TL;DR#
Current text-to-image (T2I) models often generate unsafe content due to their training on large-scale datasets containing inappropriate material. Existing unlearning techniques are easily bypassed through adversarial attacks. This creates a significant challenge for ensuring the safe and responsible deployment of these models.
Direct Unlearning Optimization (DUO) tackles this problem by employing a preference optimization approach. It uses carefully curated paired image data to teach the model to remove unsafe visual concepts without affecting its ability to generate safe images. A key innovation is the use of output-preserving regularization to maintain the model’s performance on unrelated topics. Extensive experiments demonstrate that DUO effectively defends against state-of-the-art adversarial attacks, establishing its robustness and reliability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on safe and robust text-to-image models because it introduces a novel framework that effectively mitigates the risks associated with generating harmful content while preserving model performance. It directly addresses the limitations of existing unlearning methods, offering a robust solution to adversarial attacks. The research opens new avenues for developing more responsible and reliable text-to-image models, contributing significantly to the advancement of AI safety.
Visual Insights#

🔼 This figure illustrates the vulnerability of prompt-based unlearning methods to adversarial attacks. Prompt-based methods aim to prevent the model from generating unsafe content by modifying its response to unsafe prompts. However, adversaries can easily bypass these methods by slightly altering the unsafe prompts. In contrast, image-based unlearning focuses on directly removing unsafe visual concepts from the model, regardless of the prompt, making it more robust to adversarial attacks. The figure compares the results of prompt-based and image-based unlearning when exposed to safe, natural unsafe, and adversarial prompts.
read the caption
Figure 1: Image-based unlearning. Prompt-based unlearning can be easily circumvented with adversarial prompt attack. On the other hand, image-based unlearning robustly produces safe images regardless of the given prompt. We use for publication purposes.

