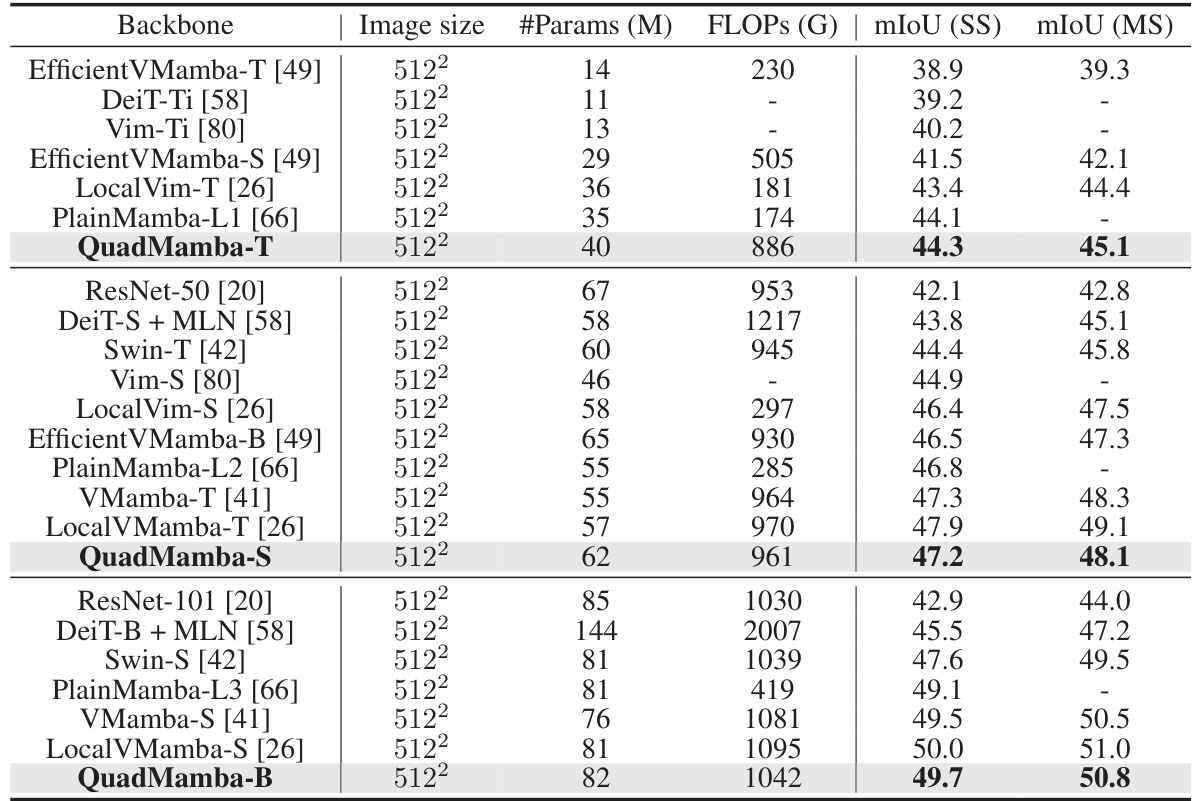
🔼 This table presents the results of semantic segmentation experiments on the ADE20K dataset using the UperNet model. It compares the performance of QuadMamba against various other backbones, including ResNet, DeiT, Swin Transformer, EfficientVMamba, LocalViM, and PlainMamba. The metrics used are mean Intersection over Union (mIoU) for both single-scale (SS) and multi-scale (MS) testing. FLOPs (floating point operations) and model parameters are also reported, providing insight into computational efficiency.
read the caption
Table 3: Semantic segmentation results on ADE20K using UperNet [62]. mIoUs are measured with single-scale (SS) and multi-scale (MS) testings on the val set. FLOPs are measured with an input size of 512 × 2048.
