↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Real-time object detection is crucial for various applications, and YOLO series have emerged as a leading approach due to their balance of speed and accuracy. However, current YOLO models rely on Non-Maximum Suppression (NMS), a post-processing step that hinders end-to-end deployment and impacts inference latency. Moreover, design inefficiencies within various components of YOLO models limit their potential for performance improvement.
This paper introduces YOLOv10, addressing these limitations. YOLOv10 uses a novel training method that eliminates the need for NMS, significantly boosting speed. It also employs a holistic design strategy that comprehensively optimizes various model components, leading to improved accuracy and reduced computational overhead. The method’s effectiveness is demonstrated through experiments showing state-of-the-art performance across various model scales, exceeding other models in speed and efficiency while maintaining high accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in real-time object detection. It significantly advances the performance and efficiency of YOLO models by introducing a novel NMS-free training strategy and a holistic efficiency-accuracy driven model design. The state-of-the-art results achieved across various model scales highlight its immediate applicability and inspire further research into performance optimization for real-time object detection. This opens avenues for exploring consistent dual assignments, lightweight model components, large kernel convolutions, and partial self-attention mechanisms to improve efficiency and accuracy.
Visual Insights#
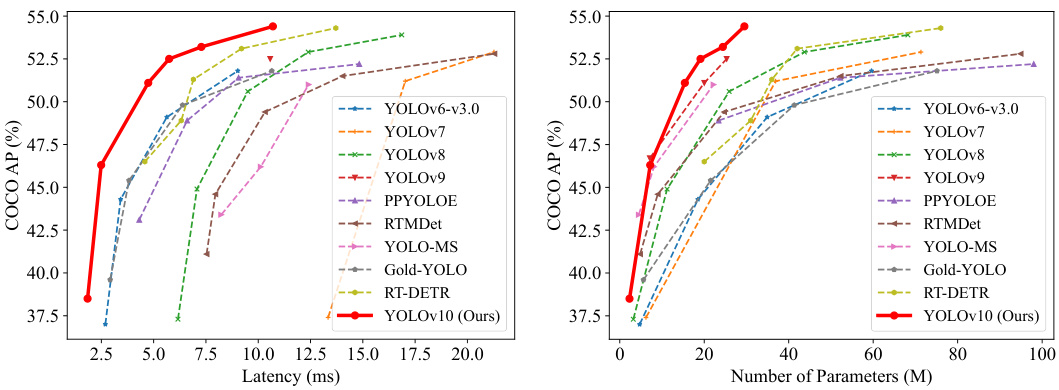
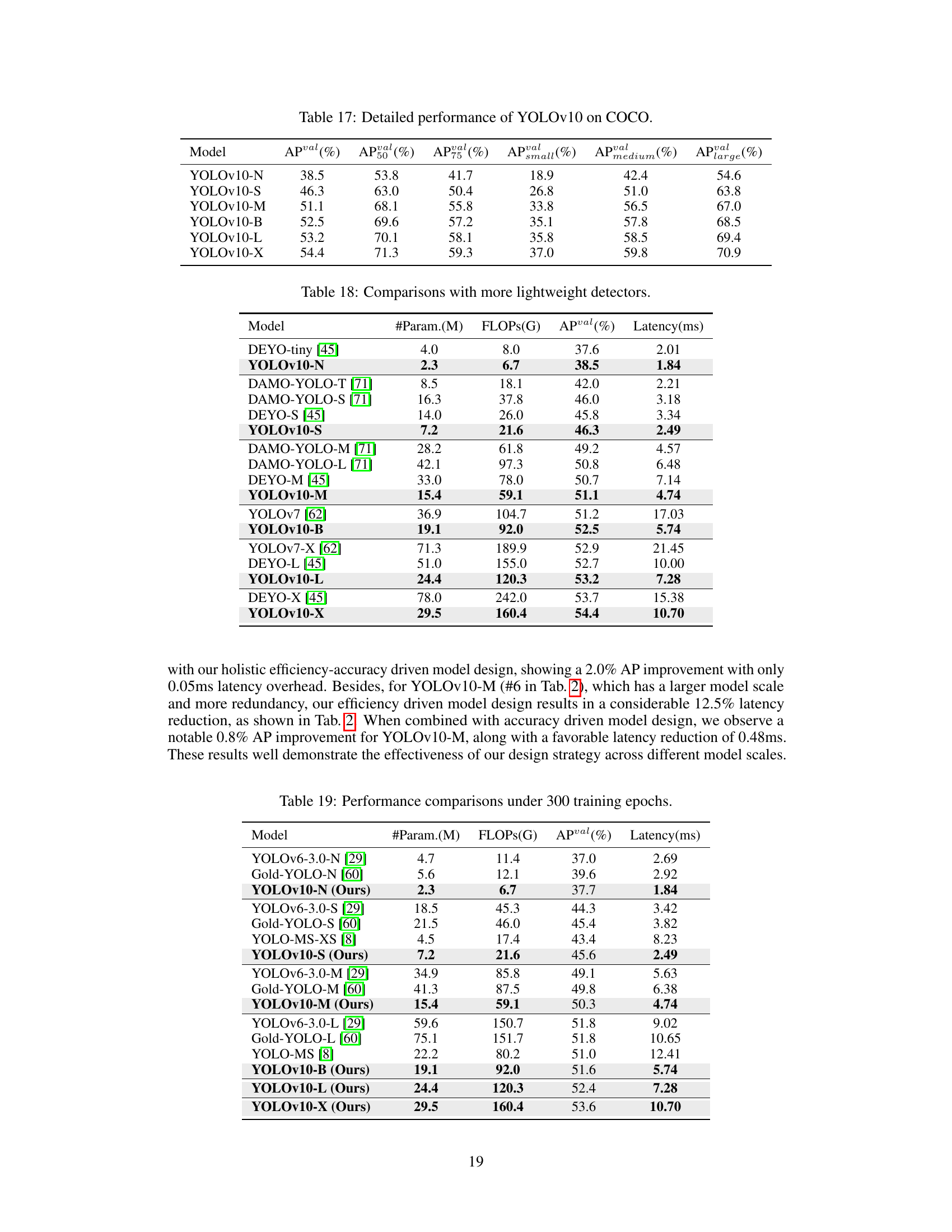
This figure compares YOLOv10 with other state-of-the-art real-time object detection models. The left graph shows the trade-off between latency (inference speed) and accuracy (mAP). The right graph displays the trade-off between model size (number of parameters) and accuracy. YOLOv10 demonstrates a favorable balance across various scales, achieving both high accuracy and efficiency.
