↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual learning typically involves jointly training representations and classifiers, assuming learned representations outperform fixed ones. This paper empirically challenges this assumption by introducing RanDumb, a method that uses fixed random transforms to project raw pixels into a high-dimensional space before training a simple linear classifier. RanDumb surprisingly outperforms state-of-the-art continual learning methods across standard benchmarks. This finding reveals that existing online continual learning methods may struggle to learn effective representations, particularly in low-exemplar scenarios.
RanDumb’s success stems from its simplicity and efficiency. It doesn’t store any exemplars and processes one sample at a time, making it ideal for online learning with limited resources. The study expands to pretrained models where only a linear classifier was trained on top; the results demonstrate that this approach surpasses most continual fine-tuning strategies. This strongly suggests that the focus should shift towards better understanding and improving the efficacy of representation learning rather than solely focusing on catastrophic forgetting prevention.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the conventional wisdom in continual learning, particularly regarding representation learning. By demonstrating the surprising superiority of simple random projections over complex, continually learned representations, it opens avenues for more efficient and effective continual learning methods. It also highlights the limitations of current benchmarks and encourages researchers to explore new evaluation strategies. This is especially important given the increasing interest and applications of continual learning in various domains.
Visual Insights#
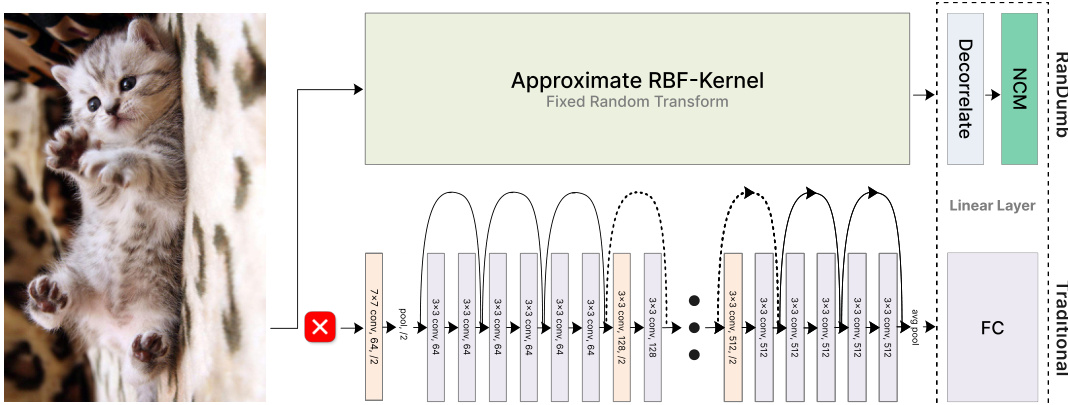
This figure compares a standard deep learning model for continual learning with RanDumb, a novel approach proposed in the paper. The standard model consists of a deep convolutional neural network that learns representations and classifiers simultaneously. In contrast, RanDumb uses a fixed, random transformation to project the input pixels into a high-dimensional space. It then decorrelates the features and uses a simple nearest class mean classifier. The figure highlights the surprising finding that the simple RanDumb model outperforms the complex deep learning model, suggesting that continually learning representations may not be as effective as previously thought.
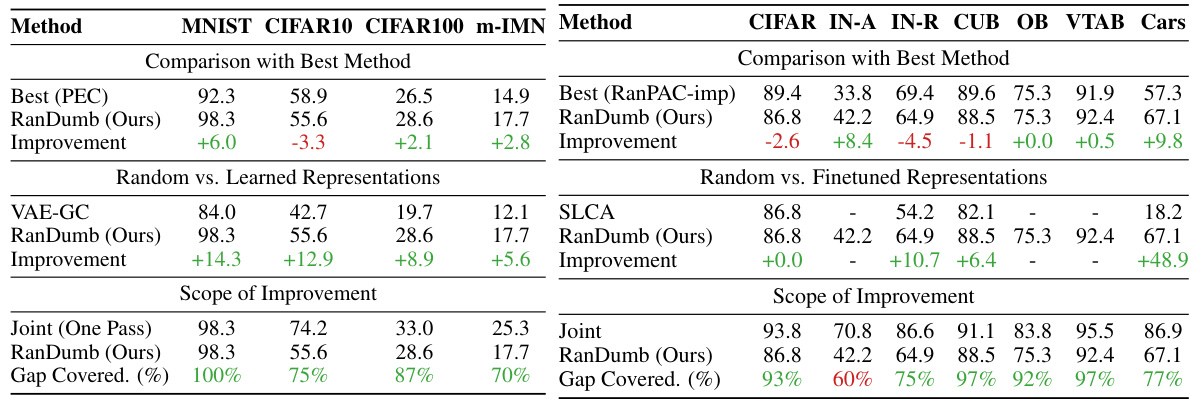
This table presents a comparison of RanDumb’s performance against other state-of-the-art online and offline continual learning methods. The left side shows RanDumb’s superiority in online learning scenarios, outperforming existing methods on various benchmarks. The right side demonstrates that RanDumb achieves near-identical performance to the joint training approach in offline learning, challenging the effectiveness of the continual representation learning techniques used in other methods.
