↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current subject-driven text-to-image generation models often struggle to produce images that accurately reflect both textual prompts and reference images, requiring expensive setups and extensive training. They also suffer from overfitting. This research tackles these issues.
The paper proposes a novel A-Harmonic reward function that provides a reliable reward signal, enabling early stopping and faster training. By combining this with a Bradley-Terry preference model, it introduces a new method called Reward Preference Optimization (RPO). RPO simplifies the training process, requiring significantly fewer negative samples and gradient steps compared to existing approaches. Experiments show that RPO achieves state-of-the-art results on DreamBench, demonstrating its effectiveness and efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to subject-driven text-to-image generation that addresses limitations of existing methods. It offers a faster, more efficient training process, requiring fewer resources and achieving state-of-the-art results. This opens up new avenues for subject-driven image generation research and has implications for various applications.
Visual Insights#
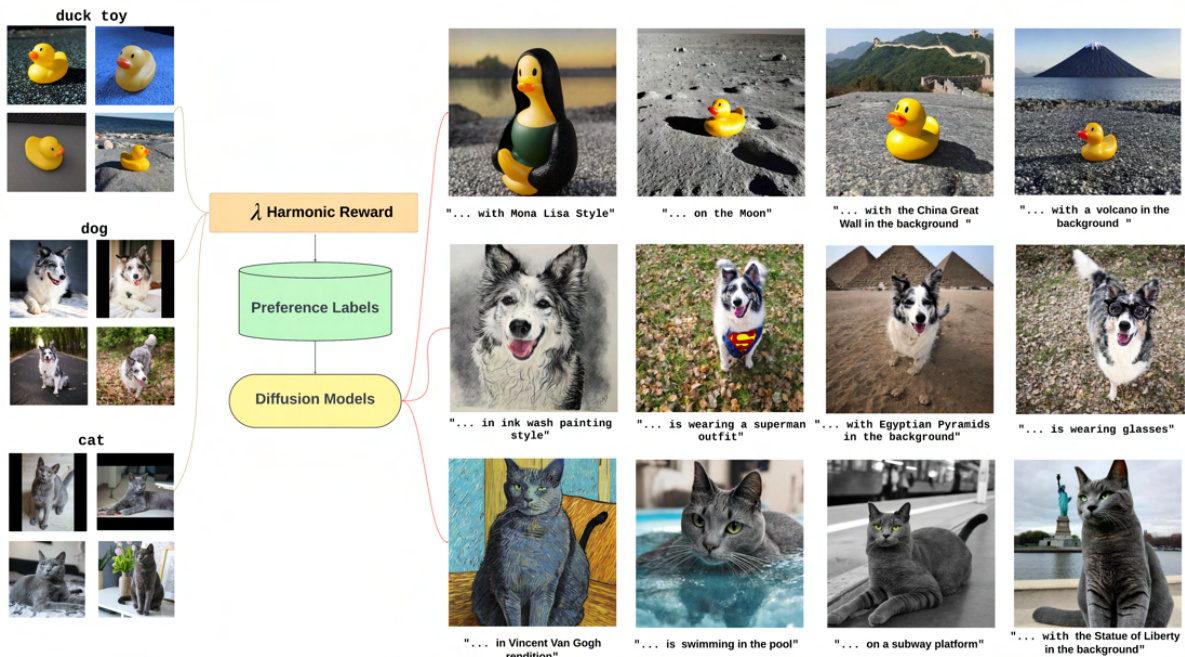
This figure demonstrates the λ-Harmonic reward function used in subject-driven text-to-image generation. It shows how preference labels, generated using the λ-Harmonic function and a few reference images, guide the generation of new images. The generated images maintain the identity of the subject from the reference image while incorporating the details described in the accompanying text prompt. This illustrates the effectiveness of the method for producing images that are both faithful to the original subject and consistent with the text prompt.
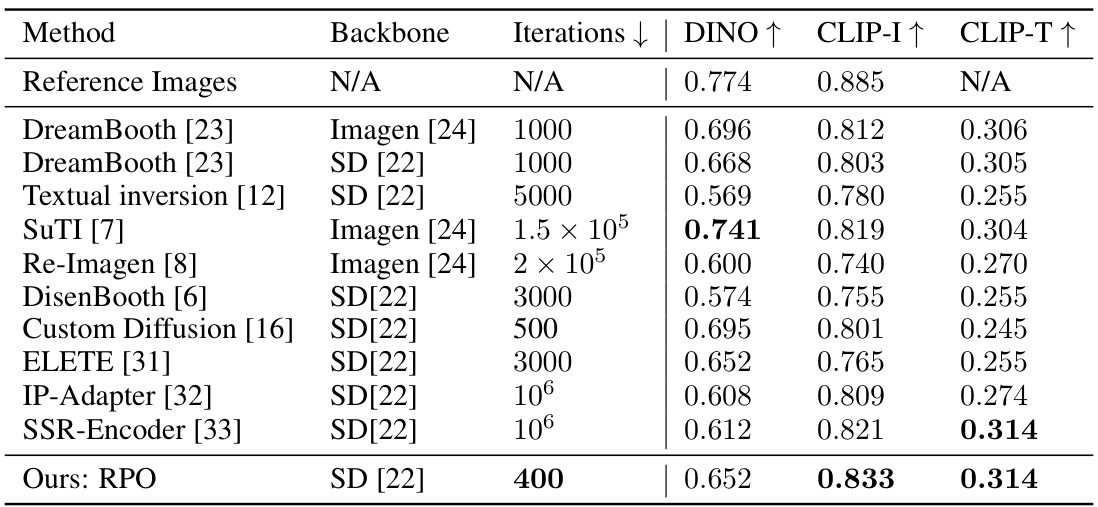
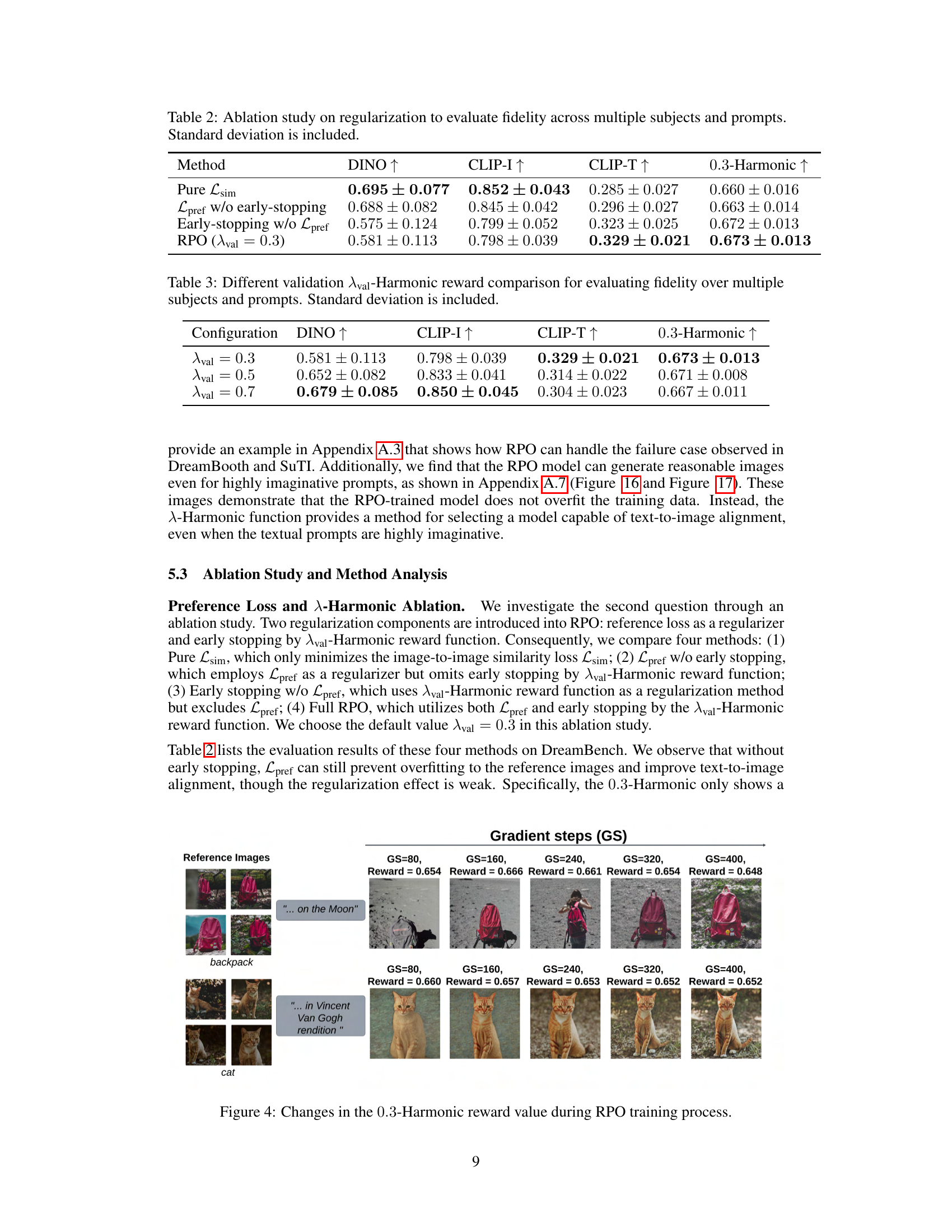
This table compares the performance of several subject-driven text-to-image generation methods on the DreamBench dataset. The metrics used are DINO (image-to-image similarity), CLIP-I (image-to-text alignment), and CLIP-T (text-to-image alignment). The table shows the number of iterations required for training each model, along with the scores achieved on each metric. It highlights that the proposed RPO method achieves state-of-the-art results using fewer training steps and less computational resources than existing methods.
