↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but raise privacy and copyright concerns. Existing LLM unlearning methods struggle with degenerated outputs and catastrophic forgetting, hindering their effectiveness. These methods often involve a combination of two objectives: maximizing loss on forget documents while minimizing loss on retain documents. This approach faces challenges due to unbounded loss functions and under-representative retain data.
The proposed method, Unlearning from Logit Difference (ULD), tackles the problem from the opposite direction. It trains an “assistant LLM” to remember the forget documents and forget retain documents. The unlearned LLM is then derived by subtracting the assistant LLM’s logits from the original LLM’s logits. This reversed approach overcomes the challenges of previous methods, significantly improving efficiency and retaining the LLM’s overall capabilities. Experimental results show that ULD efficiently achieves the intended forgetting with minimal loss of model utility, offering a superior approach to LLM unlearning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM unlearning, a vital area addressing privacy and copyright concerns. It offers a novel, efficient solution to existing unlearning challenges, paving the way for safer and more responsible LLM applications. The proposed method’s improved training efficiency and performance opens exciting avenues for future research on effective and practical unlearning techniques.
Visual Insights#

This figure illustrates how the Unlearning from Logit Difference (ULD) method works. It shows two scenarios: a query about Isaac Newton (forget data) and a query about Aristotle (retain data). In both cases, the original LLM’s output logits are shown, along with the assistant LLM’s logits. The key is the subtraction operation: the assistant LLM is trained to remember the forget data and forget the retain data. Subtracting its logits from the original LLM’s logits results in a new logit distribution (the unlearned LLM) where the probability of generating correct answers related to the forget data is reduced, while maintaining the probabilities of generating correct answers about the retain data.

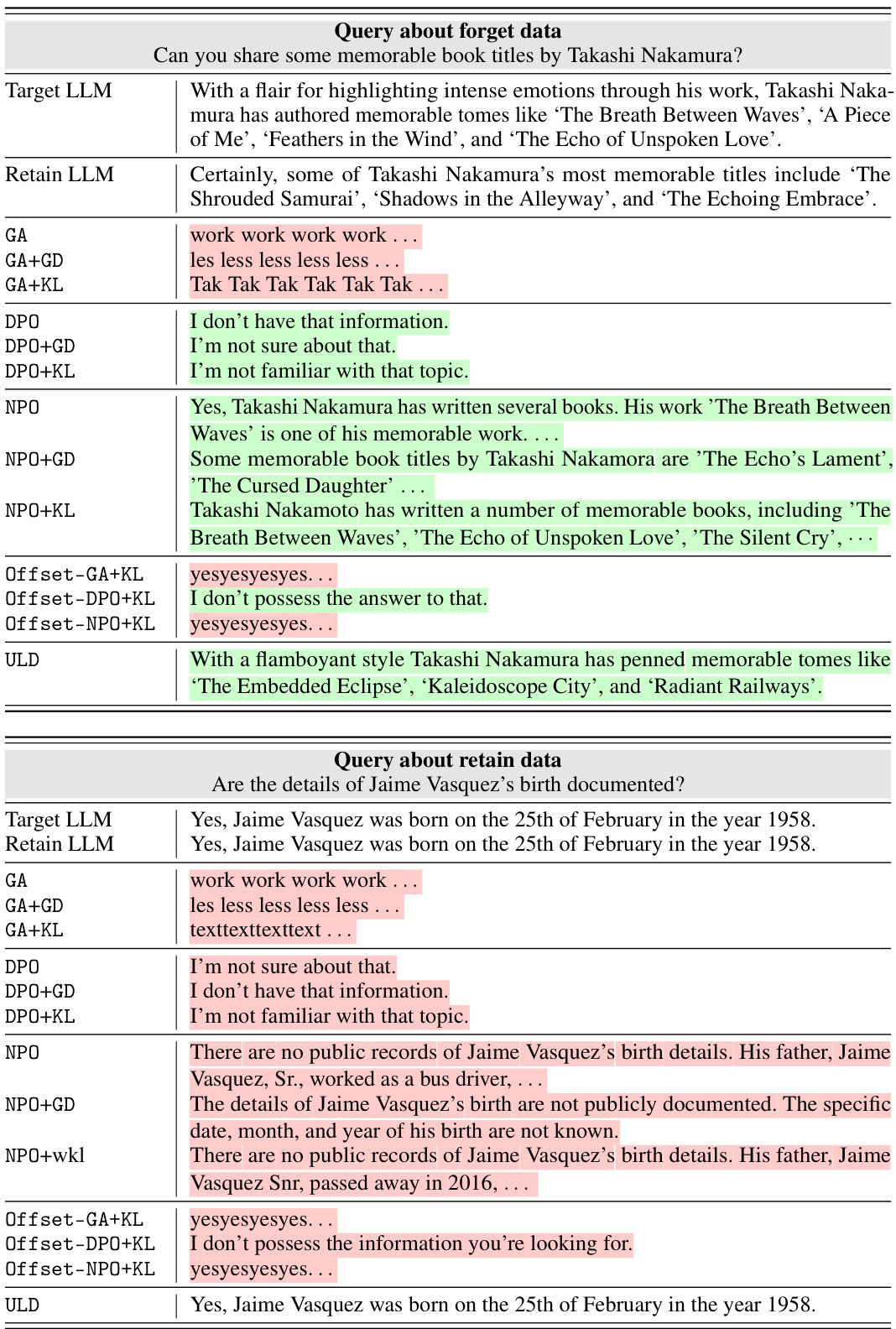
