↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
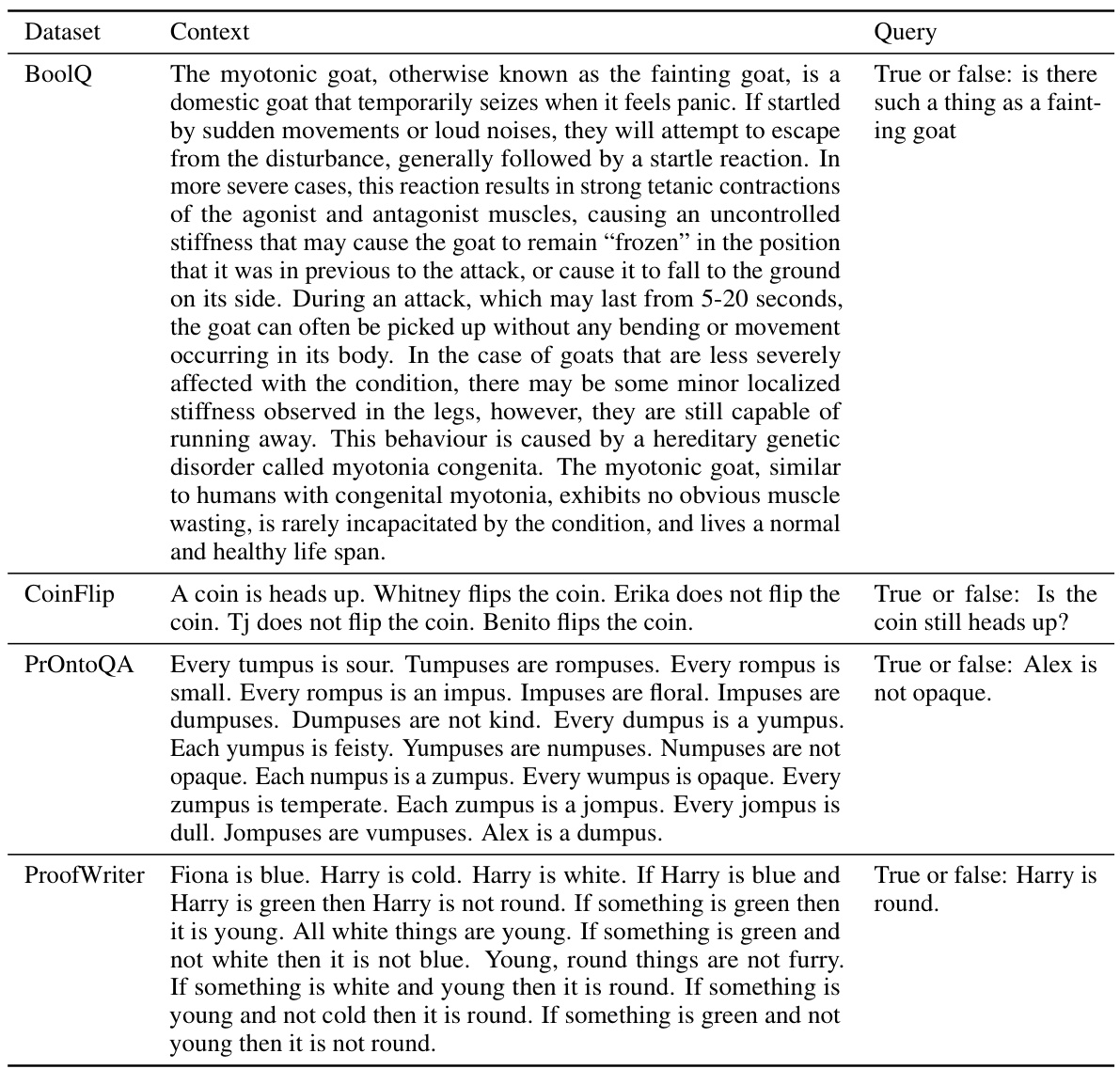
Large language models (LLMs), aided by techniques like chain-of-thought prompting, have shown impressive reasoning abilities. However, these models frequently generate contradictory or erroneous outputs, raising concerns about their reliability. This paper investigates the internal workings of LLMs to understand how these inconsistencies arise, focusing on the relationship between generated rationales and the model’s internal representations. The analysis reveals that inconsistencies emerge between the model’s internal representations at different layers, potentially undermining the reliability of its reasoning process.
To address this issue, the researchers propose using internal consistency as a measure of model confidence by assessing the agreement of predictions from intermediate layers. Experiments demonstrate that high internal consistency effectively distinguishes correct from incorrect reasoning. Based on this, the paper proposes a calibration method that up-weights reasoning paths with high internal consistency, significantly improving reasoning performance. This work highlights the potential of using internal representations for LLM self-evaluation and suggests a novel approach to calibrate LLM reasoning.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel method for calibrating reasoning in large language models (LLMs), a critical area of current research. By identifying and addressing inconsistencies in LLMs’ internal representations, the study offers insights into enhancing the reliability of LLM reasoning. This opens avenues for future research into improving LLM self-evaluation and developing more robust and trustworthy AI systems. The proposed internal consistency measure is particularly valuable as it’s an off-the-shelf method, requiring no additional training.