In-depth insights#
A-Harmonic Reward#
The A-Harmonic reward function is a crucial innovation designed to address overfitting and accelerate training in subject-driven text-to-image generation. It leverages the harmonic mean of ALIGN-I (image alignment) and ALIGN-T (text alignment) scores, offering a more robust and reliable reward signal than the arithmetic mean. This is particularly beneficial because the harmonic mean is more sensitive to lower scores, thus penalizing models that are either unfaithful to reference images or misaligned with textual prompts. The function enables early stopping, which significantly reduces training time and computational costs, as the model’s performance is effectively monitored based on the A-Harmonic reward. By combining it with a Bradley-Terry preference model, it provides efficient preference labels for subject-driven generation, streamlining the training process. This combination represents a significant advancement over existing methods, which often require expensive setups and extensive training to achieve comparable results. The A-Harmonic reward is a key element contributing to the overall efficiency and performance of the proposed Reward Preference Optimization (RPO) algorithm.
RPO Optimization#
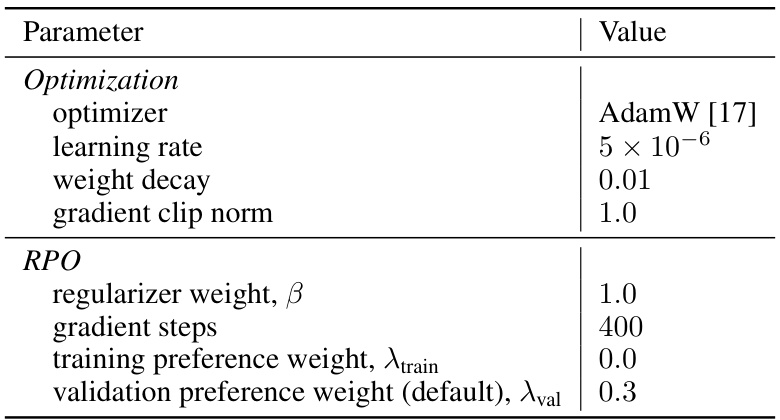
Reward Preference Optimization (RPO) presents a novel approach to subject-driven text-to-image generation. RPO leverages a novel A-Harmonic reward function which provides a reliable reward signal, enabling faster training and effective regularization by avoiding overfitting. This reward function is combined with a Bradley-Terry preference model to efficiently generate preference labels, simplifying the setup and reducing the need for extensive negative samples, a significant improvement over existing methods. The RPO framework’s simplicity is a major advantage, requiring only a small percentage of the negative samples used by comparable techniques like DreamBooth. This efficiency translates to faster