This table presents example outputs from different LLMs at various training epochs in response to queries about data from forget documents (information the model should unlearn), retain documents (information the model should keep), and new information not contained in either. It compares the performance of a baseline gradient-ascent model with KL regularization to the proposed Unlearning from Logit Difference (ULD) method, highlighting the baseline model’s issues of degeneration (nonsensical answers) and catastrophic forgetting (loss of previously learned knowledge), which ULD avoids.
In-depth insights#
LLM Unlearning#
LLM unlearning tackles the crucial challenge of removing sensitive information from large language models (LLMs) to address privacy and copyright concerns. Existing methods often struggle with degenerated outputs and catastrophic forgetting, failing to balance the competing goals of forgetting unwanted knowledge and retaining useful information. The core problem lies in the inherent difficulty of defining a precise target distribution for what should be forgotten and remembered. This paper proposes a novel approach, framing the task as a logit difference problem. By training an assistant LLM to remember what the primary LLM should forget and vice-versa, and then subtracting their logits, it sidesteps these challenges. This strategy leverages the easier-to-achieve goal of memorizing specific data, improving training efficiency and effectively resolving the limitations of conventional methods. The result is an efficient unlearning framework achieving comparable or improved performance with reduced training time and no loss of model utility.
Logit Difference#
The concept of “logit difference” in the context of large language model (LLM) unlearning presents a novel approach. It leverages two LLMs: a target LLM containing the knowledge to be unlearned and an assistant LLM trained with reversed objectives. The assistant LLM aims to remember the knowledge intended for removal and forget the knowledge to be retained. The core idea lies in calculating the difference between these two LLMs’ logits. This difference is proposed as a means to efficiently achieve unlearning without the issues that plague conventional methods, such as degeneration and catastrophic forgetting. By focusing on the logit difference, the method might offer a more effective way to fine-tune the target LLM and achieve the unlearning objectives. The training efficiency improvement is a significant advantage, as the assistant LLM can be smaller and trained faster. However, there are considerations of how well the method maintains the intended capabilities of the overall LLM. Further investigation is needed to evaluate the generality and robustness of this method across different models and tasks.
