↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large vision-language models (LVLMs) are rapidly advancing, but a critical issue—their inconsistency in answering the same question phrased differently—has been largely ignored. This paper tackles this problem by introducing ConBench, a new benchmark designed to specifically assess this consistency across different prompt types. ConBench evaluates LVLMs on various visual question answering tasks, revealing a significant gap between their performance on simple prompts and complex, more open-ended ones.
The researchers found that larger solution spaces lead to lower accuracy, and there’s a positive correlation between the discriminative and generative consistency of LVLMs. Closed-source models generally outperform open-source ones regarding consistency. To address this inconsistency, they propose a trigger-based diagnostic refinement, which boosts caption quality in several LVLMs without retraining. This novel benchmark and refinement method significantly contribute to the development of more robust and reliable LVLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large vision-language models (LVLMs). It introduces a novel benchmark, ConBench, for evaluating the consistency of LVLMs, a critical aspect often overlooked in previous research. The findings highlight significant consistency issues in existing LVLMs and propose a practical method for improvement. This work will accelerate research in this critical area, helping build more reliable and trustworthy multimodal AI systems.
Visual Insights#

This figure provides a high-level overview of the paper. Part (a) shows examples of inconsistencies found in large vision-language models (LVLMs), where different question formats yield contradictory answers for the same image. Part (b) introduces ConBench, a novel benchmark for evaluating consistency, and shows its top three performing models. Part (c) summarizes the paper’s three main findings based on the ConBench analysis.