training, achieving state-of-the-art results with a streamlined fine-tuning process that focuses on optimizing only the U-Net component, without the need for expensive text encoder optimization. RPO’s effective use of preference-based reinforcement learning and its innovative reward function makes it a significant contribution to the field, offering a practical and efficient solution to the challenging task of subject-driven image synthesis.
Subject-driven Gen#
Subject-driven generation in text-to-image synthesis presents a significant challenge, demanding the ability to control the generation process to incorporate specific subjects from reference images while adhering to textual descriptions. This task is difficult because it requires fine-grained control over the model’s representation of the subject and its interaction with the background and textual cues. DreamBooth and Subject-driven Text-to-Image (SuTI) represent pioneering work in this area, but often suffer from high computational costs, reliance on large datasets, or overfitting to training data. A key innovation is the development of efficient reward functions and preference-based training methods. By leveraging a carefully designed reward function that incorporates both image similarity and textual consistency, the training process can be accelerated, leading to improved model selection and reduced overfitting. The adoption of preference-based learning helps streamline the optimization process, reducing the need for extensive negative sampling, a significant bottleneck in previous approaches. This focus on efficiency and refinement addresses the limitations of prior methods and paves the way for more scalable and effective subject-driven generation models. The emphasis on reliable reward signals and preference optimization distinguishes this work, allowing faster training and superior generation quality.
Early Stopping#
