TL;DR#
Existing color video SCI reconstruction algorithms struggle with the increasing popularity of quad-Bayer sensors in smartphones, leading to color distortion and poor image quality. These algorithms are typically designed for traditional Bayer sensors and are not directly applicable to quad-Bayer data, limiting their effectiveness in high-resolution video applications.
MambaSCI, a novel algorithm using Mamba and UNet architectures, efficiently reconstructs quad-Bayer patterned SCI. It introduces Residual-Mamba-Blocks, incorporating STMamba, EDR, and CA modules for handling long-range spatio-temporal dependencies, improving edge detail, and compensating for missing channel information. The results show that MambaSCI significantly outperforms existing methods in both quantitative metrics and visual quality, achieving state-of-the-art performance with lower computational costs. This is particularly important for resource-constrained mobile devices.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computational imaging and video processing. It introduces the first algorithm for quad-Bayer patterned video snapshot compressive imaging (SCI) reconstruction, addressing limitations of existing methods and opening new avenues for high-resolution, low-light mobile video capture. The efficient MambaSCI model offers improved performance and reduced computational complexity, directly impacting smartphone camera technology and high-speed video applications.
Visual Insights#

🔼 Figure 1(a) shows a comparison of the traditional Bayer color filter array (CFA) pattern and the quad-Bayer CFA pattern. The quad-Bayer pattern combines four sub-pixels into a single pixel, resulting in larger effective pixel size and improved light sensitivity. Figure 1(b) presents a performance comparison between MambaSCI and other state-of-the-art (SOTA) methods for color video snapshot compressive imaging (SCI). It displays the peak signal-to-noise ratio (PSNR) versus the number of floating-point operations (FLOPS) for several methods, highlighting MambaSCI’s superior performance in terms of PSNR while maintaining lower computational cost.
read the caption
Figure 1: (a) Bayer CFA vs. Quad-Bayer CFA. (b) PSNR and FLOPS on color simulation videos (larger size means more parameters).

