↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Offline reinforcement learning (RL) struggles with generalization to new, unseen tasks. Existing methods often rely on expert demonstrations or other forms of domain knowledge, which are costly and sometimes impossible to obtain. This limits their applicability in real-world scenarios. Furthermore, traditional RL approaches often suffer from issues like function approximation, off-policy learning, and bootstrapping, leading to instability and unreliable results.
Meta-DT tackles these challenges by leveraging the power of transformer-based sequence modeling and world model disentanglement. The method uses a pre-trained context-aware world model to create a compact task representation, injecting this representation as contextual information into a transformer to generate sequences of actions. A self-guided prompt, created from history trajectories, is employed to provide additional task-specific information. This innovative approach eliminates the need for expert demonstrations or domain knowledge at test time, significantly enhancing the practicality and generalizability of offline meta-RL. Experiments show that Meta-DT outperforms existing methods on benchmark tasks, demonstrating its superior generalization ability across various scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Meta-DT, a novel offline meta-RL framework that achieves efficient generalization to unseen tasks without expert demonstrations or domain knowledge at test time. This addresses a critical limitation of current RL agents and opens new avenues for building more robust and generalizable AI systems. The use of a context-aware world model and a complementary prompt mechanism are particularly significant contributions, offering a practical approach to meta-RL.
Visual Insights#
🔼 This figure illustrates the Meta-DT framework. It shows how a context-aware world model is pre-trained to learn a compact task representation from multi-task data. This representation is then used as a condition for a causal transformer to generate sequences, guiding task-oriented behavior. The figure also highlights a self-guided prompt generation method using past trajectories to select informative segments.
read the caption
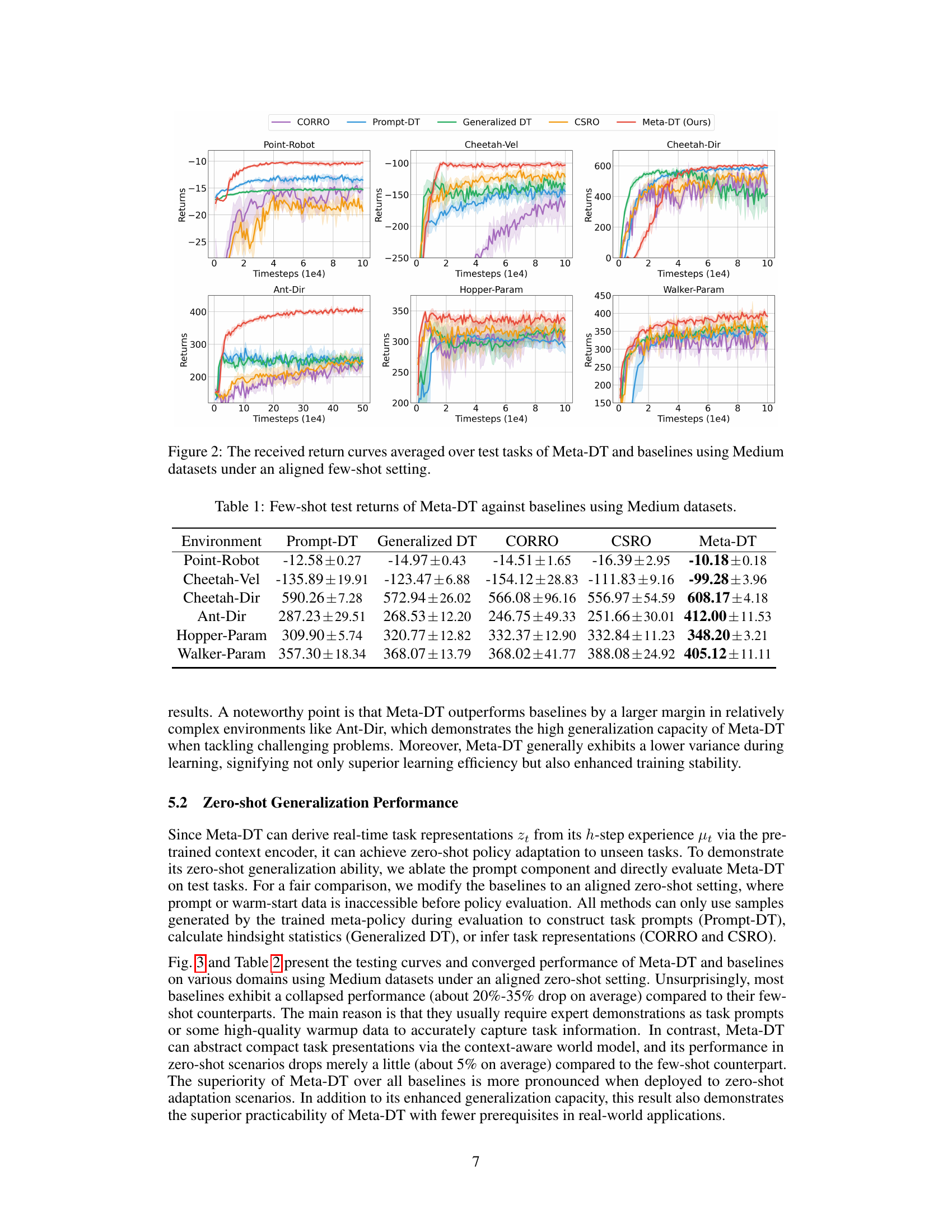
Figure 1: The overview of Meta-DT. We pretrain a context-aware world model to accurately disentangle task-specific information. It contains a context encoder Ery that abstracts recent h-step history με into a compact task representation zį, and the generalized decoders (R4, Tp) that predict the reward and next state conditioned on zį. Then, the inferred task representation is injected as a contextual condition to the causal transformer to guide task-oriented sequence generation. Finally, we design a self-guided prompt from history trajectories generated by the meta-policy at test time. We select the trajectory segment that yields the largest prediction error on the pretrained world model, aiming to encode task-relevant information complementary to the world model maximally.
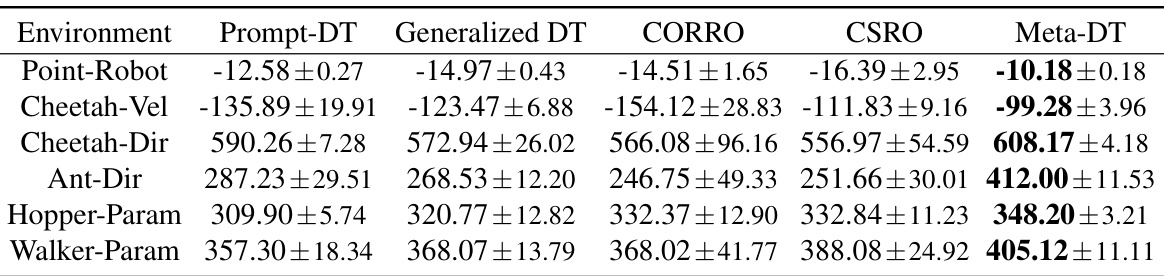
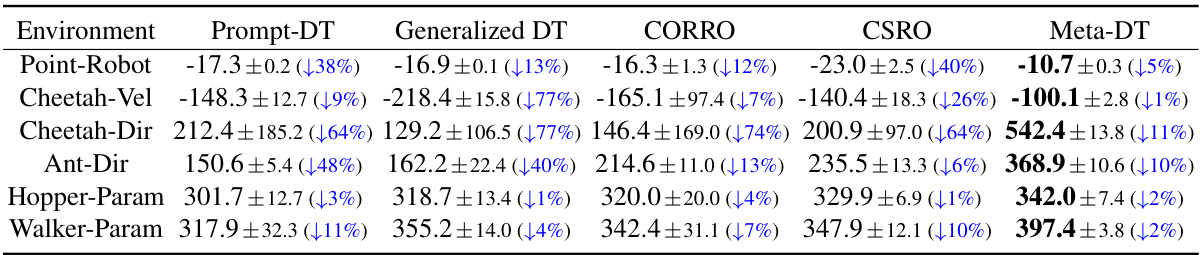
🔼 This table presents the few-shot test results comparing Meta-DT’s performance against several baseline methods on various MuJoCo and Meta-World benchmark environments. The results are averaged over multiple test tasks, using medium-quality datasets collected with a medium-performing policy. The table highlights the superior performance of Meta-DT in terms of the average return achieved. Lower values represent worse performance in these tasks.
read the caption
Table 1: Few-shot test returns of Meta-DT against baselines using Medium datasets.
