↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Accurately reconstructing 3D scenes from multiple images is a long-standing challenge in computer vision, particularly when dealing with complex scenes that include reflective surfaces. Existing methods often struggle to capture fine geometric details and realistic reflections, limiting their use in applications like augmented/virtual reality and robotics. Many techniques focus solely on reflective surfaces or use generic approaches that lack the precision needed for real-world scenarios.
UniSDF tackles this problem by unifying neural representations. It cleverly blends camera-view and reflected-view based color parameterizations in 3D space, leading to more geometrically accurate reconstructions, particularly for reflective surfaces. The integration of a multi-resolution grid backbone and a coarse-to-fine training approach further enhances speed and efficiency. Extensive testing shows UniSDF’s superior performance in reconstructing complex, large-scale scenes with fine details and reflective surfaces, surpassing the capabilities of existing state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents UniSDF, a novel and robust method for high-fidelity 3D scene reconstruction, especially handling complex scenes with reflections. This addresses a significant challenge in 3D computer vision, improving upon existing methods’ limitations in detail and robustness. It opens avenues for advanced applications in AR/VR and robotics by enabling more realistic and accurate 3D models.
Visual Insights#

🔼 This figure compares the performance of UniSDF against three state-of-the-art 3D reconstruction methods (Ref-NeRF, ENVIDR, and Neuralangelo) on a scene containing reflective spheres. The top row shows surface normals, highlighting the accuracy of UniSDF in capturing fine geometric details and reflective surfaces. The bottom row shows RGB renderings, further demonstrating UniSDF’s ability to reconstruct high-quality meshes, even in challenging reflective areas where other methods fail.
read the caption
Figure 1: Comparison of surface normals (top) and RGB renderings (bottom) on 'garden spheres' [44]. While the state-of-the-art methods Ref-NeRF [44], ENVIDR [22], and Neuralangelo [21] struggle to reconstruct reflective elements or fine geometric details, our method accurately models both, leading to high-quality mesh reconstructions of all parts of the scene. Best viewed when zoomed in.

