TL;DR#
Large language models (LLMs) are computationally expensive, hindering their deployment. Post-training quantization (PTQ) is a promising solution, but it often suffers from accuracy loss. Existing PTQ methods often use linear transformations introducing inference overhead.
The paper proposes MagR (Weight Magnitude Reduction), a novel non-linear preprocessing technique that reduces the maximum weight magnitude and smooths out outliers, facilitating subsequent quantization. MagR uses an efficient proximal gradient descent algorithm, introducing no additional inference overhead. Experimental results demonstrate that MagR achieves state-of-the-art performance on LLaMA models, significantly boosting accuracy for low-bit weight quantization without affecting inference speed.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on model compression and efficient deep learning. It introduces a novel preprocessing technique, MagR, that significantly improves the accuracy of post-training quantization (PTQ) for large language models (LLMs) without incurring any inference overhead. This addresses a major challenge in deploying LLMs on resource-constrained devices and opens avenues for further research in low-bit quantization techniques and efficient LLM deployment strategies.
Visual Insights#

🔼 This figure shows the effectiveness of MagR in reducing the maximum magnitude of weights. It presents three scatter plots, each representing a different layer from the LLaMa2-7B model. The x-axis shows the maximum magnitude of a weight channel before applying MagR, while the y-axis shows the magnitude after applying MagR. The plots demonstrate that MagR significantly reduces the maximum magnitude in most weight channels, typically halving it. This reduction in magnitude is crucial because it makes the weights easier to quantize, leading to improved post-training quantization performance.
read the caption
Figure 1: Motivation behind MagR: we can effectively reduce the magnitude of weights at the preprocessing stage. Each point denotes the maximum magnitude before (x-coordinate) and after (y-coordinate) applying MagR within a sampled channel (or column) of the weight matrix from three random layers of LLaMa2-7B [38]. These column-wise maximum magnitudes are typically more than halved through MagR.
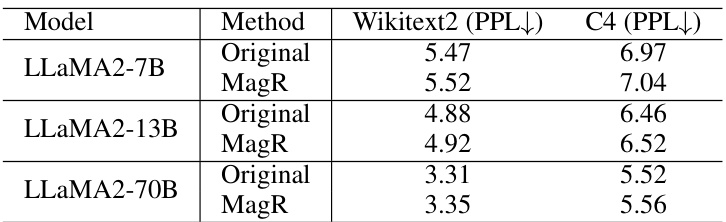
🔼 This table compares the perplexity scores achieved on the Wikitext2 and C4 datasets using the original pre-trained LLaMA2 models and those processed with the MagR method. The perplexity metric indicates how well the language model predicts the next word in a sequence, with lower scores representing better performance. The table shows results for three different sizes of LLaMA2 models (7B, 13B, and 70B parameters).
read the caption
Table 1: A comparison of perplexity (PPL) for the original pre-trained and the MagR-processed LLaMA2 models.
In-depth insights#
MagR’s Optimization#
MagR’s optimization is a crucial aspect of the paper, focusing on enhancing post-training quantization. The core idea revolves around reducing the maximum magnitude of weights in each linear layer using a channel-wise ℓ∞-regularized optimization problem. This is achieved through a proximal gradient descent algorithm, efficiently addressing the non-differentiable ℓ∞-norm. The choice of the ℓ∞-norm is deliberate, aiming to minimize the range of weights, thereby directly improving quantization’s effectiveness. This method’s elegance lies in its simplicity and inference-time efficiency, unlike alternative approaches involving linear transformations with subsequent inversions which introduce computational overhead during inference. MagR’s non-linearity distinguishes it from linear transformations, ensuring that the optimization doesn’t burden runtime. The optimization’s effectiveness hinges on the approximately rank-deficient nature of the feature matrices in large language models, ensuring the existence of solutions that preserve layer outputs while shrinking weight magnitudes. Overall, MagR’s optimization offers a powerful, lightweight solution to a significant problem in efficient LLM deployment.
PTQ Enhancement#
Post-training quantization (PTQ) aims to enhance the efficiency of large language models (LLMs) by reducing the precision of their weights. However, this often comes at the cost of reduced accuracy. PTQ enhancement techniques focus on mitigating this accuracy loss. The paper explores a preprocessing technique called Weight Magnitude Reduction (MagR) that addresses this challenge. MagR minimizes the maximum magnitude of weights, which facilitates subsequent quantization and improves performance without introducing inference overhead. This is a key advantage over other methods that use linear transformations, which require additional computation at inference time. By using an efficient proximal gradient descent algorithm, MagR effectively reduces the quantization scale, leading to state-of-the-art results in experiments on various LLMs and benchmarks. The non-linear nature of MagR, unlike many linear transformation-based techniques, contributes significantly to its efficiency gains and superior performance. This approach highlights the potential of pre-processing optimization for improving quantization outcomes without compromising inference speed. Overall, MagR presents a promising advancement in the quest to achieve efficient and accurate PTQ of LLMs.
