TL;DR#
Existing video restoration methods often struggle with real-world scenarios where videos are degraded in multiple, unknown, and time-varying ways. These methods typically focus on addressing single, known degradation types, hence are inefficient in handling the complexity of real-world video degradation. This limitation makes them less applicable in practical settings. The paper highlights this critical limitation as a challenge that needed addressing.
To overcome this, the researchers propose AverNet, an all-in-one video restoration network. AverNet uses two core modules: Prompt-Guided Alignment (PGA) to align frames despite pixel shifts caused by TUD, and Prompt-Conditioned Enhancement (PCE) to restore videos despite multiple unknown degradations. Extensive testing on synthesized datasets shows AverNet significantly outperforms existing methods in restoring videos affected by TUD, demonstrating its effectiveness and robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the largely ignored problem of time-varying unknown degradations (TUD) in video restoration. It introduces AverNet, a novel solution that demonstrates significant improvement over existing methods. This opens up exciting new avenues in video processing and related fields and provides a robust, more practical solution than existing all-in-one approaches, paving the way for advancements in various applications like film restoration, surveillance video enhancement, and medical imaging. Its efficiency also suggests potential for real-time applications.
Visual Insights#

🔼 This figure compares two approaches to video restoration: classic and all-in-one. The classic approach uses a separate model for each known degradation type. In contrast, the all-in-one approach uses a single unified model to handle multiple unknown degradation types, especially those that change over time (time-varying unknown degradations or TUD). The all-in-one approach is presented as more practical and challenging.
read the caption
Figure 1: Illustration of classic and all-in-one video restoration. (a) aims to develop a specific model for each degradation to handle the corrupted video, assuming that the degradation types and levels are the same and known for all frames. In contrast, (b) intends to handle videos containing time-varying unknown degradations through a unified model, which is more practical and challenging.

🔼 This table compares the number of parameters and runtime of AverNet with several other state-of-the-art video and image restoration methods. It highlights that AverNet achieves comparable or better performance with significantly fewer parameters and faster runtime than most of the other All-in-One Image Restoration (AIR) methods, demonstrating its efficiency.
read the caption
Table 1: Comparisons on parameters and runtime. From the table, one could observe that our method is more efficient than most AIR methods.
In-depth insights#
AverNet’s Core Modules#
AverNet’s architecture hinges on two core modules: Prompt-Guided Alignment (PGA) and Prompt-Conditioned Enhancement (PCE), synergistically addressing the challenges of time-varying unknown degradations (TUD) in video restoration. PGA tackles the pixel-level misalignment caused by TUD through prompt-based frame alignment, leveraging learned prompts to guide the alignment process and improve accuracy compared to traditional optical flow methods. PCE addresses the issue of multiple unknown degradations by framing the restoration task as a conditional problem, using prompts to implicitly establish a mapping between degraded and ground truth frames. This conditional approach allows the network to handle diverse and unpredictable degradation types effectively. The combined power of PGA and PCE enables AverNet to achieve superior performance in restoring videos affected by TUD, showcasing a significant advance in robust and versatile video restoration.
TUD Challenge#
The TUD (Time-varying Unknown Degradation) challenge highlights a critical limitation in traditional video restoration methods. These methods typically assume that a video’s degradations remain consistent throughout, enabling the design of specific models for known degradation types. However, real-world videos rarely maintain this consistency; degradations often change over time, introducing noise, blur, compression artifacts, or other distortions that vary in type and intensity across frames. This variability makes it challenging to apply traditional methods effectively. The TUD challenge, therefore, emphasizes the need for robust and adaptable restoration techniques capable of handling diverse and dynamic degradations, calling for innovative approaches that can learn the changing nature of the degradation over time and adapt their restoration strategies accordingly. AverNet, as presented in the paper, addresses this challenge by incorporating mechanisms for temporal alignment and handling multiple degradations simultaneously, representing a significant advancement in video restoration capabilities.