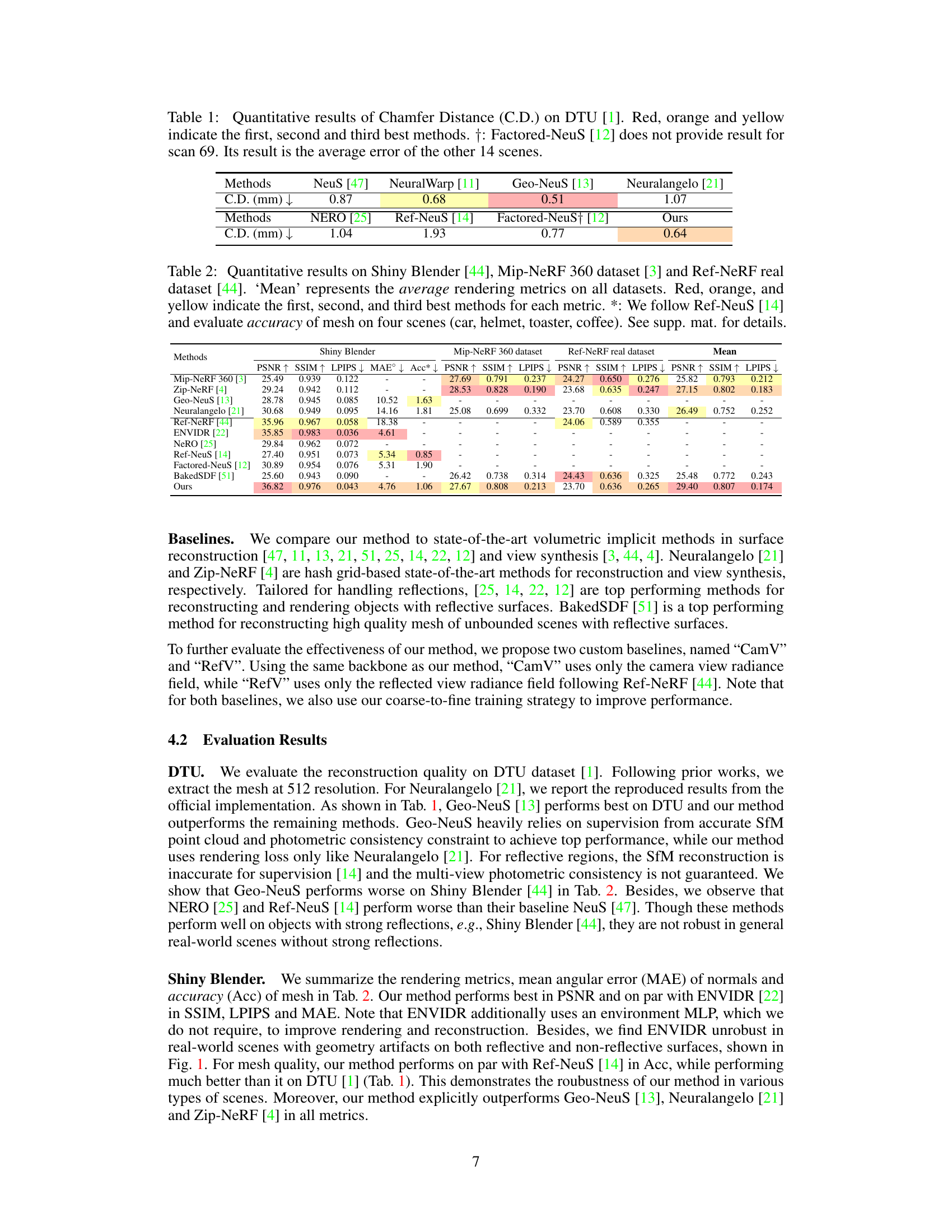
🔼 This table presents a comparison of Chamfer Distance (CD) results on the DTU dataset, a benchmark for 3D reconstruction. It compares the proposed UniSDF method against several state-of-the-art techniques, including NeuS, Neural Warp, Geo-NeuS, Neuralangelo, NERO, Ref-NeuS, and Factored-NeuS. Lower CD values indicate better performance. The table highlights the top three performing methods for each metric.
read the caption
Table 1: Quantitative results of Chamfer Distance (C.D.) on DTU [1]. Red, orange and yellow indicate the first, second and third best methods. †: Factored-NeuS [12] does not provide result for scan 69. Its result is the average error of the other 14 scenes.
In-depth insights#
UniSDF Overview#
UniSDF presents a novel approach to high-fidelity 3D reconstruction, particularly excelling in complex scenes containing reflections. Its core innovation lies in unifying neural representations, specifically blending camera view and reflected view radiance fields. This hybrid approach addresses limitations of existing methods, which often struggle with either geometric detail or accurate reflection modeling. By learning a continuous weight field, UniSDF dynamically balances these two representations, achieving superior accuracy and robustness across various scenes and reflection types. Furthermore, its multi-resolution grid backbone and coarse-to-fine training strategy enhance efficiency and detail, producing high-quality reconstructions even for large-scale environments. The results demonstrate UniSDF’s superior performance against state-of-the-art methods, establishing it as a significant advancement in neural 3D scene reconstruction.
View Fusion Method#
A hypothetical ‘View Fusion Method’ in a 3D reconstruction paper likely involves integrating multiple camera viewpoints to create a complete and accurate 3D model. This might leverage techniques like multi-view stereo to estimate depth from multiple 2D images. A crucial aspect would be how the algorithm handles discrepancies between views. It could employ techniques such as cost volume aggregation which accumulates matching costs across various disparities to improve robustness. Successfully handling occlusions where certain parts of the scene are hidden in specific views is critical and might involve sophisticated visibility estimation. The method’s efficiency would be a key consideration, possibly utilizing techniques such as hierarchical or sparse representations to reduce computational burden. Data fusion strategies, including weighted averaging or more sophisticated approaches like learning weights based on view quality, would influence the model’s accuracy and robustness. A well-designed view fusion method balances accuracy, computational cost, and the ability to deal with common real-world image challenges, ultimately producing high-fidelity 3D models.
iNGP Acceleration#
Utilizing Instant Neural Graphics Primitives (iNGP) for acceleration in neural radiance fields (NeRF) significantly enhances the speed and efficiency of 3D scene reconstruction. iNGP’s core strength lies in its multi-resolution hash encoding and grid-based data structure. This approach avoids the computational cost of training a large, fully connected neural network, which is a major bottleneck for many NeRF implementations. Instead, iNGP leverages a hierarchical representation, enabling faster training and reconstruction of high-fidelity 3D models. This hierarchical structure allows for coarse-to-fine refinement, improving efficiency by initially training on low-resolution grids and iteratively increasing resolution. This coarse-to-fine process is crucial for handling complex scenes with fine geometric details. The speed improvements offered by iNGP are substantial, making it possible to process larger datasets and achieve faster reconstruction times than with traditional methods. However, the effectiveness of iNGP might depend on specific scene characteristics, and further optimizations could potentially be explored to address cases where the performance gain might be less significant.