🔼 This table presents a comparison of three different versions of the MambaSCI model (MambaSCI-T, MambaSCI-S, and MambaSCI-B), each differing in the number of channels and the complexity of the network. The table shows the PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), the number of model parameters (in millions), and the FLOPS (floating point operations per second) for each model. This allows a reader to assess the trade-off between reconstruction quality and computational cost for each model variant.
read the caption
Table 1: Reconstruction quality and computational complexity for different versions of MambaSCI.
In-depth insights#
Quad-Bayer SCI#
The concept of “Quad-Bayer SCI” merges the advancements in quad-Bayer sensor technology with the computational imaging technique of snapshot compressive imaging (SCI). Quad-Bayer sensors, featuring a 2x2 arrangement of color filters, enhance light sensitivity and resolution compared to traditional Bayer patterns. Combining this with SCI, which captures multiple video frames simultaneously, offers significant potential for high-quality video acquisition in mobile devices. This approach however presents challenges in color reconstruction and demosaicing algorithms due to the unique pattern’s increased complexity. Existing color video SCI reconstruction methods are not directly applicable, highlighting the need for novel algorithms specifically tailored to the Quad-Bayer pattern. The advantages of this combination include a reduction in computational burden and memory requirements, resulting in better mobile photography capabilities, particularly useful for high resolution video in low light scenarios. However, challenges remain in efficiently managing the increased data complexity and eliminating artifacts caused by motion and the quad-Bayer structure itself. Therefore, future research should focus on developing efficient, artifact-free reconstruction algorithms capable of exploiting the advantages of Quad-Bayer sensors within the SCI framework.
MambaSCI Model#
The MambaSCI model is a novel approach to color video snapshot compressive imaging (SCI) reconstruction, specifically designed for quad-Bayer patterned sensors. It leverages the strengths of both Mamba and U-Net architectures. Mamba’s efficiency in capturing long-range spatial-temporal dependencies is crucial, especially considering the challenges posed by quad-Bayer data’s unique structure. This efficiency is achieved through customized Residual-Mamba-Blocks, which combine the STMamba module for spatiotemporal modeling, an EDR module for detailed edge reconstruction, and a Channel Attention module to mitigate the lack of channel information interaction. The U-Net architecture provides a hierarchical structure, enabling multi-scale feature extraction and reconstruction. The key innovation is the integration of these components within the Residual-Mamba-Block, leading to superior reconstruction quality with reduced computational complexity. This makes MambaSCI particularly suitable for deployment on resource-constrained mobile devices, which is a significant advancement in mobile photography and video processing. The results demonstrate the effectiveness of the MambaSCI approach, surpassing existing methods in both PSNR and SSIM metrics while significantly reducing computational costs. The pseudo-code provided further enhances reproducibility and allows for community involvement in refining this valuable method.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a complex model. In this context, it would involve removing or deactivating parts of the MambaSCI model (e.g., STMamba, EDR, CA modules) to assess their impact on the overall performance. Key insights would be gained by comparing the model’s performance with and without each component, isolating their specific effects on metrics like PSNR and SSIM. The results would not only quantify the contribution of each module but also reveal potential redundancies or interactions between them. For instance, if removing the CA module leads to a significant drop in PSNR, it strongly suggests that channel attention is crucial for high-quality reconstruction. Conversely, a minor performance drop upon removing a module might indicate its lesser importance or possible redundancy with other parts. The ablation study’s conclusions are vital for understanding the model’s design choices and overall effectiveness, and may guide future model improvements by identifying areas for optimization or simplification.
Limitations#
The research paper’s limitations section is crucial for establishing credibility and fostering trust. Addressing limitations demonstrates a thorough understanding of the study’s scope and context. The authors acknowledge the trade-off between computational complexity and performance, particularly due to the CA module’s increased parameters and FLOPS. This transparency is commendable, highlighting the challenges inherent in balancing model accuracy and efficiency. A key limitation is the unavailability of real-world quad-Bayer datasets for evaluation. This constraint restricts the generalizability of findings and necessitates reliance on simulated data, potentially limiting the real-world applicability of the proposed method. Addressing the data limitation through future research is suggested and could strengthen the study’s overall impact. The honest acknowledgment of these limitations enhances the paper’s integrity and encourages further investigation to overcome these challenges. Future work could focus on refining the model architecture to reduce computational cost while maintaining accuracy, and exploring alternative demosaicing techniques to address the current dependence on simulation data.
Future Work#
Future research directions stemming from this work on MambaSCI for quad-Bayer patterned video snapshot compressive imaging could explore several promising avenues. Improving the efficiency of the CA module is crucial, potentially through architectural changes or alternative attention mechanisms. Investigating different state space models beyond Mamba, such as those with varying degrees of temporal dependence, might lead to further performance enhancements and allow for exploring the trade-off between model size and computational complexity more effectively. Extending the method to handle more complex imaging scenarios like those with varying lighting conditions, motion blur, or severe compression artifacts is another area of importance. The current reliance on simulated data presents a limitation; therefore, developing a robust real-world quad-Bayer video dataset is essential for validating and further advancing this work. Finally, exploring applications of MambaSCI beyond video reconstruction should be a priority. The underlying principles could be valuable for other computational imaging problems, particularly in settings where computational efficiency is paramount.
More visual insights#
More on figures

🔼 This figure compares the proposed quad-Bayer-based color video snapshot compressive imaging (SCI) method with previous Bayer-based methods. Subfigure (a) shows a schematic illustrating the difference in measurement and reconstruction process between the two approaches. Subfigure (b) presents a visual comparison of images captured using quad-Bayer and Bayer CFA patterns, highlighting the improved sharpness and reduced noise in the quad-Bayer image.
read the caption
Figure 2: (a) Schematic diagram of the comparison between color video SCI based on the proposed quad-Bayer-based method and the previous Bayer-based method. (b) Photo taken by quad-Bayer CFA pattern (Sony IMX689) (top) and Bayer CFA pattern (bottom). One can see that the upper image is sharper with less noise.

