TL;DR#
Cross-domain recommendation (CDR) aims to improve recommendation accuracy by utilizing data from multiple domains, but faces issues like data sparsity, privacy concerns during knowledge transfer, and negative transfer (where source domain knowledge harms target domain performance). Existing methods often overlook these challenges, especially in settings with many source domains.
To address these issues, the authors propose FedGCDR, a federated graph learning framework. FedGCDR uses a two-stage process. First, a positive knowledge transfer module employs differential privacy to protect user data during inter-domain knowledge transmission, and a feature mapping mechanism ensures reliable knowledge transfer. Second, a knowledge activation module filters out negative knowledge, enhancing the target domain’s training via graph expansion and model fine-tuning. Experiments on Amazon datasets demonstrate that FedGCDR significantly surpasses existing approaches in recommendation accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on cross-domain recommendation and federated learning. It addresses critical challenges of data sparsity, negative transfer, and privacy in a multi-domain setting. The proposed approach, FedGCDR, provides a novel solution with strong empirical results, opening avenues for improved recommendation systems and privacy-preserving data sharing.
Visual Insights#

🔼 This figure illustrates the challenges in broader-source cross-domain recommendation (BS-CDR). Subfigure (a) shows how BS-CDR aims to leverage user preferences from multiple source domains (Movies, Toys, Games, Music, Clothing, Sports, and Phone) to improve recommendation accuracy in the target domain (Books). However, privacy-preserving techniques can lead to low-quality data in some source domains, resulting in negative knowledge transfer. Subfigure (b) shows that as the number of source domains increases, the positive effect of knowledge transfer diminishes, while the negative impact from low-quality data accumulates, leading to overall performance degradation.
read the caption
Figure 1: (a) In order to obtain accurate recommendations in the Books domain, we aim to exploit user preferences (i.e., knowledge of external domains should be fully utilized, e.g. Movie, Toys, and Games domains). However, with the influence of lossy privacy-preserving techniques, the results of the transfer could be negative (e.g., the Music domain with low-quality data). (b) There is a diminishing marginal effect on the growth rate of the model performance with pure positive knowledge, while NT accumulates with an increasing number of source domains. Consequently, the performance of existing methods declines and is worse than that of a single domain model.

