↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current diffusion-based image super-resolution (SR) models often struggle to balance performance and efficiency. Many either ignore pretrained models or require many forward passes, limiting their practical use. This research addresses these issues.
DoSSR, a new SR model, tackles these limitations head-on. It cleverly starts the diffusion process from low-resolution (LR) images instead of random noise and introduces a novel ‘domain shift’ equation to integrate seamlessly with pretrained diffusion models. This significantly improves both efficiency and performance, setting a new state-of-the-art with a remarkable speedup and high-quality image generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image super-resolution because it presents DoSSR, a novel and efficient approach. It significantly improves inference speed (5-7x faster than previous methods) while maintaining state-of-the-art performance by leveraging pretrained diffusion models more effectively. This opens up exciting avenues for real-world applications of diffusion-based SR, pushing the boundaries of efficiency and performance trade-offs.
Visual Insights#
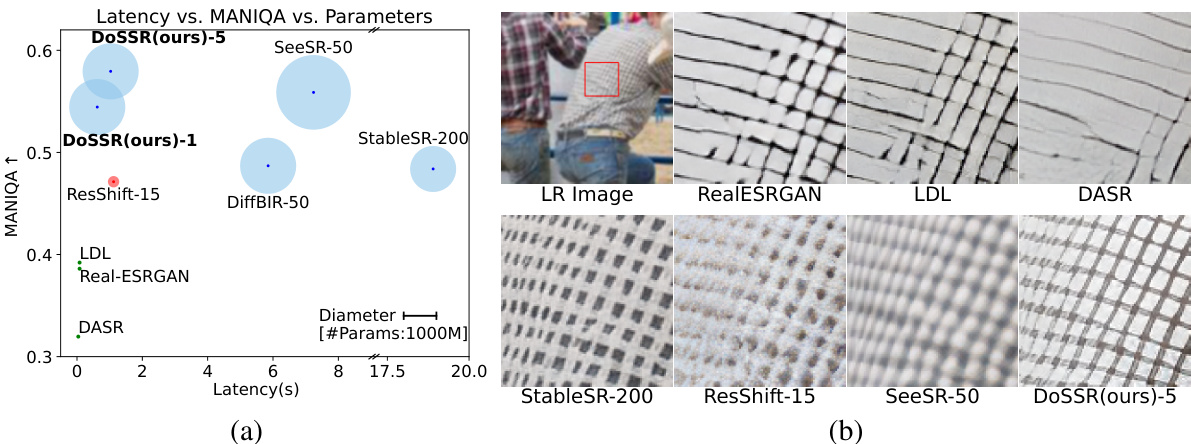
This figure presents a comparison of DoSSR against other state-of-the-art models. Subfigure (a) shows a scatter plot illustrating the trade-off between model latency (inference time), perceptual quality (measured by MANIQA), and model size (number of parameters). DoSSR demonstrates a superior balance of speed and performance compared to other approaches. Subfigure (b) provides a visual comparison of super-resolution results from DoSSR and other competing methods on a sample image, highlighting DoSSR’s ability to achieve superior qualitative results.
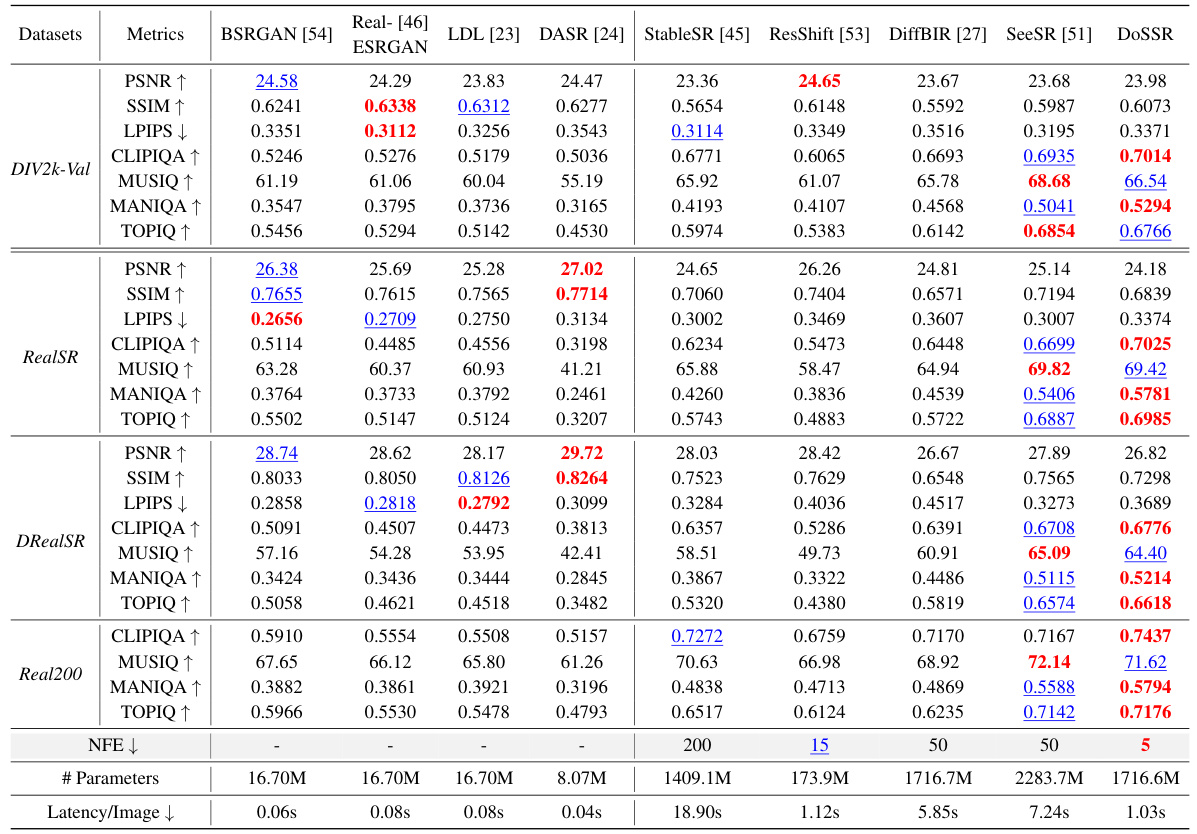
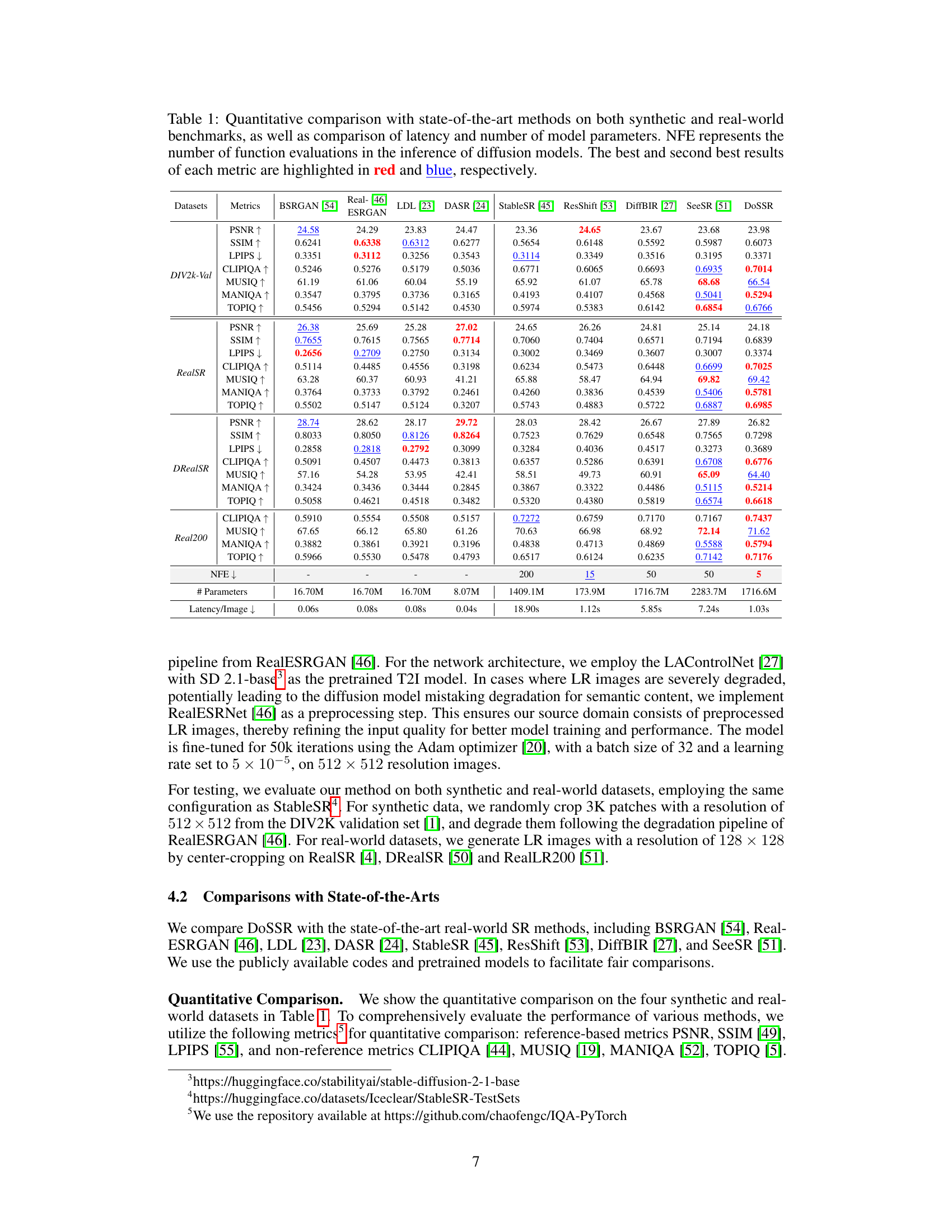
This table presents a quantitative comparison of DoSSR against other state-of-the-art super-resolution models on various metrics, including PSNR, SSIM, LPIPS, and others. It shows performance on both synthetic and real-world datasets and includes comparisons of inference latency and model size. The best and second-best results are highlighted.
In-depth insights#
Diffusion SR Models#
Diffusion-based super-resolution (SR) models have emerged as a powerful technique in image processing, offering compelling advantages over traditional methods. Their strength lies in the ability to generate highly realistic and perceptually pleasing high-resolution images from low-resolution inputs, often surpassing the quality achieved by GAN-based approaches. This is attributed to the inherent generative capabilities of diffusion models, which