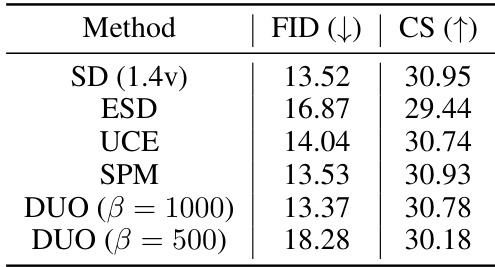
🔼 This table presents the Fréchet Inception Distance (FID) and CLIP similarity scores for nudity. Lower FID scores indicate better image quality, while higher CLIP scores indicate better semantic similarity. The table compares the performance of several methods, including the Stable Diffusion baseline (SD 1.4v), ESD, UCE, SPM, and DUO with different beta values (500 and 250). It shows that DUO achieves comparable image quality to other methods, while offering varying degrees of success in removing nudity.
read the caption
Table 1: FID and CLIP score (CS) for nudity.
In-depth insights#
Unsafe T2I Mitigation#
Unsafe T2I mitigation is a crucial area of research focusing on minimizing the generation of harmful or inappropriate content by text-to-image models. Current approaches often center on prompt-based methods, attempting to filter unsafe inputs, but these are vulnerable to adversarial attacks. A more robust solution lies in directly modifying the model’s internal representations of harmful concepts, essentially making it ‘forget’ how to generate unsafe images. This could involve techniques like direct unlearning optimization or preference optimization, using paired data of safe and unsafe images to guide the model towards generating only desirable outputs. The challenge is to achieve this while preserving the model’s ability to generate safe content and maintaining its overall quality. This requires careful consideration of how to selectively remove unsafe visual features without impacting other aspects of image generation. Future research should explore more sophisticated methods to robustly and safely mitigate the generation of unsafe content, addressing the limitations of current approaches and enhancing the reliability of T2I systems.
DUO Framework#
The DUO framework, designed for robust and safe text-to-image models, tackles the challenge of unsafe content generation. Its core innovation lies in direct unlearning optimization, moving beyond prompt-based approaches easily bypassed by adversarial attacks. Instead, DUO leverages preference optimization using curated paired image data, where an unsafe image is paired with its safe counterpart. This allows the model to learn to remove unsafe visual concepts while preserving unrelated features. The framework is further strengthened by an output-preserving regularization term, maintaining generative capabilities on safe content. This results in a model that generates safe images consistently, even when encountering adversarial prompts, thus significantly improving the robustness and safety of text-to-image systems. The effectiveness of DUO is validated through extensive experiments demonstrating its resilience against state-of-the-art red teaming methods and negligible performance degradation on unrelated tasks.
Robust Unlearning#
Robust unlearning in machine learning models, particularly generative models like text-to-image models, focuses on developing techniques to remove specific undesirable knowledge from the model while preserving its overall functionality and performance on other tasks. This is crucial because initial training datasets often contain harmful or biased content that needs to be mitigated. The challenge lies in designing methods that resist adversarial attacks aiming to bypass the unlearning process and regenerate unwanted outputs. A robust unlearning system must not only effectively remove harmful content but also maintain the model’s ability to generate diverse and high-quality images on safe prompts. Ideally, such robustness is achieved through methods that directly modify the model’s internal representation of unsafe concepts, rather than relying on superficial filtering techniques that can easily be circumvented. This requires a deeper understanding of how the model stores information and a sophisticated approach to carefully remove unwanted knowledge without causing catastrophic forgetting.
Red Teaming Defense#
A robust “Red Teaming Defense” strategy in AI models, especially text-to-image models, necessitates a multi-faceted approach. It should go beyond simple prompt-based filtering, which is easily bypassed by adversarial attacks. Instead, a strong defense incorporates techniques like direct unlearning optimization, which modifies the model’s internal representations of unsafe concepts to eliminate their generation regardless of the input prompt. This requires carefully curated datasets, preferably paired data with safe and unsafe images, to guide the unlearning process. Furthermore, output-preserving regularization is crucial to prevent the model from losing its ability to generate safe images. The effectiveness of this defense should be rigorously tested against various red teaming methods, including both black-box attacks (which don’t have access to model internals) and white-box attacks (which do). Quantitative metrics, such as FID and CLIP scores, should measure the impact on the model’s overall performance and image quality. Qualitative evaluations of generated images also play a vital role, providing a nuanced understanding of the model’s ability to generate images free from problematic content. A well-rounded “Red Teaming Defense” is not merely a single technique but a combination of methods and rigorous testing. The ultimate goal is to build robust models that remain safe and effective even when facing sophisticated adversarial attacks.
Future Directions#
Future research could explore several promising avenues. Improving the robustness of DUO against more sophisticated adversarial attacks is crucial. This might involve developing more advanced regularization techniques or incorporating alternative preference optimization strategies. Investigating the impact of different data augmentation strategies on DUO’s performance would also be valuable, as would exploring methods to more effectively preserve the model’s generative capabilities on unrelated concepts, potentially through the use of advanced generative models. Finally, expanding research to other generative AI models beyond text-to-image models, and applying DUO to diverse safety challenges in AI, such as mitigating bias or toxicity, presents exciting possibilities for future work.
More visual insights#
More on figures

🔼 This figure illustrates the importance of using paired data (unsafe and corresponding safe images) in the unlearning process. The left panel shows an unsafe image containing both undesirable concepts (e.g., nudity) and related concepts (e.g., a woman in a forest). Simply removing the unsafe image might lead to the unintended loss of related visual information. The right panel explains that by using paired data, preference optimization helps the model learn to distinguish between undesirable and related concepts, effectively removing only the unsafe visual features while preserving the others.
read the caption
Figure 2: Importance of using both unsafe and paired safe images to preserve model prior. We use for publication purposes. Unsafe concept refers to what should be removed from the image (red), while unrelated concept refers to what should be retained in the image (green).

🔼 This figure illustrates the importance of using paired image data for effective unlearning in text-to-image models. The left image shows an ‘unsafe image’ containing both undesirable (‘unsafe concepts’) and desirable (‘unrelated concepts’) features. Simply removing the unsafe image might lead to the loss of desirable features as well. The right image shows a ‘safe image’, where the unsafe elements have been removed using a method like SDEdit, while preserving the unrelated elements. This paired data allows the model to learn to remove only the unsafe visual concepts, without affecting the generation of safe content.
read the caption
Figure 2: Importance of using both unsafe and paired safe images to preserve model prior. We use for publication purposes. Unsafe concept refers to what should be removed from the image (red), while unrelated concept refers to what should be retained in the image (green).

