↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are vulnerable to jailbreaking attacks, where malicious prompts elicit harmful responses. Existing defense methods often prove insufficient or come with significant drawbacks like high computational costs or reduced response quality. This creates a critical need for robust and efficient defense mechanisms that can protect LLMs without compromising their functionality.
This paper introduces IBProtector, a defense mechanism grounded in the information bottleneck principle. IBProtector selectively compresses and perturbs prompts to protect LLMs from malicious attacks. It uses a lightweight trainable extractor that preserves essential information for the target LLM to respond as expected. Empirical evaluations demonstrate that IBProtector outperforms existing defenses, mitigating jailbreaks effectively without significantly affecting response quality or inference speed. Its adaptability across various attacks and LLMs highlights its potential as a robust and transferable solution to a critical problem in the field of LLM security.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it introduces a novel defense mechanism against jailbreaking attacks. It offers a transferable and lightweight solution that doesn’t require modifying the underlying models, addressing a critical security concern in the field. Furthermore, it opens avenues for future research on information bottleneck principles in LLM security. This work is highly relevant given the increasing prevalence of sophisticated attacks aiming to circumvent LLM safety measures.
Visual Insights#

This figure illustrates the difference between a normal jailbreaking attack and the proposed defense mechanism, IBProtector. The left panel shows a standard jailbreaking attack where an adversarial prompt (prefix and suffix) manipulates the LLM into generating harmful content. The right panel shows how IBProtector mitigates this by compressing and selectively perturbing the prompt, retaining only essential information needed for a safe response. The colored sections highlight the adversarial components of the prompts.

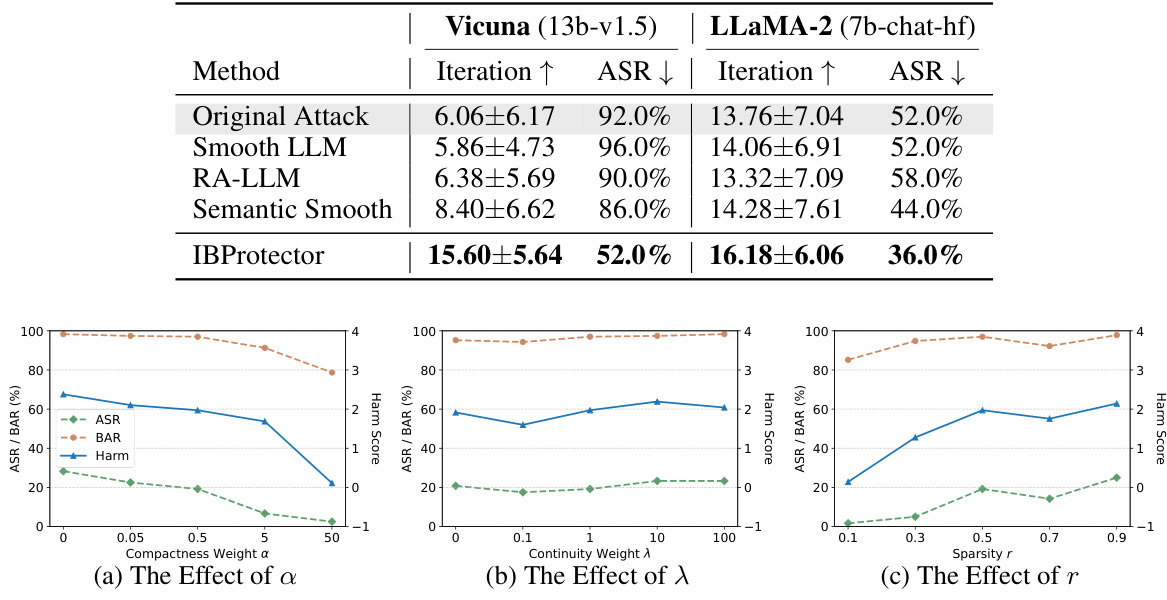
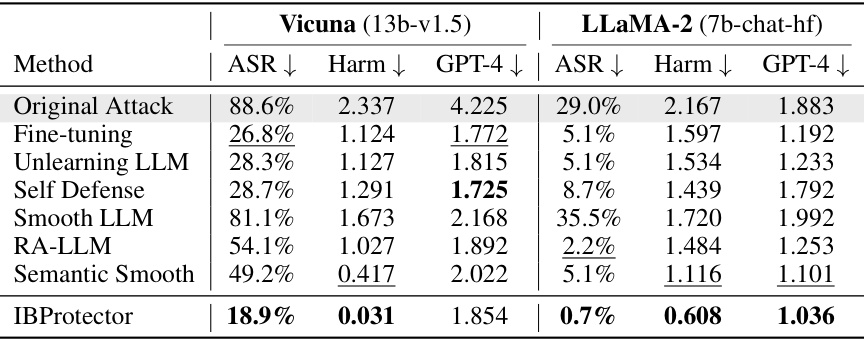
