TL;DR#
Current audio captioning methods heavily rely on large, labeled datasets, hindering progress in this area. The ‘modality gap’ between audio and visual elements poses a significant challenge for multimodal representation learning. This paper addresses these challenges by re-purposing existing image captioning models to perform zero-shot audio captioning. This innovative approach avoids the need for extensive labeled audio data.
The proposed solution involves a novel two-stage methodology. First, it aligns the token distributions of an audio encoder and the image captioner’s encoder using Maximum Mean Discrepancy (MMD) or Optimal Transport (OT). This alignment enables the image captioner to perform zero-shot audio captioning. Second, it fine-tunes the model using audiovisual distillation, refining the model’s ability to generate audio captions based on both audio and visual information. The research achieves significant improvements in zero-shot audio captioning, showcasing the effectiveness of its approach.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel approach to zero-shot audio captioning, a challenging task with limited labeled data. The unsupervised methodology, leveraging advanced image captioning models and distribution alignment, offers a substantial advancement. Its potential impact lies in enabling applications requiring audio description without extensive training data, opening new avenues for research in multimodal learning and cross-modal adaptation. The results demonstrate state-of-the-art performance, surpassing existing methods. Therefore, this work provides crucial insights and technical contributions for researchers in audio-visual understanding and AI.
Visual Insights#
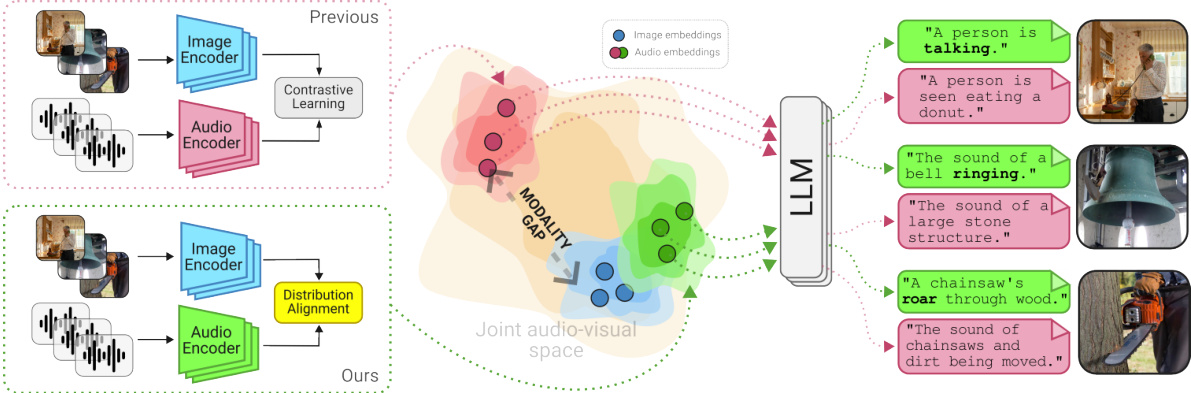
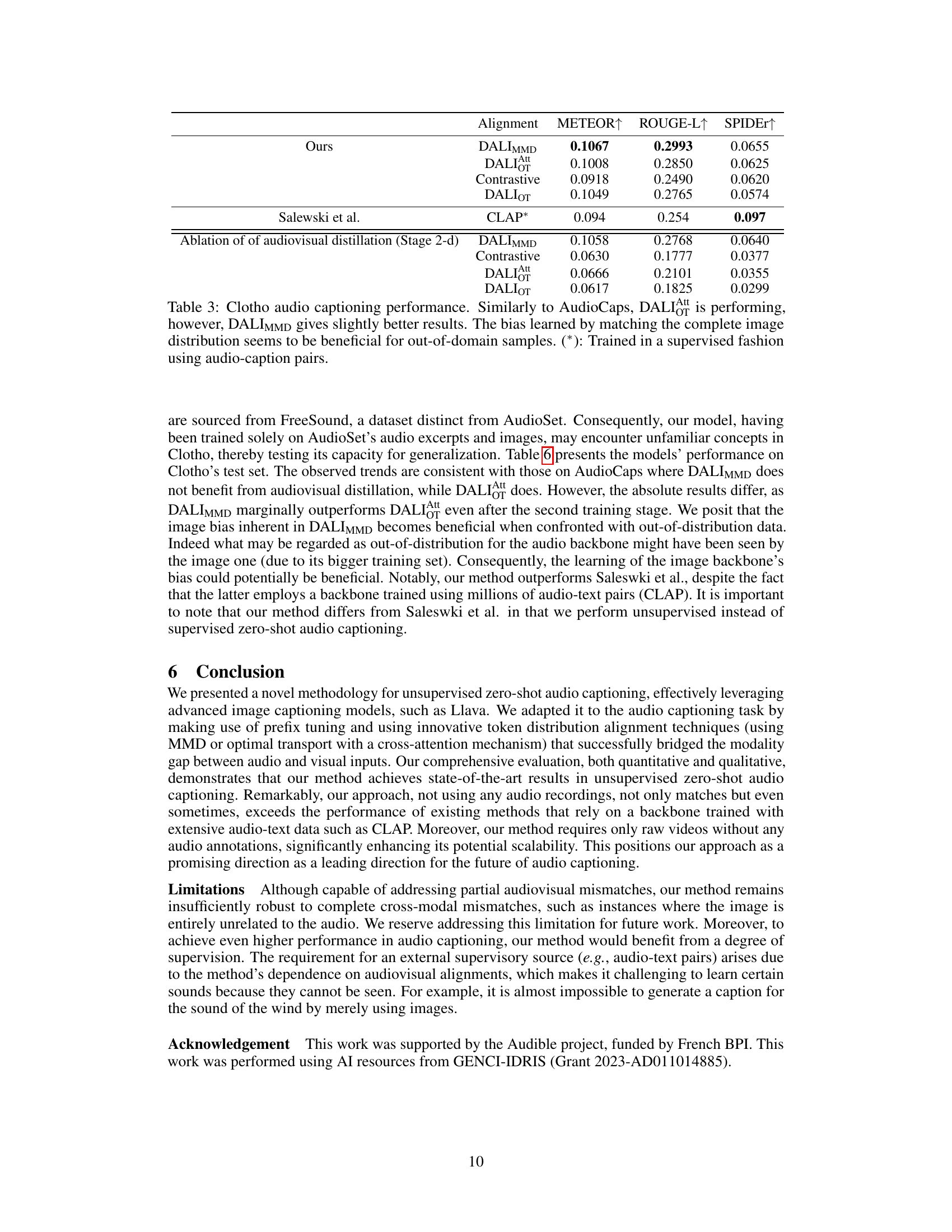
🔼 This figure illustrates the difference between traditional contrastive learning methods for audiovisual alignment and the proposed distribution alignment method. Contrastive learning, while effective in aligning features across modalities, often results in a ‘modality gap’, where audio and visual embeddings are represented in distinct, non-overlapping regions of the embedding space. This hinders smooth integration between modalities. In contrast, the proposed distribution alignment method directly matches the distributions of tokens produced by an audio backbone and those of an image captioner, effectively bridging the modality gap and enabling better joint representations for audio captioning. The figure visually depicts this using manifolds representing different modalities in embedding space.
read the caption
Figure 1: Conventional audiovisual alignment through contrastive learning leads to a gap between modalities. Our proposed distribution alignment method matches closely both distributions leading to better joint representations for audio captioning.