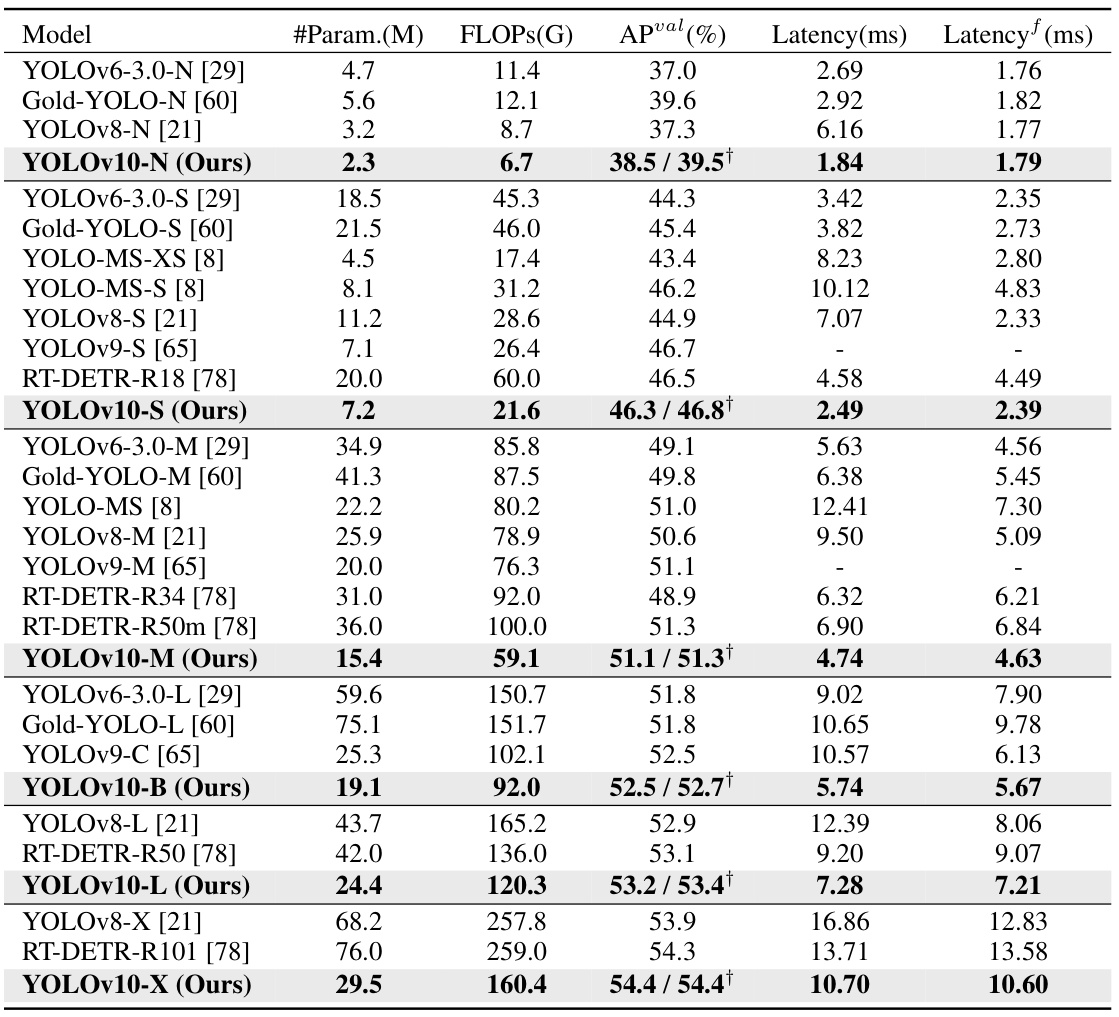
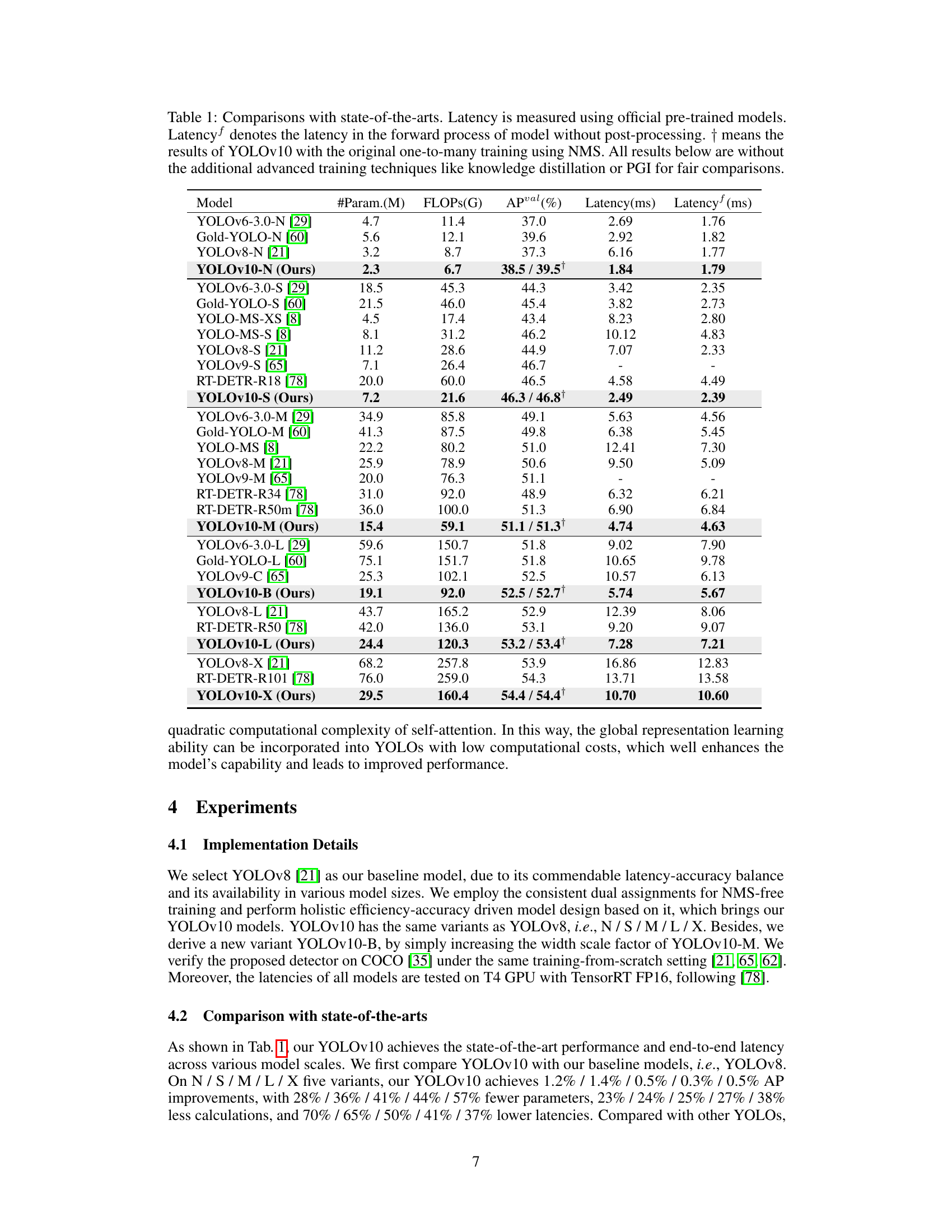
This table compares the performance of YOLOv10 with other state-of-the-art real-time object detection models across various scales (N, S, M, L, X). Metrics include the number of parameters (#Param.), Giga Floating Point Operations (FLOPs), average precision (APval), end-to-end latency (Latency), and latency of the forward pass only (Latencyf). The table highlights YOLOv10’s improved speed and efficiency while maintaining competitive accuracy, showcasing its advantages over existing models.
In-depth insights#
NMS-Free YOLO#
The concept of “NMS-Free YOLO” addresses a critical limitation in traditional YOLO object detection models: the reliance on Non-Maximum Suppression (NMS) for post-processing. NMS, while effective at eliminating redundant bounding boxes, introduces computational overhead and hinders true end-to-end optimization. A NMS-free approach aims to integrate the suppression of redundant predictions directly into the model’s training and architecture. This is achieved through modifications to the loss function and potentially architectural changes like different label assignment strategies (e.g., one-to-one assignments instead of one-to-many). The benefits include faster inference speeds and improved efficiency, leading to a more streamlined and optimized object detection pipeline. Challenges in