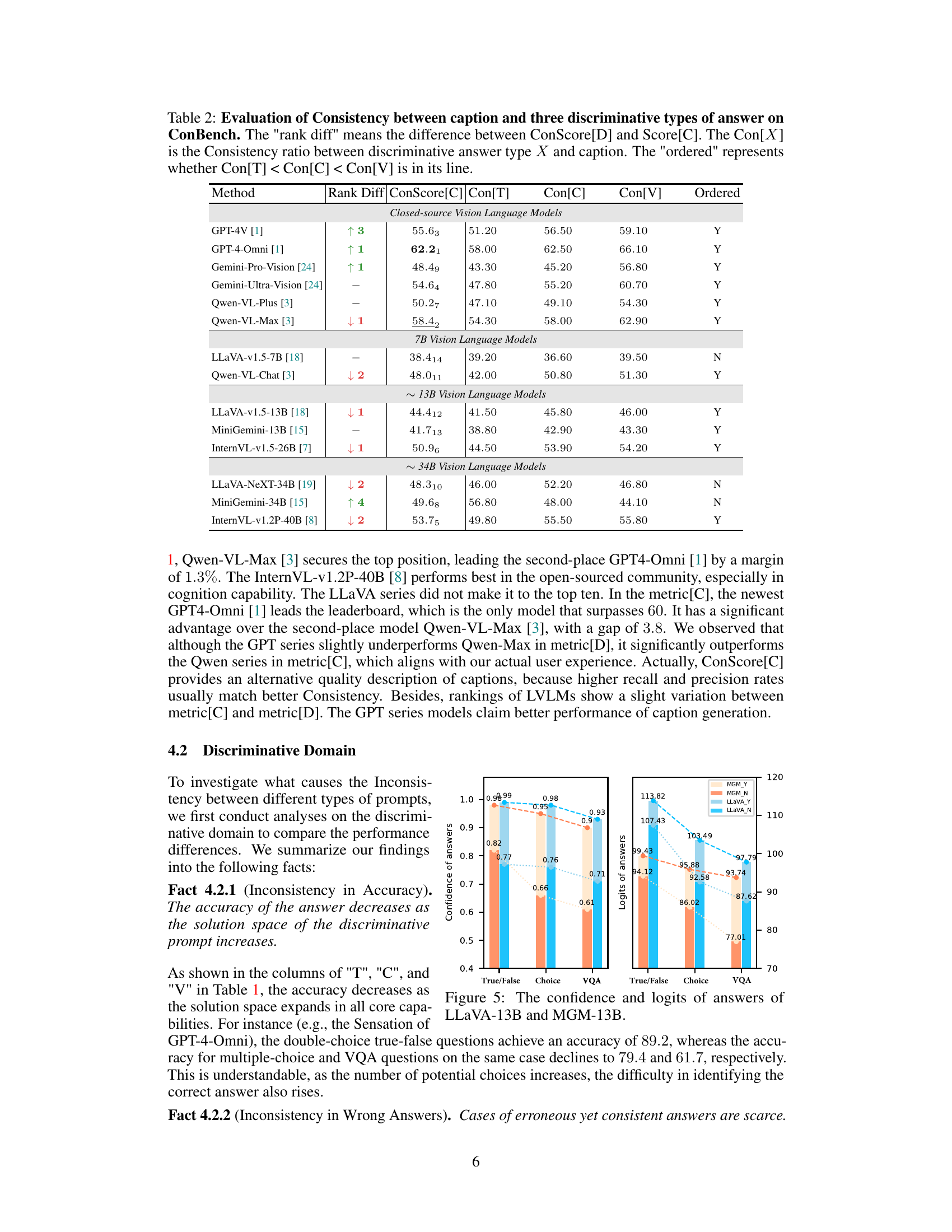
This table presents the performance of various Large Vision-Language Models (LVLMs) on the ConBench benchmark. It breaks down the results based on three core capabilities (Sensation, Cognition, and Knowledge) and three question types (True/False, Multiple Choice, and Visual Question Answering - VQA). Each question type assesses the model’s accuracy and consistency in different aspects of visual understanding. The table also includes a ConScore[D], which is a composite score reflecting the overall consistency of the LVLMs.
In-depth insights#
Consistency Benchmark#
A Consistency Benchmark within the context of large vision-language models (LVLMs) is crucial for evaluating their reliability and robustness. It assesses the consistency of model responses across various prompt formulations and solution spaces, revealing potential weaknesses. A robust benchmark should encompass diverse prompt types (e.g., true/false, multiple-choice, open-ended), ensuring a comprehensive evaluation. The design should also consider the size of the solution space, as larger spaces may reveal inconsistencies unseen in smaller, more constrained ones. Bias detection is another important aspect, identifying any systematic preferences or limitations in the models’ responses, especially those concerning open-source vs. closed-source models. Furthermore, a valuable benchmark needs clear metrics for quantifying consistency and methods for visualizing and analyzing results to aid in understanding the nuances of LVLMs’ performance. Ultimately, a well-designed Consistency Benchmark facilitates the development of more reliable and trustworthy LVLMs.
Bias in LVLMs#
Analyzing bias in Large Vision-Language Models (LVLMs) is crucial for understanding their limitations and ensuring fair and equitable outcomes. Bias can manifest in various ways, stemming from biases present in the training data (e.g., underrepresentation of certain demographics or viewpoints) or from architectural limitations of the models themselves. These biases can lead to unfair or discriminatory predictions, particularly when dealing with sensitive topics like gender, race, or socioeconomic status. Identifying and mitigating bias requires a multifaceted approach. This includes careful curation of training data, development of bias detection techniques, and exploring architectural innovations that promote fairness. Furthermore, evaluating