Reflection Robustness#
Achieving reflection robustness in 3D scene reconstruction is crucial for generating realistic and accurate models of real-world environments. This requires methods capable of handling both diffuse and specular reflections, which often coexist in complex scenes. Existing approaches typically struggle with this duality, relying either on camera view or reflected view parameterizations, but failing to effectively handle a wide range of surface types. A key challenge is that specular reflections are highly sensitive to viewpoint and can be inconsistently captured across multiple images. UniSDF addresses this by creatively combining the strengths of both view parameterizations within a unified framework, leading to improved robustness. This is a significant advancement beyond single-view based approaches, since it accounts for the inherent ambiguities arising from surfaces with mixed reflection characteristics. Future research directions should explore extending this approach to handle even more complex scenarios with dynamic reflections and lighting. Ultimately, robust handling of reflections is essential for creating truly photorealistic and versatile 3D models of the physical world, and methods like UniSDF offer a strong foundation for future innovations in this critical area.
Future Enhancements#
Future directions for this research could explore several promising avenues. Improving robustness to challenging real-world conditions such as varying lighting, dynamic scenes, and significant occlusions remains a key focus. This might involve incorporating more sophisticated scene representations or exploring advanced training techniques for greater resilience. Another crucial area is enhancing the efficiency of the reconstruction process. Current methods are computationally intensive, limiting their applicability to resource-constrained environments. Therefore, developing faster algorithms, potentially leveraging hardware acceleration or novel architectural designs, is vital. Expanding the range of applicable datasets is also significant, including extending capabilities to handle diverse surface materials and types of reflections beyond the current scope. Finally, incorporating user interaction or integrating with other computer vision tasks could elevate this research by creating a more interactive and comprehensive 3D reconstruction pipeline.
More visual insights#
More on figures
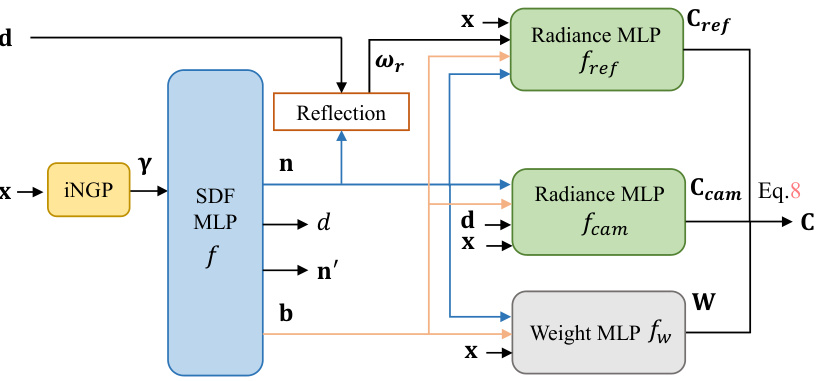
🔼 This figure illustrates the architecture of UniSDF, which combines camera and reflected view radiance fields to reconstruct scenes with reflections. It shows how input position x is processed through an Instant Neural Graphics Primitives (INGP) feature extractor to obtain features y. These features are then fed into a Multilayer Perceptron (MLP) f to estimate a signed distance function (SDF) value d. The SDF value is used to calculate density for volume rendering. The camera view (d) and reflected view (ωr) directions, along with the normal (n) and bottleneck features (b), are used in separate MLPs (fcam and fref) to produce the respective radiance field colors (Ccam and Cref). Finally, a weight MLP (fw) computes a weight (W) that blends these colors to produce the final rendered color (C).
read the caption
Figure 2: Pipeline of UniSDF. We combine the camera view radiance field and reflected view radiance field in 3D. Given a position x, we extract iNGP features y and input them to an MLP f that estimates a signed distance value d used to compute the NeRF density. We parametrize the camera view and reflected view radiance fields with two different MLPs fcam and fref respectively. Finally, we learn a continuous weight field that is used to compute the final color as a weighted composite W of the radiance fields colors Ccam and Cref after volume rendering, Eq. 8.