🔼 This table presents the statistics of the Amazon dataset used in the experiments. It shows the minimum, median, and maximum values for the number of users (|Ua|), the number of items (|Ia|), and the number of ratings (|Rd|) for four different subsets of the dataset: Amazon-4, Amazon-8, Amazon-16, and Amazon-Dual. The Amazon-Dual dataset represents a subset with only two domains and fully overlapping users, while the others represent increasing numbers of domains. The ‘avg (sparsity)’ column indicates the average sparsity level of the rating matrices for each subset.
read the caption
Table 1: Statistics on the Amazon Dataset. (min-median-max) values are provided for |Ua|, |Ia| and Rd.
In-depth insights#
FedGCDR Framework#
The FedGCDR framework is a novel approach to cross-domain recommendation that leverages federated graph learning to address both privacy and negative transfer issues. It does so through a three-stage, horizontal-vertical-horizontal pipeline. The framework’s core innovation lies in its two key modules: a positive knowledge transfer module, employing differential privacy to ensure secure inter-domain knowledge exchange, and a positive knowledge activation module that filters out harmful knowledge and enhances target domain training via graph expansion and model fine-tuning. This approach is particularly effective in broader source cross-domain recommendation scenarios where many source domains might introduce conflicting information, thus outperforming single-domain models and existing multi-domain methods.
Privacy-Preserving Transfer#
Privacy-preserving transfer in federated learning tackles the challenge of sharing sensitive data across multiple domains for collaborative model training. Differential privacy is a common technique, adding carefully calibrated noise to training data or model parameters to prevent individual data points from being identified while still enabling useful model improvements. Federated aggregation methods play a crucial role, ensuring that sensitive information remains decentralized and only aggregate model updates are exchanged. Secure multi-party computation offers another approach, enabling computations on encrypted data without revealing the underlying data. The trade-off between privacy and utility is central: stronger privacy guarantees may come at the cost of reduced model accuracy. Careful selection of privacy parameters and rigorous privacy analyses are essential. Future research might focus on developing more efficient privacy-preserving techniques to minimize communication overhead while maintaining high levels of privacy.
Negative Transfer Mitigation#
Negative transfer, where knowledge from a source domain hinders performance in the target domain, is a critical challenge in cross-domain recommendation. Mitigating this requires careful consideration of knowledge selection and filtering. Strategies might include pre-filtering source domain knowledge based on similarity or relevance to the target domain, employing attention mechanisms to weight source domain contributions differentially, or using adversarial training to explicitly identify and suppress harmful knowledge transfer. Federated learning offers a promising approach, enabling privacy-preserving knowledge sharing while allowing each domain to control its own data. However, even with these techniques, the complex interplay between domains and the potential for unexpected interactions necessitates robust evaluation methods that thoroughly assess negative transfer across diverse settings and datasets. Domain adaptation techniques, such as feature mapping or alignment, are also crucial to bridge the gap between the feature spaces of source and target domains and prevent negative transfer. Furthermore, understanding the root causes of negative transfer, whether due to inherent domain differences or noisy data, is essential for developing targeted mitigation strategies.
Amazon Dataset Results#
Analyzing the Amazon dataset results section of a research paper requires a nuanced approach. The results should be evaluated by considering the metrics used (e.g., precision, recall, NDCG), the specific tasks addressed (e.g., top-K recommendation), and the experimental setup (e.g., data splits, baselines). A critical assessment would involve examining whether the reported improvements are statistically significant and if the chosen metrics appropriately capture the performance of the model. Furthermore, the paper should discuss the limitations of the study, including any biases in the data or limitations in the experimental design. Understanding the context of the Amazon dataset, its characteristics, and how it’s commonly used in the recommender systems research community is crucial for properly interpreting the findings. Close attention should be paid to the qualitative analysis, if provided, to see whether the model’s recommendations make practical sense in the context of the Amazon products. Finally, assessing how the results compare to those of previous studies using the same dataset can help to determine the novelty and significance of the work. Overall, a thorough evaluation requires a combination of quantitative and qualitative analysis, along with a strong understanding of the research area.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the framework to handle more complex data types beyond ratings, such as text reviews or images, would significantly broaden its applicability. Investigating the impact of different graph structures and incorporating more sophisticated graph neural networks to improve knowledge transfer are also important. A thorough investigation into the trade-off between privacy and model performance with varying levels of differential privacy is crucial. Finally, applying the federated graph learning approach to other recommendation scenarios, like session-based or sequential recommendations, would demonstrate its broader utility and robustness. These advancements could unlock more comprehensive, accurate, and privacy-preserving recommendation systems.
More visual insights#
More on figures

🔼 This figure illustrates the challenges in broader source cross-domain recommendation (BS-CDR). (a) shows how incorporating knowledge from multiple source domains can lead to negative transfer if privacy-preserving methods result in low-quality data. (b) shows that while positive knowledge transfer initially improves performance, the accumulation of negative transfer from multiple domains eventually reduces performance below that of a single-domain model.
read the caption
Figure 1: (a) In order to obtain accurate recommendations in the Books domain, we aim to exploit user preferences (i.e., knowledge of external domains should be fully utilized, e.g. Movie, Toys, and Games domains). However, with the influence of lossy privacy-preserving techniques, the results of the transfer could be negative (e.g., the Music domain with low-quality data). (b) There is a diminishing marginal effect on the growth rate of the model performance with pure positive knowledge, while NT accumulates with an increasing number of source domains. Consequently, the performance of existing methods declines and is worse than that of a single domain model.

