↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world time series tasks require models that are both accurate and efficient enough for deployment on resource-limited edge devices. Unsupervised domain adaptation (UDA) methods have shown promise in transferring knowledge between domains, but their success often hinges on complex model architectures unsuitable for such devices. Existing solutions integrating knowledge distillation into domain adaptation often suffer from network capacity issues and inefficient knowledge transfer.
This paper introduces Reinforced Cross-Domain Knowledge Distillation (RCD-KD) to address these limitations. RCD-KD uses reinforcement learning to dynamically select the most suitable target domain samples for knowledge transfer, improving the efficiency of the process and adapting to the student model’s capacity. Experiments across four public datasets demonstrate that RCD-KD outperforms existing methods, showcasing its effectiveness in transferring knowledge efficiently while maintaining high accuracy in the target domain. The use of reinforcement learning for sample selection is a key innovation, as it enables the method to dynamically adapt to the student model’s capabilities and avoid transferring unreliable information from the teacher.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on unsupervised domain adaptation and knowledge distillation for time-series data. It addresses the challenge of deploying complex models on resource-constrained devices by proposing a novel framework that enhances the efficiency of knowledge transfer. The findings are relevant to various time-series applications and open new avenues for research in efficient model adaptation and resource-aware AI.
Visual Insights#
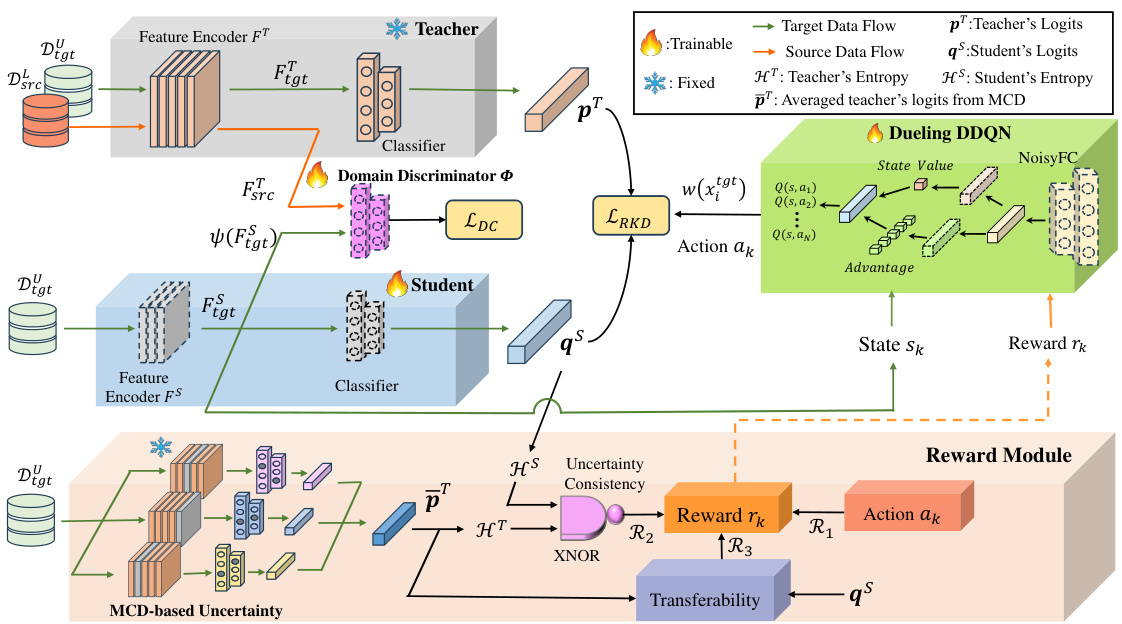
This figure illustrates the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) framework. It shows the interaction between a teacher and student model, a domain discriminator, and a reinforcement learning module for target sample selection. The reward module incorporates uncertainty consistency and sample transferability to guide the selection of optimal target samples for knowledge transfer. The domain discriminator ensures domain-invariant knowledge transfer.