🔼 This figure demonstrates the effectiveness of using SDEdit for generating paired image data to resolve ambiguity in image-based unlearning. It shows three images: (a) an original unsafe image; (b) a naively generated safe image using prompt substitution, which fails to accurately identify what information to retain and remove; and (c) a safe image generated using SDEdit, which successfully identifies and removes only the unsafe concept while preserving unrelated visual features. The use of paired data from SDEdit helps the model resolve the ambiguity of what should be removed during the unlearning process.
read the caption
Figure 3: Effectiveness of utilizing SDEdit for generating paired image data for unlearning. When unlearning (a), if a retain sample is naively generated as shown in (b), the model cannot accurately determine what information should be retained and what should be forgotten. Using SDEdit as shown in (c), the model can identify what information should be retained and what should be forgotten from the undesirable sample. We use for publication purposes.
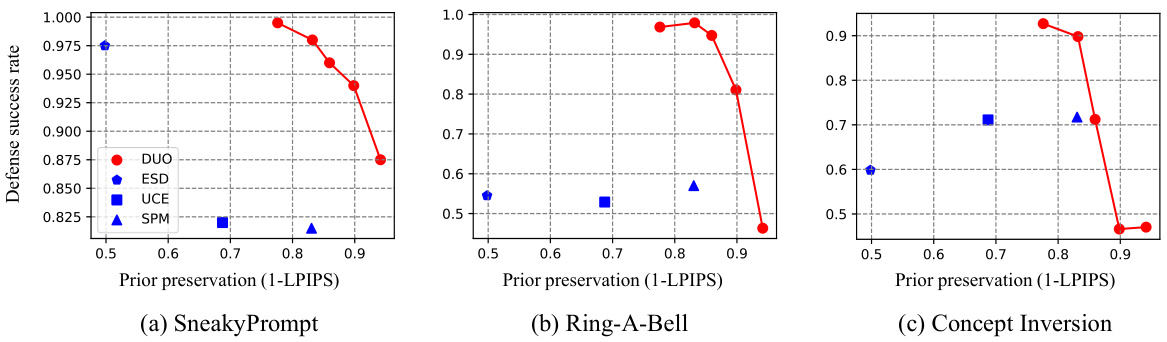
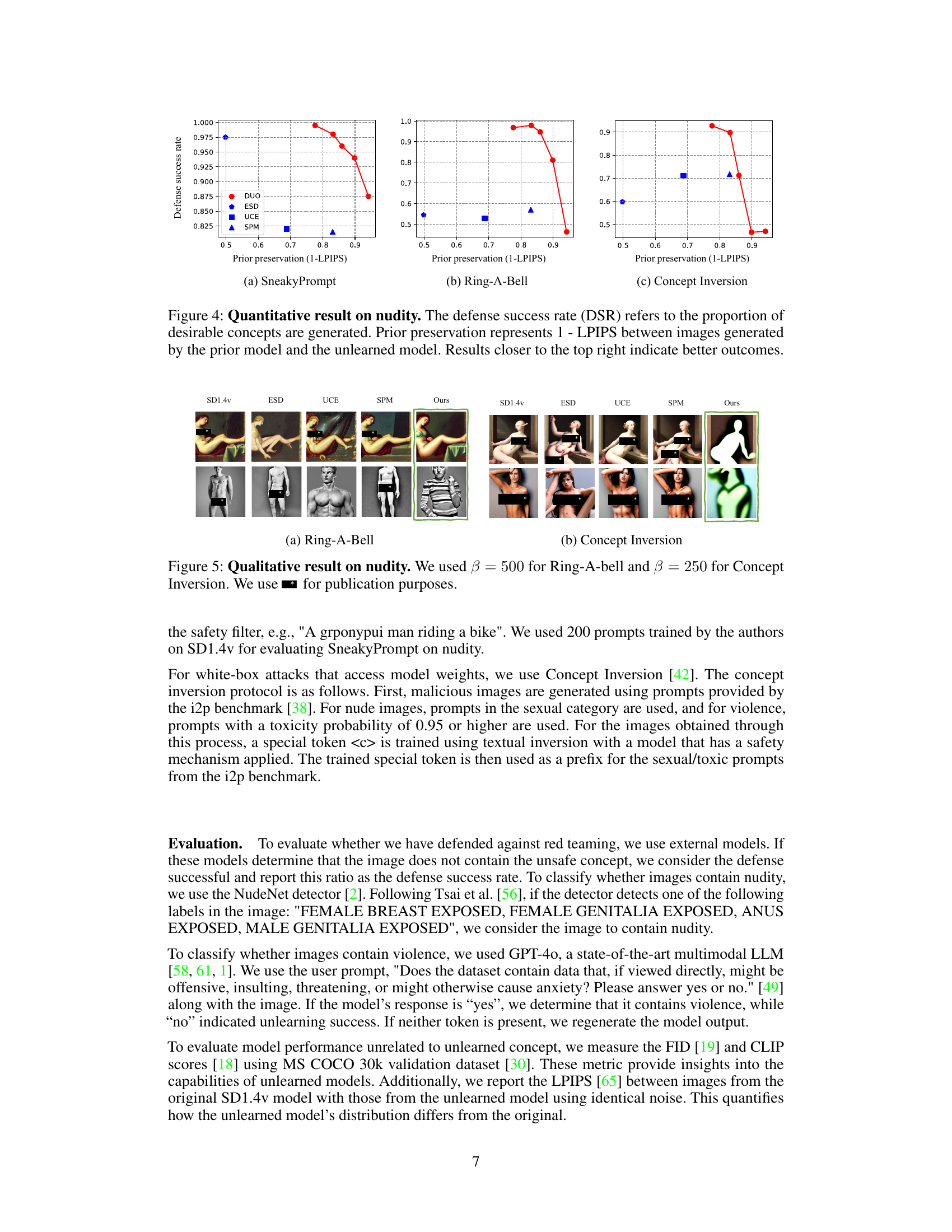
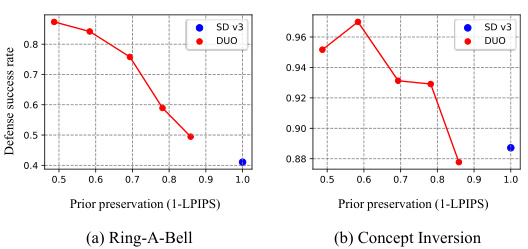
🔼 This figure shows the quantitative results of the proposed DUO method and three other baselines (ESD, UCE, and SPM) on the nudity unlearning task. The x-axis represents the prior preservation, measured by 1 - LPIPS (Lower LPIPS scores mean better preservation of original model’s generation capabilities). The y-axis represents the defense success rate (DSR), which is the percentage of generated images that do not contain nudity. Higher DSR values indicate better performance in defending against adversarial attacks. The three subfigures (a), (b), and (c) show the results against three different red-teaming attacks: SneakyPrompt, Ring-A-Bell, and Concept Inversion, respectively. The top-right corner represents the ideal scenario where the model successfully removes nudity while maintaining the generation quality of safe images. DUO demonstrates better performance than the other three methods, especially for SneakyPrompt and Ring-A-Bell.
read the caption
Figure 4: Quantitative result on nudity. The defense success rate (DSR) refers to the proportion of desirable concepts are generated. Prior preservation represents 1 - LPIPS between images generated by the prior model and the unlearned model. Results closer to the top right indicate better outcomes.