AVR Framework#
An All-in-one Video Restoration (AVR) framework presents a significant advancement in video processing. Its core strength lies in handling time-varying, unknown degradations, a challenge traditional methods often struggle with. This is achieved through a unified model, avoiding the need for separate models for different degradation types. Key components like Prompt-Guided Alignment (PGA) for pixel-level frame alignment and Prompt-Conditioned Enhancement (PCE) for multi-degradation handling are crucial. The framework’s effectiveness hinges on its ability to learn and utilize prompts, implicitly mapping degradations to ground truths, thereby enabling robust restoration even under complex and changing degradation scenarios. While the use of synthesized data for training raises concerns about real-world generalizability, the architecture’s novel approach to temporal and spatial consistency in video restoration is a notable contribution. Future work could focus on evaluating performance with real-world, diverse video data and exploring the limitations of the prompt-based approach.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a video restoration model, this might involve removing modules responsible for temporal alignment, noise reduction, or artifact correction. By observing the impact of each removal on performance metrics (e.g., PSNR, SSIM), researchers can determine which components are essential and which are redundant. A well-designed ablation study isolates the effects of individual modules, ruling out confounding factors and providing a clear picture of their relative importance. The results highlight the effectiveness of each component and guide future model improvements. A comprehensive ablation study is crucial for building reliable and efficient models, as it offers a deeper understanding beyond simply reporting overall performance. It enables researchers to focus on enhancing key aspects, optimizing resource allocation, and potentially simplifying the model architecture while maintaining or even improving performance.
Future of AverNet#
The future of AverNet hinges on addressing its limitations and expanding its capabilities. Improving robustness to a wider variety of time-varying degradations is crucial, moving beyond the seven types tested. This would involve incorporating more diverse and realistic degradation models, perhaps even learning degradation representations directly from real-world video data. Improving efficiency is another key area. While AverNet is already more efficient than many comparable methods, further optimization, such as exploring more efficient network architectures or pruning techniques, would enhance its real-world applicability, especially for high-resolution or long videos. Finally, extending AverNet to handle different video formats and resolutions would make it a truly versatile solution. This would require significant architectural modifications and potentially retraining on a much larger, more diverse dataset. Future research could also explore the integration of AverNet with other video processing tasks, creating a comprehensive all-in-one video processing pipeline.
More visual insights#
More on figures

🔼 This figure shows how time-varying degradations affect pixel alignment in video frames. The optical flow (movement of pixels between frames) is calculated for clean frames, noisy frames with static degradations, and noisy frames with dynamic degradations. The arrows represent the calculated optical flow vectors. The results show that time-varying degradations result in a larger and more complex pixel shift compared to time-invariant degradations. This highlights the difficulty of aligning frames with dynamic degradation, making it a significant challenge for video restoration.
read the caption
Figure 2: Illustration of the pixel shift issue. We compute the optical flow between two consecutive frames with time-invariant and time-varying degradations. Several directional vectors are visualized as red arrows to indicate the estimated pixel alignments between the two frames. One could observe that time-varying degradations lead to less accurate estimations compared to time-invariant degradations, causing a larger and more complex pixel shift after alignment.