In-depth insights#
RanDumb’s Design#
RanDumb’s design is deceptively simple yet powerfully effective. It cleverly sidesteps the complexities of continually learning representations by using random Fourier features to map raw pixel data into a high-dimensional space. This acts as a fixed, data-independent approximation of an RBF kernel, eliminating the need for continual adaptation of the representation itself. The subsequent classification uses a linear classifier operating on these random projections, enhancing efficiency and mitigating catastrophic forgetting. The ingenious use of Mahalanobis distance decorrelates the feature dimensions, enabling improved separability between classes. This streamlined design, requiring no exemplar storage and only a single pass over the data, makes RanDumb remarkably efficient for online continual learning, while surprisingly outperforming more complex state-of-the-art approaches.
Rep Learning Limits#
The heading ‘Rep Learning Limits’ suggests an investigation into the boundaries of representational learning, particularly within the context of continual learning. The core argument likely revolves around the inadequacy of learned representations in online continual learning scenarios, where models must adapt incrementally to sequentially arriving data streams without catastrophic forgetting. The research probably demonstrates that continually learned representations, despite being jointly optimized with classifiers, underperform in comparison to simpler, pre-defined representations, such as random projections. This challenges the prevailing assumption that continually learning representations is crucial for effective online adaptation and highlights the importance of alternative approaches, like directly using pre-trained representations or fixed random transforms, potentially emphasizing their computational efficiency and ease of implementation. Low-exemplar regimes are likely to be a key area of focus, as the limited data availability in online learning might hinder the capability of deep networks to learn effective representations. The findings may propose that simpler approaches are surprisingly effective, suggesting that current continual learning benchmarks may be overly restrictive, thereby necessitating more realistic and less constrained evaluations.
Benchmark Critique#
The paper’s “Benchmark Critique” section would thoughtfully analyze the limitations of existing continual learning benchmarks. It would likely argue that current benchmarks, often focusing on high-exemplar or offline settings, don’t adequately capture the challenges of online continual learning with low-exemplar scenarios. The authors would demonstrate how these benchmarks fail to differentiate effective representation learning strategies from simpler baselines. Overly restrictive constraints, such as those on memory and computational resources, mask the true capabilities of representation learning algorithms. The critique would emphasize the need for benchmarks that better reflect the real-world constraints of online continual learning, ultimately advocating for a shift towards more realistic and less constrained evaluation protocols to facilitate fairer comparisons and promote more robust continual learning advancements. Such a critique would highlight the need for a nuanced understanding of the limitations of current evaluations, thereby providing valuable guidance for future benchmark design and algorithm development. A key insight would be the discovery that current metrics may inadvertently reward approaches that address the limitations of the benchmark rather than truly advancing the state-of-the-art in representation learning.
Pre-trained Feature Use#
The utilization of pre-trained features presents a compelling avenue for enhancing continual learning performance. Leveraging a pre-trained model’s feature extractor as a fixed representation, rather than continually training it, introduces a degree of stability and efficiency. This approach sidesteps the challenges of catastrophic forgetting and the associated stability-plasticity trade-off inherent in continual representation learning. By freezing the pre-trained weights, the model’s initial representational capacity is harnessed effectively, allowing the focus to shift to learning task-specific classifiers. This method often surpasses continual fine-tuning and prompt-tuning strategies, underscoring that continually learning representations may not always be advantageous. The results suggest that, under certain circumstances, carefully selected pre-trained features offer a powerful alternative to complex continual learning strategies, achieving comparable or superior results with reduced computational cost and enhanced stability.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Developing a more robust theoretical framework to explain why randomly generated representations outperform learned representations in online continual learning settings is crucial. This would involve investigating the interplay between the inherent properties of data distributions, the learning algorithm, and the capacity of the representation to capture relevant information. Investigating alternative embedding techniques beyond random Fourier features, such as learned embeddings with specific inductive biases tailored for continual learning, would be beneficial. Examining the effect of different architectures and their impact on the effectiveness of random projections is another important direction. Further exploration of the trade-off between computational cost and representational power by varying the dimensionality of the random projection is needed. Lastly, it would be valuable to expand these findings to broader continual learning scenarios, including tasks with more complex relationships between classes or settings with varying levels of data availability per class.