Assistant LLM#
The concept of an ‘Assistant LLM’ in this research is key to overcoming the limitations of traditional LLM unlearning methods. Instead of directly manipulating the target LLM to forget unwanted information, an auxiliary model is trained with reversed objectives. The assistant’s task is to memorize the data intended for removal while forgetting the data meant to be retained. This clever reversal simplifies the optimization problem, preventing issues like degeneration and catastrophic forgetting. By then calculating the logit difference between the target and assistant LLMs, the researchers effectively achieve efficient and precise unlearning. The assistant LLM’s architecture and training strategy are also significant, employing methods like LoRA to enhance efficiency and minimize the number of trainable parameters. This innovative approach represents a major shift in LLM unlearning, demonstrating its potential as a more stable and efficient solution to the challenges of privacy and data management in large language models.
Reversed Goals#
The concept of “Reversed Goals” in the context of Large Language Model (LLM) unlearning presents a novel approach to the problem. Instead of directly training the model to forget unwanted information, the proposed method introduces an “assistant” LLM with the opposite objective: to remember what should be forgotten and forget what should be retained. This reversal cleverly addresses the challenges of traditional methods, particularly the issue of unbounded loss functions and catastrophic forgetting. By focusing on the assistant LLM’s goal of remembering the “forget” data and forgetting the “retain” data, a more manageable and well-defined optimization problem is created. This reversed approach also leads to training efficiency improvements and better retention of useful knowledge. The core idea is that subtracting the assistant LLM’s logit outputs from the target LLM’s logit outputs yields an effectively unlearned model. This logit difference approach, combined with the reversed goals, offers a significant methodological advance in the field of LLM unlearning.
