↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Offline visual reinforcement learning faces challenges like overfitting and overestimation bias, hindering accurate reward prediction and effective policy learning. Current solutions tend to be too conservative, limiting exploration. This paper introduces CoWorld, a novel model-based approach addressing these challenges.
CoWorld uses online simulators as “testbeds” for offline policies, transferring knowledge to enhance value estimation. It introduces a cross-domain critic model that mitigates discrepancies in the state and reward spaces between online and offline environments. This approach allows for more flexible constraints in value estimation without impeding exploration, resulting in superior performance compared to existing methods. Experiments show CoWorld’s effectiveness in various benchmark environments.
Key Takeaways#
Why does it matter?#
This paper is crucial because offline visual reinforcement learning (RL) is a challenging field with significant limitations. The proposed approach, CoWorld, directly addresses these challenges by introducing a novel model-based RL paradigm that leverages online simulators. This innovative methodology has the potential to significantly advance the field and inspire new research directions, especially concerning the exploration of efficient techniques for knowledge transfer between online and offline domains.
Visual Insights#

The figure illustrates the CoWorld approach for offline visual reinforcement learning. It shows how an online environment with a source world model and agent is used to provide knowledge transfer and constraints for a target world model and agent trained on offline data. The key is to leverage off-the-shelf RL simulators as a test bed for offline policies, enabling online-to-offline knowledge transfer that mitigates cross-domain discrepancies in state and reward spaces.

This table compares the target domain, RoboDesk, with the auxiliary source domain, Meta-World, highlighting key differences in task dynamics, action spaces, reward scales, and observation types to emphasize the cross-domain challenges addressed by the proposed CoWorld approach. The differences underscore the difficulty of direct knowledge transfer and the need for domain alignment strategies.
In-depth insights#
Offline Visual RL#
Offline visual reinforcement learning (RL) presents unique challenges due to the high dimensionality of visual data and the limitations of offline datasets. Overfitting is a major concern, as models trained on limited visual data may fail to generalize well to unseen situations. Value overestimation is another significant problem; offline algorithms often overestimate the value of actions, leading to poor performance when deployed in the real world. Addressing these challenges requires careful consideration of representation learning and value function approximation. Model-based methods that learn a world model from data have shown promise in offline RL, as they can leverage the model to generate synthetic data for training and improve generalization. However, model-based methods are computationally expensive, and their accuracy depends heavily on the quality of the learned model. Approaches incorporating domain adaptation or transfer learning from related online environments are also actively being researched to alleviate data scarcity and overfitting issues in offline visual RL. Conservative Q-learning techniques attempt to mitigate overestimation, but can sometimes overly restrict exploration, limiting the potential for discovering high-reward actions. Future research will likely focus on creating more robust methods for representation learning, value estimation, and data augmentation, possibly combining elements from model-based and model-free approaches to leverage their respective strengths.
CoWorld Model#
The CoWorld model is a novel model-based transfer reinforcement learning approach designed to address the challenges of offline visual reinforcement learning. It tackles overfitting and overestimation issues by leveraging readily available online simulators as auxiliary training domains. The core concept involves training separate world models and agents for both the offline (target) and online (source) domains. A key innovation is its iterative training strategy focusing on state and reward space alignment between these models. This alignment ensures that knowledge gained from the interactive source environment can effectively transfer to guide and constrain the learning of the offline agent. The resulting ‘mild-conservatism’ of the target value estimation avoids excessively penalizing exploration, unlike overly conservative approaches. CoWorld’s modular design allows for flexible integration of multiple source domains, enhancing its generalizability and robustness. The architecture facilitates robust knowledge transfer across distinct visual and dynamic settings, significantly enhancing the performance of offline visual RL.
Domain Alignment#
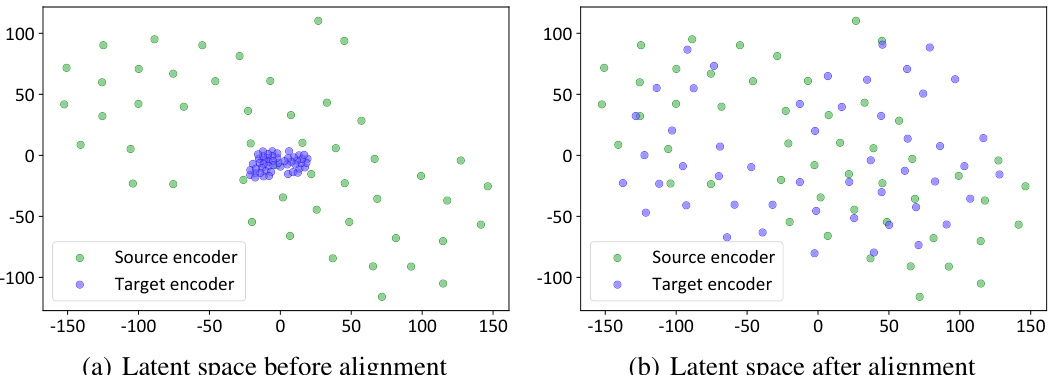
In bridging the gap between offline and online visual reinforcement learning, domain alignment is paramount. It tackles the critical challenge of transferring knowledge learned in an online, readily-available simulator to an offline dataset, which often suffers from limited data and domain shift. This involves carefully aligning both the state and reward spaces between the two domains. State alignment ensures that the latent state representations generated from visual observations in the offline and online environments are comparable, allowing for effective knowledge transfer. Reward alignment focuses on adjusting the reward function to achieve consistency between the offline and online domains, ensuring that the agent’s learned behavior translates seamlessly. Careful consideration of discrepancies in visual inputs, physical dynamics, and action spaces is necessary to accomplish successful domain alignment. Ultimately, effective domain alignment is crucial for leveraging the benefits of online interactions, leading to the development of more robust and capable offline visual reinforcement learning models.
Cross-Domain Transfer#
Cross-domain transfer in this context likely refers to the method of leveraging knowledge from a source domain (e.g., a readily available simulator) to enhance learning in a target domain (e.g., a challenging offline visual RL dataset). The core idea is to bridge the gap between differing data distributions and task characteristics. This is crucial because directly applying offline RL algorithms to visual tasks often leads to overfitting and overestimation bias. By carefully aligning representations and rewards between the source and target domains, the method aims to transfer valuable knowledge, improving performance and generalization in the target domain. The effectiveness depends heavily on successful domain alignment techniques that minimize cross-domain discrepancies, ensuring that the knowledge transferred is relevant and beneficial, not detrimental. A key challenge is balancing the transfer of useful information with avoiding negative transfer caused by mismatched features or inappropriate mappings.
Future Works#
Future work could explore several promising directions. Extending CoWorld to handle more complex visual environments with significant variations in lighting, viewpoint, or object appearance would enhance its robustness and generalizability. Investigating the impact of different simulator choices on performance is crucial. Developing more sophisticated domain adaptation techniques beyond simple alignment could improve knowledge transfer. Analyzing the tradeoffs between computational cost and performance gains is important, especially when employing multiple source domains. Finally, applying CoWorld to a wider range of tasks and robotics platforms would demonstrate its broader applicability and practical value. Further investigation into the theoretical underpinnings of the CoWorld model and a detailed analysis of its limitations would strengthen the research.
More visual insights#
More on figures

