↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Audio-Visual Question Answering (AVQA) systems struggle with overfitting to dataset biases, leading to poor generalization. Current AVQA datasets lack precise diagnostics for these biases. This paper tackles this problem by introducing several key improvements.
The researchers created MUSIC-AVQA-R, a new dataset designed to comprehensively evaluate model robustness. This was achieved through two steps: rephrasing questions and introducing distribution shifts. This allows for evaluation across rare and frequent question types, providing a more thorough assessment of model performance. The paper also proposes a new AVQA architecture with a multifaceted cycle collaborative debiasing strategy to mitigate bias learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of dataset bias in audio-visual question answering (AVQA). By introducing a new, robust dataset (MUSIC-AVQA-R) and a novel debiasing method, it significantly advances the field’s understanding and pushes the boundaries of model robustness. The findings are highly relevant to current research in multi-modal learning and bias mitigation, opening doors for more reliable and generalizable AVQA systems.
Visual Insights#

This figure shows that current AVQA datasets use a limited set of predefined question templates. This can lead to models overfitting to these templates and not generalizing well to real-world scenarios. The example shows that two questions that differ only by one word (“ukulele” vs. “flute”) produce different answers from the STG method, while the proposed “Ours” method handles both correctly, highlighting the issue of bias learning in existing AVQA approaches.
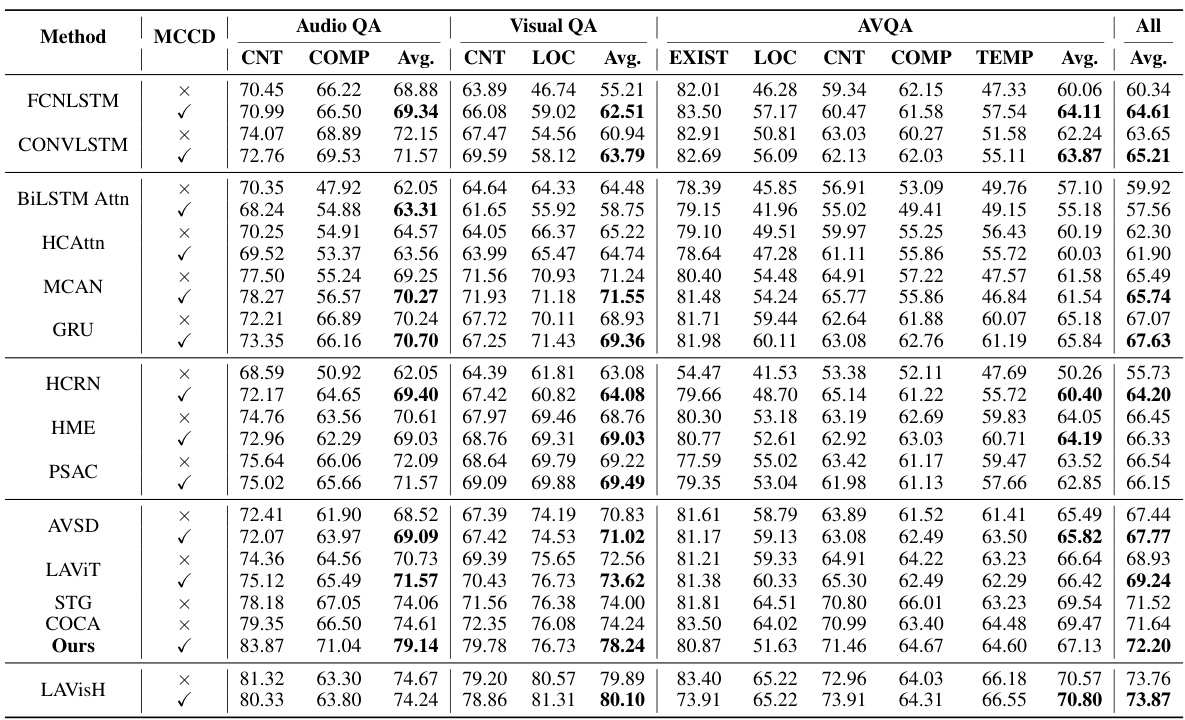
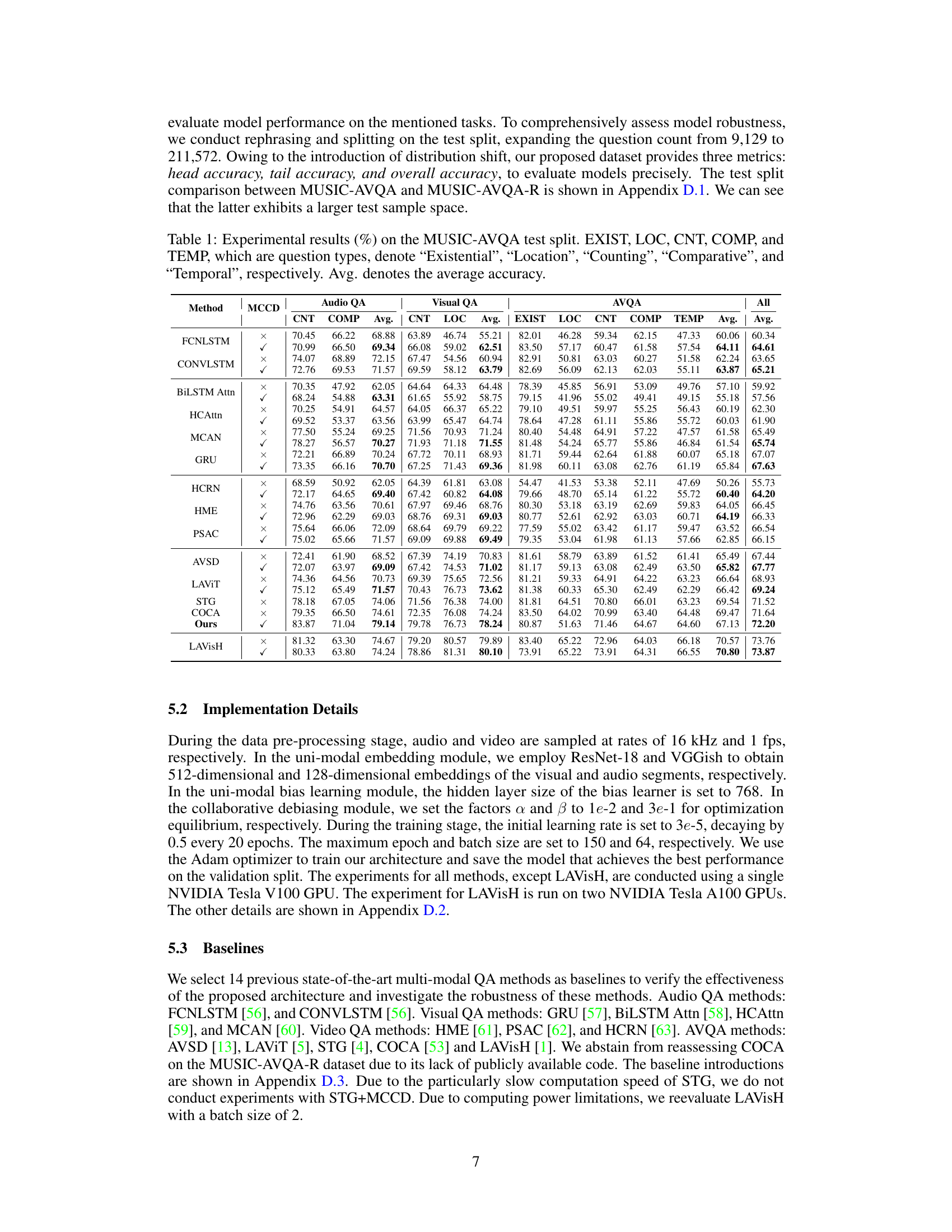
This table presents the experimental results of various methods on the MUSIC-AVQA test dataset. It breaks down the performance by question type (Existential, Location, Counting, Comparative, Temporal) and provides an average accuracy across all question types. The table allows for a comparison of different methods’ abilities to answer questions based on audio and visual information.
In-depth insights#
AVQA Dataset Bias#