This table presents a comparison of the performance of several defense methods, including IBProtector, against two types of adversarial attacks (prompt-level and token-level) on the AdvBench dataset. The metrics used for comparison include Attack Success Rate (ASR), Harm Score (lower is better, indicating less harmful outputs), GPT-4 Score (lower is better), and Benign Answering Rate (BAR, higher is better, showing the ability to correctly answer benign questions). The table shows that IBProtector outperforms the other methods in mitigating both types of attacks while maintaining a high BAR.
In-depth insights#
IBProtector: A Novel Defense#
IBProtector presents a novel defense against adversarial attacks targeting large language models (LLMs). Its core innovation lies in leveraging the information bottleneck principle, selectively compressing and perturbing prompts to retain only crucial information for the LLM to generate safe responses. This approach cleverly avoids trivial solutions by incorporating a trainable extractor that learns to identify and preserve essential information, successfully mitigating various attack strategies, including both token-level and prompt-level attacks. IBProtector’s lightweight nature avoids the overhead of LLM fine-tuning and offers adaptability across diverse models, significantly improving robustness without compromising response quality or inference speed. The method’s transferability across different LLMs and attack methods highlights its potential for broad applicability and strengthens the security of LLMs without model modifications. However, the reliance on a trainable extractor and the assumption of access to the target LLM’s tokenizer during training are potential limitations.
Tractable IB Objective#
The heading ‘Tractable IB Objective’ suggests a focus on making the Information Bottleneck (IB) principle practically applicable. IB, while theoretically elegant, often involves intractable mutual information calculations. The core idea here is likely to reformulate the IB objective function into a form that is computationally manageable. This might involve using approximations for mutual information (e.g., using variational inference or other bounds), or redefining the objective to avoid direct mutual information estimation. The tractability of the new objective is crucial for training a practical IB-based system, especially one handling high-dimensional data like natural language prompts. Success would likely depend on demonstrating that the approximation retains sufficient accuracy while significantly reducing computational cost. The use of a trainable, lightweight extractor implies a focus on efficient implementation, complementing the tractable objective function to create a scalable and robust solution.