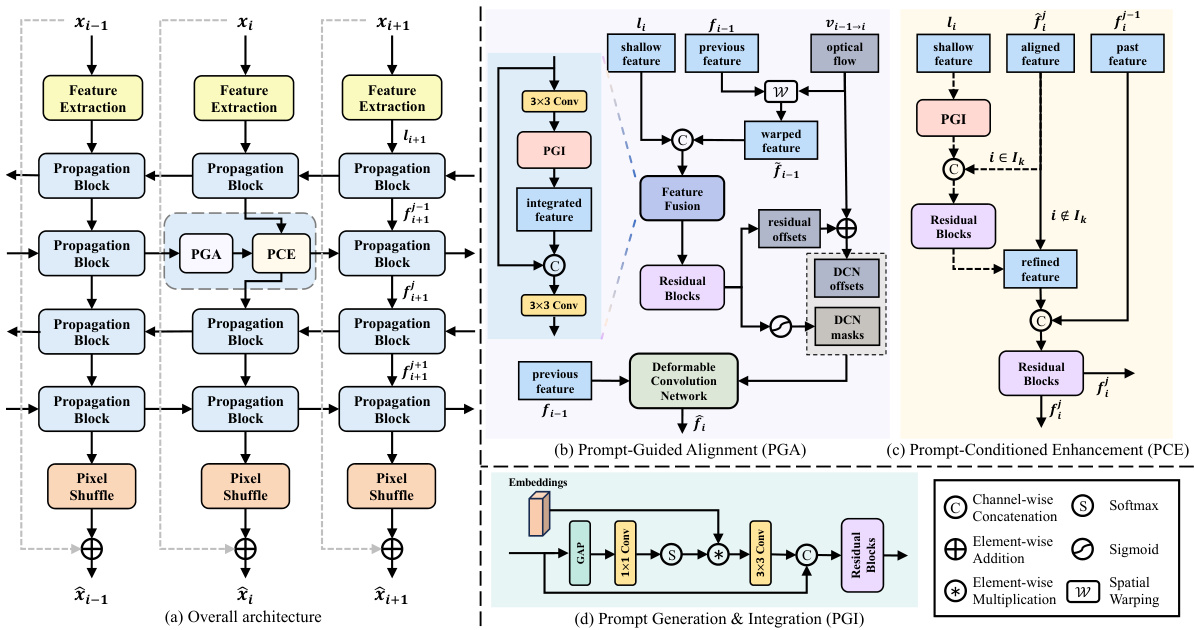
🔼 This figure presents the overall architecture of AverNet, which is composed of propagation blocks. Each block includes two core modules: Prompt-Guided Alignment (PGA) and Prompt-Conditioned Enhancement (PCE). The PGA module aligns features across frames affected by time-varying degradations using prompt-guided deformable convolutions. The PCE module enhances features of the current frame with unknown degradations, also using prompts. A Prompt Generation & Integration (PGI) module generates and integrates input-conditioned prompts to guide both PGA and PCE.
read the caption
Figure 3: Architecture overview. (a) Overall architecture of our AverNet, which is mainly composed of propagation blocks. Each block consists of a (b) PGA module for spatially aligning features across frames with time-varying degradations, and a (c) PCE module for enhancing the features of current frame with unknown degradations. (d) PGI modules endow PGA and PCE with the capacity of conditioning on degradations by means of input-conditioned prompts. For simplicity, the superscripts j in (b) are omitted. In (c), the past feature is from the last time of propagation, and Ik refers to the indices of key frames.

🔼 This figure compares the video restoration results of several methods on the ’tractor’ video from the DAVIS-test dataset, where the degradation variation interval is 12 frames. The methods include WDiffusion, TransWeather, AirNet, PromptIR, BasicVSR++, Shift-Net, RVRT, and AverNet (the proposed method). The ground truth (GT) is also shown for comparison. The figure visually demonstrates that AverNet produces significantly clearer results with fewer artifacts compared to the other methods, showing its effectiveness in recovering videos from time-varying unknown degradations.
read the caption
Figure 4: Qualitative results on the 'tractor' video from DAVIS-test (t = 12), from which one could observe that existing methods leave residual noise or artifacts in the results. In contrast, our method obtains clearer results that are closer to GT.

🔼 This figure shows a qualitative comparison of video restoration results on the ’tractor’ video from the DAVIS-test dataset, where the time-varying degradation interval is set to 12. It compares the results of several state-of-the-art methods (WDiffusion, TransWeather, AirNet, PromptIR, BasicVSR++, Shift-Net, RVRT) against the proposed AverNet and the ground truth (GT). The results highlight AverNet’s ability to produce clearer results with fewer artifacts and noise compared to the other methods, demonstrating its effectiveness in restoring videos with time-varying unknown degradations.
read the caption
Figure 4: Qualitative results on the 'tractor' video from DAVIS-test (t = 12), from which one could observe that existing methods leave residual noise or artifacts in the results. In contrast, our method obtains clearer results that are closer to GT.

