↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Air drawing, creating sketches using hand gestures, is gaining popularity but existing AR/VR tools are expensive and require significant skills. This necessitates developing more accessible and user-friendly methods. This research addresses these issues by proposing a new framework.
The proposed method uses a self-supervised training method with an image diffusion model to translate noisy hand-tracking data into refined sketches. This process uses augmentations to simulate real-world noise in hand-tracking. The results show that this approach produces aesthetically pleasing sketches comparable to traditional methods, showcasing its potential to revolutionize air drawing.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces AirSketch, a novel approach to generating sketches from hand motions using a controllable image diffusion model. This addresses limitations of existing AR/VR drawing tools by eliminating the need for expensive hardware and specialized skills. The research opens up new avenues for marker-less air drawing and has implications for AR/VR applications. The proposed self-supervised training procedure and the use of controllable diffusion models offer valuable insights for researchers in image generation, computer vision, and human-computer interaction.
Visual Insights#
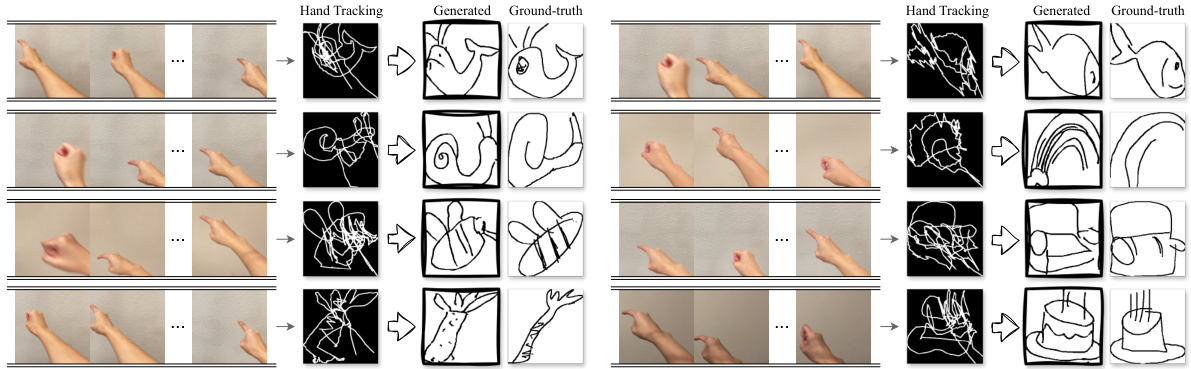
This figure shows the process of generating a clean sketch from a hand-drawn video. The left column shows the hand drawing video. The middle column shows the noisy tracking image extracted from the video using a hand detection algorithm. The right column displays the generated clean sketch, compared with the ground truth sketch. This demonstrates the ability of the model to translate from a noisy input to a clean and aesthetically pleasing output.