Empirical Evaluation#
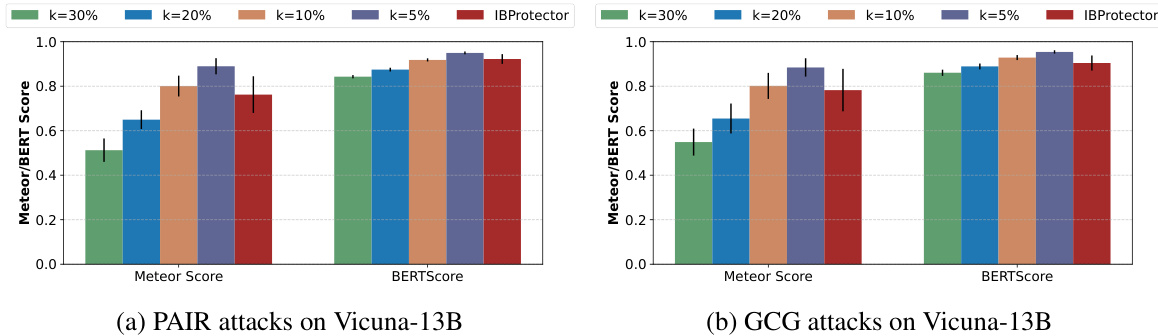
A robust empirical evaluation section is crucial for validating the claims of a research paper. It should thoroughly investigate the proposed method’s performance, comparing it against relevant baselines using appropriate metrics. The choice of metrics is critical, ensuring they directly measure the key aspects being evaluated. A comprehensive evaluation considers various aspects: performance under different conditions (varying input sizes, noise levels, etc.), robustness to different attacks or adversarial examples, and a thorough analysis of statistical significance. The evaluation should also address potential biases or limitations in the experimental setup, acknowledging any factors affecting the results. Clear visualization of results (e.g., graphs, tables) is essential for easy understanding and interpretation. Overall, a strong empirical evaluation strengthens the paper’s credibility by providing compelling evidence supporting its claims and offering insightful interpretations. Ideally, the evaluation should also discuss the computational efficiency and scalability of the proposed method, indicating its practical applicability.
Transferability and Limits#
The concept of “Transferability and Limits” in the context of a machine learning model, particularly one designed for protecting large language models (LLMs) from adversarial attacks, is crucial. Transferability refers to the model’s ability to generalize its defensive capabilities to different attack methods or target LLMs not encountered during training. A highly transferable model is robust and versatile, adaptable to unseen scenarios. However, limits inevitably exist. These limits could stem from the inherent nature of the adversarial attacks, such as their complexity or ability to adapt and circumvent defenses. Furthermore, the specific architecture and training data of the protective model will constrain its generalizability. Factors like the types of prompts used in training, the specific LLMs targeted, and even the computational resources available affect the limits of transferability. A thorough analysis of “Transferability and Limits” would involve benchmarking the defense mechanism against a diverse range of attacks and target LLMs, quantifying its performance under varied conditions, and carefully identifying the scenarios where it falls short. This allows researchers to pinpoint the model’s weaknesses and further refine its design, aiming for enhanced robustness and broader applicability.
Future Research#
Future research directions stemming from this paper could explore several key areas. Extending IBProtector’s effectiveness against more sophisticated and adaptive attacks is crucial, especially those employing techniques like chain-of-thought prompting or iterative refinement. Further investigation into the generalizability across diverse LLM architectures beyond the models tested is warranted. Quantifying the trade-off between security and utility more precisely remains a key challenge, as does determining optimal parameter settings for varied use cases. The impact of different perturbation methods requires a deeper analysis. Exploring the integration of IBProtector with other defense mechanisms, such as those based on reinforcement learning or fine-tuning, holds significant potential for creating a more robust and layered defense. Finally, adapting IBProtector to handle different data modalities including images and audio, would significantly broaden its applicability and impact.