designing NMS-free YOLO methods involve ensuring the model can effectively learn to suppress redundant detections during training without sacrificing detection accuracy. The key is to achieve a balance where the model’s learning is sufficiently guided to generate high-quality, non-redundant predictions, avoiding the need for a computationally expensive post-processing step. Success in this area would represent a significant advance in real-time object detection.
Dual Label Assign#
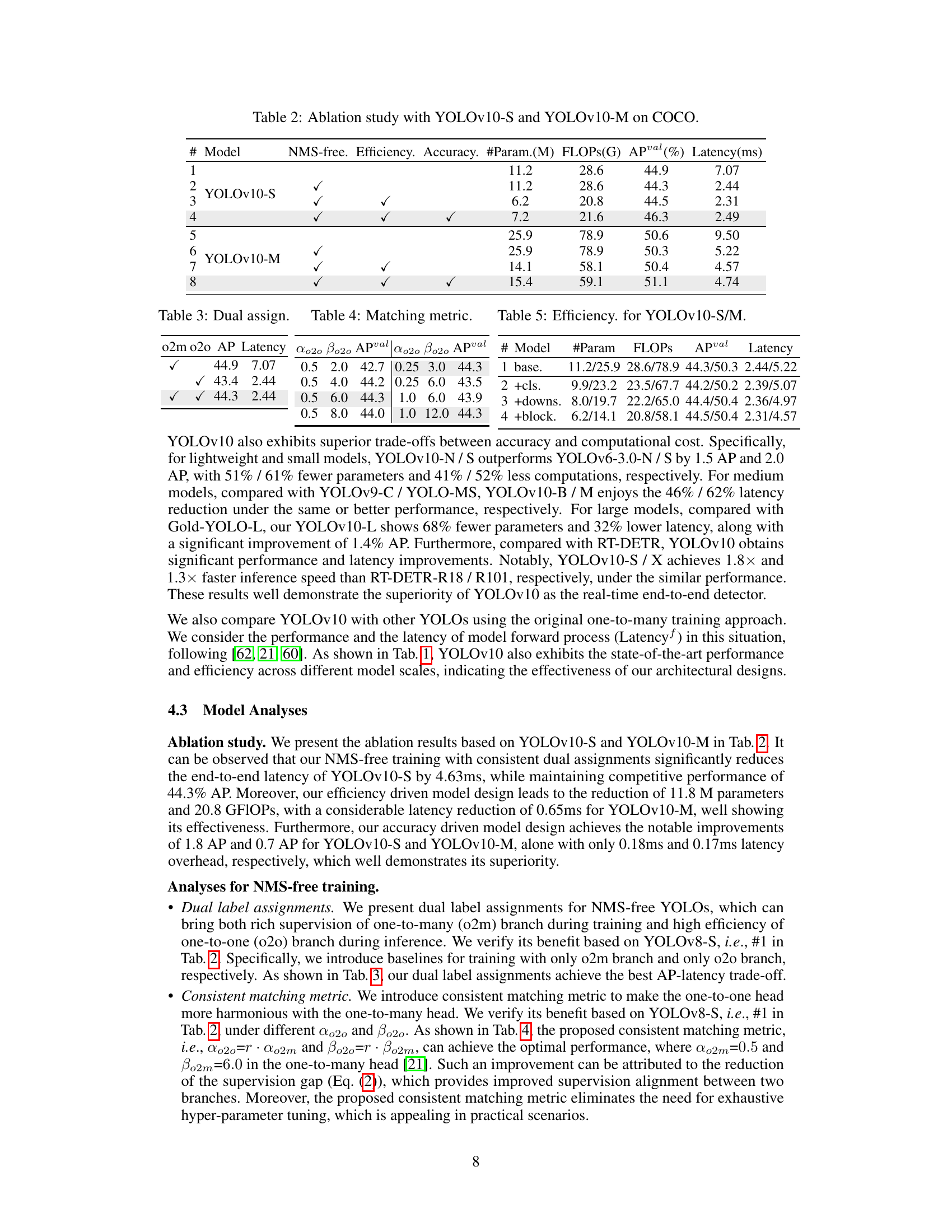
The concept of ‘Dual Label Assignment’ in object detection aims to improve training efficiency and accuracy by employing two distinct label assignment strategies simultaneously. One-to-many assignment, a common technique in YOLO-type detectors, provides rich supervision but requires post-processing with Non-Maximum Suppression (NMS), impacting speed. One-to-one assignment, on the other hand, offers an end-to-end solution, eliminating NMS, but suffers from weak supervision during training due to limited label pairings. By merging both methods, ‘Dual Label Assignment’ leverages the strengths of each: the plentiful training signals from one-to-many and the streamlined inference of one-to-one. A crucial element is a consistent matching metric, ensuring the two heads are harmoniously optimized and reducing the need for hyperparameter tuning and improving overall model performance.