Early stopping is a crucial regularization technique in machine learning, especially relevant in scenarios prone to overfitting, such as subject-driven text-to-image generation. Its effectiveness stems from halting the training process before the model begins to memorize the training data, thereby improving generalization performance on unseen data. The optimal stopping point is often determined by a validation set’s performance, using metrics like CLIP score. In subject-driven generation, early stopping is particularly beneficial because models tend to overfit to the reference images. By using a robust reward function that effectively captures similarity to the reference image and fidelity to the textual prompt, and applying preference-based reinforcement learning, early stopping facilitates quicker and more efficient training while preventing overfitting. The A-Harmonic reward function, for instance, guides early stopping, providing a more reliable reward signal than traditional approaches and enabling more efficient model selection. This technique significantly reduces the computational cost associated with training complex generative models and enhances the model’s ability to create realistic and relevant outputs. This allows for faster experimentation and more scalable subject-driven image generation.
Future Work#
The paper’s ‘Future Work’ section suggests several promising avenues. Improving regularization and mitigating overfitting are key concerns, potentially through online reinforcement learning techniques. Exploring the LoRA (Low-Rank Adaptation) approach for enhancing efficiency is another direction, alongside a comparison with LoRA DreamBooth. Finally, there is a strong need for a larger, more diverse, open-source dataset for subject-driven generation tasks, which would allow for more robust evaluation and benchmarking of different models. These suggestions collectively point to a focus on improving model performance, scalability, and the reliability of the evaluation metrics.
More visual insights#
More on figures
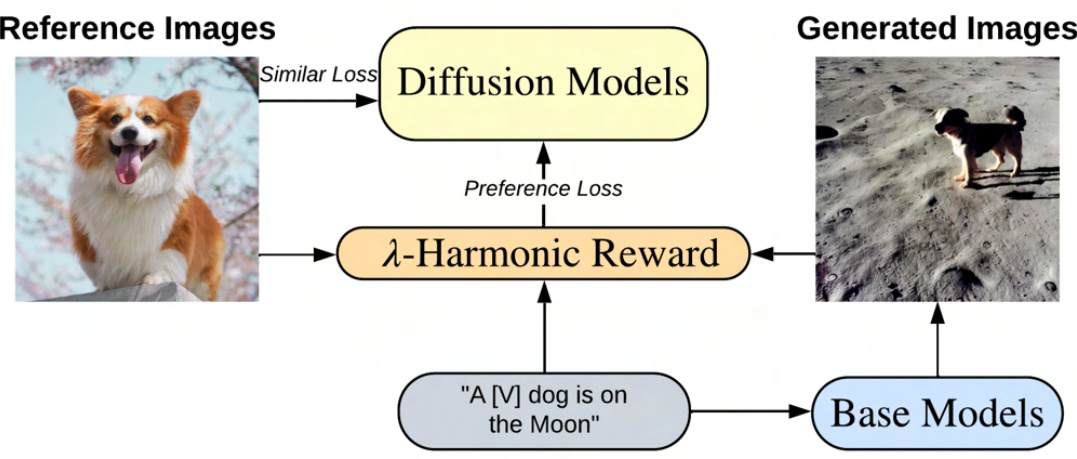
This figure illustrates the training phase of the Reward Preference Optimization (RPO) method. It shows how the base diffusion model generates images using new training prompts. The λ-Harmonic reward function then calculates rewards for both the generated and reference images. These rewards are used with the Bradley-Terry model to sample preference labels. Finally, the diffusion model is fine-tuned by minimizing both similarity and preference losses.