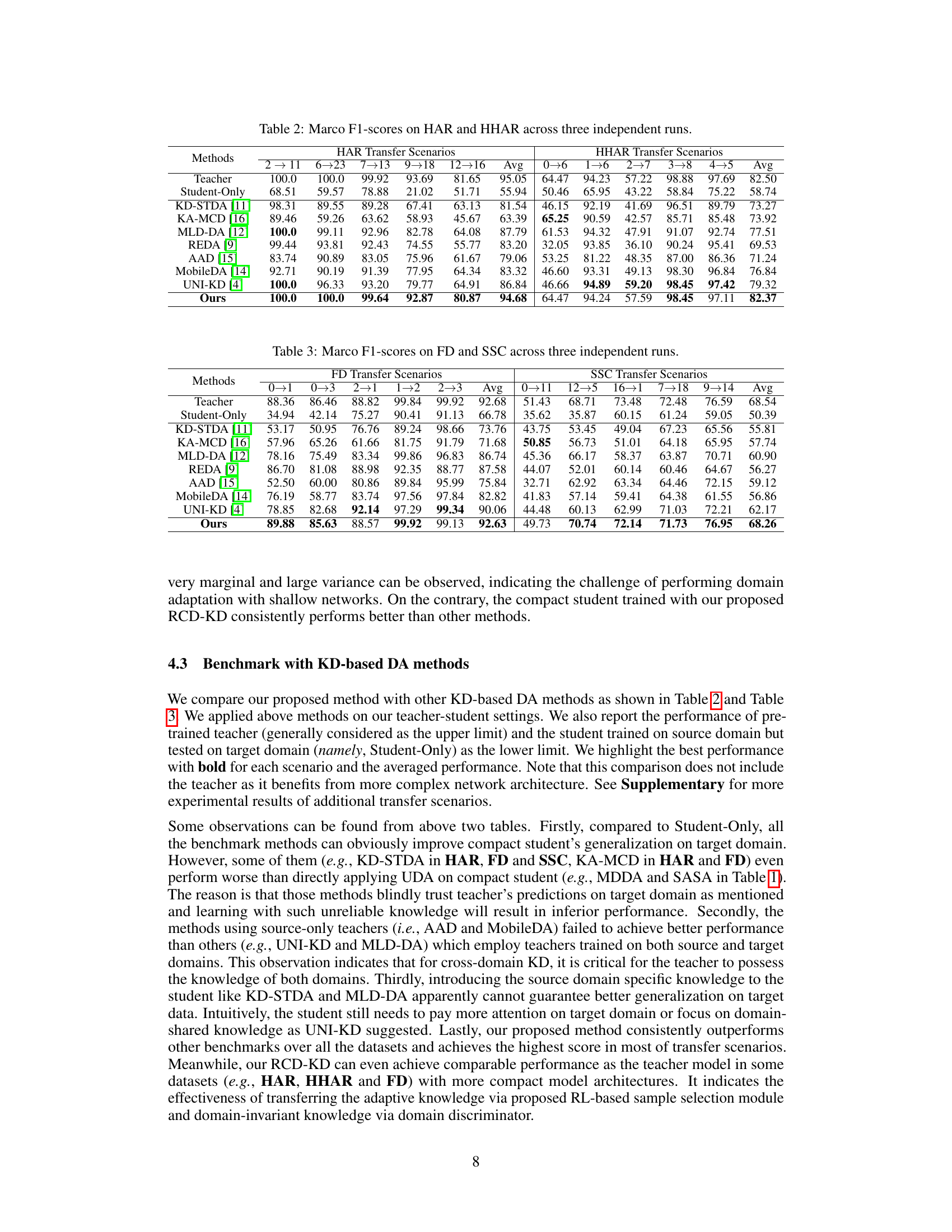
This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method with several other unsupervised domain adaptation (UDA) methods across four different datasets (HAR, HHAR, FD, SSC) using three different metrics. The ‘Student-Only’ column represents the performance of a compact student model trained only on the source domain without any domain adaptation. The remaining columns present the performance of different UDA methods, including the proposed RCD-KD method, showing the macro F1 score achieved for each method on each dataset. This allows for a direct comparison of the proposed method’s performance against state-of-the-art techniques in handling domain shift problems.
In-depth insights#
Cross-Domain KD#
Cross-domain knowledge distillation (KD) tackles the challenge of adapting models trained on one data domain to perform effectively on another, distinct domain. This is crucial when labeled data is scarce in the target domain, making traditional training impractical. The core idea is to leverage a teacher model, already well-trained on the source domain, to guide the training of a student model on the target domain. Effective cross-domain KD methods carefully manage the transfer of knowledge, addressing the potential for negative transfer from domain-specific features. Key techniques include adversarial learning to align domain-invariant features and reinforcement learning to selectively choose the most informative target domain samples for distillation. The goal is a student model that is both accurate and efficient, ideally significantly smaller and faster than the teacher, making deployment on resource-constrained devices feasible. Successful approaches typically combine multiple techniques to address the complexities of domain shift and knowledge transfer, resulting in robust and adaptable models.
RL Sample Selection#
Reinforcement learning (RL) applied to sample selection in knowledge distillation offers a powerful mechanism for addressing the challenge of adapting a student model to a target domain with limited resources. Dynamic sample selection, guided by an RL agent, allows the system to prioritize transferring knowledge from the teacher only on the target samples that are most beneficial for the student’s learning, based on its current capacity. This approach contrasts with conventional methods that simply transfer all source domain knowledge, potentially leading to negative transfer. The RL agent learns a policy that balances exploration (trying different samples) and exploitation (selecting high-reward samples) to optimize the overall knowledge transfer. The design of the reward function is crucial, and it is typically tailored to reflect the student’s ability to learn from specific samples, thereby promoting efficient knowledge transfer and improved performance in the target domain. This adaptive approach tackles the network capacity gap, a common limitation in knowledge distillation, where a less powerful student might not be capable of absorbing the complete knowledge of a more powerful teacher. This framework promises improved efficiency and performance compared to conventional knowledge distillation techniques.