In-depth insights#
Offline Meta-RL#
Offline meta-reinforcement learning (RL) tackles the challenge of generalizing RL agents to novel tasks using only pre-collected data, eliminating the need for online interaction with the environment. This paradigm is particularly appealing due to its efficiency and safety, as it avoids the risks and costs associated with online exploration, especially in real-world scenarios. The core challenge in offline meta-RL lies in effectively leveraging the historical data to learn a robust meta-policy that adapts quickly to new tasks. This requires careful consideration of several factors, including the diversity and representativeness of the offline dataset, the choice of appropriate meta-learning algorithms, and the method for transferring knowledge from previously seen tasks to unseen ones. Successful approaches often involve techniques such as contextual embedding of tasks, world model learning, and meta-policy optimization, to ensure the agent can accurately infer the task characteristics and adapt its behavior accordingly. Despite the progress, key challenges remain, notably in handling distribution shifts between training and test tasks and improving the sample efficiency of offline meta-RL. The field is actively exploring new methods like sequence modeling and self-supervised learning to address these challenges and enable more effective generalization in offline meta-RL.
World Model Use#
The research paper cleverly utilizes a world model to improve the generalization capabilities of offline meta-reinforcement learning. A key aspect is the disentanglement of task-specific information from behavior policies within the world model, enabling robust task representation learning regardless of the behavior policy used during data collection. This disentanglement is crucial for preventing bias in task inference and improving generalization to unseen tasks. The world model is pretrained on a multi-task offline dataset, learning to encode task-relevant information into a compact representation that is then injected as context into a decision transformer. This contextual information guides the transformer in generating task-oriented sequences, effectively leveraging the model’s sequential modeling capabilities. The paper also introduces a novel self-guided prompting technique using prediction error from the world model to enhance task-specific information encoding. This approach eliminates the need for expert demonstrations at test time, enhancing practical applicability. In essence, the world model acts as a bridge, transferring knowledge effectively across various tasks and datasets, leading to improved generalization in offline meta-RL.
Transformer Power#
The concept of “Transformer Power” in the context of a research paper likely refers to the capabilities and advantages offered by transformer-based models. These models, known for their ability to process sequential data effectively, have demonstrated remarkable success in various natural language processing and computer vision tasks. The “power” stems from their attention mechanisms, which enable them to weigh the importance of different elements within the input sequence, leading to superior performance compared to traditional recurrent neural networks. Furthermore, transformers benefit from parallelization, which significantly speeds up training and inference. A paper exploring “Transformer Power” would likely delve into these aspects, potentially benchmarking transformer models against other architectures on specific tasks and analyzing the factors that contribute to their effectiveness. The analysis might also touch on the scalability of transformers—their ability to leverage larger datasets and compute resources for enhanced performance— and their transfer learning capabilities, enabling knowledge gained from one domain to be applied to others. Finally, the paper could address potential limitations of using transformers and suggest directions for further research and development.
Prompt Engineering#
Prompt engineering, in the context of large language models (LLMs), is the process of carefully crafting input prompts to elicit desired outputs. Effective prompt engineering is crucial for maximizing the capabilities of LLMs, as poorly designed prompts can lead to inaccurate, nonsensical, or biased results. Techniques in prompt engineering involve various strategies including few-shot learning (providing examples), chain-of-thought prompting (guiding the model’s reasoning), and specifying desired output formats. The art of prompt engineering lies in understanding the model’s biases and limitations, and tailoring the prompt to mitigate these issues. Furthermore, prompt engineering is an active area of research, with ongoing efforts focused on developing more robust and generalizable prompting techniques. Ultimately, effective prompt engineering is vital for unlocking the full potential of LLMs and ensuring they are applied safely and responsibly.
Future Directions#
The paper’s core contribution is a novel offline meta-RL framework, Meta-DT. Future work could focus on scaling Meta-DT to handle significantly larger datasets, potentially leveraging self-supervised learning techniques to improve efficiency and generalization. Exploring diverse and more challenging environments beyond the benchmarks used would be beneficial to verify the robustness and broader applicability of the approach. Investigating a unified framework that simultaneously learns task representations and the meta-policy could enhance training efficiency. This could involve in-context learning strategies, enabling direct adaptation to new tasks with minimal fine-tuning. Finally, further analysis of Meta-DT’s robustness to noisy or incomplete data, a common issue in real-world offline RL scenarios, is crucial. Addressing these challenges would solidify Meta-DT as a powerful tool for broader offline meta-RL applications.
More visual insights#
More on figures
🔼 This figure provides a visual overview of the Meta-DT architecture. It shows the context-aware world model which learns a compact task representation from historical data. This representation is then used as a context for a causal transformer which generates task-specific sequences. A key element is the use of a self-guided prompt, based on the prediction error of the world model, to improve the performance of the causal transformer.
read the caption
Figure 1: The overview of Meta-DT. We pretrain a context-aware world model to accurately disentangle task-specific information. It contains a context encoder Eψ that abstracts recent h-step history μt into a compact task representation zi, and the generalized decoders (Rφ, Tφ) that predict the reward and next state conditioned on zi. Then, the inferred task representation is injected as a contextual condition to the causal transformer to guide task-oriented sequence generation. Finally, we design a self-guided prompt from history trajectories generated by the meta-policy at test time. We select the trajectory segment that yields the largest prediction error on the pretrained world model, aiming to encode task-relevant information complementary to the world model maximally.
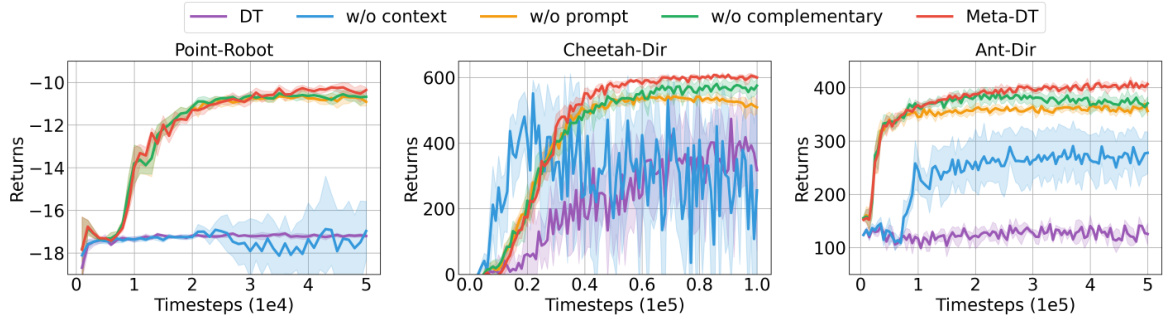
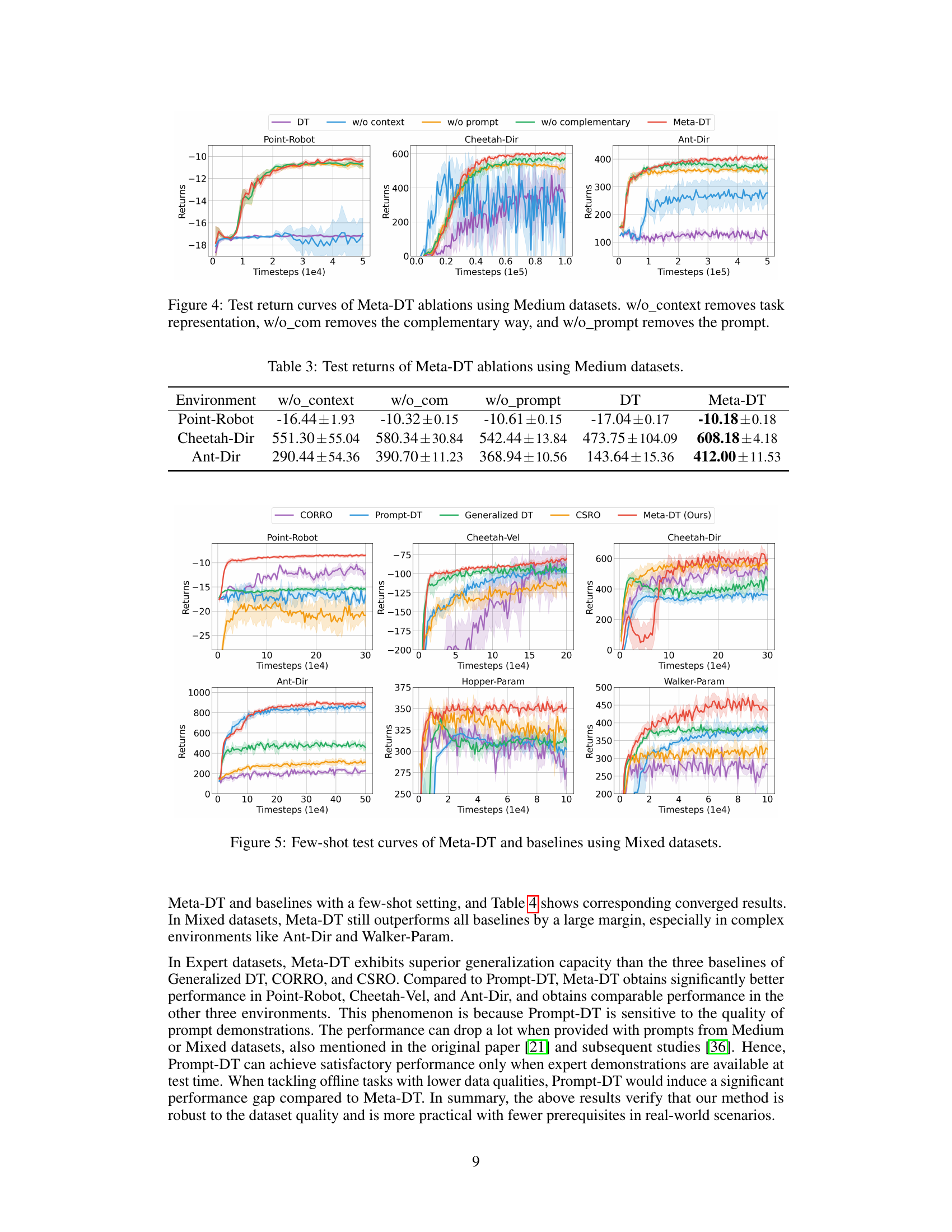
🔼 This figure shows the ablation study results of the Meta-DT model on three different environments using Medium datasets. The ablation studies systematically remove different components of the Meta-DT framework to determine their individual contributions to the overall performance. Specifically, it shows the impact of removing the task representation (w/o_context), the complementary prompt generation strategy (w/o_com), and the prompt itself (w/o_prompt). The results highlight the importance of each component and demonstrate that Meta-DT’s performance relies on the synergistic interaction of all its components.