More visual insights#
More on figures
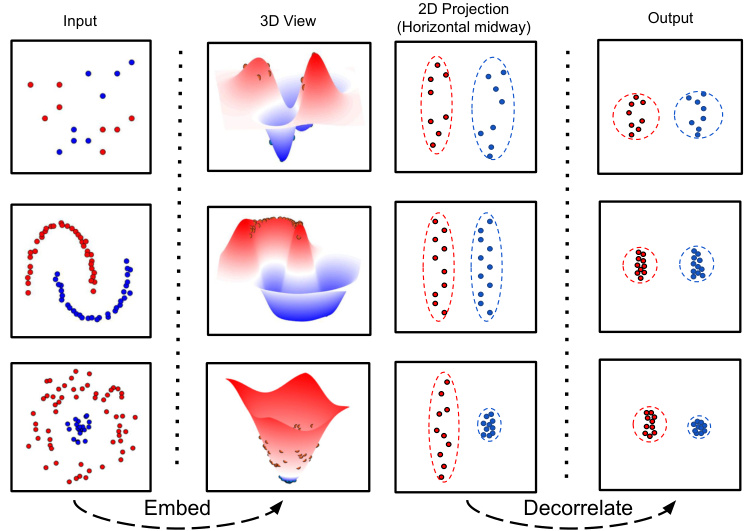
This figure shows how RanDumb improves class separation. It starts with data points in a low-dimensional space where classes overlap (Input). RanDumb projects these points into a high-dimensional space using a random projection, resulting in better separation (Embed). Then, it decorrelates the features by scaling each dimension to have unit variance (Decorrelate), which further enhances the separation of classes, enabling more accurate classification using simple nearest class mean methods (Output). The 3D view provides a visual representation of the data in both the original and transformed spaces, illustrating how the process improves class separability.
This figure illustrates the core concept of the RanDumb method and compares it to traditional online continual learning methods. It shows how RanDumb replaces a deep feature extractor with a random projection, which projects raw image pixels into a high-dimensional space using random Fourier projections. Then, it decorrelates the features and classifies based on the nearest class mean. The figure highlights that this simple method surprisingly outperforms the continually learned representations of deep networks.
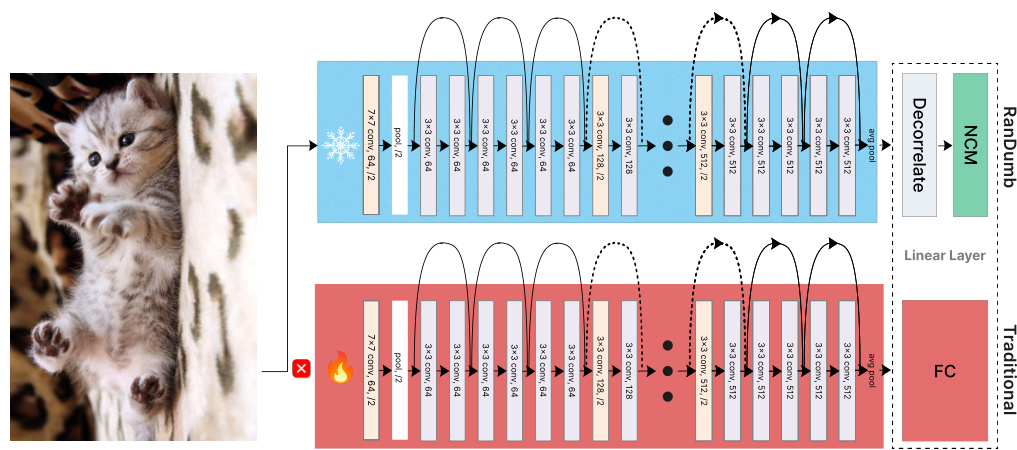
This figure compares a standard deep learning architecture with RanDumb. The standard architecture uses a deep feature extractor to learn representations and a classifier to learn the model. RanDumb replaces the deep feature extractor with a random projection, highlighting that the representation learned by the deep feature extractor is not superior to a simple random projection. The comparison demonstrates that random projection outperforms standard continual learning approaches.
More on tables
This table presents a comparison of RanDumb’s performance against other state-of-the-art methods in both online and offline continual learning scenarios. The left side shows RanDumb significantly outperforming existing online continual learning methods on the PEC benchmark. The right side demonstrates RanDumb achieving comparable performance to the best joint training methods in offline continual learning, even when using pre-trained models, thus challenging the effectiveness of current continual representation learning techniques.