🔼 This figure compares the video restoration results of different methods on the ’tractor’ video from the DAVIS-test dataset. The variation interval (t) is set to 12. The figure shows that existing methods (WDiffusion, TransWeather, AirNet, PromptIR, BasicVSR++, Shift-Net, and RVRT) produce results with noticeable artifacts and residual noise. In contrast, the proposed AverNet method achieves cleaner results that are closer to the ground truth (GT).
read the caption
Figure 4: Qualitative results on the 'tractor' video from DAVIS-test (t = 12), from which one could observe that existing methods leave residual noise or artifacts in the results. In contrast, our method obtains clearer results that are closer to GT.

🔼 This figure compares the video restoration results of different methods on the ’tractor’ video from the DAVIS-test dataset, using a time-varying degradation interval (t=12). The figure shows that existing methods like WDiffusion, TransWeather, AirNet, PromptIR, BasicVSR++, Shift-Net, and RVRT all exhibit artifacts, noise, or other issues in their restorations. In contrast, the proposed AverNet method produces a cleaner result that is much closer to the ground truth (GT). This demonstrates the effectiveness of AverNet in handling time-varying unknown degradations.
read the caption
Figure 4: Qualitative results on the 'tractor' video from DAVIS-test (t = 12), from which one could observe that existing methods leave residual noise or artifacts in the results. In contrast, our method obtains clearer results that are closer to GT.