🔼 This figure shows the architecture of MambaSCI, a novel network for reconstructing color videos from quad-Bayer patterned snapshot compressive imaging (SCI) measurements. It details the overall reconstruction process, the MambaSCI network architecture, the Residual-Mamba-Block (RSTMamba) which is a core building block consisting of Spatial-Temporal Mamba (STMamba), Edge-Detail-Reconstruction (EDR) and Channel Attention (CA) modules, and finally, the STMamba module which uses structured State Space Models (SSMs) for efficient spatial-temporal feature extraction.
read the caption
Figure 3: The proposed MambaSCI network architecture and overall process for color video reconstruction. (a) Quad-Bayer patterned color video SCI reconstruction process. It feeds quad-Bayer pattern measurement Y and masks M into the initialization block to get Xin and inputs it into MambaSCI network to get the reconstructed RGB color video Xout. (b) The overall network architecture of the proposed MambaSCI network. (c) Structure of Residual-Mamba-Block (RSTMamba) with STMamba, EDR, and CA modules connected via residuals. The detailed design of EDR and CA is shown in Fig. 4. (d) STMamba. It captures spatial-temporal consistency via structured SSMs that enable parallel scanning in the spatial forward-backward and temporal dimensions.
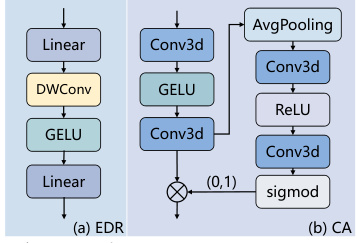
🔼 This figure shows the detailed architecture of the Edge-Detail-Reconstruction (EDR) module and the Channel Attention (CA) module, which are key components of the Residual-Mamba-Block. The EDR module uses a combination of linear layers, depthwise separable convolutions (DWConv), and GELU activation functions to enhance edge details. The CA module uses average pooling, multiple Conv3d layers, and a sigmoid activation function to generate channel attention weights, which are then used to refine the features. Both modules are designed to improve the reconstruction quality by addressing limitations in the original Mamba model.
read the caption
Figure 4: Detailed design of EDR and CA module.

🔼 This figure compares the visual reconstruction results of several different algorithms on four different middle-scale simulation color video datasets. Each row shows the ground truth video frame and the reconstruction results from GAP-TV, PnP-FastDVDnet, STFormer-B, EfficientSCI-B, and MambaSCI-B. The PSNR and SSIM values are given for each reconstruction to show a quantitative comparison in addition to the visual comparison.
read the caption
Figure 5: Visual reconstruction results of different algorithms on middle-scale simulation color video dataset (Bosphorus #10, Runner #11, Traffic #32 and Jockey #24 in order from top to bottom). PSNR/SSIM is shown in the upper left corner of each picture.

🔼 This figure compares the visual reconstruction results of different algorithms on four mid-scale simulation color video sequences. Each row represents a different video sequence, showing the ground truth and the reconstructions generated by GAP-TV, PnP-FastDVDnet, STFormer-B, EfficientSCI-B, MambaSCI-S, and MambaSCI-B. The PSNR and SSIM values are provided for each reconstruction to quantify the quality.
read the caption
Figure 5: Visual reconstruction results of different algorithms on middle-scale simulation color video dataset (Bosphorus #10, Runner #11, Traffic #32 and Jockey #24 in order from top to bottom). PSNR/SSIM is shown in the upper left corner of each picture.

🔼 This figure shows three images demonstrating the reconstruction process from raw data to a color RGB image. (a) shows the initial reconstruction raw data, which is grayscale. (b) shows the data after applying the quad-Bayer pattern, showing a green and blue color pattern superimposed on the grayscale image. (c) shows the final RGB color image obtained after demosaicing, which is a color image with clear details.
read the caption
Figure 7: Process of reconstruction from Raw to color RGB image.

