↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Video Instance Segmentation (VIS) is a challenging computer vision task aiming to simultaneously detect, segment, and track objects in videos. Existing DETR-based VIS methods often employ asynchronous designs, either using only video-level queries or query-sensitive cascade structures, resulting in suboptimal performance, particularly in complex scenarios. These asynchronous designs hinder the effective modeling of intricate spatial-temporal relationships in videos.
SyncVIS addresses these issues by introducing a novel synchronized framework. It employs both video-level and frame-level query embeddings and incorporates two key modules: a synchronized video-frame modeling paradigm that promotes mutual learning between frame-level and video-level embeddings and a synchronized embedding optimization strategy that tackles the optimization complexity of long videos by dividing them into smaller clips. Extensive experiments on YouTube-VIS and OVIS benchmarks demonstrate that SyncVIS achieves state-of-the-art results, highlighting its effectiveness and generality.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video instance segmentation because it introduces SyncVIS, a novel framework that significantly improves accuracy and efficiency, especially in complex scenarios. Its synchronous modeling paradigm and optimization strategy offer new avenues for research and development in this active field, addressing existing limitations of asynchronous approaches. The results on challenging benchmarks are compelling and showcase the potential of the proposed method.
Visual Insights#
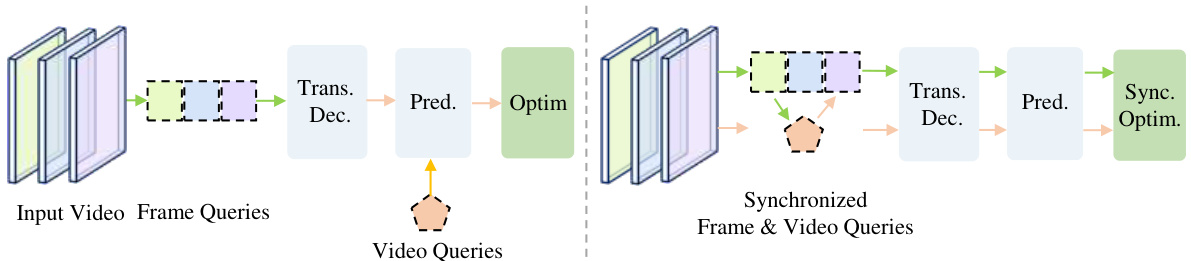
This figure compares the asynchronous and synchronous approaches of video instance segmentation. The left side shows the traditional approach, where frame-level queries are processed independently before being integrated with video-level queries which may result in a loss of information and increased complexity. The right side illustrates the SyncVIS approach where frame and video-level queries are processed synchronously. The synchronized processing allows for mutual learning and refinement, resulting in a more robust and effective model.