Student Optimization#
The heading ‘Student Optimization’ in a research paper likely details how a smaller, more efficient model (the student) learns from a larger, more complex model (the teacher). This process, often a core component of knowledge distillation, involves adapting the student’s parameters to effectively capture the teacher’s knowledge. Effective student optimization might involve carefully selecting which data samples from the teacher are most beneficial for the student’s learning and could employ techniques like regularization, loss function design, or reinforcement learning to enhance the transfer process. Addressing the network capacity gap between teacher and student is crucial. A robust optimization strategy might dynamically adjust the learning process based on the student’s performance, ensuring efficient knowledge transfer and minimizing the risk of negative transfer. The specific methods used for student optimization depend greatly on the context of the paper, potentially including techniques such as adversarial training or regularization.
Empirical Results#
An ‘Empirical Results’ section in a research paper would ideally present a thorough evaluation of the proposed method. This would involve showcasing performance metrics on multiple datasets, comparing against established baselines, and conducting ablation studies to understand the contribution of individual components. Clear visualization of the results using tables and figures is crucial, ensuring easy comprehension of trends and significant differences. The discussion should go beyond simply stating the numbers; it should interpret the findings, explaining why certain results were obtained and providing insights into the strengths and weaknesses of the approach. Statistical significance should be assessed to confirm the reliability of reported improvements, ideally using appropriate tests and reporting p-values or confidence intervals. Furthermore, a detailed description of the experimental setup, including datasets, evaluation metrics, and hyperparameter tuning, is critical for reproducibility, ensuring others can replicate and verify the reported results. The analysis should also include discussions on the resource usage (computation time, memory) and potential limitations of the proposed method.
Future Works#
Future work could explore several promising avenues. Extending RCD-KD to handle more complex time series data, such as those with high dimensionality or non-Euclidean structures, would significantly broaden its applicability. Investigating alternative reward functions within the reinforcement learning framework could improve the efficiency and stability of target sample selection. Combining RCD-KD with other domain adaptation techniques, or exploring different teacher-student architectures, could lead to further performance gains. A thorough analysis of the model’s sensitivity to hyperparameters is also warranted, and developing automated methods for hyperparameter tuning would enhance its practical usability. Finally, applying RCD-KD to diverse real-world applications and evaluating its performance on large-scale datasets would demonstrate its robustness and generalizability.
More visual insights#
More on figures
This figure illustrates the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) framework. It shows how a Monte Carlo Dropout (MCD)-based reward module dynamically selects target samples for knowledge transfer to a student network, based on uncertainty consistency and transferability. A domain discriminator ensures domain-invariant knowledge transfer. The dueling DDQN is used to learn the optimal sample selection policy.
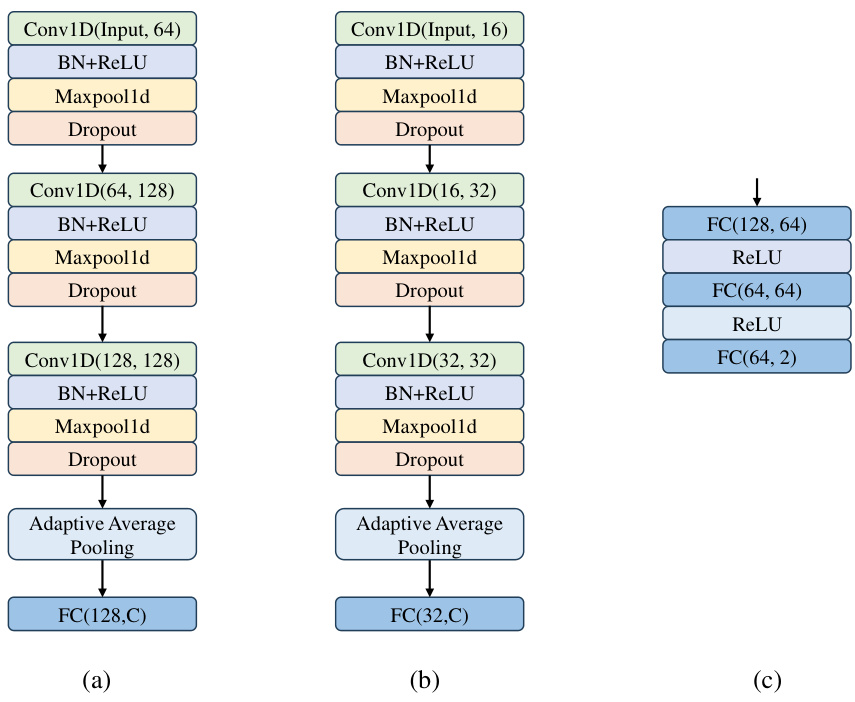
This figure illustrates the architecture of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) framework. It highlights the key components: a Monte Carlo Dropout (MCD) based reward module for optimal target sample selection, a dueling Double Deep Q-Network (DDQN) for learning the selection policy, and a domain discriminator for transferring domain-invariant knowledge. The reward function considers action, uncertainty consistency, and sample transferability.