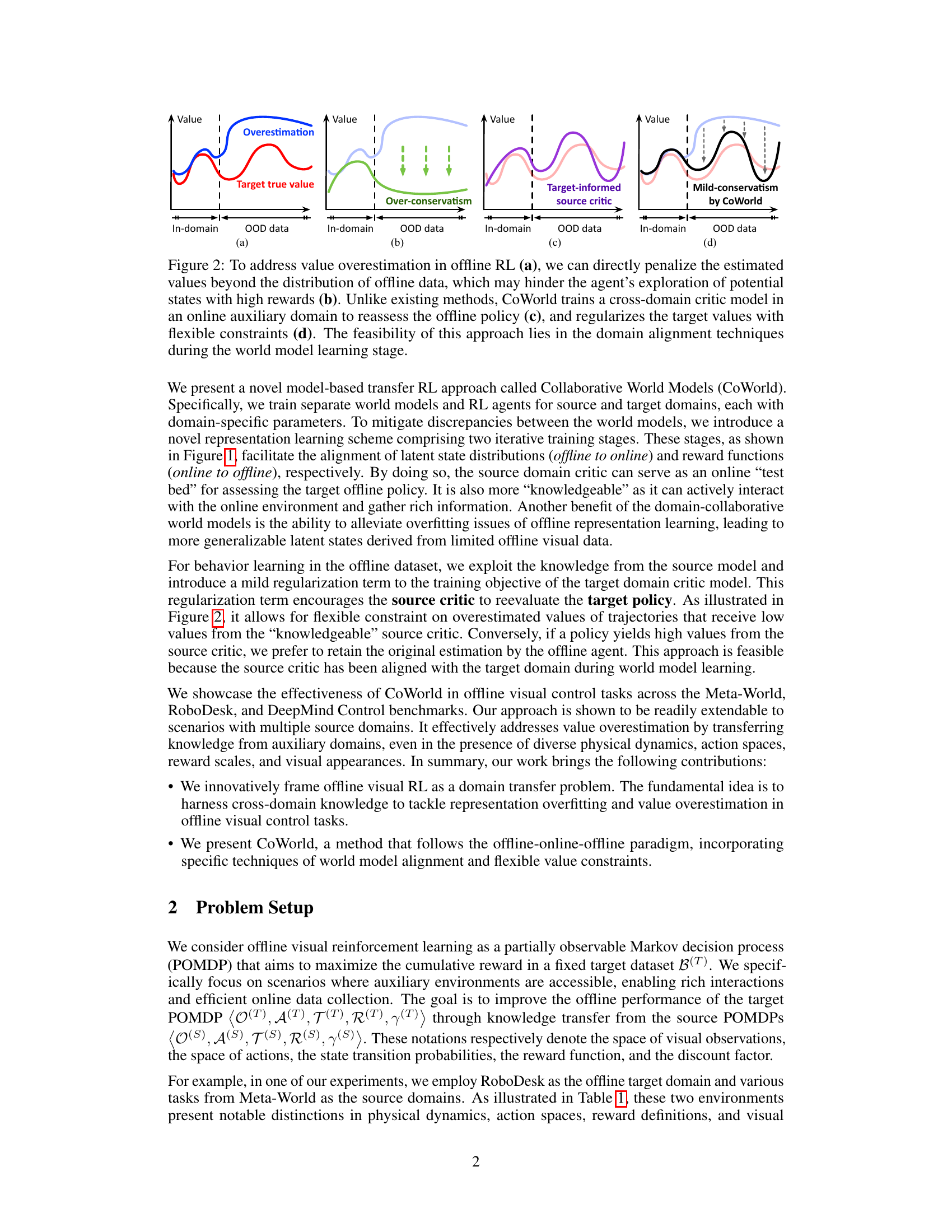
This figure illustrates the core idea of CoWorld in addressing value overestimation in offline RL. Panel (a) shows the problem of overestimation in offline RL, where the estimated values are higher than the true values, especially for out-of-distribution (OOD) data. Panel (b) demonstrates how directly penalizing overestimated values can lead to over-conservatism, preventing exploration of potentially high-reward states. In contrast, CoWorld (c, d) leverages an online auxiliary domain and a cross-domain critic to provide more flexible value constraints. The online critic reassesses the offline policy, resulting in a milder form of conservatism (d) that balances the risk of overestimation and the need for exploration.

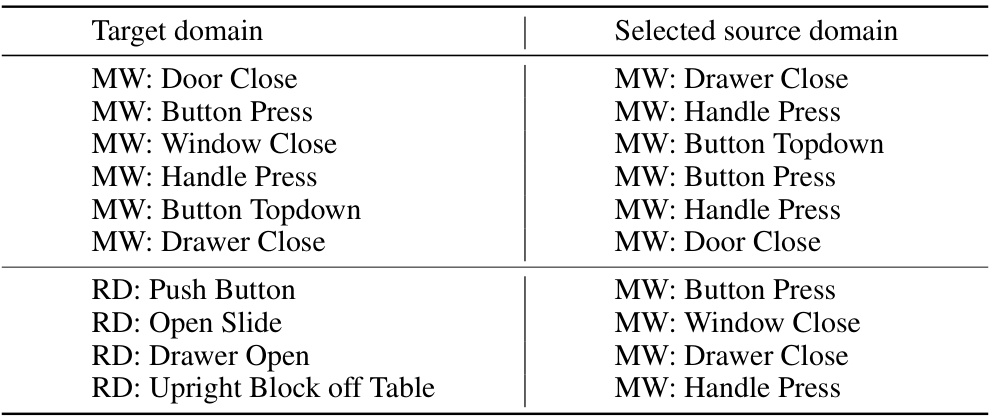
The left part of the figure shows a heatmap visualizing the performance improvement of CoWorld over Offline DV2 across various source-target domain combinations for Meta-World tasks. The right part shows a line graph comparing the performance of CoWorld with different source domains on a specific task (Drawer Close), highlighting the ability of multi-source CoWorld to automatically select a high-performing source domain.