Visual Insights#
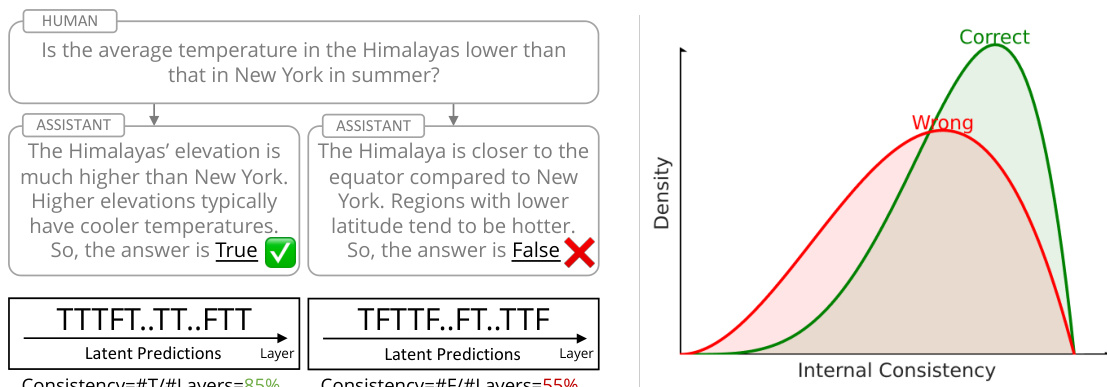
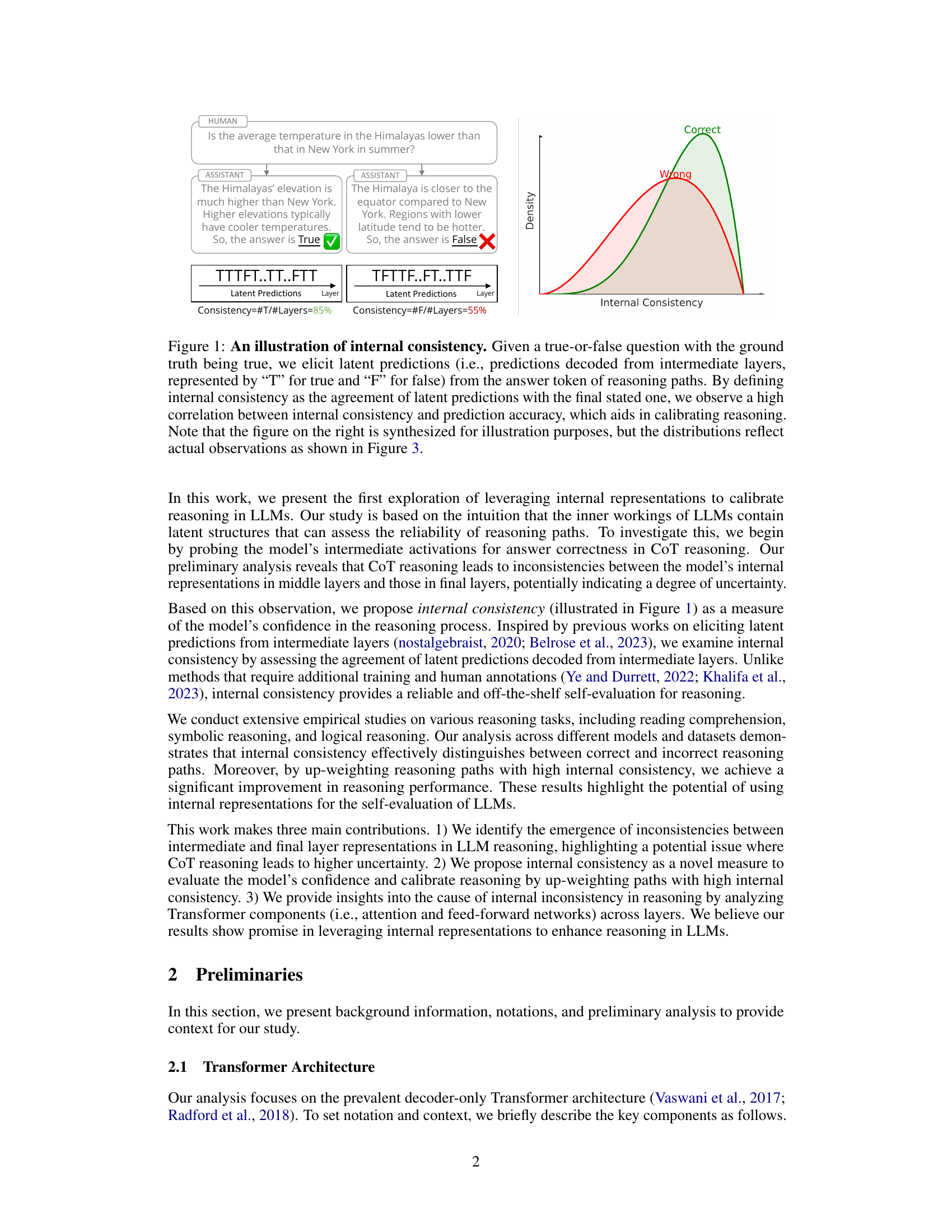
This figure illustrates the concept of internal consistency using a true/false question example. Two different reasoning paths are shown, one leading to a correct answer and the other to an incorrect answer. Latent predictions (predictions from intermediate layers of the model) are decoded, and internal consistency is calculated as the agreement between these latent predictions and the final prediction. The figure shows that higher internal consistency correlates with higher prediction accuracy, forming the basis of a method to calibrate reasoning in large language models.
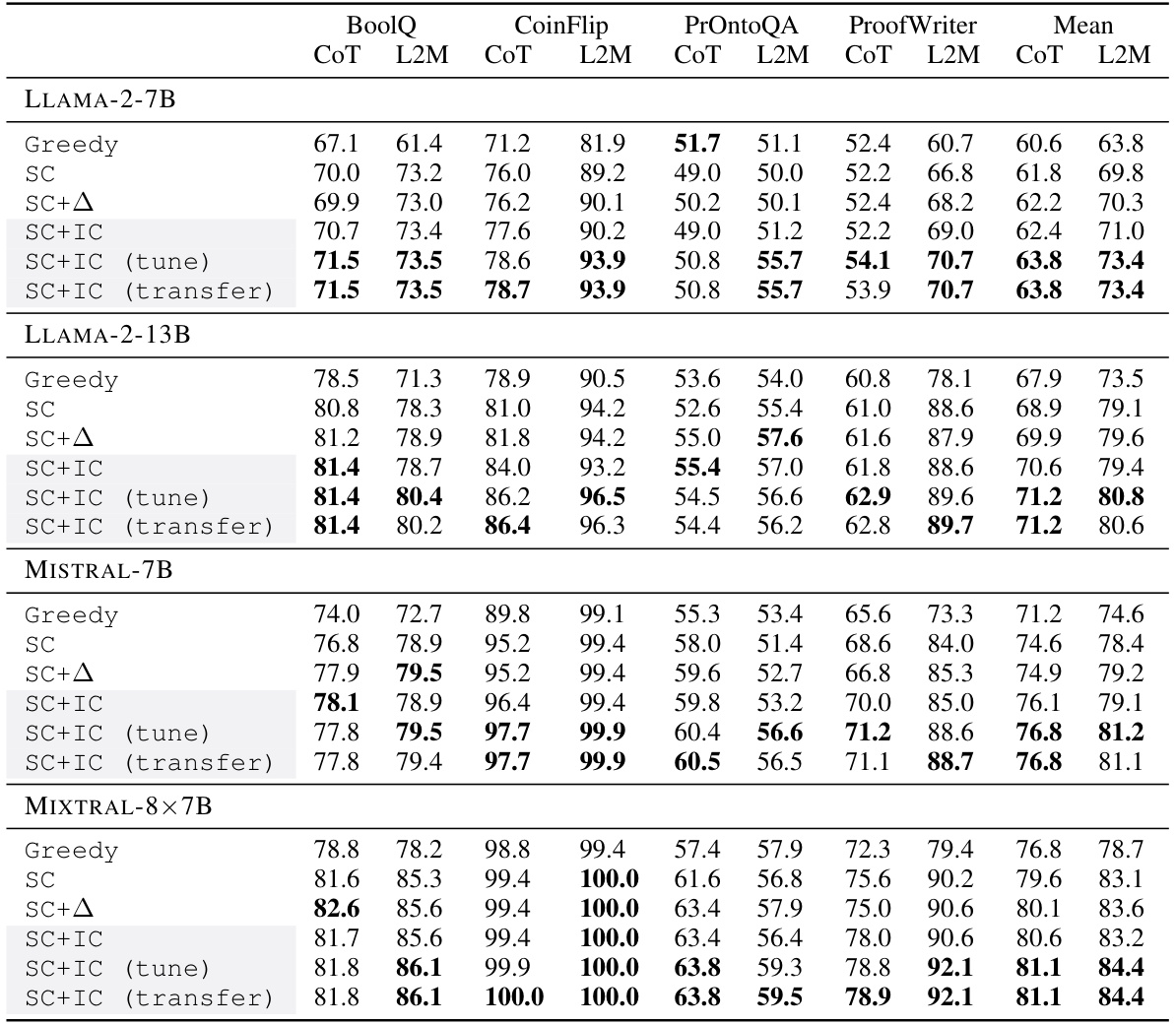
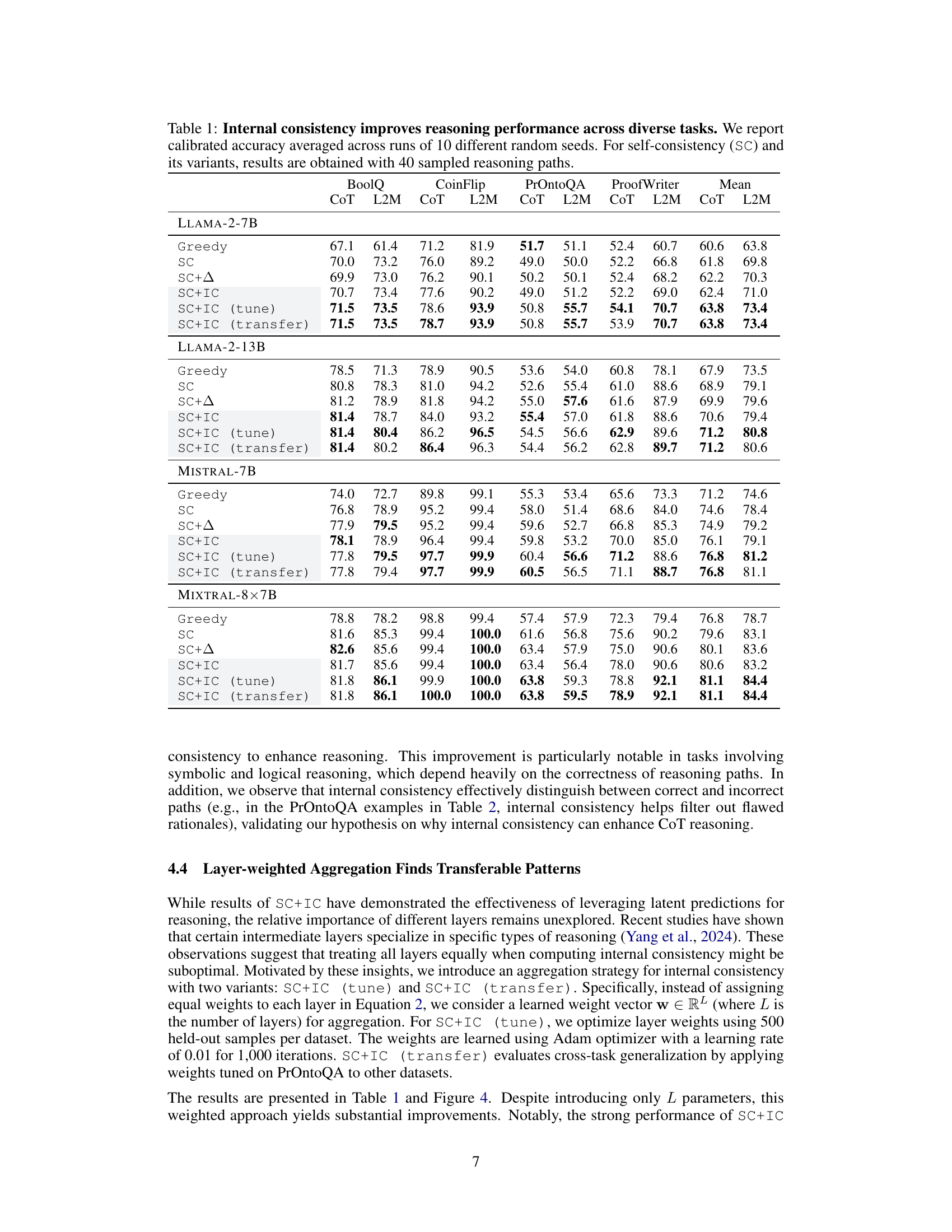
This table presents the calibrated accuracy results for different LLMs (Llama-2-7B, Llama-2-13B, Mistral-7B, Mistral-8x7B) across various reasoning tasks (BoolQ, CoinFlip, PrOntoQA, ProofWriter). The table compares the performance of several methods: Greedy decoding, Self-Consistency (SC), SC with logit-based calibration (SC+Δ), and Self-Consistency with Internal Consistency calibration (SC+IC). Three variants of SC+IC are included: SC+IC (tune) which uses tuned layer weights, and SC+IC (transfer) that transfers those weights across tasks. The results demonstrate the improvement in reasoning performance when using internal consistency for calibration.
In-depth insights#
LLM Reasoning#
LLM reasoning, while showing impressive capabilities in various tasks, is notoriously unreliable. Chain-of-thought prompting, while improving accuracy, introduces inconsistencies between intermediate and final layer representations. This suggests that LLMs may not fully utilize information gathered during intermediate reasoning steps, potentially undermining the reliability of their conclusions. The paper introduces internal consistency as a novel metric to assess the reliability of reasoning paths, demonstrating a strong correlation between high internal consistency and accuracy. By weighting reasoning paths based on their internal consistency, the authors achieve significant performance improvements in diverse reasoning tasks, highlighting the potential of leveraging internal representations for self-evaluation and calibration of LLMs. This approach provides a valuable, off-the-shelf method for improving reasoning without requiring additional training or human annotations.