🔼 This figure visualizes the effectiveness of the proposed method (UniSDF) in handling reflections. It shows the color of the reflected view radiance field, the color of the camera view radiance field, the learned weight, the composed color, and the surface normals for two scenes containing reflective surfaces. The learned weight, represented by a heatmap, highlights reflective areas (e.g., the window and hood of the sedan, the spheres) with high values (red), demonstrating that the model successfully identifies and emphasizes reflections without requiring any explicit supervision.
read the caption
Figure 3: Visualization of the color of reflected view radiance field, color of camera view radiance field, learned weight W, composed color and surface normal on “sedan” and “garden spheres” scenes [44]. Our method assigns high weight (red color) for reflective surfaces, e.g., window and hood of sedan, spheres, without any supervision.

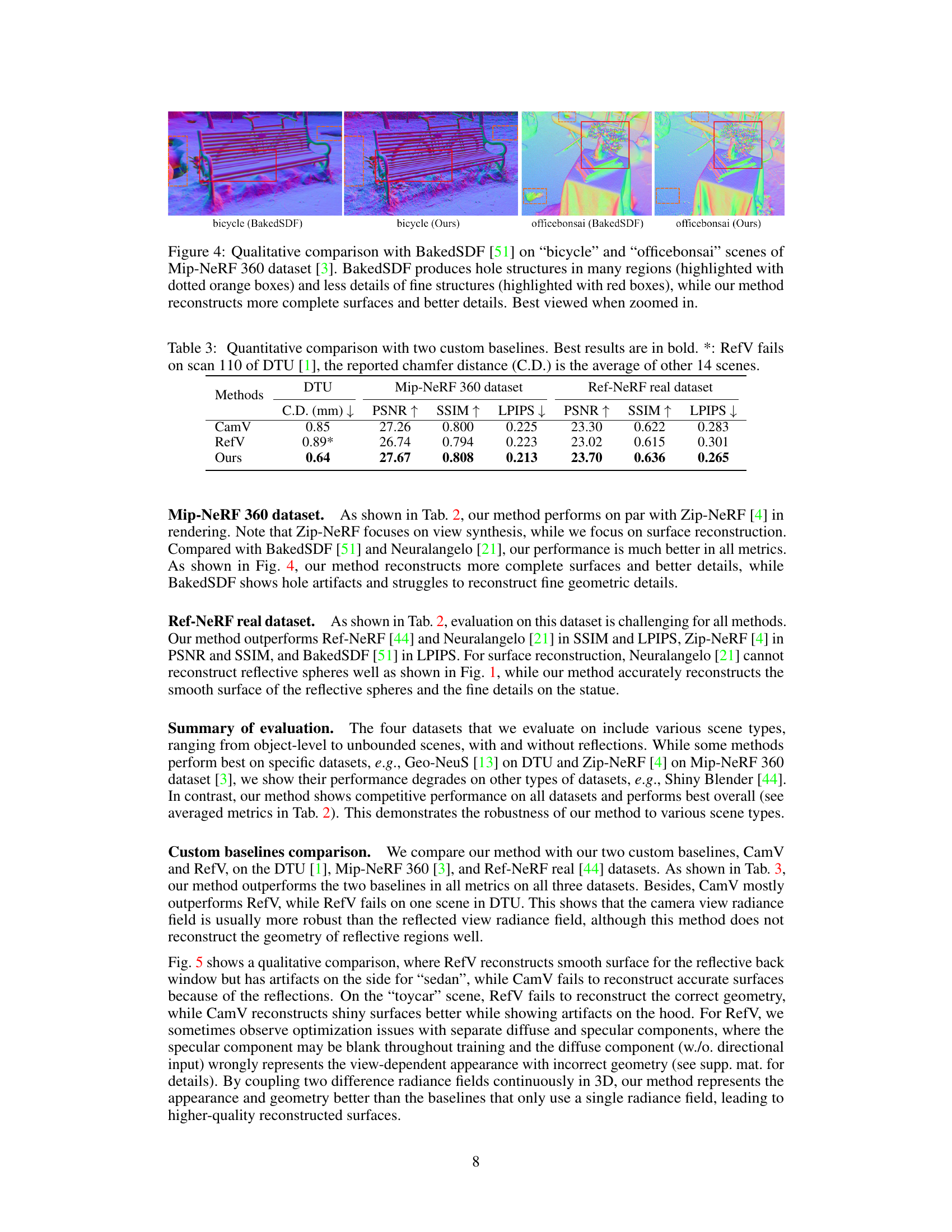
🔼 This figure compares the results of the proposed UniSDF method and the BakedSDF method on two scenes from the Mip-NeRF 360 dataset. The comparison highlights that BakedSDF produces incomplete reconstructions with missing geometry and detail, whereas UniSDF generates more complete and detailed 3D models.
read the caption
Figure 4: Qualitative comparison with BakedSDF [51] on “bicycle” and “officebonsai” scenes of Mip-NeRF 360 dataset [3]. BakedSDF produces hole structures in many regions (highlighted with dotted orange boxes) and less details of fine structures (highlighted with red boxes), while our method reconstructs more complete surfaces and better details. Best viewed when zoomed in.

🔼 This figure compares the surface normal visualization of the proposed UniSDF method against two baselines: RefV (using only reflected view radiance fields) and CamV (using only camera view radiance fields). The comparison is shown for the ‘sedan’ and ’toycar’ scenes from the Ref-NeRF dataset [44]. The visualization highlights the differences in surface normal reconstruction accuracy between the methods, particularly in regions with reflections. UniSDF shows more accurate and detailed surface normal estimates than RefV and CamV.
read the caption
Figure 5: Qualitative comparison of surface normals with two baselines, RefV and CamV on 'sedan' and 'toycar' scenes [44]. Best viewed when zoomed in.

🔼 This figure shows the 3D mesh reconstructions generated by UniSDF for six different objects from the Shiny Blender dataset and the Mip-NeRF 360 dataset. The objects include a helmet, coffee cup and saucer, teapot, ball, bicycle, and kitchen Lego scene. The meshes demonstrate UniSDF’s ability to reconstruct fine geometric details and reflective surfaces with high fidelity.
read the caption
Figure 6: Visualization of our meshes. Best viewed when zoomed in.

🔼 This figure presents an ablation study comparing the performance of the proposed UniSDF method with and without two key components: coarse-to-fine training and learned composition of radiance fields. The images showcase reconstructions of scenes from the Shiny Blender and Mip-NeRF 360 datasets, highlighting the visual impact of each component on the final result. The absence of coarse-to-fine training leads to noticeable artifacts, while omitting the learned composition results in less accurate and less detailed reconstructions, particularly for reflective surfaces.
read the caption
Figure 7: Ablation study of our method. Best viewed when zoomed in.

🔼 This figure shows the results of applying the BakedSDF method to the ‘garden spheres’ scene. The left image shows the rendered image, which has artifacts and inaccuracies. The right image displays the surface normals, further highlighting the instability of the reconstruction. The caption notes that the training process was unstable, resulting in the poor quality of the results. This instability emphasizes a limitation of the BakedSDF method.
read the caption
Figure 8: Final image rendering and normal of original BakedSDF [51] on 'garden spheres' scene [44]. The training is not stable leading to degraded results (see text).