LVLMs for bias necessitates rigorous benchmarking and assessment tools that go beyond simple accuracy metrics, specifically designed to probe for these biases. Transparency in model development and deployment is also essential to ensure accountability and enable community scrutiny. A comprehensive investigation of bias necessitates collaborations among researchers, engineers, and policymakers to establish best practices and ethical guidelines for the creation and application of LVLMs.
Trigger-based Refinement#
The proposed ‘Trigger-based Diagnostic Refinement’ method offers a compelling approach to enhance the consistency and quality of Large Vision-Language Models (LVLMs) without retraining. By identifying low-confidence words (triggers) within LVLMs’ initial responses, the method strategically formulates targeted discriminative questions. This iterative refinement process encourages self-verification within the model, leading to improved caption quality. The effectiveness is demonstrated through noticeable improvements in the consistency scores of LLaVA-34B and MiniGemini-34B, suggesting that this cost-effective method holds promise for enhancing LVLMs’ performance. The focus on low-confidence words is particularly insightful, directly addressing areas where the model lacks certainty. This targeted approach is more efficient than full retraining, making it a practical solution for enhancing existing LVLMs. Future work could explore expanding the types of trigger questions and investigating the impact of iterative refinement rounds on model performance and computational cost.
Generative Consistency#
Generative consistency, in the context of large vision-language models (LVLMs), explores the agreement between a model’s generated descriptions (captions) and its answers to related questions. Inconsistency arises when the model provides contradictory information depending on the question’s phrasing or context, despite the underlying visual information remaining the same. This undermines trust and limits the practical utility of LVLMs. Analyzing generative consistency reveals crucial insights into a model’s internal reasoning process and its ability to maintain a coherent understanding of the visual input. Addressing this issue requires sophisticated methods that go beyond simple accuracy metrics and focus on the consistency and reliability of the model’s overall understanding. This is a critical area for future research, as improving generative consistency can significantly enhance the trustworthiness and practical applicability of LVLMs.