Internal Consistency#
The concept of “Internal Consistency” in the context of large language models (LLMs) centers on evaluating the agreement between a model’s intermediate reasoning steps and its final prediction. High internal consistency indicates a robust and reliable reasoning process, suggesting a greater confidence in the final answer. Conversely, inconsistencies between intermediate and final layers raise doubts about the model’s reasoning reliability, potentially highlighting flawed rationales or uncertainty. The authors propose using internal consistency as a metric to gauge the confidence of LLMs, which can be leveraged to improve model performance by up-weighting consistent reasoning paths. This approach offers a unique perspective on LLM calibration, moving beyond simply examining the alignment between verbalized rationales and final answers. By directly analyzing internal representations, the method provides an intrinsic measure of reasoning quality, offering a novel self-evaluation mechanism for LLMs that doesn’t require additional training or human annotation.
Calibration Methods#
Calibration methods are crucial for improving the reliability of large language models (LLMs), especially in reasoning tasks. Internal consistency, a novel approach, assesses the agreement of latent predictions from intermediate layers, effectively identifying reliable reasoning paths. This method is advantageous because it is off-the-shelf, requiring no additional training or human annotation. By up-weighting reasoning paths with high internal consistency, significant improvements in reasoning performance are achieved. Traditional calibration methods, while effective, often rely on additional training, making them less adaptable and computationally expensive. The effectiveness of internal consistency highlights the potential of leveraging internal representations within LLMs for self-evaluation and improved reasoning capabilities, while also offering a more efficient alternative to existing techniques. Further research should investigate the generalizability of this method to various model architectures and the exploration of alternative measures of internal consistency.
Transformer Analysis#
A thoughtful analysis of a research paper’s section on Transformers would delve into the specific aspects examined. Did the analysis focus on the attention mechanism, exploring its role in capturing relationships between words and sentences? Were specific layers of the Transformer dissected to determine their contributions to overall performance? Perhaps the study examined the impact of different activation functions or the effect of hyperparameter tuning on model behavior. A comprehensive evaluation would also address how the analysis compared the Transformer architecture’s performance to other model architectures, highlighting its strengths and weaknesses. Detailed visualizations, such as heatmaps of attention weights or activation patterns, would be crucial elements to assess the effectiveness of the analysis, demonstrating a clear understanding of the Transformer’s inner workings.
Future Work#