learn intricate data distributions and can effectively extrapolate details beyond the information present in the LR image. However, a key challenge with diffusion SR models is the computational cost, often requiring numerous iterative sampling steps, which significantly impacts inference efficiency. This limitation hinders their real-world applicability, especially in resource-constrained environments. Recent research efforts are actively focused on optimizing the diffusion process for SR, either through novel model architectures or more efficient sampling techniques. These advancements seek to balance the superior image quality provided by diffusion models with the need for faster and more efficient inference, aiming to bridge the gap between the impressive results seen in controlled settings and practical application demands.
DoS-SDES Approach#
The proposed DoS-SDES approach cleverly addresses the efficiency-performance trade-off in diffusion-based super-resolution. By framing super-resolution as a domain shift from low-resolution (LR) to high-resolution (HR) space, it elegantly integrates this shift into the diffusion process itself. This avoids the computationally expensive process of starting from random noise, a common drawback of traditional diffusion models. Instead, DoS-SDES leverages the generative power of pretrained diffusion models by initiating the diffusion process from the LR image, significantly speeding up inference. The transition from discrete to continuous domain shift via SDEs introduces further efficiency gains, enabling fast, custom-designed solvers to accelerate sampling. This continuous formulation improves computational tractability, allowing for faster and more accurate approximations during sampling. The result is a method achieving state-of-the-art performance while requiring substantially fewer sampling steps, showcasing a significant improvement in efficiency over prior diffusion-based SR methods.
Efficient Samplers#
Efficient samplers are crucial for diffusion-based models, particularly in computationally intensive applications like image super-resolution. The core idea revolves around accelerating the process of generating high-resolution images from low-resolution inputs by cleverly navigating the diffusion process. Instead of starting from random noise and iteratively refining, efficient samplers leverage the information present in the low-resolution image itself. This drastically reduces the number of steps required, leading to significant speed improvements. The key to this efficiency often lies in carefully designed modifications to the diffusion equations, enabling faster convergence. This might involve