↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Consistency models offer a fast alternative to slow diffusion models for image generation, but their image quality is usually lower. This paper addresses this issue by proposing a post-processing method, overcoming the slowness of diffusion models while maintaining relatively simple training. This is achieved by directly mapping noise to data.
The proposed method uses a joint classifier-discriminator model trained adversarially. The classifier grades images based on class assignment, while the discriminator, leveraging softmax values, assesses image proximity to the target data manifold, essentially functioning as an energy-based model. Example-specific projected gradient iterations refine the synthesized images, leading to substantially improved FID (Fréchet Inception Distance) scores on the ImageNet 64x64 dataset for both consistency training and distillation techniques.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves the quality of images generated by consistency models, a fast and efficient alternative to diffusion models. The proposed method enhances image fidelity without requiring extensive retraining, opening new avenues for research in efficient image synthesis and post-processing techniques. This work directly addresses a major limitation of consistency models, contributing to faster and higher-quality image generation.
Visual Insights#

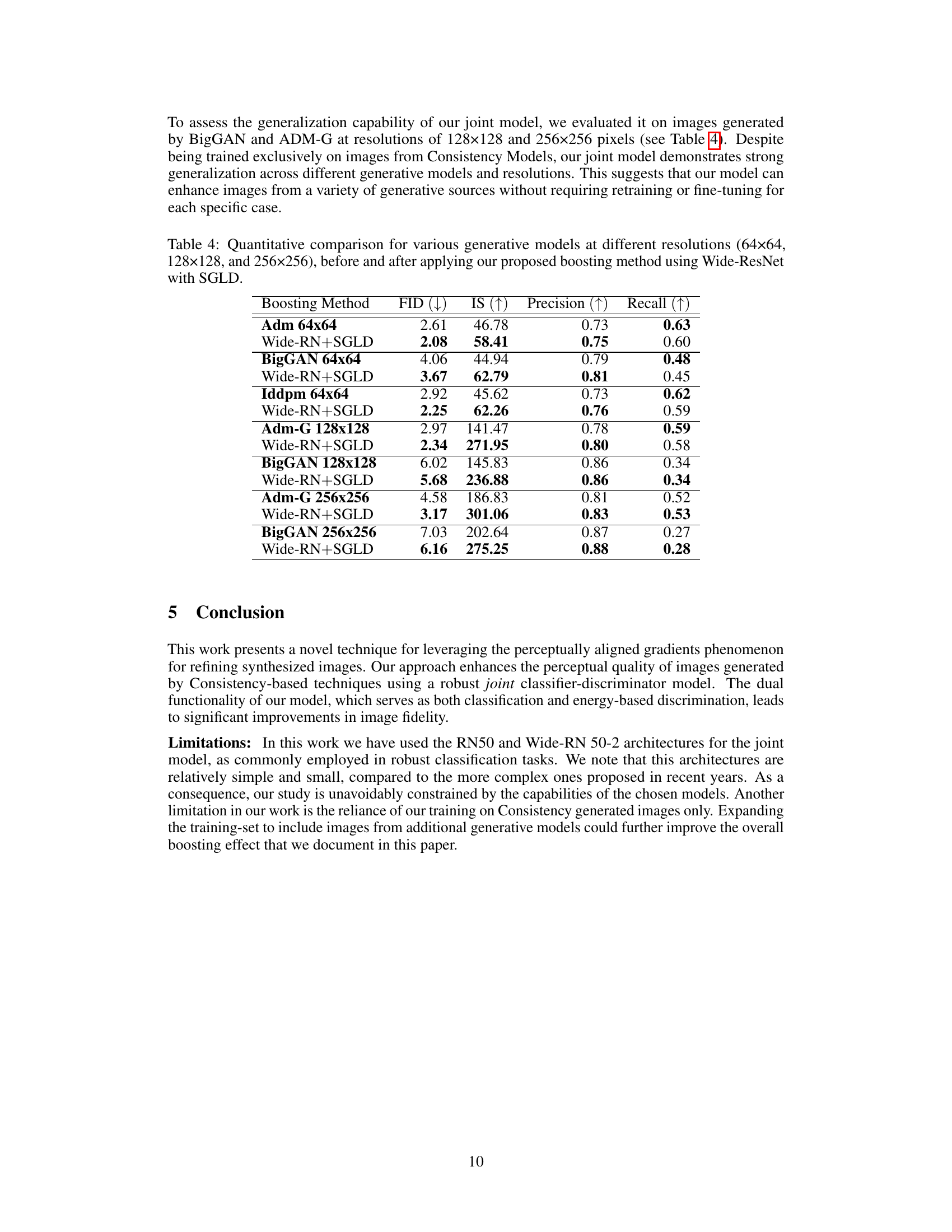
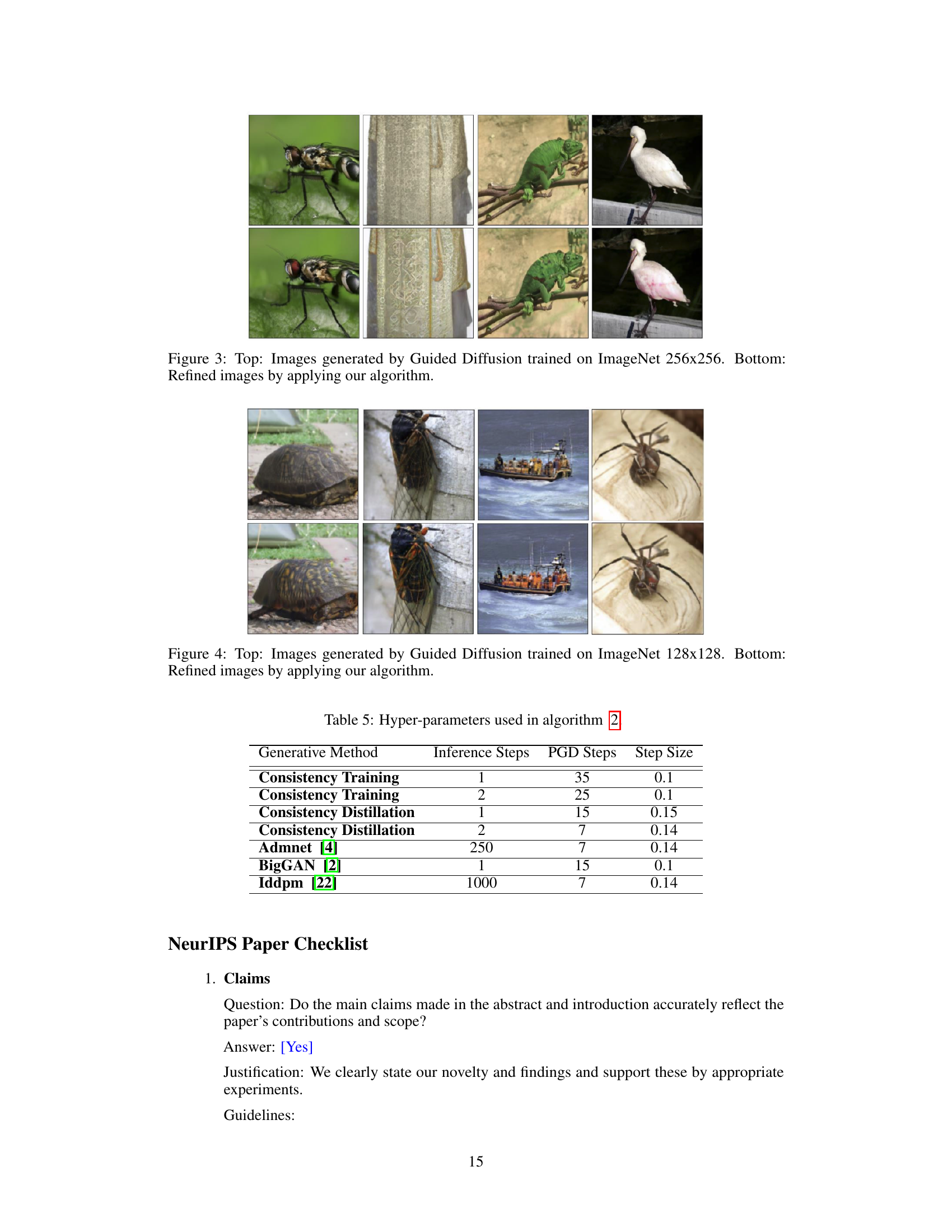
This figure shows a comparison of images generated by Consistency Models and the same images after being processed by the algorithm proposed in the paper. The top row displays original images generated by the Consistency Models, exhibiting some artifacts and lack of fine detail. The bottom row presents the refined images which have improved visual quality, exhibiting sharper details and more realistic textures. This visual improvement demonstrates the effectiveness of the proposed post-processing technique.

