↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision transformers (ViTs) and convolutional neural networks (CNNs) are often considered as alternatives. While some works try to integrate both, they apply these operators simultaneously at the finest granularity. This approach causes scalability issues, making it difficult to adapt ViTs to high-resolution images. Previous works usually apply heavy multi-head self-attention (MHSA) to every pixel of the input. This is computationally expensive. In addition, Convs are already efficient in extracting per-pixel features. Therefore, it is unnecessary to apply MHSA to every pixel.
This paper proposes GLMix, a novel approach to address this issue by using convolutions and MHSAs at different granularities. It represents images using both a fine-grained grid (for convolutions) and a coarse-grained set of semantic slots (for MHSAs). A fully differentiable soft clustering module bridges these representations, enabling local-global fusion. Experiments demonstrate GLMix’s efficiency and superior performance on various vision tasks, surpassing recent state-of-the-art models while using significantly fewer parameters and FLOPs.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel approach to integrating convolutional and attention mechanisms in vision backbones, a critical area in computer vision. It addresses scalability issues with existing methods by employing them at different granularities and achieves state-of-the-art results, making it highly relevant to researchers working on efficient and high-performing vision models. The introduction of soft clustering also opens avenues for weakly-supervised semantic segmentation.
Visual Insights#
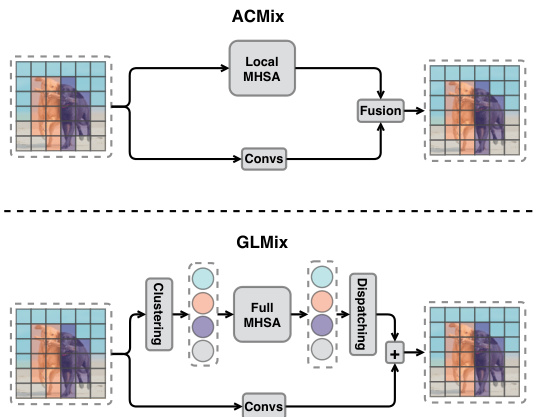
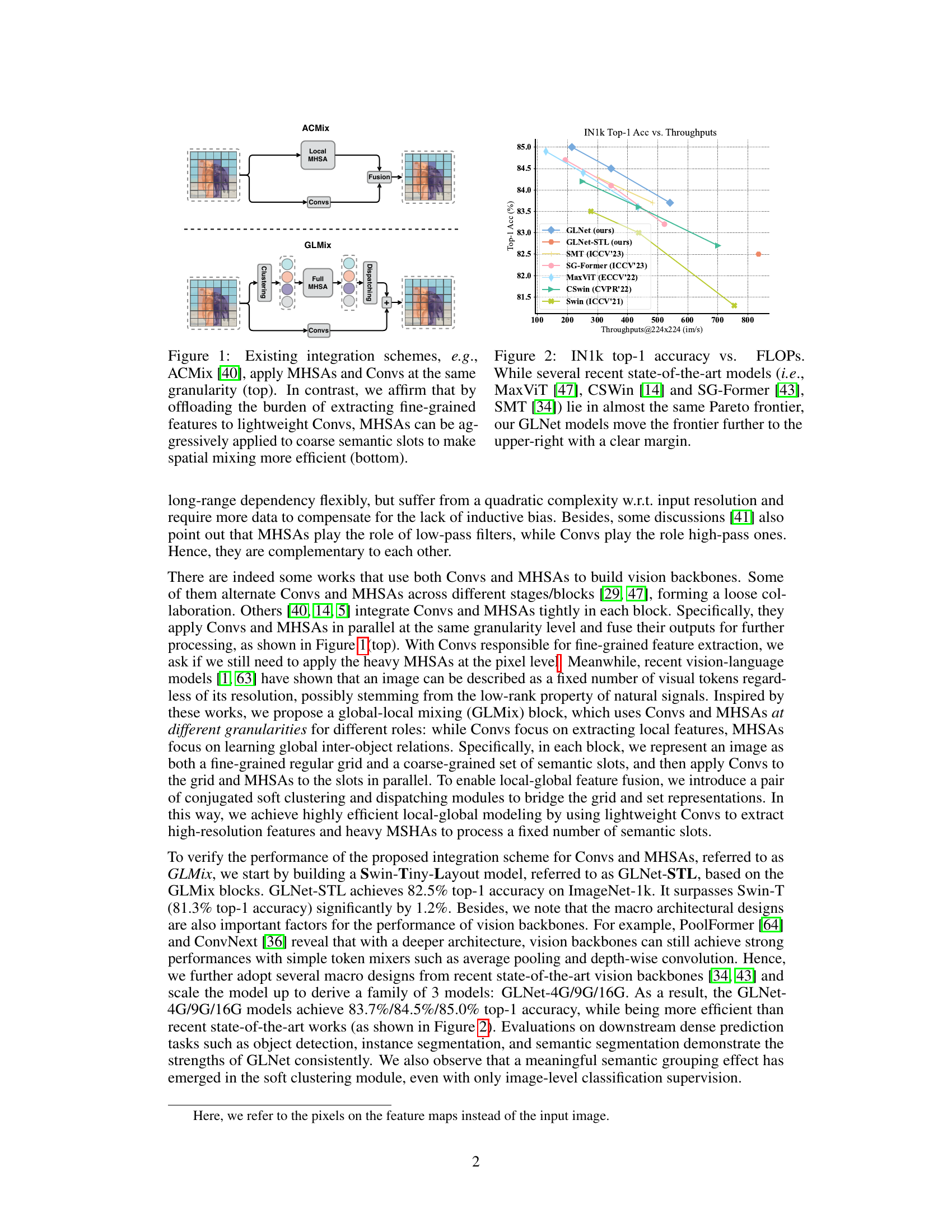
This figure compares two different approaches for integrating convolutional and multi-head self-attention mechanisms in vision backbones. The top part illustrates the existing approach (ACMix), where both operations are applied at the same fine-grained level. The bottom part shows the proposed GLMix approach, which uses MHSAs at a coarser granularity (on semantic slots) and Convs at a finer granularity (on a regular grid), leading to improved efficiency.