Future research could explore several promising directions. Extending the internal consistency framework to encoder-decoder models is crucial, as many real-world applications involve both encoding and decoding processes. This requires adapting the methodology to capture latent representations from the encoder as well. Investigating various prompting techniques beyond chain-of-thought would reveal if internal consistency remains a robust metric across diverse reasoning paradigms. The impact of model size and architecture on internal consistency also warrants deeper investigation. Analyzing the influence of specific Transformer components (attention, feed-forward networks) across diverse tasks can offer valuable insights into the emergence of inconsistencies. Developing more sophisticated calibration methods that leverage internal consistency, such as weighted path integration schemes, could enhance reasoning accuracy further. Finally, exploring the application of this work to other LLMs beyond those evaluated is important to ascertain the generalizability and robustness of the findings.
More visual insights#
More on figures
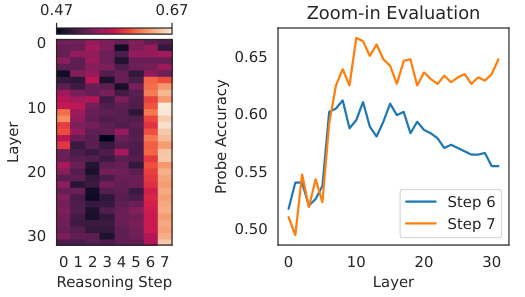
This figure shows the results of probing experiments on the Llama-2-7B model using the PrOntoQA dataset. The left panel is a heatmap showing the accuracy of linear probes trained on different layers of the model at each reasoning step during chain-of-thought (CoT) prompting. The right panel zooms in on the last two reasoning steps to highlight the increasing discrepancy between the probe accuracies of middle and later layers, suggesting inconsistencies in the model’s internal representation during CoT reasoning. The improved accuracy through verbalized reasoning is also shown.
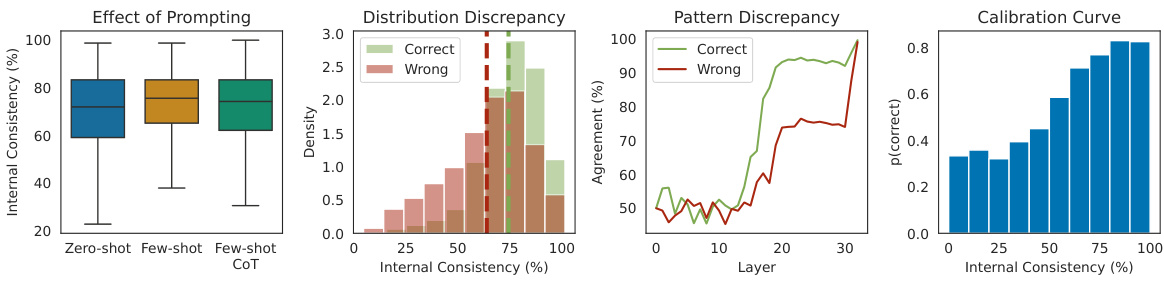
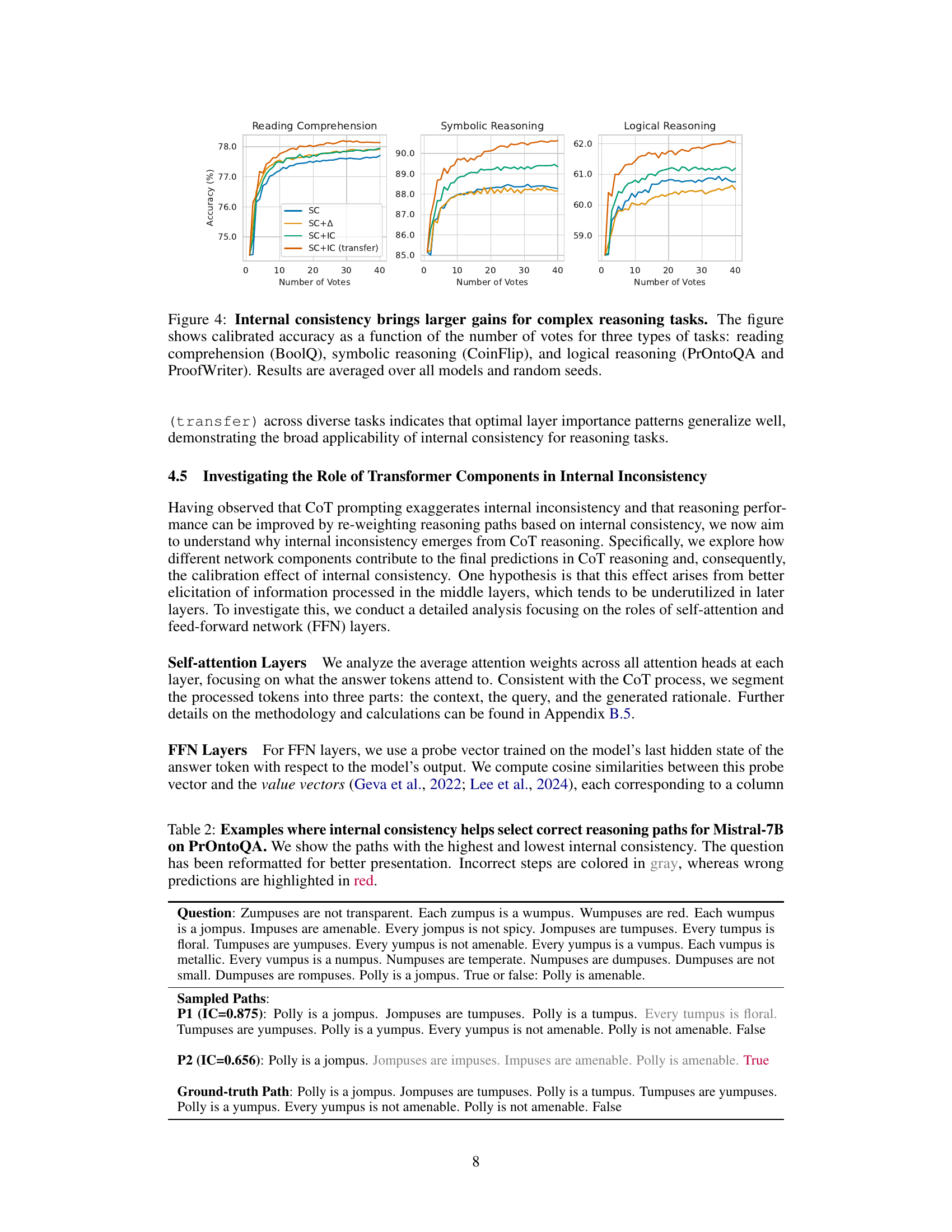
This figure demonstrates the correlation between internal consistency and the accuracy of predictions in chain-of-thought (CoT) reasoning. It shows how internal consistency, measured by the agreement of latent predictions from different layers, effectively distinguishes between correct and incorrect reasoning paths. The figure includes four subplots illustrating: (1) the impact of different prompting techniques (zero-shot, few-shot, CoT) on internal consistency; (2) the distribution of internal consistency for correct versus incorrect predictions; (3) how the agreement of latent predictions changes across different layers; and (4) a calibration curve showing the relationship between internal consistency and prediction accuracy. These results highlight the value of internal consistency as a reliable metric for evaluating and improving reasoning in large language models.
This figure demonstrates the strong correlation between internal consistency and the model’s prediction accuracy in Chain-of-Thought (CoT) reasoning. It shows how different prompting methods affect internal consistency, the discrepancies in internal consistency between correct and incorrect answers, the patterns of consistency across different layers, and a calibration curve showing the relationship between internal consistency and accuracy.
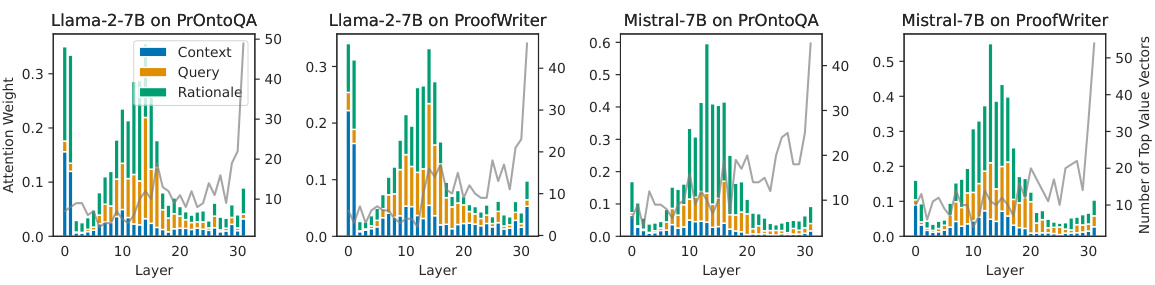
This figure displays the attention weights across different layers of the model for context, query, and rationale. The gray line represents the number of value vectors in the feed-forward network (FFN) layers that are highly similar to the model’s final prediction. The misalignment between layers with high attention on critical tokens and those promoting specific predictions is highlighted as a possible cause for internal inconsistency in chain-of-thought (CoT) reasoning.