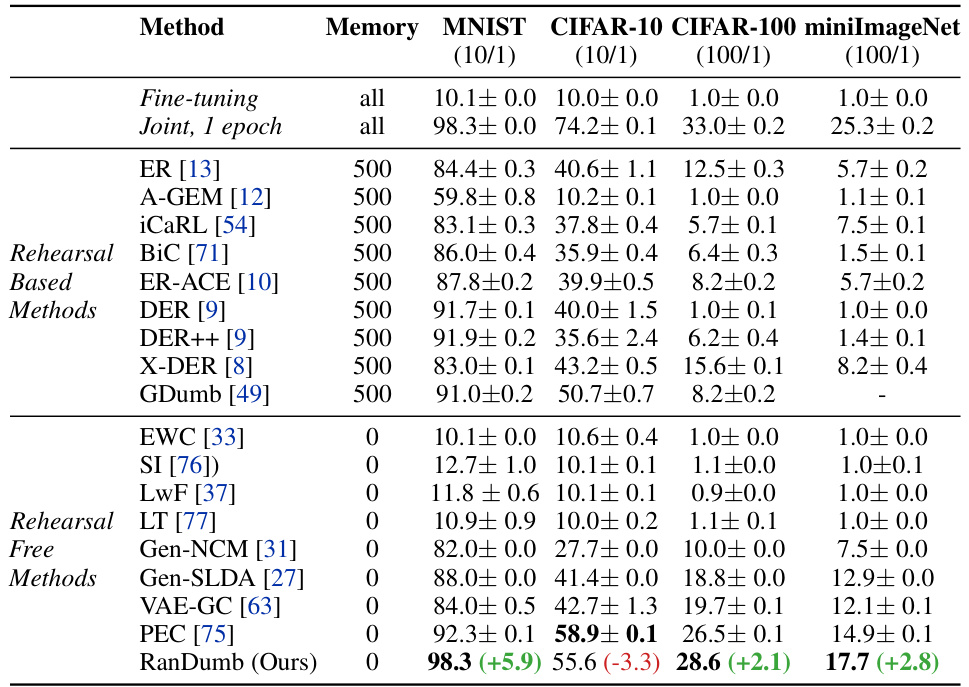
This table presents a comparison of RanDumb’s performance against other state-of-the-art online and offline continual learning methods on various benchmark datasets. The left side shows results for online learning, comparing RanDumb to VAE-GC and the best-performing method from the PEC benchmark. The right side shows results for offline continual learning, comparing RanDumb to RanPAC-imp and joint training (a non-continual learning approach). The results demonstrate that RanDumb significantly outperforms existing methods in both online and offline settings, highlighting the sub-optimality of continually learned representations.
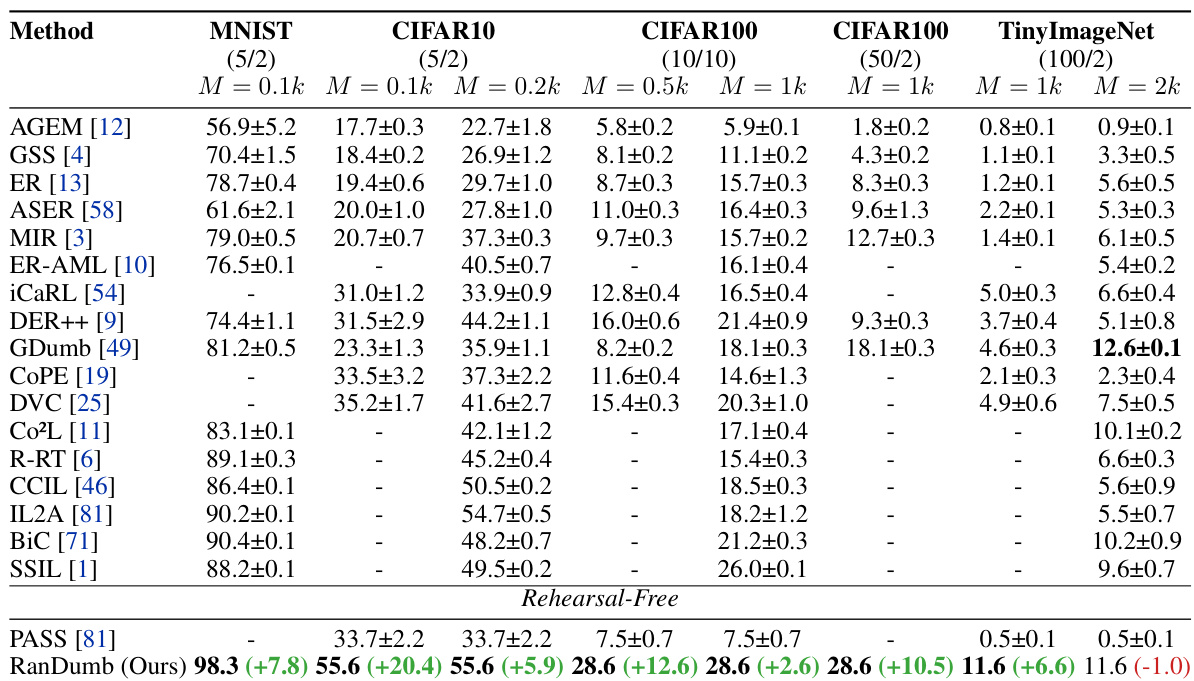
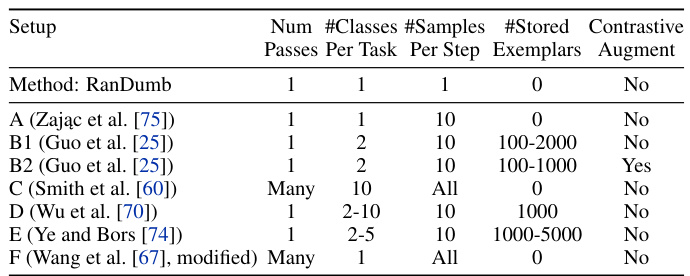
This table presents a comparison of RanDumb’s performance against other methods on Benchmark B.1, which involves multiple classes per task. The results show that RanDumb significantly outperforms most