read the caption
Figure 4: Test return curves of Meta-DT ablations using Medium datasets. w/o_context removes task representation, w/o_com removes the complementary way, and w/o_prompt removes the prompt.
🔼 This figure provides a comprehensive overview of the Meta-DT architecture. It illustrates the process of pretraining a context-aware world model to extract task-specific information from historical data, using this information to guide sequence generation via a causal transformer, and employing a self-guided prompt to enhance learning by focusing on areas where the world model’s predictions are least accurate.
read the caption
Figure 1: The overview of Meta-DT. We pretrain a context-aware world model to accurately disentangle task-specific information. It contains a context encoder Ery that abstracts recent h-step history μe into a compact task representation zi, and the generalized decoders (Rφ, Tφ) that predict the reward and next state conditioned on zi. Then, the inferred task representation is injected as a contextual condition to the causal transformer to guide task-oriented sequence generation. Finally, we design a self-guided prompt from history trajectories generated by the meta-policy at test time. We select the trajectory segment that yields the largest prediction error on the pretrained world model, aiming to encode task-relevant information complementary to the world model maximally.
🔼 This figure shows a schematic of the Meta-DT architecture. It illustrates how a context-aware world model is pre-trained to learn a compact task representation from historical data. This representation is then used to condition a causal transformer for sequence generation, guiding the model to produce task-appropriate actions. A crucial aspect is the use of a self-guided prompt generated from past trajectories to enhance task-specific information and complement the world model.
read the caption
Figure 1: The overview of Meta-DT. We pretrain a context-aware world model to accurately disentangle task-specific information. It contains a context encoder Eψ that abstracts recent h-step history μt into a compact task representation zi, and the generalized decoders (Rφ, Tφ) that predict the reward and next state conditioned on zi. Then, the inferred task representation is injected as a contextual condition to the causal transformer to guide task-oriented sequence generation. Finally, we design a self-guided prompt from history trajectories generated by the meta-policy at test time. We select the trajectory segment that yields the largest prediction error on the pretrained world model, aiming to encode task-relevant information complementary to the world model maximally.
🔼 This figure illustrates the overall architecture of the Meta-DT model. It shows how a context-aware world model is used to learn compact task representations from historical data. These representations are then fed into a causal transformer, which generates sequences of actions. A key component is the ‘complementary prompt’, a trajectory segment selected to maximize prediction error from the world model, aiming to add task-specific information not already captured by the model.
read the caption
Figure 1: The overview of Meta-DT. We pretrain a context-aware world model to accurately disentangle task-specific information. It contains a context encoder Eψ that abstracts recent h-step history μit into a compact task representation zit, and the generalized decoders (Rϕ, Tφ) that predict the reward and next state conditioned on zit. Then, the inferred task representation is injected as a contextual condition to the causal transformer to guide task-oriented sequence generation. Finally, we design a self-guided prompt from history trajectories generated by the meta-policy at test time. We select the trajectory segment that yields the largest prediction error on the pretrained world model, aiming to encode task-relevant information complementary to the world model maximally.
🔼 This figure illustrates the Meta-DT framework. A context-aware world model is pretrained to learn a compact task representation from historical data, which is then used as a contextual condition for a causal transformer to generate task-oriented sequences. A self-guided prompt, created from the trajectory segment with the largest prediction error from the world model, provides additional task-specific information.
read the caption
Figure 1: The overview of Meta-DT. We pretrain a context-aware world model to accurately disentangle task-specific information. It contains a context encoder Eψ that abstracts recent h-step history μt into a compact task representation zt, and the generalized decoders (Rφ, Tφ) that predict the reward and next state conditioned on zt. Then, the inferred task representation is injected as a contextual condition to the causal transformer to guide task-oriented sequence generation. Finally, we design a self-guided prompt from history trajectories generated by the meta-policy at test time. We select the trajectory segment that yields the largest prediction error on the pretrained world model, aiming to encode task-relevant information complementary to the world model maximally.
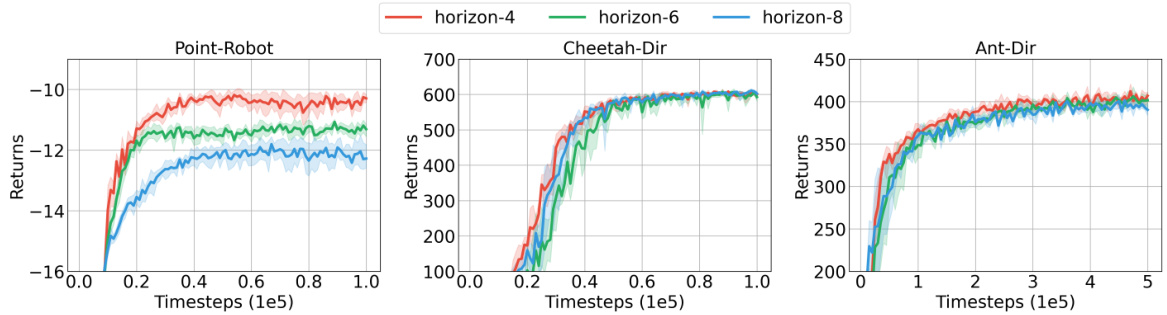
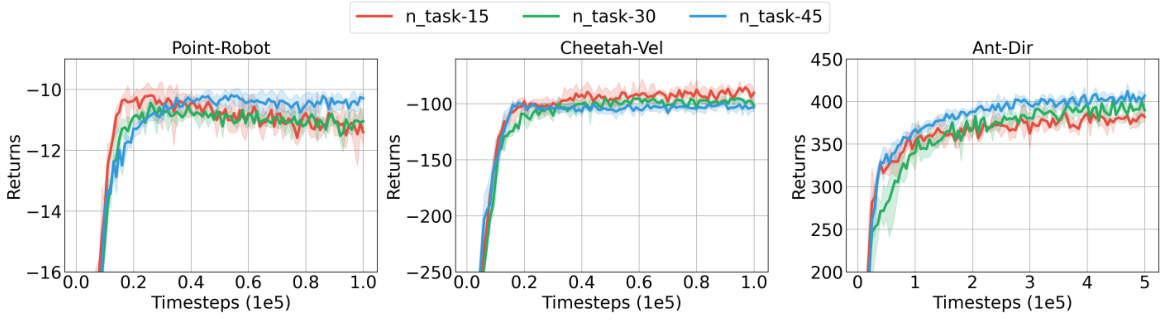
🔼 This figure shows the performance of Meta-DT with different context horizons (h=4, 6, 8) on three different environments: Point-Robot, Cheetah-Dir, and Ant-Dir. The x-axis represents the training timesteps (in 1e5 units), and the y-axis represents the cumulative returns. The shaded region around each line represents the standard deviation or error bars. The figure helps to analyze the influence of the hyperparameter ‘context horizon’ (h) on the performance and stability of Meta-DT.
read the caption
Figure 9: The received return curves averaged over test tasks of Meta-DT with different values of context horizon h using Medium datasets under an aligned few-shot setting.
