↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Humans effortlessly draw new objects from a single example, a skill challenging for AI. Current generative models, while improving, still struggle with the originality and recognizability of human drawings. This paper tackles this ‘one-shot drawing’ challenge by investigating how different inductive biases affect Latent Diffusion Models (LDMs).
The researchers explored various regularizers, including standard LDMs, supervised ones (classification and prototype-based), and contrastive ones (SimCLR and redundancy reduction). They found that LDMs using redundancy reduction and prototype-based regularizations produced remarkably human-like drawings, judged both for recognizability and originality. A psychophysical evaluation further confirmed a closer alignment with human perception.
Key Takeaways#
Why does it matter?#
This paper significantly advances one-shot image generation, bridging the gap between human and machine capabilities by exploring representational inductive biases in latent diffusion models. It introduces novel regularizations and a feature importance map comparison, paving the way for more human-like AI generative models.
Visual Insights#

This figure illustrates the architecture of a Latent Diffusion Model (LDM). It consists of two main stages: a Regularized AutoEncoder (RAE) and a diffusion model. The RAE (green boxes) takes an image (x) as input and outputs a latent representation (z). The RAE includes an encoder (qφ) and a decoder (pθ). The latent representation (z) is then used as input to the diffusion model (orange boxes), which learns the distribution of the latent representations and is responsible for generating variations of the image. The diffusion model takes the latent representation (z) of an exemplar image (y) as conditioning input and outputs a denoised latent representation (z0). Finally, the decoder (pθ) converts the denoised latent representation (z0) into the generated image (x’). The figure highlights how the diffusion model uses the latent representation from the autoencoder and how the regularizations are applied to the latent space via the autoencoder.