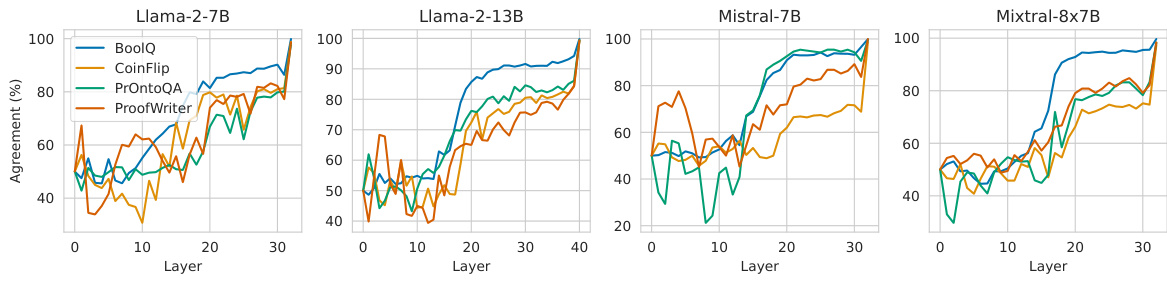
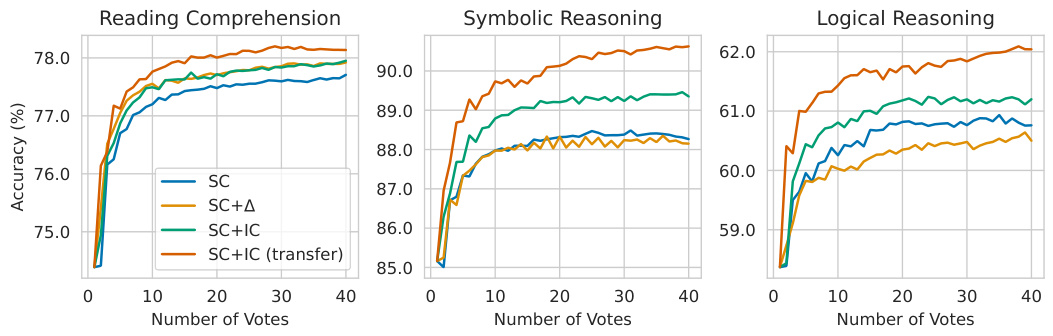
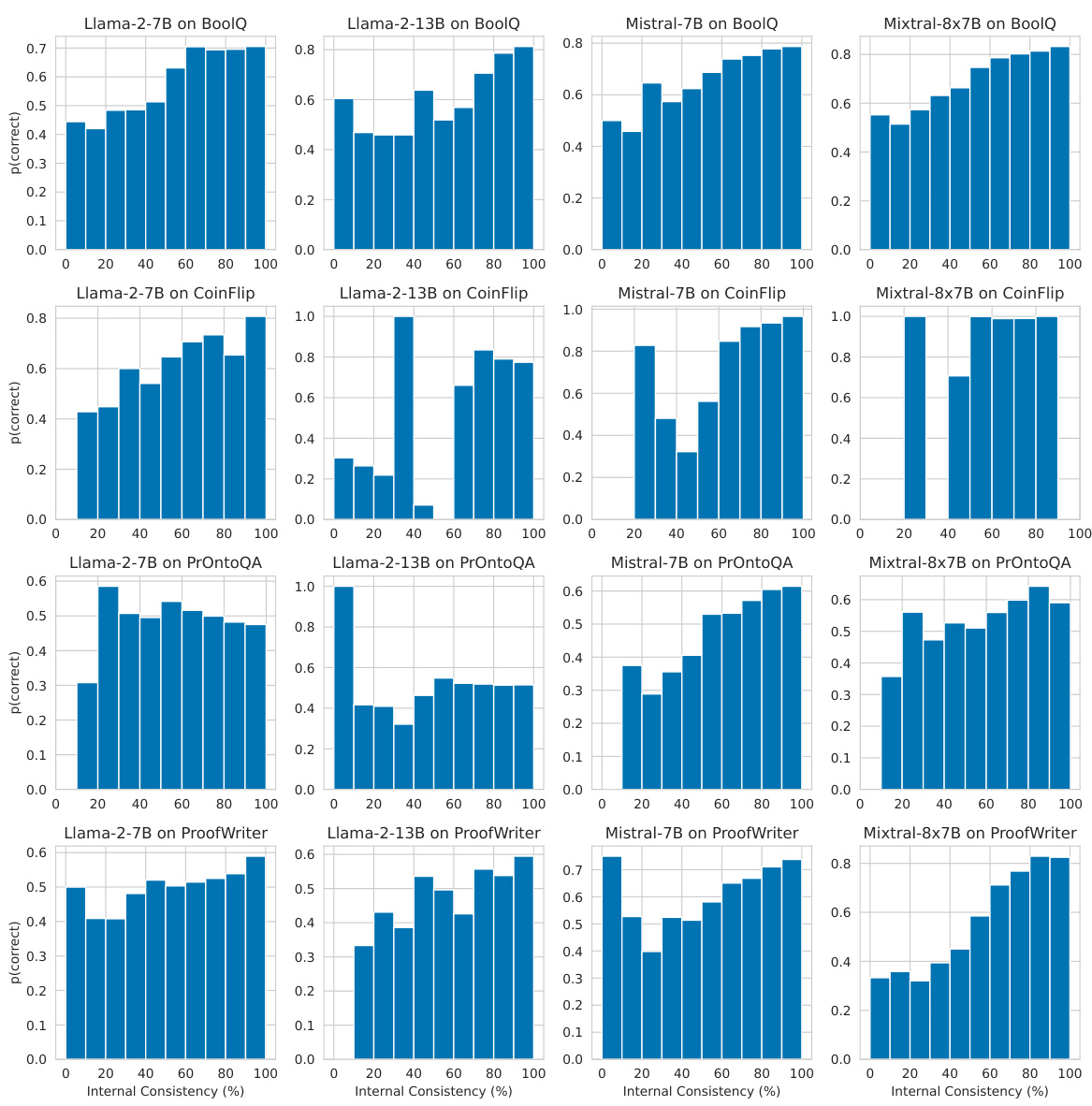
This figure displays the patterns of internal consistency across different tasks and models. The y-axis shows the ‘agreement’, representing the ratio of data instances where the latent predictions from intermediate layers match the model’s final predictions. The x-axis represents the layer number. The plot reveals that the patterns of internal consistency are largely consistent across the various models (Llama-2-7B, Llama-2-13B, Mistral-7B, Mixtral-8x7B) and datasets (BoolQ, CoinFlip, PrOntoQA, ProofWriter), indicating a general trend in how internal consistency behaves during the reasoning process. The zero-shot prompting setting was used for these results.