🔼 This figure illustrates the overall architecture of Meta-DT, highlighting the three key components: a context-aware world model for disentangling task-relevant information, a causal transformer for task-oriented sequence generation, and a complementary prompt design using past trajectories to enhance generalization. The world model takes recent history as input, encodes it into a task representation, and predicts future rewards and states. This representation is then used as context for the transformer, which generates actions. The prompt is created using a trajectory segment with high prediction error from the world model to further optimize performance.
read the caption
Figure 1: The overview of Meta-DT. We pretrain a context-aware world model to accurately disentangle task-specific information. It contains a context encoder Ery that abstracts recent h-step history μt into a compact task representation zt, and the generalized decoders (Rφ, Tφ) that predict the reward and next state conditioned on zt. Then, the inferred task representation is injected as a contextual condition to the causal transformer to guide task-oriented sequence generation. Finally, we design a self-guided prompt from history trajectories generated by the meta-policy at test time. We select the trajectory segment that yields the largest prediction error on the pretrained world model, aiming to encode task-relevant information complementary to the world model maximally.
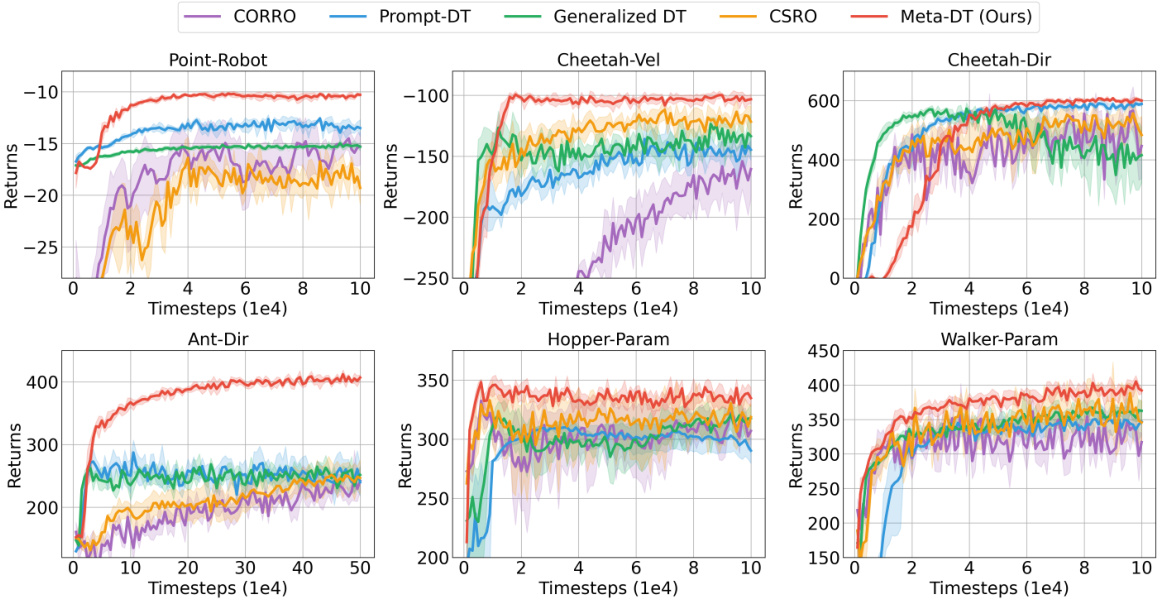
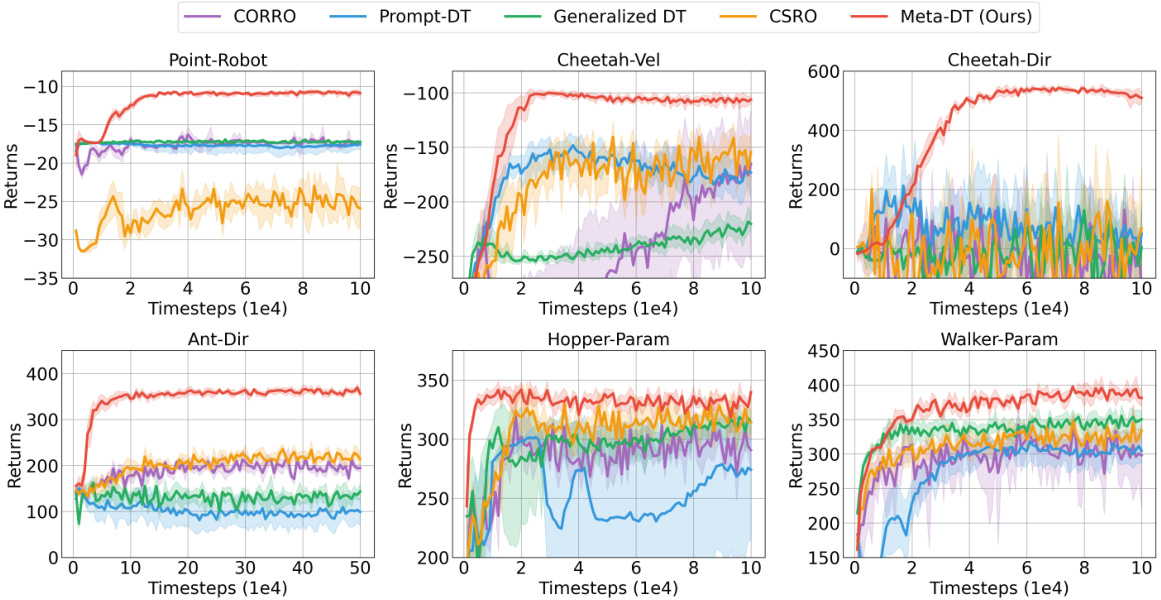
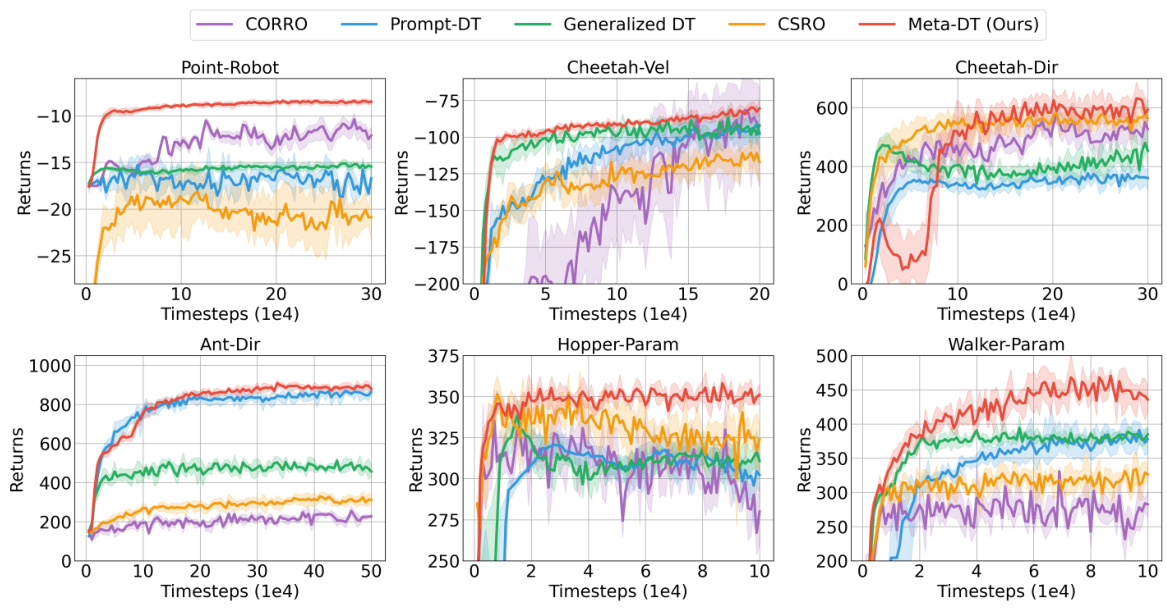
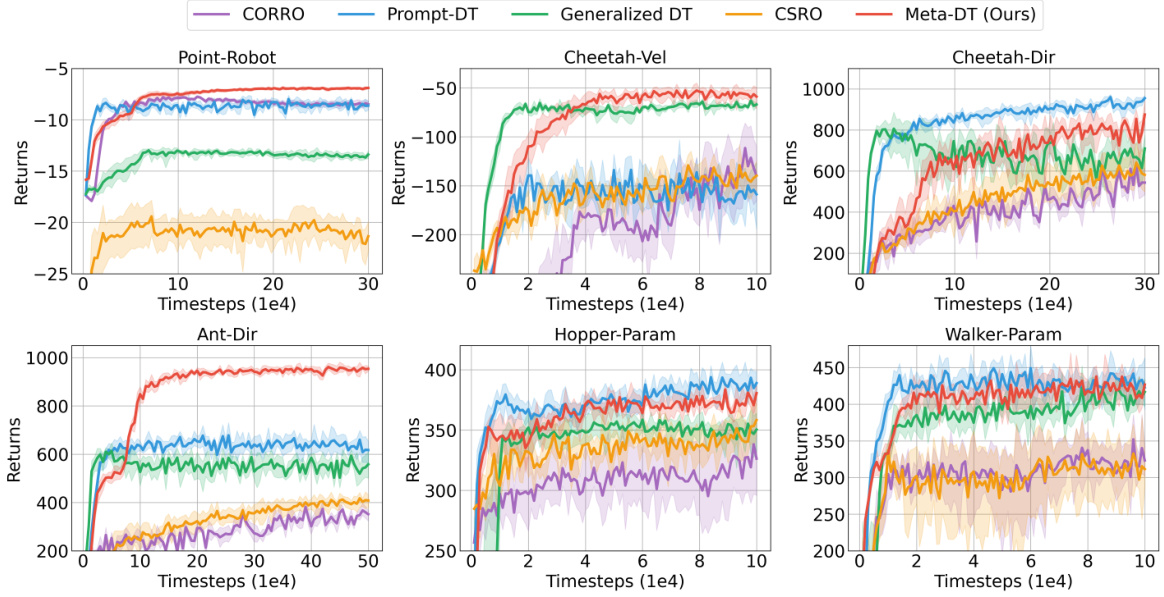
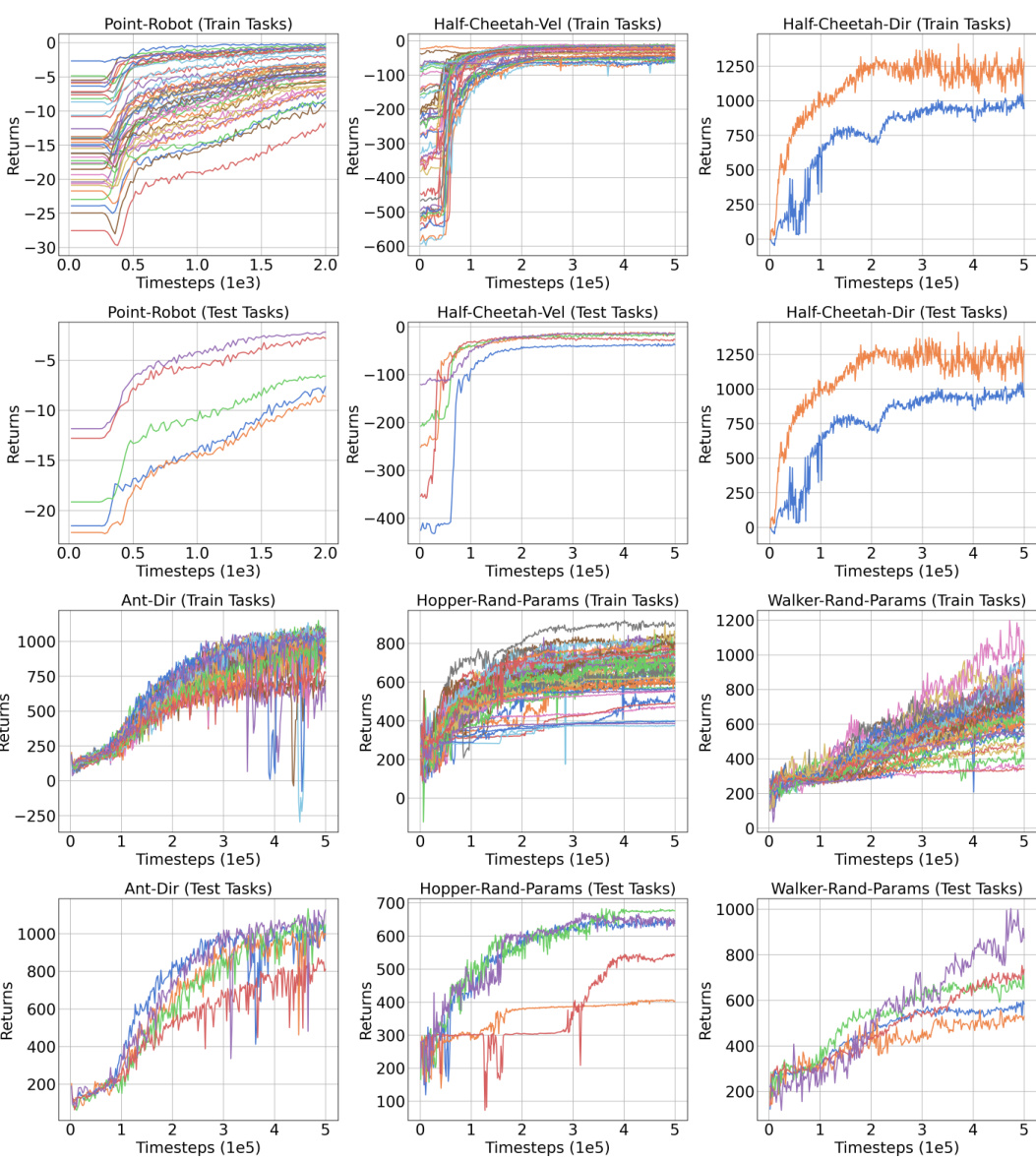
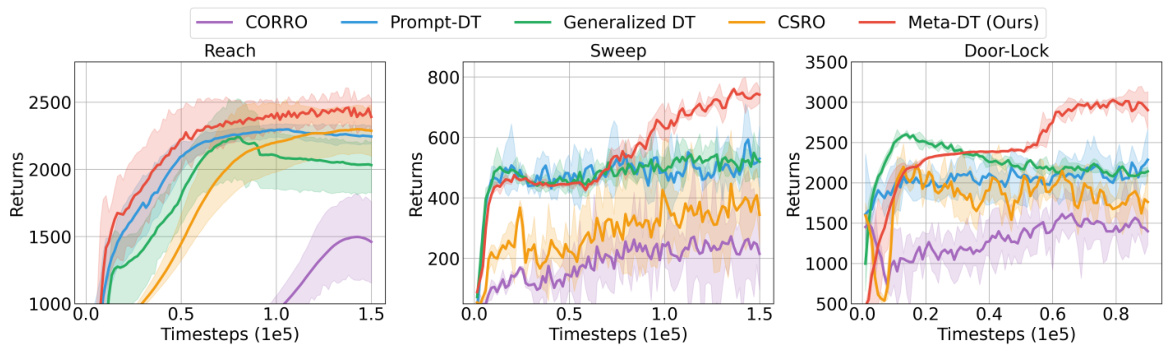