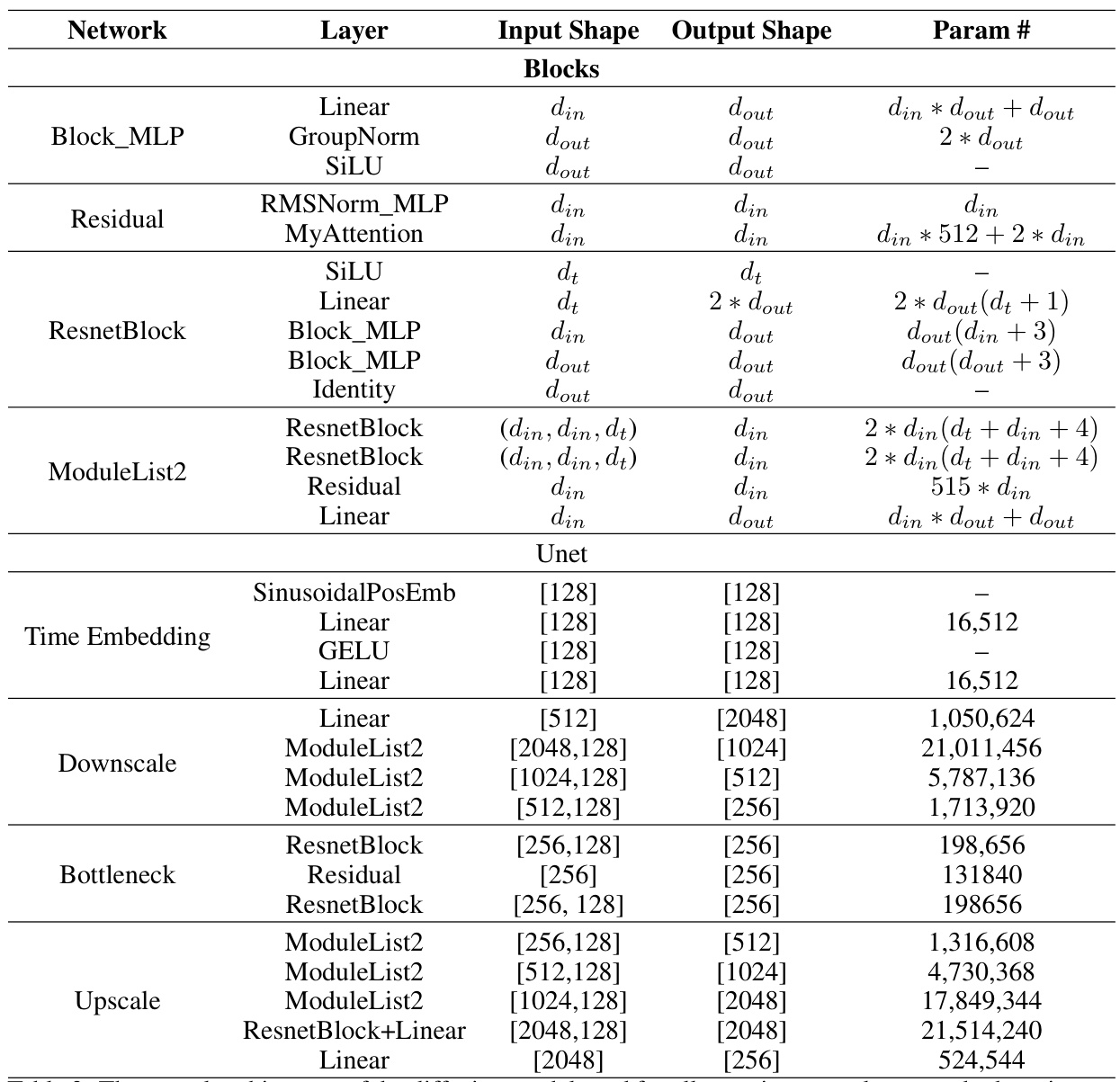
This table details the architecture of the RAE encoder and decoder, which are composed of convolutional layers, batch normalization layers, ReLU activation functions, and linear layers. The input and output shapes for each layer are listed, along with the number of parameters. Different latent space sizes (d) are used for Omniglot (d=64) and QuickDraw (d=128).
In-depth insights#
Latent Bias Effects#
The concept of “Latent Bias Effects” in the context of a research paper likely explores how biases embedded within latent representations of machine learning models impact downstream tasks. It suggests that biases aren’t explicitly programmed but emerge from the training data and model architecture. An analysis of such effects would investigate how these implicit biases influence model outputs, particularly focusing on their impact on fairness, generalization, and the model’s alignment with human-like behavior. For example, a generative model trained on biased data might generate outputs reflecting those biases, even if the model itself is not explicitly designed to discriminate. The paper might then investigate techniques to mitigate or control these latent biases. This might include careful data curation, architectural modifications to the model, or using regularization methods that encourage fairness or other desirable properties in the latent space. The overall goal would be to understand and improve the reliability and trustworthiness of machine learning models by carefully examining and addressing the often-unseen, inherent biases they acquire during training.
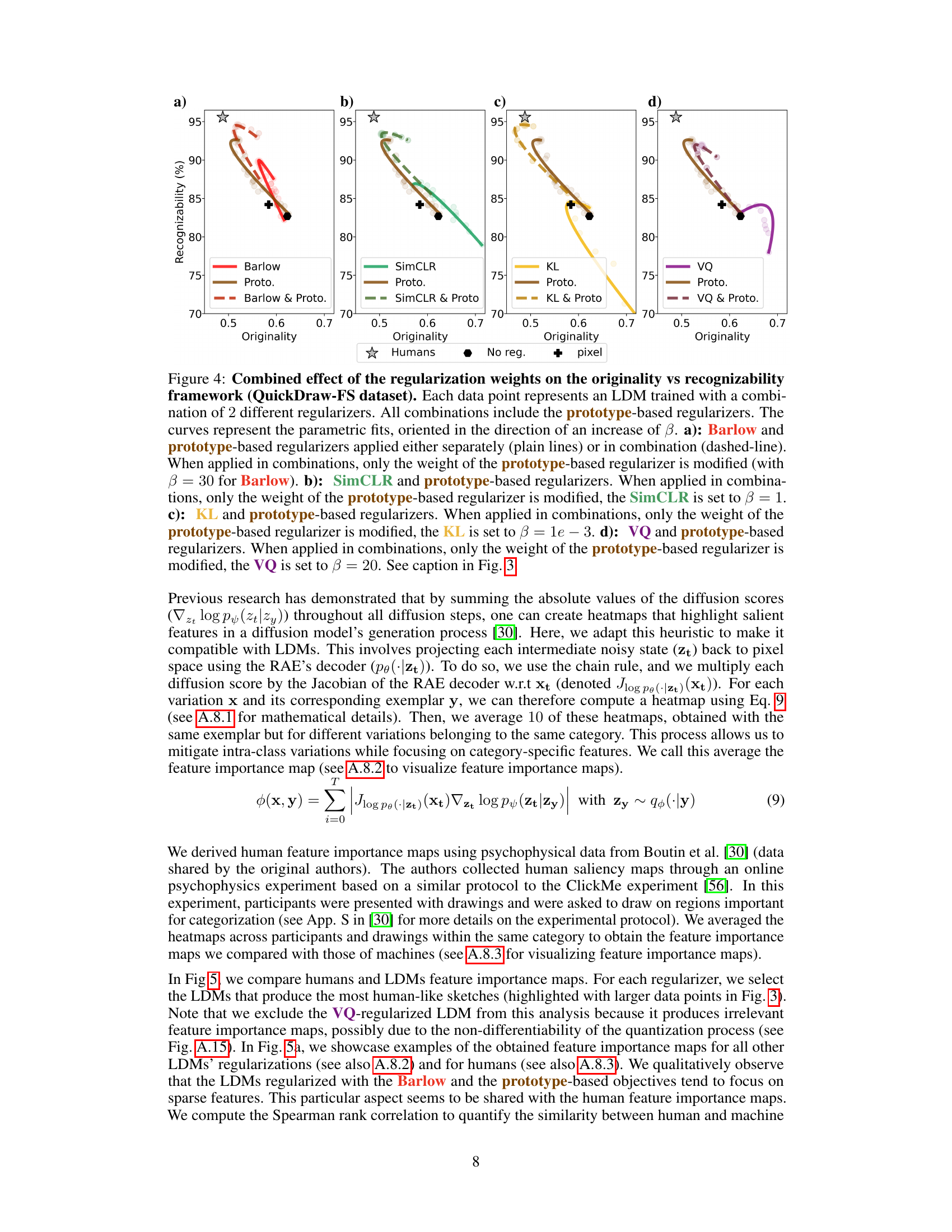
LDM Regularization#
The effectiveness of Latent Diffusion Models (LDMs) hinges significantly on the regularization strategies employed. This paper explores various regularizers, categorized into standard (KL and VQ), supervised (classification and prototype-based), and contrastive (SimCLR and Barlow) methods. Prototype-based regularization emerges as particularly effective, demonstrating superior performance compared to classification methods. This highlights the importance of representation learning biases aligned with human