This figure illustrates the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) framework. It shows the interaction between the teacher and student models, the reinforcement learning module for sample selection, and the domain discriminator used for domain adaptation. The reward function is based on uncertainty consistency and sample transferability.
More on tables

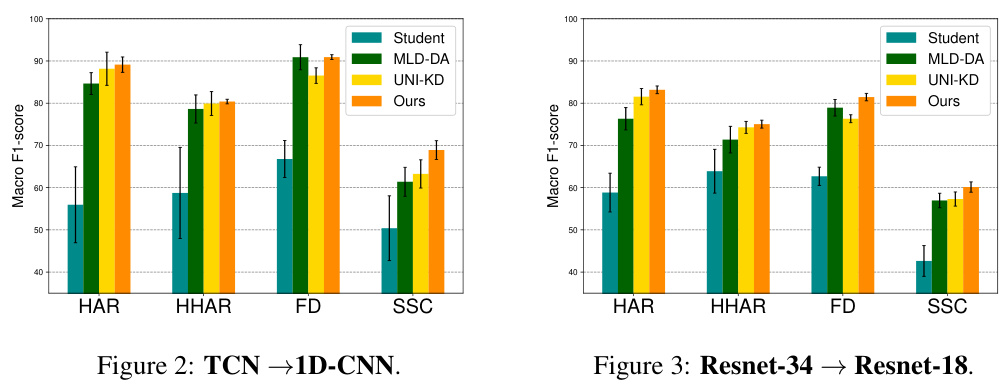
This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method with several state-of-the-art unsupervised domain adaptation (UDA) methods on four different time series datasets (HAR, HHAR, FD, and SSC). The performance metric used is macro F1-score. It shows the performance of a student model trained with only source data (‘Student-Only’), various metric-based UDA methods (HoMM, MDDA, SASA), various adversarial-based UDA methods (DANN, CoDATS, AdvSKM), and the proposed RCD-KD method. The results demonstrate the effectiveness of RCD-KD compared to other UDA methods in improving the performance of a compact student model on the target domain.
This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method against several state-of-the-art unsupervised domain adaptation (UDA) methods. The comparison is done using four metrics across four different datasets (HAR, HHAR, FD, SSC). Each dataset represents a different time series task. The ‘Student-Only’ column shows the performance of a simple student model trained only on the source domain, providing a baseline. The table highlights the superior performance of RCD-KD, which consistently outperforms the other methods across various datasets and tasks.
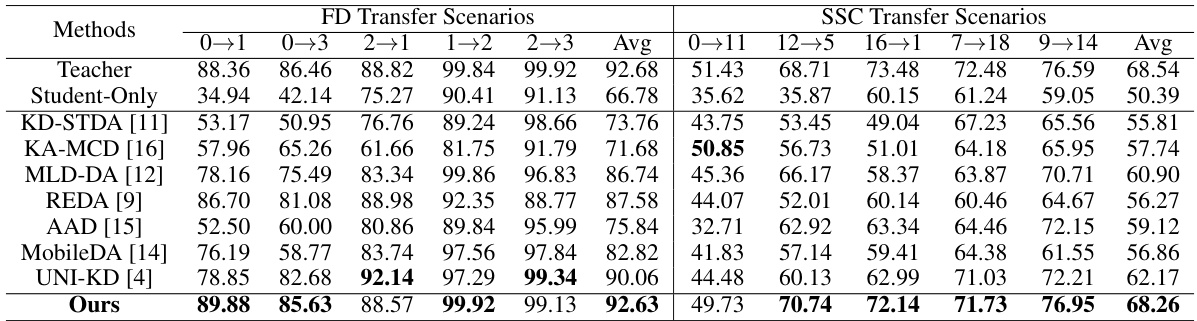
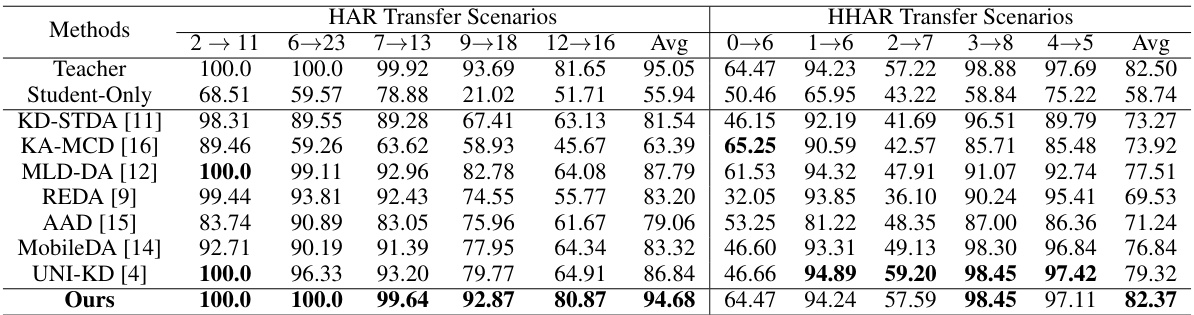
This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method with several state-of-the-art unsupervised domain adaptation (UDA) methods across four different datasets (HAR, HHAR, FD, SSC) and multiple transfer scenarios. Each dataset represents a specific time-series task, and the transfer scenarios involve adapting a model trained on one subset of the data to perform well on a different, unseen subset. The table shows the macro F1-score for each method, providing a comprehensive comparison of their effectiveness in handling domain shift in time-series data. The ‘Student-Only’ row indicates the performance of a model trained only on the source domain without any domain adaptation.