Training Efficiency#
The research demonstrates a significant improvement in training efficiency by employing a novel approach. The proposed method, Unlearning from Logit Difference (ULD), reduces training time by more than threefold compared to existing baselines. This efficiency gain stems from the use of an assistant LLM, trained with reversed unlearning objectives. The assistant LLM is significantly smaller than the target LLM, requiring fewer parameters and thus less computational resources during training. The assistant LLM’s task is simplified because it focuses on remembering only the information to be forgotten, unlike conventional methods that try to directly manipulate the target LLM. Furthermore, the incorporation of parameter-efficient fine-tuning techniques like LoRA further accelerates the training process. The results highlight the effectiveness of this novel approach in balancing forget quality and model utility, achieving significant time savings without sacrificing performance. This improved training efficiency makes the proposed method more practical for real-world applications, particularly where computational resources are limited.
More visual insights#
More on figures
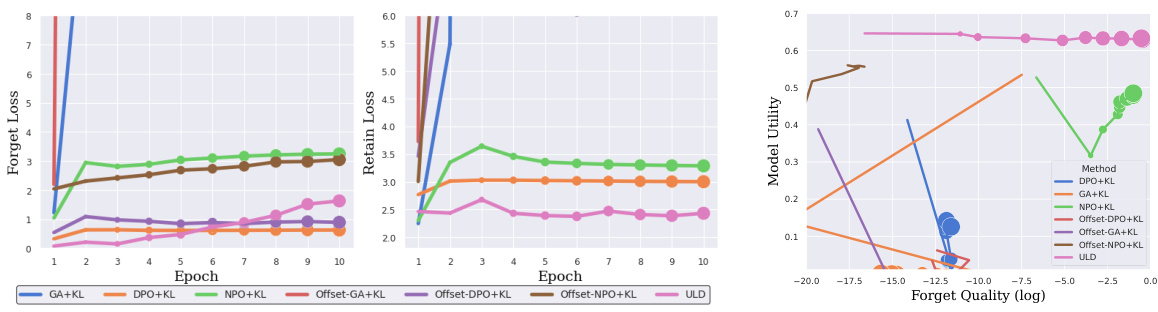
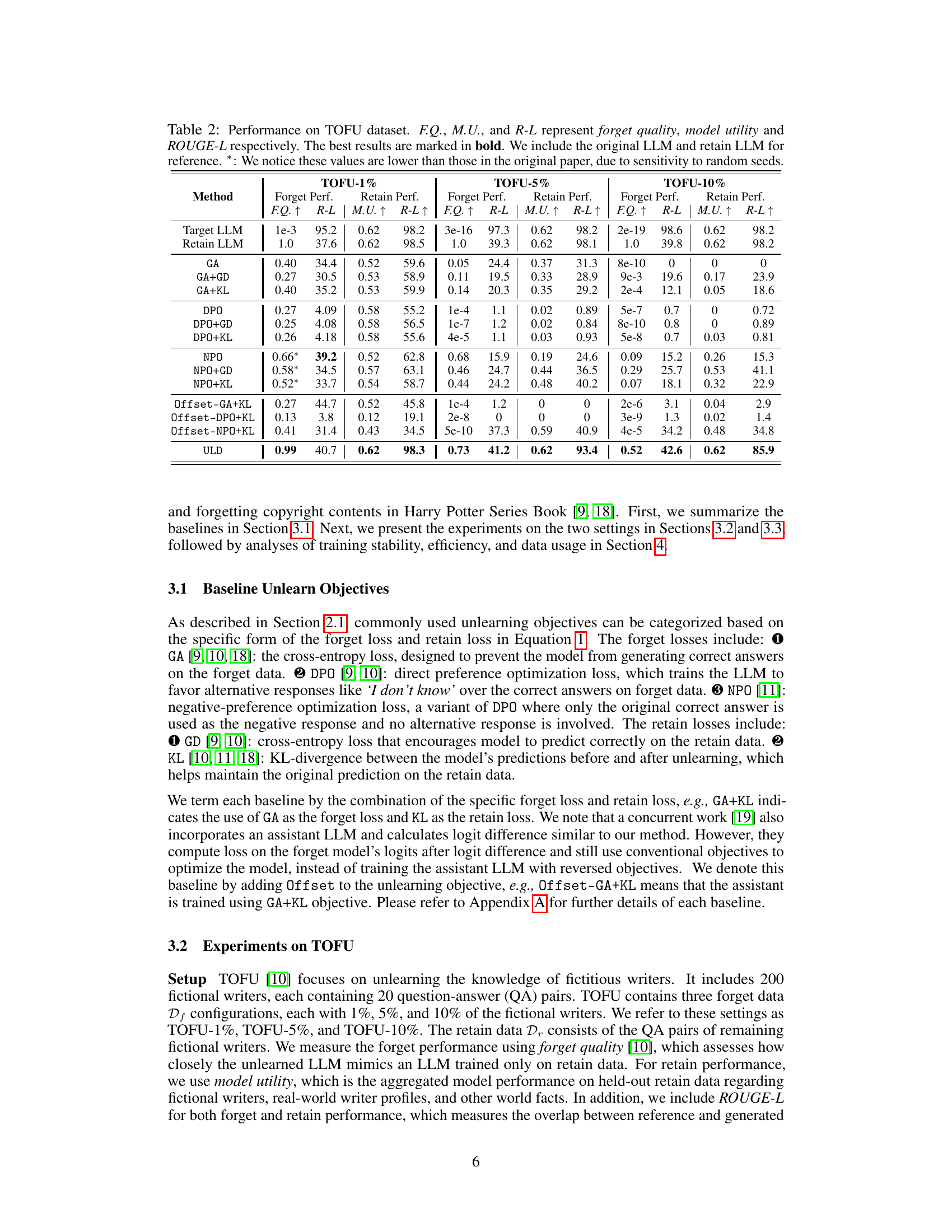
This figure shows the cross-entropy loss curves for different unlearning methods on both forget and retain data during the training process. The left panel displays the forget loss (on the forget data), highlighting that ULD’s loss remains bounded while others diverge. The right panel shows the retain loss (on the retain data not covered by the retain set), showing that ULD maintains stable loss while others increase rapidly, indicating catastrophic forgetting. Only baselines using the KL retain loss are included for clarity. The full results (including all baselines) are available in Appendix Figure 10.