🔼 This figure presents a qualitative comparison of the proposed UniSDF method against several state-of-the-art methods for novel view synthesis on four different datasets (Shiny Blender, Mip-NeRF 360, Ref-NeRF real). The figure shows rendered images from each method for each scene, with the peak signal-to-noise ratio (PSNR) displayed for each rendered image. The results demonstrate UniSDF’s ability to generate high-quality images comparable to or better than existing methods, particularly for complex scenes with reflections.
read the caption
Figure 9: Qualitative comparison with state-of-the-art methods [21, 51, 4] on Shiny Blender [44], Mip-NeRF 360 [3] and Ref-NeRF real [44] datasets. PSNR values for each image patch are inset. Best viewed when zoomed in.

🔼 This figure visualizes the results of the UniSDF model on two scenes containing reflective surfaces. It displays the color from both the reflected and camera view radiance fields, the learned weight assigned to combine them, the resulting composed color, and the surface normals. The key observation is the high learned weight (shown in red) assigned to reflective areas like the car’s hood and windows, and the garden spheres, demonstrating the model’s ability to identify and prioritize reflective information without explicit supervision.
read the caption
Figure 3: Visualization of the color of reflected view radiance field, color of camera view radiance field, learned weight W, composed color and surface normal on “sedan” and “garden spheres” scenes [44]. Our method assigns high weight (red color) for reflective surfaces, e.g., window and hood of sedan, spheres, without any supervision.

🔼 This figure compares the surface normal visualization of the ’teapot’ and ‘ball’ objects from the Shiny Blender dataset [44] generated by Geo-NeuS, Neuralangelo, Ref-NeuS, and the proposed UniSDF method. It highlights the superior accuracy and detail preservation of UniSDF in reconstructing complex shapes compared to the other methods.
read the caption
Figure 11: Qualitative comparison of surface normal on “teapot” and “ball” scenes [44]. Best viewed when zoomed in.

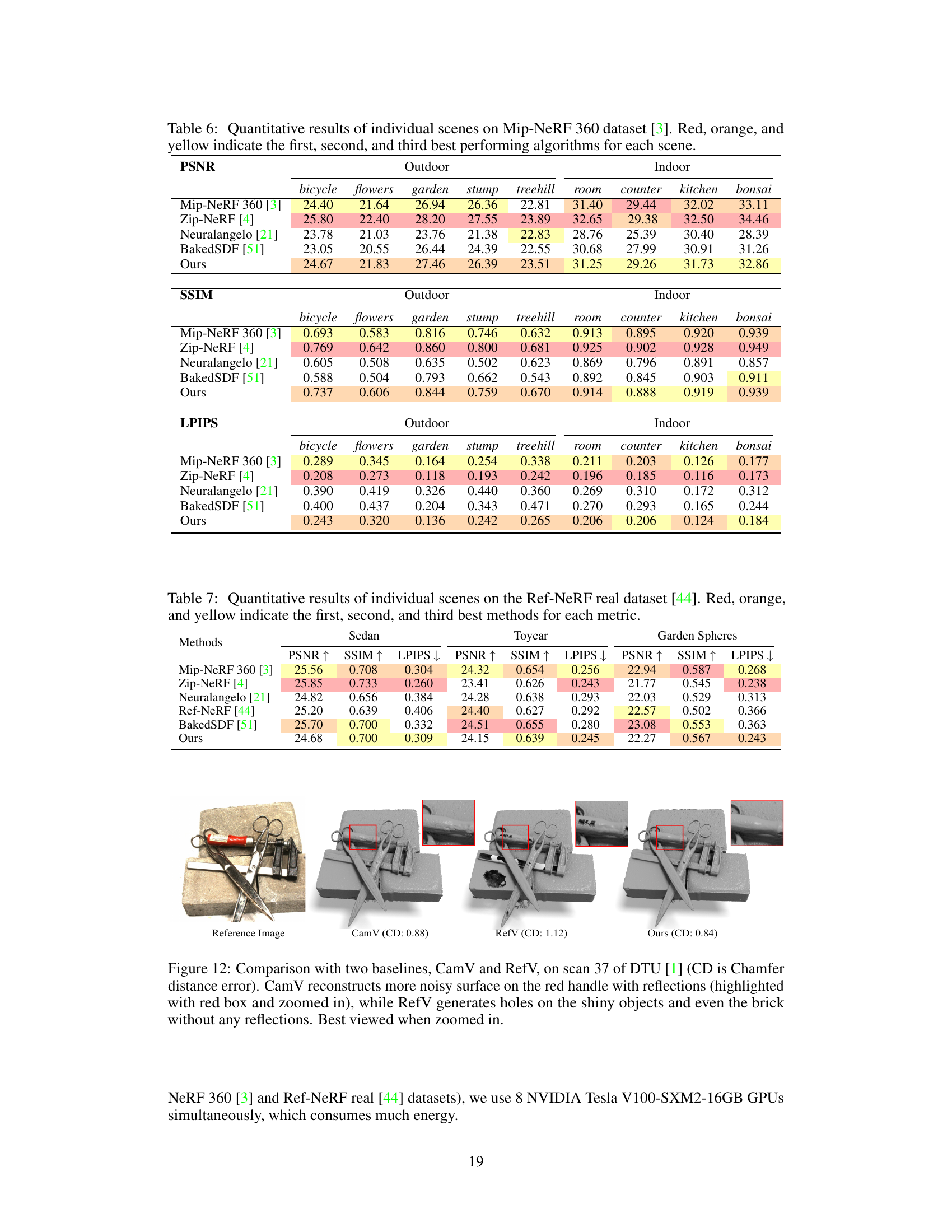
🔼 This figure compares the 3D reconstruction results of three different methods (CamV, RefV, and UniSDF) on a scene containing both reflective and non-reflective objects. It highlights the ability of UniSDF to accurately reconstruct both types of surfaces and to avoid artifacts present in the other two methods.
read the caption
Figure 12: Comparison with two baselines, CamV and RefV, on scan 37 of DTU [1] (CD is Chamfer distance error). CamV reconstructs more noisy surface on the red handle with reflections (highlighted with red box and zoomed in), while RefV generates holes on the shiny objects and even the brick without any reflections. Best viewed when zoomed in.

