↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs), while powerful, suffer from slow inference speeds due to their quadratic complexity. Linear Recurrent Neural Networks (RNNs), such as Mamba, offer faster inference but usually underperform Transformers in benchmarks when trained from scratch. This creates a need for methods that combine the strengths of both architectures.
This paper addresses this challenge by distilling large pretrained Transformers into linear RNNs. The researchers leverage the linear projection weights from Transformer attention layers to initialize a modified Mamba architecture. They also develop a hardware-aware speculative decoding algorithm to further accelerate inference. Their experiments show that the resulting hybrid model achieves performance comparable to the original Transformer, while outperforming existing linear RNN models in chat and general benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in natural language processing and machine learning due to its significant advancements in efficient large language model deployment. It introduces novel distillation and acceleration techniques, applicable across various models, directly impacting the field’s trajectory toward more efficient and accessible large language models. The methods proposed open avenues for new research and improvements in inference speed, scalability and resource utilization.
Visual Insights#

This figure illustrates the process of transferring weights from a Transformer model to a Mamba model. The orange weights in the Mamba architecture are directly initialized from corresponding weights in the Transformer’s attention mechanism. The Mamba model replaces the Transformer’s attention blocks, while the MLP layers remain unchanged (frozen during training). Additional parameters (green) are introduced for the Mamba model to learn more complex functions and improve performance. The figure visually depicts this weight transfer and adaptation.