🔼 This figure shows a comparison of video restoration results on the ‘subway’ video clip from the DAVIS-test dataset. The video was degraded with a combination of noise and blur. The results from several state-of-the-art video restoration methods are presented, alongside the ground truth. AverNet, the proposed method, provides significantly clearer and more detailed results compared to other methods.
read the caption
Figure 8: Qualitative results on the 'subway' video from DAVIS-test in the noise&blur degradation combination, from which one could observe that the results of existing methods are blurry. In contrast, the results of our method have clearer outlines and tones that are more similar to the GT.
More on tables
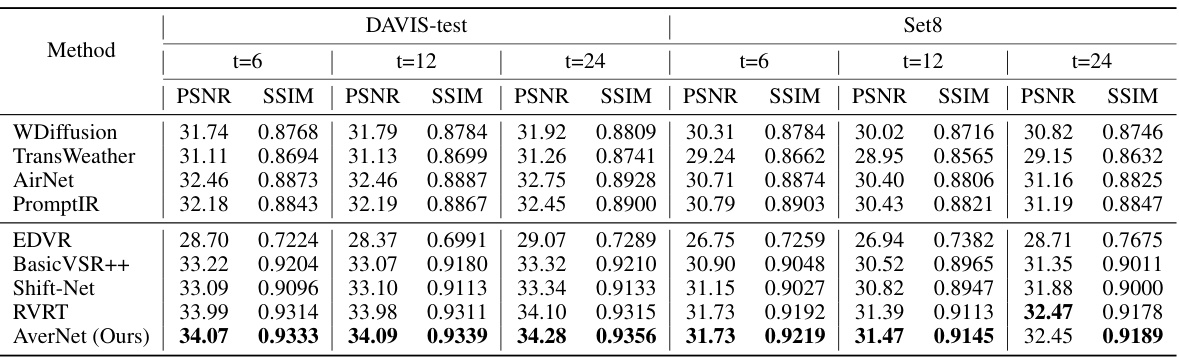
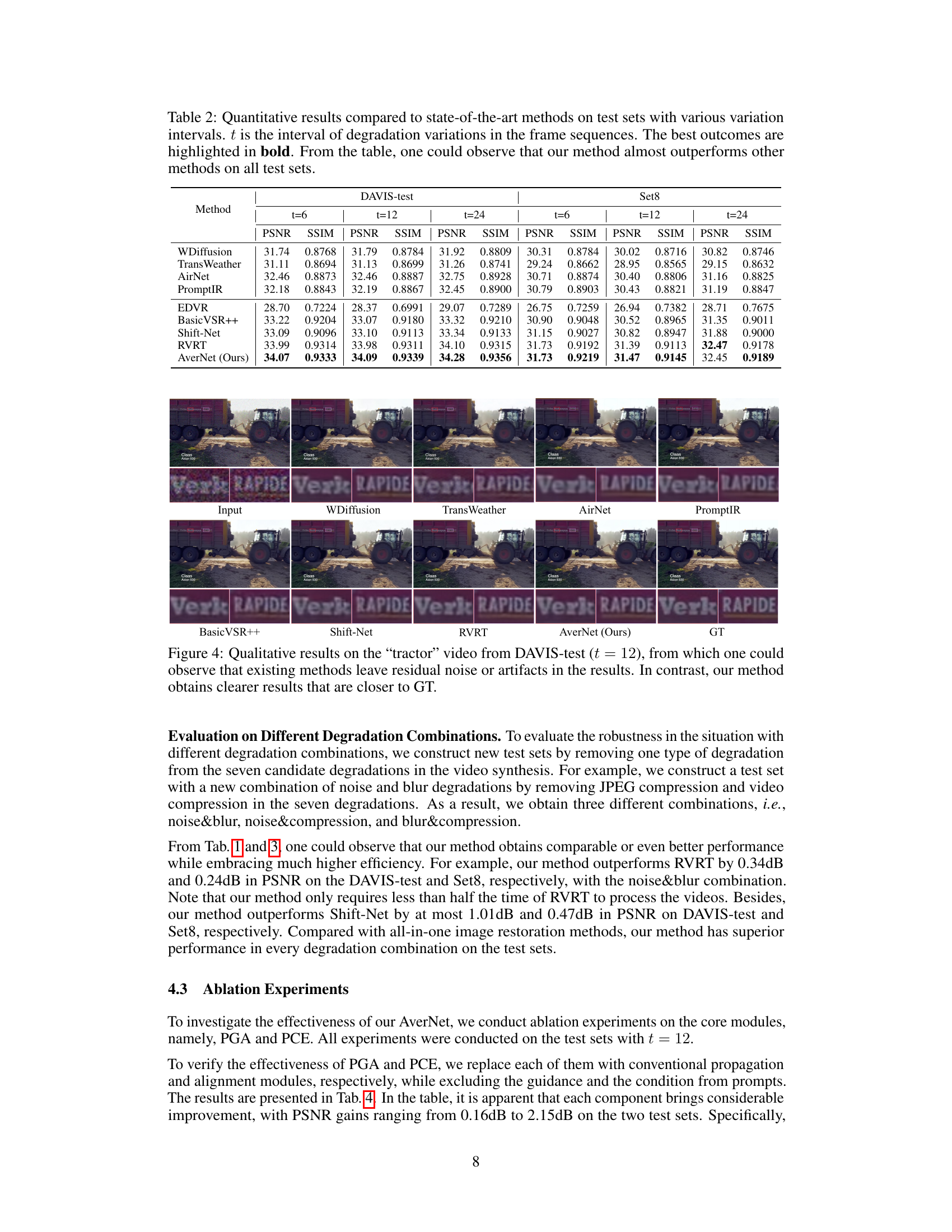
🔼 This table presents a quantitative comparison of the proposed AverNet model against several state-of-the-art video and image restoration methods. The comparison is performed on six different test sets, each characterized by a varying interval (t) of degradation variations within the video sequences. The results are reported in terms of PSNR and SSIM metrics, highlighting the superior performance of AverNet across all test sets and variation intervals.
read the caption
Table 2: Quantitative results compared to state-of-the-art methods on test sets with various variation intervals. t is the interval of degradation variations in the frame sequences. The best outcomes are highlighted in bold. From the table, one could observe that our method almost outperforms other methods on all test sets.