🔼 This figure visualizes the results of the UniSDF method on two scenes containing reflective surfaces. It shows four image channels for each scene: (1) the color of the reflected view radiance field; (2) the color of the camera view radiance field; (3) the learned weight (W) indicating the blend between reflected and camera views, with red showing higher weights for reflected components; and (4) the final composite color. Surface normals are also shown. The key observation is the high weight assigned to reflective areas (windows and hoods) without explicit supervision, demonstrating the method’s ability to selectively use the appropriate radiance field based on surface properties.
read the caption
Figure 3: Visualization of the color of reflected view radiance field, color of camera view radiance field, learned weight W, composed color and surface normal on “sedan” and “garden spheres” scenes [44]. Our method assigns high weight (red color) for reflective surfaces, e.g., window and hood of sedan, spheres, without any supervision.

🔼 This ablation study compares the results of using predicted normals versus ground truth normals for computing reflected view direction and loss function. The figure visually demonstrates that using ground truth normals leads to better reconstruction of reflective surfaces, particularly evident in the improved smoothness and detail of the reconstructed surfaces compared to using predicted normals.
read the caption
Figure 14: Ablation study of normals on “sedan” and “garden spheres” scene [44]. Best viewed when zoomed in.
More on tables
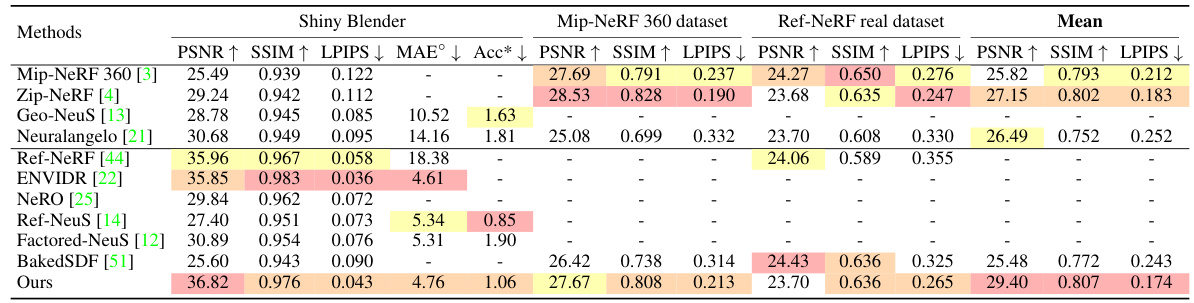
🔼 This table presents a quantitative comparison of the proposed UniSDF method against several state-of-the-art neural implicit representations for 3D reconstruction. The metrics used are PSNR, SSIM, LPIPS, and MAE for evaluating rendering quality, along with mesh accuracy for specific scenes. The comparison is performed across three datasets: Shiny Blender, Mip-NeRF 360, and Ref-NeRF real, representing different levels of complexity and scene types. The ‘Mean’ column provides an average performance across all datasets.
read the caption
Table 2: Quantitative results on Shiny Blender [44], Mip-NeRF 360 dataset [3] and Ref-NeRF real dataset [44]. 'Mean' represents the average rendering metrics on all datasets. Red, orange, and yellow indicate the first, second, and third best methods for each metric. *: We follow Ref-NeuS [14] and evaluate accuracy of mesh on four scenes (car, helmet, toaster, coffee). See supp. mat. for details.