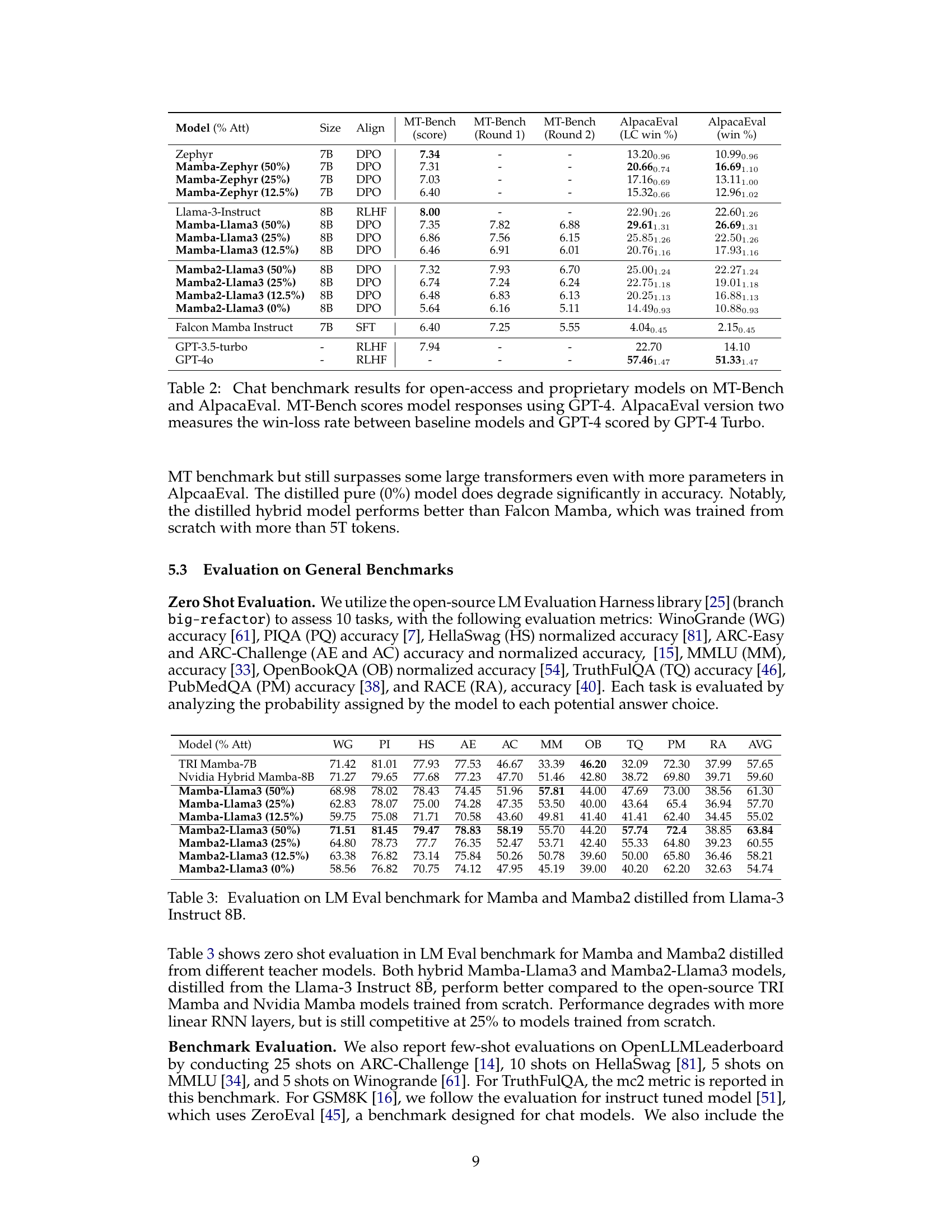
This table compares the performance of different language models, including open-source and proprietary ones, on two benchmark tasks: MT-Bench (multi-turn chat) and AlpacaEval (single-turn chat). MT-Bench scores are based on GPT-4 judgments, while AlpacaEval uses GPT-4 Turbo to assess win/loss rates against GPT-4. The table shows the models’ performance in terms of scores and win rates, allowing for a comparison of different model architectures and training methods.
In-depth insights#
Hybrid Model Distillation#
Hybrid model distillation, as explored in this research, focuses on effectively transferring knowledge from large, computationally expensive Transformer models to more efficient linear RNN architectures like Mamba. The core idea is to leverage pretrained Transformer weights, specifically from attention layers, to initialize a modified Mamba model. This avoids training from scratch, significantly reducing resource requirements. The resulting hybrid model incorporates a portion of the original Transformer’s attention layers, retaining performance while enhancing efficiency. A key innovation is the multistage distillation process, combining progressive distillation, supervised fine-tuning, and preference optimization for enhanced performance. This approach mirrors the standard LLM pipeline, effectively adapting the linear RNN to the intricacies of language modeling tasks. The results demonstrate that the hybrid approach achieves impressive results in chat benchmarks, exceeding the performance of similar linear RNN models trained from scratch. A significant enhancement to inference is presented through a hardware-aware speculative decoding algorithm, accelerating the generation speed of the hybrid model without sacrificing accuracy. This work highlights the balance between computational costs and accuracy in large language models, paving the way for more efficient and widely deployable LLMs.
Linear RNN Efficiency#
Linear Recurrent Neural Networks (RNNs) offer a compelling alternative to Transformers for various Natural Language Processing tasks. Their efficiency stems from their linear time complexity, unlike Transformers’ quadratic dependency on sequence length, making them significantly faster for long sequences. This speed advantage is crucial for applications like long-form text generation and real-time interactions. However, achieving comparable performance to Transformers remains a challenge, particularly at larger scales. Research focuses on architectures like Mamba, which employ sophisticated state-space models and hardware-aware optimizations to enhance performance and efficiency. Distillation techniques that transfer knowledge from large pretrained Transformers to smaller, more efficient linear RNNs are actively explored to bridge the performance gap while retaining the speed benefits of linear RNNs. The ultimate goal is to leverage the best of both worlds – the high accuracy of Transformers and the efficiency of linear RNNs – resulting in faster, more resource-friendly language models.
Speculative Decoding#
Speculative decoding is a crucial technique for accelerating autoregressive language model generation. By predicting future tokens, it allows for parallel computation, significantly reducing latency. The paper explores the challenges of applying speculative decoding to linear RNN models like Mamba, particularly highlighting the memory overhead associated with caching previous hidden states for potential backtracking. A novel multi-step RNN speculation algorithm is introduced to overcome these challenges by efficiently computing multiple steps and selectively caching states to minimize memory usage and maximize throughput. The algorithm is designed to be hardware-aware, optimizing performance on current GPU architectures. Experimental results demonstrate that this approach significantly improves the speed of linear RNN inference, showcasing the benefits of speculative decoding in the context of efficient large language model deployment.
Multi-Stage Distillation#
Multi-stage distillation, in the context of large language model (LLM) compression, likely refers to a training process that sequentially refines a smaller, distilled model using different stages or objectives. This is a significant improvement over single-stage distillation because it addresses the limitations of trying to capture all of the LLM’s complexity in one step. Each stage likely focuses on a specific aspect of the LLM’s behavior, progressively improving the distilled model’s performance and alignment with the original. Early stages might focus on general language modeling capabilities, perhaps employing standard knowledge distillation techniques like minimizing KL divergence between teacher and student model outputs. Subsequent stages may introduce more specialized objectives such as instruction following or preference optimization, using methods like supervised fine-tuning or reinforcement learning from human feedback. This iterative approach allows for a more nuanced transfer of knowledge, effectively addressing the challenge of transferring complex, multi-faceted knowledge from a large model to a smaller one. The result is a potentially more efficient and accurate distilled model compared to a single-stage approach, trading off computational cost for improved accuracy and alignment.
Limitations and Future#
The research paper’s limitations center on the use of only chat corpora for training due to budgetary constraints, potentially limiting the generalizability of findings. Future work could explore training on broader datasets and scaling to larger model sizes to ascertain the impact on performance and efficiency. Another limitation stems from the model’s reliance on a specific hardware-aware speculative decoding algorithm; further research into alternative algorithms for broader compatibility is necessary. Finally, while the distilled hybrid models demonstrate promising results, a comprehensive evaluation across a wider range of benchmarks and tasks is crucial to validate their robustness and generalization capabilities. Addressing these points would strengthen the methodology and broaden the applicability of this efficient LLM distillation approach.
More visual insights#
More on figures