transitioning from a discrete-time to a continuous-time formulation (using stochastic differential equations), which allows for the design of customized and faster numerical solvers. Another approach is to intelligently incorporate pre-trained diffusion models as priors, guiding the sampling process towards more realistic and coherent outputs. Such techniques achieve state-of-the-art performance while requiring only a small fraction of the sampling steps of conventional methods. The design of optimized samplers must consider a trade-off between efficiency and accuracy, ensuring that speed gains do not compromise the quality of the final generated image.
Ablation Experiments#
Ablation experiments systematically remove components of a model to assess their individual contributions. In the context of a research paper, these experiments are crucial for understanding the effectiveness of individual components and design choices. By isolating and removing specific modules or techniques, researchers can determine their impact on overall performance and identify critical elements. For example, in image super-resolution, an ablation study might involve removing different stages of a deep learning pipeline, such as upsampling layers or attention mechanisms, and then evaluating the results. This helps determine which aspects most significantly contribute to high-quality results. A well-designed ablation study is essential for validating design choices, understanding the relative importance of different model components, and supporting the paper’s claims. The results often guide future work by highlighting areas for improvement or simplification and are critical to a strong, impactful paper. They also help establish the necessity of each component and demonstrate whether any performance gains can be attributed to a specific component.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Improving the robustness of the model to diverse real-world degradations is crucial, potentially through incorporating more sophisticated degradation models during training. Investigating alternative sampling methods beyond the proposed SDE solvers could further enhance efficiency, perhaps focusing on techniques better suited for specific hardware architectures. Another key area involves exploring different network architectures, such as incorporating transformers or other advanced modules, to potentially improve performance and generalization. Finally, extending the approach to other image restoration tasks, like inpainting or denoising, could demonstrate the broader applicability and generalizability of the core principles introduced in this research.
More visual insights#
More on figures