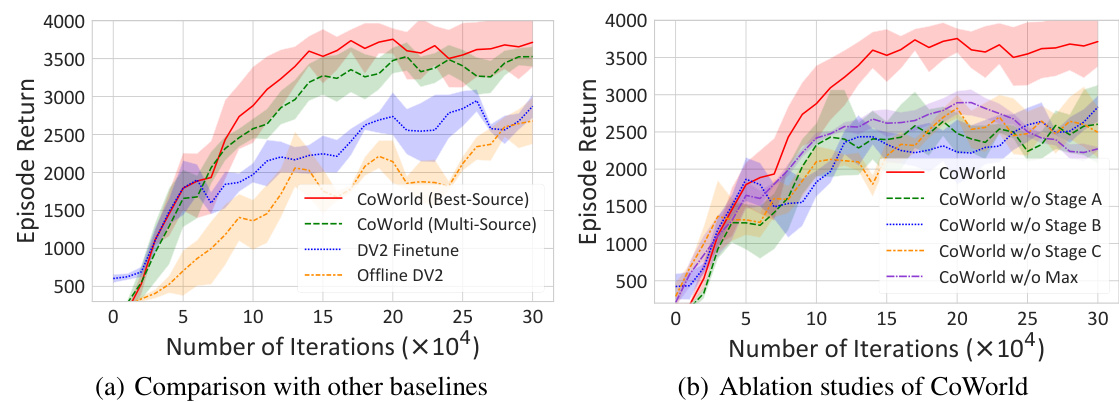
This figure presents the quantitative results of the CoWorld model in domain transfer scenarios from Meta-World to RoboDesk. It shows the learning curves (episode return vs. training iterations) for four different domain transfer tasks: Button Press → Push Button, Window Close → Open Slide, Drawer Close → Drawer Open, and Handle Press → Upright Block off Table. The plots compare the performance of CoWorld (best-source, multi-source), Offline DV2, and DV2 Finetune. This visualization helps demonstrate CoWorld’s ability to effectively transfer knowledge from the source domain (Meta-World) to the target domain (RoboDesk) despite the differences between the two environments in terms of visual observations, physical dynamics, action spaces, reward definitions, etc.
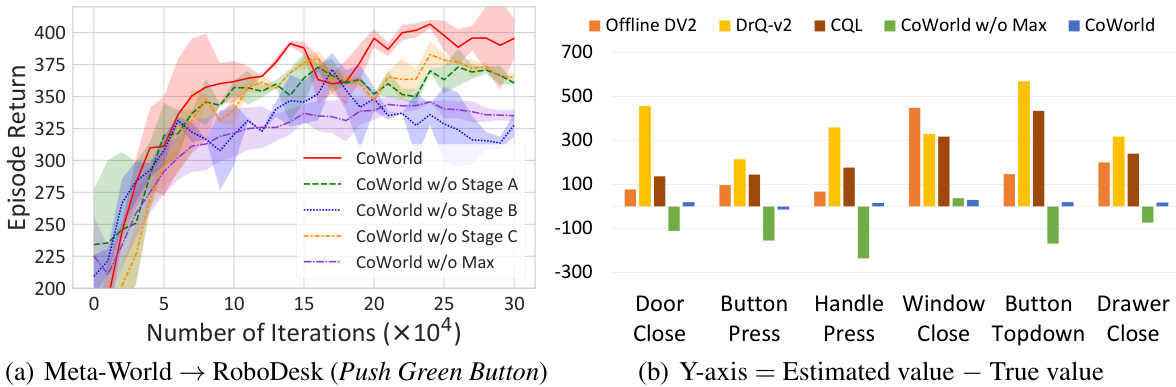
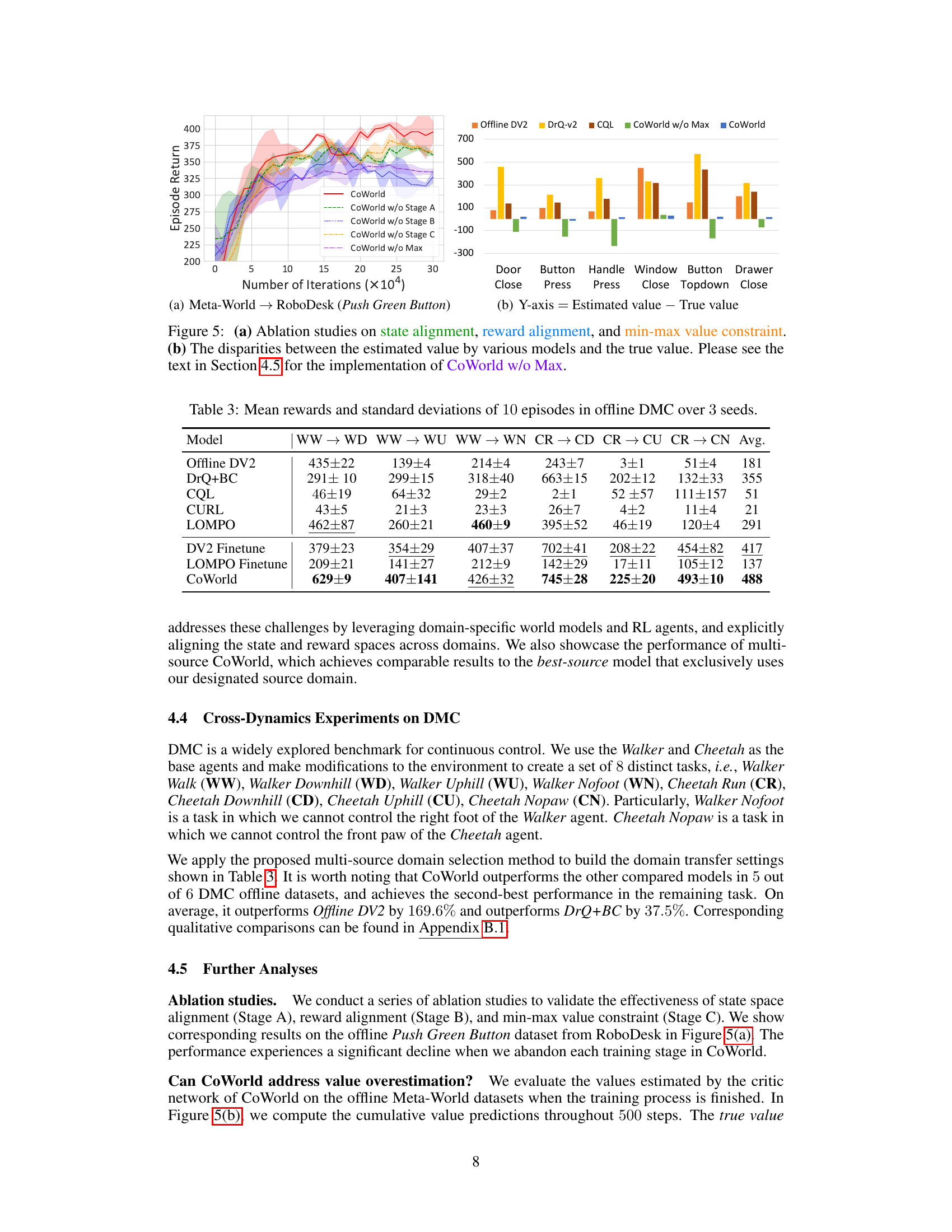
This figure presents ablation study results for the CoWorld model, showing the impact of removing each stage (state alignment, reward alignment, and min-max constraint) on the model’s performance. The left subplot shows the learning curves for the complete model and the versions with each stage removed, illustrating their individual contributions. The right subplot visualizes the value overestimation problem, comparing the estimated values of different models against the true values. This demonstrates CoWorld’s ability to address value overestimation.