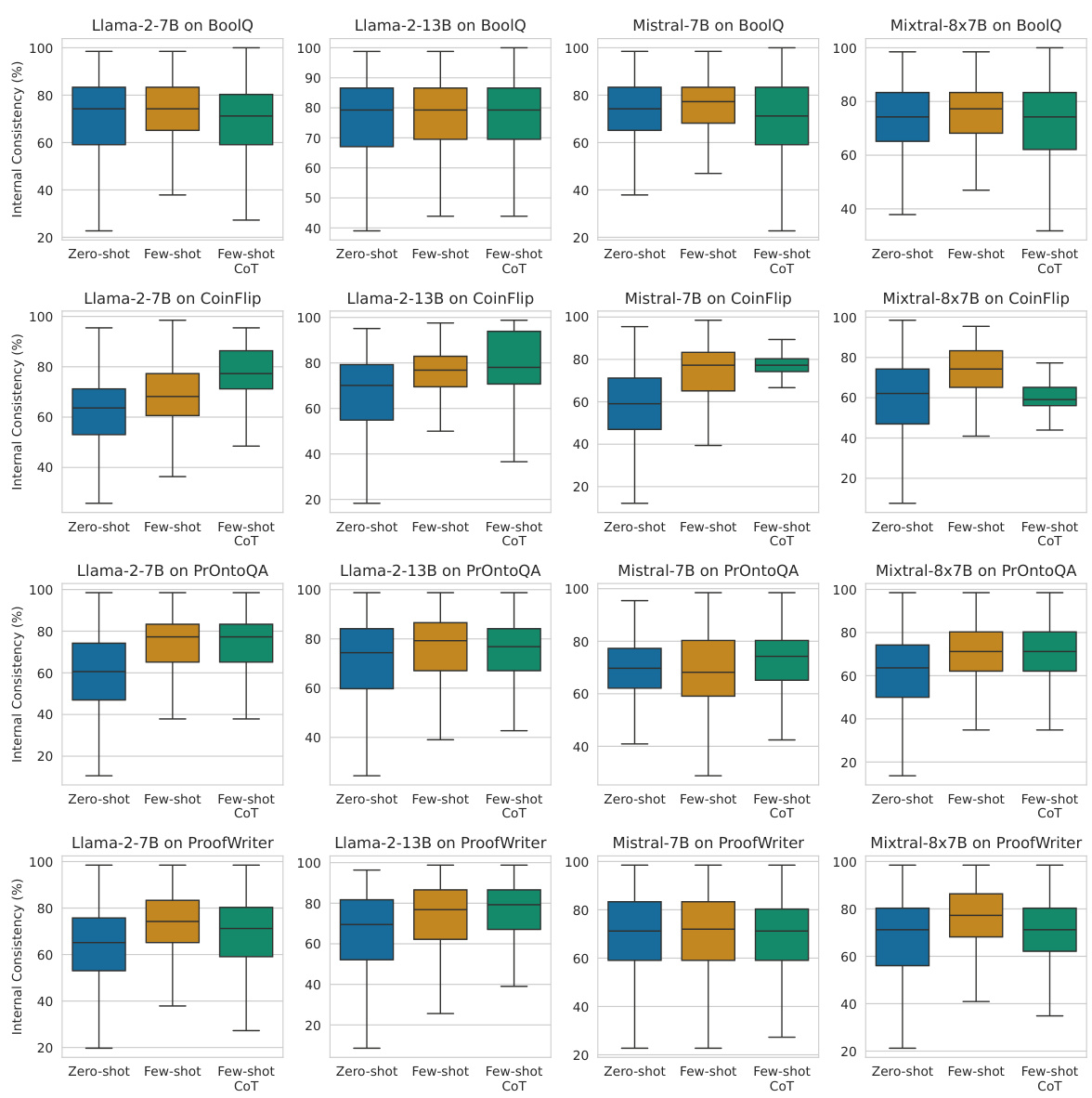
This figure presents four subplots that illustrate different aspects of the relationship between internal consistency and the accuracy of chain-of-thought (CoT) reasoning in large language models (LLMs). The first subplot shows the effect of different prompting techniques (zero-shot, few-shot, and CoT) on the model’s internal consistency. The second subplot shows the distribution of internal consistency scores for correct and incorrect predictions. The third subplot shows the pattern of agreement between latent predictions from different layers, highlighting how consistency increases in later layers. The fourth subplot shows a calibration curve, demonstrating that higher internal consistency is associated with higher prediction accuracy. Overall, the figure demonstrates that internal consistency is a reliable measure of prediction confidence in CoT reasoning.
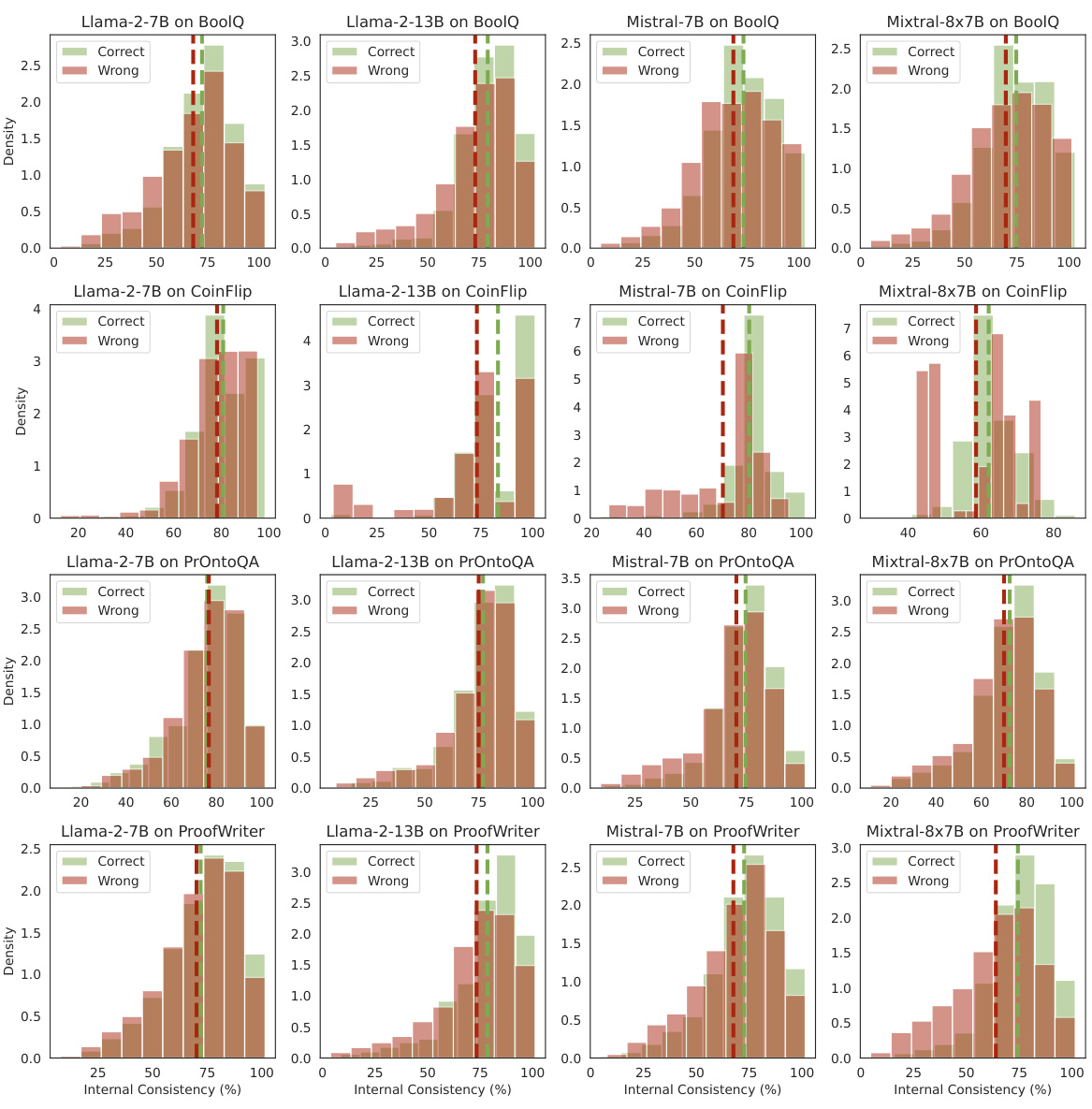
This figure provides a comprehensive analysis of internal consistency in chain-of-thought (CoT) reasoning. It shows how internal consistency, a measure of agreement between intermediate and final layer predictions, correlates with prediction accuracy. The four panels illustrate (1) the impact of different prompting techniques on consistency, (2) the difference in consistency between correct and incorrect predictions, (3) the variation of consistency across different layers, and (4) a calibration curve demonstrating the relationship between consistency and accuracy. The results are averaged across various LLMs and datasets, with detailed results in Appendix C.