This table presents a quantitative comparison of image generation performance using different methods on the ImageNet 64x64 dataset. It compares the Fréchet Inception Distance (FID), Inception Score (IS), precision, and recall achieved by several methods. These methods include Consistency Training (CT) and Consistency Distillation (CD) with different network architectures (RN50 and Wide-RN), and the use of robust classifiers and a joint classifier-discriminator. The table shows the results for both one and two inference steps, highlighting the impact of the proposed boosting method.
In-depth insights#
Consistency Boost#
A hypothetical “Consistency Boost” section in a research paper would likely explore methods for improving the quality and stability of image generation models based on the consistency principle. This might involve techniques to enhance the model’s ability to generate consistent outputs across multiple runs or variations in the input. Adversarial training could play a key role, using a discriminator to identify inconsistencies and guide the generator toward higher-quality, more consistent images. The section would likely detail specific strategies employed, including the types of losses used (e.g., adversarial loss, consistency loss), network architectures, and training procedures. It would be crucial to evaluate the effectiveness of the proposed method using appropriate metrics, potentially including FID and Inception Scores to assess image quality and diversity. The results would then be thoroughly discussed, highlighting both strengths and limitations, especially concerning the trade-off between consistency, quality, and computational cost. The analysis might also address the generalizability of the approach to various model architectures and data distributions, ultimately contributing to a deeper understanding of how to optimize consistency-based image generation.
Adversarial Training#
Adversarial training, a core concept in enhancing model robustness, is thoughtfully explored in this research. The approach cleverly leverages the power of adversarial examples, forcing the model to learn features that are less susceptible to malicious manipulation. This is achieved by training the model not only on genuine data but also on slightly altered (adversarial) versions. This strategy improves the model’s ability to generalize and resist attacks. The method’s effectiveness is meticulously investigated through rigorous experimentation, demonstrating significant performance improvements in terms of fidelity and perceptual quality. Furthermore, the choice of adversarial attack strategy and the careful balance between adversarial and clean data training are detailed. The researchers emphasize the importance of this delicate balance for attaining optimal performance. The study’s contribution extends beyond specific applications, offering valuable insights into robust model training strategies. The paper effectively highlights the multifaceted nature of adversarial training, underscoring its significance in building more resilient and reliable models.
Energy-Based Models#
Energy-based models (EBMs) offer a flexible and powerful framework for density estimation and generative modeling. Their core idea is to define a probability distribution implicitly through an energy function, assigning lower energy values to more probable data points. This approach avoids the explicit modeling of the probability density, which can be challenging for high-dimensional data. EBMs are particularly appealing for complex distributions where other methods struggle, such as those encountered in image generation. However, training EBMs presents unique challenges. The partition function, a normalization constant required for probability calculation, is often intractable to compute directly, making training and inference more complex. Therefore, efficient methods such as Markov Chain Monte Carlo (MCMC) or stochastic gradient Langevin dynamics (SGLD) are often employed for sampling from the model, but these methods can be computationally intensive. Despite these challenges, EBMs continue to be an active area of research, with ongoing work focusing on improving training efficiency and exploring connections with other generative models like diffusion models and GANs. The ability to model complex, high-dimensional data, and the flexibility in defining the energy function, makes EBMs a valuable tool in various applications, including image synthesis, natural language processing, and beyond.