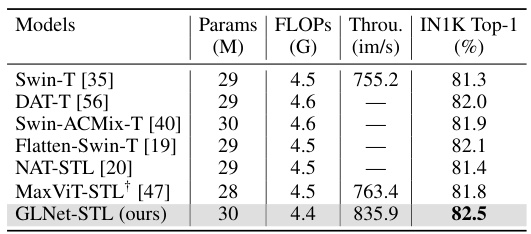
This table compares the proposed GLNet-STL model with other state-of-the-art models using the Swin-Tiny-Layout protocol. The metrics include the number of parameters (Params), floating point operations (FLOPs), throughput (Throu.), and top-1 accuracy on the ImageNet-1K dataset (IN1K Top-1). It highlights that GLNet-STL achieves the best top-1 accuracy (82.5%) with a similar parameter count and FLOPs, but a significantly higher throughput.
In-depth insights#
Conv-Attn Fusion#
Conv-Attn fusion strategies in vision models aim to synergistically leverage the strengths of convolutional neural networks (CNNs) and transformers. CNNs excel at capturing local spatial features efficiently, while transformers excel at modeling long-range dependencies and global context. Naive approaches often apply both simultaneously at the same granularity, which is computationally expensive and may not fully realize the potential benefits of each. A more effective strategy is to integrate them at different granularities. For example, CNNs can be employed for high-resolution, fine-grained feature extraction, and transformers can operate on a coarser level to model global relationships between semantic regions. This hierarchical approach reduces computational cost. Key challenges include designing mechanisms to effectively bridge the different feature representations (fine-grained and coarse-grained) for fusion. This might involve attention-based mechanisms to selectively incorporate global context into local feature maps or clustering strategies to group pixels into semantically meaningful regions. The effectiveness of a Conv-Attn fusion architecture hinges on balancing computational efficiency with performance gains, especially for high-resolution images. Careful design of the fusion mechanism is vital to avoid introducing artifacts or hindering performance.