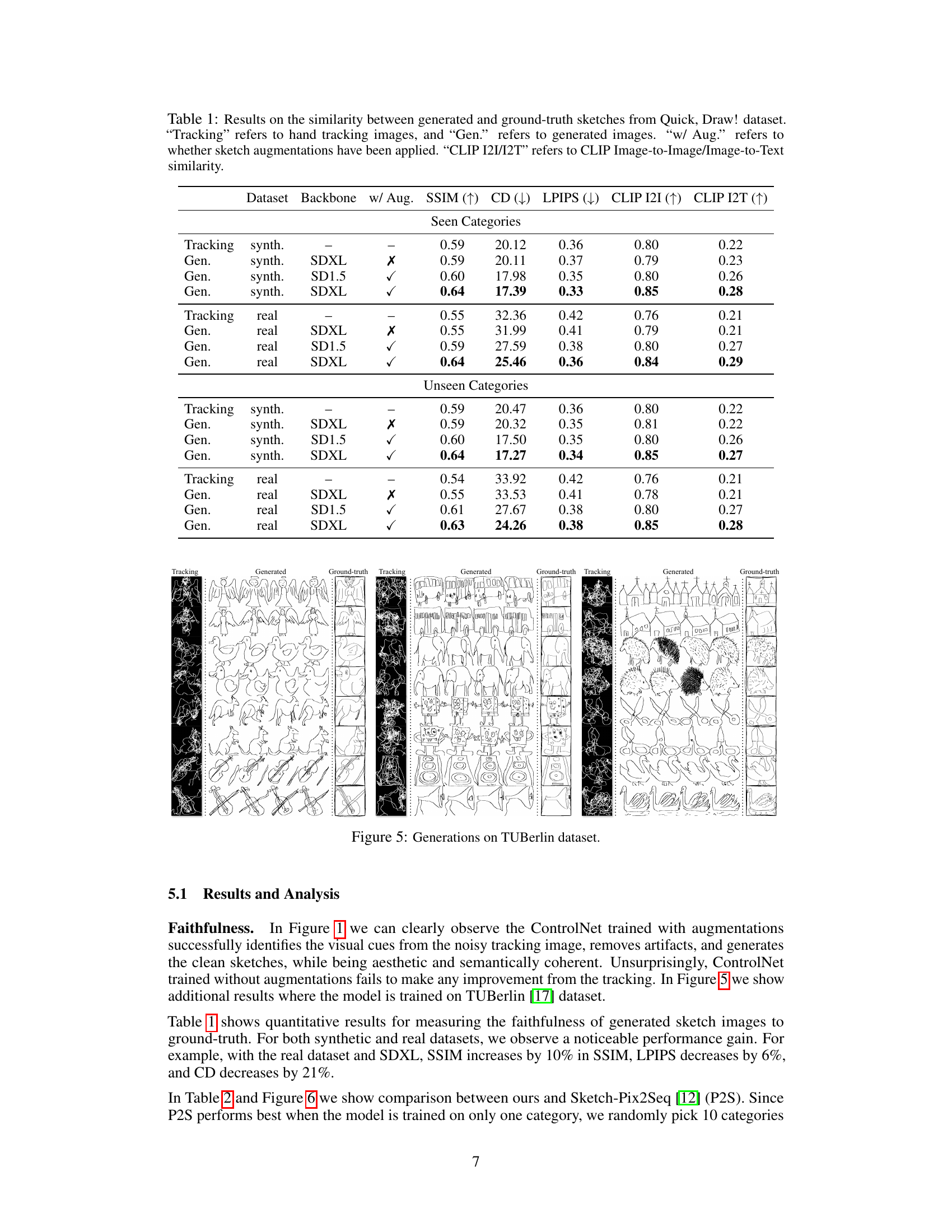
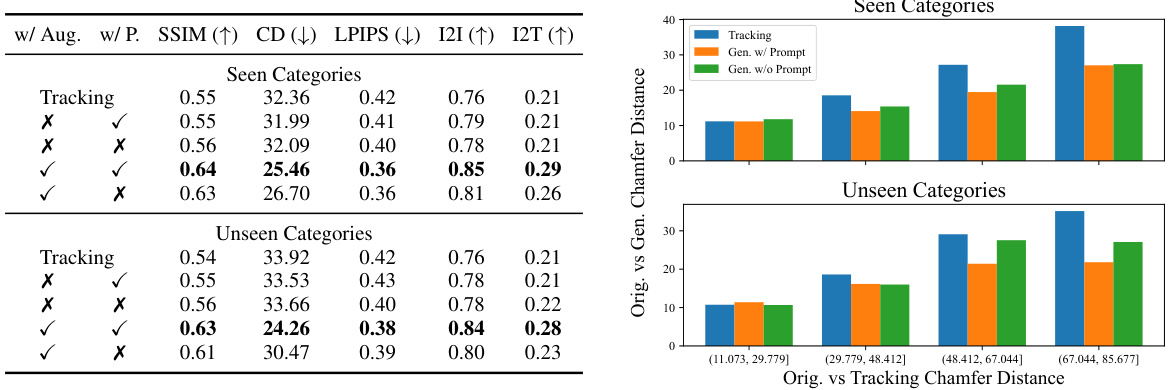
This table presents a quantitative comparison of the similarity between generated sketches and ground truth sketches from the Quick, Draw! dataset. It compares results using different backbones (SDXL, SD1.5), with and without augmentations, and across seen and unseen categories. The metrics used are SSIM, CD, LPIPS, CLIP I2I, and CLIP I2T to assess different aspects of similarity.
In-depth insights#
AirSketch: Motion to Sketch#
AirSketch: Motion to Sketch presents a novel approach to generating sketches directly from hand motions, eliminating the need for specialized hardware. The core idea leverages controllable image diffusion models trained using a self-supervised augmentation-based method to translate noisy hand-tracking data into clean, aesthetically pleasing sketches. This technique addresses limitations of existing air drawing systems that rely on costly hardware and considerable user skill. Two datasets were developed for this research: a synthetic dataset generated using 3D human arm animation and a real-world dataset recorded from human users. The results show promising sketch generation from noisy hand-tracking data, improving faithfulness and aesthetic quality. Further research could investigate scalability and robustness of the models across various drawing styles and user skills. The technique also opens possibilities for marker-less air drawing in augmented and virtual reality applications.
Controllable Diffusion#
Controllable diffusion models represent a significant advancement in generative modeling. They offer a powerful approach to generating high-quality images while allowing for fine-grained control over the generation process. Unlike traditional diffusion models that primarily rely on text prompts for guidance, controllable diffusion allows for additional forms of control, such as incorporating sketches, edge maps, or depth information. This expanded controllability opens up exciting possibilities in various applications. For example, in image editing, controllable diffusion can facilitate tasks like inpainting, outpainting, and style transfer with higher precision and fidelity. The integration of control mechanisms with diffusion models is still an active area of research, and further advancements will likely improve the quality, realism, and diversity of generated images. One key challenge involves effectively combining multiple control signals without compromising the model’s ability to generate coherent and meaningful outputs. Addressing this challenge will unlock further opportunities and push the boundaries of what’s possible with generative AI.
Augmentation Training#
The effectiveness of the proposed AirSketch model hinges significantly on its augmentation training strategy. Instead of relying on large, meticulously labeled datasets, which are expensive and time-consuming to create for this task, the authors employ a self-supervised approach. They introduce random augmentations to the ground-truth sketches, simulating the noisy data produced by real-world hand-tracking algorithms. These augmentations, categorized as local, structural, and false strokes, mimic common errors in air drawing, such as jitters, distortions, and misplaced lines. By training the model to reconstruct the original, clean sketches from these augmented versions, AirSketch learns to filter out noise and produce aesthetically pleasing outputs. This clever self-supervised strategy is a key strength of the paper, addressing the scarcity of high-quality, paired hand-motion and sketch datasets and making the model more robust and generalizable to unseen scenarios. The authors’ careful analysis of the impact of different augmentation types further strengthens the methodology, demonstrating a thoughtful approach to this crucial aspect of model training.