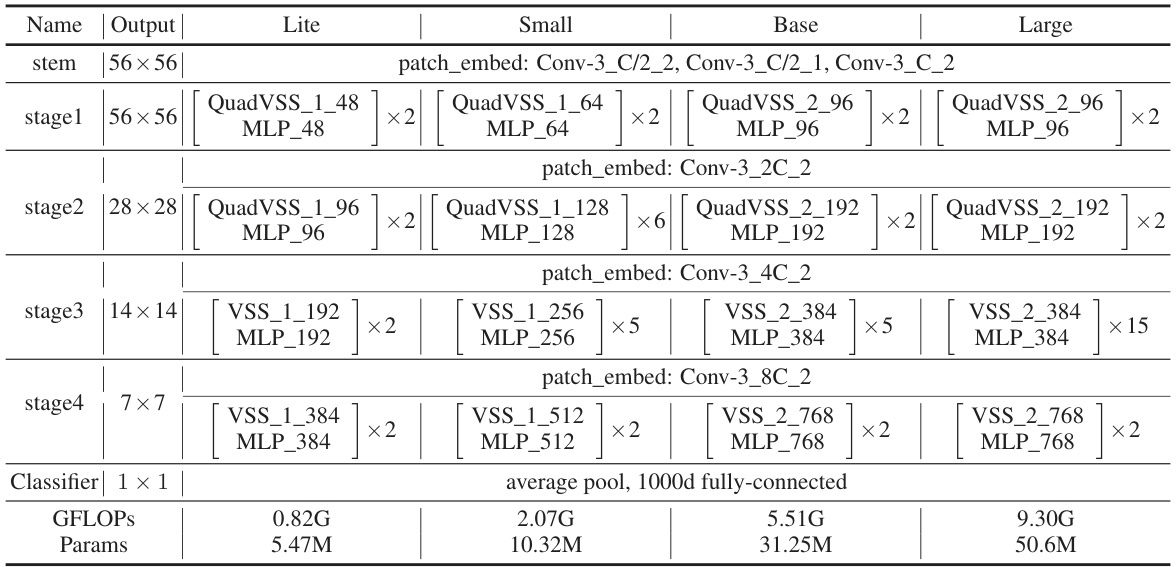
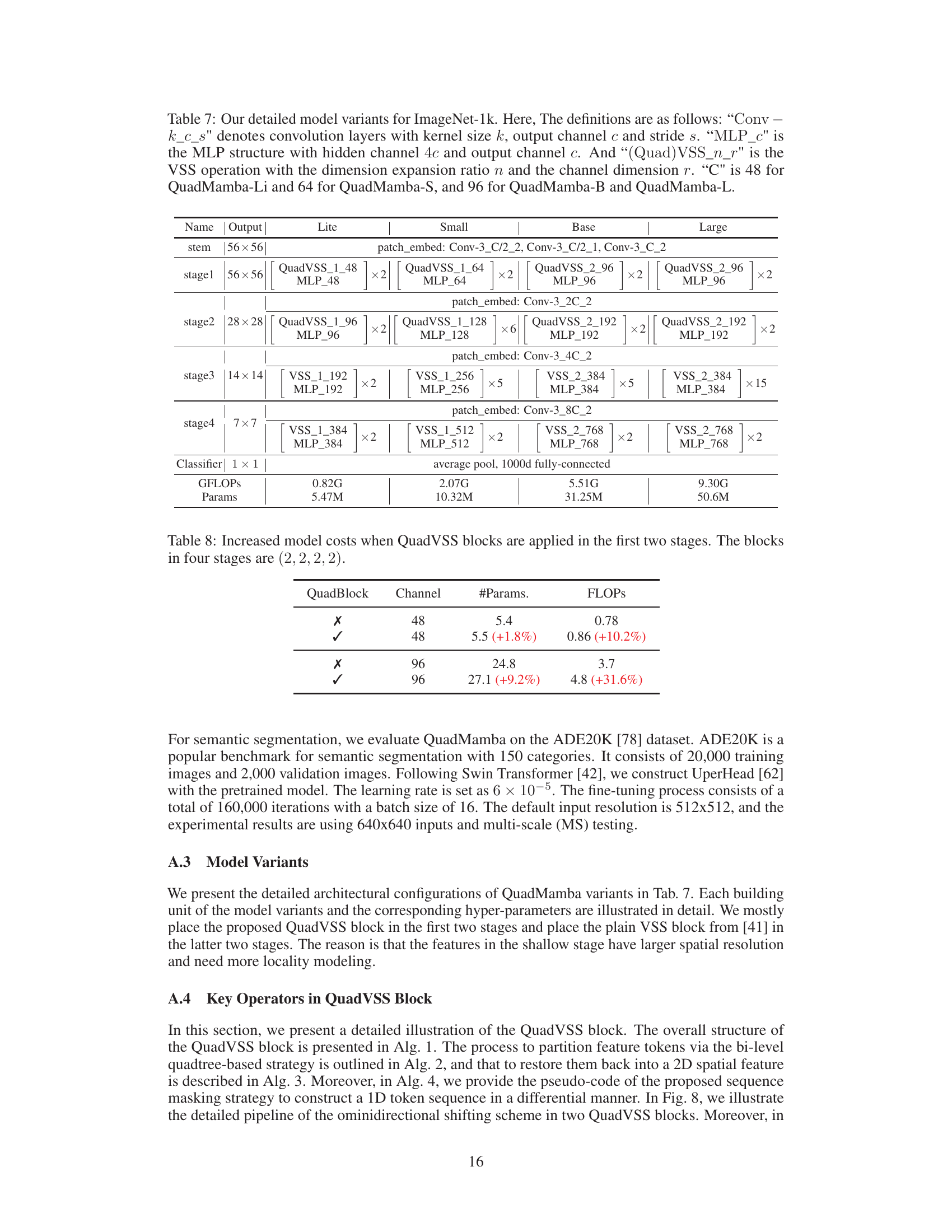
🔼 This table details the model variations used for ImageNet-1k experiments in the paper. It provides a breakdown of the architecture for four different QuadMamba variants: Lite, Small, Base, and Large. The table shows the structure (convolution layers, QuadVSS/VSS blocks, MLP layers), the number of times each block is repeated (x2, x5, x6, x15), and the channel dimension used at each stage. Finally, it summarizes the GFLOPs and number of parameters for each model variant.
read the caption
Table 7: Our detailed model variants for ImageNet-1k. Here, The definitions are as follows: 'Conv-k_c_s' denotes convolution layers with kernel size k, output channel c and stride s. “MLP_c' is the MLP structure with hidden channel 4c and output channel c. And ')(Quad)VSS_n_r' is the VSS operation with the dimension expansion ratio n and the channel dimension r. 'C' is 48 for QuadMamba-Li and 64 for QuadMamba-S, and 96 for QuadMamba-B and QuadMamba-L.