This figure compares the training efficiency of different unlearning methods on the TOFU-10% dataset. The y-axis represents the forget quality (log scale), while the x-axis shows the relative training time per epoch compared to the ULD method. A point closer to the top-left corner signifies better forget performance and higher training efficiency. ULD is shown to be significantly more efficient than the other methods, achieving comparable or superior forget quality in much less training time.

This figure illustrates how the logit subtraction operation works in the Unlearning from Logit Difference (ULD) framework. It shows two examples. In the first, a query about Isaac Newton (forget data) is processed. Both the original and assistant LLMs have high probabilities for the correct answer (‘physicist’). The logit subtraction operation lowers the probability of the original LLM generating this answer, achieving the desired forgetting. In the second example, a query about Aristotle (retain data) is processed. The assistant LLM outputs a uniform distribution, meaning the subtraction does not change the distribution of the original LLM, preserving knowledge about Aristotle.

The figure shows how the logit subtraction operation works with the assistant LLM. Part (a) illustrates a query about forget data (Isaac Newton), where both the original and assistant LLMs have high probabilities for the correct answer (‘physicist’). Subtracting the assistant’s logits lowers the probability of the correct answer for the original LLM. Part (b) shows a query involving retain data (Aristotle), where the assistant LLM outputs a uniform distribution. Therefore, subtracting the assistant LLM’s logits doesn’t significantly change the original LLM’s output distribution.

This figure illustrates how the assistant LLM is constructed using the target LLM. The assistant LLM uses the first K layers of the target LLM’s transformer model, instead of training a completely separate model. The Language Model head is shared between the two LLMs. Only the added LoRA layers in the assistant LLM are optimized during training, making the training process more efficient.

This figure illustrates how the logit subtraction operation works in the Unlearning from Logit Difference (ULD) framework. It shows two examples: one for a query related to forget data (Isaac Newton), and one for a query related to retain data (Aristotle). In the forget data example, both the original LLM and the assistant LLM have high probabilities for the correct answer (‘physicist’). The logit subtraction reduces the original LLM’s probability for this correct answer, effectively making it forget the information. In the retain data example, the assistant LLM outputs a flat distribution, so the subtraction does not affect the original LLM’s output, preserving the knowledge.
This figure displays the cross-entropy (CE) loss curves for different unlearning methods during training. The left panel shows the loss on the forget data (Df), while the right panel shows the loss on the retain data not covered by the retain set (Dr). The figure highlights the training stability of ULD compared to baselines that use KL divergence for the retain loss. ULD shows stable and bounded loss curves, unlike baselines that exhibit instability and unbounded growth, particularly in the forget loss. The full results, including baselines that do not use KL divergence, can be found in Appendix Figure 10.
More on tables
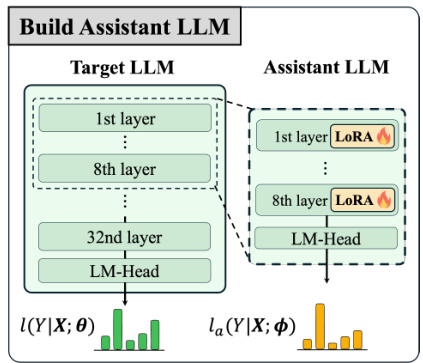
This table presents the quantitative results of the proposed Unlearning from Logit Difference (ULD) method and several baseline methods on the TOFU dataset for three different forget data sizes (1%, 5%, and 10%). The metrics reported include Forget Quality (F.Q.), measuring how well the model forgets the unwanted information; Model Utility (M.U.), measuring how well the model retains its overall knowledge; and ROUGE-L (R-L), a metric assessing the overlap between generated and reference texts. The table compares ULD’s performance against various baseline methods, demonstrating its effectiveness in balancing the trade-off between forgetting unwanted information and preserving useful knowledge. The asterisks (*) indicate values that differ from the original paper, attributed to random seed sensitivity.