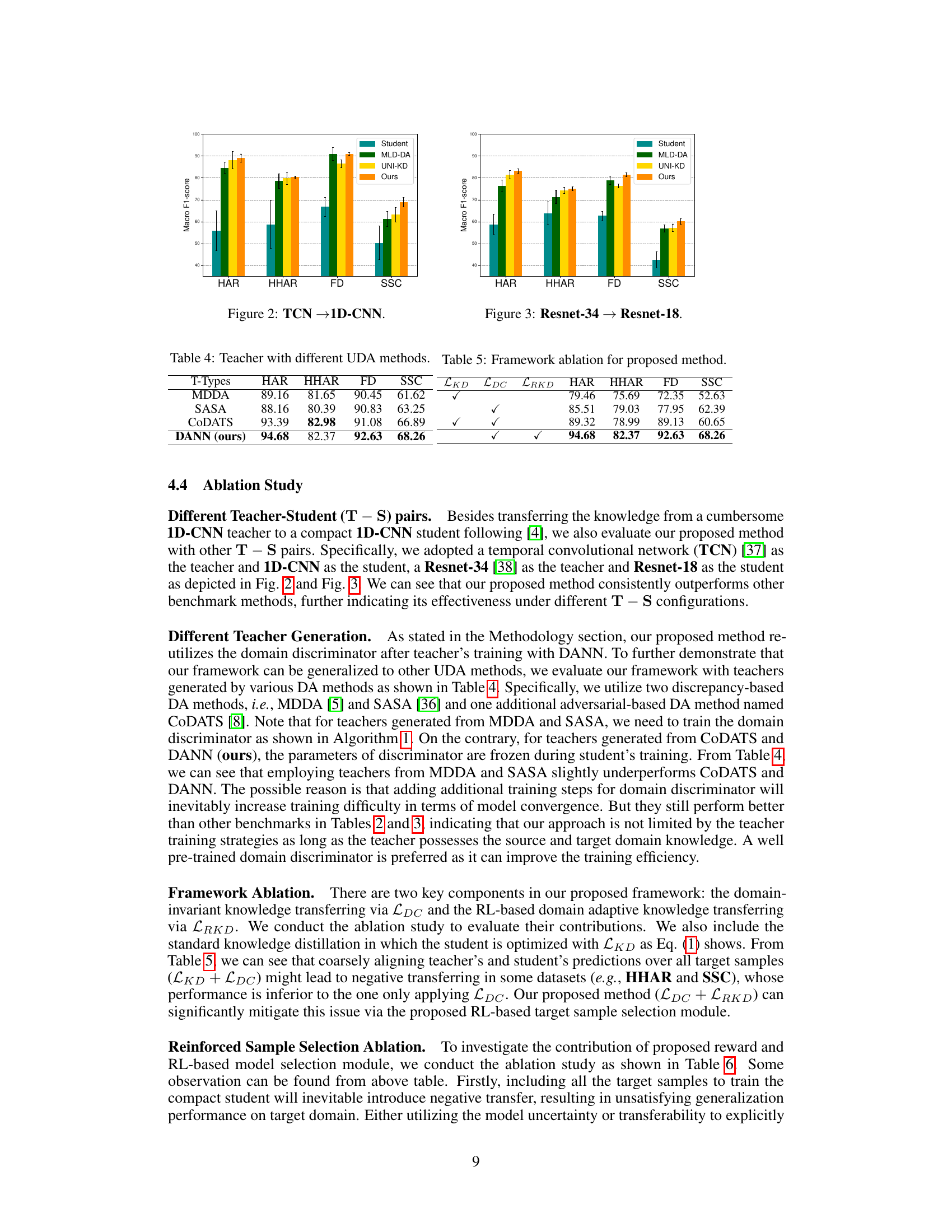
This table presents the performance comparison of using different Unsupervised Domain Adaptation (UDA) methods for pre-training the teacher model. The goal is to analyze how the choice of UDA method for teacher training affects the final performance of the student model in the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) framework. Different UDA methods used for teacher training are compared: MDDA, SASA, CODATS, and DANN. The table shows the macro F1 scores achieved by the student model after knowledge distillation, for the HAR, HHAR, FD, and SSC datasets. The table also includes ablation study results showing the effect of removing knowledge distillation loss, domain confusion loss, and reinforced cross-domain knowledge distillation loss from the proposed method.