🔼 This figure illustrates the FedGCDR framework, detailing its three stages: horizontal source domain training, vertical positive knowledge transfer, and horizontal positive knowledge activation. Each stage utilizes federated learning and graph attention networks (GATs). The positive knowledge transfer module uses differential privacy for security. The positive knowledge activation module filters out negative knowledge and improves model accuracy by expanding the target domain graph.
read the caption
Figure 2: An overview of FedGCDR. It consists of two key modules and follows a HVH pipeline: (1) Source Domain Training (Horizontal FL): 1 Each source domain maintains its graph attention network (GAT)-based federated model. (2) Positive Knowledge Transfer Module (Vertical FL): 2 Source domain embeddings are extracted from GAT layers and perturbed with Gaussian noise. 3 The multilayer perceptron aligns the feature space of source domain embeddings and target domain embeddings. (3) Positive Knowledge Activation Module (Horizontal FL): ④ Local graph is expanded with source domain embeddings. 5 Enhanced federated training of the target domain is achieved through the expanded graph. ⑥ The target domain maintains its GAT-based federated model. The target domain freezes the GAT layer and fine tunes the model.
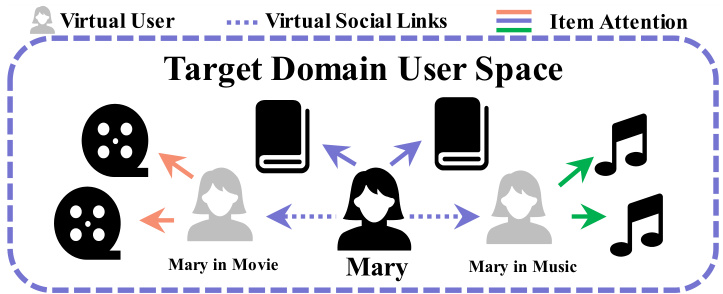
🔼 This figure illustrates how the target domain’s graph is expanded by incorporating virtual users and virtual social links. The virtual users represent the same real user from different source domains (Movie and Music in this example). These links create domain-specific attentions, allowing the model to focus on the most relevant source domain knowledge for better recommendation accuracy in the target domain.
read the caption
Figure 3: Illustration of target domain graph expansion. The virtual users are constructed with the source domain embeddings from the Movie domain and the Music domain. The attentions generated by social links to the virtual user can be regarded as the domain attentions.