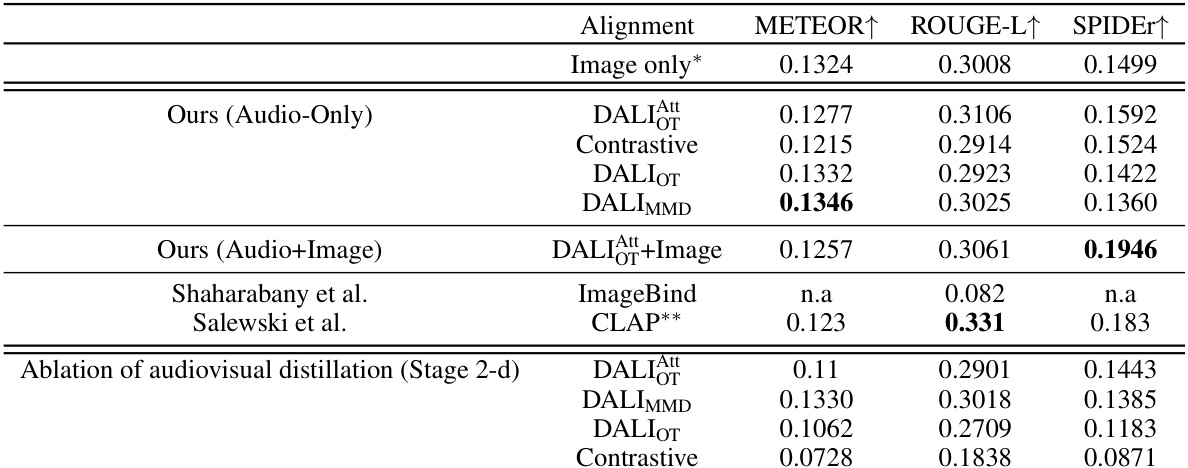
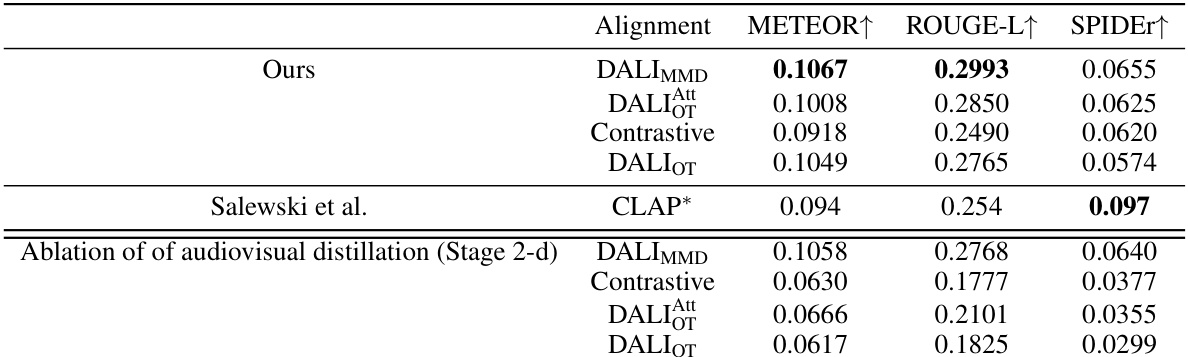
🔼 This table presents a comparison of different audio captioning methods on the AudioCaps test set. The methods compared include the authors’ proposed methods (DALI with different alignment strategies and with/without audiovisual distillation), a contrastive learning baseline, and two existing state-of-the-art methods (Shaharabany et al. and Salewski et al.). The table shows the performance of each method using three standard metrics: METEOR, ROUGE-L, and SPIDEr. The results indicate that the authors’ proposed DALI method significantly outperforms existing methods in zero-shot settings, particularly when using audiovisual information.
read the caption
Table 1: Audio captioning performance on AudioCaps test set. Our results are obtained using 16 (image,audio-captions) pairs for the prefix tuning phase. (*): No alignment. (**): Trained in a supervised fashion using audio-caption pairs. Results are ordered by SPIDEr score.
In-depth insights#
Audio-Visual Alignment#
Audio-visual alignment in multimodal learning seeks to bridge the gap between auditory and visual information. The core challenge lies in the inherent disparity between these modalities; sounds may originate from unseen objects, while visible objects might not produce any sound. Successful alignment requires sophisticated techniques to effectively encode and relate these heterogeneous data types. Contrastive learning, a prevalent method, aims to learn joint representations by maximizing agreement between corresponding audio and visual features while minimizing agreement between dissimilar pairs. However, this approach often struggles with the “modality gap,” where distinct modalities are poorly integrated. Alternative methods, such as distribution alignment, offer a promising avenue to circumvent this challenge by matching the distributions of tokens from separate audio and visual backbones. These methods require careful consideration of how best to represent and align the respective data structures. Ultimately, successful audio-visual alignment is crucial for developing more robust and contextually rich multimodal systems, particularly for applications like audio captioning, where a comprehensive understanding of the audio-visual scene is paramount.