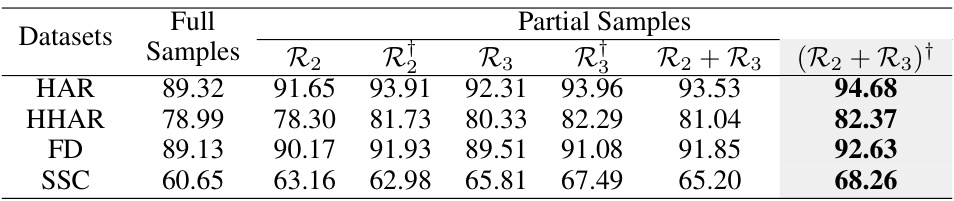
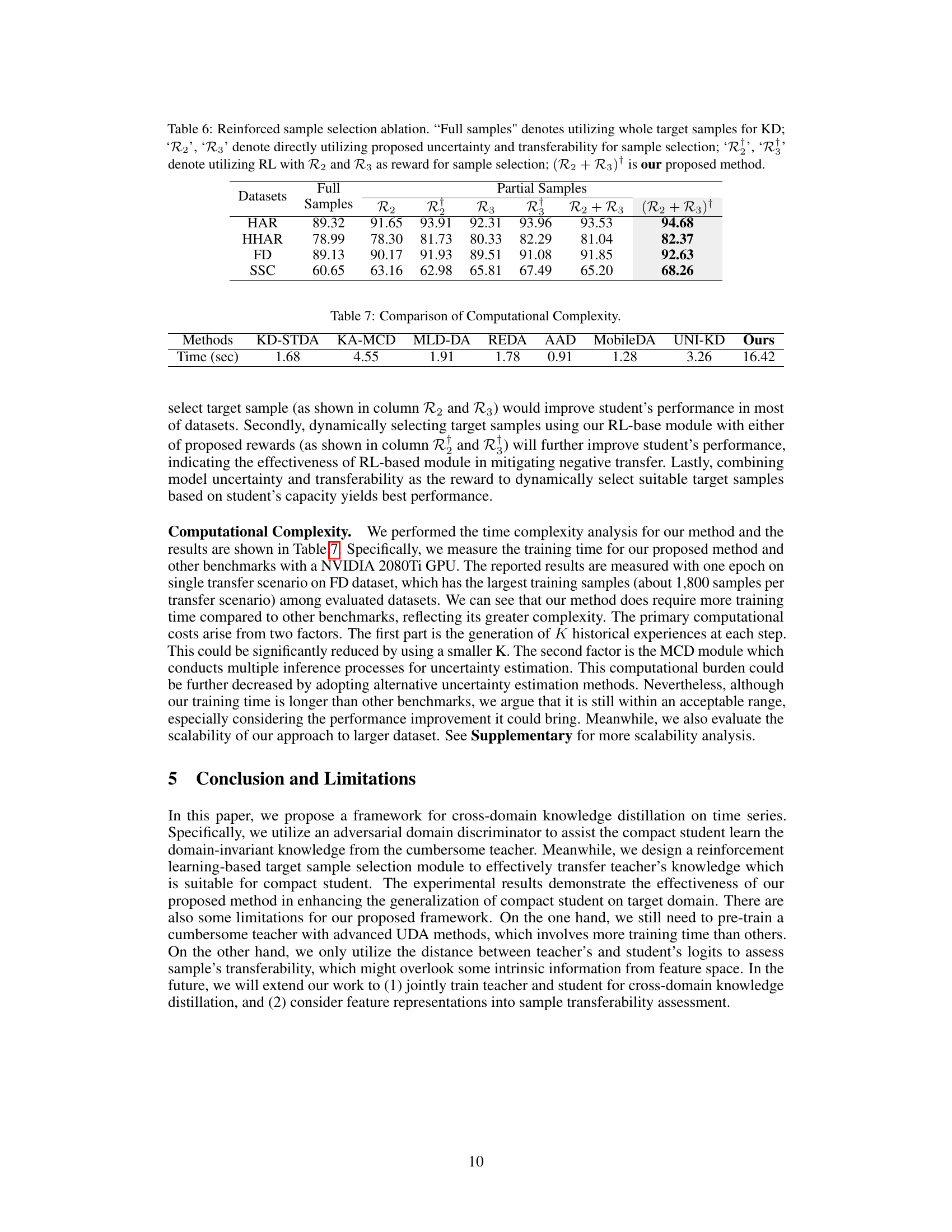
This table presents the ablation study on the proposed reward function and RL-based sample selection module. It compares the performance of using all target samples for knowledge distillation (Full Samples) against using only a subset selected based on different criteria: uncertainty (R2), transferability (R3), and reinforcement learning based on these criteria (R1, R1, (R2+R3)†). The results show the impact of each component and highlight the superior performance of the complete method, (R2+R3)†.