competing methods, especially those without extensive data augmentation, achieving improvements ranging from 3% to 20%. RanDumb only falls short of one method in a single instance.

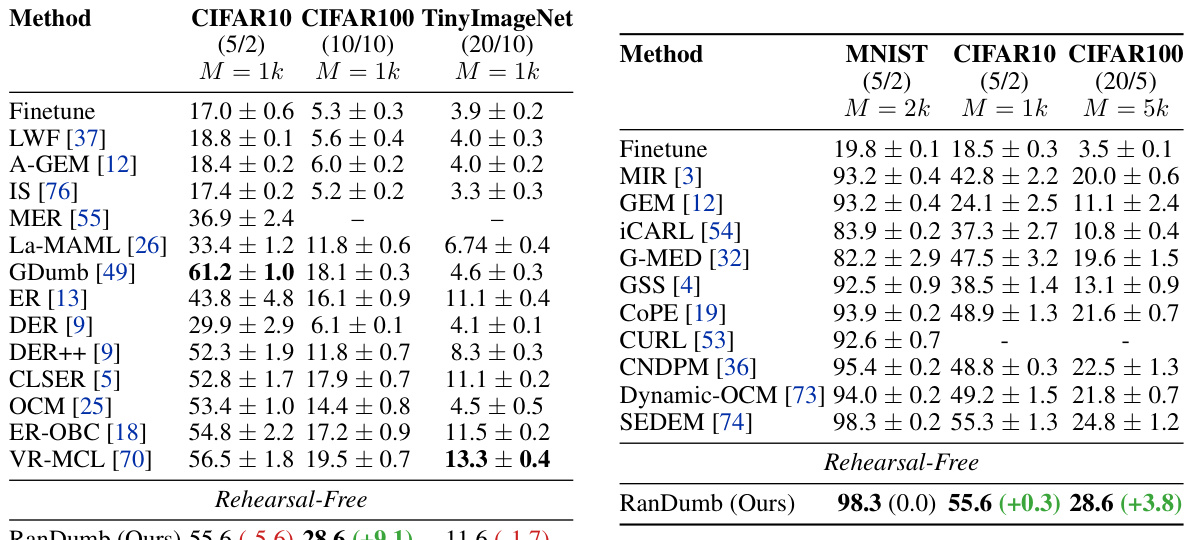
This table presents a comparison of RanDumb’s performance against other continual learning methods on two benchmarks: B.2 and C. Benchmark B.2 compares RanDumb to methods that use contrastive representation learning and sophisticated augmentations, focusing on small-exemplar settings. Benchmark C compares RanDumb to rehearsal-free methods, demonstrating its superior performance by a 4% margin.
This table presents a comparison of RanDumb’s performance against other methods on benchmark B.1, which involves multiple classes per task. RanDumb consistently outperforms most competing methods by a significant margin (3-20%), even without employing heavy augmentations or exemplar storage, showcasing its effectiveness in low-memory scenarios.