Inference Overhead#
Inference overhead is a critical concern in deploying quantized large language models (LLMs). Many quantization techniques introduce additional computational steps during inference, offsetting the benefits of reduced model size and faster processing. This overhead often manifests as extra matrix operations or transformations applied to the input features before the model’s core operations. The paper focuses on minimizing this overhead, emphasizing that MagR (Weight Magnitude Reduction), unlike other methods, functions as a non-linear preprocessing step, causing no extra computation during inference. This advantage is a major contribution, ensuring that the quantization gains are fully realized without compromising real-world performance. The absence of inference overhead makes MagR a practical and efficient solution for quantizing LLMs, particularly for deployment on resource-constrained devices.
LLaMA Family#
The LLaMA family of large language models (LLMs) represents a significant advancement in the field, offering high performance with relatively low computational costs. The paper highlights the effectiveness of the proposed method, MagR, in enhancing the post-training quantization of these models. This is particularly important given the enormous computational demands associated with LLMs, making efficient compression techniques such as quantization crucial for wider adoption. MagR’s performance on the LLaMA family underscores its potential as a state-of-the-art preprocessing technique capable of significantly improving quantization results without introducing any inference overhead. The use of the LLaMA family as a benchmark effectively demonstrates the method’s applicability to a widely used and influential set of LLMs, thus increasing the credibility of its claims.
Future Directions#
Future research could explore extending MagR’s applicability beyond LLMs. Adapting MagR to other deep learning architectures, such as computer vision models or those used in reinforcement learning, would be valuable. Investigating the interaction between MagR and different quantization techniques is another avenue. While MagR shows promise with gradient-free methods, combining it with gradient-based approaches may unlock further performance gains. A comprehensive study comparing MagR’s performance across a broader range of model sizes and quantization bit-widths would be beneficial. Finally, further investigation into the theoretical underpinnings of MagR, particularly the relationship between the l∞-regularization and quantization error, is crucial for a deeper understanding of its effectiveness and potential for future improvements. Exploring different regularization techniques or combining l∞-regularization with other methods could potentially lead to more robust and efficient solutions for post-training quantization.
More visual insights#
More on tables
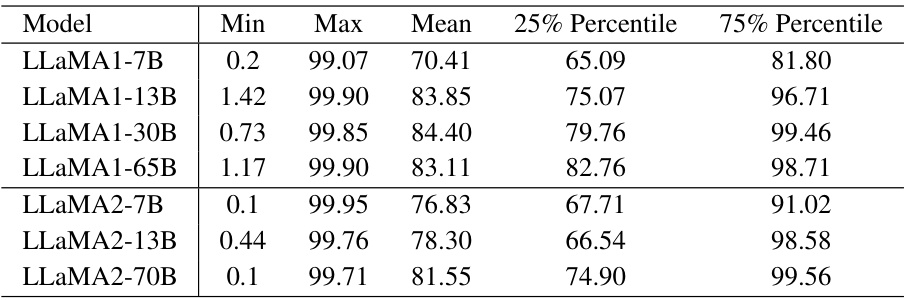
🔼 This table shows the statistics of the approximate fraction ranks of feature matrices (X) across all layers in various LLaMA models. The fraction rank is calculated as the percentage of singular values of X that are greater than 0.01 times the maximum singular value. The table demonstrates that the feature matrices in all LLaMA models are approximately rank-deficient, with some exhibiting very low ranks.
read the caption
Table 2: The statistics of (approximate) fraction ranks in percentage (%) of feature matrix X across all layers of LLaMA models. All feature matrices are approximately rank-deficient with a fraction rank less than 100%. Some of them are highly low-rank with a fraction rank ≈ 1%.
🔼 This table compares the perplexity scores achieved on the Wikitext2 and C4 datasets using the original pre-trained LLaMA2 models (7B, 13B, and 70B parameters) and those same models after being processed by the MagR method. Lower perplexity scores indicate better performance.
read the caption
Table 1: A comparison of perplexity (PPL) for the original pre-trained and the MagR-processed LLaMA2 models.