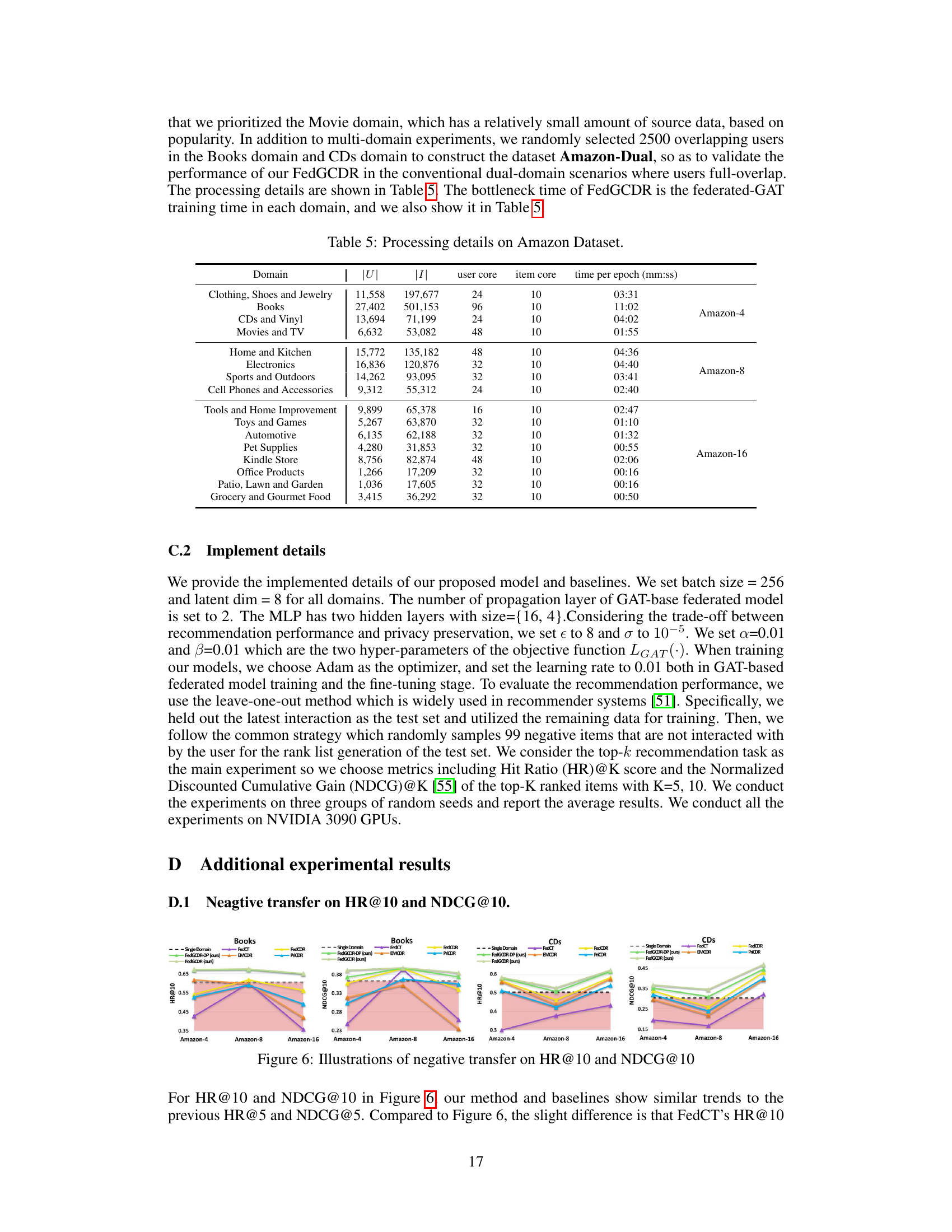
🔼 This figure shows the negative transfer effect on HR@5 and NDCG@5, comparing the performance of FedGCDR with baselines across different numbers of domains in the Amazon dataset. The red shaded area highlights cases where multi-domain models perform worse than single-domain models, illustrating the negative impact of transferring knowledge from less relevant domains. The HR@10 and NDCG@10 results, showing similar trends, are provided in the appendix.
read the caption
Figure 4: Illustrations of negative transfer on HR@5 and NDCG@5. Metric values lower than single-domain (dotted line and red area) mean severe negative soft transfer. The figure on HR@10 and NDCG@10 is shown in Appendix D.1.

🔼 This ablation study on Amazon-16 datasets (CDs and Books as target domains) compares the performance of FedGCDR with two variants: FedGCDR-M (missing the attention graph expansion and target domain fine-tuning) and FedGCDR-T (missing the feature mapping). The results demonstrate the importance of both the positive knowledge transfer module and the positive knowledge activation module in achieving superior recommendation performance (HR@5, HR@10, NDCG@5, NDCG@10).
read the caption
Figure 5: Ablation study on Amazon-16@CDs and Amazon-16@Books.

🔼 This figure shows the performance of different models on two metrics (HR@5 and NDCG@5) across three different datasets (Amazon-4, Amazon-8, and Amazon-16) for two target domains (Books and CDs). The dotted black line represents the performance of a single-domain model (without cross-domain transfer), serving as a baseline. The red shaded area highlights cases where the multi-domain models perform worse than the single-domain baseline, indicating negative transfer. The chart visually demonstrates the impact of the number of source domains on the effectiveness of cross-domain recommendation, illustrating how the accumulation of negative knowledge from multiple sources can harm the model’s performance.
read the caption
Figure 4: Illustrations of negative transfer in HR@5 and NDCG@5. Metric values lower than single-domain (dotted line and red area) mean severe negative soft transfer. The figure on HR@10 and NDCG@10 is shown in Appendix D.1.