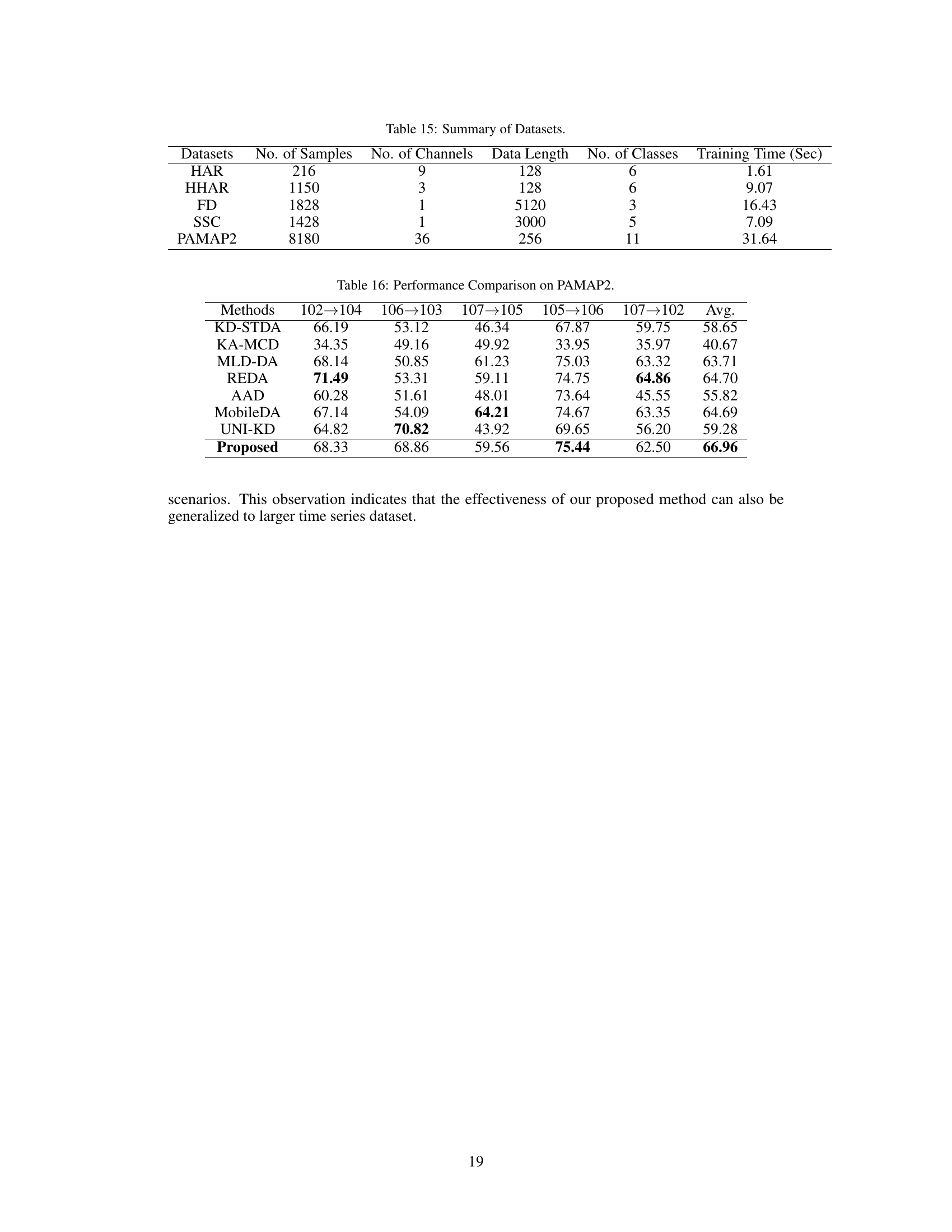
This table compares the training time (in seconds) required by different domain adaptation methods, including KD-STDA, KA-MCD, MLD-DA, REDA, AAD, MobileDA, UNI-KD, and the proposed RCD-KD method. The training time is a measure of computational complexity, showing how long each method takes to train a model. The results indicate that the proposed RCD-KD method has significantly higher computational cost compared to other methods.