perceptual processes. Contrastive methods, particularly Barlow Twins, showcase the benefit of redundancy reduction for enhancing the originality and recognizability of generated sketches, indicating that feature disentanglement is key. The combined effects of prototype and Barlow regularization prove highly synergistic, resulting in remarkably human-like output. The findings underscore the critical role of representational inductive biases in achieving human-level performance in one-shot drawing, advocating for a shift from architectural biases to representational ones in future generative models. The choice of regularization significantly impacts the model’s capacity to generalize to novel visual categories, closing the gap between machine-generated and human-like drawings.
Human-likeness Gap#
The concept of a “Human-likeness Gap” in AI, specifically within the context of one-shot drawing, highlights the discrepancy between human and machine abilities to generate novel sketches from a single example. Humans effortlessly extrapolate visual concepts, exhibiting both recognizability and originality in their drawings. AI models, while making significant progress with diffusion models, still struggle to replicate this dual capability. This gap isn’t merely about technical limitations; it speaks to the profound differences in inductive biases—the inherent assumptions and prior knowledge—that shape human and machine learning. Bridging this gap requires exploring and incorporating more sophisticated inductive biases in AI architectures. Prototype-based and redundancy-reduction regularizations show promise, but fully understanding and replicating the human visual system’s flexibility remains a significant challenge. This “Human-likeness Gap” is thus not just a quantitative measure of performance, but a qualitative indicator of the complex cognitive processes involved in creative generation.
Feature Importance#
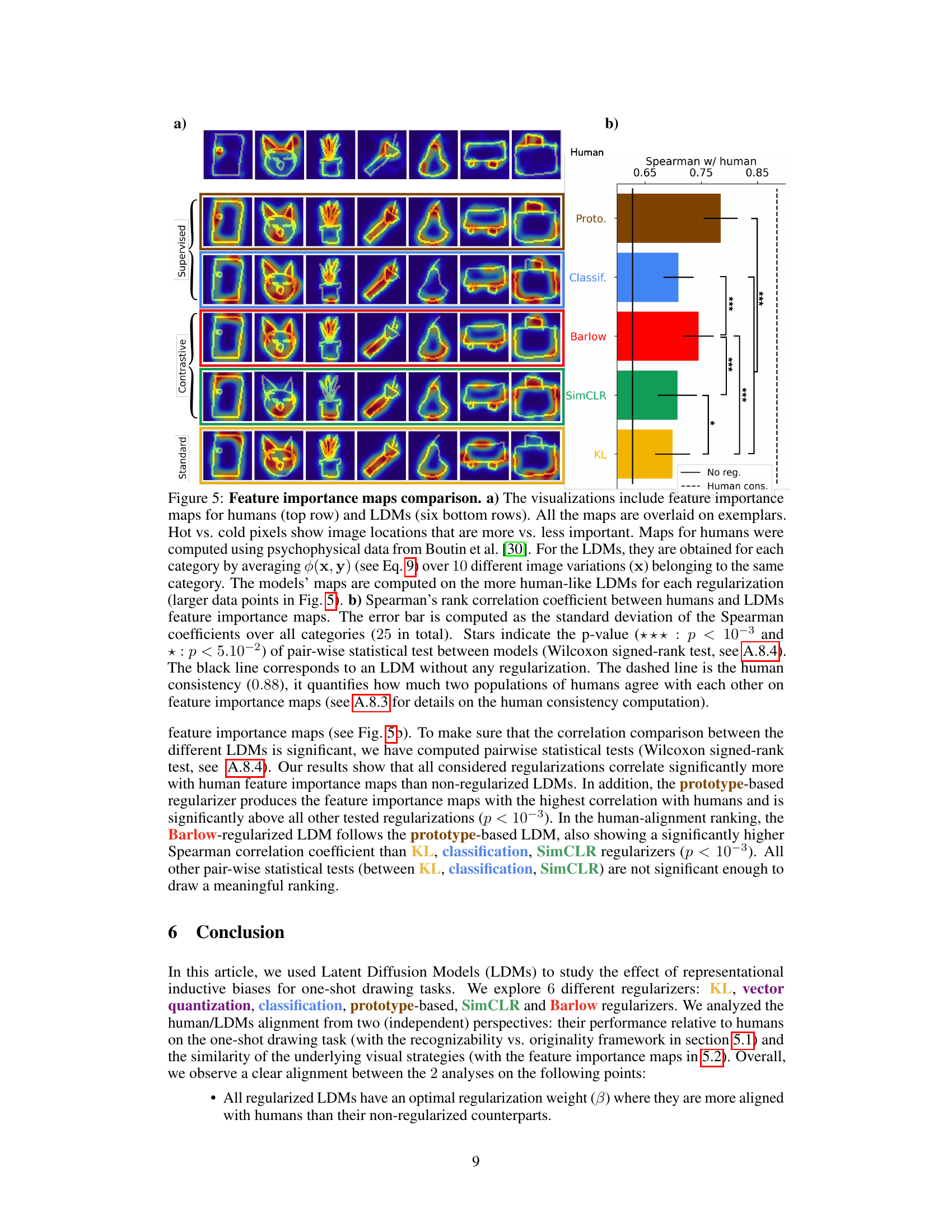