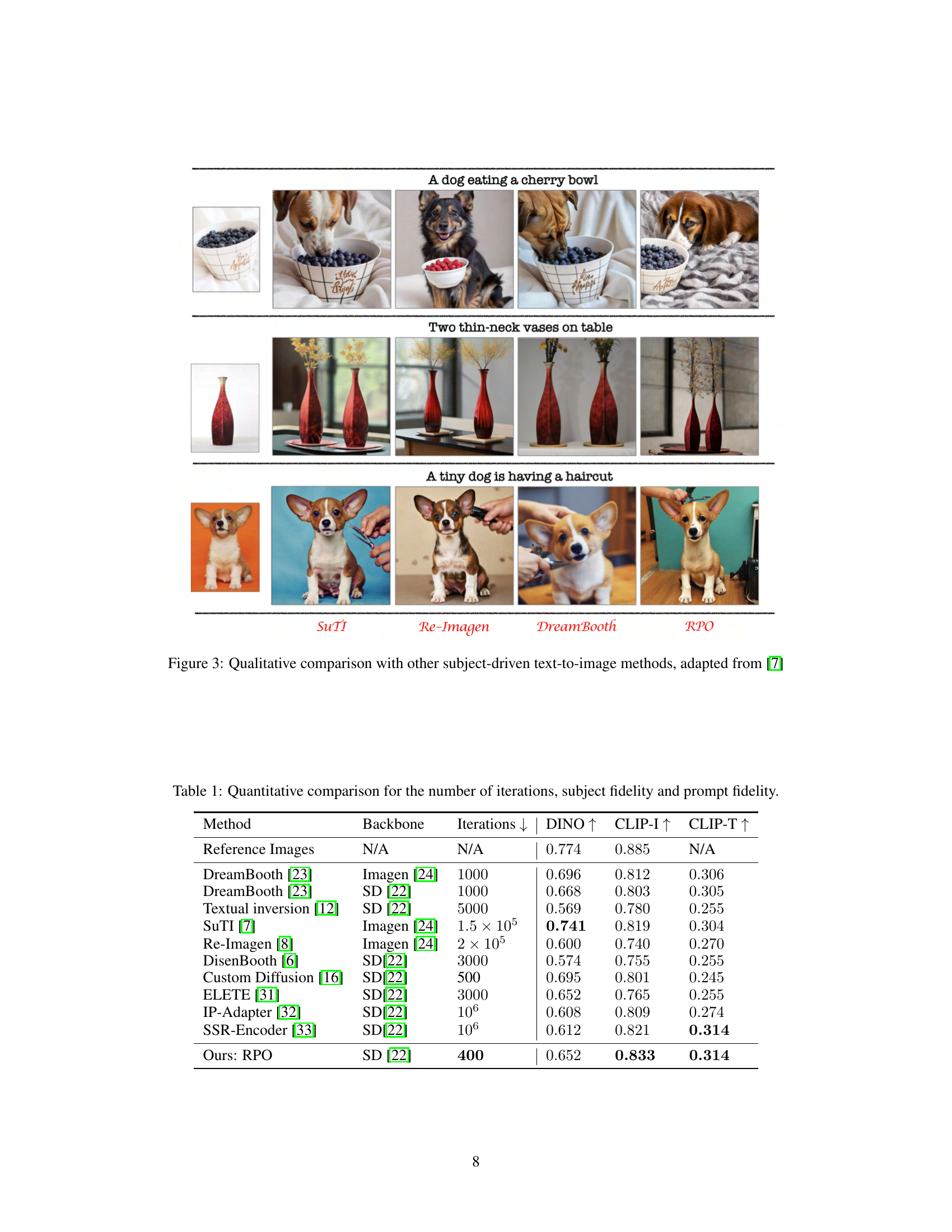
This figure compares the image generation results of four different methods: SuTI, Re-Imagen, DreamBooth, and the proposed RPO method. The methods are applied to three separate subject-driven image generation tasks. For each task, example reference images are displayed and followed by the generated images for each of the four methods. The purpose of the figure is to qualitatively showcase the comparative performance of RPO against state-of-the-art methods in terms of subject fidelity, text prompt adherence, and overall image quality. The results suggest that RPO produces images that are more faithful to both the reference images and text prompts than other methods, especially when dealing with more challenging prompt variations.