More visual insights#
More on figures
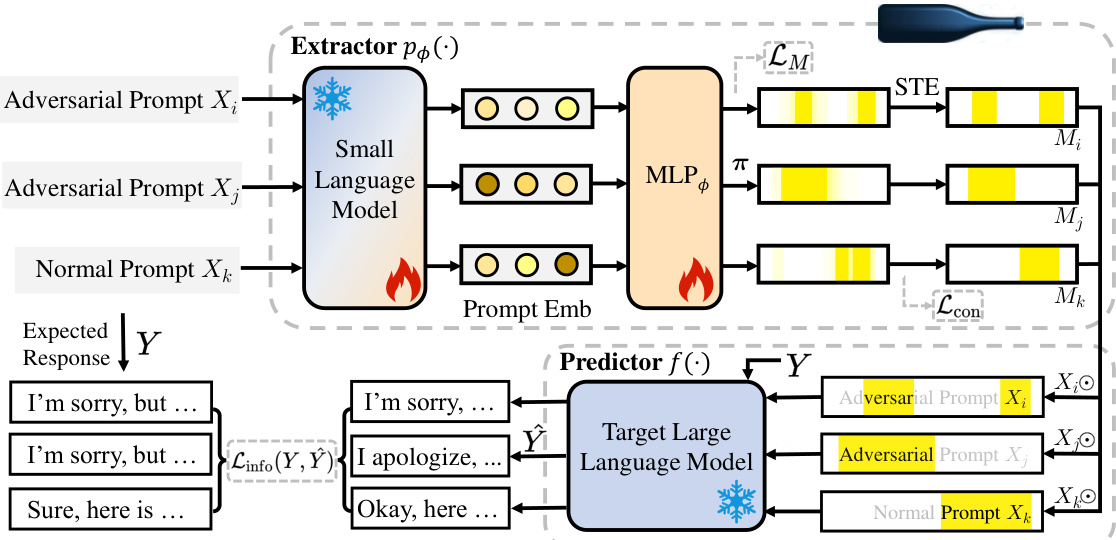
The figure shows the architecture of the IBProtector, a defense mechanism against adversarial attacks on LLMs. It consists of two main components: a trainable extractor and a frozen predictor. The extractor, which uses a small language model (optional) processes the input prompt and extracts the most informative parts. This is done by creating a mask that highlights the important tokens for the prediction. This mask is generated by optimizing the compactness and informativeness of the extraction. The extracted, masked prompt is then fed into the frozen predictor, a target large language model. The predictor generates the response to the input prompt based on this extracted information. The training process involves minimizing a loss function that considers both the compactness (minimal information loss) and the prediction quality (accurate responses). The figure illustrates the flow of data through the different components and shows how the trained extractor learns to selectively preserve essential information and reduce noise in the input.

This figure compares the normal jailbreaking process with the proposed IBProtector defense mechanism. The left side shows a standard jailbreak attack, highlighting how adversarial prefixes and suffixes are used to manipulate an LLM into generating harmful content. The right side illustrates how IBProtector works by selectively compressing and perturbing the input prompt, removing extraneous information that could trigger a harmful response while preserving essential details needed for a safe and appropriate answer.
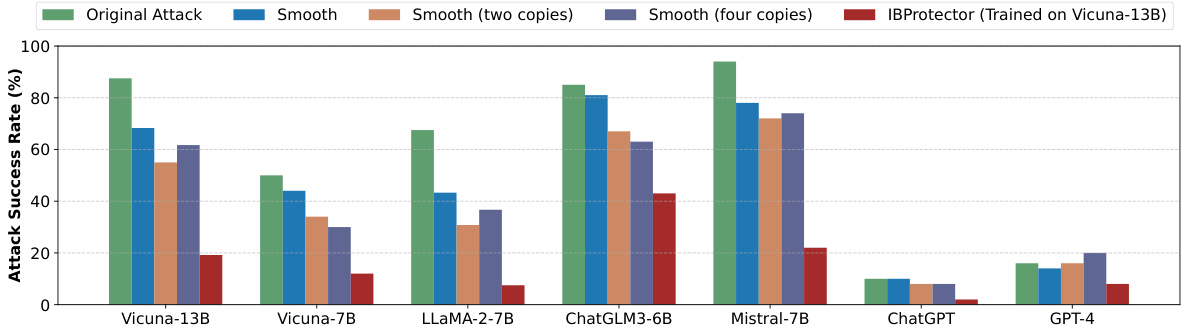
This figure shows the transferability of IBProtector and Smooth LLMs across different LLMs. The attack success rate (ASR) is shown for each model, comparing the original attack with IBProtector and Smooth LLMs (with 1, 2, and 4 copies). IBProtector demonstrates significantly lower ASRs across all tested models, highlighting its generalizability. The Smooth LLM results show that increasing the number of copies (ensemble) improves its performance, but still significantly underperforms IBProtector.