Efficient YOLOv10#
The concept of “Efficient YOLOv10” suggests a focus on optimizing the YOLO object detection model for speed and resource efficiency without sacrificing accuracy. This likely involves several key strategies: architectural modifications to reduce computational complexity (e.g., using lightweight layers, efficient attention mechanisms, or reduced feature map resolutions); optimized training techniques to accelerate convergence and improve generalization (e.g., advanced loss functions, regularization methods, or data augmentation strategies); and post-processing enhancements to minimize latency (e.g., efficient non-maximum suppression or alternative bounding box refinement approaches). The goal is to create a real-time object detector that performs well even on devices with limited processing power or memory, making it suitable for applications like mobile devices or embedded systems. The “10” designation implies this is potentially a more recent iteration building on the advancements of previous YOLO versions, integrating best practices and further improvements to achieve state-of-the-art efficiency. A successful implementation would be a significant contribution to real-time computer vision.
Accuracy Enhance#
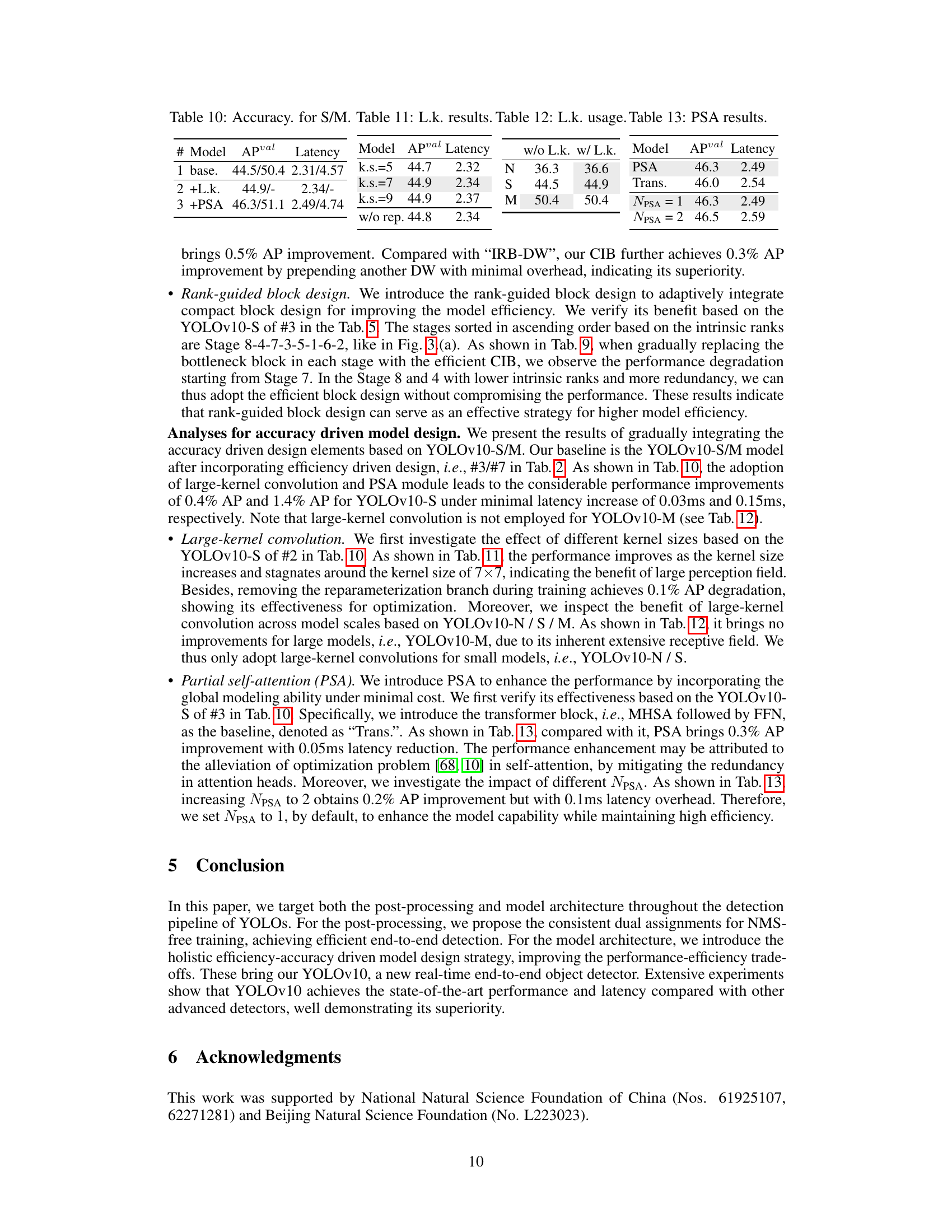
Enhancing accuracy in object detection models is a crucial area of research, and strategies for achieving this often involve intricate architectural designs and training methodologies. Large-kernel convolutions offer a path to improved accuracy by expanding the receptive field, enabling the model to capture more contextual information crucial for precise object localization. However, simply increasing kernel size can be computationally expensive. Therefore, careful considerations regarding computational cost and effective implementation are necessary. Self-attention mechanisms, while powerful, introduce significant computational overhead, especially with high-resolution images. Partial self-attention techniques aim to mitigate this by selectively focusing on crucial parts of the feature maps, significantly improving efficiency without substantial accuracy trade-offs. These techniques show promise but require careful tuning and optimization to achieve optimal performance gains.