Audio-Visual Question Answering (AVQA) datasets suffer from inherent biases, significantly impacting model performance and generalizability. Dataset biases arise from several sources, including limited question templates, skewed answer distributions (long-tailed distributions), and overrepresentation of certain visual or audio characteristics. These biases lead to models that overfit to the training data and perform poorly on unseen data, hindering the development of truly robust AVQA systems. Addressing AVQA dataset bias is crucial for advancing the field. Strategies for mitigation involve developing more diverse and balanced datasets using more realistic question generation techniques and diverse audio-visual scenarios. Careful evaluation metrics that account for various biases and in/out-of-distribution performance are necessary. Furthermore, robust model training methodologies should focus on reducing overfitting and improving model generalization, thereby leading to more reliable and effective AVQA systems.
MCCD Debiasing#
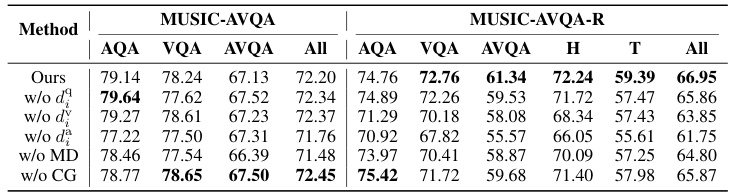
The proposed Multifaceted Cycle Collaborative Debiasing (MCCD) strategy is a novel approach to address bias in audio-visual question answering (AVQA) models. It tackles the problem from multiple angles: first, by learning separate uni-modal biases for audio, video, and text, thereby isolating potential sources of skewed performance. Then, it actively promotes the dissimilarity between the uni-modal biases and a combined multi-modal representation. This encourages the model to rely less on individual, potentially biased, modalities and more on the integrated understanding of all inputs. Further, a cycle guidance mechanism ensures consistency across the uni-modal representations, preventing overcorrection or the creation of new biases. The plug-and-play nature of MCCD is a significant advantage, as it can be easily integrated with existing AVQA architectures to improve their robustness and accuracy. The experimental results demonstrate its effectiveness in enhancing the generalization capabilities of AVQA models, particularly on challenging, out-of-distribution data, thus highlighting MCCD as a promising solution for creating more reliable and robust AVQA systems.