This figure shows the architecture of the IBProtector model, which consists of a trainable extractor and a frozen predictor. The extractor takes an input prompt and selectively compresses it, preserving only the essential information needed for the predictor to generate the appropriate response. The small language model is optional and serves as a component of the extractor. The figure uses visual metaphors (fire and snowflake) to denote the frozen (pre-trained) and trained model components respectively. The overall design aims to improve the robustness of LLMs against adversarial prompts by focusing on informative content and reducing the impact of irrelevant information.

This figure shows a comparison between the normal jailbreaking process and the proposed IBProtector method. The left side illustrates a normal jailbreak attack where an adversarial prompt (with malicious prefix and suffix highlighted in red) causes the language model to generate harmful content. The right side shows how IBProtector mitigates this by extracting only essential information from the prompt, compressing it, and then feeding the compressed information to the language model, preventing the generation of harmful content.

The figure shows the architecture of the IBProtector model. It consists of two main components: a trainable extractor and a frozen predictor. The extractor takes an input prompt and outputs a compressed sub-prompt, highlighting only the most informative parts. The predictor then uses this sub-prompt to generate a response, without needing to modify the underlying LLM. A small language model is optionally included to help the extractor, but it’s not a requirement for the process to work. The figure uses fire and snowflake icons to represent the frozen (pre-trained) and trainable parts of the model.