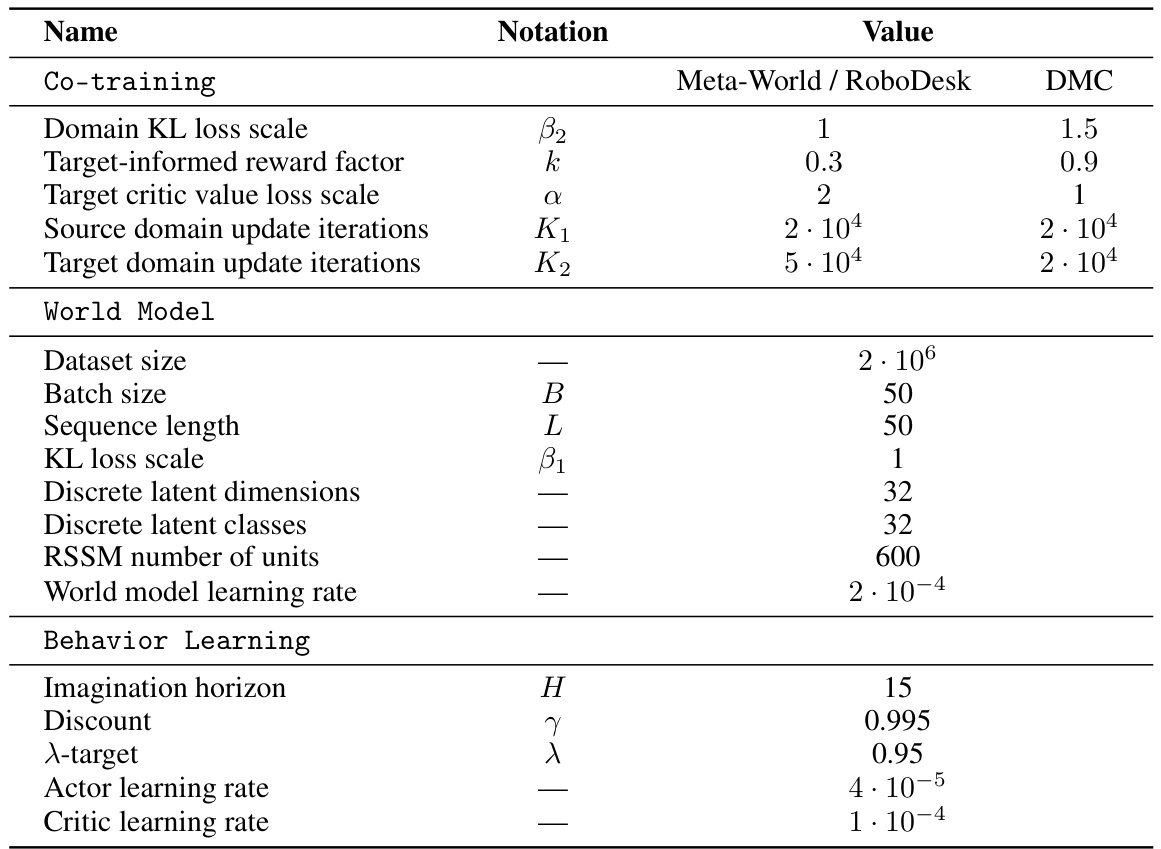
This figure shows the sensitivity analysis of three hyperparameters used in the CoWorld model: the domain KL loss scale (β2), the target-inclined reward factor (k), and the target critic value loss scale (α). Each subfigure shows how the episode return varies with different values of a specific hyperparameter while holding the other two hyperparameters constant. The plots reveal the optimal range for each hyperparameter to achieve the best performance. For instance, a smaller β2 value leads to lower episode return, while an excessively larger α value results in value over-conservatism in the target critic.
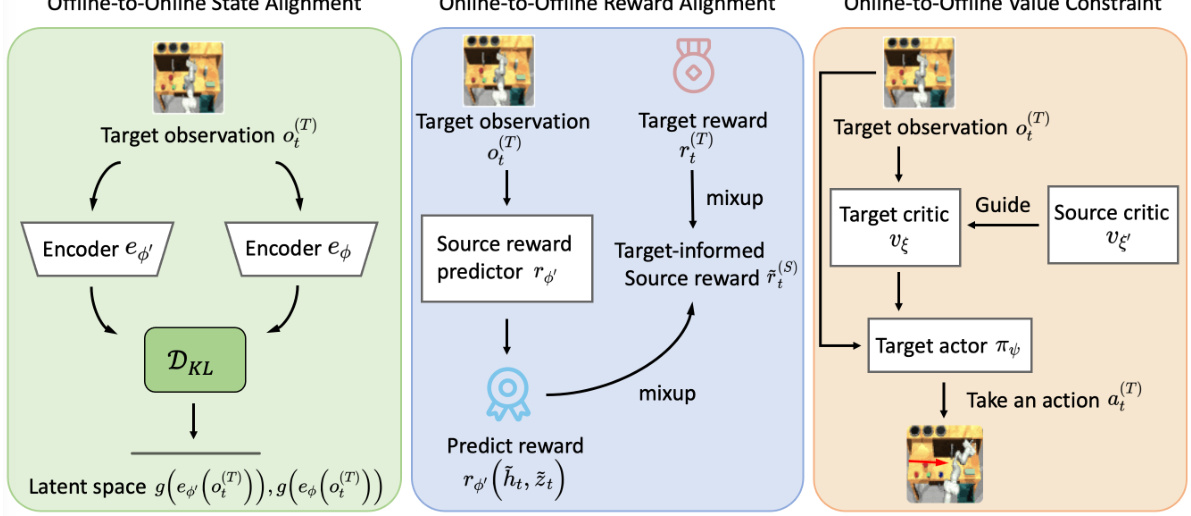
This figure illustrates the CoWorld approach for offline visual reinforcement learning. It shows how offline data, an online environment (acting as a source world), and two world models (one for the source world and one for the target offline world) are used to learn a policy. The source world provides rich interactions, the source agent explores the environment, and value constraints are applied to help avoid overestimation. The state and reward spaces are aligned between the two world models to improve knowledge transfer.