Future Consistency Research#
Future research in consistency for large vision-language models (LVLMs) should prioritize developing new benchmarks that go beyond single-prompt evaluations and incorporate diverse question formats and solution spaces to better reflect real-world usage. Improving the evaluation metrics themselves is also crucial, moving beyond simple accuracy to incorporate measures of consistency and robustness across various prompt types. Furthermore, research should explore novel architectural designs for LVLMs that inherently promote consistency, potentially incorporating mechanisms for self-verification or uncertainty quantification. Investigating the relationship between model size, architectural choices, and consistency is vital, as is understanding how to effectively leverage knowledge bases or external reasoning modules to reduce inconsistency. Finally, developing techniques to directly enhance the consistency of existing LVLMs during training or through post-training refinement, such as the trigger-based method, is a promising area for future work, and could focus on improving both the reliability and user experience of these powerful tools.
More visual insights#
More on figures
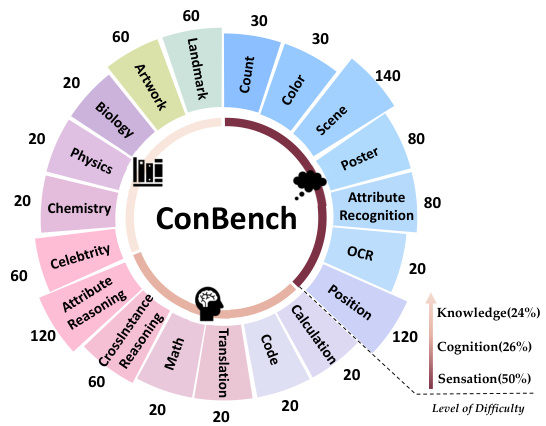
This figure provides a visual representation of the ConBench benchmark’s hierarchical structure. It’s divided into three core capabilities: Sensation, Cognition, and Knowledge, each encompassing various sub-categories of tasks. The size of each section visually represents the proportion of questions related to that category within the benchmark. The concentric circles also represent the increasing level of difficulty from sensation to knowledge, with sensation tasks being the easiest and knowledge tasks the most challenging.
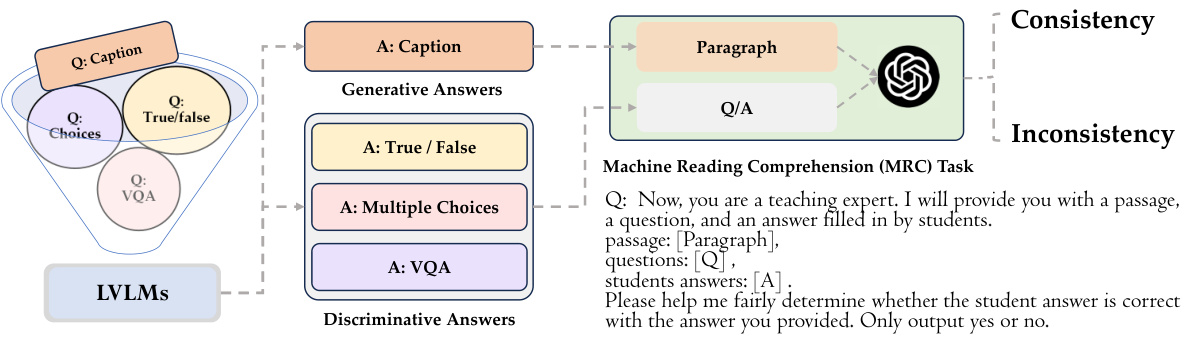
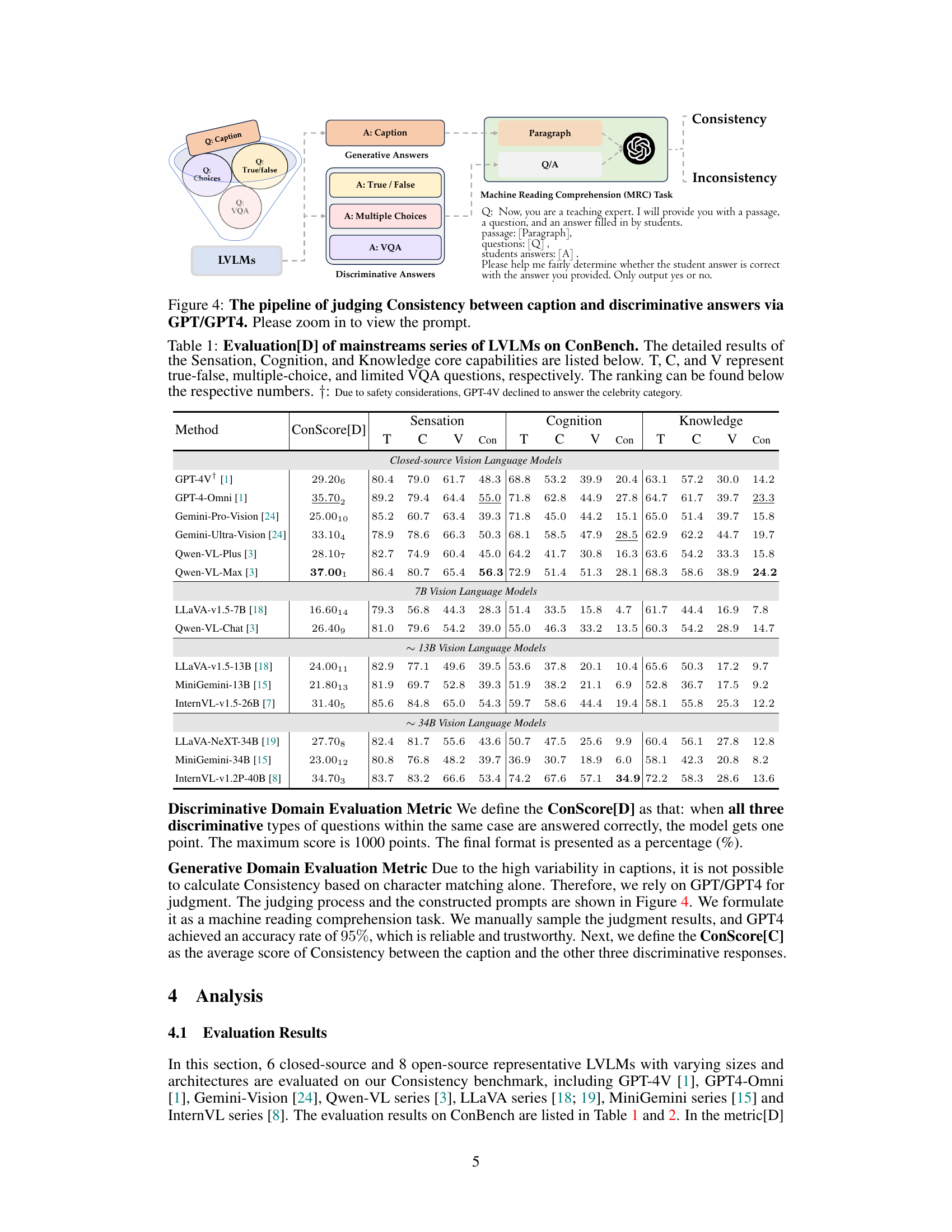
This figure illustrates the process of evaluating the consistency between a model’s caption generation and its answers to three types of discriminative questions (True/False, Multiple Choices, and VQA). The process uses a machine reading comprehension (MRC) task, where GPT/GPT4 acts as a judge, comparing the generated caption against the discriminative answers to determine consistency or inconsistency.