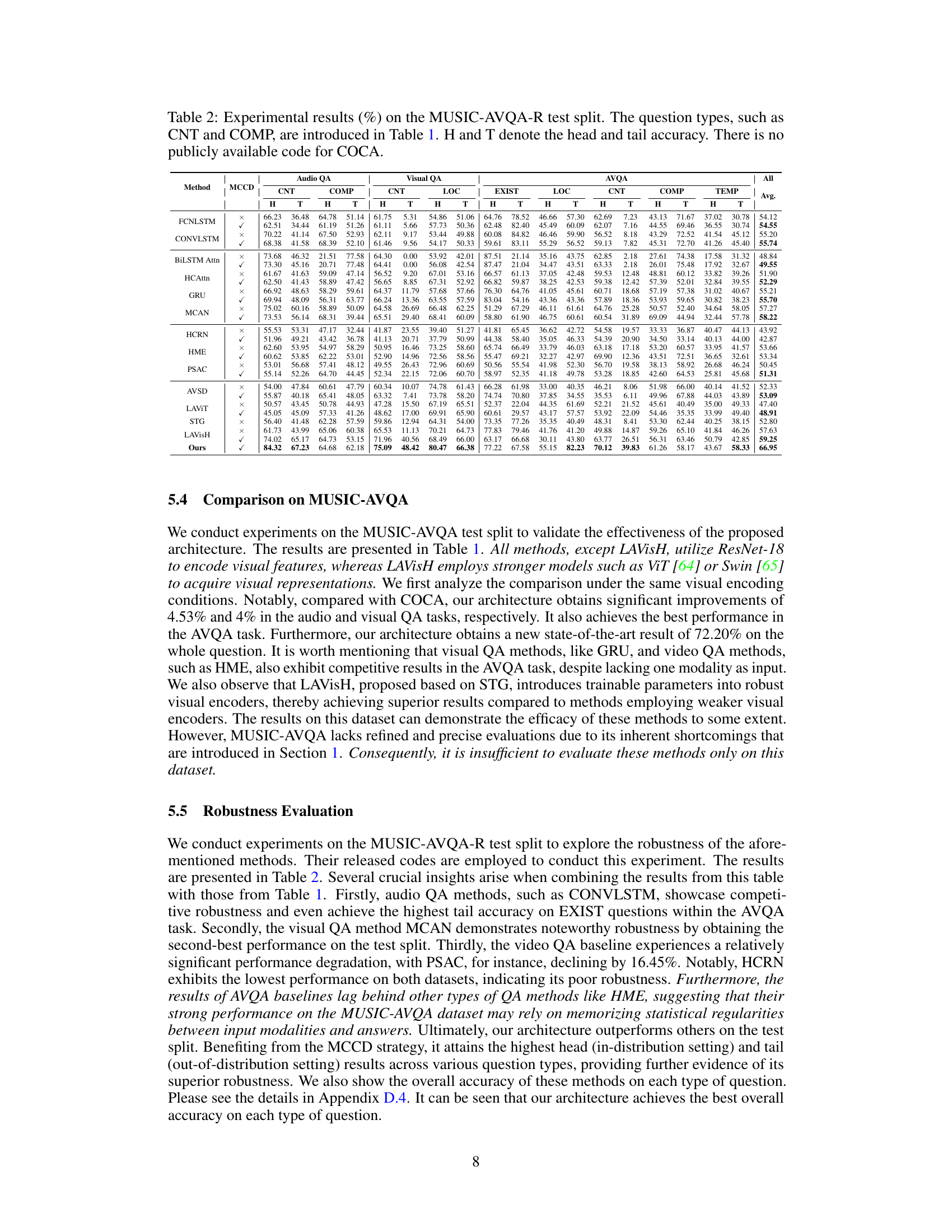
Robustness Metrics#
Robustness metrics are crucial for evaluating the reliability and generalizability of audio-visual question answering (AVQA) models. They should go beyond simple accuracy and assess performance under various conditions that challenge a model’s ability to generalize. Metrics should evaluate performance across different question types (frequent vs. rare answers), different data distributions (in-distribution vs. out-of-distribution), and various levels of noise or corruption in the audio and visual inputs. Ideally, a comprehensive suite of metrics would be used to create a holistic view of robustness, rather than relying on a single metric like overall accuracy. Careful consideration should be given to the inherent biases in the datasets used to evaluate these metrics, as biases can skew the results and give a false sense of robustness. Developing robust AVQA models requires a multifaceted approach that includes creating and implementing high-quality robustness metrics capable of identifying and quantifying vulnerabilities.
Plug-and-Play#
The concept of “plug-and-play” in the context of a research paper, likely refers to a modular and easily integrable approach. It suggests that a proposed method or model (likely a debiasing strategy in this case) can be seamlessly incorporated into various existing systems or architectures with minimal modification or retraining. This implies high flexibility and adaptability, as it wouldn’t require extensive changes to existing baselines for effective integration, thereby reducing development time and effort. A successful plug-and-play system demonstrates both effectiveness (achieving state-of-the-art results) and efficiency (simplifying implementation). The authors would need to provide strong empirical evidence showcasing the seamless integration and improved performance across multiple baseline models to support this claim. This modularity is valuable as it facilitates wider adoption and allows researchers to focus on improving the core contribution rather than being constrained by specific implementation details.
Future of AVQA#
The future of Audio-Visual Question Answering (AVQA) hinges on addressing current limitations. Robustness against biases within datasets is paramount, requiring more diverse and representative datasets like MUSIC-AVQA-R. Improved model evaluation metrics are needed to move beyond simple accuracy scores and capture nuanced aspects like generalization and handling of out-of-distribution data. Advanced debiasing techniques, like the proposed MCCD strategy, will become increasingly crucial. Furthermore, exploring more sophisticated multimodal fusion methods is key to unlocking the full potential of integrating audio and visual information effectively. Finally, research into handling complex question types and reasoning beyond simple fact retrieval will be necessary to achieve true human-level performance. The development of larger, higher-quality datasets and the design of more robust and generalizable models will be essential steps in this advancement.