The concept of ‘Feature Importance’ in the context of a research paper analyzing one-shot drawing tasks using Latent Diffusion Models (LDMs) is crucial for understanding how these models learn and generalize. It suggests investigating which visual features within the input images are most influential in shaping the model’s generated outputs. This analysis goes beyond simply evaluating the model’s accuracy or originality; it delves into the internal mechanisms of the LDM, providing insights into whether the model’s attention aligns with human perception. Determining feature importance can be achieved through various techniques, such as analyzing gradients, generating saliency maps, or utilizing techniques like attention mechanisms within the model’s architecture. Comparing the model’s feature importance maps to those derived from human psychophysical studies provides a powerful way to evaluate the model’s alignment with human visual processing strategies. Moreover, the investigation of feature importance helps pinpoint the impact of different inductive biases incorporated in the LDMs. The results likely show whether the chosen regularizers (e.g., prototype-based, Barlow Twins) influence the model’s attention to specific visual features. In essence, feature importance analysis serves as a bridge between model performance metrics and a deeper comprehension of how the models learn to mimic human-like sketching capabilities.
Future Directions#
Future research could explore more sophisticated inductive biases beyond those tested, potentially drawing inspiration from neuroscience and cognitive psychology. Investigating the interplay between different inductive biases within LDMs, combining their strengths, is crucial for achieving human-level performance. Addressing the computational cost associated with the training of two-stage generative models is also important; further exploration of end-to-end training procedures may improve efficiency. The current evaluation metrics could be refined, incorporating more nuanced assessments of originality and recognizability, potentially incorporating perceptual and psychophysical studies for more human-centric evaluation. Finally, expanding the application of these findings to more complex datasets, including natural images, presents an exciting direction, challenging LDMs to handle the complexities of real-world visual data.
More visual insights#
More on figures