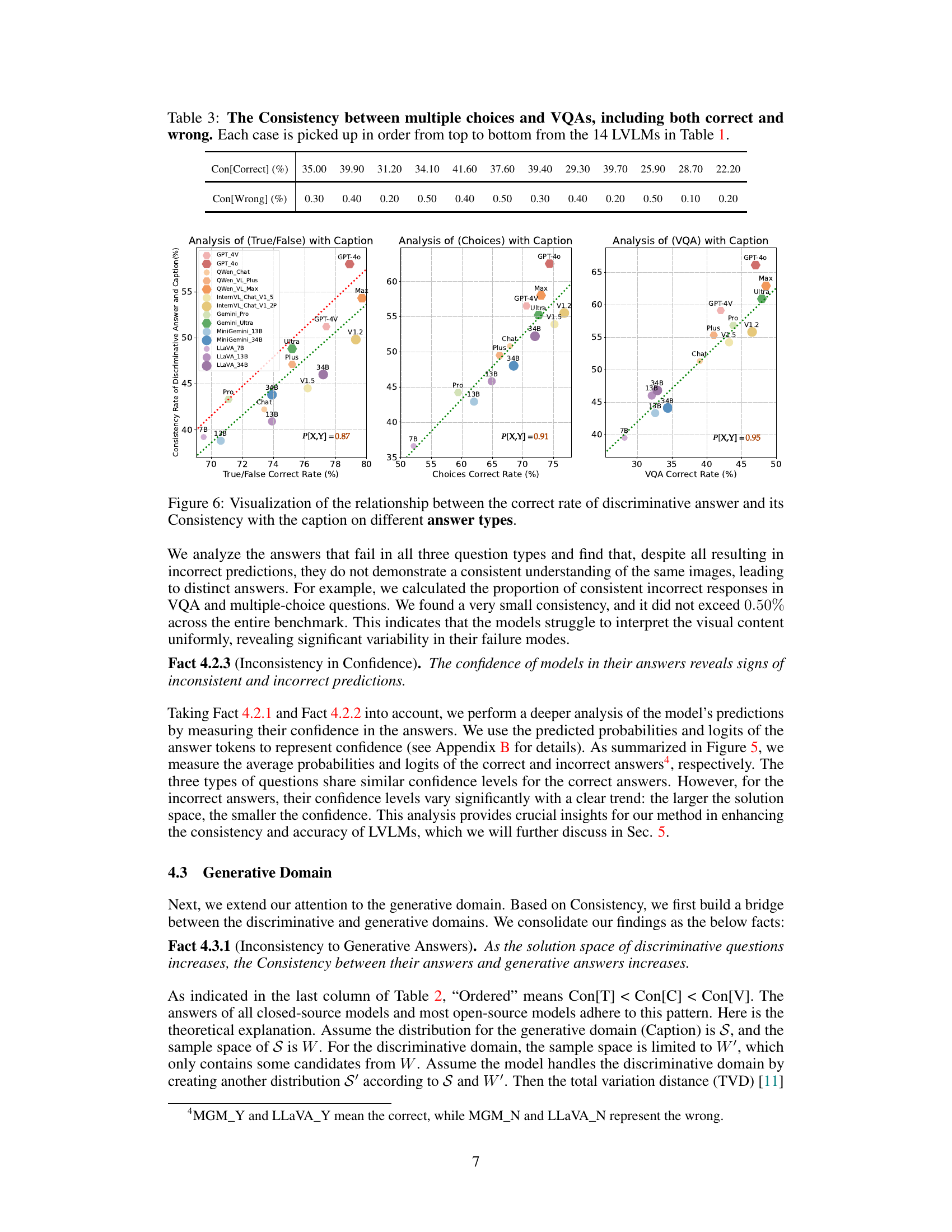
This figure shows a comparison of the confidence and logits of answers given by two different large vision-language models (LLaVA-13B and MGM-13B) for three types of questions: True/False, Choice, and VQA. The x-axis represents the question type and the y-axis shows the confidence (left panel) and logits (right panel) scores. The bars are color-coded to differentiate between correct answers (brighter colors) and incorrect answers (duller colors). The figure demonstrates that the confidence and logits vary among the question types and that there is a difference between the two models in their response behavior. Higher values in the confidence and logits generally indicate higher certainty in the model’s answer.