The figure shows the architecture of the IBProtector model, which consists of a trainable extractor and a frozen predictor. The extractor takes an input prompt and extracts the most informative parts, which are then passed to the predictor to generate a response. The small language model is optional and can be used to further enhance the performance of the extractor. The figure also highlights the different components of the model and their interactions.
The figure shows the architecture of the IBProtector model, which consists of a trainable extractor and a frozen predictor. The extractor takes an input prompt and extracts the most informative parts. These informative parts are then passed to the predictor, which generates the response. A small language model is used optionally to improve the performance of the extractor. The figure highlights that the parameters of the extractor are trained, while the parameters of the predictor are frozen.

The figure shows the architecture of the IBProtector, a defense mechanism against adversarial attacks on LLMs. It consists of two main components: a trainable extractor and a frozen predictor. The extractor processes the input prompt and selectively extracts the most informative parts, compressing the prompt while preserving essential information for the LLM to generate the expected response. The predictor then uses this compressed information to generate the response. A small language model is optionally included in the extractor to aid in the process. The figure uses visual metaphors (fire and snowflake) to represent the frozen and trained parameters respectively.
More on tables
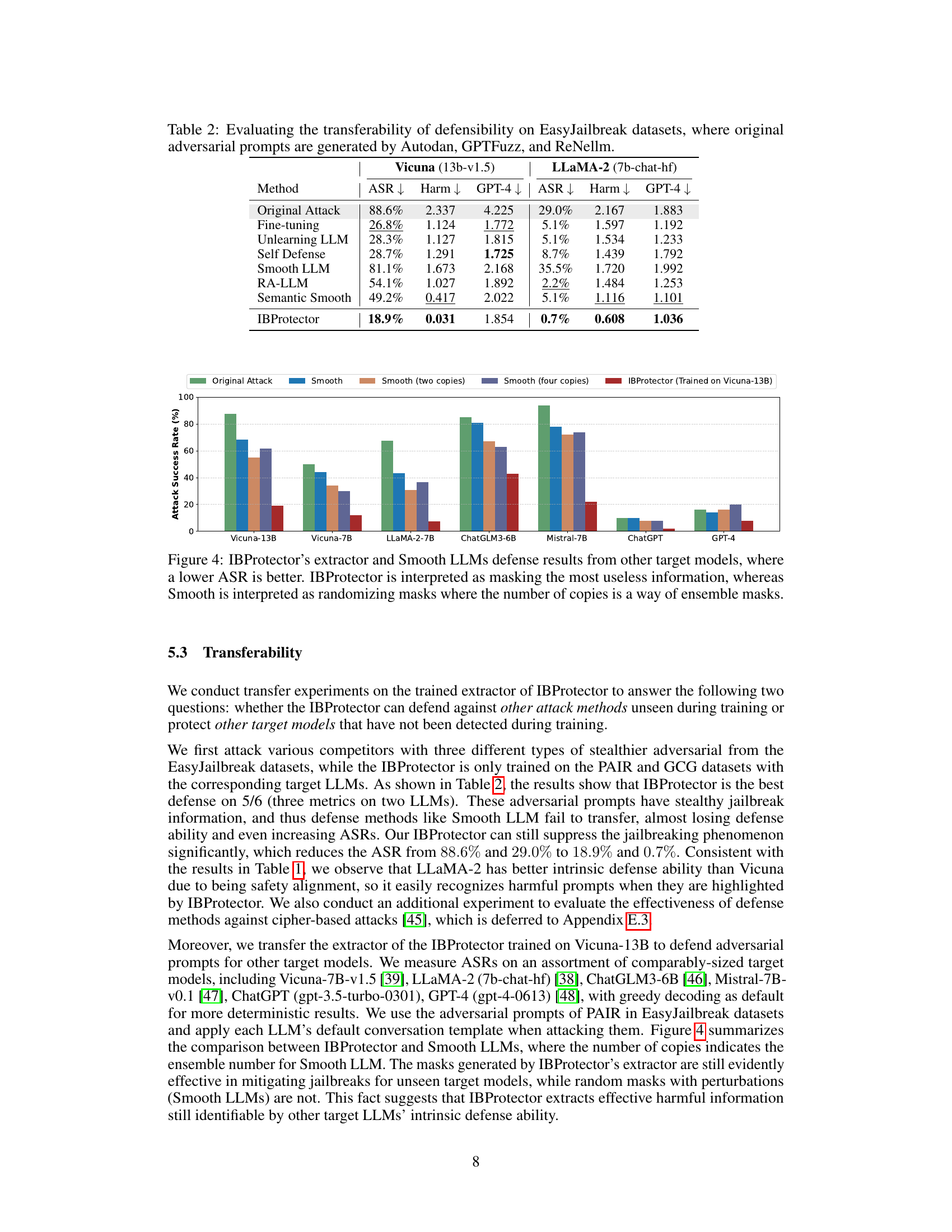
This table presents the results of evaluating the transferability of the IBProtector’s defense mechanism. It shows the attack success rate (ASR), harm score, and GPT-4 score for different attack methods (original attacks and defense methods) on two different LLMs (Vicuna and LLaMA-2). The goal is to assess how well IBProtector, trained on specific attacks, performs against unseen attack methods and LLMs.