🔼 This figure compares the visual reconstruction results of different algorithms on four mid-scale simulation videos. Each video is shown with the ground truth and reconstructions by GAP-TV, PnP-FastDVDnet, STFormer-B, EfficientSCI-B, MambaSCI-S, and MambaSCI-B. The PSNR and SSIM values are provided for each reconstruction, offering a quantitative comparison in addition to the qualitative visual assessment.
read the caption
Figure 5: Visual reconstruction results of different algorithms on middle-scale simulation color video dataset (Bosphorus #10, Runner #11, Traffic #32 and Jockey #24 in order from top to bottom). PSNR/SSIM is shown in the upper left corner of each picture.

🔼 This figure compares the visual reconstruction results of different algorithms on four mid-scale simulation color video datasets. The ground truth is shown alongside the results from GAP-TV, PnP-FFDNet, PnP-FastDVDnet, STFormer-B, EfficientSCI-B, MambaSCI-S, and MambaSCI-B. PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index) values are provided for each reconstruction to quantify the quality of the reconstruction. The red boxes highlight specific areas for visual comparison of detail.
read the caption
Figure 5: Visual reconstruction results of different algorithms on middle-scale simulation color video dataset (Bosphorus #10, Runner #11, Traffic #32 and Jockey #24 in order from top to bottom). PSNR/SSIM is shown in the upper left corner of each picture.

🔼 This figure compares the visual reconstruction results of several algorithms on four middle-scale simulation color video datasets. The ground truth video frames are shown alongside the reconstructions from GAP-TV, PnP-FFDNet, PnP-FastDVDnet, STFormer-B, EfficientSCI-B, MambaSCI-S, and MambaSCI-B. The PSNR and SSIM values for each reconstruction are provided in the top-left corner of each frame. The figure demonstrates the superior visual quality and detail preservation achieved by MambaSCI-B compared to the other algorithms.
read the caption
Figure 5: Visual reconstruction results of different algorithms on middle-scale simulation color video dataset (Bosphorus #10, Runner #11, Traffic #32 and Jockey #24 in order from top to bottom). PSNR/SSIM is shown in the upper left corner of each picture.

🔼 This figure compares the visual reconstruction quality of different algorithms on four mid-scale simulation color video sequences. The ground truth is shown alongside results from GAP-TV, PnP-FastDVDnet, STFormer-B, EfficientSCI-B, MambaSCI-S, and MambaSCI-B. The PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index) values are displayed in the top-left corner of each reconstructed video frame. It visually demonstrates the improved visual quality and reduced artifacts of the proposed MambaSCI method compared to state-of-the-art methods.
read the caption
Figure 5: Visual reconstruction results of different algorithms on middle-scale simulation color video dataset (Bosphorus #10, Runner #11, Traffic #32 and Jockey #24 in order from top to bottom). PSNR/SSIM is shown in the upper left corner of each picture.

🔼 This figure compares the visual reconstruction quality of different algorithms (GAP-TV, PnP-FastDVDnet, STFormer-B, EfficientSCI-B, and MambaSCI-B) on four middle-scale simulation color videos. The top row shows the ground truth, followed by the reconstruction results of each algorithm. PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index) values are provided for each reconstruction, offering quantitative metrics for comparing reconstruction performance. Visually, the image demonstrates how MambaSCI achieves superior reconstruction quality compared to other methods, preserving more details and colors.
read the caption
Figure 5: Visual reconstruction results of different algorithms on middle-scale simulation color video dataset (Bosphorus #10, Runner #11, Traffic #32 and Jockey #24 in order from top to bottom). PSNR/SSIM is shown in the upper left corner of each picture.