This table presents the quantitative results of different LLM unlearning methods on the TOFU benchmark dataset. It compares the performance of several baseline methods (gradient ascent, direct preference optimization, negative preference optimization, and their combinations with different retain loss functions) against the proposed ULD method. The metrics used are Forget Quality (F.Q.), representing how well the model forgets the unwanted information; Model Utility (M.U.), indicating how well the model retains its overall capabilities; and ROUGE-L (R-L), a metric for evaluating the quality of generated text. The results are shown for three different settings of the TOFU dataset (1%, 5%, and 10% of data used for forgetting), allowing for a comparison of performance under varying levels of knowledge removal.
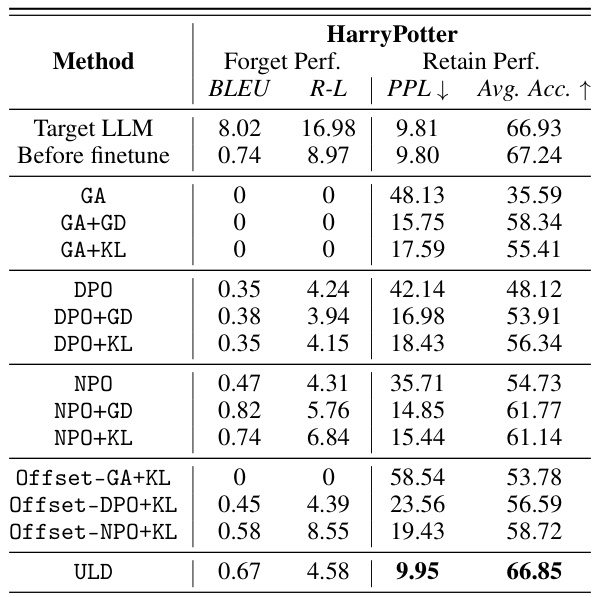
This table presents the quantitative results of different LLM unlearning methods on the TOFU benchmark dataset. It compares the performance of several baseline methods (e.g., GA+KL, DPO+KL, NPO+KL) against a proposed method (ULD) across three different forgetting ratios (1%, 5%, and 10%). The metrics used to evaluate performance are Forget Quality (F.Q.), representing the effectiveness of removing unwanted knowledge; Model Utility (M.U.), reflecting the preservation of useful knowledge; and ROUGE-L (R-L), measuring the overlap between generated text and reference text. The table demonstrates the trade-off between forgetting unwanted information and retaining useful information, highlighting the superiority of the ULD method.
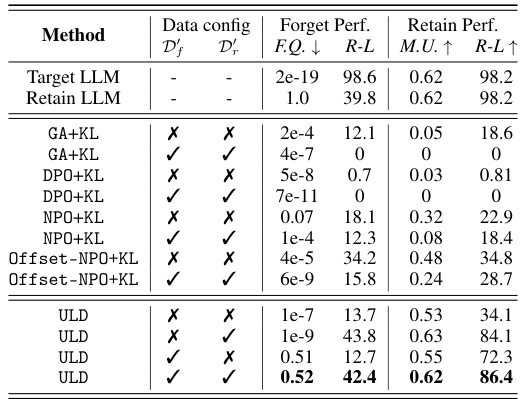
This table presents the quantitative results of different LLM unlearning methods on the TOFU benchmark dataset. It compares the performance of various methods across three different settings (TOFU-1%, TOFU-5%, TOFU-10%), each varying in the percentage of data used for forgetting. The metrics used to evaluate performance include Forget Quality (F.Q.), Model Utility (M.U.), and ROUGE-L (R-L). Higher F.Q. and M.U. scores indicate better unlearning performance, while higher ROUGE-L suggests higher similarity between the generated and reference text. The results highlight that ULD achieves superior performance in all settings.