Zero-Shot Learning#
Zero-shot learning (ZSL) aims to enable models to recognize unseen classes during testing, which were not present during training. This is achieved by leveraging auxiliary information such as semantic attributes or word embeddings to bridge the gap between seen and unseen classes. A key challenge is the ‘semantic gap,’ the difficulty in accurately aligning visual features with semantic descriptions. Existing methods often rely on learning mappings between visual and semantic spaces, typically through supervised or weakly supervised approaches. The paper explores a novel approach to address ZSL by aligning the distribution of tokens in both the visual and auditory domains. This approach is quite powerful, as it enables zero-shot audio captioning. By leveraging the knowledge learned from image captioning models, the proposed method eliminates the need for handcrafted audio-caption pairs during training, thereby enhancing efficiency and scalability. The authors also innovatively match token distributions using Maximum Mean Discrepancy or Optimal Transport, which further aids in bridging the semantic gap and achieving better performance in zero-shot scenarios. The use of prefix tuning to guide the model towards audio captioning also stands out as a method to enhance performance, while maintaining the original image captioning capabilities. In summary, this research advances ZSL by tackling the challenges of modality gaps in audio-visual data, effectively transferring knowledge learned from one modality to another, and achieving robust zero-shot performance.
Distribution Alignment#
The concept of “Distribution Alignment” in the context of multimodal learning, specifically for zero-shot audio captioning, involves bridging the gap between the distinct distributions of audio and image token representations. Instead of relying on traditional contrastive learning, which often suffers from a “modality gap,” this technique directly aligns the probability distributions. This alignment is crucial because it allows the model to leverage the knowledge embedded within a pre-trained image captioning model for the task of audio description without explicit training on audio-text pairs. Two main methods are explored: Maximum Mean Discrepancy (MMD) and Optimal Transport (OT), the latter enhanced by cross-attention. MMD measures the distance between the distributions, while OT finds an optimal mapping minimizing the transportation cost, further improved with cross-attention to selectively align semantically similar tokens. This sophisticated alignment enables smooth integration of audio and visual information for significantly improved zero-shot audio captioning performance.
Prefix Tuning#
Prefix tuning, in the context of large language models (LLMs), is a parameter-efficient fine-tuning method that adapts a pre-trained model to a new task by learning a small set of prefix tokens that are prepended to the input. This technique avoids retraining the massive parameter space of the LLM, making it computationally efficient and less prone to overfitting. The prefix tokens act as a soft prompt, conditioning the model’s behavior and guiding it towards the desired output for the target task. In the paper, prefix tuning is used to adapt an image captioning model towards audio captioning, effectively enabling the model to generate text descriptions of sounds from either audio-only or audio-visual input, demonstrating the transferability of knowledge learned within the VLM. The effectiveness of this approach hinges on the ability of prefix tuning to successfully condition the LLM without altering the core parameters of the image encoder and thus preserving its original functionality. The integration of prefix tuning with other methods like token distribution alignment, further demonstrates a parameter-efficient and flexible approach to zero-shot audio captioning.
Future Directions#
Future research could explore several promising avenues. Improving the robustness of the audio-visual alignment is crucial, especially in handling scenarios with significant mismatches or occlusions between audio and visual modalities. Investigating alternative token distribution alignment techniques beyond MMD and OT, perhaps incorporating generative models or transformer-based approaches, could lead to more accurate and coherent joint representations. Expanding the model’s capacity to handle more complex audio events and integrating external knowledge sources like audio ontologies and semantic networks could enhance caption quality. Finally, addressing the computational costs of the approach for wider adoption and exploring real-time applications presents a significant challenge, but one with high potential reward.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage process of the proposed approach for zero-shot audio captioning. Stage 1 involves prefix tuning with image-audio caption pairs and token distribution alignment between the audio and image backbones, enabling audio captioning by replacing the image backbone. Stage 2 refines audio captions using audio-visual inputs and fine-tunes the MLP, allowing for audio captioning using audio or audio-visual inputs.