🔼 This figure compares the visual reconstruction results of several algorithms on a middle-scale simulation color video. The algorithms shown include GAP-TV, PnP-FFDNet, PnP-FastDVDnet, STFormer-B, EfficientSCI-B, MambaSCI-S, and MambaSCI-B. The figure highlights the visual differences in reconstruction quality between the various methods, particularly concerning details and artifacts. Red boxes are used to highlight specific areas of the image for easier comparison of the details of reconstruction.
read the caption
Figure 10: Visual reconstruction results of different algorithms on middle-scale simulation color video Bosphrous #16.
More on tables
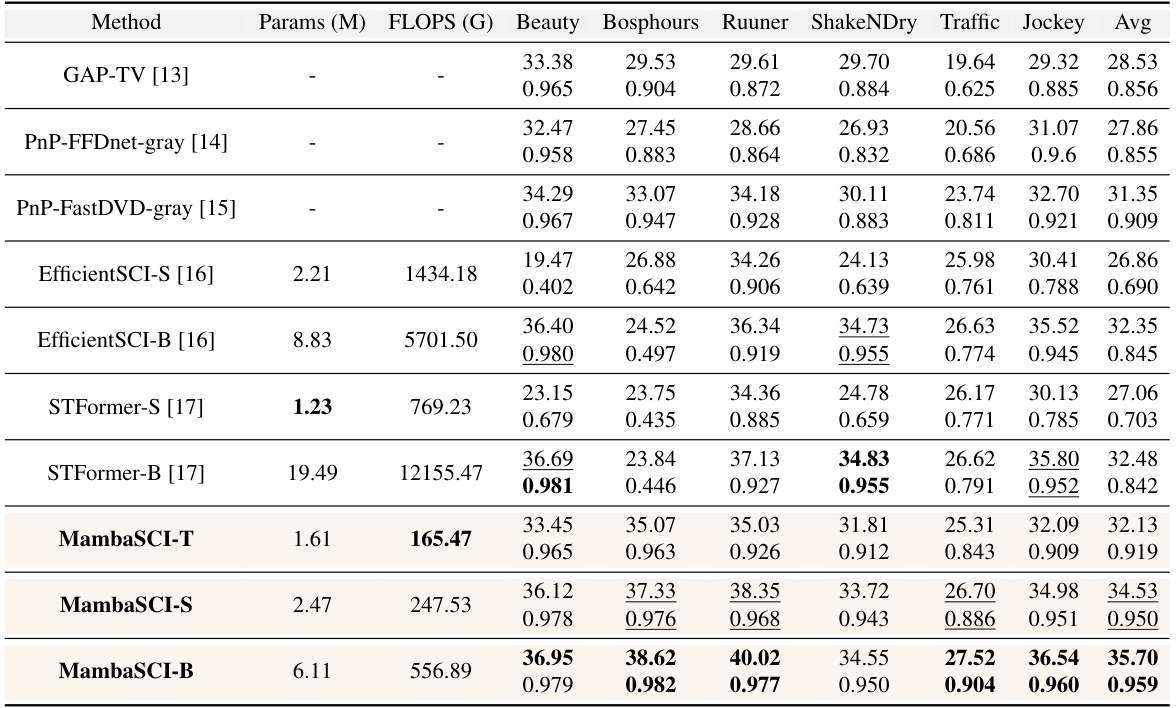
🔼 This table compares the performance of the proposed MambaSCI method against six state-of-the-art (SOTA) methods on six simulated videos. The comparison is based on two metrics: Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). Higher values for both metrics indicate better performance. The table highlights the best and second-best results for each video.
read the caption
Table 2: Comparisons between MambaSCI and SOTA methods on 6 simulation videos. PSNR (upper entry in each cell), and SSIM (lower entry in each cell) are reported. The best and second-best results are highlighted in bold and underlined.
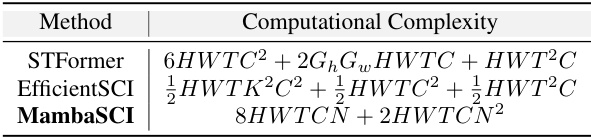
🔼 This table compares the computational complexity of three different video SCI reconstruction methods: STFormer, EfficientSCI, and the proposed MambaSCI. The complexity is expressed in terms of the height (H), width (W), number of frames (T), number of channels (C), kernel size (K), and parameters (N). It highlights that MambaSCI achieves significantly lower complexity than the other two methods.
read the caption
Table 3: Computational complexity of several SOTAs.
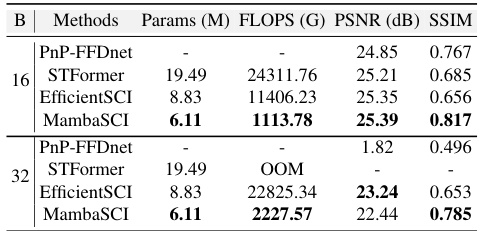
🔼 This table presents a performance comparison of different video reconstruction methods (PnP-FFDNet, STFormer, EfficientSCI, and MambaSCI) under different compression ratios (B=16 and B=32). It shows the number of parameters (Params), GFLOPS (FLOPS), PSNR (dB), and SSIM for each method. The results illustrate the trade-off between model complexity and reconstruction performance at varying compression levels. Note that STFormer ran out of memory (OOM) at B=32.