This figure displays samples generated by Latent Diffusion Models (LDMs) trained with different regularizers. Each row represents a different regularizer (No reg., Proto., Classif., Barlow, SimCLR, KL, VQ), and each column shows samples for the same category. The samples shown correspond to the LDMs that exhibit the closest performance to human performance, indicated as larger data points in Figure 3. The image helps visualize the impact of different inductive biases on the quality and style of generated drawings.
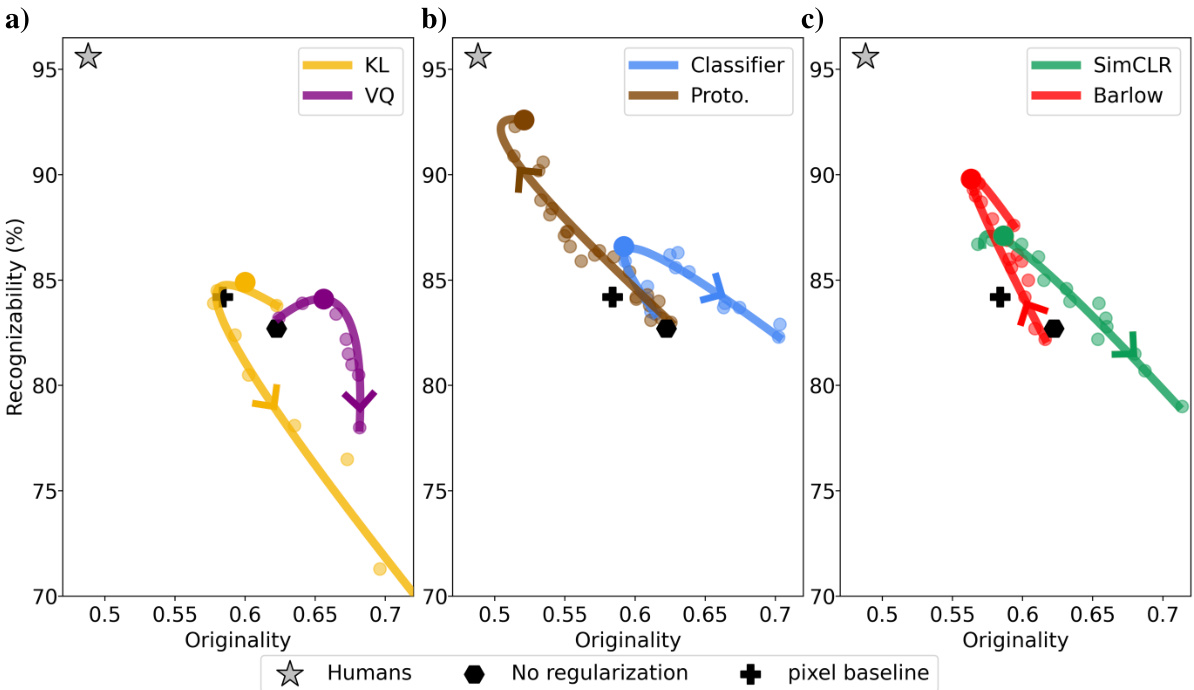
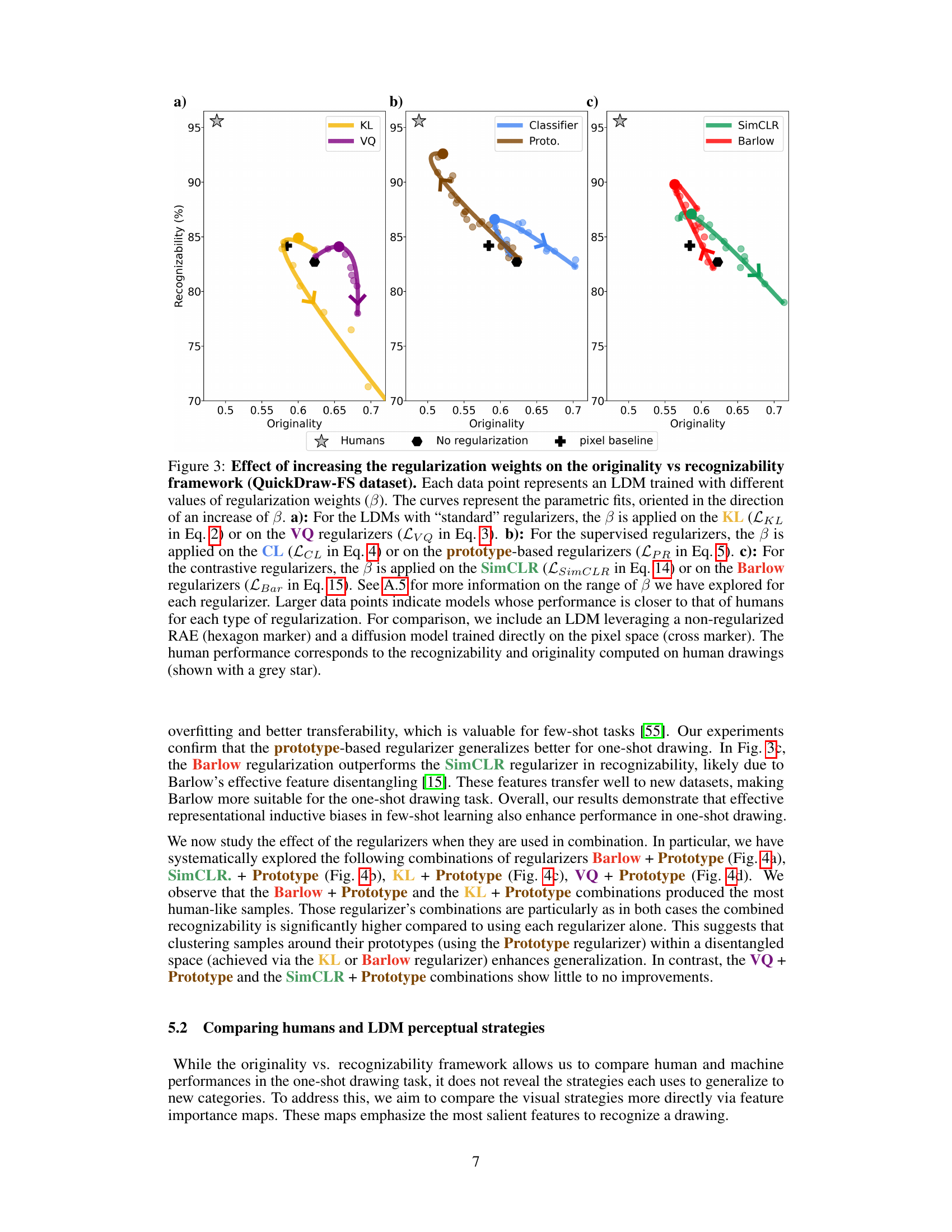
This figure shows the effect of different regularization weights on the originality and recognizability of one-shot drawings generated by Latent Diffusion Models (LDMs). Each subplot represents a different type of regularization (standard, supervised, contrastive). The curves show the trade-off between originality and recognizability as the regularization weight increases. The proximity of the data points to the human data point (grey star) indicates how well the LDMs mimic human drawing performance.
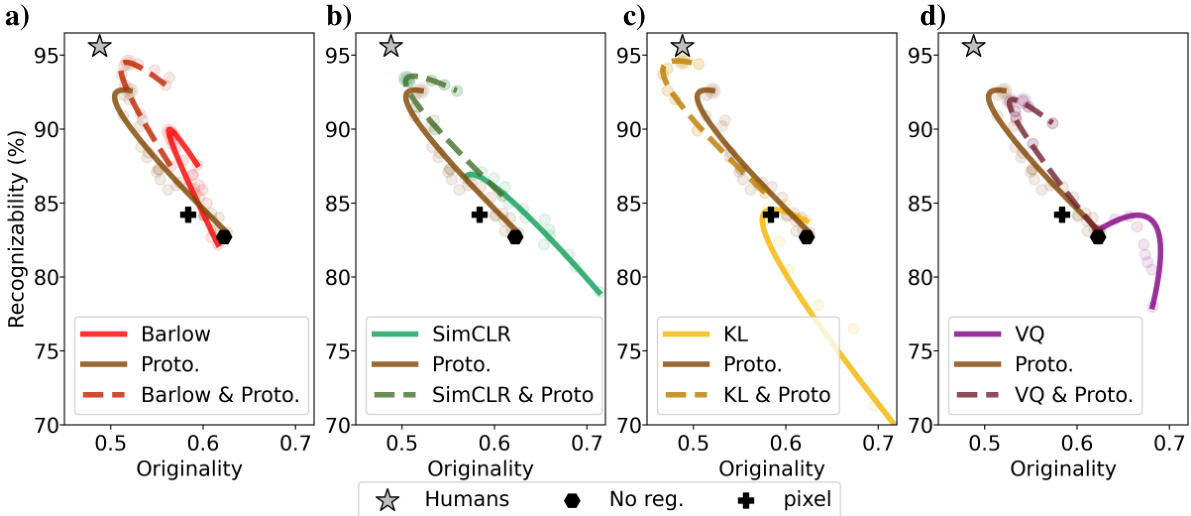
This figure shows the effect of different regularization weights on the originality and recognizability of one-shot drawings generated by Latent Diffusion Models (LDMs). It compares various LDMs against human performance, revealing that prototype-based and Barlow regularizations yield results closest to human-like drawings.