read the caption
Figure 2: Overview of the proposed approach. In the first stage, a prefix tuning is performed using a few (image, audio-caption) pairs (1-a). Additionally, the audio backbone is aligned with the image backbone (1-b) through distribution alignment. Audio captioning can then be performed by switching the image backbone with the audio backbone and adding the prefix tokens (1-c). In a second stage, visually-informed audio captions are generated using both audio, image, and prefix tokens. The MLP mapping the audio encoder to the language model is then fine-tuned with these pseudo captions (2-d). The final inference for audio captioning, using audio or audio visual inputs, is performed by forwarding the aligned audio backbone's output through the trained MLP to obtain the LLM input (2-e).
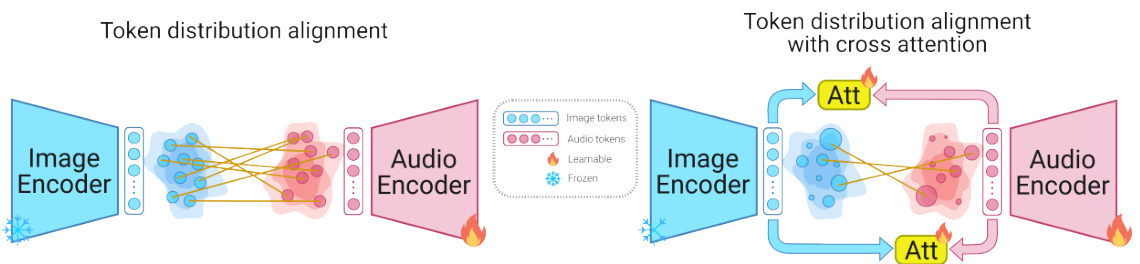
🔼 This figure illustrates two methods for aligning the distributions of audio and image tokens. The left side shows a method using optimal transport, where a cost matrix is computed based on the audio and image tokens, and the alignment is performed by minimizing the transport cost. The right side depicts a method using attentive optimal transport, which utilizes cross-attention layers to learn the weights for the transport cost matrix, allowing for a more flexible and accurate alignment.
read the caption
Figure 3: Multimodal distribution alignment through optimal transport. The audio and image tokens are used to compute the cost matrix, while two separate cross-attention layers estimate the weights Att and Att.
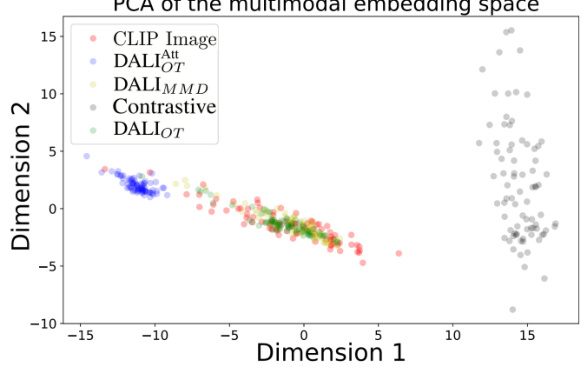
🔼 This figure visualizes the average token distributions from different methods on the AudioCaps dataset using Principal Component Analysis (PCA). It shows that contrastive learning produces audio and image embeddings that occupy distinct regions in the embedding space, illustrating the ‘modality gap.’ In contrast, Maximum Mean Discrepancy (MMD) and Optimal Transport (OT) based methods generate embeddings that are closer together. Specifically, the model using attentive Optimal Transport produces audio embeddings that are more closely aligned with the image embeddings than those produced by MMD or contrastive learning. This visualizes the effectiveness of their proposed distribution alignment method at bridging the modality gap.
read the caption
Figure 4: AudioCaps average tokens distribution. While contrastive learning maps the audio in a space separate from the image ones, MMD and optimal transport project in the same part of the space. The model trained using attentive optimal transport projects the audios in a space closer to the image, with marginal overlap.