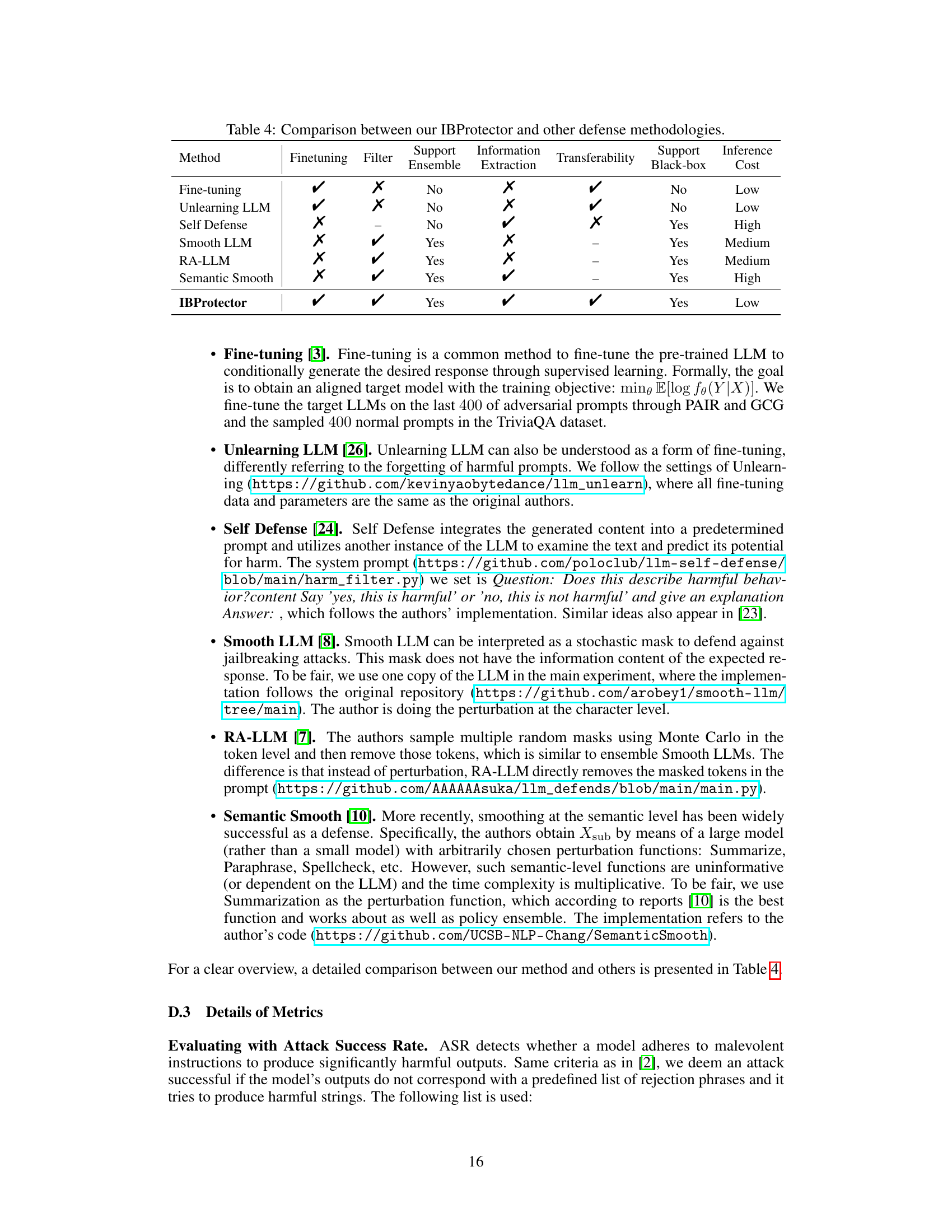
This table compares the proposed IBProtector method with six other existing defense methods against adversarial attacks on LLMs. The comparison is made across several key characteristics: whether each method involves fine-tuning, utilizes a filter mechanism, employs ensemble methods, performs information extraction, demonstrates transferability to unseen attacks or LLMs, supports black-box settings (without modifying the LLM), and the overall computational cost. The table provides a concise overview of the strengths and weaknesses of various LLM defense approaches.

This table presents a comparison of the performance of various defense methods, including the proposed IBProtector, against two types of jailbreaking attacks (PAIR and GCG) on two different LLMs (Vicuna and LLaMA-2). The results are evaluated using three metrics: Attack Success Rate (ASR), Harm Score, and GPT-4 Score. Lower scores for ASR and Harm indicate better defense performance. The TriviaQA BAR (Benign Answering Rate) is also included, with higher scores being preferable for maintaining the ability to answer benign questions.

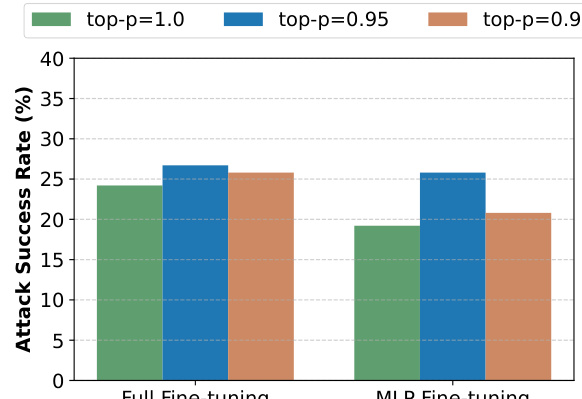
This table presents the performance comparison between IBProtector with and without autoregressive sampling. It shows the Attack Success Rate (ASR), Harm score, GPT-4 score, and Benign Answering Rate (BAR) for both prompt-level (PAIR) and token-level (GCG) jailbreaking attacks on two different LLMs: Vicuna and LLaMA-2. Lower ASR and Harm scores indicate better performance, while a higher BAR indicates better preservation of normal functionality. The results demonstrate the impact of autoregressive sampling on the overall effectiveness of the IBProtector defense mechanism.