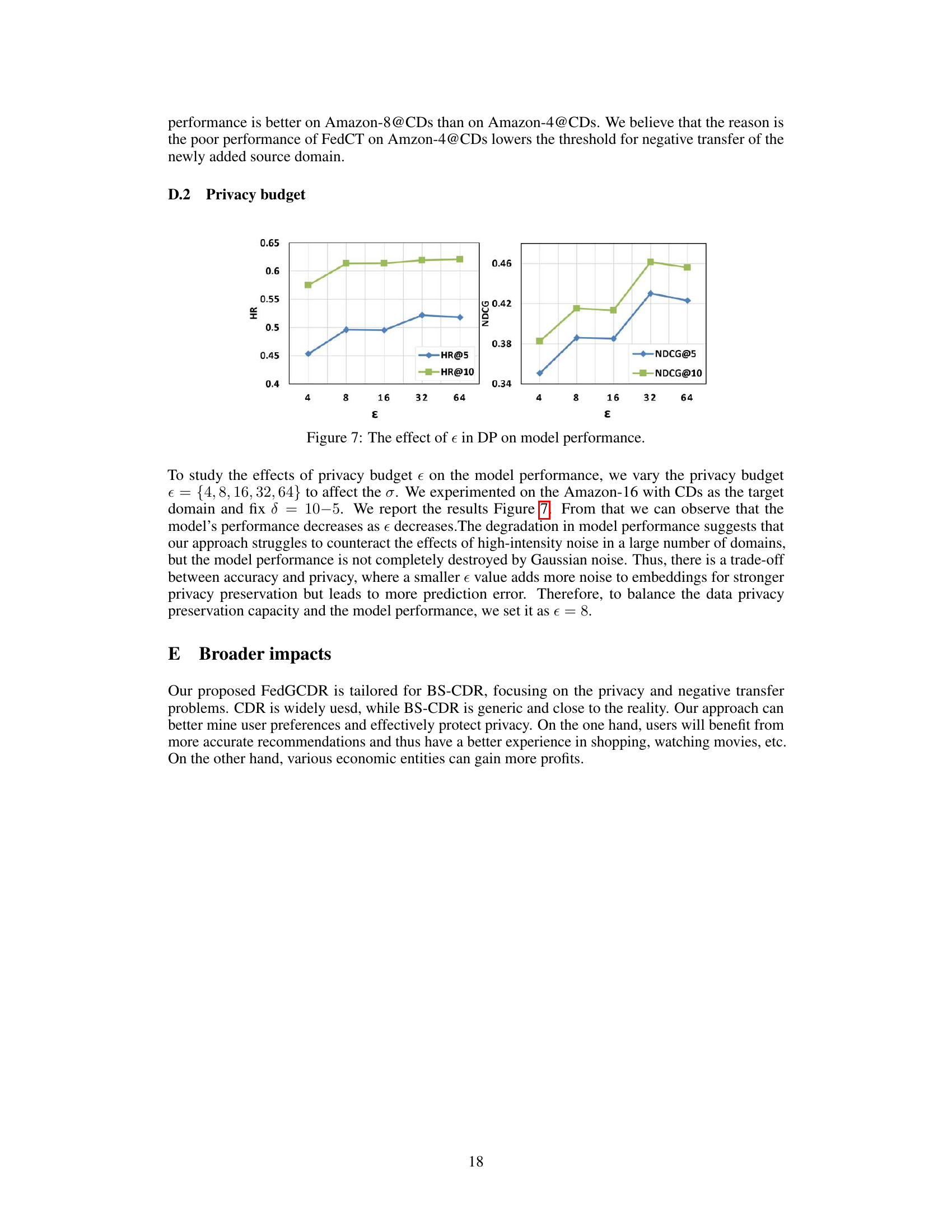
🔼 This figure shows the impact of the privacy budget (ε) on the model’s performance in terms of HR@5, HR@10, NDCG@5, and NDCG@10. The x-axis represents the privacy budget (ε), and the y-axis represents the performance metrics. The results demonstrate a trade-off between privacy and accuracy; as ε decreases (stronger privacy), performance diminishes. This indicates that the level of noise added to protect privacy affects the model’s ability to learn accurate recommendations.
read the caption
Figure 7: The effect of ε in DP on model performance.
More on tables