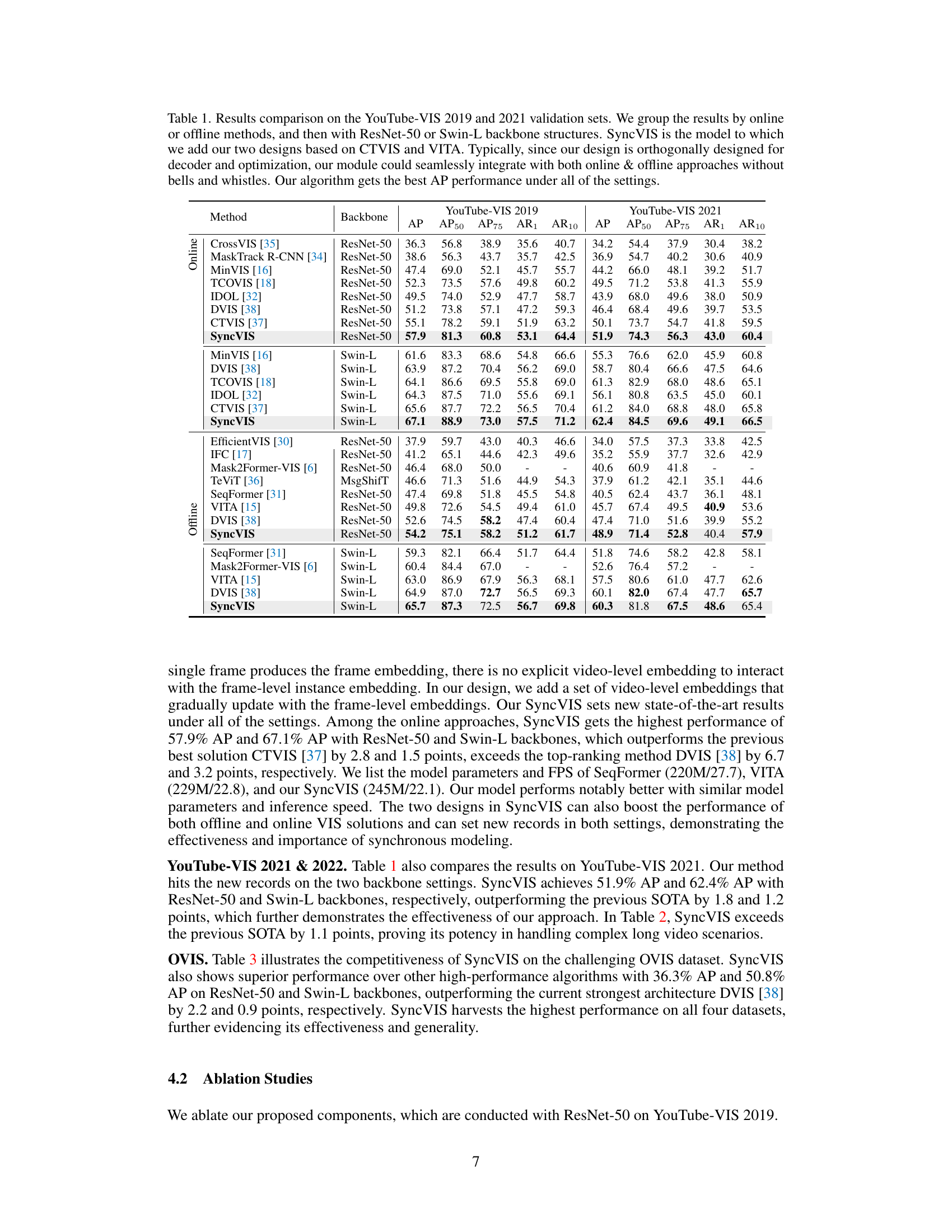
This table compares the performance of SyncVIS with other state-of-the-art video instance segmentation methods on the YouTube-VIS 2019 and 2021 datasets. It shows the Average Precision (AP) and other metrics for different models using ResNet-50 and Swin-L backbones, categorizing results by online and offline approaches. The table highlights SyncVIS’s superior performance and the effectiveness of its design in integrating seamlessly with various existing methods.
In-depth insights#
SyncVIS Framework#
The SyncVIS framework presents a novel approach to video instance segmentation, addressing limitations of existing asynchronous methods. Its core innovation lies in synchronized video-frame modeling, enabling direct interaction between video-level and frame-level embeddings within a transformer decoder. This contrasts with previous methods that often decouple these levels, leading to information loss and suboptimal performance, especially in complex scenarios. A further key component is the synchronized embedding optimization strategy, which divides long videos into smaller clips to manage the computational complexity of bipartite matching. This technique not only improves efficiency but also enhances the ability to model instance trajectories accurately across longer sequences. By unifying frame and video-level predictions synchronously, SyncVIS effectively leverages both spatial and temporal information to achieve state-of-the-art results. The framework’s modular design allows for easy integration with existing approaches, and its effectiveness is validated on multiple challenging benchmarks.
Synchronized Modeling#
The concept of “Synchronized Modeling” in video instance segmentation is a crucial advancement addressing the limitations of asynchronous approaches. Asynchronous methods often model video sequences using either video-level queries alone or query-sensitive cascade structures, leading to suboptimal performance in complex scenarios. Synchronized modeling, in contrast, aims for simultaneous processing of frame-level and video-level information. This is achieved through mechanisms that explicitly facilitate interaction and mutual learning between frame-level and video-level representations. Key to this synchronization is the ability to unify frame-level and video-level predictions, allowing the model to leverage both the detailed appearance information from individual frames and the comprehensive temporal context from the entire video sequence. This results in a more robust and effective representation of object instances and their trajectories, which is particularly beneficial in handling challenges such as occlusions, complex motions, and long-range dependencies. Furthermore, the optimization strategy should also be synchronized, to ensure that the model fully exploits the unified representations for efficient training and improved accuracy. The synchronized nature of this approach leads to significant improvements in accuracy and generalization compared to traditional, asynchronous techniques.
Optimization Strategy#