Future Works#
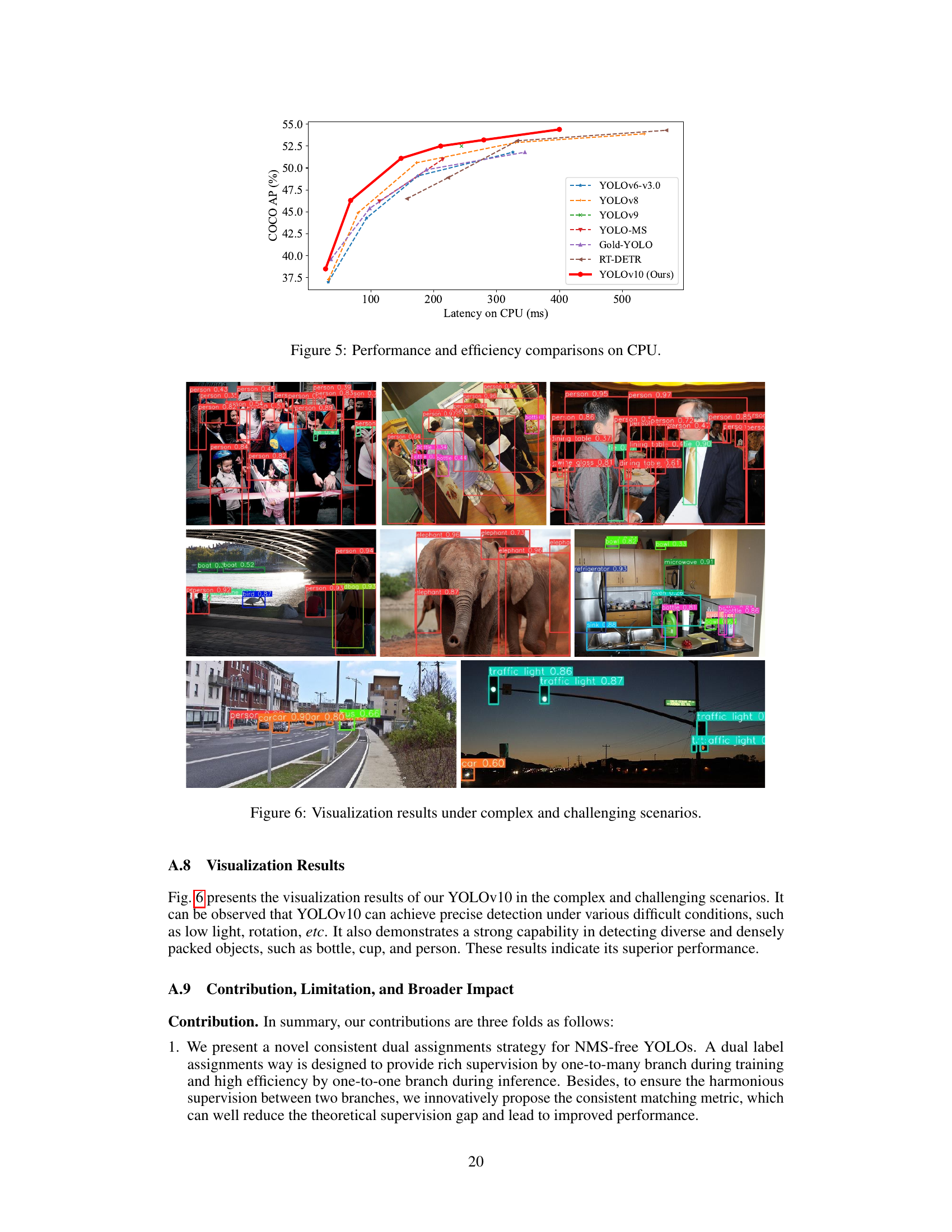
Future research directions stemming from this YOLOv10 model could explore several promising avenues. Improving the end-to-end performance, particularly closing the gap observed between the proposed NMS-free training and traditional one-to-many training, is crucial. Investigating more sophisticated matching methods or architectural modifications to enhance feature discriminability could be key. Extending the model’s capabilities to handle more challenging scenarios (e.g., extreme weather conditions, extreme object occlusion) would significantly enhance its real-world applicability. Exploring more efficient training strategies, possibly using advanced techniques like quantization or pruning to reduce the computational costs associated with the dual head approach, remains an open area. Finally, thorough investigation into the model’s robustness and potential biases, alongside the development of effective mitigation strategies, is essential for responsible deployment and ensuring fairness and equity.
More visual insights#
More on figures
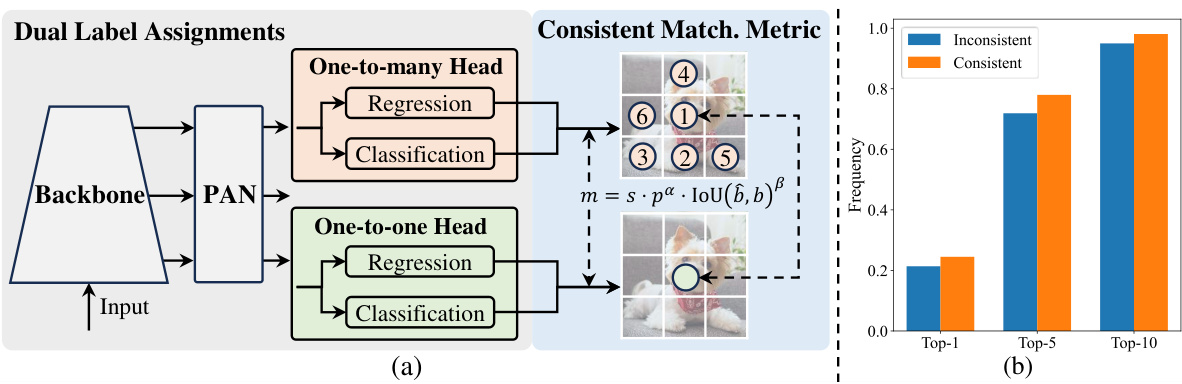
This figure illustrates the dual label assignment strategy used in the YOLOv10 model for NMS-free training. (a) shows the architecture, with a one-to-many head and a one-to-one head processing feature maps from the backbone and neck. The consistent matching metric, shown in (a) as well, harmonizes supervision from both heads. (b) compares the frequency of one-to-one assignments among the top predictions (top 1, top 5, top 10) of the one-to-many head, showing improved alignment (consistency) with the proposed matching metric.