Granularity Matters#
The concept of ‘Granularity Matters’ in the context of convolutional neural networks (CNNs) and vision transformers (ViTs) highlights the crucial role of the level of detail at which operations are performed. Effective integration of CNNs and ViTs necessitates a nuanced approach to granularity, recognizing that CNNs excel at fine-grained local feature extraction while ViTs are adept at capturing long-range global relationships. A single granularity for both approaches is suboptimal; instead, a hybrid model leveraging parallel processing at different granularities, merging local and global information, demonstrates superior performance. This involves applying convolutions to a fine-grained image grid for local features and self-attention mechanisms to a coarser, semantically meaningful representation for global context, potentially achieving a balance between efficiency and accuracy. The success of such an approach depends on a clever mechanism to seamlessly fuse the information extracted at these disparate levels of detail, emphasizing the significance of thoughtful design in combining these powerful architectures.
Soft Clustering#
Soft clustering, in the context of the provided research paper, appears to be a crucial component of a novel approach to integrating convolutional and self-attention mechanisms in vision backbones. Instead of using hard clustering methods like k-means, which are computationally expensive and non-differentiable, the authors propose a fully differentiable soft clustering module. This allows for seamless integration within a neural network architecture, facilitating end-to-end optimization. The soft clustering module seemingly achieves meaningful semantic grouping of features, even with only image-level classification supervision, suggesting a potential for improved interpretability and inspiration for weakly-supervised semantic segmentation approaches. This innovative technique efficiently bridges local (convolutional) and global (self-attention) feature representations, significantly enhancing the efficiency and performance of the vision backbone while mitigating the scalability issues associated with traditional methods. The use of a soft clustering mechanism stands out as a key differentiator and a significant contribution of this research.
GLNet: Efficiency#
The efficiency of GLNet stems from its novel integration of convolutions and multi-head self-attentions at different granularities. Offloading the burden of fine-grained feature extraction to lightweight convolutions allows the computationally expensive MHSA modules to operate on a smaller set of semantic slots, significantly reducing computational cost. This approach contrasts with existing methods that apply both operators at the same fine-grained level, leading to scalability issues with high-resolution inputs. The use of a fully differentiable soft clustering mechanism to bridge the grid and set representations further enhances efficiency by enabling a more effective local-global feature fusion without the need for iterative or heuristic approaches. GLNet’s architecture, combined with these optimizations, achieves state-of-the-art performance while maintaining high throughput and reducing FLOPs, demonstrating its significant efficiency gains compared to existing vision backbones.
Future: Dynamic Slots#
The concept of “Future: Dynamic Slots” suggests a promising direction for enhancing the efficiency and adaptability of the proposed GLMix architecture. Static slots, as currently implemented, limit the model’s ability to respond effectively to the diverse range of visual information present in different images. A system with dynamically allocated slots would allow the model to focus computational resources where they are most needed, improving performance on complex scenes. This could involve a mechanism that adjusts the number of slots or their spatial distribution based on the scene’s content. Computational efficiency will be crucial; any added complexity must not outweigh the performance gains. Implementing such a system would likely require a novel slot allocation strategy, perhaps incorporating a learned attention mechanism that guides resource allocation. Interpretability could also benefit, as visualizing the dynamic slot assignments may provide further insight into the model’s decision-making process. The research should focus on both enhancing efficiency and maintaining or improving the model’s accuracy. Success will require careful consideration of computational cost, training stability, and the impact on overall model accuracy.
More visual insights#
More on figures

This figure shows a comparison of the trade-off between top-1 accuracy on ImageNet-1k and FLOPS (floating point operations per second) for several state-of-the-art models, including the proposed GLNet models. It demonstrates that GLNet achieves higher accuracy at similar or better throughput compared to other models, representing an improvement in efficiency.