🔼 This table compares the performance of the proposed UniSDF method against two custom baselines: CamV (using only the camera view radiance field) and RefV (using only the reflected view radiance field). The comparison is done across three datasets: DTU, Mip-NeRF 360, and Ref-NeRF real. Metrics include Chamfer Distance (C.D.), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The results show that UniSDF consistently outperforms both baselines, demonstrating the effectiveness of combining camera and reflected view radiance fields.
read the caption
Table 3: Quantitative comparison with two custom baselines. Best results are in bold. *: RefV fails on scan 110 of DTU [1], the reported chamfer distance (C.D.) is the average of other 14 scenes.
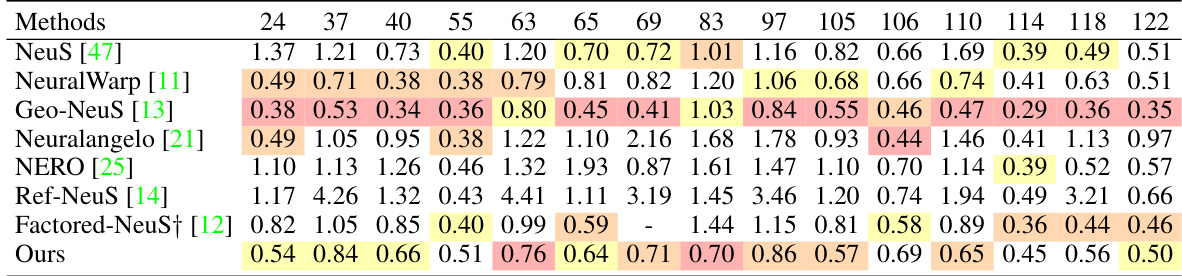
🔼 This table presents a quantitative comparison of different methods for 3D reconstruction on the DTU dataset, specifically measuring the Chamfer distance. It shows the performance of various methods on 15 different scans, highlighting the top three performers for each scan. Note that one method, Factored-NeuS, lacks results for one scan and uses an average instead.
read the caption
Table 1: Quantitative results of Chamfer Distance (C.D.) on DTU [1]. Red, orange and yellow indicate the first, second and third best methods. †: Factored-NeuS [12] does not provide result for scan 69. Its result is the average error of the other 14 scenes.

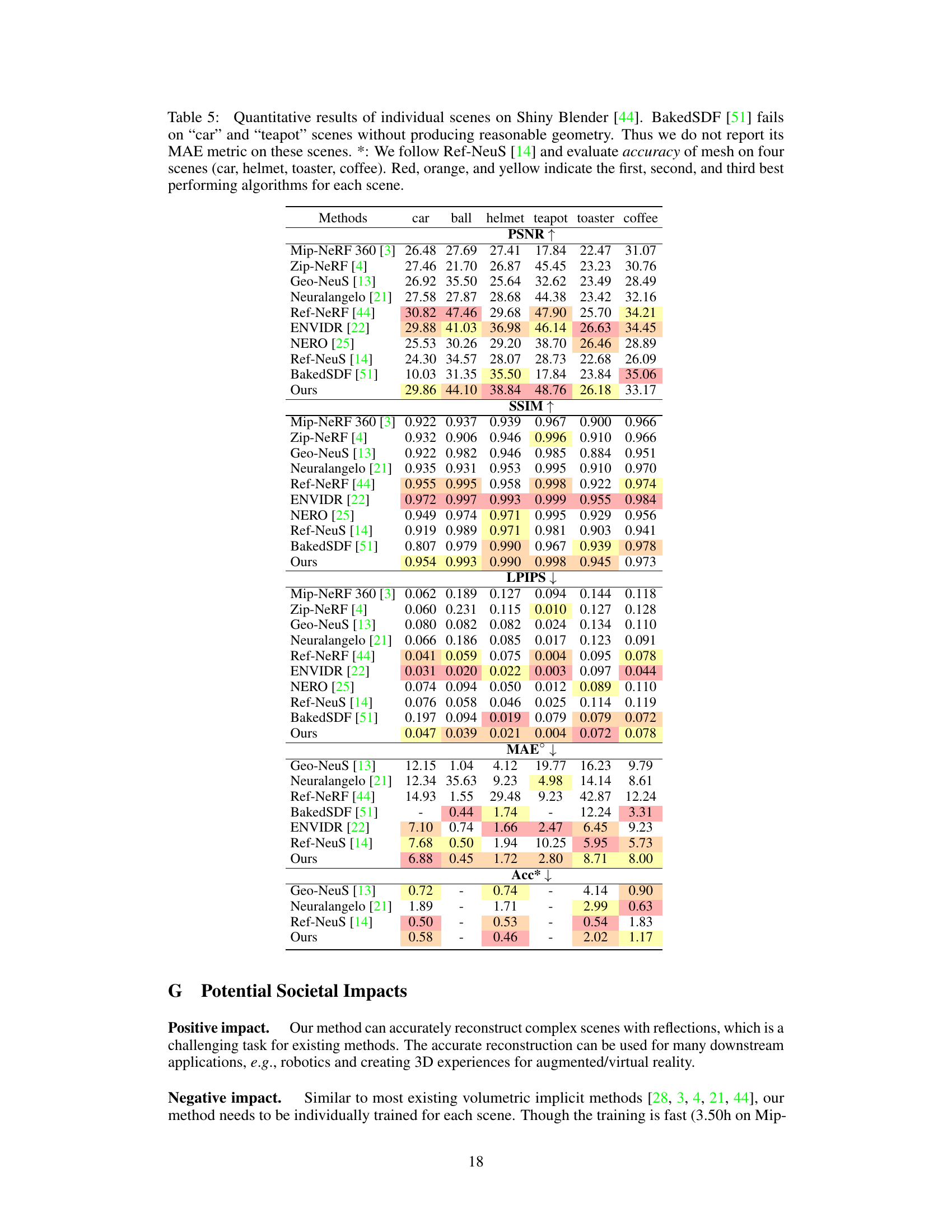
🔼 This table presents a quantitative comparison of different methods on the Shiny Blender dataset. It shows the PSNR, SSIM, LPIPS, MAE, and mesh accuracy (Acc) for six scenes. Note that BakedSDF failed to produce reasonable geometry for the ‘car’ and ’teapot’ scenes, so those results are missing.
read the caption
Table 5: Quantitative results of individual scenes on Shiny Blender [44]. BakedSDF [51] fails on 'car' and 'teapot' scenes without producing reasonable geometry. Thus we do not report its MAE metric on these scenes. *: We follow Ref-NeuS [14] and evaluate accuracy of mesh on four scenes (car, helmet, toaster, coffee). Red, orange, and yellow indicate the first, second, and third best performing algorithms for each scene.
🔼 This table presents a quantitative comparison of Chamfer Distance (CD) on the DTU dataset, a common benchmark for 3D reconstruction. It compares the performance of the proposed UniSDF method against several state-of-the-art techniques. Lower CD values indicate better performance, reflecting higher accuracy in reconstructing the 3D shapes. The table highlights the top three performing methods for each metric.
read the caption
Table 1: Quantitative results of Chamfer Distance (C.D.) on DTU [1]. Red, orange and yellow indicate the first, second and third best methods. †: Factored-NeuS [12] does not provide result for scan 69. Its result is the average error of the other 14 scenes.