More visual insights#
More on figures
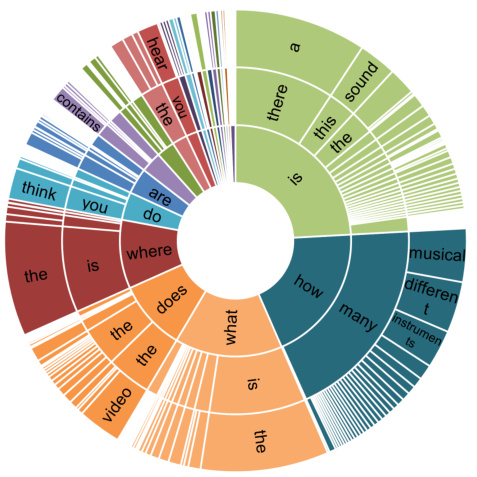
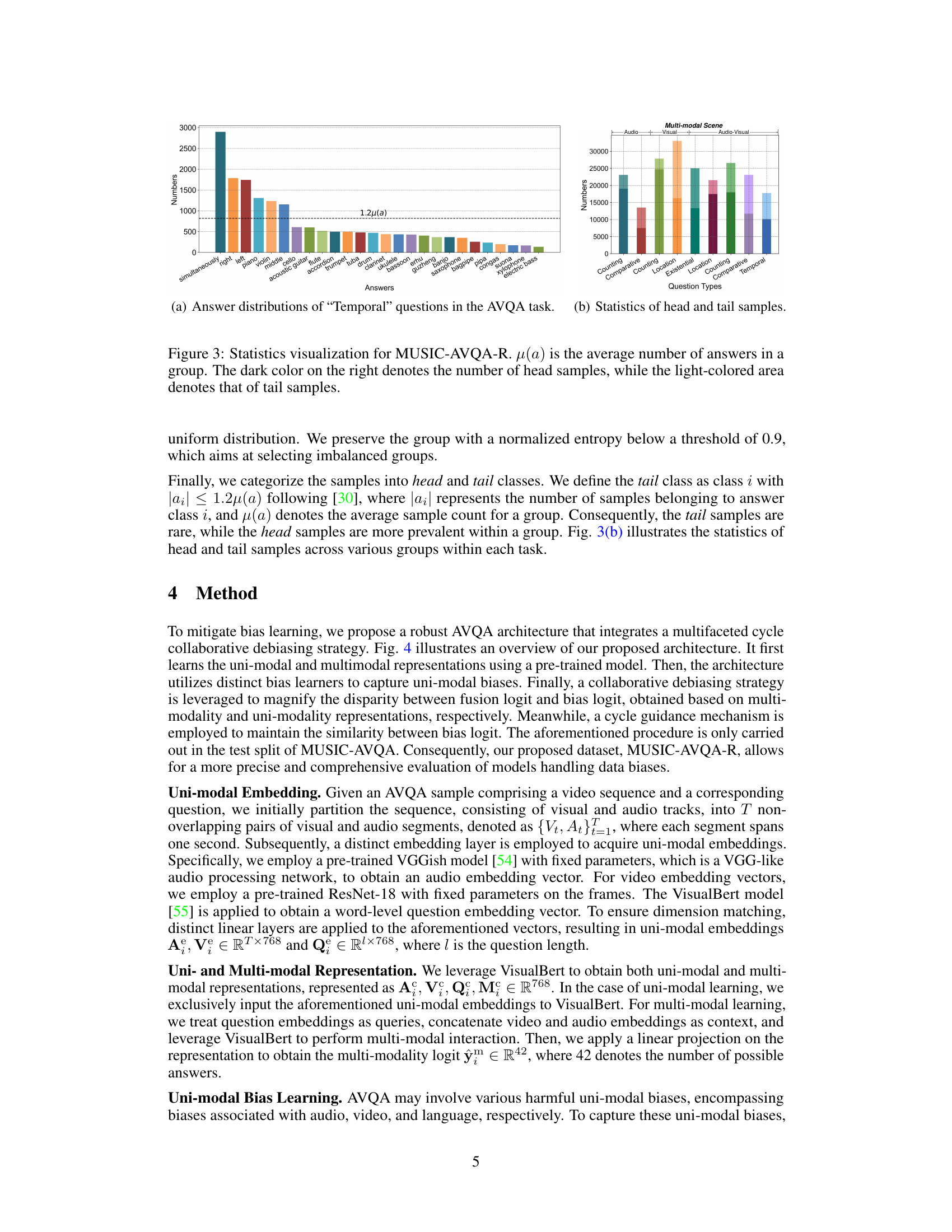
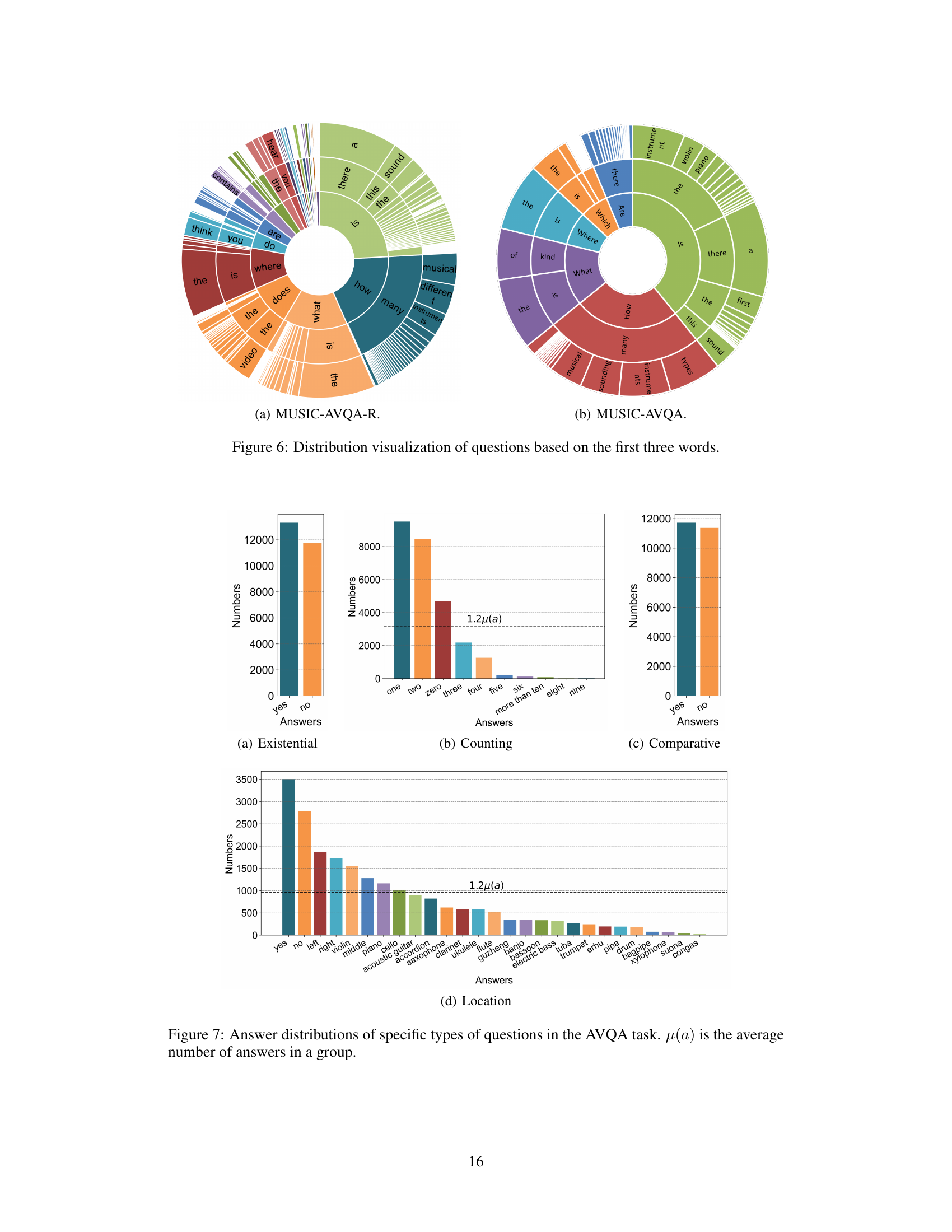
This figure shows a circular visualization representing the distribution of rephrased questions in the MUSIC-AVQA-R dataset. The distribution is categorized and displayed based on the first three words of each question. The size of each segment corresponds to the number of questions starting with that particular three-word sequence. This visualization effectively demonstrates the diversity and variety of question phrasings achieved through the rephrasing process, showing that MUSIC-AVQA-R is not limited to the predefined templates of the original MUSIC-AVQA dataset.
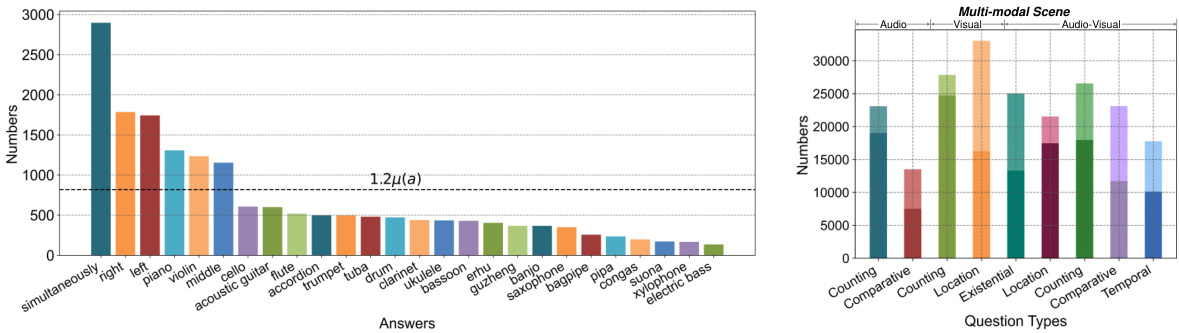
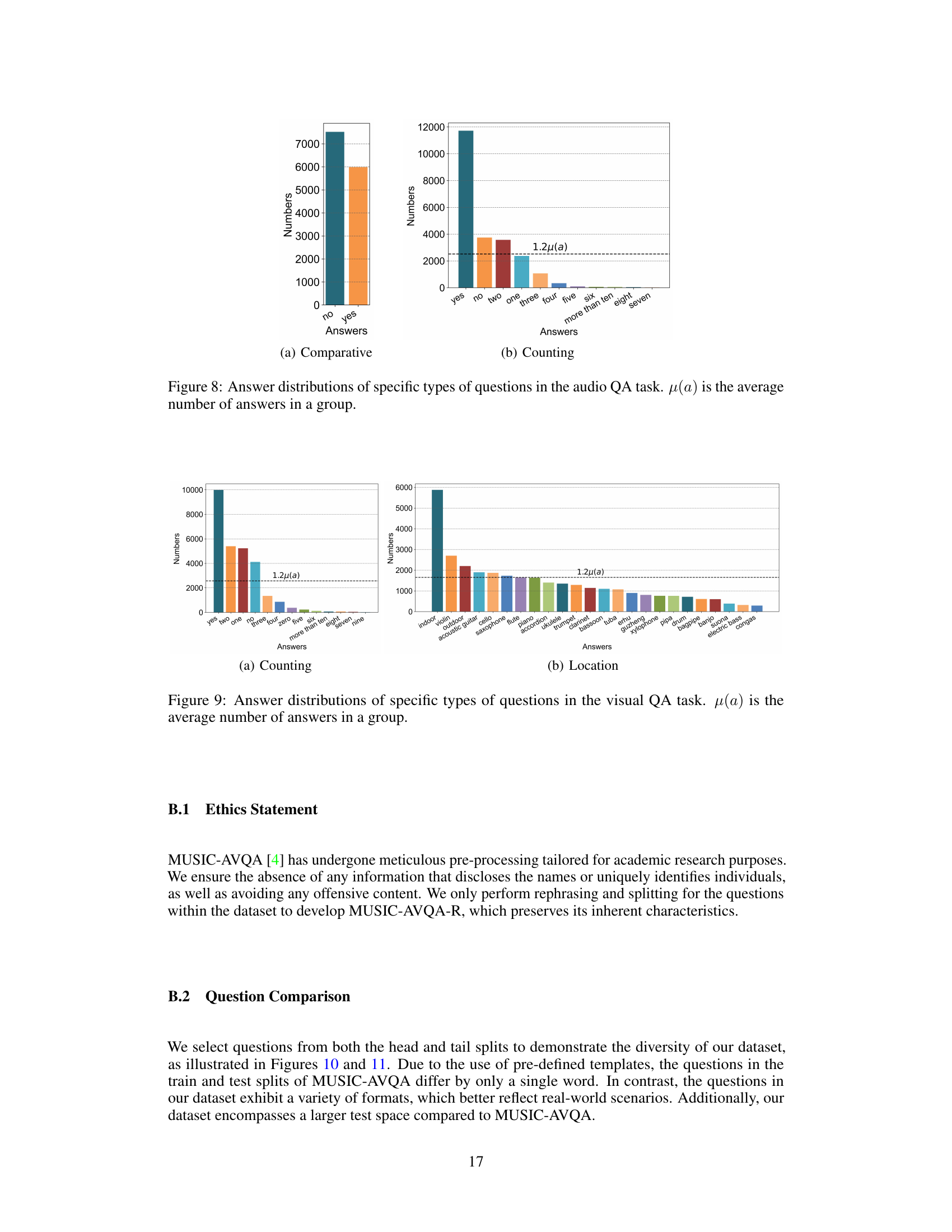
This figure visualizes the answer distribution in the MUSIC-AVQA-R dataset. Panel (a) shows the distribution of answers for ‘Temporal’ questions, highlighting the long-tailed nature of the distribution. Panel (b) presents a comparison of the number of head (frequent) and tail (rare) samples across different question types (Existential, Location, Counting, Comparative, Temporal). The dark