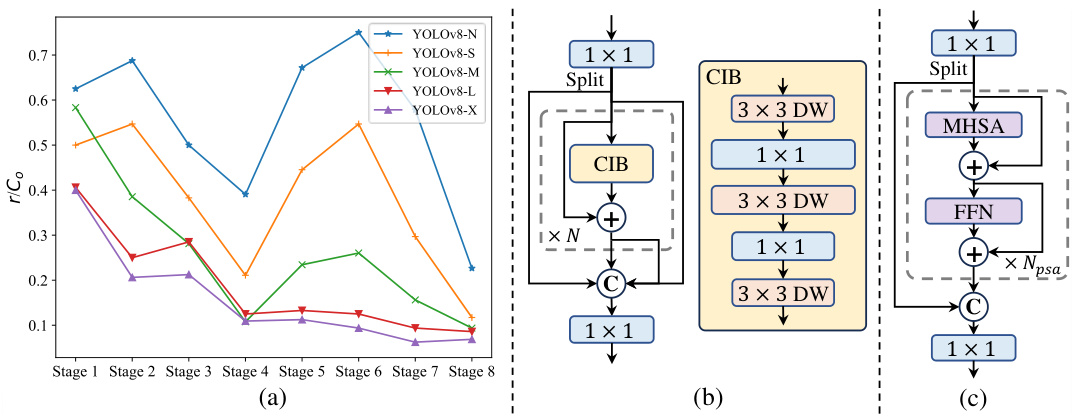
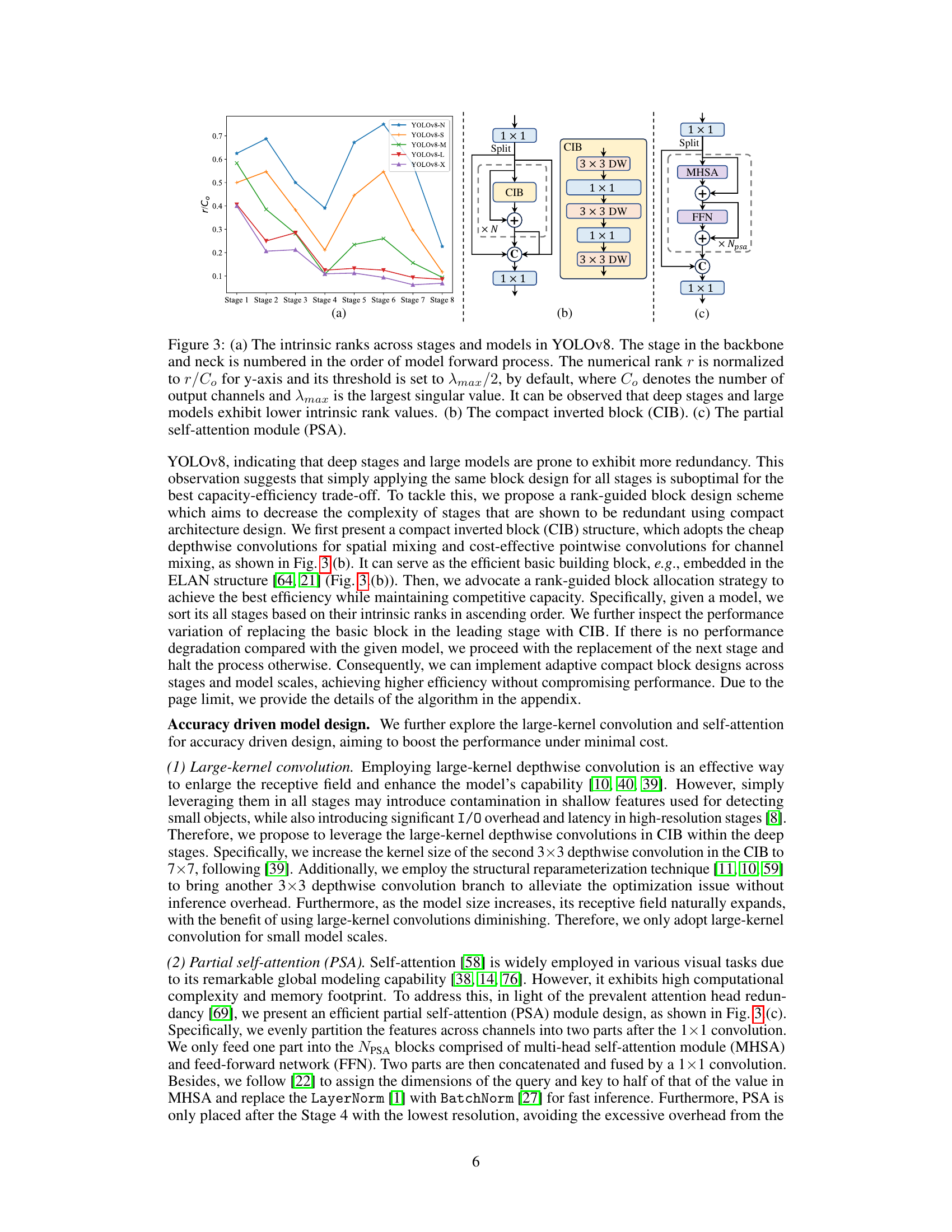
This figure shows the intrinsic ranks across different stages and models of YOLOv8, illustrating that deeper stages and larger models have lower intrinsic ranks, indicating redundancy. It also presents the architecture of the proposed compact inverted block (CIB) and partial self-attention module (PSA) designed to improve efficiency and accuracy.

Figure 3 visualizes the intrinsic ranks across different stages and model sizes in YOLOv8, demonstrating that deeper stages and larger models show lower ranks, suggesting redundancy. It also illustrates the proposed compact inverted block (CIB) and partial self-attention module (PSA) as components of the optimized YOLOv10 architecture.