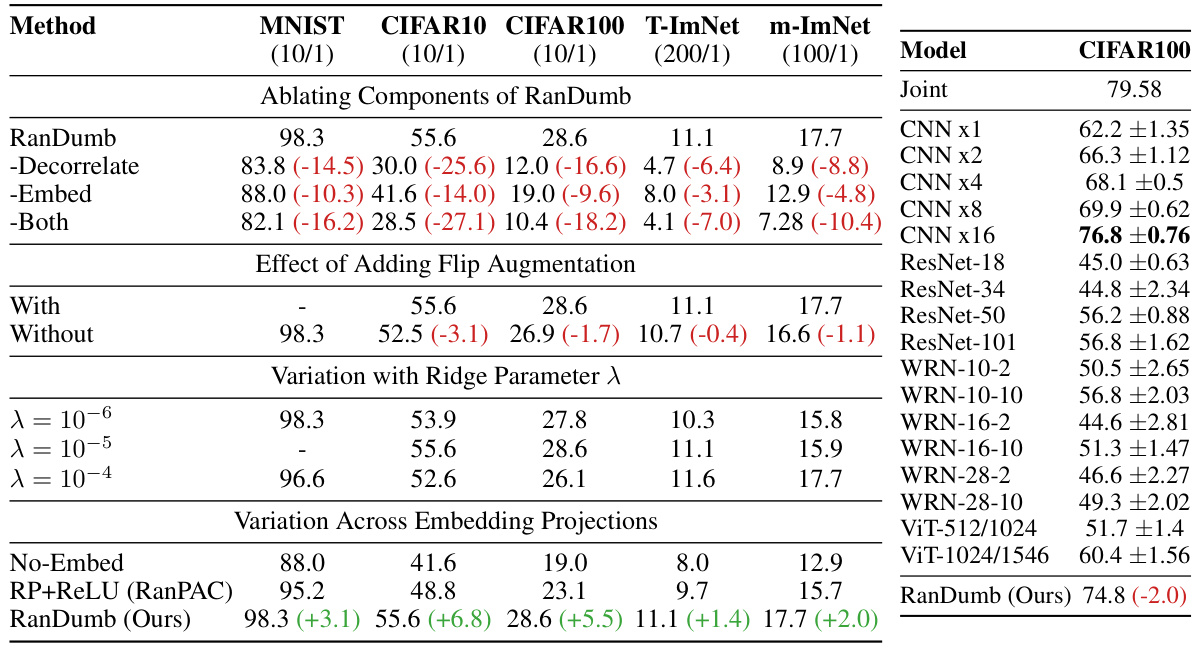
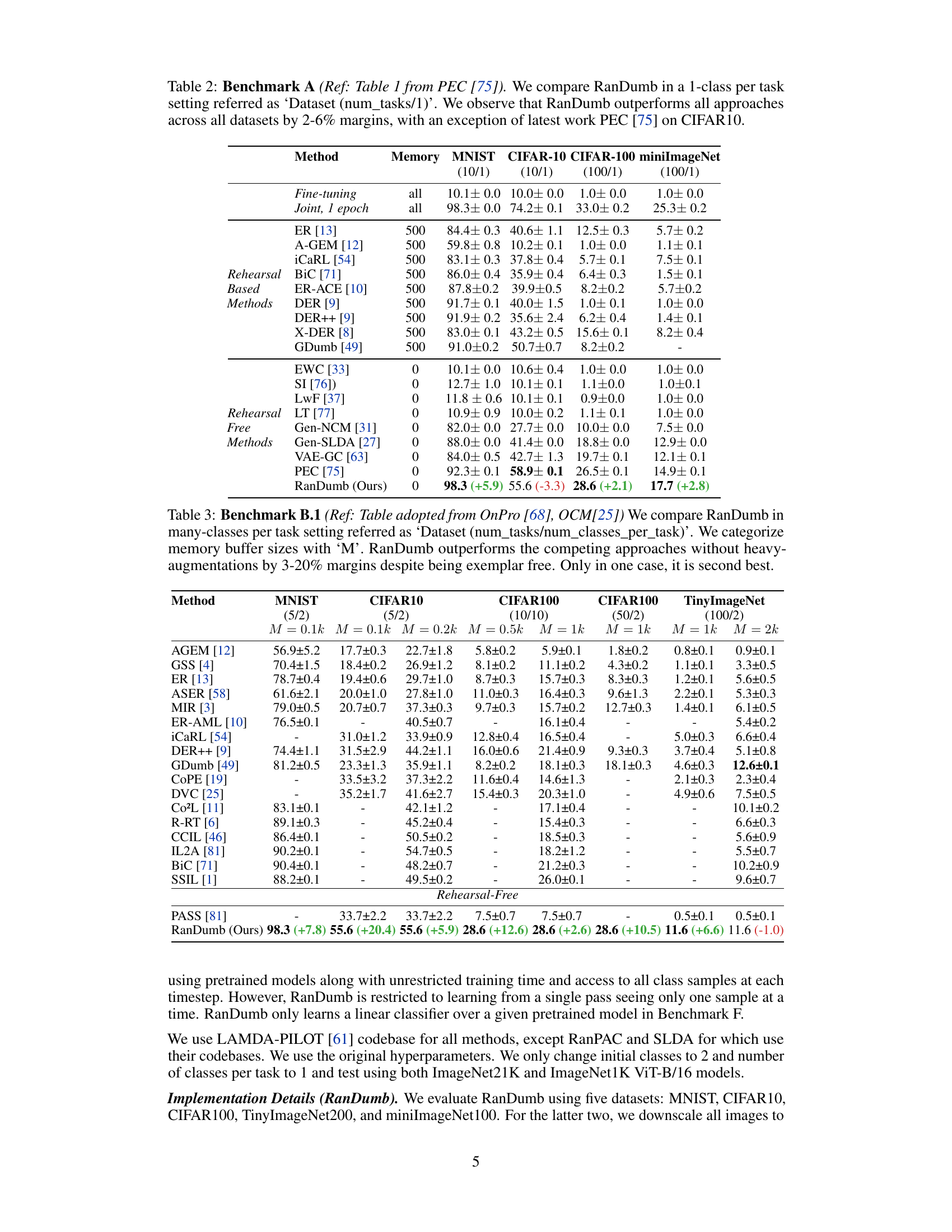
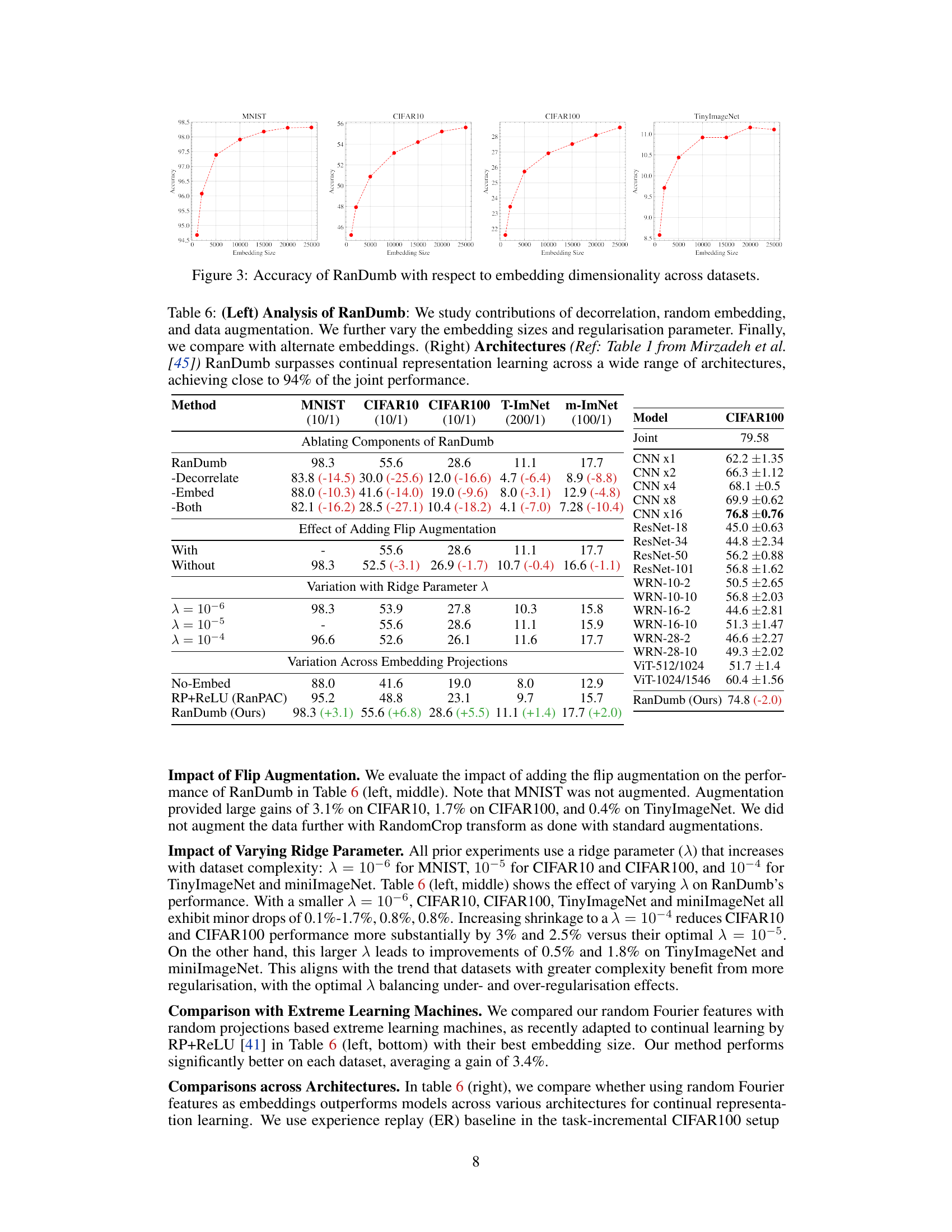
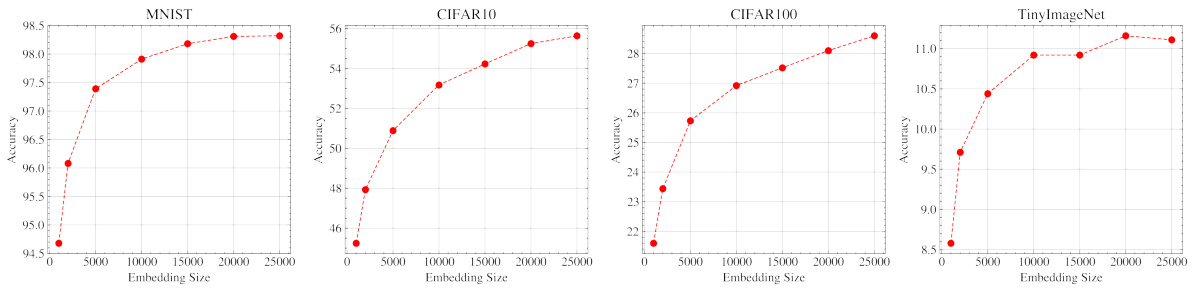
This table presents the ablation study of RanDumb’s components (decorrelation, random embedding, data augmentation) and its performance variation with different embedding sizes and regularization parameters. It also compares RanDumb’s performance with alternative