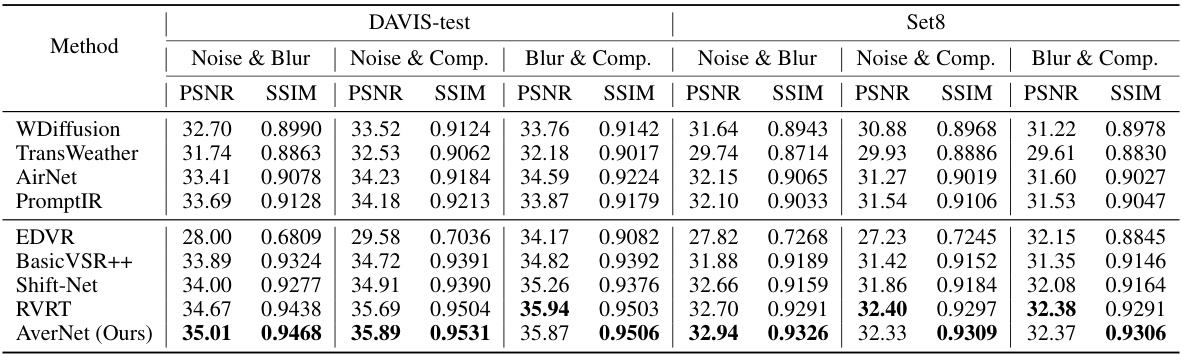
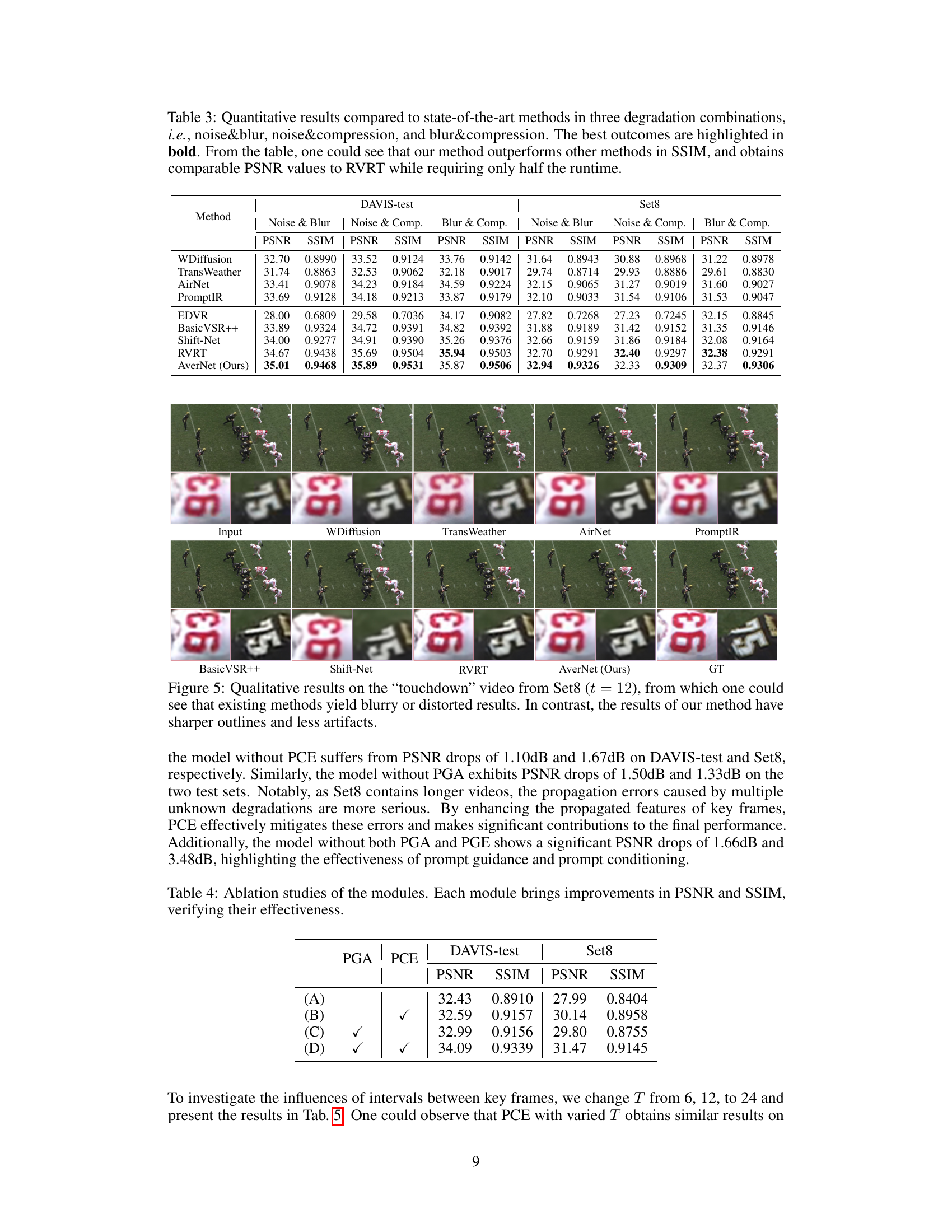
🔼 This table presents a quantitative comparison of the proposed AverNet model against several state-of-the-art video and image restoration methods. The comparison is performed across three different degradation combinations: noise and blur, noise and compression, and blur and compression. The metrics used for evaluation are PSNR and SSIM. The results show that AverNet achieves either comparable or better performance than existing methods, particularly excelling in SSIM scores, while also exhibiting significantly improved computational efficiency.
read the caption
Table 3: Quantitative results compared to state-of-the-art methods in three degradation combinations, i.e., noise&blur, noise&compression, and blur&compression. The best outcomes are highlighted in bold. From the table, one could see that our method outperforms other methods in SSIM, and obtains comparable PSNR values to RVRT while requiring only half the runtime.
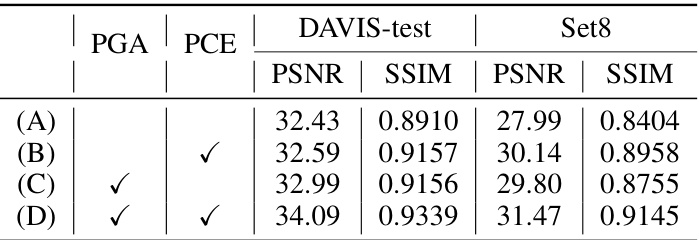