🔼 The figure shows the learning curves for several algorithms on various benchmark tasks in a few-shot setting using medium-quality datasets. The x-axis represents the number of timesteps, and the y-axis represents the average return. The plot shows Meta-DT achieving better performance and lower variance compared to several baselines, including CORRO, CSRO, Prompt-DT, and Generalized DT, demonstrating its superior generalization ability and stability in few-shot scenarios.
read the caption
Figure 2: The received return curves averaged over test tasks of Meta-DT and baselines using Medium datasets under an aligned few-shot setting.
🔼 This figure shows a schematic overview of the Meta-DT architecture. It highlights the three key components: a context-aware world model for disentangling task-specific information, a meta decision transformer for sequence modeling, and a complementary prompt generated from past trajectories. The world model learns compact task representations which are then used to condition the transformer’s sequence generation, making it task-aware. The prompt mechanism uses the world model to guide the selection of informative trajectory segments for further improving performance.
read the caption
Figure 1: The overview of Meta-DT. We pretrain a context-aware world model to accurately disentangle task-specific information. It contains a context encoder Ery that abstracts recent h-step history με into a compact task representation zį, and the generalized decoders (R4, Tp) that predict the reward and next state conditioned on zį. Then, the inferred task representation is injected as a contextual condition to the causal transformer to guide task-oriented sequence generation. Finally, we design a self-guided prompt from history trajectories generated by the meta-policy at test time. We select the trajectory segment that yields the largest prediction error on the pretrained world model, aiming to encode task-relevant information complementary to the world model maximally.