FID Score Enhance#
An analysis of a hypothetical research paper section titled “FID Score Enhance” would delve into the methods used to improve the Fréchet Inception Distance (FID) score, a metric evaluating the quality of generated images by comparing them to real images. A lower FID score indicates better image generation quality. The paper might explore techniques such as adversarial training, using a discriminator to differentiate between real and generated images, thereby pushing the generator to produce more realistic outputs. Post-processing methods like enhancing image features or applying subtle transformations to align generated images with the characteristics of real images might also be discussed. The research likely examines different architectural modifications to generative models, such as incorporating attention mechanisms or improving the training stability of the model, ultimately leading to FID score improvements. Evaluation of the enhancements would include detailed quantitative analyses of FID scores, alongside qualitative assessments of image realism and diversity, potentially including perceptual studies involving human subjects. The study may also compare results against other state-of-the-art generative models, highlighting any significant performance gains. The discussion might address any limitations, such as computational cost or the inherent difficulty of completely closing the gap between real and generated images. Overall, “FID Score Enhance” would present a comprehensive exploration of strategies to enhance image generation quality, offering valuable insights for researchers and practitioners in the field.
Future Directions#
Future research could explore improving the efficiency of the proposed post-processing technique. The current approach involves iterative refinement, which could be computationally expensive for high-resolution images. Investigating alternative optimization strategies or more efficient network architectures could significantly enhance its practicality. Another promising direction is expanding the scope beyond consistency models. The core methodology of leveraging perceptually aligned gradients could be generalized to other generative models, potentially improving their image quality and diversity. Furthermore, robustness to different types of generative models should be tested. While the current work shows promise across multiple models, a thorough investigation of the technique’s effectiveness with a broader range of GANs and diffusion models could be valuable. Finally, exploring the potential for direct integration of the adversarial training within the generative model itself during training, rather than as a post-processing step, is worth exploring. This approach could lead to a more efficient and seamless integration of the classifier-discriminator, potentially resulting in even higher-quality generated images. In addition to model improvement, applications in other domains should be considered. The ability to refine images could be beneficial in various fields such as medical image analysis, satellite imagery processing, and artistic image creation.
More visual insights#
More on figures

This figure shows a comparison of images generated by Consistency Models before and after applying the proposed image refinement algorithm. The top row displays the original generated images, while the bottom row shows the same images after undergoing the algorithm’s post-processing step. The goal of the algorithm is to enhance the realism and visual appeal of the generated images, making them more similar to real images from the ImageNet 64x64 dataset. The visual difference highlights the improvements achieved by the algorithm, such as increased sharpness, better texture details, and more natural colors. Each pair of images showcases the refinement applied to a specific image.

This figure shows four pairs of images. Each pair presents an image generated using a Consistency Model trained on the ImageNet 64x64 dataset (top) and the same image after being processed by the algorithm proposed in the paper (bottom). The algorithm aims to refine the generated image, improving its quality and realism. By comparing the top and bottom images in each pair, one can visually assess the effectiveness of the proposed refinement technique. The differences are subtle but noticeable; the refined images exhibit improved texture, sharpness, and overall visual quality.

This figure shows four pairs of images. Each pair consists of an image generated by a consistency model and a refined version of the same image after applying the proposed algorithm. The top row displays the original images, while the bottom row presents their refined counterparts. The improvements in image quality are evident in the refined images, which exhibit enhanced details, sharper edges, and more realistic textures.
More on tables

This table presents a quantitative comparison of image generation performance using different methods on the ImageNet 64x64 dataset. It compares the Fréchet Inception Distance (FID), Inception Score (IS), precision, and recall achieved by Consistency Training (CT) and Consistency Distillation (CD) models, both with and without the proposed boosting method. The boosting method uses either a robust classifier or a joint classifier-discriminator model, and the results are shown for both one and two inference steps. Lower FID scores and higher IS, precision, and recall values indicate better image quality.