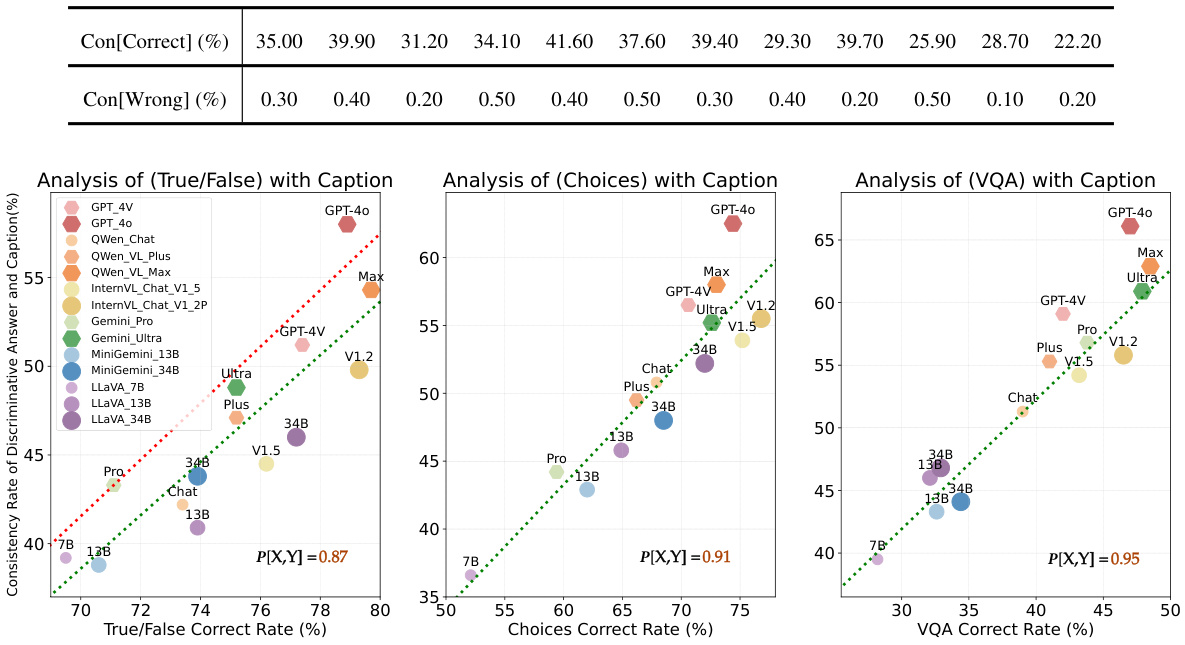
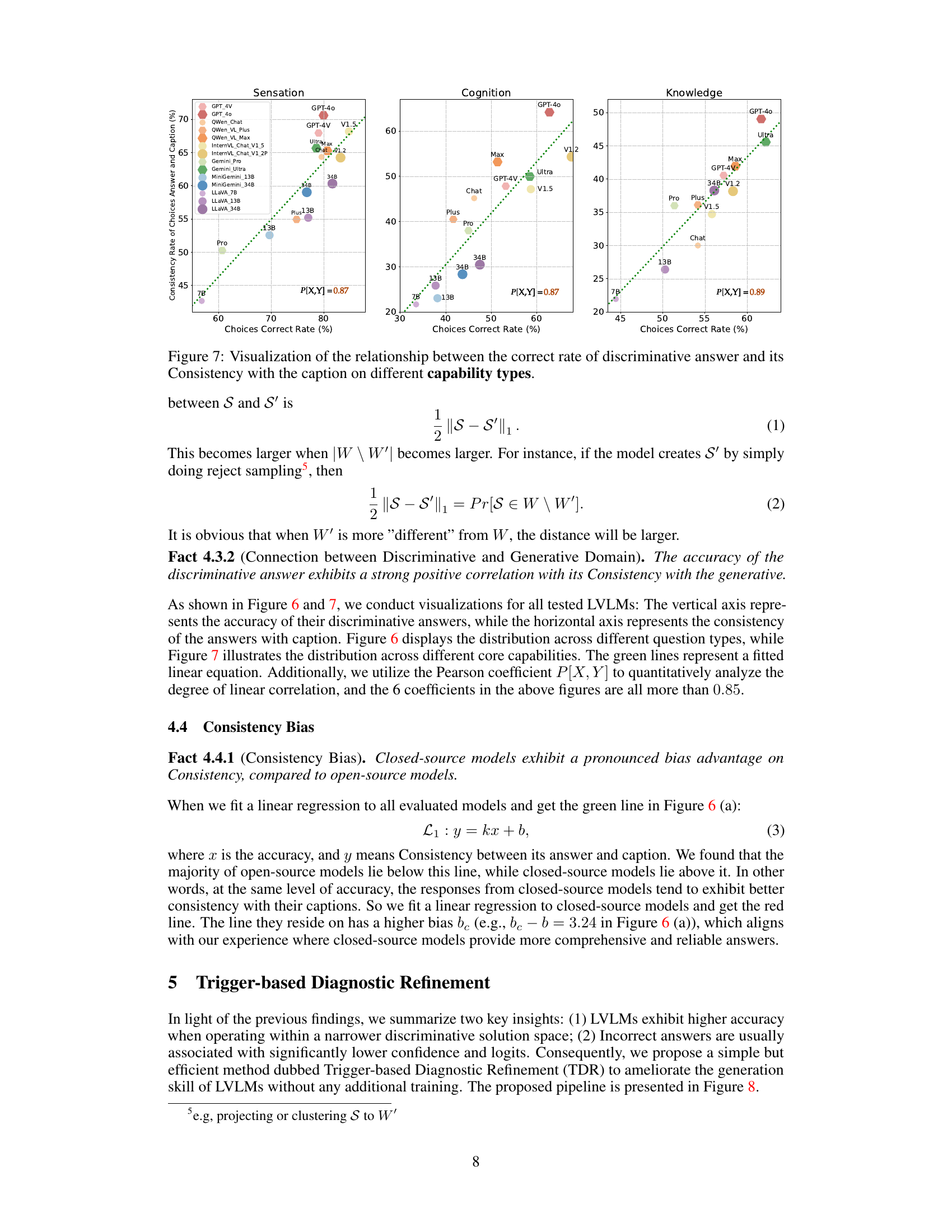
This figure visualizes the correlation between the accuracy of discriminative answers and their consistency with the generated caption across three different question types: True/False, Multiple Choice, and VQA. The x-axis represents the accuracy of the discriminative answers, while the y-axis shows the consistency rate (percentage of times the answer aligns with the caption). Each point represents a specific LVLMs’ performance. The plots show a clear positive correlation, indicating that more accurate discriminative answers tend to have higher consistency with the captions. The Pearson correlation coefficient (P[X,Y]) is provided for each plot, demonstrating the strength of the relationship.