This figure illustrates the proposed diffusion process with domain shift in DoSSR. Panel (a) shows the forward diffusion process, starting from a high-resolution (HR) image and gradually shifting towards a low-resolution (LR) image while adding noise. Panel (b) shows the reverse process, beginning from the LR image at time t₁ and using a fast sampler to generate the HR image. Panel (c) compares the score fields of Stable Diffusion (SD) and DoSSR, highlighting DoSSR’s enhanced ability to learn the pathway from LR to HR domains. Finally, panel (d) depicts the shifting sequence (ηt), which allows inference to start from t₁ instead of time T, improving efficiency.

This figure presents a qualitative comparison of the image super-resolution results obtained using DoSSR and other state-of-the-art diffusion-based methods. It showcases the visual quality of the results at different numbers of sampling steps, highlighting the improvements in detail and texture as the number of steps increases. The figure includes two examples, one featuring a Spiderman image and another with street scene, demonstrating DoSSR’s performance in handling diverse image types and levels of degradation.

This figure shows the impact of the number of sampling steps on the performance of DoSSR. (a) shows the quantitative results of SSIM and MUSIQ scores as a function of the number of inference steps. (b) displays a visual comparison of the results obtained with DoSSR using different numbers of steps and compared to those from other state-of-the-art methods. The results demonstrate that using a higher number of steps can result in better visual quality, but the improvement starts to plateau after a certain number of steps.

This figure presents a qualitative comparison of the image super-resolution results obtained using DoSSR and other state-of-the-art diffusion-based methods. It demonstrates the visual quality improvements at different numbers of inference steps, highlighting DoSSR’s ability to generate high-quality results even with a small number of steps. The images showcase improvements in texture detail and sharpness.

This figure illustrates the overall framework of the DoSSR model. The training process involves adding noise to the high-resolution (HR) image, gradually transitioning it to a low-resolution (LR) representation while incorporating preprocessed LR images as conditioning inputs. The inference process begins with an LR image, adding noise according to a specific domain shift equation, and then using a pretrained diffusion model (SD 2.1 UNet) along with a ControlNet for N steps to generate the HR image. The model leverages a domain shift strategy to improve efficiency by starting inference from an LR image instead of random noise.

This figure shows qualitative comparisons of the results from DoSSR and other state-of-the-art diffusion-based super-resolution (SR) methods. Different rows represent different input LR images and different columns represent the zoomed LR image, BSRGAN, RealESRGAN, LDL, DASR, StableSR, ResShift, DiffBIR, SeeSR, and DoSSR. The suffix -N denotes the number of inference steps for DoSSR and other diffusion methods. The figure demonstrates DoSSR’s ability to generate visually appealing and high-quality results, especially at fewer inference steps.

This figure compares the results of different diffusion-based super-resolution (SR) methods (DiffBIR, SeeSR, ResShift, and DoSSR) when using different random seeds. The goal is to show how sensitive these methods are to the choice of random seed, which is a common issue with diffusion models. The figure highlights that the results can vary significantly even with small changes to the random seed, despite the same number of inference steps. This demonstrates the stochastic nature of diffusion models and the need for techniques to mitigate the effects of random seed variability.

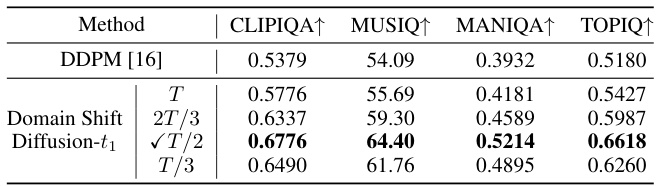
This figure presents an ablation study on the number of steps in DoSSR. Subfigure (a) shows the impact on quality metrics (SSIM and MUSIQ) with different numbers of sampling steps. Subfigure (b) shows qualitative results comparing DoSSR at different steps with other state-of-the-art SR methods. It demonstrates that while increasing the number of steps improves the quality of the results, DoSSR can achieve acceptable results in as few as one step.