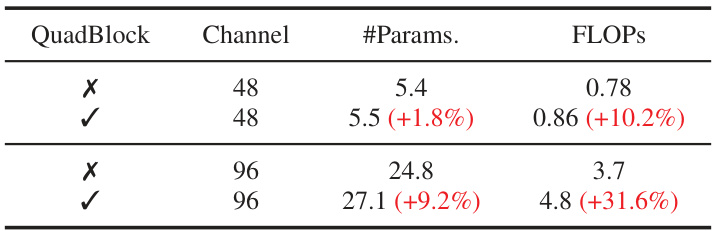
🔼 This table shows the increase in model parameters and FLOPs when QuadVSS blocks are added to the first two stages of the model. It demonstrates the computational overhead introduced by the Quadtree-based Visual State Space blocks. The baseline configuration uses (2,2,2,2) blocks across the four stages. The table highlights the tradeoff between added complexity and potential performance gains from applying the QuadVSS blocks in earlier stages.
read the caption
Table 8: Increased model costs when QuadVSS blocks are applied in the first two stages. The blocks in four stages are (2, 2, 2, 2).

🔼 This table presents the throughput (images/s) of four different variants of the QuadMamba model (Lite, Tiny, Small, Base) measured using an A800 GPU. Each variant has a different number of parameters and FLOPs (floating point operations), resulting in varying levels of computational efficiency and speed.
read the caption
Table 9: Throughputs of QuadMamba variants. Measurements are taken with an A800 GPU.
Full paper#