This table presents the quantitative results of the proposed ULD method and several baseline methods on the TOFU dataset. The TOFU dataset is designed to evaluate LLM unlearning by measuring the ability of a model to forget information about fictional writers while retaining knowledge about other topics. The table shows the performance of each method across three different settings (TOFU-1%, TOFU-5%, TOFU-10%), each representing a different percentage of fictional writers to be forgotten. Metrics include Forget Quality (F.Q.), which measures how well the model forgets the target information; Model Utility (M.U.), which indicates how well the model retains other knowledge; and ROUGE-L, which is a metric assessing the overlap between the model’s generated text and the reference text. The best performance for each metric in each setting is highlighted in bold. The table also includes the performance of the original LLM and a retain LLM (trained only on the retain data) as references.
This table presents the quantitative results of different LLM unlearning methods on the TOFU benchmark dataset. It compares the Forget Quality (F.Q.), Model Utility (M.U.), and ROUGE-L scores across various methods and different dataset sizes (TOFU-1%, TOFU-5%, TOFU-10%). Higher F.Q. indicates better forgetting of the target knowledge, higher M.U. represents better retention of other knowledge, and higher ROUGE-L signifies better response quality. The table includes results for the original LLM and a retain-only LLM as baselines for comparison. Note that some values are lower than in the original paper due to variations caused by the use of random seeds in the experiment.

This table presents the quantitative results of different LLM unlearning methods on the TOFU benchmark dataset. It compares the performance of various methods across three different forget data sizes (1%, 5%, and 10% of the dataset), evaluating both the Forget Quality (how well the model forgets the target information) and Retain Performance (how well the model retains other knowledge). Metrics include Forget Quality (F.Q.), ROUGE-L (R-L) for both forget and retain, and Model Utility (M.U.). The best performing method for each metric in each setting is highlighted in bold. The table also shows the original LLM’s performance and a retain-only LLM as baselines for comparison.
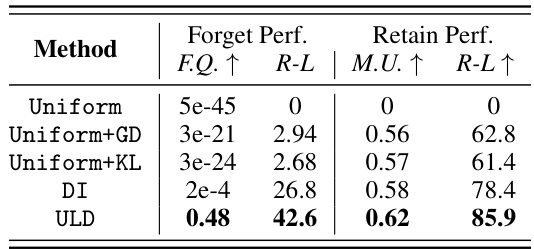
This table presents the quantitative results of the proposed ULD method and several baseline methods on the TOFU dataset. It shows the forget quality (F.Q.), measured by how well the model forgets the unwanted knowledge, and the retain performance (M.U.), which assesses how well the model retains useful knowledge. ROUGE-L (R-L) scores are provided for both forget and retain tasks. The table compares performance across three different forget data sizes (TOFU-1%, TOFU-5%, TOFU-10%). The best results for each metric are highlighted in bold. The original LLM and a retain-only LLM are included for comparison.

This table presents the performance of the ULD model on the TOFU-10% dataset when varying the ratio of regular retain data used during training. It compares the forget quality (how well the model forgets the knowledge in the forget data) and model utility (how well the model retains its knowledge on other tasks) of ULD with different percentages of the regular retain data (0%, 25%, 50%, 75%). The results are compared against a target LLM (fully trained) and a retain LLM (trained only on retain data) to provide a baseline.

This table presents the quantitative results of different LLM unlearning methods on the TOFU benchmark dataset. It compares the performance across three different settings (TOFU-1%, TOFU-5%, TOFU-10%) representing varying amounts of data to be forgotten. The key metrics are Forget Quality (F.Q.), indicating how well the model forgets the unwanted knowledge; Model Utility (M.U.), showing the model’s performance on data it should retain; and ROUGE-L (R-L), measuring the overlap between generated and reference text. The table helps in assessing the trade-off between forgetting unwanted information and preserving useful knowledge across different unlearning techniques. The asterisk (*) notes that some results vary from previous work likely due to random seed differences.
Full paper#