This figure shows a qualitative comparison of policy evaluations on three DeepMind Control (DMC) tasks: Walker Downhill, Walker Uphill, and Walker Nofoot. For each task, the figure displays a sequence of images (t=1 to t=45) illustrating the agent’s actions over time, as performed by four different methods: CURL, LOMPO, Offline DV2, and CoWorld. The images provide a visual representation of the policies learned by each algorithm, allowing for a direct comparison of their performance and behavior.

This figure shows a qualitative comparison of policy evaluation results across four different methods (CURL, LOMPO, Offline DV2, and CoWorld) on three distinct DeepMind Control (DMC) tasks: Walker Downhill, Walker Uphill, and Walker Nofoot. For each task and method, the figure displays a sequence of images showing the agent’s movements at different time steps (t=1, 5, 10, …, 45). This visualization helps understand how well each algorithm learns to control the agent’s movements in various situations and compares their relative performance.

This figure shows a qualitative comparison of the policies learned by different methods (CURL, LOMPO, Offline DV2, and CoWorld) on three different DeepMind Control (DMC) tasks: Walker Downhill, Walker Uphill, and Walker Nofoot. Each row represents a different method, and each column shows the state of the agent at a specific time step (t=1, 5, 10, …, 45). The visualizations help illustrate how effectively each method learns to control the agent in the challenging DMC environments, highlighting the differences in their approaches to locomotion.

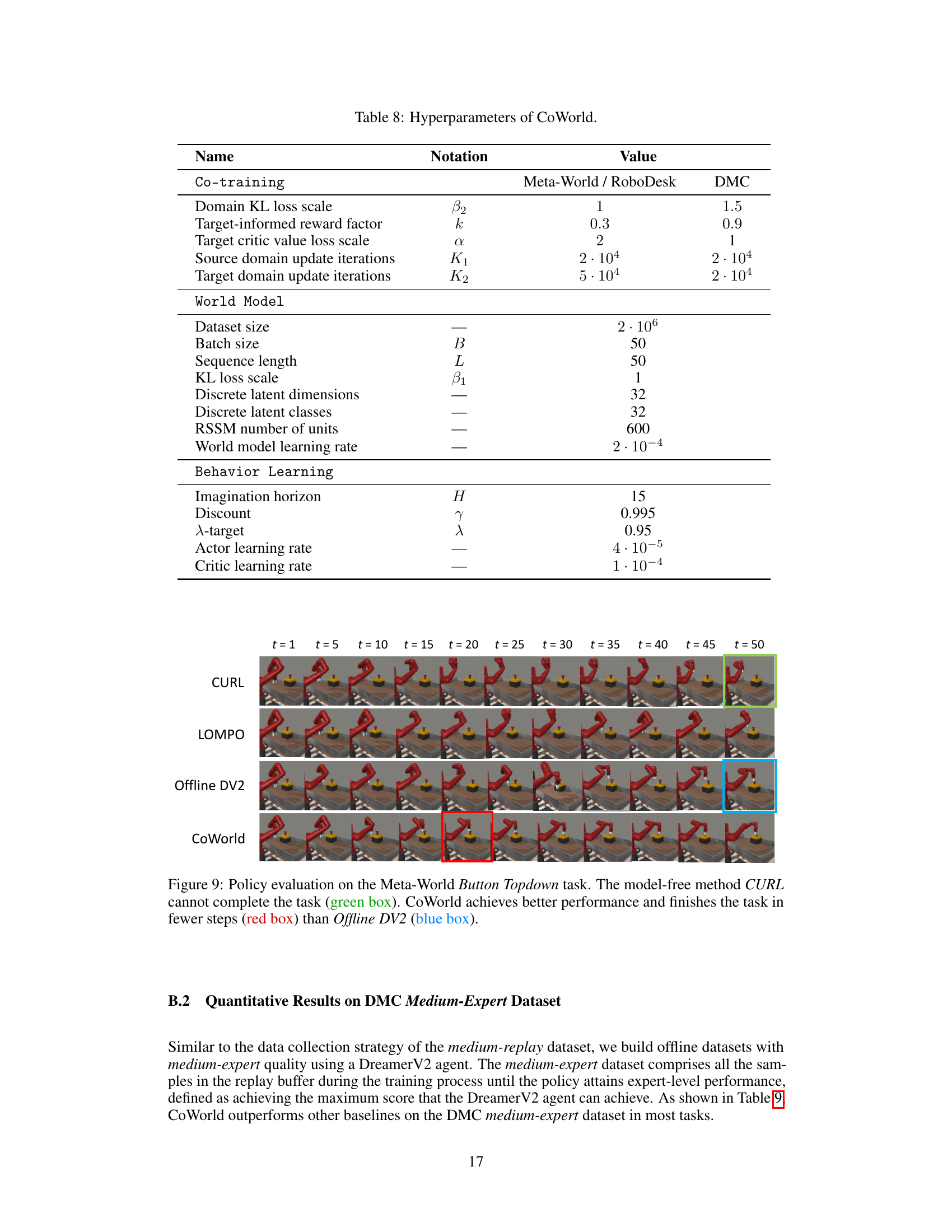
This figure shows a qualitative comparison of the performance of different offline reinforcement learning methods on the Meta-World Button Topdown task. The images depict the agent’s actions over time. CURL fails to complete the task. Offline DV2 completes it, but CoWorld shows a more efficient and successful approach.
This figure illustrates the overall approach proposed in the paper for offline visual reinforcement learning. It shows an offline dataset being used to train a target world model and agent. The key innovation is the inclusion of an online environment and source agent, which interact with a source world model. This allows for knowledge transfer between the online and offline domains, enabling more effective learning by mitigating the challenges of overfitting and overestimation often seen in offline visual RL.
This figure illustrates the CoWorld approach for offline visual reinforcement learning. It shows how offline data is combined with an online environment (a simulator) to train a model. The offline dataset informs the target world model and agent, while the online environment, through the source world model and agent, helps refine the value estimation, mitigating overestimation and promoting better exploration. The process is iterative, moving between offline and online phases.
More on tables

This table compares the target domain, RoboDesk, with the auxiliary source domain, Meta-World, highlighting key differences across various aspects. These differences include the type of robot arm used (Sawyer vs. Franka), the dimensionality of the action space, the reward scaling, and the viewpoints of the observations (right-view images vs. top-view images). Understanding these discrepancies is crucial for effective cross-domain knowledge transfer in the offline visual reinforcement learning task.