This figure illustrates the process of transferring weights from a Transformer model to a Mamba model. Weights from the Transformer’s linear projections (Q, K, V) are directly initialized into the corresponding Mamba blocks (C, B, X). The existing Transformer MLP blocks are frozen during fine-tuning, and only new parameters (shown in green) for the Mamba layers (A) are trained. This hybrid architecture, where Mamba blocks replace Transformer attention heads, aims for efficient inference while retaining performance.

This figure shows the performance comparison between the multi-step and single-step SSM (State Space Model) kernels in generating 32 tokens. The x-axis represents the step size (K), and the y-axis represents the time in milliseconds. The multi-step kernel demonstrates significantly faster generation times, especially at smaller step sizes, while the single-step kernel shows relatively constant generation time regardless of step size. This illustrates the efficiency gains achieved by the multi-step speculative decoding algorithm.
More on tables

This table compares the performance of different language models, including both open-source and proprietary models, on two distinct chat benchmarks: MT-Bench and AlpacaEval. MT-Bench assesses the quality of model responses using GPT-4 as a judge, while AlpacaEval v2 utilizes GPT-4 Turbo to determine a win/loss rate against baseline models. The table allows for a comparison of various model architectures and training methodologies, highlighting their strengths and weaknesses in different evaluation settings.
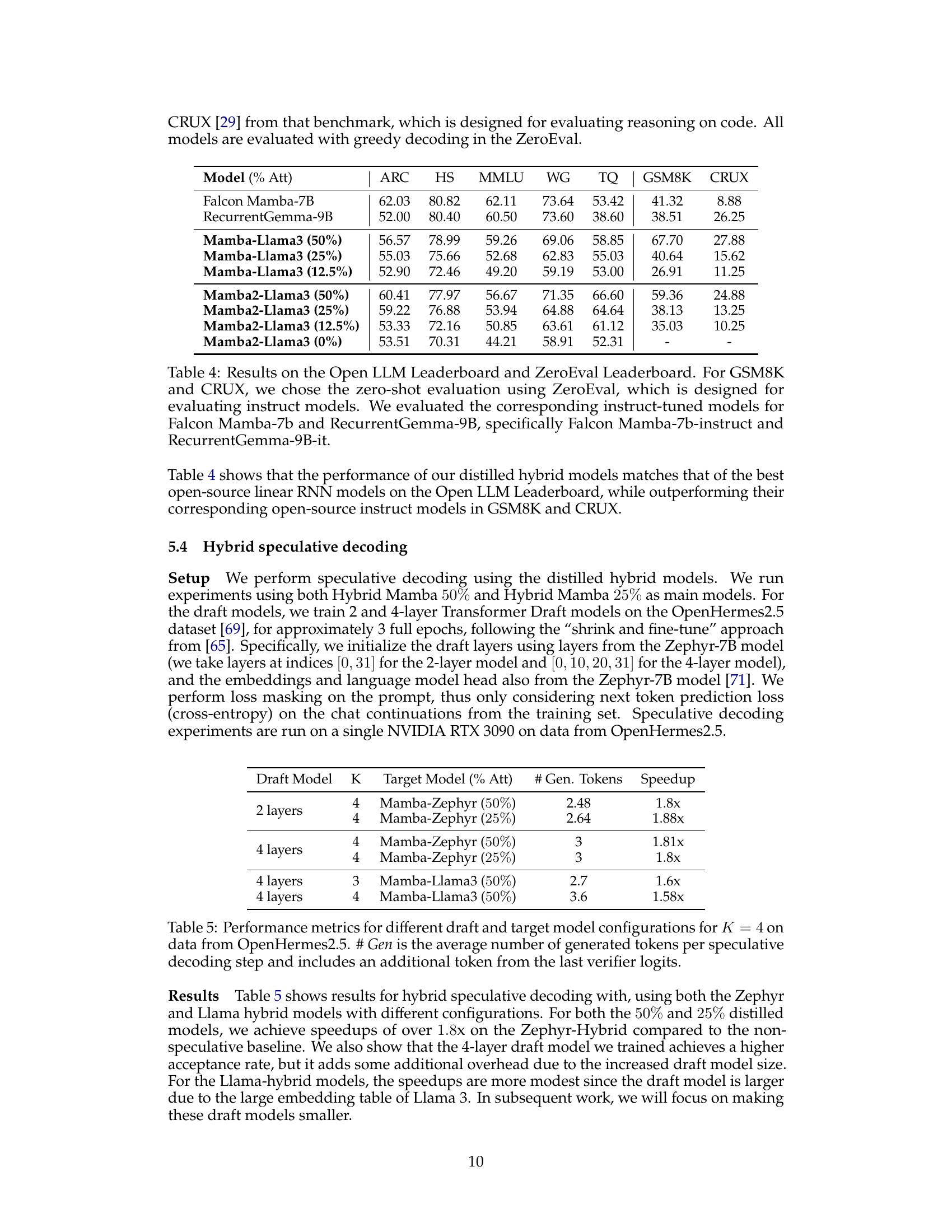
This table presents the speedup achieved by using speculative decoding with pure Mamba models of different sizes (2.8B and 7B parameters) on different GPUs (3090 and H100). The speedup is calculated by comparing the throughput (tokens per second) of speculative decoding against a baseline non-speculative decoding approach. It shows that speculative decoding provides substantial speed improvements, particularly with the H100 GPU. The number of draft tokens generated and the model sizes used are also indicated.