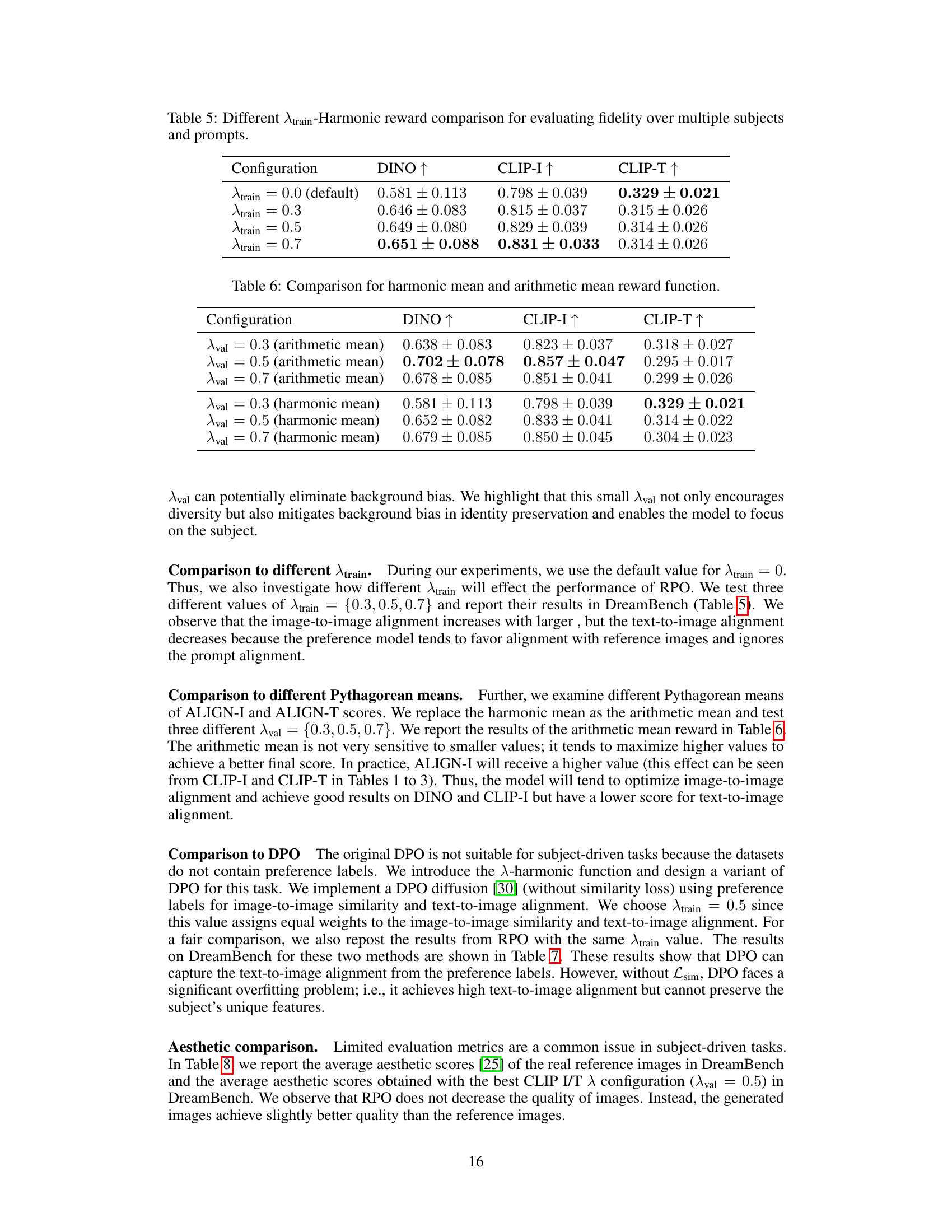
This figure shows how the λ-Harmonic reward changes during the training process for two different subjects (backpack and cat). Each row represents a subject and displays the generated images and the corresponding λ-Harmonic reward at various gradient steps (GS) during fine-tuning. The goal is to illustrate how the reward function helps guide the training process and regularize against overfitting by monitoring the image quality and its alignment with textual prompts. The reward values indicate the model’s performance, with higher values suggesting better image quality and alignment. The figure demonstrates that the λ-Harmonic reward function provides informative feedback for early stopping, allowing for more efficient training.