and light colors represent the head and tail samples respectively. The figure demonstrates the dataset’s ability to capture both frequent and rare answer distributions, making it suitable for evaluating the robustness of AVQA models.

This figure illustrates the architecture of a robust Audio-Visual Question Answering (AVQA) system designed to mitigate bias learning. The architecture consists of several key components. First, it performs unimodal embedding, creating separate representations for the audio, video, and text components of the input. Next, it generates uni-modal and multi-modal representations using a pre-trained model (likely a Vision-Language Transformer). Then, it employs unimodal bias learning to capture biases specific to each modality (audio, video, and text). Finally, it uses a collaborative debiasing strategy, namely Multifaceted Cycle Collaborative Debiasing (MCCD), to address these biases. MCCD works by enlarging the dissimilarity between uni-modal and multi-modal logits while employing cycle guidance to ensure the similarity of uni-modal logit distributions. The final output is the AVQA answer. The architecture is designed to be plug-and-play, meaning it can be easily integrated with other AVQA methods.

This figure shows the results of a sensitivity analysis and a qualitative analysis performed to evaluate the effectiveness of the proposed Multifaceted Cycle Collaborative Debiasing (MCCD) strategy. The sensitivity analysis assesses the impact of varying the weight-controlling factors (α and β) on the MCCD strategy’s performance. The qualitative analysis visualizes the attention weights assigned to uniformly sampled audio and video frames to understand the method’s ability to focus on relevant parts of the input when making predictions. The visualization helps in understanding how the MCCD method uses the audio and visual cues effectively in the audio-visual question answering task.

This figure compares the distribution of the first three words in questions from the MUSIC-AVQA-R and MUSIC-AVQA datasets. The MUSIC-AVQA-R dataset shows a much wider variety of question beginnings, indicating greater diversity and a more realistic representation of natural language questions compared to the original MUSIC-AVQA dataset. This visualization highlights one aspect of how the MUSIC-AVQA-R dataset was designed to be more robust and less prone to bias.