This table compares the performance of various language models, including the distilled hybrid Mamba models, on two chat benchmarks: MT-Bench and AlpacaEval. MT-Bench uses GPT-4 to score the model’s responses, while AlpacaEval uses GPT-4 Turbo to measure the win/loss rate against GPT-4. The table shows the scores achieved by different models, highlighting the performance of the distilled models compared to the original models and other baselines. The model size, alignment method, and architecture are also specified.
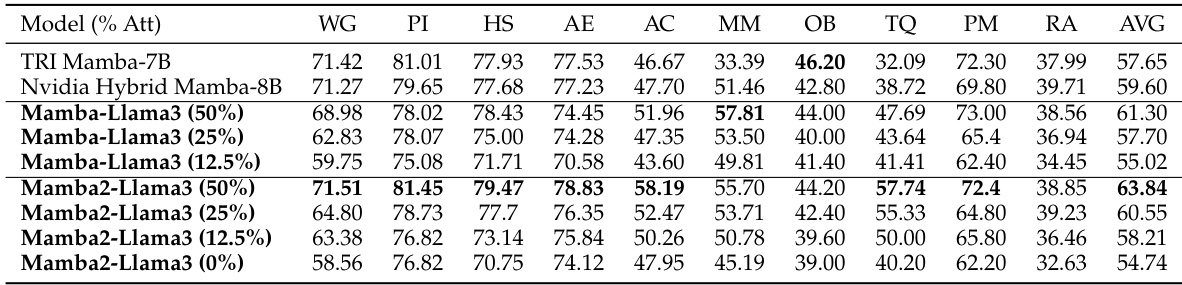
This table presents the results of zero-shot evaluation on the LM-Eval benchmark for Mamba and Mamba2 models distilled from Llama-3 Instruct 8B. It compares the performance of different configurations of these models (varying the percentage of attention layers replaced with linear RNNs) across ten tasks, showing their accuracy or normalized accuracy on each. The table also includes results for baseline models TRI Mamba-7B and Nvidia Hybrid Mamba-8B for comparison. The purpose is to demonstrate the effectiveness of the distillation method and the performance of the resulting hybrid models in a general language modeling evaluation setting.
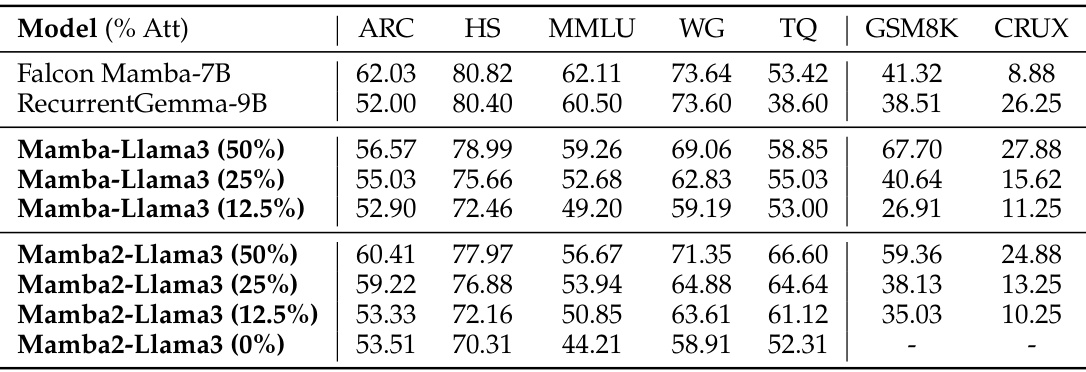
This table presents the zero-shot performance of different language models on various benchmarks from the Open LLM Leaderboard and ZeroEval Leaderboard. The benchmarks cover diverse tasks including commonsense reasoning, knowledge, and code understanding. The table compares the performance of distilled hybrid Mamba models with different percentages of attention layers retained against several strong baselines, including Falcon Mamba and RecurrentGemma. The results highlight the competitive performance of the distilled models, particularly those with a higher percentage of attention layers.