This figure illustrates the architecture of the GLMix block, a core component of the proposed GLNet model. The GLMix block integrates convolutional and multi-head self-attention operations at different granularities. It takes as input both a fine-grained grid representation (from convolutions) and a coarse-grained set representation (semantic slots). A pair of fully differentiable soft clustering and dispatching modules are used to bridge these representations, enabling the fusion of local and global features. The clustering module groups the fine-grained features into semantic slots, while the dispatching module redistributes the processed features from the slots back to the grid. This architecture aims to combine the strengths of both local (convolution) and global (self-attention) feature processing, achieving efficient local-global feature fusion.

This figure illustrates the difference between the proposed method’s representation of an image and the traditional approach used in Vision Transformers. The left side shows how the proposed method represents an image using soft irregular semantic regions as semantic slots. The right side displays how traditional Vision Transformers divide an image into hard-divided regular patches. The caption highlights that the proposed method’s approach is more similar to tokenization used in natural language processing (NLP).

This figure visualizes how the semantic slots, which are used in the GLMix block, correspond to regions of the input image. The left column shows the original input images. The middle column displays the assignment maps, showing how each pixel in the input image is assigned to one of the 64 semantic slots. The right column shows four representative slots selected by a k-medoids algorithm, providing a visual representation of the learned semantic features.

This figure visualizes the semantic slots at different depths (2nd, 5th, and 10th blocks) of the GLMix integration scheme. Each row shows an input image and the corresponding semantic slots for each block. The visualization uses color-coding to represent the clustering weights, highlighting the regions that each semantic slot focuses on. By comparing across different depths, we observe the shift in the semantic grouping from color-based patterns (shallow block) to object-level groupings (deeper block).

This figure visualizes the semantic slots generated by the GLMix module. Each row represents a different image. The leftmost column displays the input image. The central columns show heatmaps representing the assignment of each pixel to the semantic slots. Finally, the rightmost columns display the four most representative semantic slots for each image, selected automatically using the k-medoids algorithm. This visualization demonstrates the semantic grouping effect achieved by the soft clustering module, even without dense supervision.

This figure visualizes the semantic slots learned by the model. Each row shows an example image, followed by a grid of activation maps representing the different semantic slots. The selected semantic slots are visualized on the right. This helps understand how the model groups image regions into meaningful semantic concepts.
More on tables
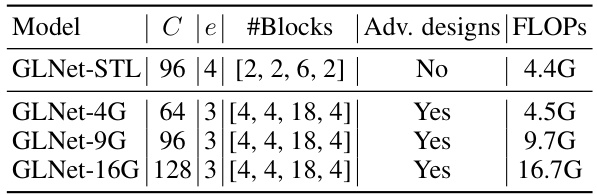
This table details the configurations of the GLNet model family, showing the base channels, FFN expansion ratio, number of blocks in each of the four stages, whether advanced designs were used, and the FLOPs (floating point operations) at a 224x224 resolution. It provides a quantitative comparison of the different GLNet models.