🔼 This figure illustrates the two-stage process proposed for zero-shot audio captioning. Stage 1 involves prefix tuning using a few image-audio caption pairs to adapt the image captioner for audio, and aligning the audio backbone with the image backbone via distribution alignment. This allows for performing audio-only captioning by replacing the image backbone with the aligned audio backbone. Stage 2 leverages visually-informed audio captions (using audio, image and prefix tokens) to fine-tune an MLP that maps audio tokens to language model embeddings, enabling robust audio and audio-visual captioning.
read the caption
Figure 2: Overview of the proposed approach. In the first stage, a prefix tuning is performed using a few (image, audio-caption) pairs (1-a). Additionally, the audio backbone is aligned with the image backbone (1-b) through distribution alignment. Audio captioning can then be performed by switching the image backbone with the audio backbone and adding the prefix tokens (1-c). In a second stage, visually-informed audio captions are generated using both audio, image, and prefix tokens. The MLP mapping the audio encoder to the language model is then fine-tuned with these pseudo captions (2-d). The final inference for audio captioning, using audio or audio visual inputs, is performed by forwarding the aligned audio backbone's output through the trained MLP to obtain the LLM input (2-e).

🔼 This figure shows the results of a Principal Component Analysis (PCA) on the average token embeddings generated by different methods for audio captioning. The contrastive learning approach shows a clear separation between audio and image embeddings, illustrating the ‘modality gap’. In contrast, the Maximum Mean Discrepancy (MMD) and Optimal Transport (OT) methods result in audio and image embeddings that occupy similar regions of the embedding space. Notably, the attentive OT method shows the closest proximity between audio and image embeddings, indicating more effective alignment of the modalities.
read the caption
Figure 4: AudioCaps average tokens distribution. While contrastive learning maps the audio in a space separate from the image ones, MMD and optimal transport project in the same part of the space. The model trained using attentive optimal transport projects the audios in a space closer to the image, with marginal overlap.