The optimization strategy is crucial in video instance segmentation for efficient and accurate results. The paper highlights the limitations of existing asynchronous methods, proposing a novel synchronized approach. This involves dividing the input video into smaller clips, allowing for easier optimization without compromising temporal information. This approach directly addresses the exponential complexity increase associated with processing longer video sequences. The synchronized optimization strategy, therefore, is key to scaling video instance segmentation to more complex and longer videos while maintaining high performance. Furthermore, it demonstrates the effectiveness of a divide-and-conquer strategy, significantly improving training efficiency and mitigating the memory challenges inherent in handling long video sequences. By focusing on smaller, manageable segments, the algorithm achieves a better balance between accuracy and computational efficiency. This optimization strategy is not only computationally advantageous but also enhances the model’s robustness to variations in video length and complexity.
VIS Benchmark Results#
A comprehensive analysis of the ‘VIS Benchmark Results’ section in a research paper would involve a deep dive into the metrics used, the datasets considered, and the comparison with state-of-the-art methods. Key metrics such as average precision (AP), average recall (AR), and the specific AP thresholds (e.g., AP50, AP75) should be examined for their relevance to the task and the insights they offer. The choice of datasets is crucial; understanding the characteristics of each dataset (e.g., video length, number of objects, presence of occlusions) is essential to interpreting the results. Comparison with existing methods should not only report the numerical improvements, but also a qualitative assessment of the strengths and limitations of the proposed approach in different contexts. A strong analysis should uncover not just superior performance but also address the generalizability of the method across diverse datasets and scenarios, perhaps via ablation studies or error analysis. Finally, limitations of the reported results, such as dataset biases or evaluation metrics limitations, must be acknowledged for a complete and nuanced understanding.
Future VIS Research#
Future research in Video Instance Segmentation (VIS) should prioritize addressing the limitations of current methods, specifically focusing on robustness in challenging scenarios such as heavy occlusions, complex motion, and significant variations in object appearance. Improving the efficiency and scalability of VIS models is crucial, particularly for real-time applications. This may involve exploring more efficient architectures, novel optimization techniques, or leveraging advances in hardware acceleration. Greater emphasis on generalization and transfer learning is needed to reduce the reliance on large, manually annotated datasets, potentially through synthetic data generation or self-supervised learning techniques. Research into handling long-range dependencies across many frames in video sequences is also critical, potentially via incorporating more advanced temporal modeling or memory mechanisms. Finally, investigating new evaluation metrics that better reflect real-world performance, and exploring applications of VIS in novel domains, are necessary steps for the field’s continued advancement.
More visual insights#
More on figures