Dataset Creation#
The creation of a robust and relevant dataset is paramount for training effective AI models, particularly in the nuanced field of sketch generation from hand motions. A thoughtfully constructed dataset should consider several key factors. Diversity is crucial; the dataset must encompass a broad range of sketches, styles, and complexities to ensure generalizability. This involves selecting diverse subjects, motion styles, and incorporating various levels of noise and artifacts which are inherent in real-world hand-drawn sketches. Data augmentation is also key to improving dataset size and model robustness, artificially enhancing existing data through various transformations such as adding noise, altering strokes, and simulating drawing errors, to aid in model training and improve resilience to real-world variations. Data annotation should be meticulous, accurately labeling both sketch images and the corresponding hand-motion videos, and may include additional metadata. A well-defined annotation process ensures the model’s ability to correctly interpret and generate desired sketch results. Finally, considerations regarding dataset size should factor into the planning, balancing the need for ample data for thorough training with the practical constraints of data acquisition and processing. A sufficiently sized dataset is vital for training a powerful and effective model, while also ensuring the data can be effectively managed and utilized.
Future of AirSketch#
The future of AirSketch hinges on several key advancements. Improving hand tracking robustness is crucial; current methods struggle with noisy data, impacting sketch accuracy. Addressing this could involve incorporating more sophisticated algorithms or sensor fusion techniques. Enhanced model controllability is also vital, allowing users greater precision and stylistic freedom. Exploring different diffusion model architectures or incorporating user feedback mechanisms could achieve this. Expanding artistic capabilities is another area ripe for development, potentially enabling the creation of more complex sketches with varied textures and colors. This could involve integrating advanced rendering techniques or incorporating AI-driven artistic styles. Dataset expansion is needed for enhanced model generalizability and better performance across diverse drawing styles and objects. Finally, exploring real-world applications beyond AR/VR, such as digital art creation, assistive technologies, or educational tools, could greatly broaden AirSketch’s impact. Addressing potential ethical concerns regarding misuse or biases present in generated sketches will be essential for responsible development and deployment. Overall, AirSketch’s future lies in a harmonious blend of technological progress and responsible innovation.
More visual insights#
More on figures
This figure shows two examples of air drawing videos. The left side displays a synthetic hand drawing video, which is computer-generated. The right side displays a real hand drawing video captured with a camera. The images are included to help illustrate the difference between the synthetic dataset (used for training) and the real-world dataset (used for evaluation). The videos showcase the hand movements that are used as input for generating sketches in the AirSketch model.