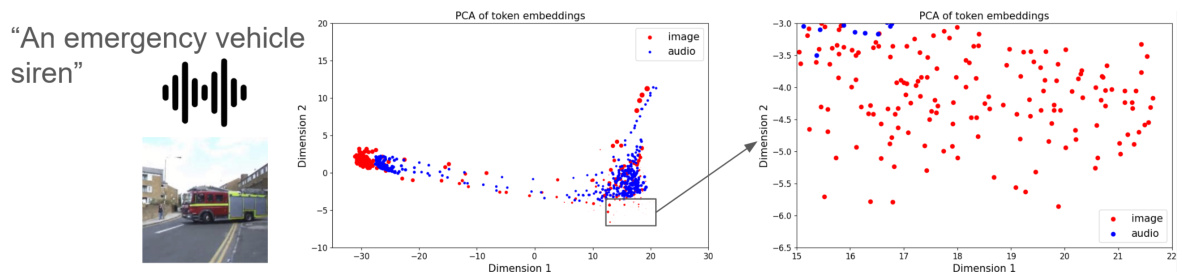
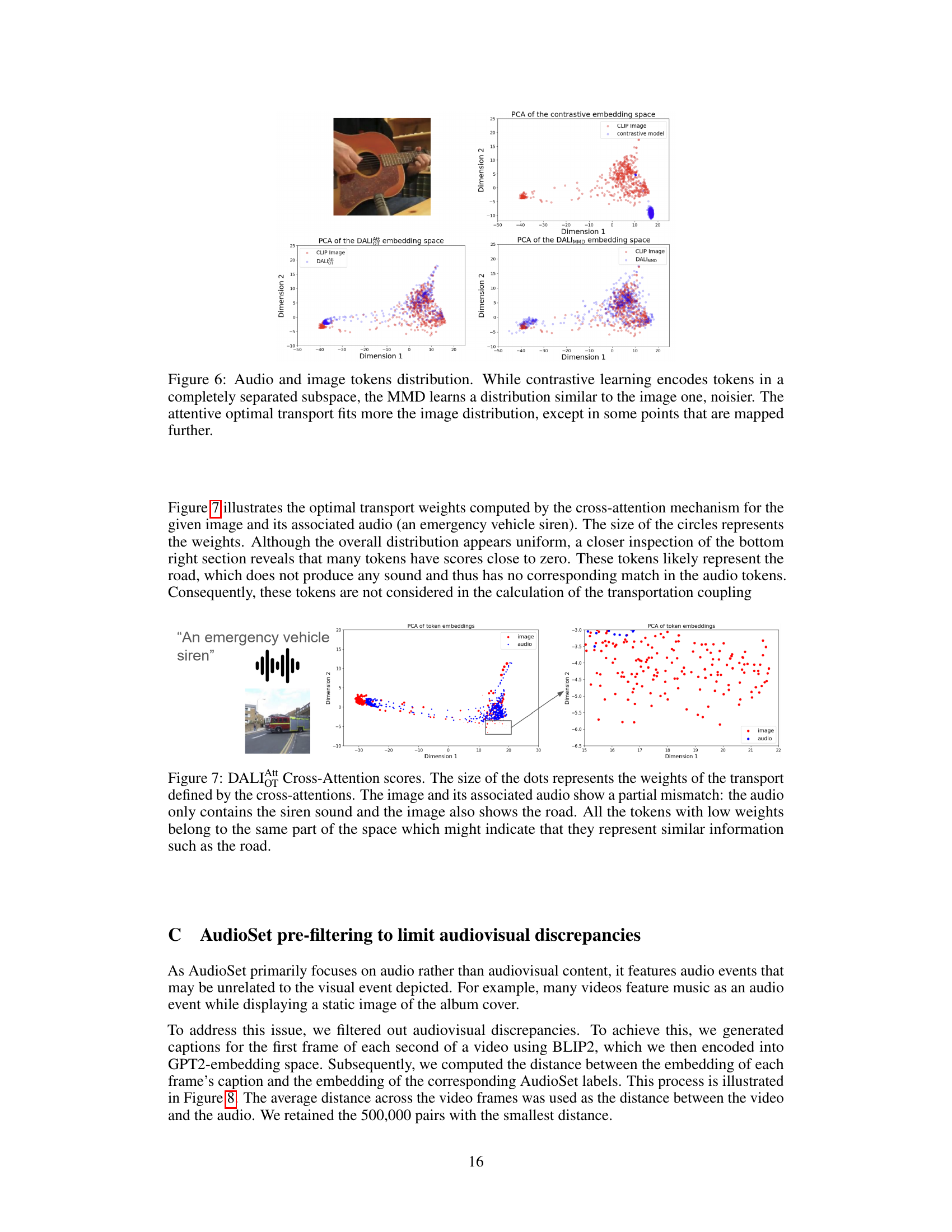
🔼 This figure shows the results of applying the cross-attention mechanism within the optimal transport method used for aligning audio and image token distributions. The size of the dots corresponds to the weight assigned by the cross-attention mechanism to each token pair. The example shown involves an image of an emergency vehicle and its associated siren sound. The figure highlights that the cross-attention mechanism effectively identifies and down-weights tokens representing elements present in the image but not the audio (e.g., the road), thus focusing the alignment on semantically relevant tokens (e.g., the siren). This demonstrates the capacity of the cross-attention mechanism to handle partial mismatches between audio and visual modalities.
read the caption
Figure 7: DALI Cross-Attention scores. The size of the dots represents the weights of the transport defined by the cross-attentions. The image and its associated audio show a partial mismatch: the audio only contains the siren sound and the image also shows the road. All the tokens with low weights belong to the same part of the space which might indicate that they represent similar information such as the road.

🔼 This figure illustrates the process used to filter the AudioSet dataset to remove videos with significant discrepancies between the audio and visual content. BLIP-2 is used to generate captions for 10 frames extracted from each video. These captions, and the AudioSet labels, are then embedded in a common vector space using an image encoder. The average distance between the BLIP-2 caption embeddings and AudioSet label embeddings is calculated for each video and represents the audiovisual discrepancy score. Videos with low discrepancy scores are retained in the filtered dataset.
read the caption
Figure 8: Discrepancies filtering process: 10 frames of the video are captioned by BLIP-2, captions are embedded in a text space and compared to the embedding of the class labels. The average of the distances of the frame is considered as the distance between audio and video.