This figure compares feature importance maps generated by humans and LDMs with different regularizers. (a) shows examples of feature importance maps, where hot/cold colors represent high/low importance. The human maps are derived from psychophysical data, while LDM maps highlight category-diagnostic features by back-projecting intermediate noisy latent states to pixel space using the RAE decoder. (b) quantifies the similarity between human and LDM maps using Spearman’s rank correlation. Higher correlation indicates better alignment between human and machine visual strategies.

This figure shows examples of how the Quick, Draw! dataset contains drawings that are semantically related but not necessarily visually similar. For example, the category ‘alarm clock’ includes both analog and digital alarm clocks, representing distinct visual concepts. This illustrates a key limitation of using the original Quick, Draw! dataset for purely visual one-shot generation tasks because the categories do not always represent the same visual concept.

This figure shows samples generated by Latent Diffusion Models (LDMs) trained with different regularizers. Each row corresponds to a specific regularizer (No reg., Proto., Classif., Barlow, SimCLR, KL, VQ), showcasing the diversity of generated drawings depending on the inductive biases in the latent space. The selection of LDMs shown is based on those models having performance closest to that of human participants, as detailed further in Figure 3.

This figure shows the impact of different regularization weights on the originality vs. recognizability of one-shot drawings generated by Latent Diffusion Models (LDMs). The x-axis represents originality, the y-axis represents recognizability. Each subplot displays results for a different group of regularizers (standard, supervised, contrastive). The lines show the parametric fit of the data points and indicate how the performance changes as the regularization weight increases. The results suggest that prototype-based and Barlow regularizations yield samples closer to those generated by humans, indicating that these inductive biases are crucial for one-shot drawing tasks.

This figure shows the directed graphical model used in the latent diffusion model. The model progressively denoises latent representations conditioned on exemplar images to generate new images.
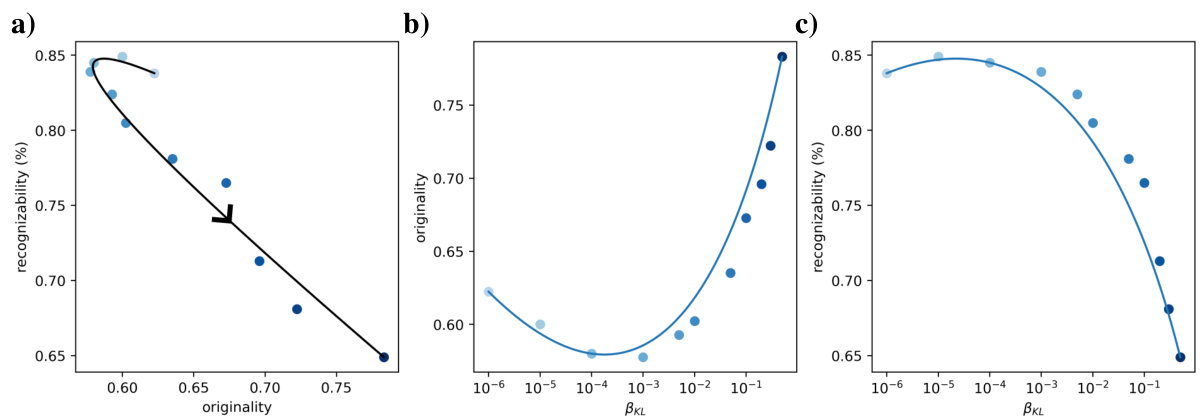
The figure shows the results of an experiment evaluating the effect of different regularization techniques on the performance of Latent Diffusion Models (LDMs) in a one-shot drawing task. The x-axis represents originality, and the y-axis represents recognizability. Each plot shows the results for different regularizers (KL, VQ, Classification, Prototype, SimCLR, Barlow). The curves show the trend of how the originality and recognizability change as the regularization strength (β) is increased.

This figure shows the effect of different regularization strengths on the originality and recognizability of one-shot drawings generated by Latent Diffusion Models (LDMs). Each subplot represents a different type of regularization (standard, supervised, contrastive). The x-axis represents originality (how different the drawings are from the exemplar), and the y-axis represents recognizability (how easily the drawings are classified). The curves show how the balance between originality and recognizability changes with increasing regularization strength. The plot also includes a comparison to human performance.

This figure shows the impact of different regularization strengths (β) on the trade-off between originality and recognizability of one-shot drawings generated by Latent Diffusion Models (LDMs). Each subplot represents a different type of regularization (standard, supervised, contrastive), showing how increasing β affects the balance between the two metrics. The human performance is shown as a grey star, providing a benchmark for comparison.

This figure shows the results of an experiment comparing different regularization techniques in latent diffusion models for one-shot drawing. It plots originality (x-axis) against recognizability (y-axis) for several models with varying regularization weights. The plots illustrate the trade-off between originality and recognizability, and how different regularization methods affect model performance relative to human-level performance.

This figure shows the effect of different regularization weights on the originality and recognizability of one-shot drawings generated by Latent Diffusion Models (LDMs). It compares the performance of LDMs with different regularizers (KL, VQ, Classification, Prototype, SimCLR, Barlow) against human performance, visualized as a grey star. The x-axis represents originality (how different the drawing is from the exemplar), and the y-axis represents recognizability (how well the drawing is classified). Each subplot shows the results for a different type of regularizer, with increasing regularization weight moving along the curves. LDMs using prototype-based and Barlow regularizations show better performance, approaching human-like results.