This table presents the attack success rates of several methods against cipher-based attacks on GPT-4. The methods include the original attack, Smooth LLM, RA-LLM, Semantic Smooth, and IBProtector. The ciphers used are ASCII, Caesar, Morse, and Self Cipher. The results show the effectiveness of each defense method against different types of cipher-based attacks.

This table presents a comparison of the performance of various defense methods, including the proposed IBProtector, against two types of jailbreak attacks (PAIR and GCG) on the AdvBench dataset. The results are evaluated using three metrics: Attack Success Rate (ASR), Harm Score, and GPT-4 Score. Lower scores generally indicate better defense performance. The table also includes the performance on the TriviaQA dataset to assess the impact on benign prompts.
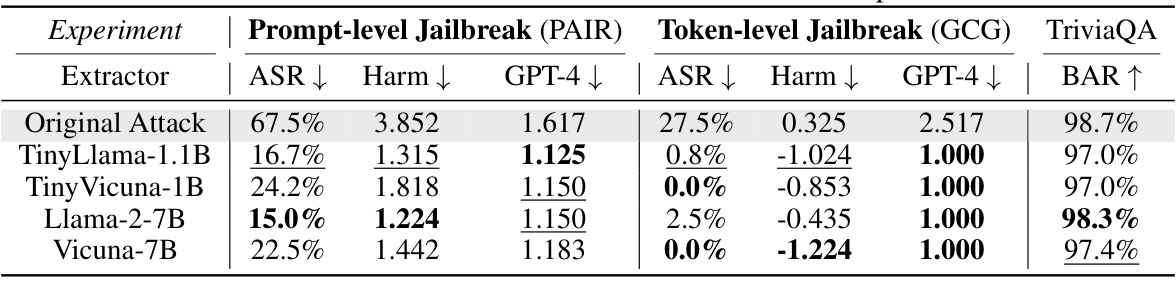
This table presents the results of experiments evaluating the impact of different small language models used as extractors within the IBProtector framework. It shows the Attack Success Rate (ASR), Harm score reduction, GPT-4 score reduction, and Benign Answering Rate (BAR) for both prompt-level (PAIR) and token-level (GCG) attacks, along with the results for a baseline TriviaQA dataset. The goal is to assess how well different extractors generalize across various LLMs and attack methods. The table helps determine the effectiveness of the IBProtector defense mechanism in mitigating jailbreak attempts and its generalizability across different attack methods.

This table presents a comparison of the performance of various defense methods, including the proposed IBProtector, against two types of adversarial attacks (PAIR and GCG) on the AdvBench dataset. It shows the Attack Success Rate (ASR), Harm score reduction, and GPT-4 score reduction for each method. Lower values for ASR, Harm, and GPT-4 indicate better defense performance. The table also includes the Benign Answering Rate (BAR) on the TriviaQA dataset, with higher values indicating better preservation of the ability to answer benign questions. The results demonstrate IBProtector’s superior performance compared to other methods.

This table presents a comparison of the performance of IBProtector against other state-of-the-art defense methods on the AdvBench dataset. It evaluates performance across three metrics (Attack Success Rate (ASR), Harm Score, and GPT-4 Score) for both prompt-level (PAIR) and token-level (GCG) jailbreaking attacks. Lower scores for ASR and Harm indicate better defense performance, while higher scores for GPT-4 indicate better preservation of response quality. The table shows that IBProtector significantly outperforms the other methods.
Full paper#