The figure illustrates the SyncVIS framework, emphasizing its two key components: synchronized video-frame modeling and synchronized embedding optimization. The synchronized video-frame modeling uses a transformer decoder to integrate video-level and frame-level embeddings, enhancing interaction and mutual learning. The synchronized embedding optimization divides the video into smaller clips, simplifying the optimization process and improving performance. The overall effect is a more robust and effective approach to video instance segmentation.

This figure shows the performance of Mask2Former-VIS and SyncVIS models on YouTube-VIS 2019 validation set with varying numbers of input frames. The x-axis represents the number of input frames (T), while the y-axis represents the average precision (AP) in percentage. The plot demonstrates that Mask2Former-VIS performance degrades as the number of input frames increases, while SyncVIS shows improved and more stable performance, indicating its better ability to handle the complexity of long-range video sequences.

This figure compares the performance of SyncVIS against Mask2Former-VIS and VITA on challenging video instance segmentation tasks. It showcases SyncVIS’s ability to accurately segment objects even in videos with long sequences, similar-looking objects, and significant occlusions, highlighting its superior performance compared to existing methods.

This figure compares the performance of SyncVIS against two state-of-the-art video instance segmentation methods: Mask2Former-VIS and VITA. The figure highlights SyncVIS’s superior accuracy in challenging video sequences characterized by long durations, objects with similar appearances, and significant occlusions. The visual examples demonstrate that SyncVIS produces more precise and complete segmentations compared to the other methods in these difficult scenarios.

This figure compares the performance of SyncVIS against two state-of-the-art video instance segmentation methods, Mask2Former-VIS and VITA, on challenging video sequences. The examples demonstrate SyncVIS’s superior ability to accurately segment and track objects even when they have similar appearances or are heavily occluded. The improved performance highlights the effectiveness of SyncVIS in handling complex real-world scenarios.

This figure compares the performance of SyncVIS against Mask2Former-VIS and VITA on long videos. SyncVIS demonstrates superior accuracy in maintaining instance segmentation consistency across longer video sequences where the previous methods struggle. The example shows that Mask2Former-VIS and VITA have either low confidence scores or produce incomplete masks for some objects in the video.

This figure compares the video instance segmentation results using different embedding strategies: only video-level embeddings, only frame-level embeddings, and the combined synchronized video-frame embeddings. It highlights the advantages of using a synchronized approach, showing better segmentation accuracy and tracking of objects, particularly in complex scenarios with occlusion and motion.
More on tables
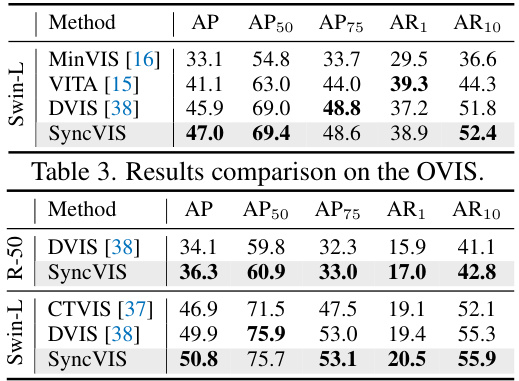
This table presents the performance comparison of SyncVIS against other state-of-the-art methods on the OVIS benchmark. The metrics used are Average Precision (AP), Average Precision at 50% IoU (AP50), Average Precision at 75% IoU (AP75), Average Recall at 1 (AR1), and Average Recall at 10 (AR10). The results are broken down by backbone used (ResNet-50 and Swin-L). SyncVIS shows improvements across all metrics compared to the competing methods.
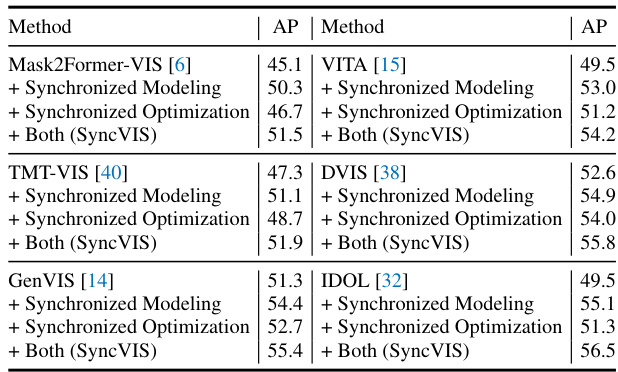
This table presents ablation experiments that evaluate the effectiveness of the proposed SyncVIS framework’s components when integrated into other state-of-the-art video instance segmentation methods. It shows the performance gains achieved by incorporating either the synchronized video-frame modeling paradigm, the synchronized embedding optimization strategy, or both, into four different existing methods: Mask2Former-VIS, VITA, TMT-VIS, GenVIS, and IDOL. The results demonstrate the consistent improvement in average precision (AP) across all methods when using SyncVIS’s components.
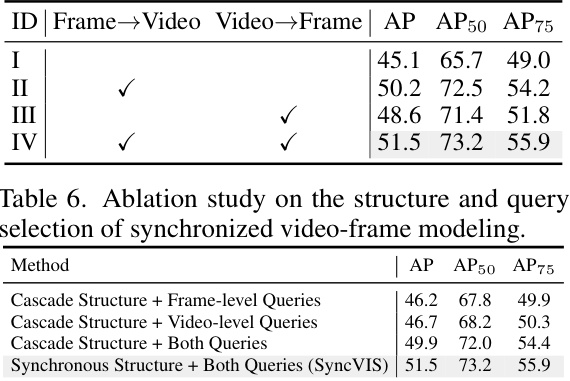
This table presents the results of an ablation study evaluating different designs of the synchronized video-frame modeling component in the SyncVIS framework. It compares the performance (AP, AP50, AP75) using various combinations of frame-level and video-level queries within both cascade and synchronous model structures. The results show that the synchronous structure with both queries yields the best performance.
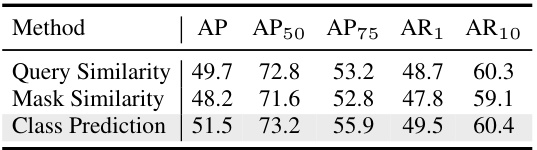
This table presents the ablation study of different aggregation strategies used in the synchronized video-frame modeling of the SyncVIS model. Three strategies are compared: Query Similarity, Mask Similarity, and Class Prediction. Each strategy uses different metrics to determine the similarity between video-level and frame-level embeddings in order to aggregate information. The table shows the results (AP, AP50, AP75, AR1, AR10) achieved by each strategy on a benchmark dataset. The results indicate the effectiveness of using class predictions for aggregation in achieving the best performance.