This figure illustrates the training and inference pipeline of the AirSketch model. During training, the model learns to reconstruct clean sketches from noisy, augmented versions of sketches. During inference, a hand-tracking algorithm processes a video of hand movements to create a noisy input sketch, which is then fed into the trained model to generate a clean output sketch. The process utilizes ControlNet, a controllable diffusion model, along with text prompts and augmentation techniques to achieve faithful and aesthetic sketch generation.

This figure shows examples of different types of augmentations applied to a sketch of an angel. The augmentations are categorized into three groups: local, structural, and false strokes. Local augmentations include jitters, stroke-wise distortions, and random spikes. Structural augmentations include sketch-level distortions, incorrect stroke sizes, and misplacements. False strokes include transitional strokes and random false strokes. Each augmentation aims to simulate different types of errors that might occur during air drawing, such as hand jitters, tracking errors, and user-induced artifacts. These augmentations are used during training to make the model robust to noisy and distorted hand tracking data.

This figure shows examples of sketches generated by the model on the TUBerlin dataset. It visually demonstrates the model’s ability to generate clean and aesthetically pleasing sketches from noisy hand-tracking data. The figure compares the hand-tracking input, the generated sketch, and the ground truth sketch for several different examples. This allows for a visual assessment of the model’s faithfulness and aesthetic quality.

This figure shows several examples of sketches generated by the model trained on the TUBerlin dataset. Each row displays the noisy hand tracking image (left), the generated sketch (middle), and the ground truth sketch (right). The figure visually demonstrates the model’s ability to generate clean and aesthetically pleasing sketches from noisy input.

This figure compares the visualization of ControlNet’s hidden states during the denoising process. The top row shows the baseline approach without augmentations, while the bottom row shows the results with augmentations. It illustrates how the augmentations help the model converge towards a clean sketch representation more effectively.

This figure shows the impact of using text prompts in sketch generation. The leftmost column displays the noisy hand-tracking input. The middle columns show sketch generations: one using a text prompt (w/ Prompt) and one without (w/o Prompt). The rightmost column shows the ground truth sketch. The results demonstrate that providing text prompts is crucial for the model to generate correct sketches for unseen categories, where the noisy hand-tracking input provides limited visual information. Without prompts, the model may produce plausible, but incorrect, sketches of seen categories.

This figure shows the effect of different combinations of augmentations (local, structural, and false strokes) on the quality of generated sketches. Each row represents a different input hand-tracking image, and each column shows the sketch generated with a different combination of augmentations applied during training. The ground truth sketch is shown in the last column for comparison. The results demonstrate the importance of different augmentation types in recovering the quality of the generated sketches.
This figure shows the process of generating clean sketches from hand-drawn videos. It starts with a hand-drawn video, from which hand tracking is performed to extract a noisy tracking image. This image is then fed into an image generation model to produce a refined and aesthetically pleasing sketch that closely resembles the original intended sketch.

This figure compares the performance of three different hand landmarking algorithms: MediaPipe, OpenPose, and NSRM. It shows that MediaPipe generally provides the most accurate hand landmark detection, while OpenPose frequently struggles to detect the hand entirely, and NSRM’s accuracy is significantly lower. The images show several frames from hand tracking videos, highlighting the differences in accuracy of the three algorithms.
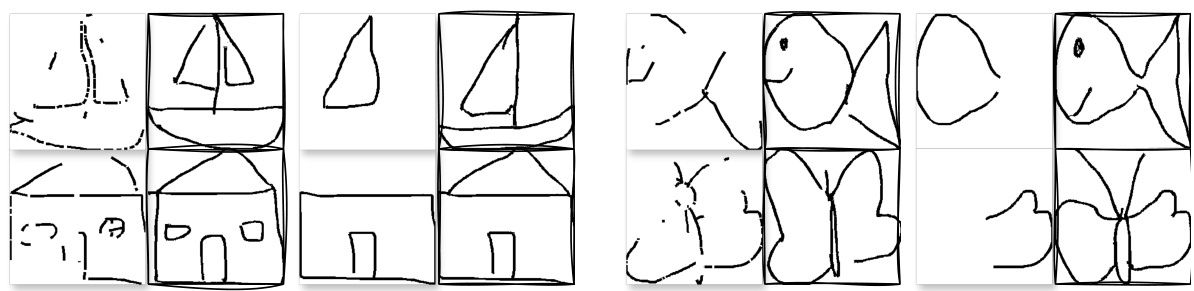
This figure shows the process of generating sketches from hand-drawn videos. The first step involves using a hand detection algorithm to extract the tracking image from the video. This tracking image is then fed into a model that generates a clean sketch. The generated sketch is compared to the ground truth sketch to evaluate the model’s performance. The figure showcases the effectiveness of the model by illustrating how it transforms the noisy tracking image into a clean and aesthetically pleasing sketch that closely resembles the intended sketch.