This figure compares the qualitative results of DoSSR using different sampler orders (first-order, second-order, and third-order) with 5 sampling steps, and a first-order sampler with 10 sampling steps. The results demonstrate how increasing the order of the sampler and/or the number of steps improves the details and realism of the super-resolution image output. Two example images are provided to show this.
More on tables
This table presents a quantitative comparison of the proposed DoSSR model with several state-of-the-art image super-resolution methods. Performance is evaluated using various metrics (PSNR, SSIM, LPIPS, CLIPIQA, MUSIQ, MANIQA, TOPIQ) on both synthetic and real-world datasets. The table also includes a comparison of the latency and number of parameters for each model, providing insights into efficiency and resource requirements. NFE, or Number of Function Evaluations, is included for diffusion models to indicate sampling efficiency.
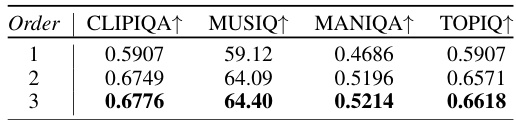
This table presents a quantitative comparison of DoSSR against other state-of-the-art super-resolution models. Metrics include PSNR, SSIM, LPIPS, CLIPIQA, MUSIQ, MANIQA, and TOPIQ, evaluated on DIV2K-Val, RealSR, and DRealSR datasets. The table also compares the latency and number of model parameters for each method, highlighting DoSSR’s efficiency.

This table presents a quantitative comparison of the proposed DoSSR model with several state-of-the-art image super-resolution (SR) models on both synthetic and real-world datasets. Metrics such as PSNR, SSIM, LPIPS, CLIPIQA, MUSIQ, MANIQA, and TOPIQ are used to evaluate the performance. The table also includes the latency, the number of parameters, and number of function evaluations (NFE) for each model, providing a comprehensive comparison of efficiency and effectiveness.
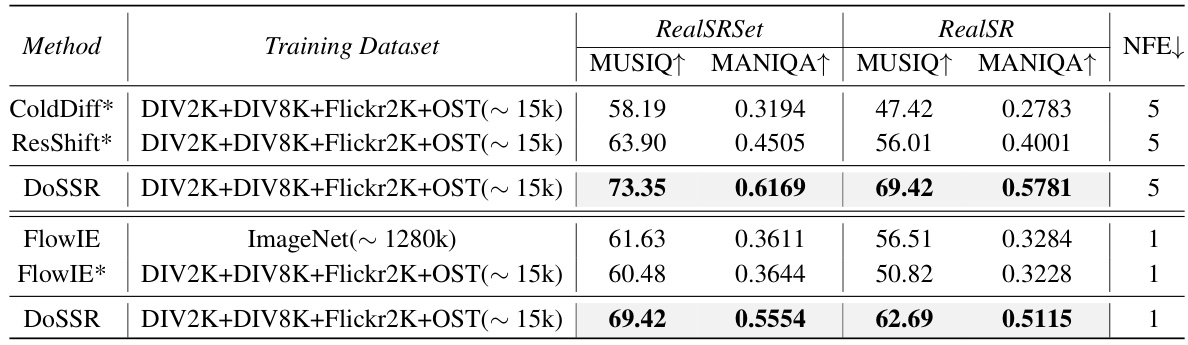
This table presents a quantitative comparison of the proposed DoSSR model with other state-of-the-art image super-resolution methods on both synthetic and real-world datasets. Metrics include PSNR, SSIM, LPIPS, CLIPIQA, MUSIQ, MANIQA, and TOPIQ. The table also compares the latency and number of model parameters for each method, highlighting the efficiency of DoSSR. NFE (Number of Function Evaluations) reflects the number of sampling steps used in the inference process, demonstrating DoSSR’s efficiency with only 5 steps.

This table presents a quantitative comparison of DoSSR with other state-of-the-art image super-resolution models. The comparison includes metrics such as PSNR, SSIM, LPIPS, CLIPIQA, MUSIQ, MANIQA, and TOPIQ on several benchmark datasets. Latency and model parameters are also compared to highlight the efficiency gains of DoSSR. The table uses red and blue highlighting to indicate the best and second-best performance for each metric.
Full paper#