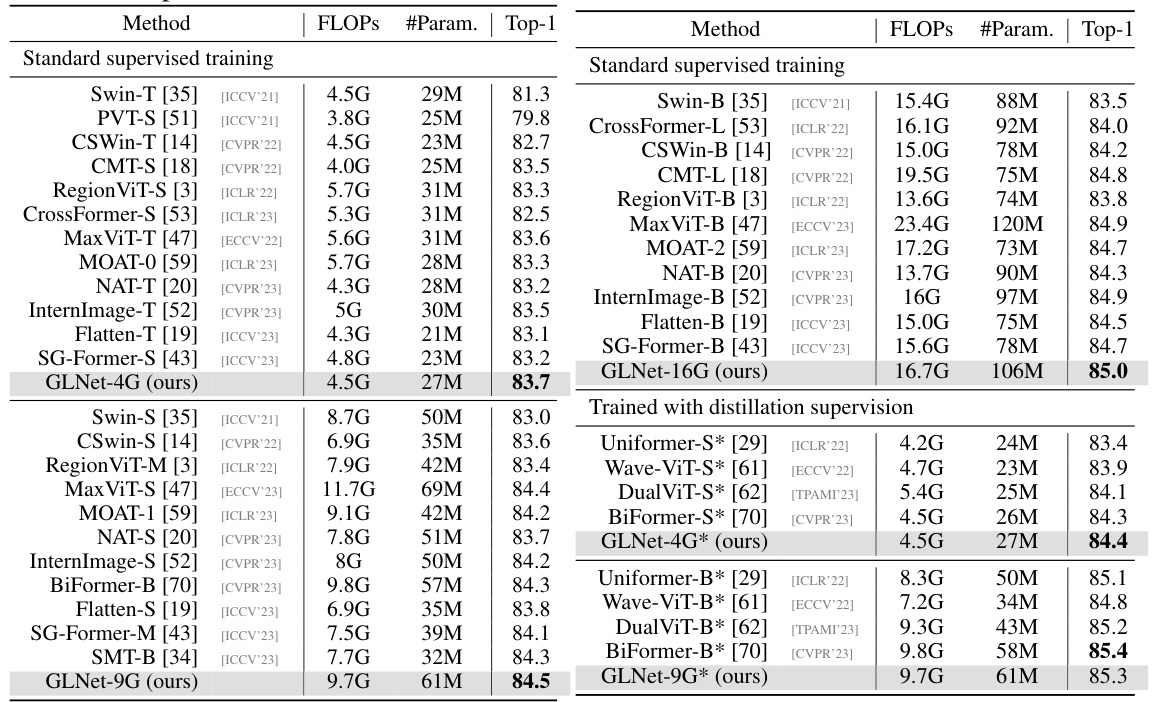
This table compares the performance of the proposed GLNet model against other state-of-the-art models on the ImageNet-1K classification task. It shows the FLOPs, number of parameters, and top-1 accuracy for each model under both standard supervised training and advanced distillation training.
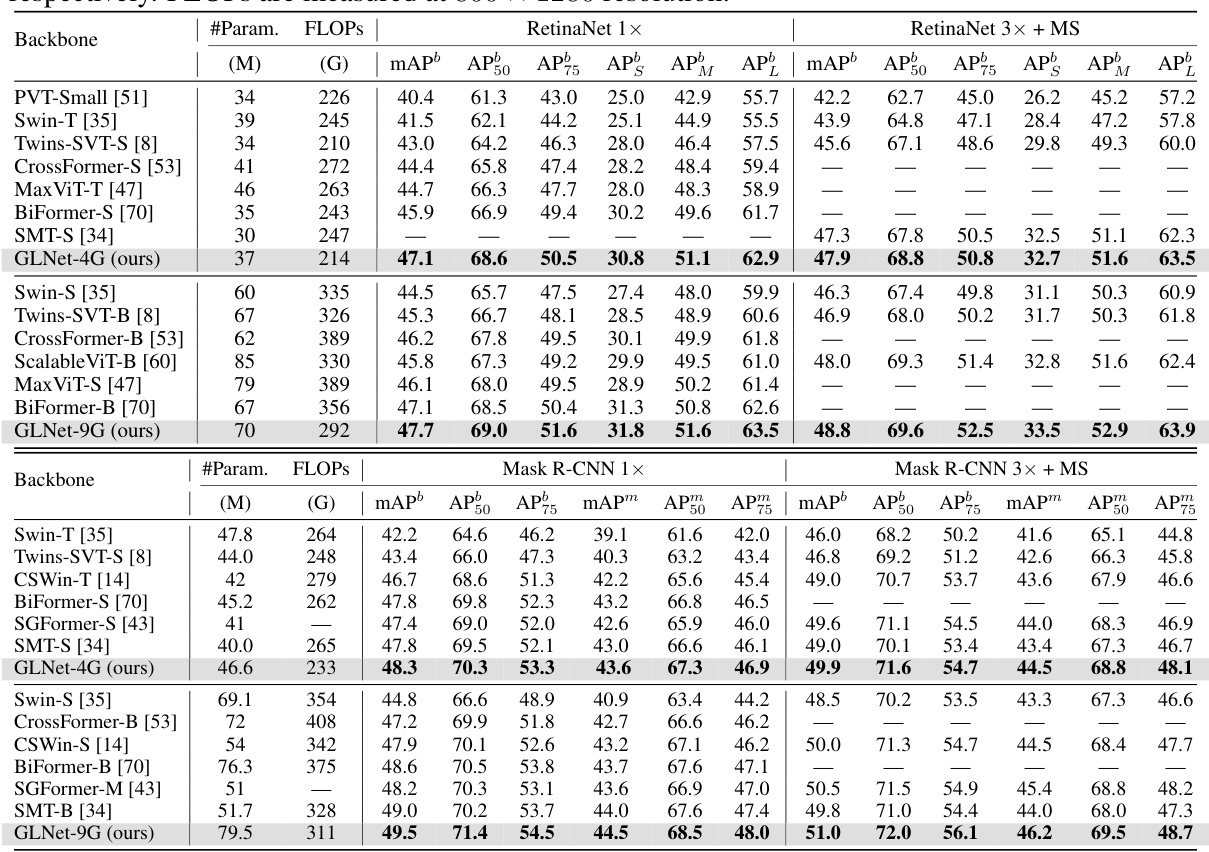
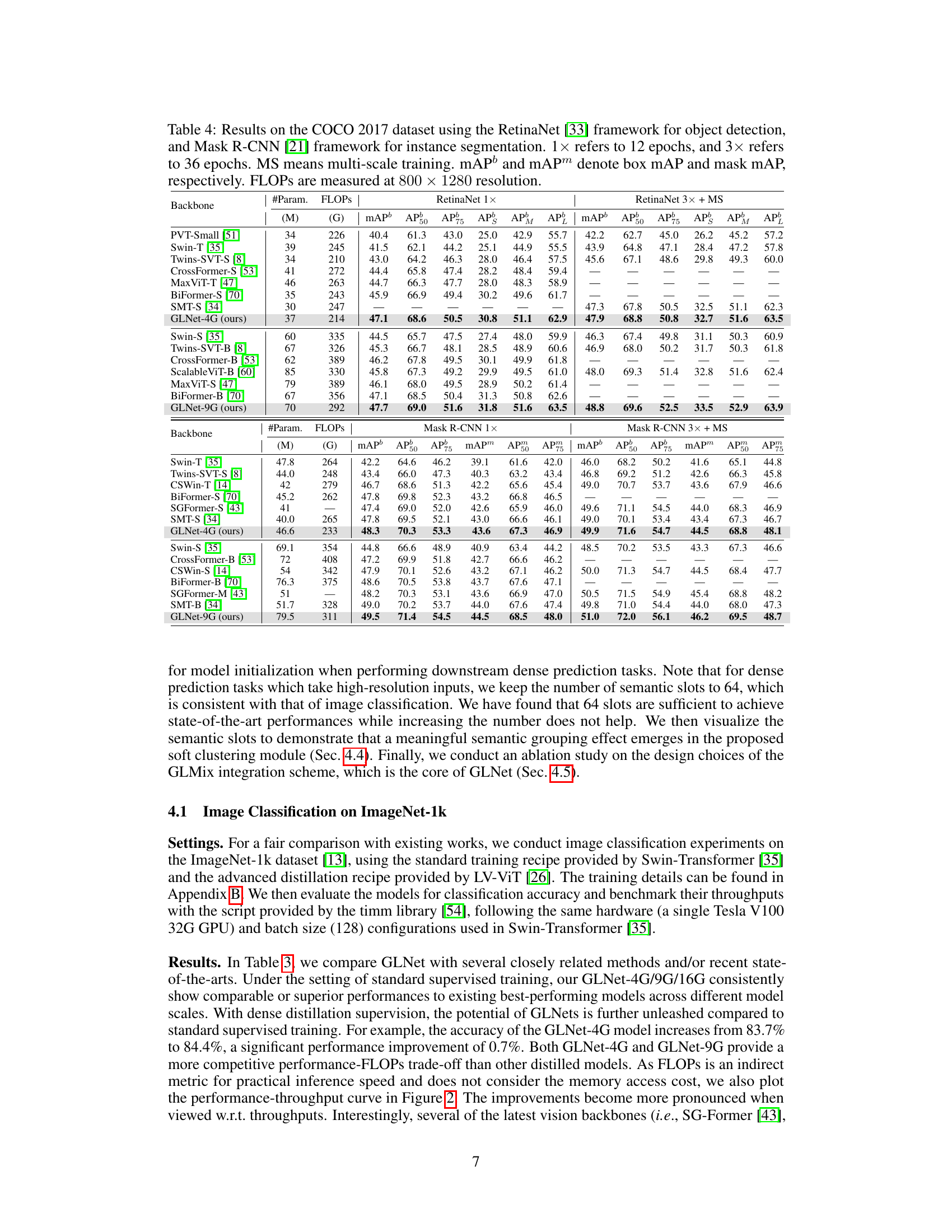
This table presents the results of object detection and instance segmentation experiments on the COCO 2017 dataset. Two models, RetinaNet and Mask R-CNN, were used with different training schedules (1x and 3x epochs with multi-scale training). The table compares the performance of several backbones (including the proposed GLNet) across different metrics: mAP (mean Average Precision), AP50, AP75, APS (small object AP), APM (medium object AP), APL (large object AP), and FLOPs (floating point operations). The FLOPs are calculated at a resolution of 800x1280 pixels.