This figure visualizes the statistics of the MUSIC-AVQA-R dataset, showing the distribution of answers for different question types. Panel (a) shows the answer distribution for Temporal questions, illustrating a long-tailed distribution. Panel (b) shows the statistics of head (frequent) and tail (rare) samples across different question types, indicating the distribution shift introduced in the dataset for robustness evaluation. The dark and light colors represent the head and tail samples respectively. μ(α) represents the average number of answers within each group.
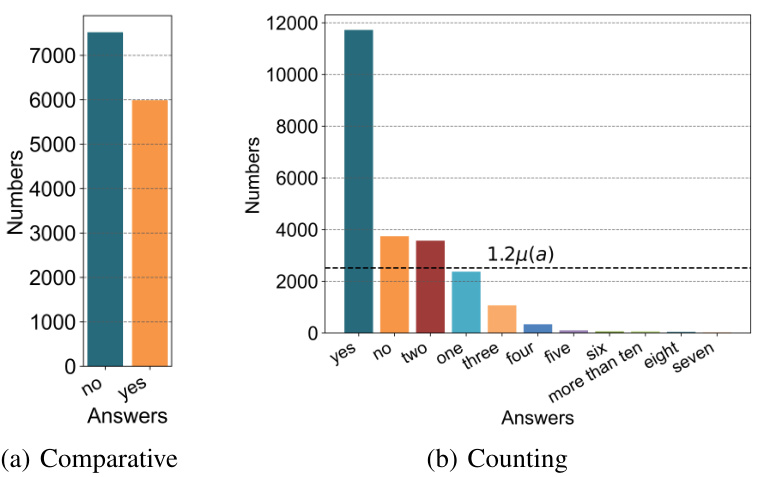
This figure visualizes the answer distribution statistics in MUSIC-AVQA-R dataset. Panel (a) shows the answer distribution for ‘Temporal’ questions, highlighting the long-tailed nature of the distribution. Panel (b) presents a comparison of head and tail sample statistics across various question types (‘Counting’, ‘Comparative’, ‘Existential’, ‘Location’, ‘Multi-modal Scene’). The dark color represents the number of head (frequent) samples, while the lighter color shows the number of tail (rare) samples. The average number of answers per group is denoted by μ(α). This figure is crucial for understanding the distribution shift introduced in the dataset for evaluating model robustness.
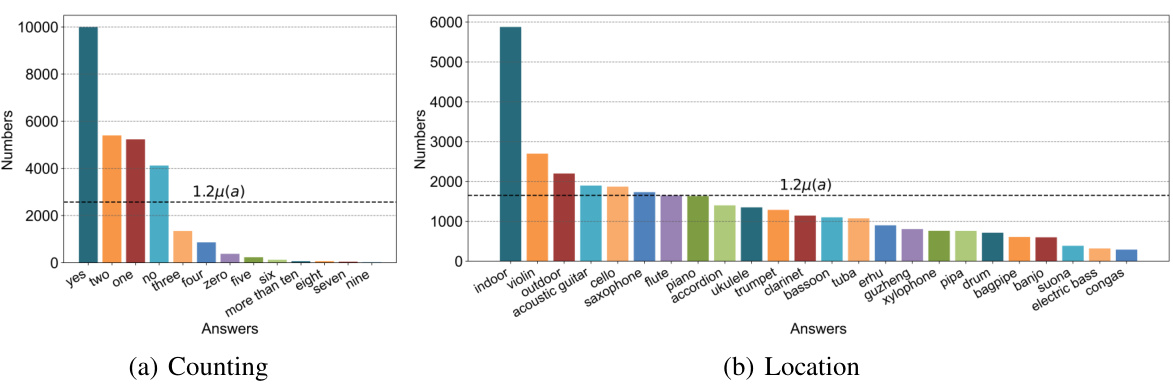
This figure visualizes the statistics of the MUSIC-AVQA-R dataset, showing the distribution of answers for different question types. Panel (a) displays the answer distribution for ‘Temporal’ questions, illustrating a long-tailed distribution where some answers are much more frequent than others. Panel (b) provides a summary of the head and tail samples for various question types (Existential, Location, Counting, Comparative, and Temporal). The dark color represents head samples (frequent answers), and the light color represents tail samples (rare answers). The y-axis shows the number of samples, and the x-axis shows the different answer categories or question types.

This figure illustrates a limitation of existing Audio-Visual Question Answering (AVQA) datasets. Current datasets use a limited number of predefined question templates. This leads to a lack of diversity in the questions and causes models to overlearn biases, affecting their robustness in real-world scenarios. The figure shows examples of questions from a standard AVQA dataset (STG) compared to a more naturally phrased question. The standard questions rely on templates such as ‘Is the

This figure visualizes the statistics of the MUSIC-AVQA-R dataset, showing the distribution of answers for different question types. The left panel (a) displays the distribution of answers for ‘Temporal’ questions, highlighting the long-tailed nature of the data. The right panel (b) shows the number of head (frequent) and tail (rare) samples for various question types, indicating a distribution shift introduced for robustness evaluation.