This figure visualizes the correlation between the accuracy of discriminative answers and their consistency with the generated captions across three core capabilities: Sensation, Cognition, and Knowledge. Each point represents a specific large vision-language model (LVM). The x-axis shows the accuracy of the model’s discriminative answers (choices), while the y-axis represents the consistency rate between those answers and the caption. The green dotted line shows the linear regression fit. The figure demonstrates that higher accuracy generally corresponds to higher consistency across all three capabilities, suggesting a strong relationship between the ability to answer discriminative questions correctly and generate consistent captions. The Pearson correlation coefficients (P[X,Y]) are also provided for each capability, indicating a strong positive correlation.
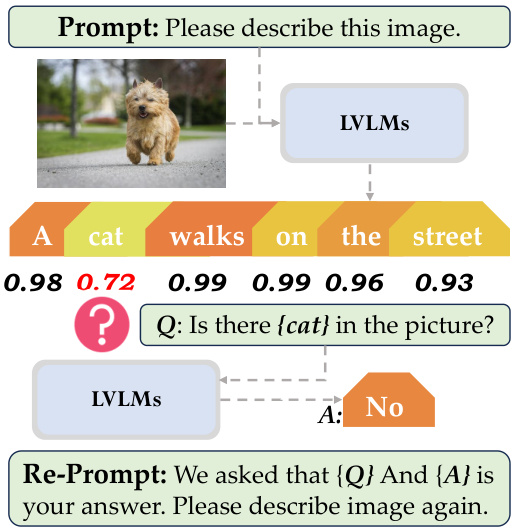
This figure illustrates the pipeline of the trigger-based diagnostic refinement method. It shows how a vision-language model (LVLMs) generates a caption for an image, with each word assigned a probability score. Words with low probability scores trigger a True/False question about the presence or absence of a specific item (e.g., ‘Is there a cat in the picture?’). The LVLMs answers this question, and both the question and answer are added to the original prompt. The refined prompt is then fed back into the LVLMs to generate a new, improved caption.