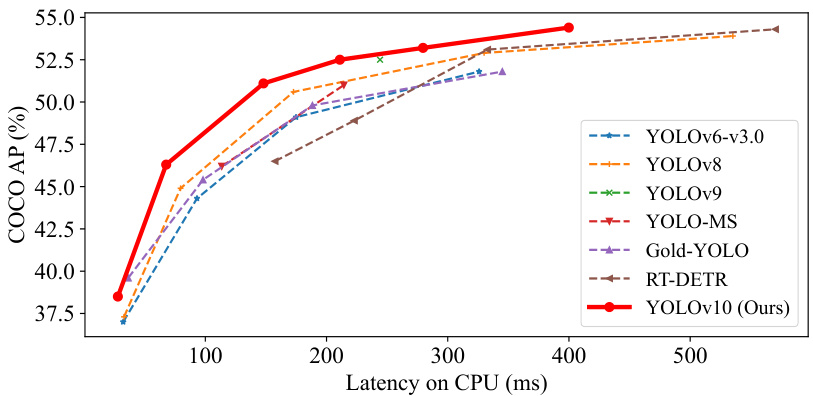
This figure compares the performance of YOLOv10 with other state-of-the-art real-time object detection models. The left-hand graph shows the trade-off between detection accuracy (AP) and inference latency (in milliseconds). The right-hand graph displays the trade-off between detection accuracy (AP) and the number of model parameters (in millions). Both graphs demonstrate that YOLOv10 achieves a strong balance between accuracy and efficiency, outperforming many competing models in both speed and size.
This figure compares YOLOv10 with other state-of-the-art real-time object detection models. The left graph shows a latency-accuracy trade-off, demonstrating that YOLOv10 achieves higher accuracy with lower latency compared to other models. The right graph illustrates a size-accuracy trade-off, indicating the model’s efficiency in terms of parameter count and FLOPs while maintaining competitive accuracy.
More on tables
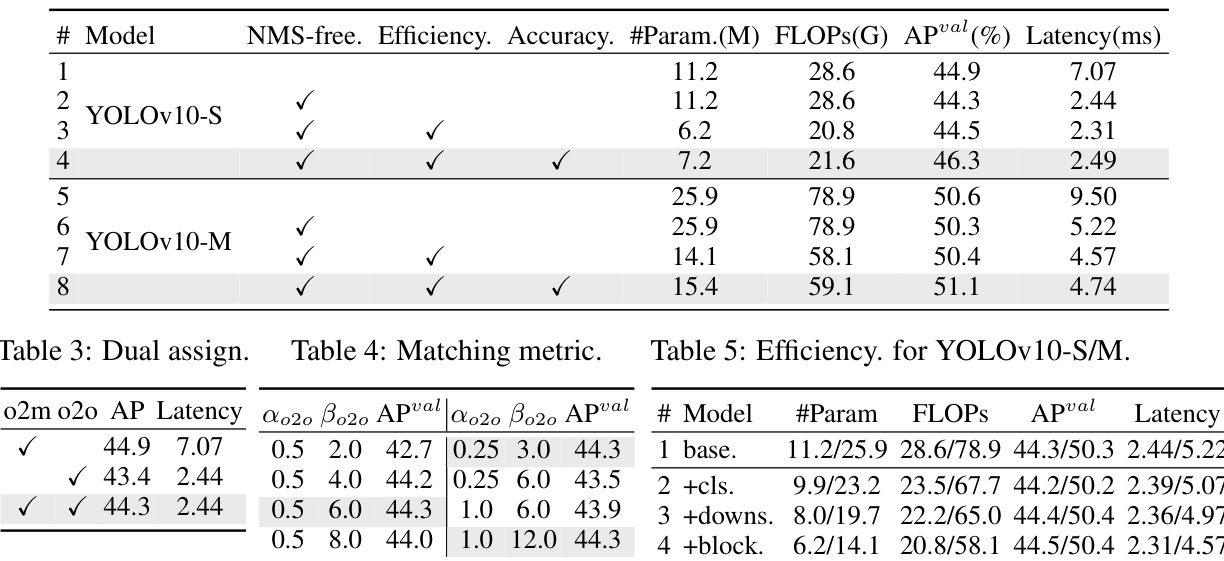
This table presents the ablation study results performed on the COCO dataset using two different models: YOLOv10-S and YOLOv10-M. It shows the impact of different components on the model’s performance and efficiency. The columns represent the model configuration (NMS-free, Efficiency, Accuracy), number of parameters, FLOPs, mAP (APval), and latency.
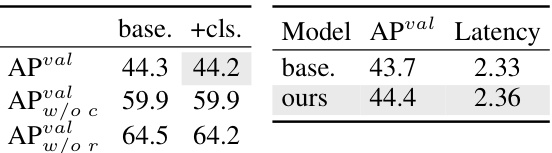
This table presents the ablation study of the spatial-channel decoupled downsampling in YOLOv10-S. It shows the impact of this technique on the model’s performance (APval) and latency. The ‘base.’ row represents the baseline model without this technique. The ‘ours’ row shows the results after implementing the spatial-channel decoupled downsampling technique. The results show a slight improvement in performance with a minimal reduction in latency.

This ablation study shows the impact of using the Compact Inverted Block (CIB) in different stages of the YOLOv8-S model. It compares the model’s performance (APval) and latency with different combinations of stages that utilize CIB, ranging from no CIB to including CIB in stages 8, 8 and 4, and 8, 4, and 7. The results highlight the trade-off between performance and computational efficiency.

This table compares the performance of YOLOv10 with other state-of-the-art real-time object detection models across various scales (N, S, M, B, L, X). The metrics used are the number of parameters (#Param.), Giga Floating Point Operations (GFLOPs), Average Precision (APval), end-to-end latency (Latency), and forward-only latency (Latencyf). The results highlight YOLOv10’s superior speed and efficiency while maintaining competitive accuracy.
This table compares the performance of YOLOv10 with other state-of-the-art real-time object detectors. Metrics include model size (#Param.), computational cost (FLOPs), accuracy (APval), end-to-end latency (Latency), and forward-only latency (Latencyf). The table highlights YOLOv10’s speed and efficiency improvements, especially when compared to RT-DETR and YOLOv9. Note that advanced training techniques were excluded for a fair comparison.