🔼 This figure shows the qualitative results of the proposed DUO method and other baseline methods on nudity removal. Images generated using Ring-A-Bell and Concept Inversion adversarial attacks are presented. The results visually demonstrate DUO’s ability to effectively remove nudity while preserving the overall image quality and structure, unlike other methods.
read the caption
Figure 5: Qualitative result on nudity. We used β = 500 for Ring-A-bell and β = 250 for Concept Inversion. We use for publication purposes.

🔼 This figure compares image generation results from the original Stable Diffusion model (top row) and the model after applying the Direct Unlearning Optimization (DUO) method to remove nudity (bottom two rows). The images are generated using prompts from the MS COCO validation dataset. Each column represents the same prompt and initial noise, highlighting how DUO affects the generated image while trying to preserve the original model’s capability for generating other unrelated concepts. The comparison shows the effectiveness of DUO in removing nudity while maintaining visual similarity to the original images.
read the caption
Figure 6: Qualitative result on prior preservation. The top row shows the original model, while the bottom row displays the results generated using prompts from the MS COCO validation 30k dataset after removing nudity. The same column uses the same initial noise and the same prompt.

🔼 This figure presents a quantitative comparison of different unlearning methods (DUO, ESD, UCE, SPM) on their ability to defend against adversarial attacks targeting nudity in generated images. The x-axis represents the degree of prior preservation (1-LPIPS), indicating how well the model retains its original image generation capabilities after unlearning. The y-axis shows the defense success rate (DSR), which measures the percentage of generated images that successfully avoid producing nudity. The top-right corner represents the ideal scenario: high defense success rate with minimal loss of prior image generation quality. The plot illustrates the performance trade-off between these two aspects for each method.
read the caption
Figure 4: Quantitative result on nudity. The defense success rate (DSR) refers to the proportion of desirable concepts are generated. Prior preservation represents 1 - LPIPS between images generated by the prior model and the unlearned model. Results closer to the top right indicate better outcomes.

🔼 This figure shows the qualitative results of applying different unlearning methods (ESD, UCE, SPM, and DUO) on nudity removal using two different attack methods: Ring-A-Bell and Concept Inversion. The left side shows results for Ring-A-Bell attack, and the right side for Concept Inversion attack. Each column represents the results from a different model. The top row uses images from the SD1.4v model, which is the original model without any unlearning applied. Subsequent rows display images generated using the same prompt, but after applying each respective unlearning method. The green box highlights the results of the proposed DUO method. DUO successfully removes explicit nudity from the generated images while preserving the overall image quality.
read the caption
Figure 5: Qualitative result on nudity. We used β = 500 for Ring-A-bell and β = 250 for Concept Inversion. We use for publication purposes.

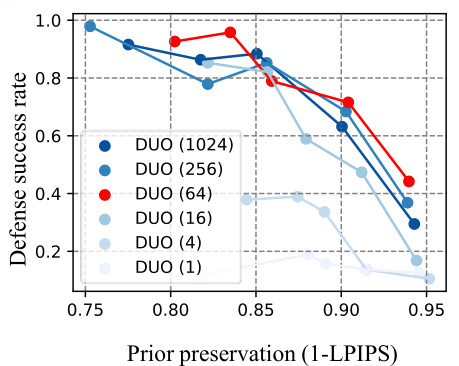
🔼 This ablation study investigates the effect of the output preservation regularization term (λ) in the DUO model. It compares the performance of DUO with (λ = 1e6) and without (λ = 0) this regularization term. The plot shows the defense success rate against the prior preservation. The results indicate that adding the output preservation regularization significantly improves the prior preservation while maintaining a relatively high defense success rate. This suggests that the regularization term is crucial for balancing the trade-off between forgetting unsafe concepts and preserving the model’s prior knowledge.
read the caption
Figure 9: Ablation study on output preserving regularization (Ring-A-Bell). Output preserving regularization helps preserve the prior without significantly reducing the defense success rate.