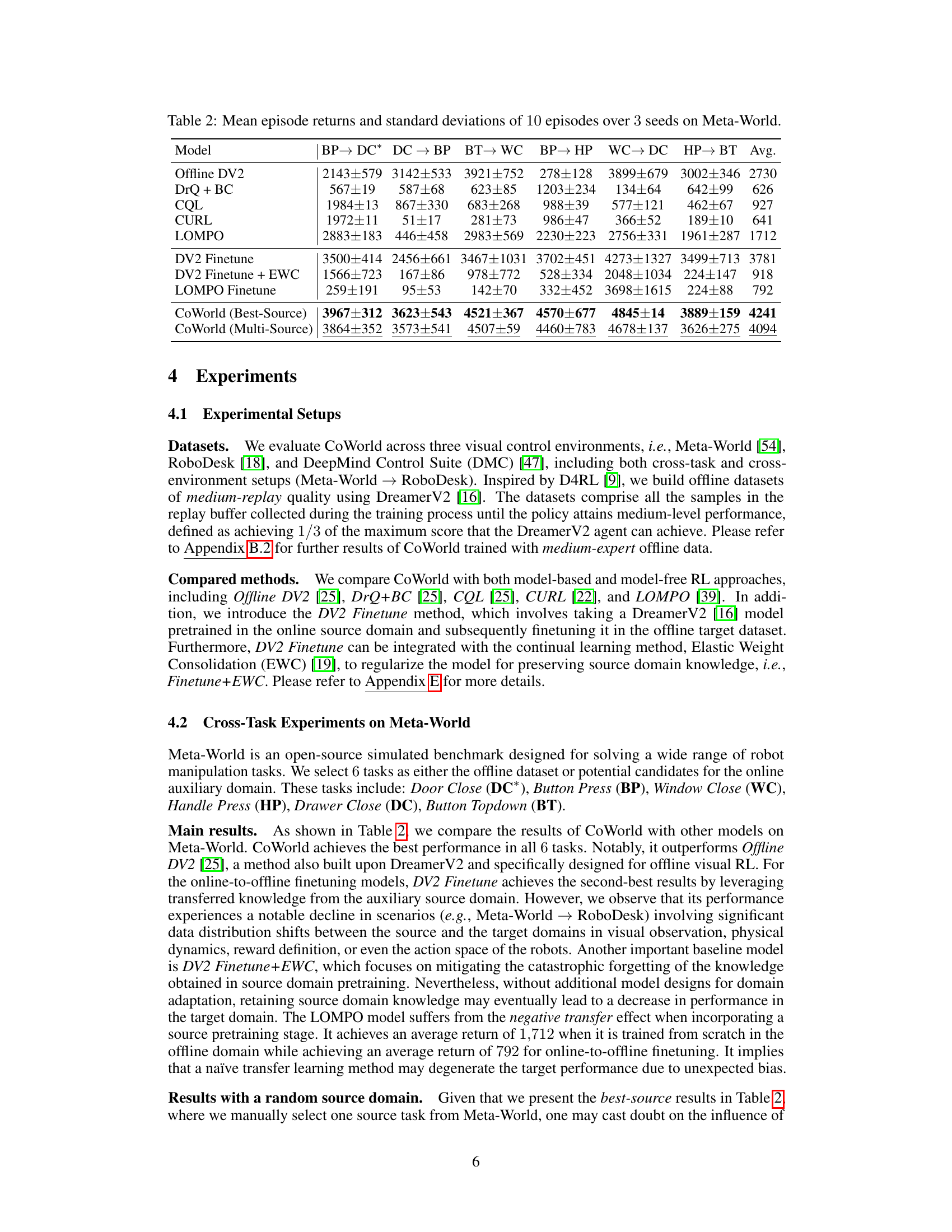
This table presents the mean and standard deviation of episode returns achieved by different offline reinforcement learning methods across six different tasks within the Meta-World environment. Each result represents an average over 10 episodes and 3 random seeds, providing a robust comparison of the algorithms’ performance. The tasks include Door Close (DC*), Button Press (BP), Window Close (WC), Handle Press (HP), Drawer Close (DC), and Button Topdown (BT). The methods compared include Offline DV2, DrQ + BC, CQL, CURL, LOMPO, DV2 Finetune, DV2 Finetune + EWC, LOMPO Finetune, and CoWorld (with both best-source and multi-source configurations). The table allows for a comprehensive comparison of the various algorithms’ performance across various Meta-World tasks.
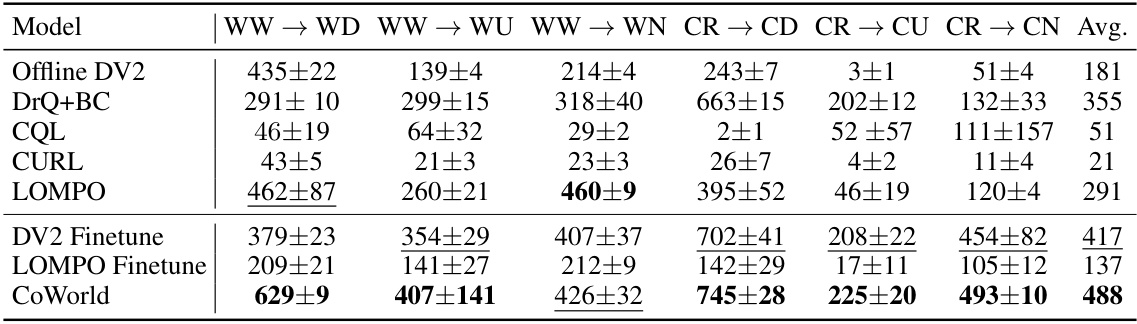
This table presents the average episode returns and standard deviations achieved by various offline reinforcement learning methods across six different tasks within the Meta-World environment. The results are averaged over 10 episodes and three random seeds, providing a robust comparison of the algorithms’ performance. The methods compared include Offline DV2, DrQ+BC, CQL, CURL, LOMPO, and CoWorld (with best-source and multi-source strategies). The table highlights the relative performance of CoWorld compared to existing offline RL approaches on a visual control benchmark.