🔼 This figure compares the performance of Meta-DT against four other baselines (Prompt-DT, Generalized DT, CORRO, and CSRO) on six different tasks from the MuJoCo and Point-Robot environments. The x-axis represents the number of timesteps (in 1e4 increments), and the y-axis shows the average return achieved. The shaded area around each line represents the standard deviation across multiple trials. The figure demonstrates Meta-DT’s superior performance and stability compared to the baselines across multiple tasks in a few-shot learning scenario.
read the caption
Figure 2: The received return curves averaged over test tasks of Meta-DT and baselines using Medium datasets under an aligned few-shot setting.
More on tables
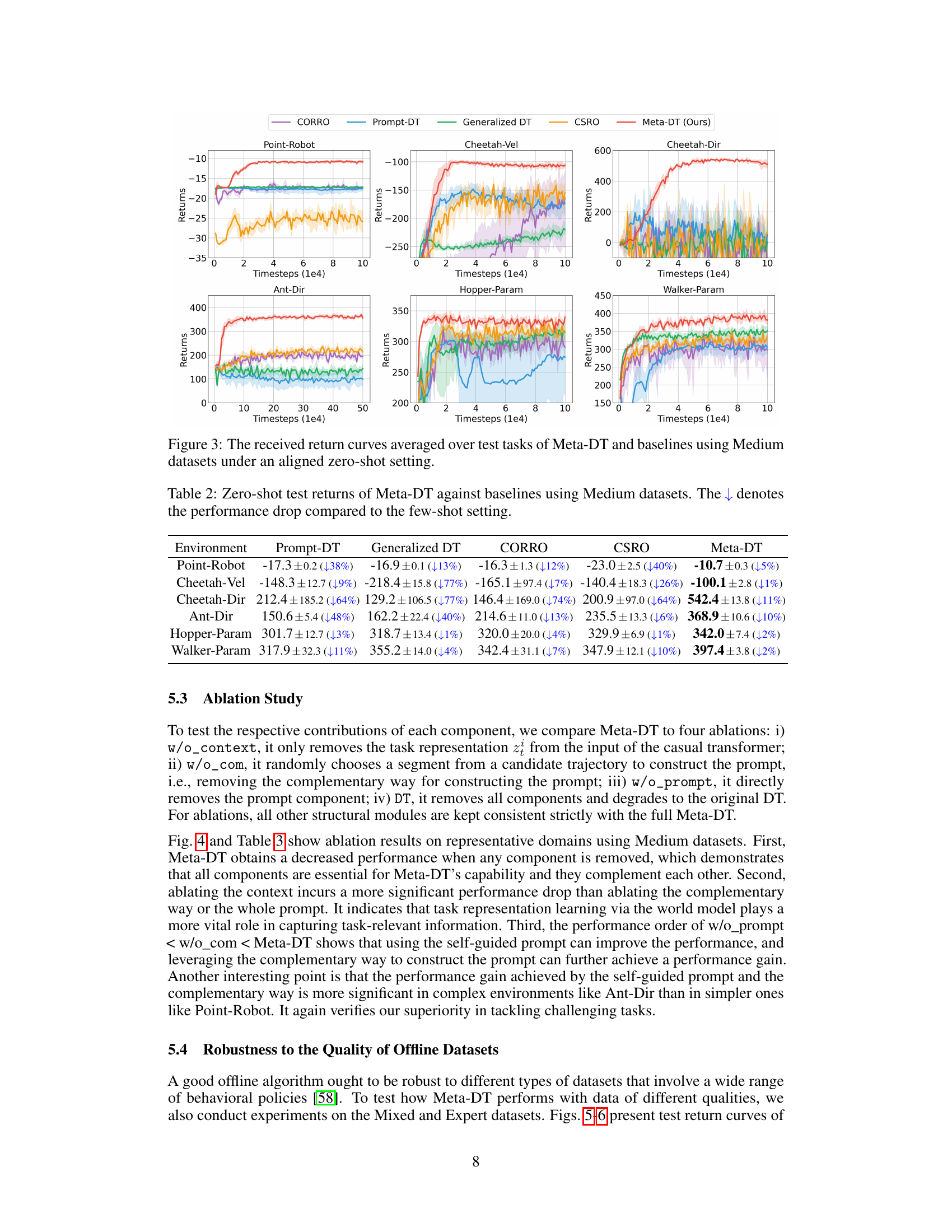
🔼 This table presents the results of a zero-shot generalization experiment on various benchmark tasks using Medium datasets. It compares the performance of Meta-DT against four other offline meta-RL algorithms (Prompt-DT, Generalized DT, CORRO, and CSRO). The table shows the average return for each algorithm on each task, and also indicates the percentage decrease in performance compared to the results obtained in the few-shot setting (shown in Table 1). The zero-shot setting means that no expert demonstrations or domain knowledge are available during test time. The results illustrate the zero-shot generalization capacity of Meta-DT, showcasing its ability to adapt to new tasks with minimal information.
read the caption
Table 2: Zero-shot test returns of Meta-DT against baselines using Medium datasets. The ↓ denotes the performance drop compared to the few-shot setting.

🔼 This table presents the results of an ablation study conducted on the Meta-DT model. It shows the impact of removing different components of the model (context, complementary prompt generation method, and the prompt itself) on performance across three different environments: Point-Robot, Cheetah-Dir, and Ant-Dir. The results are reported as mean ± standard deviation of the reward obtained in each environment, with the Medium dataset used for evaluation.
read the caption
Table 3: Test returns of Meta-DT ablations using Medium datasets. w/o_context removes task representation, w/o_com removes the complementary way, and w/o_prompt removes the prompt.
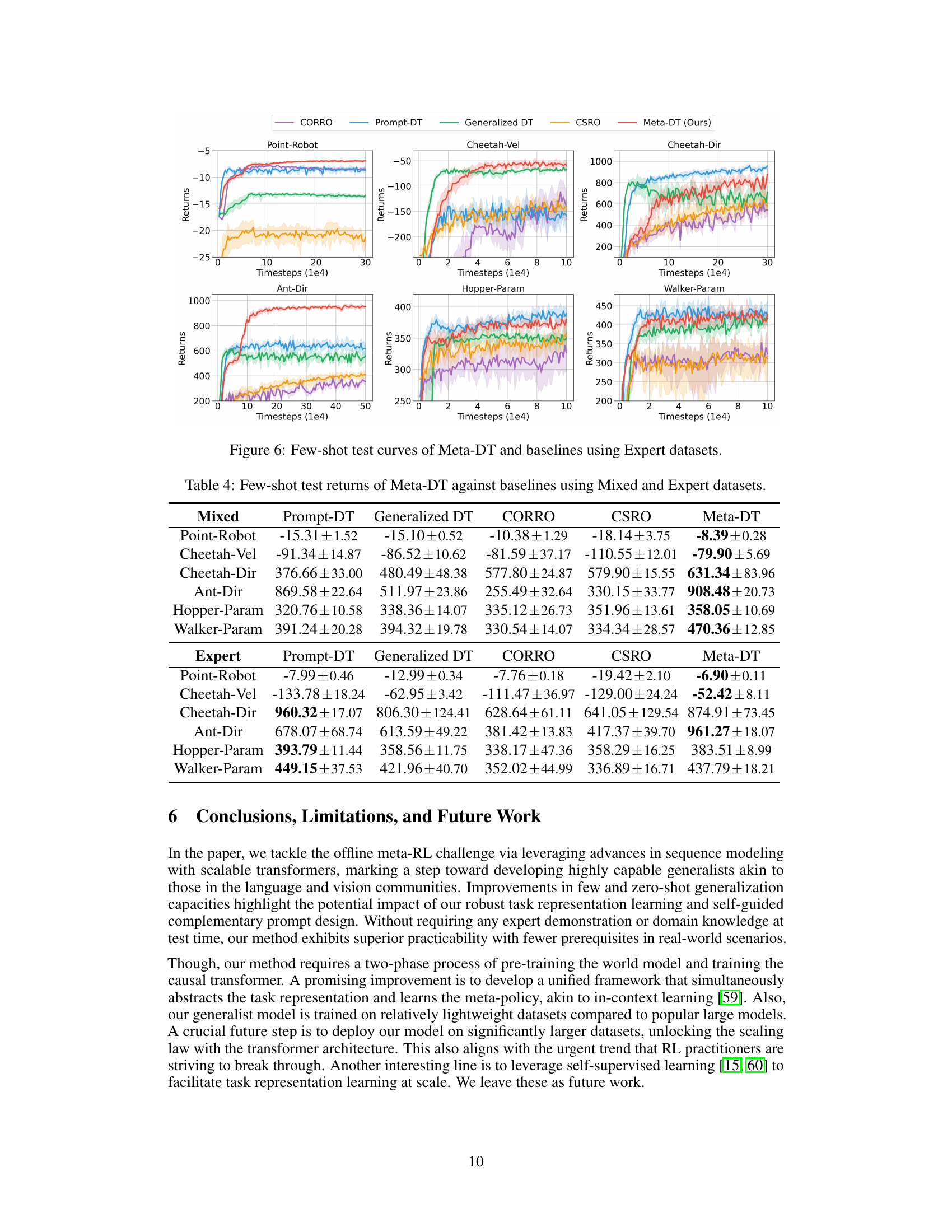
🔼 This table presents the few-shot test results of Meta-DT and four baseline algorithms across six different environments, using medium-quality datasets. For each environment, the mean test return and standard deviation are reported for each algorithm. This allows for a quantitative comparison of Meta-DT’s performance relative to the state-of-the-art in offline meta-reinforcement learning in a few-shot setting. The use of medium-quality datasets emphasizes the practical applicability of the proposed method.