More on tables

🔼 This table compares the ground truth audio captions with the captions generated by two different models (DALIMMD and DALI_Att) after the first stage of training. The first stage focused on training prefix tokens and aligning the distribution of tokens produced by an audio backbone with those from the image captioner. The goal was to enable zero-shot audio captioning. The captions from the DALIMMD model include visual artifacts while the DALI_Att captions are more focused and accurate with the task.
read the caption
Table 2: Ground-truth audio captions, and captions generated by our audio models (after stage 1, without prefix tokens) by asking 'What can you see? Answer concisely'
🔼 This table presents the results of the audio captioning performance evaluation on the Clotho dataset. It compares different methods, including those based on DALI (Distribution Alignment) with Maximum Mean Discrepancy (MMD) and Optimal Transport (OT), along with a contrastive learning approach. The table highlights that while DALI generally performs well, DALIMMD (using MMD) shows a slight edge, potentially because its bias towards image data helps handle the out-of-distribution nature of the Clotho dataset (which differs from the AudioCaps dataset used for training). A supervised approach using CLAP is also included for comparison.
read the caption
Table 3: Clotho audio captioning performance. Similarly to AudioCaps, DALI is performing, however, DALIMMD gives slightly better results. The bias learned by matching the complete image distribution seems to be beneficial for out-of-domain samples. (*): Trained in a supervised fashion using audio-caption pairs.

🔼 This table presents a comparison of different methods for audio captioning on the AudioCaps test set. It shows the performance (using METEOR, ROUGE-L, and SPIDEr metrics) of the proposed approach (DALI, using both audio-only and audio-visual inputs) compared to other existing methods (Contrastive, ImageBind, and CLAP). The impact of using prefix tuning (a small set of image-audio captions) and audiovisual distillation is also evaluated. Results are ordered by the SPIDEr score, a comprehensive metric that combines several other metrics for captioning evaluation.
read the caption
Table 1: Audio captioning performance on AudioCaps test set. Our results are obtained using 16 (image,audio-captions) pairs for the prefix tuning phase. (*): No alignment. (**): Trained in a supervised fashion using audio-caption pairs. Results are ordered by SPIDEr score.

🔼 This table presents a comparison of different audio captioning methods on the AudioCaps test set. The methods compared include several variants of the proposed Distribution Alignment approach (DALI), using either Maximum Mean Discrepancy (MMD) or Optimal Transport (OT) for alignment, with and without audiovisual distillation. Results are also shown for a contrastive learning approach, as well as the existing Shaharabany et al. and Salewski et al. methods. The table highlights the performance of the proposed methods in a zero-shot setting (without using any annotated audio data for training), and shows a significant improvement compared to existing state-of-the-art techniques. The results are ordered by the SPIDEr score, a comprehensive metric for evaluating the quality of generated captions.
read the caption
Table 1: Audio captioning performance on AudioCaps test set. Our results are obtained using 16 (image,audio-captions) pairs for the prefix tuning phase. (*): No alignment. (**): Trained in a supervised fashion using audio-caption pairs. Results are ordered by SPIDEr score.

🔼 This table presents the results of the audio captioning task using different methods on the AudioCaps dataset. It compares the proposed method (DALI with different variations, and the ablation study without audiovisual distillation) against existing state-of-the-art approaches (Shaharabany et al., Salewski et al., and CLAP). The metrics used for comparison are METEOR, ROUGE-L, and SPIDEr. The table shows the performance of models with and without image input, as well as variations of the DALI approach based on different token distribution alignment methods. The prefix tuning phase used 16 image-audio caption pairs. The results highlight the superiority of the proposed DALI method.
read the caption
Table 1: Audio captioning performance on AudioCaps test set. Our results are obtained using 16 (image,audio-captions) pairs for the prefix tuning phase. (*): No alignment. (**): Trained in a supervised fashion using audio-caption pairs. Results are ordered by SPIDEr score.
Full paper#