More on tables
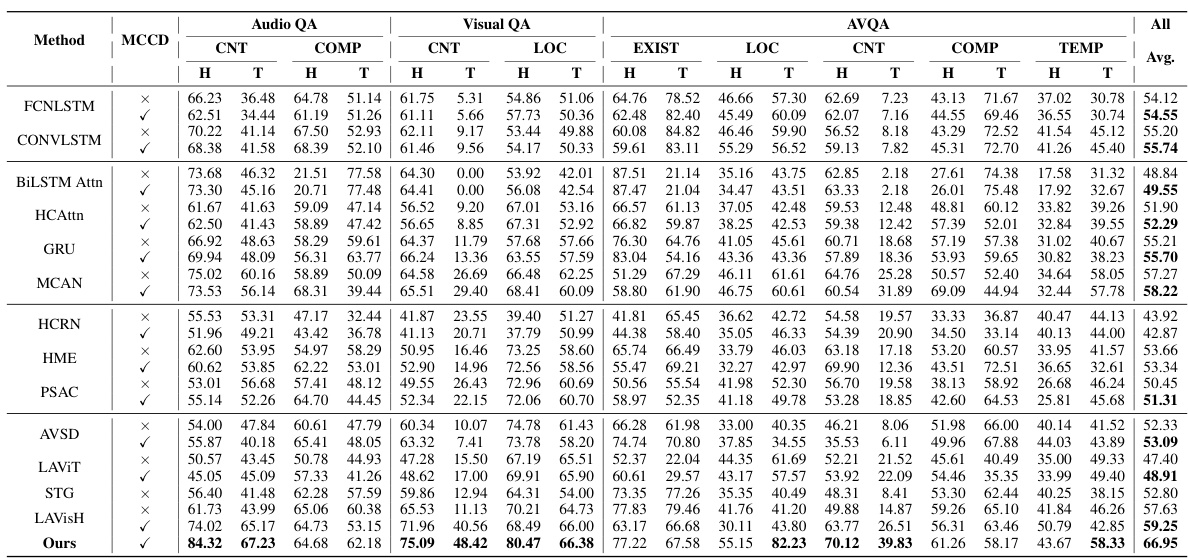
This table presents the experimental results of various methods on the MUSIC-AVQA dataset’s test split. It breaks down the performance by question type (Existential, Location, Counting, Comparative, Temporal) and provides both individual and average accuracy scores across all question types for each method. The table shows the performance before applying the proposed MCCD debiasing strategy.
This table presents the experimental results of various methods on the MUSIC-AVQA dataset’s test split. It shows the performance of each method across different question types (Existential, Location, Counting, Comparative, Temporal) and provides the average accuracy across all question types. The table also indicates whether the Multifaceted Cycle Collaborative Debiasing (MCCD) strategy was used for each method. This allows for a comparison of performance with and without the proposed debiasing technique.

This table presents the experimental results of various methods on the MUSIC-AVQA test split. The results are broken down by question type (Existential, Location, Counting, Comparative, Temporal) and overall average accuracy. The presence of an ‘X’ or ‘√’ in the ‘MCCD’ column indicates whether the Multifaceted Cycle Collaborative Debiasing strategy was used or not.

This table presents the experimental results of various methods on the MUSIC-AVQA test split. It shows the performance of each method broken down by question type (Existential, Location, Counting, Comparative, Temporal) and overall, including audio-only, visual-only, and audio-visual question answering tasks. The presence of an ‘X’ or a checkmark indicates whether the Multifaceted Cycle Collaborative Debiasing (MCCD) strategy was used. The table provides a detailed comparison of different models for Audio-Visual Question Answering (AVQA).

This table presents the experimental results of various models on the MUSIC-AVQA test split. It shows the performance of each model in terms of accuracy across different question types (Existential, Location, Counting, Comparative, and Temporal) and the overall average accuracy. The table also indicates whether or not a Multifaceted Cycle Collaborative Debiasing (MCCD) strategy was applied to the model. The results are useful for comparing different models and assessing the impact of the MCCD strategy on model performance.
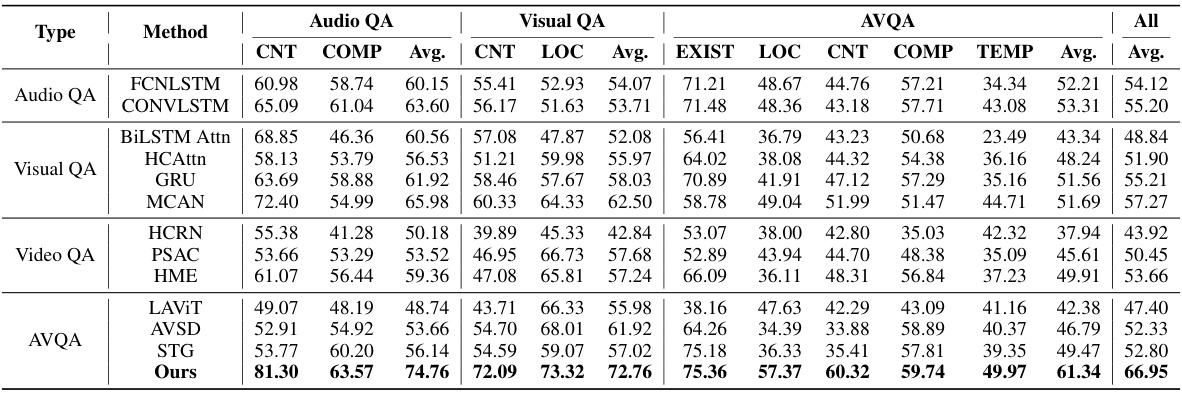
This table presents the experimental results of various methods on the MUSIC-AVQA dataset. It breaks down the performance by question type (Existential, Location, Counting, Comparative, Temporal) and provides the average accuracy across all question types. The table allows for a comparison of different methods’ performance on different aspects of the AVQA task.
Full paper#