This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method with other state-of-the-art unsupervised domain adaptation (UDA) methods on four different datasets (HAR, HHAR, FD, SSC). The results are presented as the average macro F1-score across three independent runs for each dataset and various transfer scenarios. The ‘Student-Only’ column shows the performance of a compact student model trained only on the source domain, without any domain adaptation. The table allows for a comparison of the effectiveness of RCD-KD against existing methods in terms of improving the performance of a compact student model on the target domain.

This table compares the performance of the proposed RCD-KD method with other state-of-the-art unsupervised domain adaptation (UDA) methods on four benchmark datasets (HAR, HHAR, FD, SSC). Each dataset represents a different time series task, and the table shows the performance of different methods on various transfer scenarios (different source and target domains). The ‘Student-Only’ column represents the performance of a student model trained only on the source domain, illustrating the baseline performance and how well the UDA methods can improve the performance of the compact student model. The table highlights that the proposed RCD-KD consistently outperforms other UDA methods on various datasets and transfer scenarios.

This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method with other state-of-the-art Unsupervised Domain Adaptation (UDA) methods on four different time series datasets. It shows the macro F1-score achieved by each method across three independent runs. The datasets include Human Activity Recognition (HAR), Heterogeneity HAR (HHAR), Rolling Bearing Fault Diagnosis (FD), and Sleep Stage Classification (SSC). The table highlights the superior performance of RCD-KD in most scenarios, especially when considering the variability of the results across different datasets and transfer scenarios.
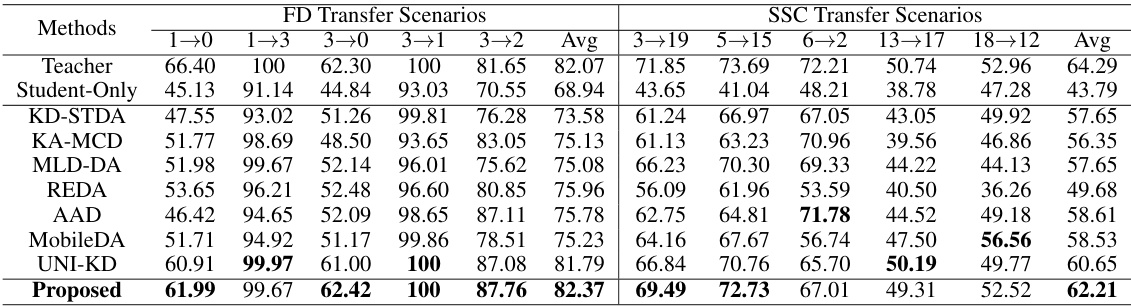
This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method with other state-of-the-art unsupervised domain adaptation (UDA) methods on four benchmark datasets (HAR, HHAR, FD, SSC) across three independent runs. The results show macro F1-scores for each method and highlight the superior performance of RCD-KD. It demonstrates that the RCD-KD method is consistently effective and outperforms other UDA approaches in most transfer scenarios.

This table presents the sensitivity analysis performed on the hyperparameters α₁ and α₂, which are used in the reward function of the reinforcement learning module for target sample selection. The table shows the Macro F1-scores achieved on four different datasets (HAR, HHAR, FD, and SSC) for various combinations of α₁ and α₂ values. The results help determine the optimal balance between the uncertainty consistency and sample transferability rewards in the reward function.

This table presents the sensitivity analysis result for the hyperparameter τ (temperature) in the proposed RCD-KD method. It shows the macro F1 scores achieved on four different time series datasets (HAR, HHAR, FD, SSC) when varying the value of τ from 1 to 16. The results indicate the optimal range for τ, showing how the model’s performance changes with different temperature values.

This table compares the performance of the proposed method against various active learning sample selection strategies, namely Least Confidence (LC), Sample Margin (M), and Sample Entropy (H). It shows the macro F1-score achieved on four different datasets (HAR, HHAR, FD, and SSC) for each strategy, both with and without the incorporation of uncertainty consistency and Reinforcement Learning (RL). The baseline represents the performance without any active learning sample selection.

This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method with several other unsupervised domain adaptation (UDA) methods on four different datasets (HAR, HHAR, FD, SSC). The ‘Student-Only’ column represents the performance of a student model trained only on the source domain without any domain adaptation. The other columns show the performance of various UDA methods and RCD-KD. The results are evaluated using the Macro F1-score metric.

This table compares the performance of the proposed Reinforced Cross-Domain Knowledge Distillation (RCD-KD) method against several state-of-the-art unsupervised domain adaptation (UDA) methods. The comparison is performed across four different datasets (HAR, HHAR, FD, SSC), each representing a distinct time series task. The table shows the macro F1-score achieved by each method, with the ‘Student-Only’ column representing the performance of a compact student model trained only on source data without any domain adaptation. The results illustrate the effectiveness of the RCD-KD approach in improving the performance of a resource-efficient student model across various time series domains.
Full paper#