🔼 This figure shows a comparison of image generation results between the original Stable Diffusion model and the model after applying the proposed Direct Unlearning Optimization (DUO) method for removing nudity. The top row displays images generated by the original model, showcasing the presence of nudity. The bottom row displays images generated by the DUO-trained model using the same prompts and initial noise conditions. This illustrates the model’s ability to remove nudity while preserving other visual features and overall image quality.
read the caption
Figure 6: Quantitative result on prior preservation. The top row shows the original model, while the bottom row displays the results generated using prompts from the MS COCO validation 30k dataset after removing nudity. The same column uses the same initial noise and the same prompt.
🔼 This figure displays a quantitative analysis of the model’s performance on nudity removal, comparing different methods. The x-axis represents ‘Prior Preservation’, measured as 1 minus the Learned Perceptual Image Patch Similarity (LPIPS) score between the original and unlearned model, indicating how well the model retains its ability to generate images unrelated to the target concept (nudity). A higher value implies better preservation. The y-axis shows the ‘Defense Success Rate’ (DSR), which is the proportion of generated images that successfully avoid nudity. The figure compares four different methods, showing how well they balance prior preservation and successful defense against NSFW content generation. Points towards the top-right indicate a better balance between preserving general image generation capabilities and successfully removing nudity.
read the caption
Figure 4: Quantitative result on nudity. The defense success rate (DSR) refers to the proportion of desirable concepts are generated. Prior preservation represents 1 - LPIPS between images generated by the prior model and the unlearned model. Results closer to the top right indicate better outcomes.
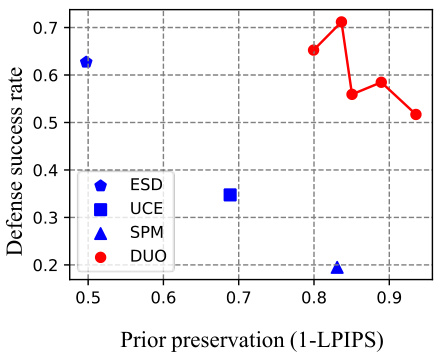
🔼 This figure shows the quantitative results of the proposed Direct Unlearning Optimization (DUO) method and three baseline methods (ESD, UCE, and SPM) for removing nudity from images. The x-axis represents the degree of prior preservation (calculated as 1 - LPIPS score, where lower LPIPS indicates higher similarity to the original model), and the y-axis represents the defense success rate (DSR). Higher DSR values imply better performance in blocking adversarial attacks trying to generate unsafe content. The results suggest that DUO outperforms the baseline methods, demonstrating a higher DSR while maintaining good prior preservation.
read the caption
Figure 4: Quantitative result on nudity. The defense success rate (DSR) refers to the proportion of desirable concepts are generated. Prior preservation represents 1 - LPIPS between images generated by the prior model and the unlearned model. Results closer to the top right indicate better outcomes.

🔼 This figure shows the quantitative results of the proposed Direct Unlearning Optimization (DUO) method on the nudity concept. It compares DUO’s performance against three other state-of-the-art unlearning methods (ESD, UCE, SPM) using three different adversarial attack methods (SneakyPrompt, Ring-A-Bell, Concept Inversion). The x-axis represents the prior preservation (measured by 1-LPIPS), indicating how well the model retains its ability to generate images unrelated to the concept being unlearned. The y-axis represents the defense success rate (DSR), showing the proportion of images generated that do not contain the nudity concept. Higher values on both axes indicate better performance, with the ideal outcome being a point in the top right corner of the graph. The figure demonstrates that DUO achieves a high defense success rate while maintaining good prior preservation.
read the caption
Figure 4: Quantitative result on nudity. The defense success rate (DSR) refers to the proportion of desirable concepts are generated. Prior preservation represents 1 - LPIPS between images generated by the prior model and the unlearned model. Results closer to the top right indicate better outcomes.

🔼 This figure shows the results of generating images of concepts closely related to the removed unsafe concepts (nudity and violence) after applying the DUO method. The goal is to demonstrate that the model retains the ability to generate images of safe concepts that share visual similarity with the removed unsafe concepts, indicating that the model doesn’t broadly forget related concepts, only the explicitly targeted unsafe ones. The top row shows the original Stable Diffusion 1.4v’s generation of ‘man’ and ‘woman’ (for nudity) followed by the DUO model’s output for the same prompt to illustrate it’s capacity to preserve related non-offensive concepts. The bottom row showcases a similar comparison but for ‘ketchup,’ ‘strawberry jam,’ and ’tomato sauce’ after removing the violence concept.
read the caption
Figure 15: Qualitative result on generating close concept related to removed concept. (a) Results of generating 'man' and 'woman' after removing nudity. (b) Results of generating 'ketchup', 'strawberry jam' and 'tomato sauce' after removing violence.