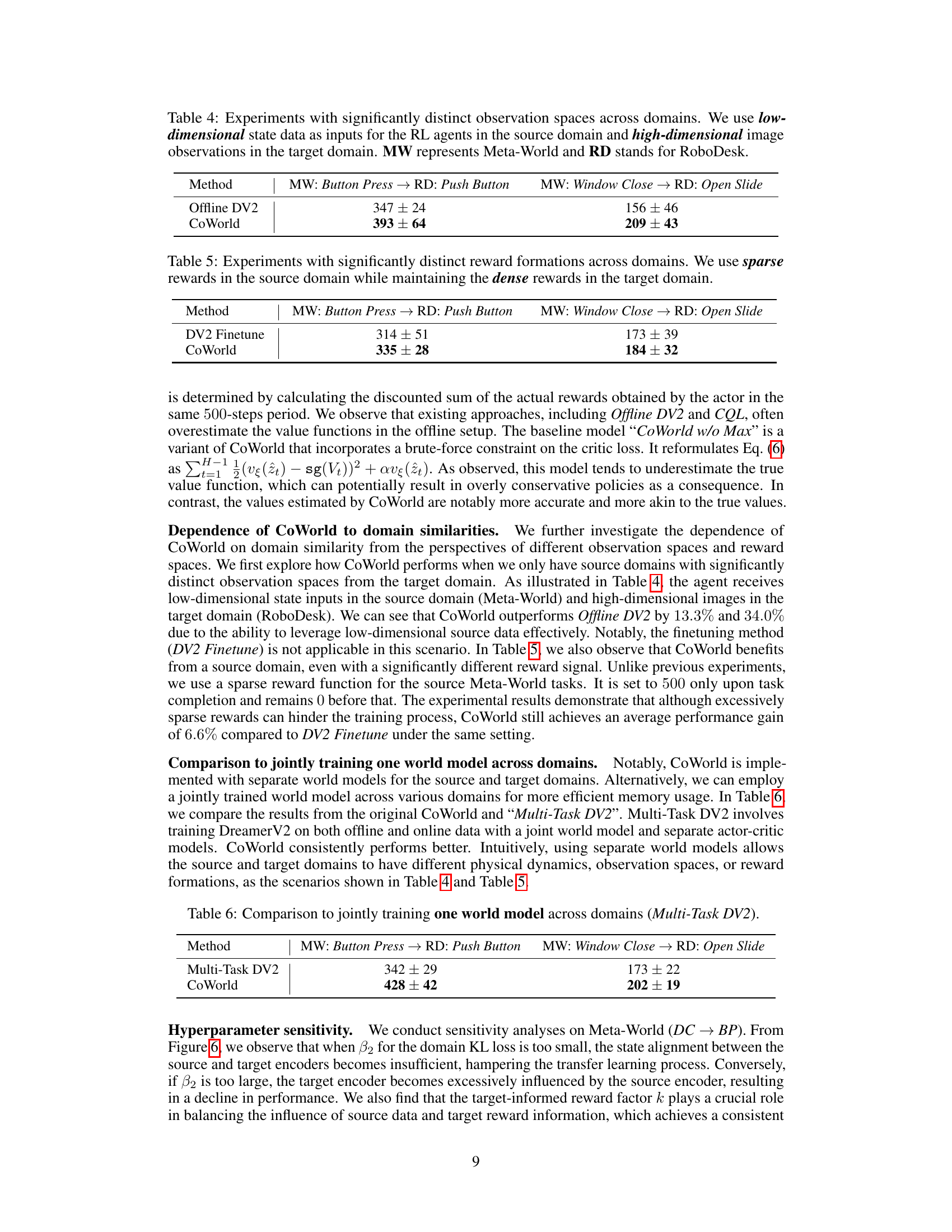
This table presents results from experiments designed to test the robustness of the CoWorld model when there are significant differences in the observation spaces between the source and target domains. The source domain uses low-dimensional state data, while the target domain uses high-dimensional image data. The table shows the mean episode return and standard deviation for two different task transfer scenarios: Meta-World Button Press to RoboDesk Push Button and Meta-World Window Close to RoboDesk Open Slide. The results demonstrate the performance of both the Offline DV2 baseline and the CoWorld model in these challenging conditions.

This table shows the results of experiments conducted to evaluate the performance of CoWorld and DV2 Finetune when there are significant differences in observation spaces between the source and target domains. In particular, the source domain uses low-dimensional state data, while the target domain uses high-dimensional image data. The table presents the mean episode return ± standard deviation for two different cross-domain transfer tasks (Meta-World Button Press → RoboDesk Push Button and Meta-World Window Close → RoboDesk Open Slide).

This table presents the results of experiments conducted to evaluate the performance of the proposed CoWorld method and a baseline method (Offline DV2) in scenarios where there are significant differences in observation spaces between the source and target domains. Specifically, the source domain uses low-dimensional state data while the target domain uses high-dimensional image data. The table shows the average episode returns and standard deviations for two different transfer tasks: Meta-World Button Press to RoboDesk Push Button and Meta-World Window Close to RoboDesk Open Slide.

This table compares the target domain, RoboDesk, and the auxiliary source domain, Meta-World, highlighting key differences for visual reinforcement learning. These differences include the type of robot arm used (Sawyer vs. Franka), the action space dimensionality, the reward scale, and the viewpoint of the observations (right-view images vs. top-view images). Understanding these differences is crucial because the paper proposes a method that leverages knowledge transfer between these domains to improve offline visual reinforcement learning performance.
This table presents the mean episode returns and standard deviations achieved by different reinforcement learning models across six tasks within the Meta-World environment. Each result represents the average over 10 episodes and 3 random seeds, providing a robust comparison of model performance across various tasks. The models compared include Offline DV2, DrQ + BC, CQL, CURL, LOMPO, and CoWorld (with both best-source and multi-source configurations). The table highlights CoWorld’s superior performance compared to existing methods.