read the caption
Table 1: Few-shot test returns of Meta-DT against baselines using Medium datasets.
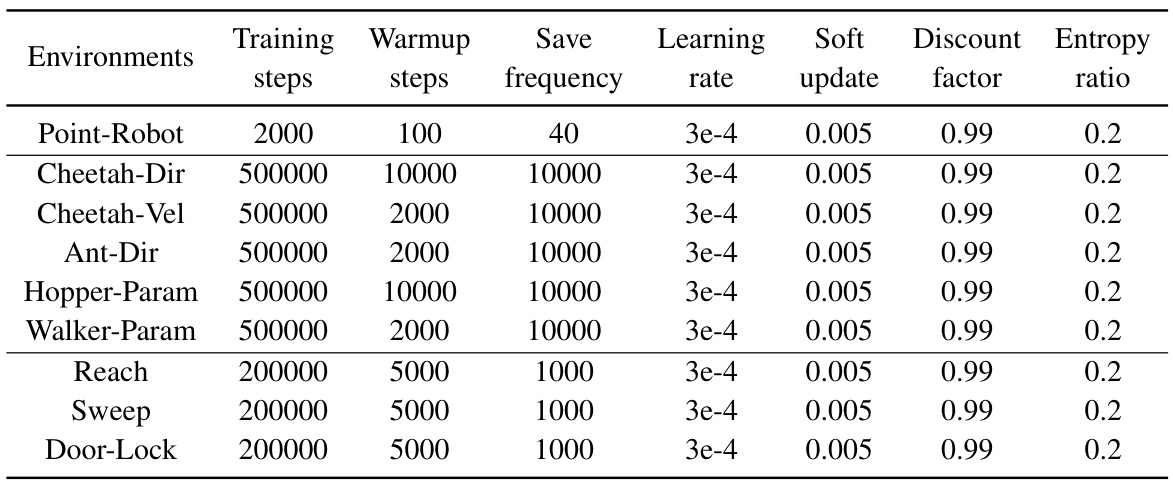
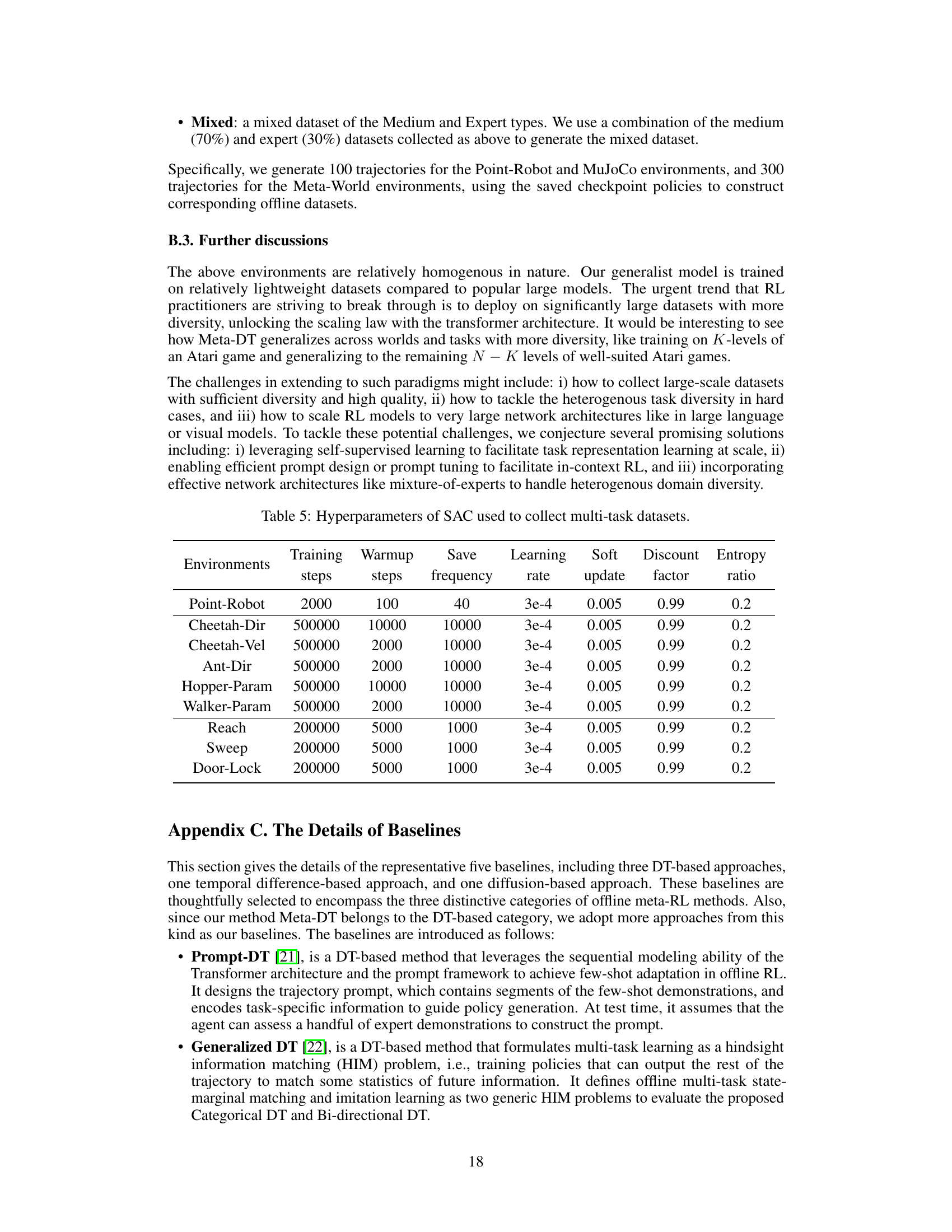
🔼 This table lists the hyperparameters used for training the Soft Actor-Critic (SAC) agents to collect the offline datasets for each environment. The hyperparameters include training steps, warmup steps, save frequency, learning rate, soft update rate, discount factor, and entropy ratio. The table shows the specific hyperparameters for each of the environments used in the paper.
read the caption
Table 5: Hyperparameters of SAC used to collect multi-task datasets.
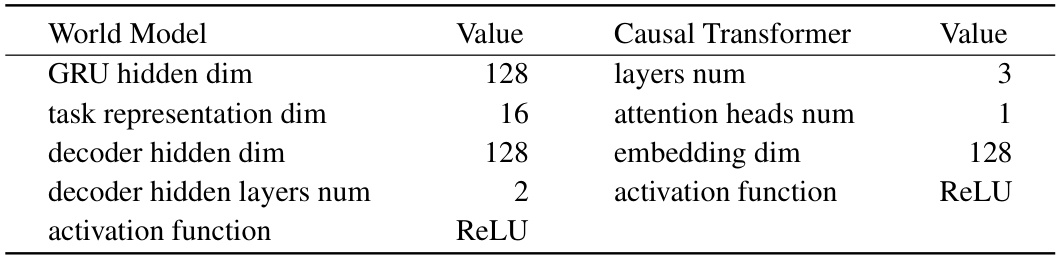
🔼 This table details the hyperparameters used in the Meta-DT model architecture. It shows the dimensions of various components, such as GRU hidden layers, task representation, decoder hidden layers, and embedding dimensions, along with the activation function used (ReLU). The table is divided into two sections: World Model and Causal Transformer, reflecting the two main components of the model.
read the caption
Table 6: The network configurations used for Meta-DT.