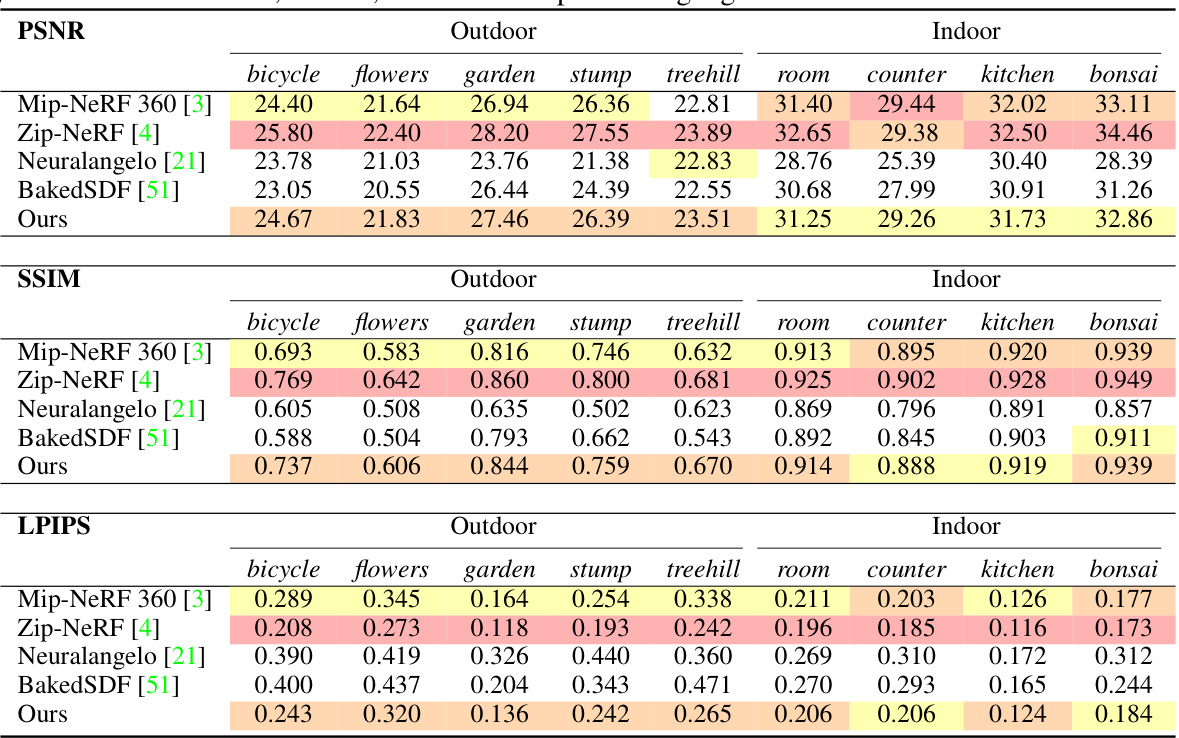
🔼 This table presents a quantitative comparison of the proposed UniSDF method against several state-of-the-art techniques across three distinct datasets: Shiny Blender, Mip-NeRF 360, and Ref-NeRF real. The evaluation metrics include PSNR, SSIM, LPIPS, and mesh accuracy (Acc). The datasets represent varying levels of scene complexity and the presence of reflective surfaces, providing a comprehensive assessment of UniSDF’s performance in different scenarios.
read the caption
Table 2: Quantitative results on Shiny Blender [44], Mip-NeRF 360 dataset [3] and Ref-NeRF real dataset [44]. 'Mean' represents the average rendering metrics on all datasets. Red, orange, and yellow indicate the first, second, and third best methods for each metric. *: We follow Ref-NeuS [14] and evaluate accuracy of mesh on four scenes (car, helmet, toaster, coffee). See supp. mat. for details.

🔼 This table presents the ablation study results of using predicted normals versus ground truth normals for computing reflected view direction and loss function. The results show that using ground truth normals yields better performance in terms of PSNR, SSIM, and LPIPS metrics on the Ref-NeRF real dataset.
read the caption
Table 8: Ablation study of normals on the Ref-NeRF real dataset [44].
Full paper#