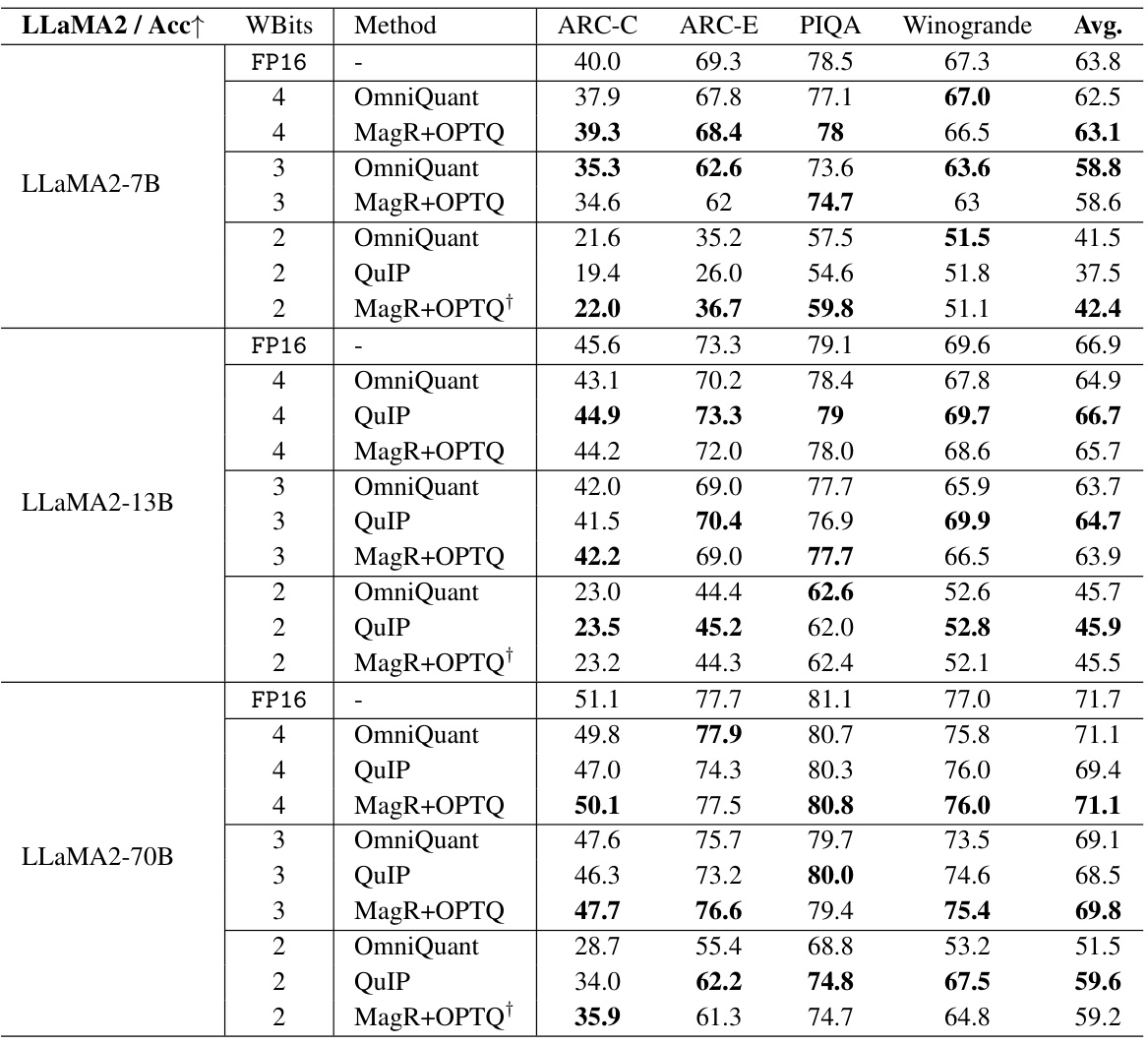
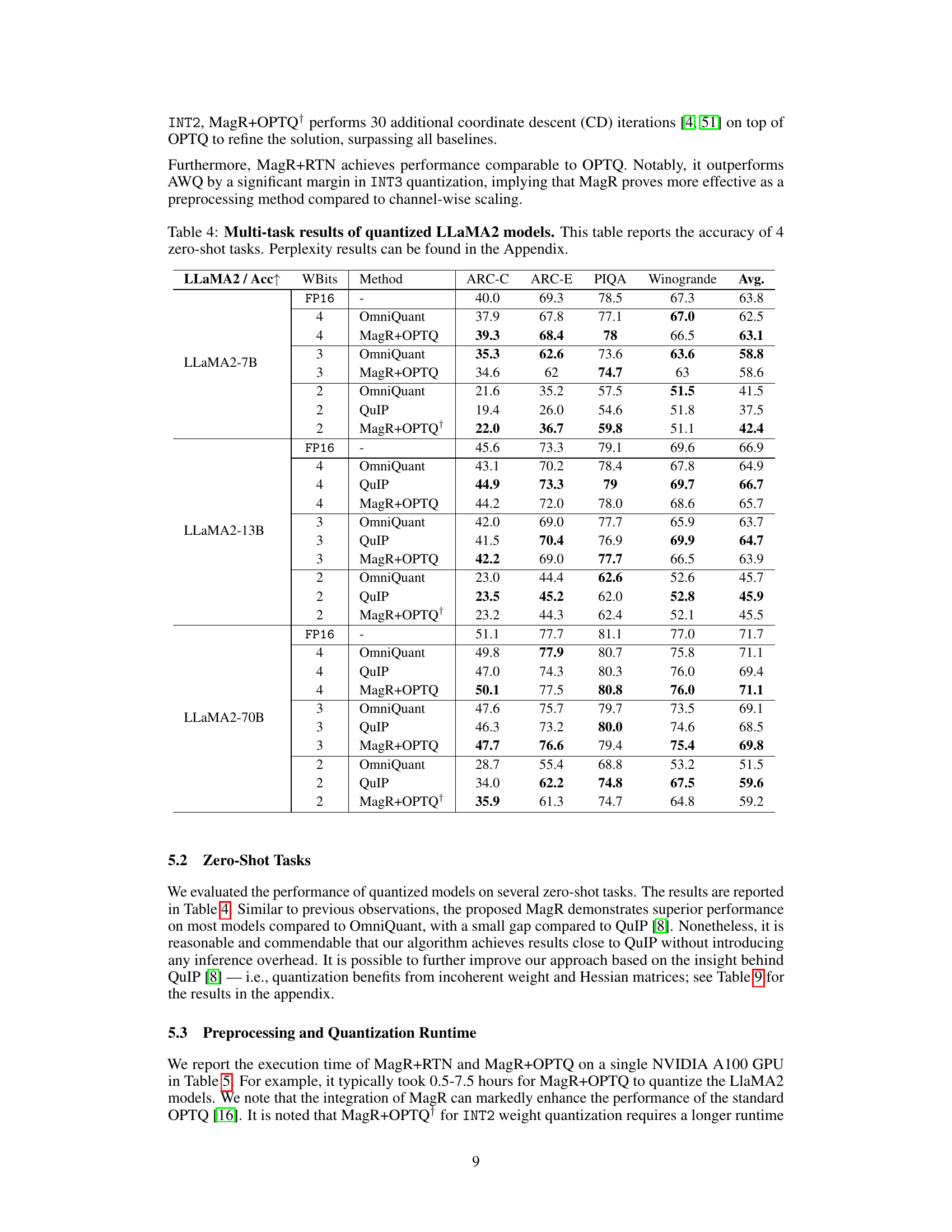
🔼 This table presents the results of zero-shot tasks on four datasets (ARC-C, ARC-E, PIQA, Winogrande) for quantized LLaMA2 models with varying bit-widths (2, 3, 4 bits) for weights and 16 bits for activations. It compares the performance of OmniQuant, QuIP, MagR+OPTQ, and MagR+OPTQ+. Note that perplexity results are available in the appendix.
read the caption
Table 4: Multi-task results of quantized LLaMA2 models. This table reports the accuracy of 4 zero-shot tasks. Perplexity results can be found in the Appendix.