This figure shows the effect of different regularization strengths on the originality and recognizability of one-shot drawings generated by Latent Diffusion Models (LDMs). It compares the performance of LDMs with various regularizers (KL, VQ, classification, prototype-based, SimCLR, and Barlow) against human performance, illustrating the trade-off between originality and recognizability. The optimal regularization strength varies for each regularizer, and prototype-based and Barlow regularization show the closest alignment with human performance.
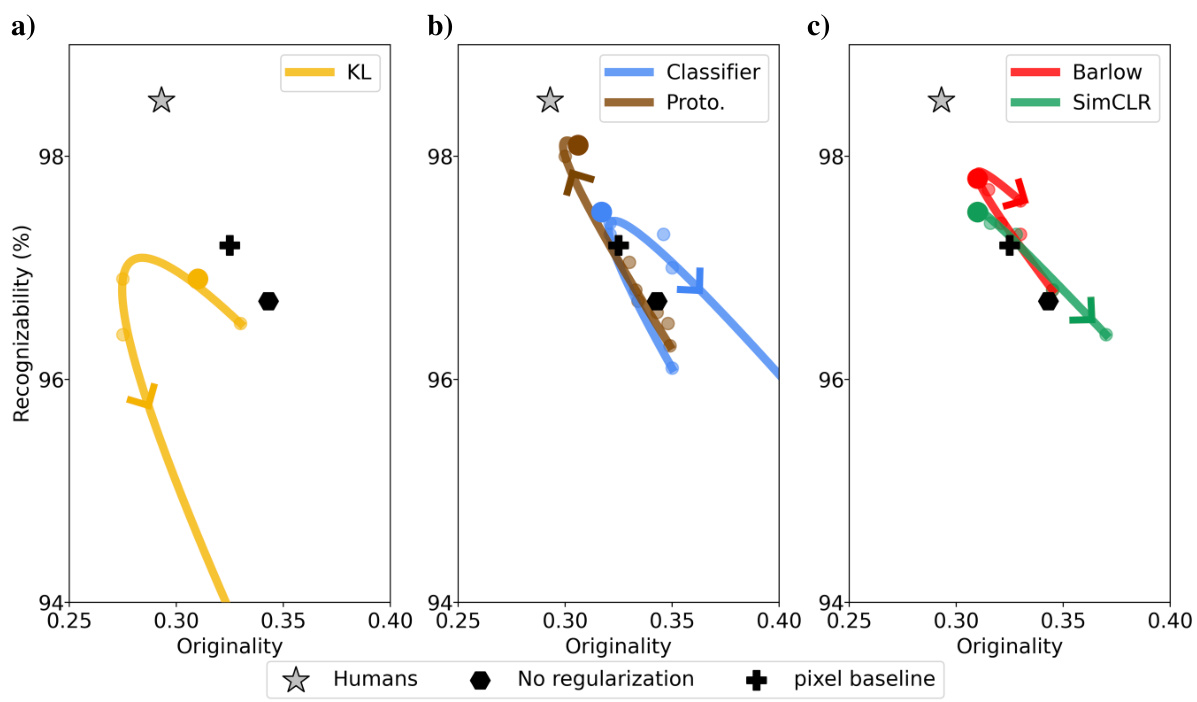
This figure shows the effect of different regularization weights on the originality and recognizability of one-shot drawings generated by Latent Diffusion Models (LDMs). Each subplot shows results for a different type of regularizer (standard, supervised, contrastive), plotting recognizability against originality. The curves show a tradeoff between these metrics, and the best-performing LDMs are highlighted, demonstrating a closer similarity to human performance.

This figure shows example sketches generated by Latent Diffusion Models (LDMs) trained with different types of regularizers. Each row represents a different regularizer (No reg., Proto, Classif., Barlow, SimCLR, KL, VQ), and each column shows a different generated sketch from that regularizer. The LDMs highlighted correspond to the models with the best performance according to the Originality vs Recognizability metrics discussed in the paper, corresponding to the larger points in Figure 3. This allows for a visual comparison of the different generated drawings and how the chosen inductive biases affect the sketches.

This figure shows samples generated by Latent Diffusion Models (LDMs) using two different contrastive regularizers: SimCLR and Barlow. The top row displays the exemplars used to condition the LDMs for each category. The remaining rows show samples generated by the LDMs. The left column shows results using the SimCLR regularizer, and the right column shows results using the Barlow regularizer. The figure helps to visually compare the effects of these two regularizers on the diversity and quality of generated samples.

This figure shows samples generated by a Latent Diffusion Model (LDM) without any regularization applied. The top row shows the exemplars used for conditioning. The remaining samples are variations generated by the model. The lack of regularization results in samples that are less diverse and may not accurately represent the intended concept compared to regularized models.

This figure shows samples generated by Latent Diffusion Models (LDMs) using contrastive regularizers. The top row displays the exemplars used to condition the models. The remaining rows show variations generated for each exemplar. (a) shows samples generated using SimCLR regularization with a hyperparameter value of 0.01, while (b) presents samples from an LDM using Barlow Twins regularization with a hyperparameter value of 30. The results illustrate the difference in generated variations obtained from these two distinct methods.

This figure compares the feature importance maps obtained from human subjects and those generated by Latent Diffusion Models (LDMs) with different regularizations. Panel (a) shows example maps visually, highlighting important regions in the drawings for both humans and LDMs. Panel (b) presents a quantitative comparison, showing the Spearman rank correlation between human and LDM feature importance maps, along with statistical significance tests.

This figure compares feature importance maps between humans and several latent diffusion models (LDMs) with different regularizations. (a) shows example maps, demonstrating the spatial distribution of importance weights for various categories. The heatmaps highlight areas deemed most crucial for object recognition. (b) presents a quantitative comparison, showing the Spearman rank correlation between human and model maps for each regularization and statistical significance tests. The prototype-based and Barlow regularized models show the highest correlation with human perception.

This figure compares feature importance maps between humans and LDMs with different regularizers. (a) shows example maps, highlighting which image regions are most important for category recognition. (b) quantifies the similarity between human and machine maps using Spearman rank correlation, revealing that prototype-based and Barlow regularized LDMs show the best alignment with human perception.

This figure compares feature importance maps generated by humans and LDMs using different regularizers. The maps highlight which image regions are most important for object recognition. Part (a) shows examples of the maps, and part (b) provides a quantitative comparison showing that the prototype-based and Barlow regularizers show the strongest agreement with human perception.