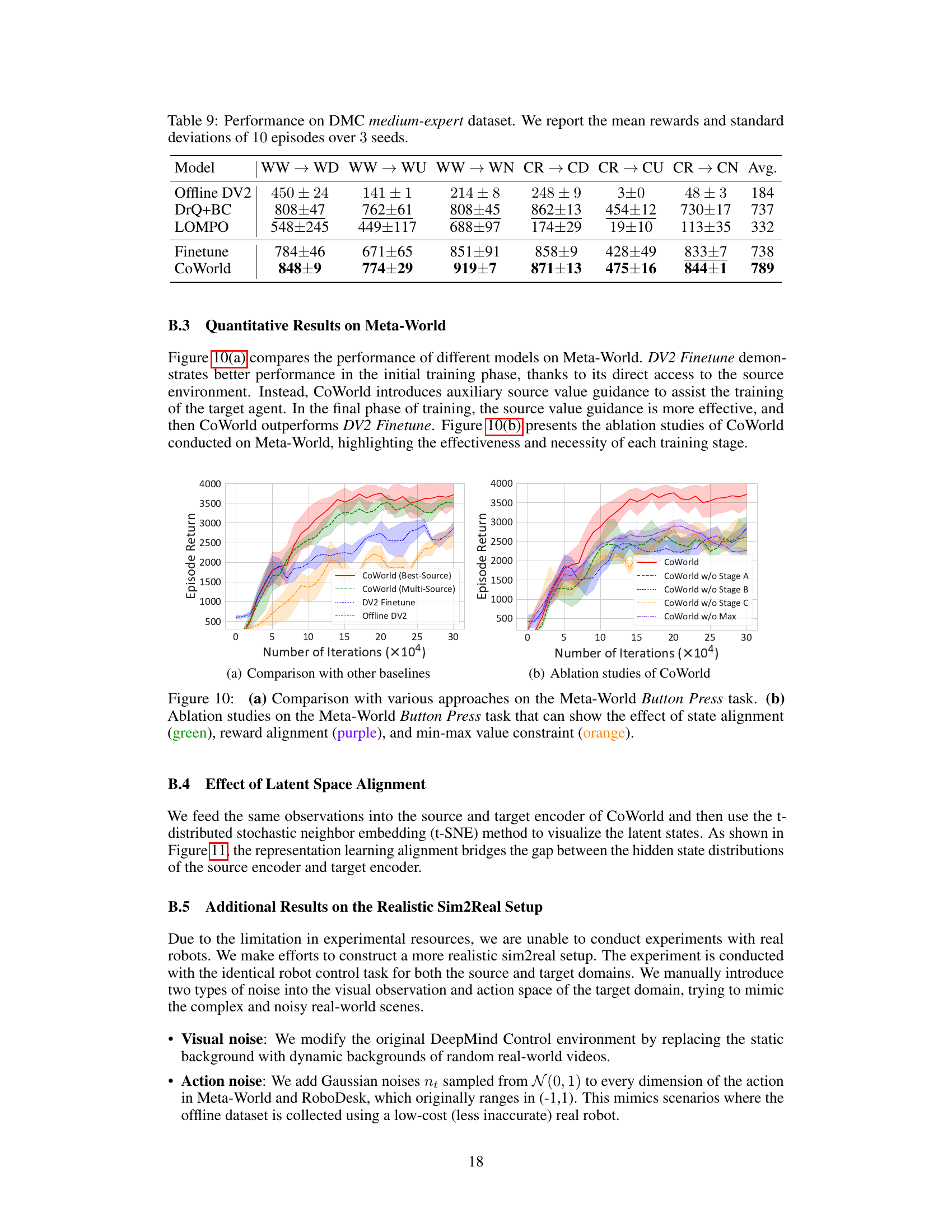
This table presents the results of different reinforcement learning methods on the DeepMind Control (DMC) benchmark using a medium-expert dataset. It shows the mean and standard deviation of episode rewards across six different tasks (three for Walker and three for Cheetah robots) for each method. The ‘Avg.’ column represents the average performance across all six tasks. The methods compared include Offline DV2, DrQ+BC, LOMPO, DV2 Finetune, and CoWorld.
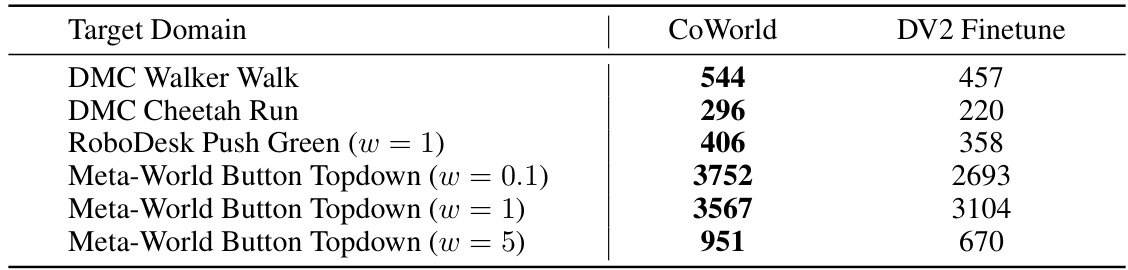
This table presents the results of CoWorld and DV2 Finetune on tasks with more significant domain discrepancies compared to other experiments. The target domains include different tasks from DMC (DeepMind Control) and Meta-World, showcasing the robustness of CoWorld across various scenarios with varying degrees of domain similarity. The noise magnitude (w) added in some Meta-World Button Topdown experiments is also specified.

This table compares the performance of CoWorld against three other models: R3M (trained with expert data), R3M (trained with the authors’ data), and DV2 Finetune. The comparison is made across three Meta-World tasks: Button Press Topdown, Drawer Close, and Handle Press. The results show CoWorld outperforming the other models in most cases, suggesting its effectiveness even when compared to pre-trained foundation models like R3M.

This table presents the mean episode returns and standard deviations achieved by different reinforcement learning models across six tasks in the Meta-World environment. The results are averaged over 10 episodes and 3 different random seeds for each model and task, providing a comprehensive comparison of their performance. The models compared include Offline DV2, DrQ + BC, CQL, CURL, LOMPO, and CoWorld (with both a best-source and multi-source variant). The table allows for a direct comparison of the performance of various methods on the same set of tasks in the same environment.
This table compares the target domain, RoboDesk, with the auxiliary source domain, Meta-World, highlighting key differences in task, dynamics, action space, reward scale, and observations (images). The differences are relevant to the challenge of transferring knowledge between the two domains for offline visual reinforcement learning. The table shows that while both domains involve robot manipulation tasks, there are significant differences in the robot arm used, the action space dimensionality, reward scaling, and most notably, the viewpoint of the camera used for generating the visual observations.
Full paper#