embedding methods and shows RanDumb’s superior performance across various architectures in continual representation learning, achieving nearly 94% of the performance of the joint model.
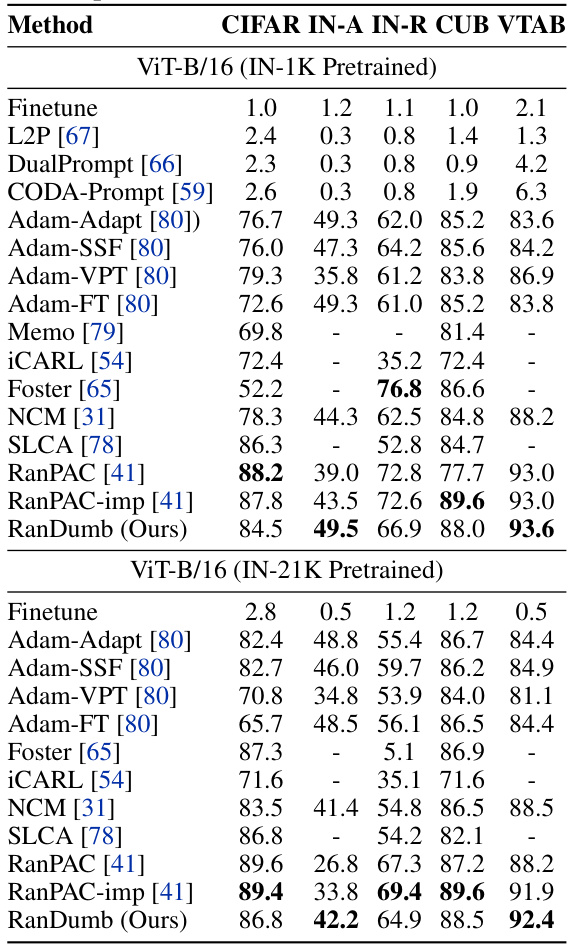
This table presents the results of comparing RanDumb’s performance against various prompt-tuning approaches on benchmark F. The benchmark uses pre-trained ViT-B/16 models with ImageNet-21K/1K weights, a setup of two initial classes followed by one class per task. The results show that many prompt-tuning methods struggle, while RanDumb consistently achieves either state-of-the-art or very close to state-of-the-art results, highlighting its effectiveness even when compared to methods that fine-tune pre-trained models. The inclusion of RanPAC-imp, an improved version of RanPAC, adds context to the performance comparisons.
Full paper#