This table presents the ablation study of the SyncVIS model focusing on two key hyperparameters: Nk (the number of top embeddings selected for aggregation in the synchronized video-frame modeling) and Ts (the size of sub-clips in the synchronized embedding optimization). The results (AP, AP50, AP75, AR1, AR10) on YouTube-VIS 2019 are shown for different values of Nk and Ts, demonstrating the optimal settings for these hyperparameters in achieving the best performance.
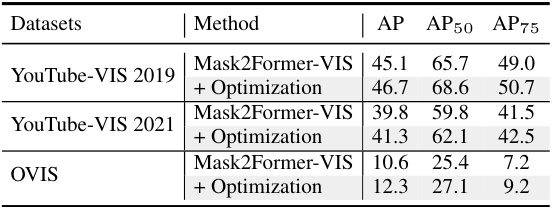
This table presents ablation studies evaluating the impact of incorporating the proposed ‘synchronized video-frame modeling paradigm’ and ‘synchronized embedding optimization strategy’ into existing state-of-the-art video instance segmentation (VIS) methods. It demonstrates the effectiveness of each module individually and in combination, showcasing consistent performance improvements across different base VIS models (Mask2Former-VIS, VITA, DVIS, and IDOL) on various datasets. The results highlight the generalizability and effectiveness of the proposed modules for enhancing VIS accuracy.

This table presents a comparison of key statistics for three popular video instance segmentation datasets: YouTube-VIS 2019, YouTube-VIS 2021, and OVIS. For each dataset, the table lists the number of videos, categories, instances, masks, average masks per frame, and average objects per video. This provides a quick overview of the size and complexity of each dataset, useful for understanding the scale of the experiments conducted in the paper.
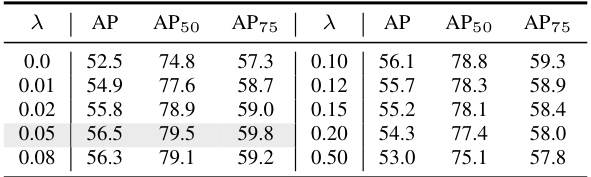
This table presents the ablation study of the update momentum (λ) used in the synchronized video-frame modeling module of the SyncVIS model. Different values of λ were tested on the YouTube-VIS 2019 dataset to determine its effect on the model’s performance, measured by Average Precision (AP), AP at 50% IoU (AP50), and AP at 75% IoU (AP75). The results show that a value of λ=0.05 yields the best performance.
Full paper#