🔼 This table shows the runtime comparison of different quantization methods on three different sizes of LLAMA2 models. It compares the original RTN and OPTQ methods to their enhanced versions that incorporate the MagR pre-processing technique. It also shows the additional time required when using MagR+OPTQ†, which includes extra coordinate descent iterations for further optimization. The table highlights that while MagR adds pre-processing time, its inference time overhead is negligible.
read the caption
Table 5: The runtime of MagR+RTN, MagR+OPTQ, and MagR+OPTQ† on an Nvidia A100 GPU, with comparisons to their vanilla counterparts, namely, RTN and OPTQ.
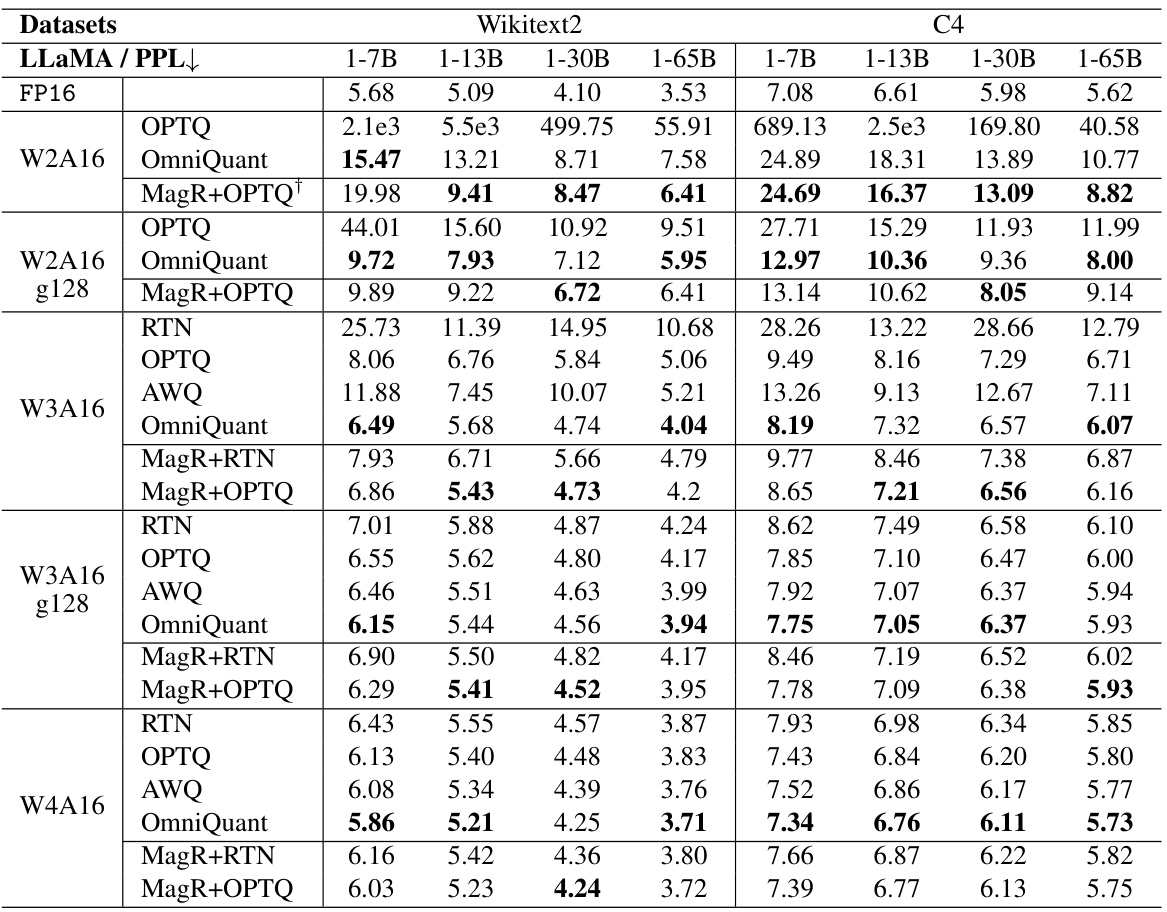
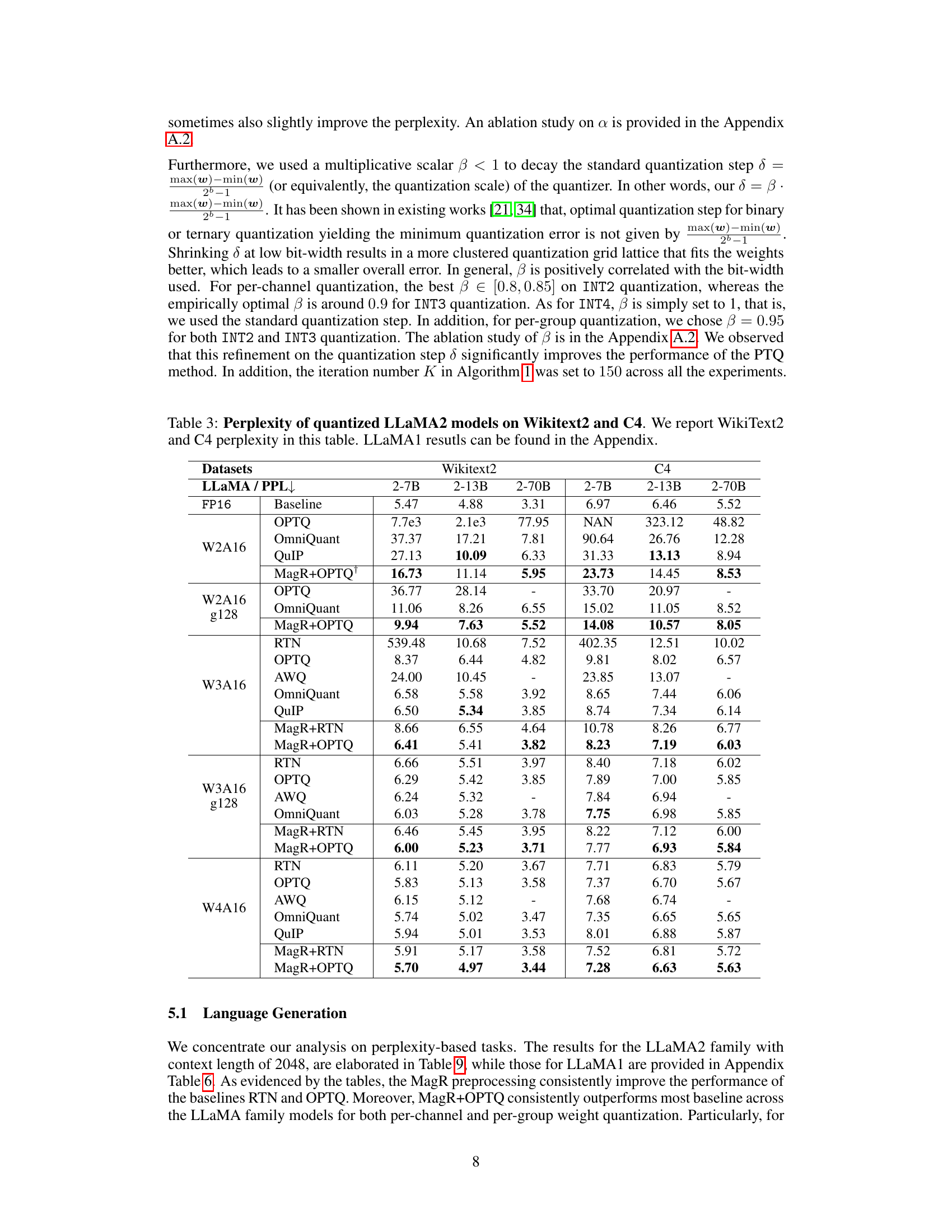
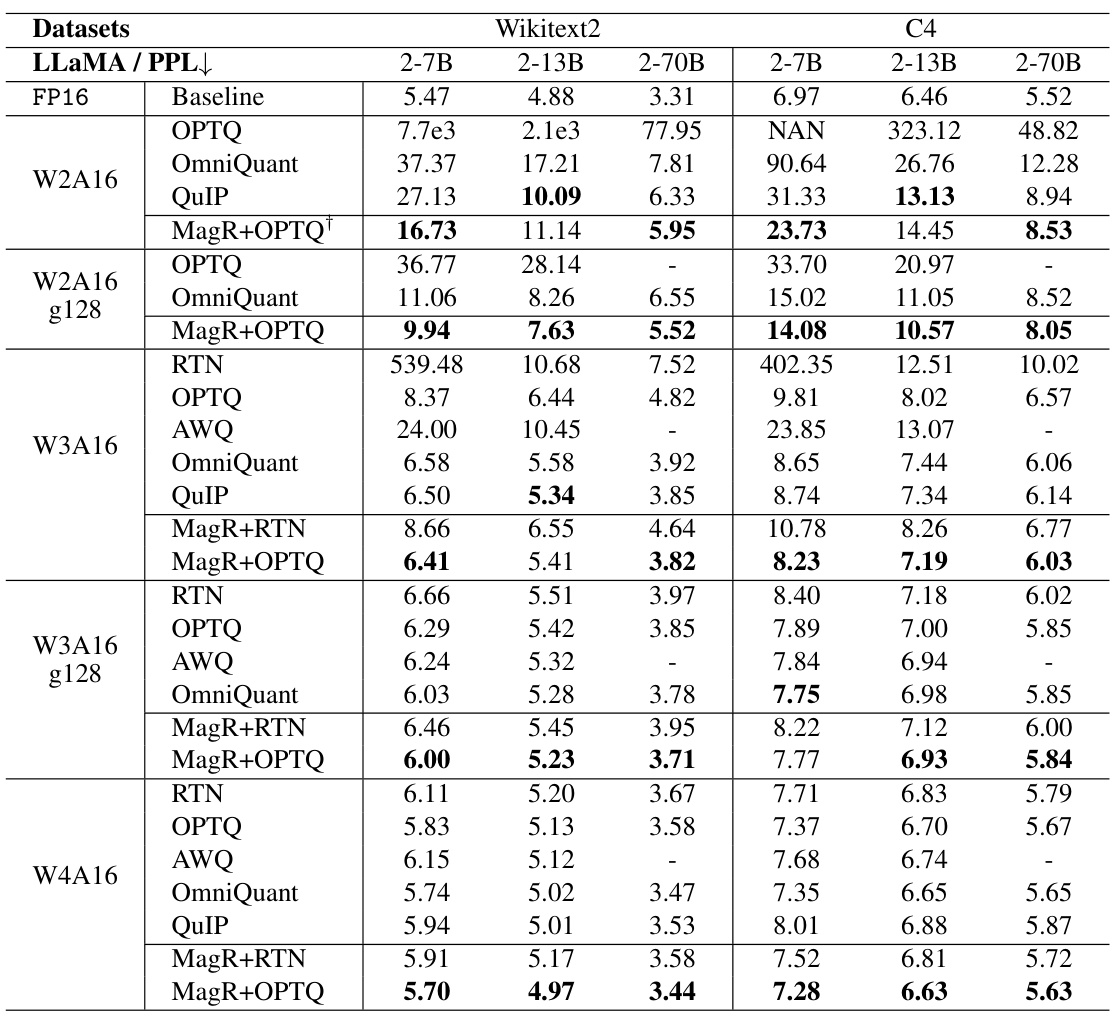
🔼 This table presents a comparison of the perplexity scores achieved by different quantization methods (OPTQ, OmniQuant, QuIP, MagR+OPTQ, etc.) on the LLaMA2 model family (7B, 13B, and 70B parameters) for different bit-widths (W2A16, W3A16, W4A16) and group sizes (g128). The perplexity is a measure of how well the model predicts a sequence of words, with lower scores indicating better performance. The results are broken down by dataset (Wikitext2 and C4) and model size, allowing for a detailed performance comparison across various settings and methods.
read the caption
Table 3: Perplexity of quantized LLaMA2 models on Wikitext2 and C4. We report WikiText2 and C4 perplexity in this table. LLaMA1 resutls can be found in the Appendix.