This figure shows the impact of the λval hyperparameter on the generated images. λval controls the balance between faithfulness to the reference image and alignment with the text prompt. A lower λval prioritizes text alignment, resulting in more diverse outputs but potentially sacrificing image fidelity. Conversely, a higher λval prioritizes image similarity, leading to more consistent results but at the risk of overfitting to the reference image.

The figure shows two lists of prompts used for training the RPO model. The ‘Object prompts’ list contains prompts describing inanimate objects in various contexts and artistic styles. The ‘Live subject prompts’ list contains prompts about living subjects (presumably animals, based on the paper’s focus), again in varied settings and styles. These prompts are designed to test the model’s ability to generate images that accurately reflect both the subject and the described scene, focusing on subject identity and contextualization. The use of placeholders like {unique_token} and {subject_token} suggests a systematic approach to generating many training examples with varied descriptions for each object/subject.

This figure compares the qualitative results of several subject-driven text-to-image generation methods, including DreamBooth, SuTI, Dream-SuTI, and the proposed RPO method. For three different prompts and associated reference images, the generated images show how each model handles the tasks of preserving the subject’s identity and aligning with the textual descriptions. The comparison highlights the strengths and weaknesses of each method in terms of faithfulness to the reference image and adherence to the text prompt.

This figure shows the impact of the λval hyperparameter on the generated images. Three different λval values (0.3, 0.5, and 0.7) are tested. Lower λval values emphasize text-to-image alignment, resulting in more diverse generations. Conversely, higher λval values prioritize image-to-image similarity, which can cause overfitting and reduce diversity.

This figure shows three failure cases of the Reward Preference Optimization (RPO) model. The first case demonstrates context-appearance entanglement, where the generated image is influenced by both the context and the appearance of the subject, resulting in an unrealistic combination. The second case illustrates incorrect contextual integration, where the model fails to accurately incorporate the contextual information into the generated image, leading to an inaccurate representation. The third case shows overfitting, where the model overfits to the training data, resulting in generated images that closely resemble the training images but lack generalization to unseen prompts.

This figure shows three examples of failure cases of the Reward Preference Optimization (RPO) model. The first failure mode demonstrates the entanglement between the context and the appearance of the subject, where the context influences the subject’s appearance rather than only the background. The second failure mode illustrates the model’s failure to generate an image that aligns with the given prompt. The third failure mode shows that the model is still overfitting to the training set.

This figure shows example results of subject-driven text-to-image generation using the proposed A-Harmonic reward function. It demonstrates the ability of the method to generate images that are consistent with both a given text prompt and a set of reference images. The top row showcases images generated for the text prompt “duck toy” using various styles and contexts. The bottom row displays similar results for the text prompt “dog” with diverse background settings.

The figure shows examples of subject-driven text-to-image generation using the A-Harmonic reward function. It demonstrates how the proposed method uses a few reference images and preference labels to generate new images that are both consistent with the reference images and accurately reflect the text prompt. For instance, images of a dog are generated in various artistic styles and settings, successfully integrating both the textual description and visual characteristics of the reference images.

This figure shows the results of applying the Reward Preference Optimization (RPO) algorithm to modify the expressions of a subject in generated images. The algorithm takes a set of reference images showing the subject with different expressions and uses them to generate new images with novel expressions (depressed, joyous, sleepy, screaming) that were not present in the training data. The results demonstrate RPO’s ability to generate diverse and faithful images with unseen expressions.

This figure shows several images generated by the Reward Preference Optimization (RPO) algorithm. Each image depicts a chow chow dog wearing different outfits (chef, nurse, police, Superman, witch, Ironman, angel wings, firefighter). The caption highlights that RPO successfully maintains the dog’s breed and hair color characteristics while realistically integrating it with the various outfits. This demonstrates RPO’s ability to control subject identity while adhering to textual prompts.

The figure shows examples of subject-driven text-to-image generation using the λ-Harmonic reward function. The top row shows images of duck toys generated with various styles and locations described in text prompts. The bottom row shows images of a dog in different settings, again based on text prompts and a reference image. The A-Harmonic reward function helps the model select for images that are both faithful to the reference image and consistent with the textual description.

This figure shows the results of using the Reward Preference Optimization (RPO) algorithm to generate images of a cat from multiple viewpoints. The prompts used specified the desired view (top, bottom, back, side), and the algorithm successfully generated images that accurately reflect those views while maintaining the identity of the cat.

This figure shows examples of novel hybrid animal synthesis generated by the RPO algorithm. The algorithm successfully combined the features of a Chow Chow with those of other animals (bear, koala, lion, panda) while maintaining the core identity of the Chow Chow. This demonstrates the algorithm’s ability to generate novel and imaginative variations of subjects.