This table compares the performance of various backbones on the ADE20K semantic segmentation dataset. The metrics shown are the number of parameters, FLOPs (floating point operations), and mean Intersection over Union (mIoU). The results are presented for two different semantic segmentation frameworks, Semantic FPN and UperNet, each trained for a different number of iterations (80k and 160k, respectively). The table allows for a comparison of model efficiency and accuracy across different architectures.

This table presents an ablation study on the GLMix integration scheme. The study systematically investigates the impact of different design choices within the GLMix block on the model’s performance, measured by IN1k Top-1 accuracy and throughput. Specifically, it analyzes: 1) the use of both local and global branches, 2) different clustering strategies (soft clustering, k-means, static initialization), 3) various convolution kernel sizes in the local branch, and 4) different numbers of semantic slots in the global branch. Results show the importance of both local and global branches working in parallel and the effectiveness of the proposed soft clustering method over alternatives.
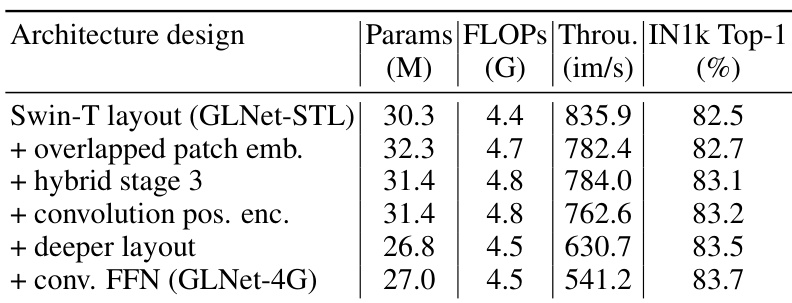
This table shows the impact of several advanced architectural designs on the performance of the GLNet model. Starting with the Swin-T layout (GLNet-STL), each row shows the effect of adding a new design, such as overlapped patch embedding or hybrid stage 3, on the number of parameters, FLOPs, throughput, and ImageNet-1k Top-1 accuracy. The final row shows the performance of GLNet-4G after all modifications have been applied.

This table compares the performance of GLNet models with other state-of-the-art models on ImageNet-1k classification. It shows the FLOPs, number of parameters, and top-1 accuracy for each model, broken down by whether they were trained using standard supervised training or an advanced distillation technique. This allows for a comparison of both accuracy and efficiency across different model architectures.
Full paper#