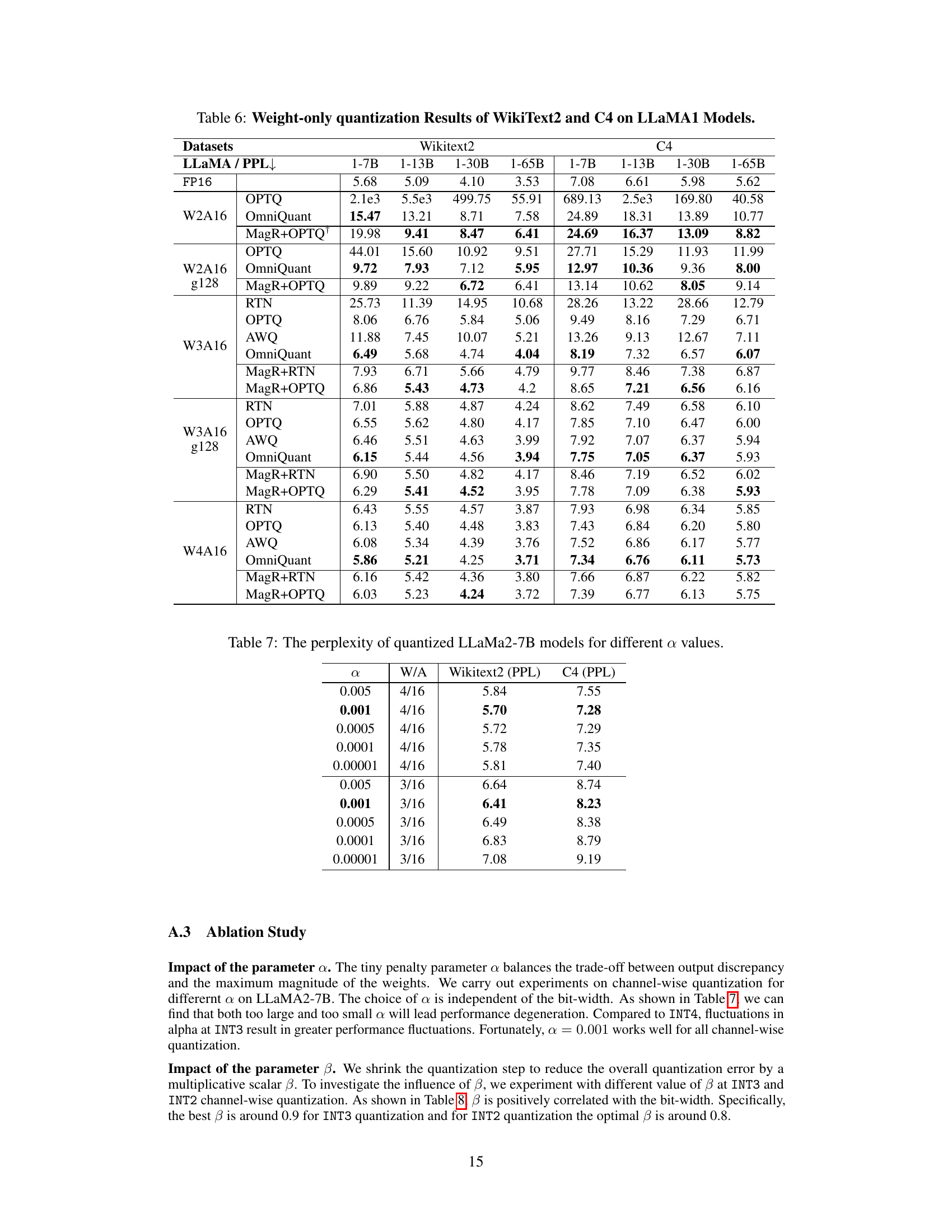
🔼 This table shows the perplexity scores on the WikiText2 and C4 datasets for different values of the regularization parameter α, with weight and activation bit-widths of 4/16 and 3/16. Lower perplexity indicates better performance. The results demonstrate the impact of α on the model’s performance after applying the MagR preprocessing technique.
read the caption
Table 7: The perplexity of quantized LLaMa2-7B models for different α values.