🔼 This figure demonstrates the model’s ability to generate images of concepts that are visually similar to the removed unsafe concepts, while maintaining generation quality. The top row shows results for nudity removal, and the bottom row shows results for violence removal. The leftmost column shows the original image generated by the unmodified model. The following columns show the outputs of the unlearning methods, showing their ability to remove the unwanted concept while preserving related safe ones.
read the caption
Figure 15: Qualitative result on generating close concept related to removed concept. (a) Results of generating 'man' and 'woman' after removing nudity. (b) Results of generating 'ketchup', 'strawberry jam' and 'tomato sauce' after removing violence.
🔼 This figure shows the quantitative results of the proposed DUO method on nudity removal, comparing it against three existing methods (ESD, UCE, and SPM). The x-axis represents the prior preservation (1 - LPIPS score), which measures how well the model retains its ability to generate images unrelated to nudity. The y-axis is the defense success rate (DSR), indicating the proportion of generated images that successfully avoid producing nudity. Higher values on both axes are desirable; a point in the top right indicates high prior preservation and high success at preventing the generation of nudity. The graph demonstrates DUO’s superior performance across various red-teaming attack methods in terms of both defense success and prior preservation.
read the caption
Figure 4: Quantitative result on nudity. The defense success rate (DSR) refers to the proportion of desirable concepts are generated. Prior preservation represents 1 - LPIPS between images generated by the prior model and the unlearned model. Results closer to the top right indicate better outcomes.

🔼 This figure displays a qualitative comparison of image generation results before and after applying the DUO method for nudity removal. The top row shows images generated by the original Stable Diffusion model (SD1.4v), while the bottom row shows images generated by the model after undergoing the unlearning process using DUO. Each column represents the same prompt and initial noise, allowing for a direct comparison of the model’s output before and after unlearning. The goal is to demonstrate the preservation of the model’s ability to generate images for unrelated concepts while removing the unwanted nudity concept.
read the caption
Figure 6: Qualitative result on prior preservation. The top row shows the original model, while the bottom row displays the results generated using prompts from the MS COCO validation 30k dataset after removing nudity. The same column uses the same initial noise and the same prompt.
More on tables
🔼 This table presents the Fréchet Inception Distance (FID) and CLIP similarity (CS) scores for violence removal experiments using different methods. Lower FID indicates better image quality, while higher CS represents better semantic similarity. The results show the FID and CS scores for the original Stable Diffusion 1.4v model (SD 1.4v) and for models trained using the ESD, UCE, SPM, and DUO methods (with β= 1000 and β = 500). It compares the performance of the different models on the task of removing violent content while preserving the quality of images in unrelated contexts.
read the caption
Table 2: FID and CLIP score (CS) for violence.

🔼 This table presents the results of an ablation study evaluating the impact of unlearning on the generation of visually similar concepts. It shows the mean and standard deviation of the Learned Perceptual Image Patch Similarity (LPIPS) scores, calculated between 128 images generated by the unlearned models and the pre-trained model. The lower LPIPS scores indicate less impact on the generation of visually similar but safe concepts, demonstrating the effectiveness of the proposed method in preserving the model’s ability to generate safe content even after unlearning of unsafe concepts.
read the caption
Table 3: Impact of unlearning on visually similar concept generation. We report mean ± standard devidation of LPIPS scores between 128 images generated from the unlearned model and the pretrained model.

🔼 This table presents the Fréchet Inception Distance (FID) scores for Stable Diffusion 3 (SD3) models trained with and without the proposed Direct Unlearning Optimization (DUO) method. Lower FID scores indicate better image generation quality. The table shows FID scores for the original SD3 model and for models trained with DUO using different values of the hyperparameter β (beta). The comparison highlights the impact of DUO on the model’s ability to generate images that avoid nudity without significantly sacrificing overall image quality.
read the caption
Table 4: FID for SD3 unlearned nudity.
Full paper#