This figure provides a high-level overview of the paper. Part (a) shows examples of inconsistencies between model answers to different question types (discriminative and generative). Part (b) introduces ConBench, a benchmark used for evaluating model consistency, along with its top-performing models. Part (c) summarizes the main findings obtained using ConBench, illustrating the relationship between solution space size, accuracy, and consistency.

This figure provides a high-level overview of the paper. Part (a) shows examples of inconsistencies where the model provides contradictory answers to similar questions based on the same image. Part (b) introduces the ConBench benchmark, highlighting its evaluation method and showing a top three leaderboard of models. Part (c) summarizes the key findings from the benchmark.

This figure provides a high-level overview of the paper’s contributions. Part (a) showcases examples of inconsistencies between model responses to different question types about the same image, highlighting a key problem the paper addresses. Part (b) introduces ConBench, a new benchmark created to evaluate model consistency, showing its leaderboard. Part (c) summarizes the paper’s three main findings based on the analysis of the benchmark.

This figure provides a high-level overview of the paper. Part (a) illustrates two examples where the model gives inconsistent answers. The answers marked in blue contradict the answers marked in purple. Part (b) shows the ConBench tool used to evaluate model consistency, along with a ranking of the top three models. Part (c) summarizes the three main findings of the paper.

This figure provides a high-level overview of the research paper. Part (a) shows examples where vision-language models give inconsistent answers depending on how the question is phrased, even when referring to the same image. Part (b) introduces the ConBench, a new benchmark used to evaluate the consistency of these models, and shows its top-performing models. Part (c) summarizes three key findings based on the ConBench results.

This figure provides a high-level overview of the paper. Part (a) shows two examples illustrating inconsistencies between the answers given by large vision-language models (LVLMs) for discriminative questions and their corresponding generative captions. The inconsistencies highlight a key problem the paper addresses: LVLMs often give contradictory responses depending on how the question is phrased. Part (b) introduces ConBench, a new benchmark designed to evaluate the consistency of LVLM responses across different question types, showing its top three performing models. Finally, Part (c) summarizes the three main findings of the study based on the ConBench results.
This figure provides a high-level overview of the paper. Part (a) shows two examples where the model provides inconsistent answers. The first answer is a caption describing the image, while the second is a yes/no response to a question about the image. These two answers contradict each other. Part (b) shows the ConBench tool which was developed to evaluate the consistency of Large Vision-Language Models (LVLMs). It shows the top 3 performing models. Part (c) summarizes the three main findings from the evaluation.

This figure provides a high-level overview of the paper’s content. Part (a) shows examples of inconsistencies between model answers to different question types about the same image. Part (b) introduces ConBench, a benchmark designed to evaluate model consistency. Part (c) summarizes the key findings derived from using ConBench.

This figure provides a high-level overview of the paper. Part (a) illustrates the concept of inconsistency in vision-language models by showing examples where the model gives contradictory answers to similar questions based on the same image. Part (b) introduces ConBench, a benchmark used to evaluate the consistency of these models, and highlights the top three performing models. Finally, part (c) summarizes the three main findings obtained using ConBench.

This figure shows the prompt used to generate the different types of questions used in the ConBench benchmark. The prompt instructs a language model to act as a question expert and, given an initial discriminative question type (e.g., true/false), generate two additional discriminative questions and a VQA question, all revolving around the same knowledge point and related to the given image. This ensures diverse question formats to comprehensively evaluate the consistency of large vision-language models.

This figure shows the prompt used to instruct a large language model (LLM) to generate discriminative questions. The prompt instructs the LLM to act as a question expert and generate two additional questions based on an initial discriminative question. The additional questions are to be of a different discriminative type than the original question and must focus on the same knowledge point. This process helps ensure that the model is tested on a range of question types and not just a single question format.

This figure provides a visual representation of the ConBench benchmark’s hierarchical structure. It shows how the 1000 images in the benchmark are categorized across three core capabilities: Sensation, Cognition, and Knowledge. Each core capability is further divided into several sub-categories, illustrating the diversity and complexity of the tasks evaluated. The visual representation helps illustrate the breadth and depth of ConBench’s evaluation, emphasizing its comprehensive assessment of large vision-language models (LVLMs).
More on tables

This table presents the results of evaluating various Large Vision-Language Models (LVLMs) on the ConBench benchmark. The evaluation metric used is ConScore[D], which measures the consistency of the models’ responses across different question types (true/false, multiple-choice, and visual question answering). The table shows the performance broken down by three core capabilities: Sensation, Cognition, and Knowledge. Each LVLMs’ performance is shown with its ConScore[D] and the individual scores for each question type (T, C, V) for each capability. The table also includes rankings and notes on any limitations (e.g., GPT-4V’s inability to answer the celebrity category due to safety considerations).
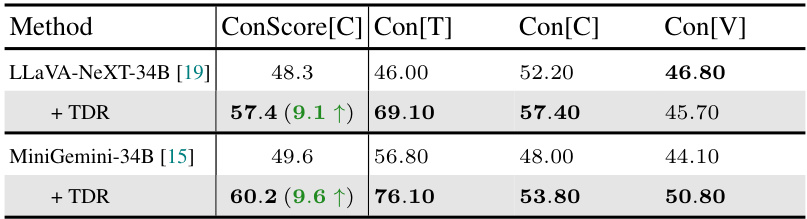
This table presents the results of applying the Trigger-based Diagnostic Refinement (TDR) method to the LLaVA-NeXT-34B and MiniGemini-34B models. The ConScore[C] metric, representing the consistency between the caption and the discriminative answers, is shown along with the individual consistency scores for True/False (Con[T]), multiple-choice (Con[C]), and VQA (Con[V]) question types. The improvements achieved by TDR are highlighted, showing significant gains in overall consistency for both models.
Full paper#