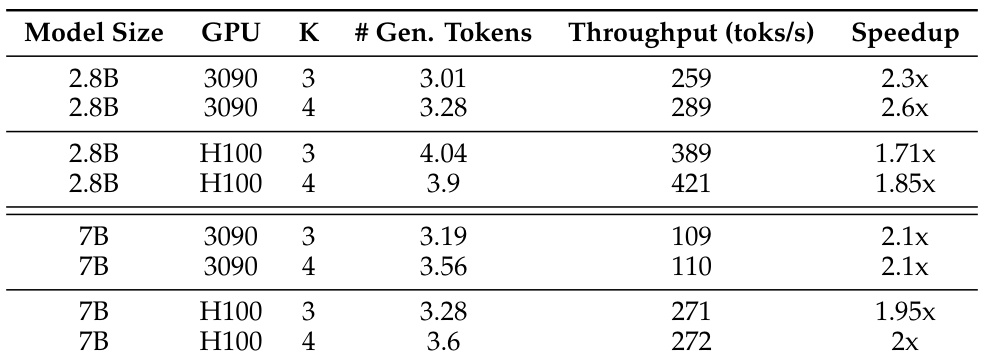
This table presents the results of speculative decoding experiments using different configurations of draft and target models. It shows the speedup achieved by speculative decoding compared to a non-speculative baseline for different models and numbers of generated tokens. The experiments were performed on the OpenHermes2.5 dataset.
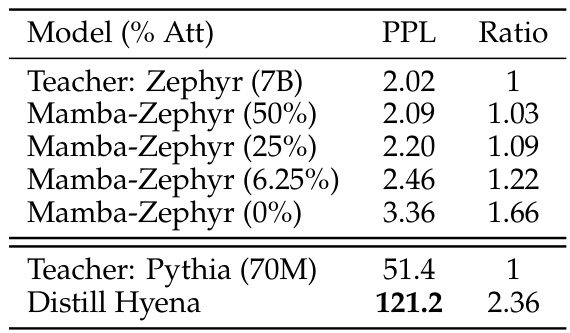
This table presents a comparison of perplexity scores between the proposed distillation method and a previous approach [59], showing the impact of removing attention layers from the model. The right side shows an ablation study investigating the effects of different alignment methods (distillation, supervised fine-tuning (SFT), and directed preference optimization (DPO)) on the performance of the distilled hybrid Mamba model using a specific dataset.

This table presents a comparison of perplexity scores between the proposed distillation method and a previous method from the literature ([59]). It also shows an ablation study on different alignment methods for the distilled hybrid Mamba model, using the MT-benchmark and the OpenHermes 2.5 dataset for supervised fine-tuning.

This table presents the results of ablation studies on the knowledge distillation process for the Mamba model. The left side shows the impact of different initialization methods on perplexity, comparing models initialized with transformer weights versus random initialization. The right side shows the effect of different distillation strategies (interleaving attention and Mamba layers versus a stepwise approach) on perplexity.

This table compares the performance of the hybrid model (Zephyr-Mamba with 50% attention layers) using two different initialization methods: default random initialization and reusing the linear projection from the attention layers of the original transformer model. The results show that using the linear projection from the attention layers leads to significantly better performance across all evaluated benchmarks, highlighting the importance of proper weight initialization for effective knowledge distillation.

This table compares the performance of the hybrid model (50% attention with Mamba and 50% attention without Mamba) using two different initialization methods: default random initialization and reusing the linear projection from the attention. The results show that initializing from attention weights is crucial for good performance.
Full paper#