This figure shows the limitations of current Latent Diffusion Models in producing faithful variations when given a single image exemplar. The example uses a self-balancing bike, an unusual vehicle not frequently represented in image datasets. Dall-E 3 generates variations missing key features of the self-balancing bike concept, such as the single wheel.
More on tables
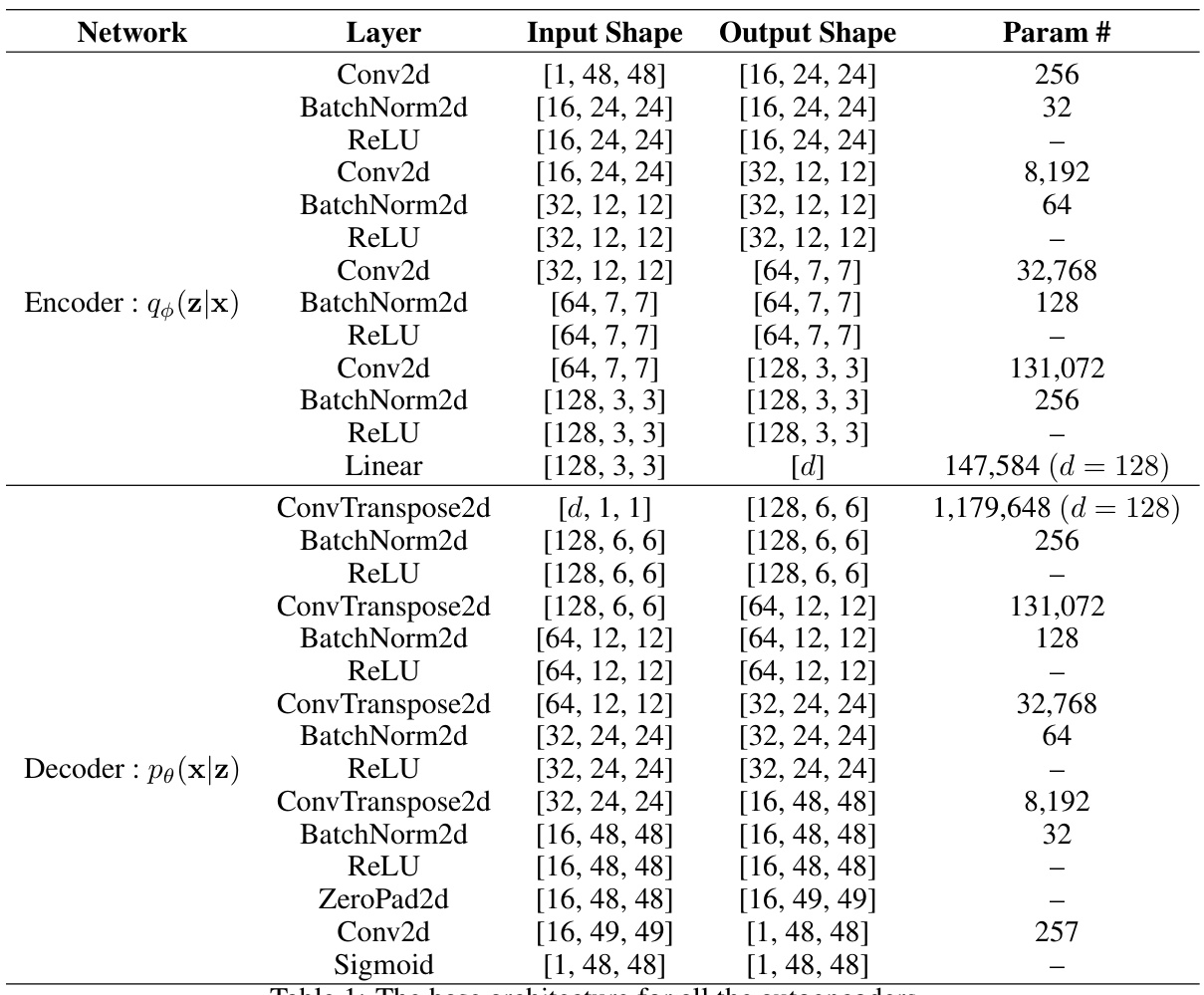
This table details the architecture of the autoencoder used in the paper. It breaks down the encoder and decoder into layers, specifying the input and output shapes of each layer, as well as the number of parameters for each layer. The architecture consists of convolutional and transposed convolutional layers interleaved with batch normalization and ReLU activation functions. The table also notes that for the Omniglot and QuickDraw datasets, different latent-space sizes (d) were used.
This table details the architecture of the autoencoder used in the paper. It breaks down the encoder and decoder networks, layer by layer, specifying the type of layer (e.g., Conv2d, BatchNorm2d, ReLU, Linear), input and output shapes at each layer, and the number of parameters for each layer. The architecture is based on the model proposed by Ghosh et al. [52] and is used for both the Omniglot and QuickDraw datasets. The table notes that the latent space size (d) differs between datasets (d=64 for Omniglot and d=128 for QuickDraw).

This table presents the p-values of pairwise statistical tests (Wilcoxon signed-rank test) performed between different types of regularized LDMs. The null hypothesis is that the two populations are sampled from the same distribution, while the alternative hypothesis is that the first population is stochastically greater than the second. Each cell shows the p-value for comparing the Spearman rank correlation of feature importance maps between a given regularized LDM and another, allowing a statistical determination of the significance of differences in the human-alignment of their generated feature importance maps. The table helps to understand the relative performance of various regularization methods.
Full paper#