read the caption
Table 4: Performance analysis at B=16 and 32 cases.
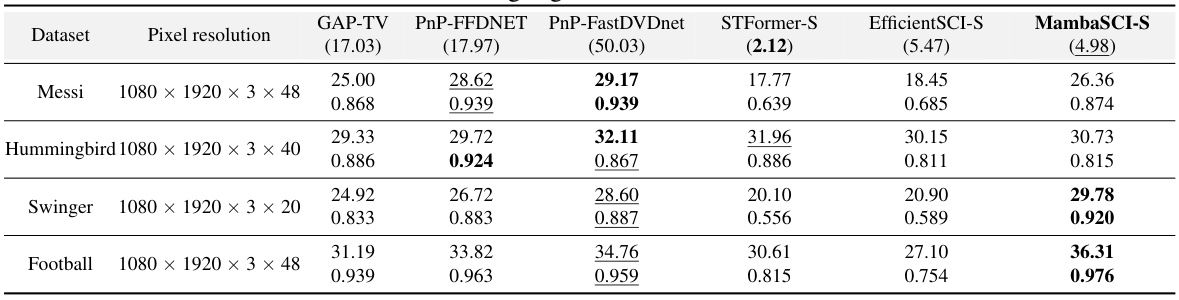
🔼 This table compares the performance of MambaSCI against other state-of-the-art (SOTA) methods on four large-scale simulation color videos. The metrics used for comparison are PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index). The table also shows the total time (in minutes) required to reconstruct all four videos using each method, providing a measure of computational efficiency. The best and second-best results for each video are highlighted.
read the caption
Table 5: Comparisons between MambaSCI and SOTA methods on 4 large-scale simulation videos. PSNR (upper), and SSIM (lower) are reported. The total time (minutes) taken to reconstruct 4 videos is under each method. The best and second-best results are highlighted in bold and underlined.

🔼 This table presents the ablation study results, comparing the reconstruction quality (PSNR and SSIM), number of parameters, and FLOPS across different models. Each row represents a model variation: the baseline model, and models with either the STMamba block, EDR module, or CA module added individually or in combination. The checkmarks (✓) indicate which module(s) are included in each model variation. The results demonstrate the contribution of each module to the overall performance of the MambaSCI architecture.
read the caption
Table 6: Ablation study on each major module.
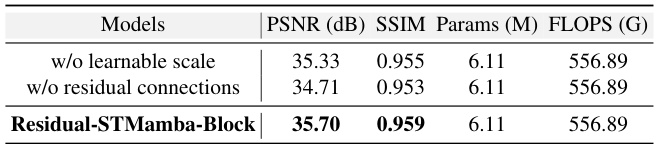
🔼 This table presents the ablation study on the Residual-Mamba-Block, comparing the performance of models with and without learnable scales and residual connections. The results show that the combination of learnable scales and residual connections in the Residual-STMamba-Block leads to the best PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index) scores. The number of parameters (Params) and floating-point operations (FLOPS) remain consistent across all models, demonstrating that improvements are not at the expense of significantly increased computational cost.
read the caption
Table 7: Ablation study on Residual-Mamba-Block
Full paper#