🔼 This table presents the ablation study results for the AverNet model. The experimenters systematically removed either the Prompt-Guided Alignment (PGA) module or the Prompt-Conditioned Enhancement (PCE) module, or both, to assess their individual contributions to the overall performance. The results are shown in terms of Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) for two datasets, DAVIS-test and Set8, indicating the effectiveness of each module in improving video restoration quality.
read the caption
Table 4: Ablation studies of the modules. Each module brings improvements in PSNR and SSIM, verifying their effectiveness.
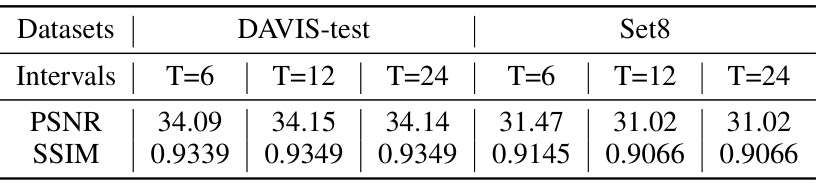
🔼 This ablation study investigates the impact of varying the interval (T) between key frames on the performance of the Prompt-Conditioned Enhancement (PCE) module. Results are shown for PSNR and SSIM metrics on the DAVIS-test and Set8 datasets, with intervals of T=6, T=12, and T=24. The findings reveal that while performance remains relatively consistent on the shorter DAVIS-test videos, using a larger interval (fewer key frames) leads to a noticeable decrease in performance on the longer Set8 videos.
read the caption
Table 5: Ablation of the key frame interval T in PCE. From the table, one could see that larger T, i.e., fewer key frames result in worse performance on the long videos of Set8.
Full paper#