This figure shows examples of images generated using the A-Harmonic reward function for subject-driven text-to-image generation. The top row shows images generated from a textual prompt about duck toys, demonstrating the model’s ability to maintain fidelity to both the text prompt and provided reference image. The bottom row shows similar results for images of a dog, highlighting the algorithm’s capacity to create novel scenes while preserving subject identity.
More on tables

This table presents the results of an ablation study conducted to evaluate the impact of different components of the proposed Reward Preference Optimization (RPO) method on the fidelity of subject-driven text-to-image generation. The study compares four different configurations: 1. Pure Lsim: Only the similarity loss is minimized. 2. Lpref w/o early-stopping: The preference loss is included, but early stopping based on the λ-Harmonic reward is not used. 3. Early-stopping w/o Lpref: Early stopping is used, but the preference loss is excluded. 4. RPO (λval = 0.3): Both the preference loss and early stopping are used with a validation λ-Harmonic reward of 0.3. The table reports the mean and standard deviation of DINO, CLIP-I, CLIP-T, and λ-Harmonic scores across multiple subjects and prompts for each configuration. The results show the effectiveness of combining both the preference loss and early stopping in achieving high-quality image generation.

This table shows the results of an ablation study comparing different values of λval (a hyperparameter in the λ-Harmonic reward function) on the performance of the RPO model. It evaluates the model’s fidelity across multiple subjects and prompts using DINO, CLIP-I, CLIP-T, and λval-Harmonic scores, providing standard deviations for each metric. The study demonstrates how the choice of λval affects the balance between model regularization and performance.
This table compares several subject-driven text-to-image generation methods (DreamBooth, SuTI, Textual Inversion, Re-Imagen, DisenBooth, Custom Diffusion, ELITE, IP-Adapter, SSR-Encoder, and RPO) across three metrics: DINO (image-to-image similarity), CLIP-I (image-to-text similarity), and CLIP-T (text-to-image similarity). It also indicates the number of iterations required for training each method and the backbone model used.

This table presents the results of an ablation study on the effect of different λtrain values on the performance of the proposed RPO method. λtrain is a hyperparameter controlling the weight of the harmonic mean reward function, influencing the balance between image and text similarity. The table shows the DINO, CLIP-I, and CLIP-T scores for several λtrain values (0.0, 0.3, 0.5, 0.7), demonstrating how changing the λtrain value affects the model’s ability to generate images that are faithful to both the reference images and textual prompts. The results indicate that a λtrain value of 0.7 achieves the best CLIP-I score, suggesting that a stronger emphasis on text-image alignment improves performance on DreamBench.

This table compares the performance of the A-Harmonic reward function using both harmonic and arithmetic means for different Aval values (0.3, 0.5, and 0.7). The results are evaluated across multiple subjects and prompts using DINO, CLIP-I, and CLIP-T scores. The harmonic mean is shown to be more robust and less susceptible to assigning high rewards due to high scores on only one of the two metrics (ALIGN-I and ALIGN-T).
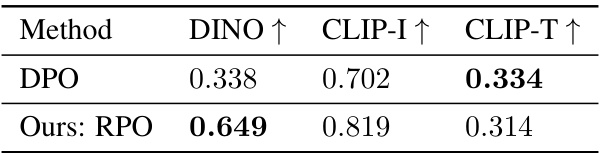
This table compares different methods for subject-driven text-to-image generation on the DreamBench dataset. It shows the number of iterations each method required during training, as well as the performance of each method in terms of DINO (image-to-image similarity), CLIP-I (image-to-text similarity), and CLIP-T (text-to-image similarity). The table highlights that the proposed RPO method achieves comparable or superior results to existing state-of-the-art methods, while requiring significantly fewer resources.

This table presents a quantitative comparison of different subject-driven text-to-image generation methods on the DreamBench dataset. It compares RPO against several baselines, including DreamBooth and SuTI, across three metrics: DINO (image-to-image similarity), CLIP-I (image-to-image similarity), and CLIP-T (text-to-image similarity). For each method, it indicates the backbone model used, the number of iterations (or training steps) performed, and the resulting scores for each metric. The table highlights RPO’s performance relative to existing state-of-the-art methods, showcasing its efficiency and effectiveness in subject-driven image generation.
Full paper#