This figure presents four subplots that show different aspects of internal consistency. The first subplot shows how different prompting methods (zero-shot, few-shot, and chain-of-thought) affect internal consistency. The second subplot illustrates the difference in the distribution of internal consistency scores between correct and incorrect predictions. The third subplot displays the pattern of agreement values across different layers of the model. Finally, the fourth subplot presents a calibration curve showing the relationship between internal consistency and prediction accuracy.
This figure presents a comprehensive evaluation of internal consistency as a measure of prediction confidence in chain-of-thought (CoT) reasoning. It demonstrates the correlation between internal consistency and reasoning accuracy across various models and datasets, highlighting its effectiveness in identifying correct and incorrect reasoning paths. The figure includes four subplots showing: 1. The impact of different prompting techniques on internal consistency. 2. The distribution difference of internal consistency between correct and incorrect predictions. 3. The changes in the agreement rate (latent predictions matching final prediction) across layers. 4. A calibration curve visualizing the relationship between internal consistency and prediction accuracy.
More on tables
This table presents the calibrated accuracy results for different LLMs (Llama-2-7B, Llama-2-13B, Mistral-7B, Mistral-8x7B) across four reasoning tasks (BoolQ, CoinFlip, PrOntoQA, ProofWriter) using different methods: Greedy decoding, self-consistency (SC), SC with logit-based approach (SC+Δ), and SC with internal consistency (SC+IC). The table showcases the performance gains achieved by incorporating internal consistency, particularly on complex reasoning tasks. The results are averaged over 10 runs, each with 40 sampled paths for SC-based methods.

This table presents the results of experiments evaluating the performance of different reasoning methods across four datasets (BoolQ, CoinFlip, PrOntoQA, ProofWriter) and two model sizes (Llama-2-7B, Llama-2-13B). The methods compared include greedy decoding, self-consistency (SC), SC with a logit-based approach (SC+∆), and self-consistency with internal consistency weighting (SC+IC). The table highlights the improvement achieved by incorporating internal consistency (SC+IC) into the self-consistency approach, demonstrating its effectiveness in improving the reliability and accuracy of LLM reasoning across diverse tasks.
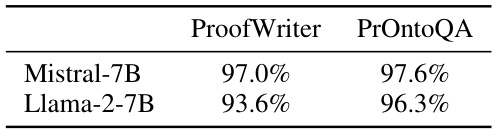
This table presents the cross-validation accuracy achieved during the training of the probe vector used in the FFN layer analysis. The probe vector is trained on the model’s last hidden state of the answer token, aiming to differentiate between correct and incorrect model predictions. The table shows results for Mistral-7B and Llama-2-7B models on two datasets: ProofWriter and PrOntoQA. High accuracy indicates effective training of the probe vector to extract relevant information from model representations.

This table presents the calibrated accuracy of different reasoning methods across various datasets and LLMs. The methods include greedy decoding, self-consistency (SC), SC with logit-based calibration (SC+Δ), and the proposed self-consistency with internal consistency (SC+IC) method and two transfer variants. The table shows that the SC+IC method consistently outperforms others across different models and datasets, demonstrating the effectiveness of incorporating internal consistency in enhancing reasoning performance. The results are averaged over 10 different random seeds and use 40 sampled reasoning paths for SC and its variants.

This table presents the results of experiments evaluating the impact of internal consistency on reasoning performance across various tasks and models. It compares the calibrated accuracy of several methods: a greedy decoding baseline, self-consistency (SC), SC augmented with a logit-based confidence measure (SC+Δ), and the proposed SC enhanced with internal consistency (SC+IC). The table also shows results with tuned and transfer learning variants of SC+IC. The tasks are BoolQ (reading comprehension), CoinFlip (symbolic reasoning), PrOntoQA and ProofWriter (logical reasoning), each using Chain-of-Thought (CoT) and Least-to-Most (L2M) prompting strategies. The table showcases the performance improvements achieved by integrating internal consistency into the reasoning process across different model sizes and prompting styles.

This table presents the results of experiments evaluating the impact of integrating internal consistency into a self-consistency (SC) approach for enhancing reasoning performance. It compares the calibrated accuracy of different methods across various reasoning tasks and language models. The methods include greedy decoding, self-consistency (SC), SC with a logit-based confidence measure (SC+Δ), and the proposed SC with internal consistency (SC+IC). The table shows that SC+IC consistently outperforms other approaches, demonstrating the effectiveness of leveraging internal consistency to improve reasoning in LLMs.

This table presents the calibrated accuracy results of different reasoning methods across various datasets and LLMs. The methods include greedy decoding, self-consistency (SC), SC with a logit-based calibration approach (SC+Δ), and the proposed self-consistency with internal consistency (SC+IC). The table shows that the SC+IC method consistently outperforms the baseline methods across all the datasets and LLMs, highlighting the effectiveness of leveraging internal consistency for enhancing reasoning performance. The table is divided into sections for different LLMs (Llama-2-7B, Llama-2-13B, Mistral-7B, Mistral-8x7B), with each section further subdivided into columns representing different datasets (BoolQ, CoinFlip, PrOntoQA, ProofWriter) and prompting methods (CoT, L2M).
Full paper#