🔼 This table presents the recommendation performance on the Amazon Books dataset for different models, including the proposed FedGCDR and several baselines. It shows HR@5, NDCG@5, HR@10, and NDCG@10 metrics across three different experimental settings (Amazon-4, Amazon-8, Amazon-16), representing varying numbers of source domains used in the cross-domain recommendation task. The best performance for each metric is highlighted in bold, while the second best is underlined. The results show how the proposed method compares against different baselines under various conditions.
read the caption
Table 2: The recommendation performance on Amazon@Books. Single Domain represents FedGNN and its performance is exactly the same on three sub-datasets. FedGCDR-DP is a complete implementation of our method while FedGCDR does not incorporate Gaussian noise. (The best result for the same setting is marked in bold and the second best is underlined. These notes are the same to others.)
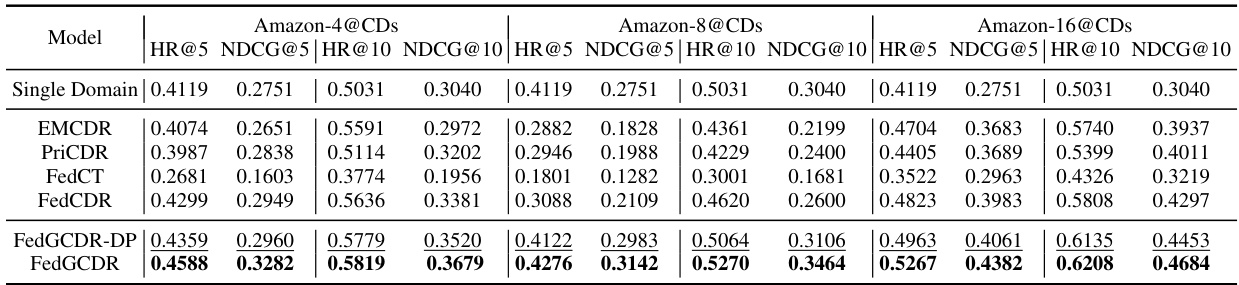
🔼 This table presents the recommendation performance results on the Amazon Books dataset for different models. It compares the performance of FedGCDR (with and without differential privacy) against several baseline models (EMCDR, PriCDR, FedCT, FedCDR, and Single Domain). The metrics used are HR@5, NDCG@5, HR@10, and NDCG@10, evaluated across three different dataset sizes (Amazon-4, Amazon-8, Amazon-16). The best results for each metric and dataset size are highlighted in bold, with the second-best underlined.
read the caption
Table 2: The recommendation performance on Amazon@Books. Single Domain represents FedGNN and its performance is exactly the same on three sub-datasets. FedGCDR-DP is a complete implementation of our method while FedGCDR does not incorporate Gaussian noise. (The best result for the same setting is marked in bold and the second best is underlined. These notes are the same to others.)

🔼 This table presents the performance of different cross-domain recommendation (CDR) models in a dual-domain setting. The models are evaluated using two metrics, HR@10 (Hit Ratio at 10) and NDCG@10 (Normalized Discounted Cumulative Gain at 10), for two scenarios: where the knowledge is transferred from the Books domain to the CDs domain and vice versa. The results show the effectiveness of the proposed model FedGCDR in improving recommendation accuracy compared to the baseline methods.
read the caption
Table 4: Dual-domain CDR performance.

🔼 This table presents the statistics of the Amazon dataset used in the experiments. It shows the minimum, median, and maximum values for the number of users (|Ua|), the number of items (|Ia|), and the number of ratings (Rd) for four different subsets of the Amazon dataset: Amazon-4, Amazon-8, Amazon-16, and Amazon-Dual. The Amazon-Dual dataset is a subset with only two domains (Books and CDs) and 2500 overlapping users. The table also includes the average sparsity of each dataset, indicating the percentage of user-item pairs with observed ratings.
read the caption
Table 1: Statistics on the Amazon Dataset. (min-median-max) values are provided for |Ua|, |Ia| and Rd.
Full paper#