This figure shows the process of generating sketches from hand-drawn videos. The left side displays a hand-drawn video’s hand tracking image which is quite noisy. The right side shows the generated, cleaned-up sketch that closely resembles the original, intended sketch.

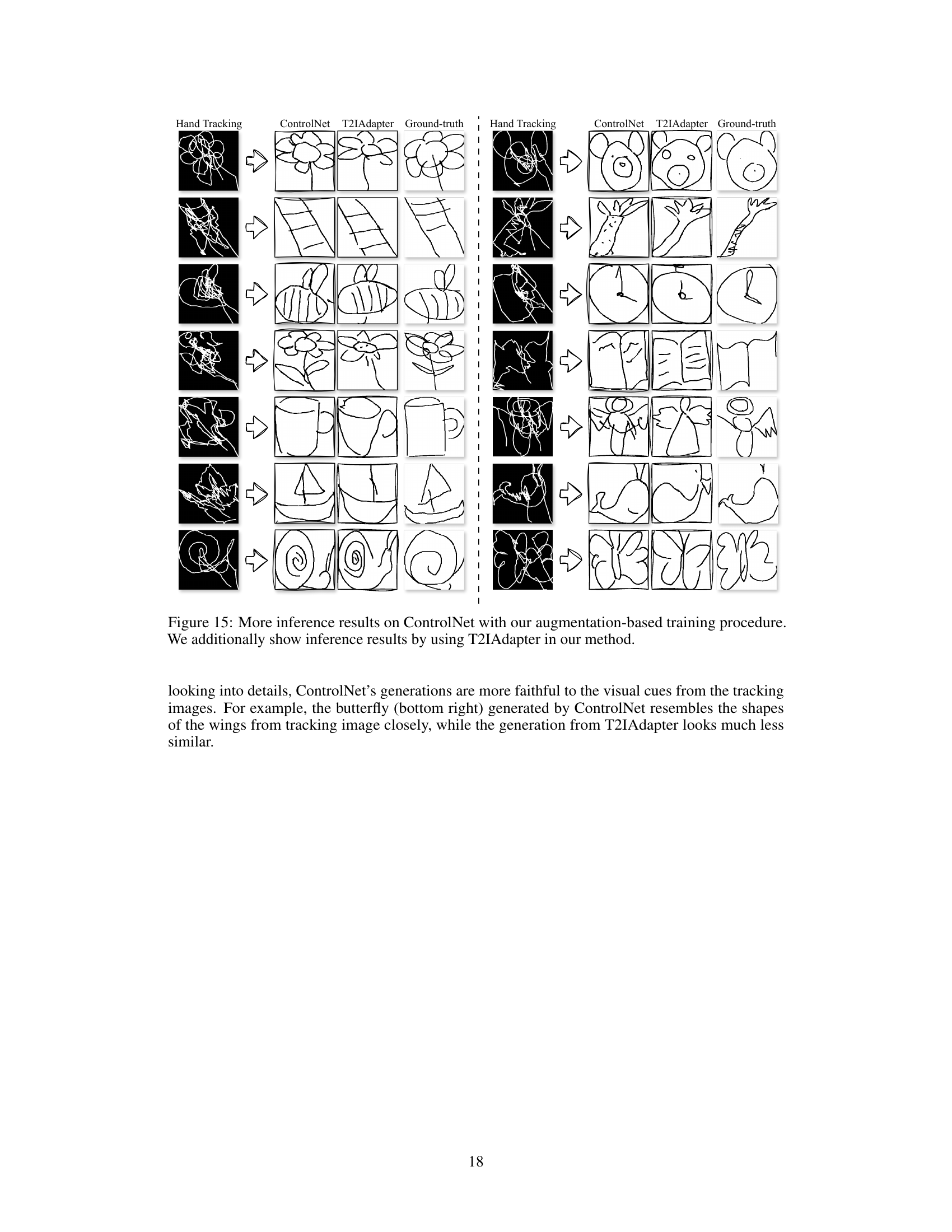
This figure compares the sketch generation results of ControlNet and T2IAdapter, both trained with the proposed augmentation-based method. The left and right columns show results from two different subsets of test images. Each row presents a hand tracking image as input (noisy and distorted), followed by the output of ControlNet, T2IAdapter, and the ground-truth sketch. The comparison highlights the differences in the ability of the two models to reconstruct clean and faithful sketches from noisy hand tracking data. ControlNet generally produces sketches that more closely resemble the ground truth, indicating that it may be better at interpreting visual cues from noisy input data.
Full paper#