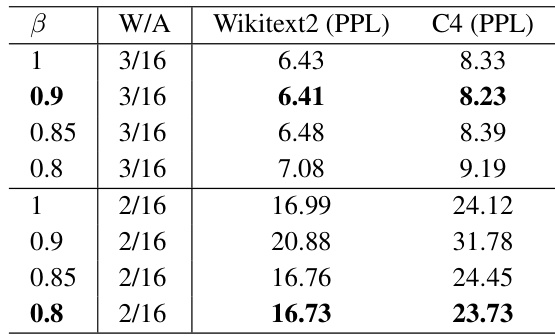
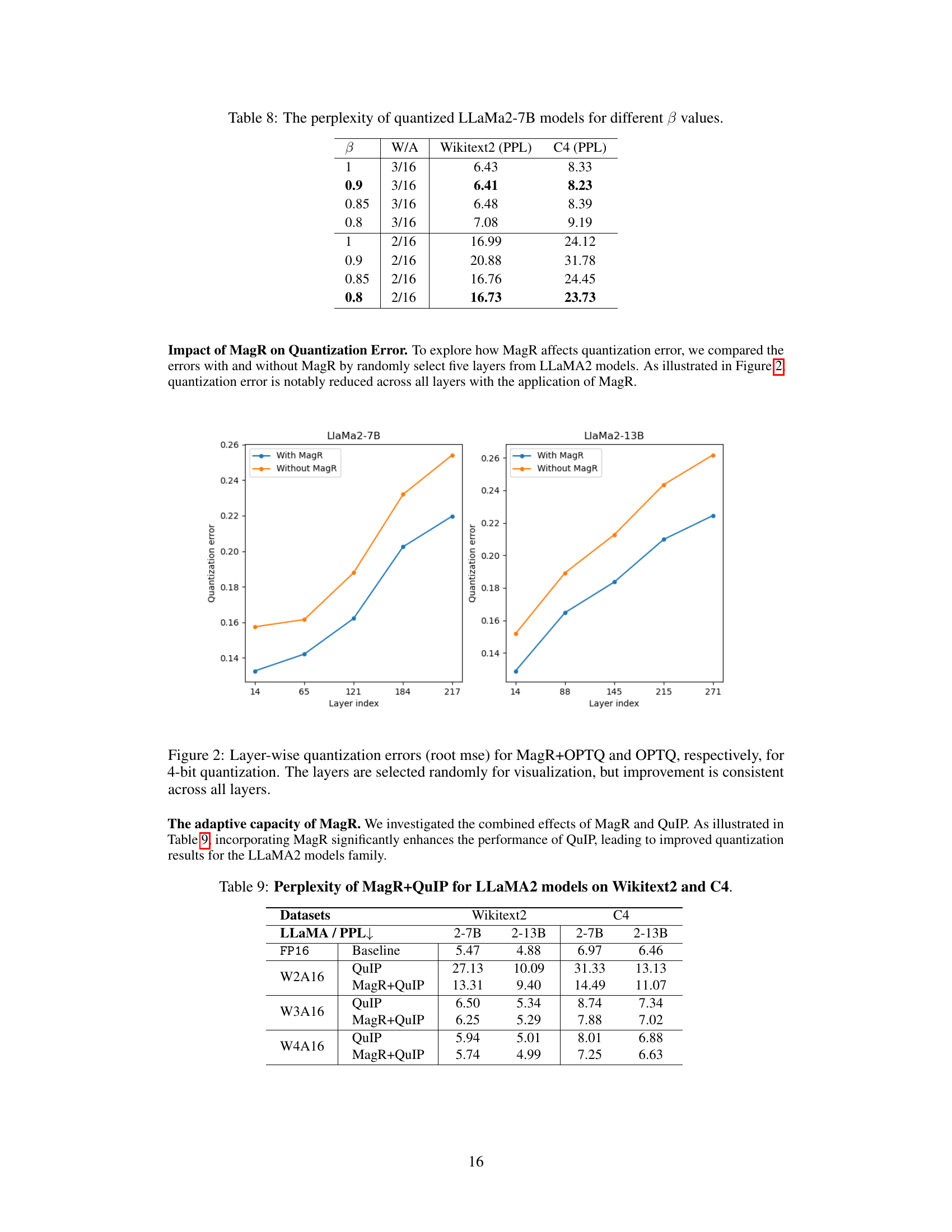
🔼 This table presents the perplexity results on WikiText2 and C4 datasets for the quantized LLaMa2-7B model with different values of the beta (β) parameter. Beta is used as a multiplicative scalar to decay the standard quantization step in the quantizer. The table shows how varying the β parameter affects the model’s performance across different bit-widths (3-bit and 2-bit) for weight-only quantization.
read the caption
Table 8: The perplexity of quantized LLaMa2-7B models for different β values.

🔼 This table presents the perplexity scores achieved by QuIP and MagR+QuIP on the WikiText2 and C4 datasets, using various bit-width settings for weights (W2, W3, W4) while keeping activations at 16 bits. It demonstrates the impact of incorporating MagR into the QuIP algorithm on model performance across different model sizes (7B and 13B parameters). Lower perplexity indicates better performance.
read the caption
Table 9: Perplexity of MagR+QuIP for LLAMA2 models on Wikitext2 and C4.
Full paper#