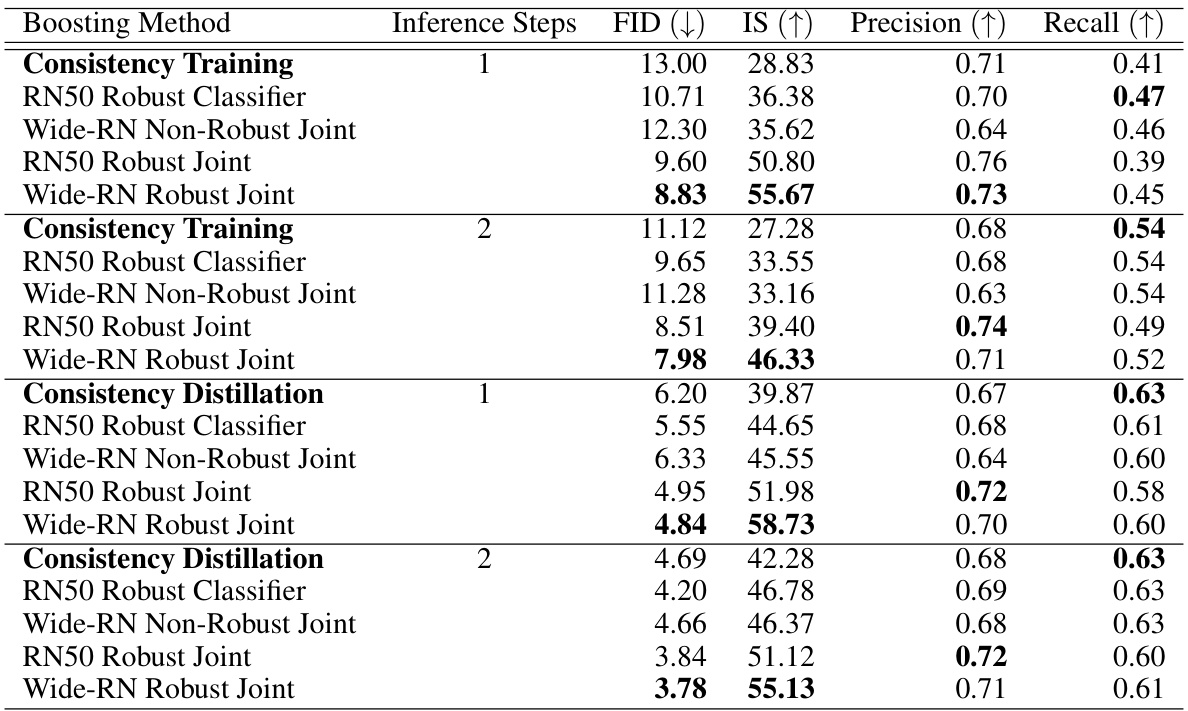
This table presents a quantitative comparison of image generation performance using various methods on the ImageNet 64x64 dataset. It compares the Fréchet Inception Distance (FID), Inception Score (IS), Precision, and Recall metrics for different models and boosting techniques. The models include those based on Consistency Training (CT) and Consistency Distillation (CD), using either one or two inference steps. Boosting methods are applied using robust classifiers and joint classifier-discriminator models. Lower FID scores and higher IS scores, Precision, and Recall values indicate better performance.
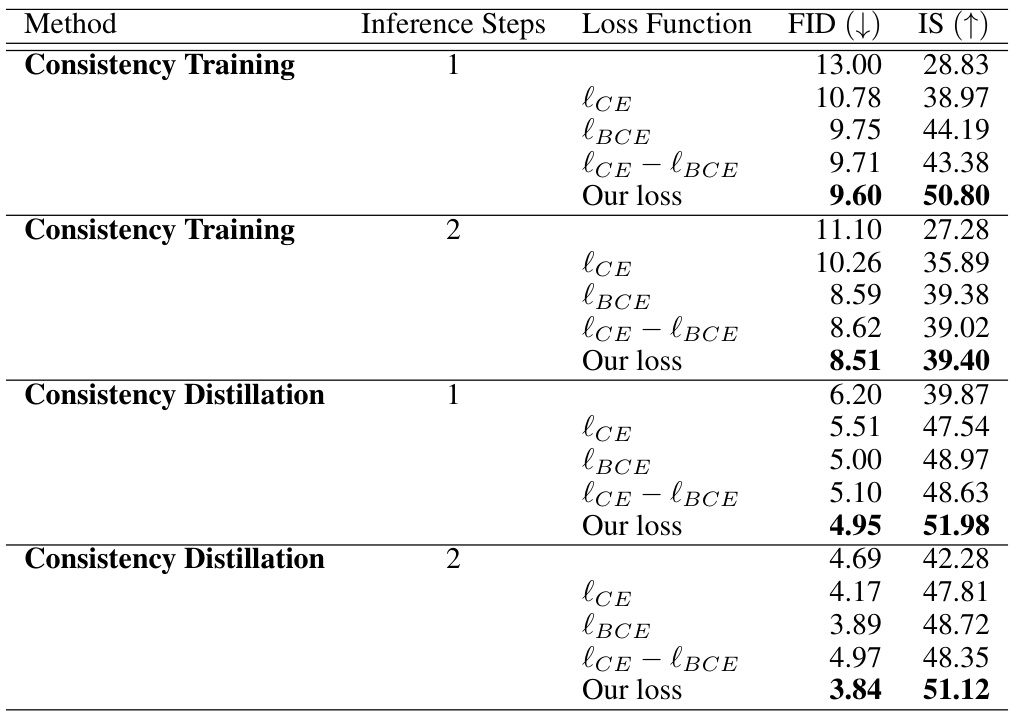
This table presents the Fréchet Inception Distance (FID) and Inception Score (IS) results for different loss functions used in the proposed model. The results are shown for both Consistency Training (CT) and Consistency Distillation (CD) methods, with 1 and 2 inference steps. The loss functions compared include cross-entropy loss (ICE), binary cross-entropy loss (IBCE), a combined cross-entropy and binary cross-entropy loss (ICE - IBCE), and the authors’ proposed loss function. Lower FID scores and higher IS scores indicate better image quality. This table demonstrates the impact of the loss function choice on model performance.

This table presents a quantitative comparison of image generation performance using different methods on the ImageNet 64x64 dataset. It compares the Fréchet Inception Distance (FID), Inception Score (IS), Precision, and Recall achieved by Consistency Training (CT) and Consistency Distillation (CD) models, both with and without the proposed boosting technique using robust classifiers and a joint classifier-discriminator model. The results show improvements across various metrics when using the proposed method, especially in the FID and IS scores.
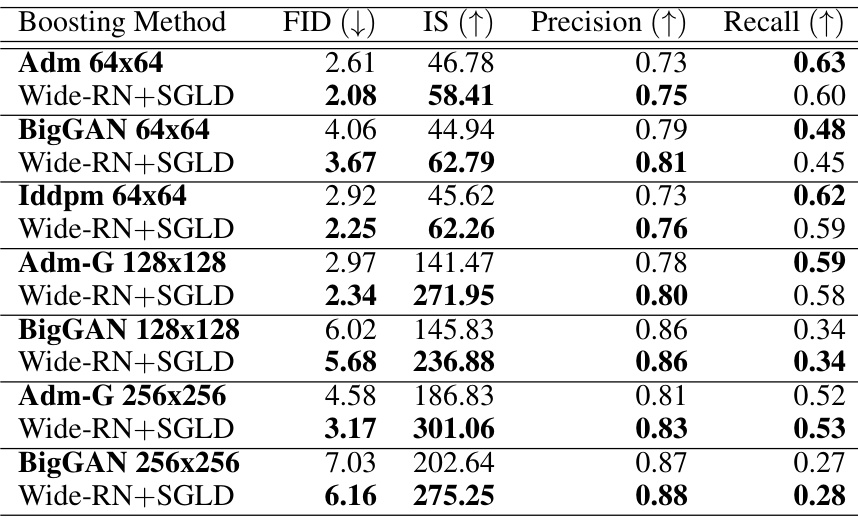
This table presents a quantitative comparison of image generation performance using FID (Fréchet Inception Distance), IS (Inception Score), precision, and recall. It compares the performance of various methods on the ImageNet 64x64 dataset. The methods include different Consistency Training (CT) and Consistency Distillation (CD) approaches, both with and without the proposed boosting techniques using robust classifiers and a joint classifier-discriminator model. The table shows FID and IS scores for different models with 1 and 2 inference steps. Lower FID scores and higher IS scores indicate better image generation quality.

This table presents a quantitative comparison of image generation performance using different methods on the ImageNet 64x64 dataset. It compares the Fréchet Inception Distance (FID), Inception Score (IS), Precision, and Recall achieved by several models. Specifically, it showcases the performance of Consistency Training (CT) and Consistency Distillation (CD) models, both with and without the proposed boosting method using robust classifiers and joint classifier-discriminator models, and using different inference steps. Lower FID scores and higher IS scores indicate better image generation quality.
Full paper#