This table compares YOLOv10 with other state-of-the-art real-time object detectors across various model scales (N, S, M, B, L, X). Metrics include the number of parameters (#Param.), Giga Floating Point Operations (GFLOPs), Average Precision (APval), end-to-end latency (Latency), and forward-only latency (Latencyf). It highlights YOLOv10’s speed and efficiency gains compared to existing models, while achieving comparable or better accuracy.
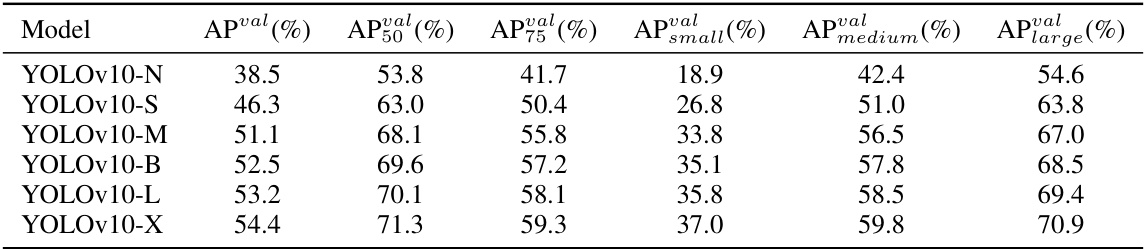
This table compares YOLOv10’s performance against other state-of-the-art real-time object detection models. Metrics include model size (#Param.), computational cost (FLOPs), accuracy (APval), and inference latency (Latencyf and Latency). It highlights YOLOv10’s speed and efficiency gains, particularly when comparing against RT-DETR models and other YOLO variants, while achieving similar or superior accuracy.
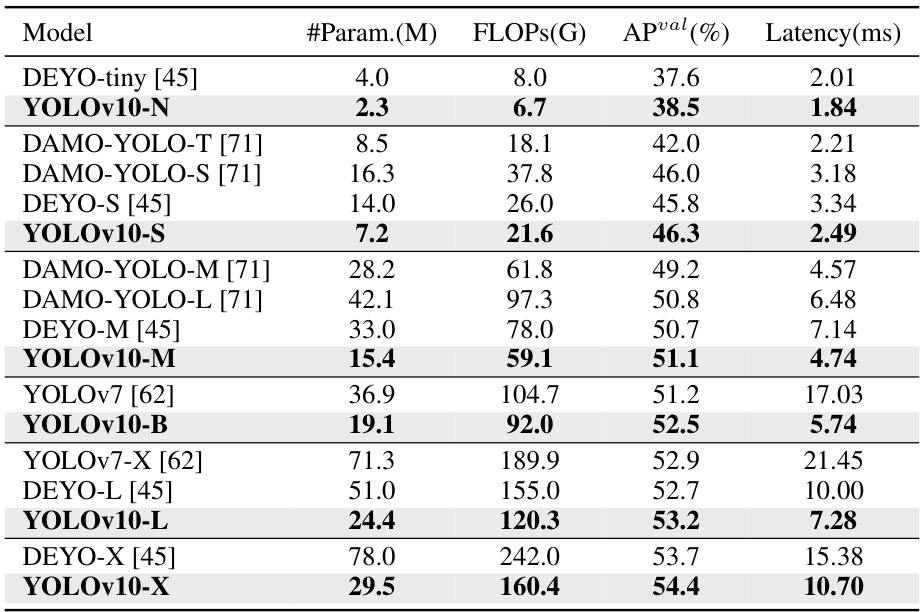
This table compares the performance of YOLOv10 with other state-of-the-art real-time object detection models. The metrics include the number of parameters (#Param.), Giga Floating Point Operations (GFLOPs), Average Precision (APval), end-to-end latency (Latency), and latency of the forward process (Latencyf). It highlights YOLOv10’s speed and efficiency advantages while maintaining competitive accuracy. The comparison includes models from the YOLO series (YOLOv6, YOLOv7, YOLOv8, YOLOv9, YOLO-MS, Gold-YOLO), and RT-DETR.
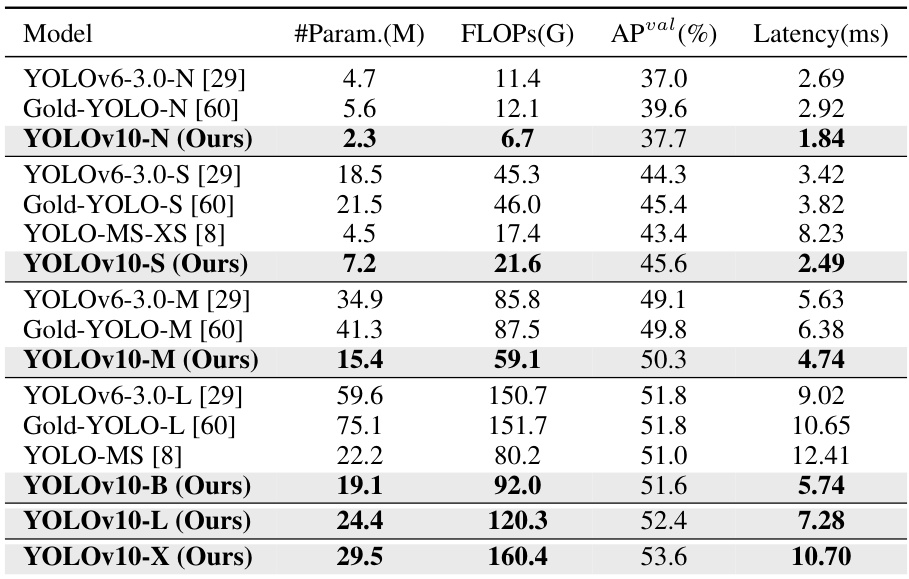
This table compares YOLOv10 with other state-of-the-art real-time object detection models. It shows a comparison of the number of parameters, FLOPs (floating point operations), average precision (APval), end-to-end latency (Latency), and forward-only latency (Latencyf) for different model sizes (N, S, M, L, X). The table highlights YOLOv10’s superior performance and efficiency across various scales, particularly its faster speed and reduced parameter count compared to models with similar accuracy. It also notes that the results exclude additional training techniques used by some other models to ensure a fair comparison.
Full paper#