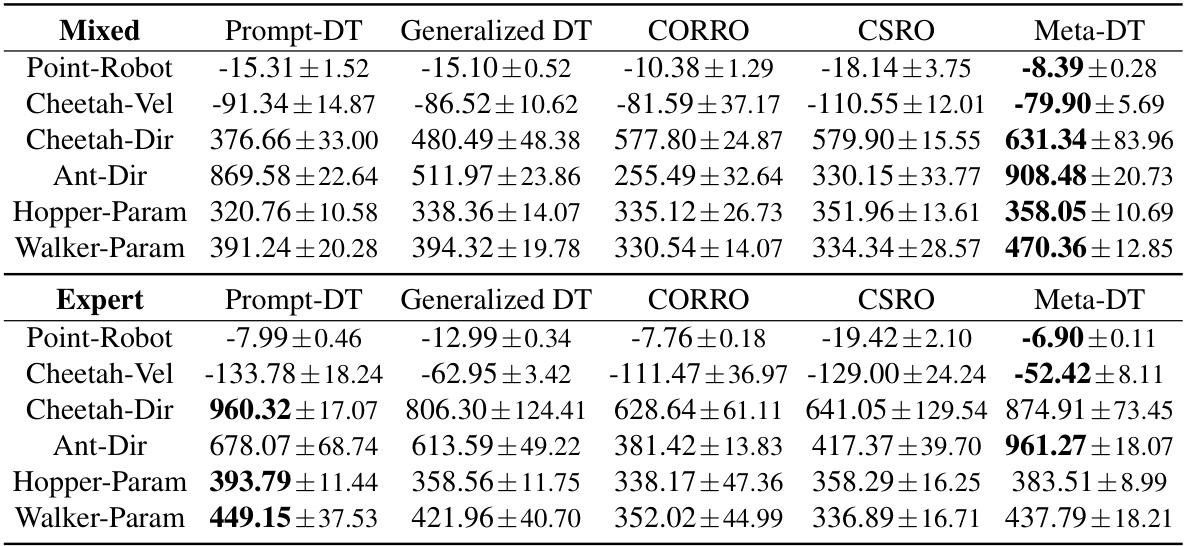
🔼 This table shows the hyperparameters used for training the Meta-DT model on the Point-Robot and MuJoCo environments. The hyperparameters are separated for three types of datasets (Medium, Expert, and Mixed). Each dataset type has different training steps, sequence length, context horizon, learning rate, and prompt length, indicating variations in the training configurations tailored to different data characteristics.
read the caption
Table 7: Hyperparameters of Meta-DT on Point-Robot and MuJoCo domains with various datasets.

🔼 This table lists the hyperparameters used for training the Meta-DT model on the Meta-World benchmark using Medium datasets. It shows the specific settings for each of the three environments: Reach, Sweep, and Door-Lock. The hyperparameters include training steps, sequence length, context horizon, learning rate, and prompt length.
read the caption
Table 8: Hyperparameters of Meta-DT trained on Meta-World domains with Medium datasets.

🔼 This table presents the few-shot test returns of the Meta-DT model with different context horizon values (h=4, 6, 8) using medium datasets. The results are averaged over multiple test tasks for each environment (Point-Robot, Cheetah-Dir, and Ant-Dir). The table shows how the performance of the model varies with the context horizon. A larger context horizon might capture more context information for better generalization, but it could also lead to overfitting. The goal is to find a context horizon value that gives the best performance in different environments.
read the caption
Table 9: Few-shot test returns averaged over test tasks of Meta-DT with different values of context horizon h using Medium datasets.

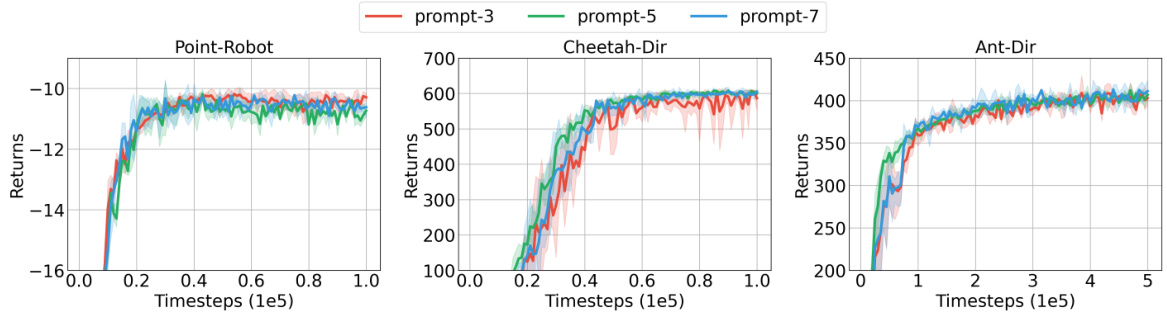
🔼 This table presents the few-shot test returns achieved by the Meta-DT model across three different environments (Point-Robot, Cheetah-Dir, Ant-Dir) using Medium datasets. The results are presented for three different prompt lengths (k=3, 5, 7). The table shows how the model’s performance varies with changes in prompt length and across different environments, demonstrating the impact of this hyperparameter on generalization capacity.
read the caption
Table 10: Few-shot test returns of Meta-DT with different prompt length k using Medium datasets.

🔼 This table presents the few-shot test results comparing Meta-DT’s performance against other baselines across various tasks. The results are averaged over multiple test tasks using medium difficulty datasets and indicate the mean return achieved along with the standard deviation. The tasks encompass diverse control challenges including locomotion and manipulation.
read the caption
Table 1: Few-shot test returns of Meta-DT against baselines using Medium datasets.

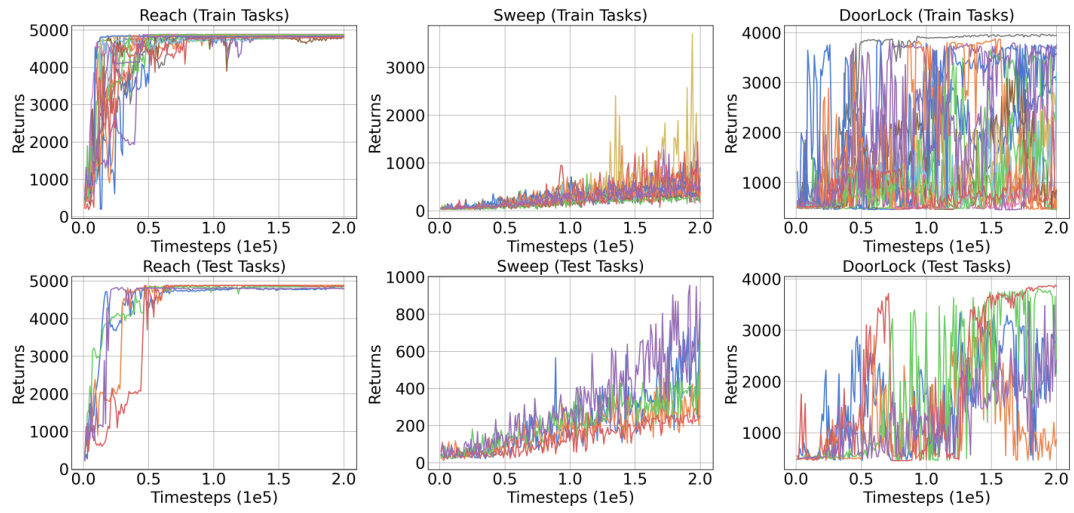
🔼 This table presents the few-shot test results of Meta-DT and four baseline algorithms (Prompt-DT, Generalized DT, CORRO, and CSRO) on three Meta-World benchmark tasks (Reach, Sweep, and Door-Lock). The results are presented as the mean ± standard deviation of the episodic return obtained using Medium datasets. The table highlights the superior performance of Meta-DT compared to the baselines across all three tasks.
read the caption
Table 12: Few-shot test returns of Meta-DT and baselines on Meta-World using Medium datasets.

🔼 This table presents the few-shot test returns achieved by different offline meta-RL methods on out-of-distribution (OOD) tasks from the Ant-Dir environment within the Meta-World benchmark. The results showcase the generalization performance of each method when the test tasks are outside the distribution of the training tasks, highlighting the ability to extrapolate knowledge to unseen scenarios.
read the caption
Table 13: Few-shot returns of OOD test tasks using Medium datasets from Ant-Dir.
Full paper#