↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Fine-tuned vision-language models (VLMs) often suffer from spurious correlations, where the model incorrectly associates image features with unrelated textual attributes, leading to poor zero-shot performance. Existing methods mainly address this issue at a global image level, neglecting fine-grained details. This limits their effectiveness in identifying and correcting the root causes of errors. Additionally, many existing solutions are designed for unimodal settings, making them unsuitable for the complex nature of VLMs.
This paper introduces RAVL, a novel region-aware approach that tackles spurious correlations in fine-tuned VLMs from a fine-grained perspective. RAVL first identifies spurious correlations by clustering local image features and assessing their contribution to classification errors. Then, it mitigates these correlations using a region-aware loss function that encourages the VLM to focus on relevant regions and ignore spurious relationships during fine-tuning. Extensive evaluation across numerous VLMs with various architectures, data domains, and spurious correlations demonstrates RAVL’s superior accuracy in discovering and mitigating these correlations compared to state-of-the-art baselines, resulting in improved zero-shot performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with vision-language models (VLMs) because it introduces a novel method to identify and mitigate spurious correlations, a significant problem affecting VLM performance and reliability. The findings are directly applicable to improving VLM robustness and generalization, which are important current research trends. The large-scale evaluation framework developed in the paper also provides a valuable resource for future research in this area.
Visual Insights#

🔼 The figure illustrates the two-stage process of RAVL. Stage 1 (Discovery) focuses on identifying spurious correlations learned by a fine-tuned Vision-Language Model (VLM). It uses a region-level clustering approach to pinpoint image features contributing to zero-shot classification errors, specifically highlighting spurious correlations between image features (like flowers) and textual attributes (like ‘butterfly’). Stage 2 (Mitigation) aims to mitigate these identified spurious correlations using a novel region-aware loss function. This loss function encourages the VLM to concentrate on relevant regions during fine-tuning while ignoring the spurious relationships.
read the caption
Figure 1: Region-aware Vision-Language learning (RAVL). RAVL takes a fine-grained perspective on VLM robustness by discovering and mitigating spurious correlations using local image features.

🔼 This table presents the mean Precision@10 scores for different methods in discovering spurious correlations across 654 evaluation settings with varying correlation strengths (Teval). RAVL consistently achieves higher precision than other methods (Random, Distilling Failures, George, Domino, and Spurious-Aware Detection) across all correlation strengths, demonstrating its superior performance in identifying spurious correlations.
read the caption
Table 1: Mean Precision@10 metrics demonstrate the efficacy of RAVL in discovering spurious correlations. On average across 654 evaluation settings, RAVL consistently outperforms baselines.
In-depth insights#
Spurious Correlation#
Spurious correlations in machine learning, particularly within vision-language models (VLMs), pose a significant challenge to model robustness and generalization. These spurious correlations, where the model learns to associate unrelated image features with textual attributes, lead to degraded zero-shot performance at test time. Addressing this requires methods that move beyond global image-level analysis, instead focusing on fine-grained image features. Identifying these spurious relationships often requires careful analysis of feature clusters to pinpoint the specific image components driving erroneous classifications. Successfully mitigating these correlations needs strategies that allow the model to focus on genuine image-text relationships while ignoring the spurious connections during training, possibly achieved through novel loss functions that incorporate region-level information. The effective detection and mitigation of spurious correlations are crucial for improving the overall reliability and dependability of VLMs.
RAVL Framework#
The RAVL framework is a novel, two-stage approach designed to improve the robustness of fine-tuned vision-language models (VLMs) by addressing spurious correlations. Stage 1 focuses on discovering these correlations at a fine-grained, region-level, rather than a global image-level. This granular approach uses region-level clustering to pinpoint specific image features contributing to classification errors, offering a more precise understanding of the learned spurious relationships than prior methods. Stage 2 leverages this discovery to mitigate the spurious correlations during fine-tuning, introducing a novel region-aware loss function that prioritizes relevant image regions while suppressing the influence of those spuriously correlated features. The framework’s comprehensive evaluation using synthetic and real-world datasets, along with comparisons to existing methods, highlights its effectiveness in accurately identifying and mitigating spurious correlations. This ultimately leads to improved zero-shot performance on downstream tasks. The methodology demonstrates significant improvements over existing techniques, paving the way for more robust and reliable VLMs.
Fine-Grained Robustness#
Fine-grained robustness, in the context of vision-language models (VLMs), signifies a system’s resilience to spurious correlations at a detailed feature level. Unlike coarse-grained approaches focusing on global image characteristics, fine-grained analysis dives into specific image regions and features, identifying precisely which contribute to erroneous zero-shot classifications. This granular perspective allows for more targeted interventions during model training, enabling the VLM to learn robust features while ignoring misleading cues. The key advantage lies in improved interpretability, as understanding exactly which image aspects cause errors allows for more effective mitigation strategies. This leads to improved zero-shot performance, especially in challenging out-of-domain settings. RAVL exemplifies fine-grained robustness by first identifying spurious feature clusters through region-level clustering and then utilizing a region-aware loss function to guide the model toward learning relevant visual-textual relationships. This approach is crucial for building robust VLMs that generalize well beyond their training data, enhancing trust and reliability.
Mitigation Strategies#
Mitigation strategies for spurious correlations in vision-language models (VLMs) are crucial for improving robustness and generalization. Existing methods often operate at a global image level, failing to address fine-grained spurious correlations. This paper proposes a region-aware approach that first identifies precise image features contributing to errors via a clustering method. Then, a novel region-aware loss function is introduced during fine-tuning. This loss encourages the model to focus on relevant image regions while ignoring spurious relationships between image features and text, thereby mitigating the effects of spurious correlations more effectively. The approach shows promising results on a large-scale evaluation, demonstrating the ability to accurately discover and effectively mitigate these correlations. Fine-grained feature analysis is a key strength, distinguishing it from prior global approaches and potentially enabling better model interpretability. However, further research could explore the sensitivity of the method to different clustering parameters and the generalization of the region-aware loss to other VLM architectures and datasets.
Future Work#
Future work could explore several promising directions. Extending RAVL to other modalities, such as audio or video, would significantly broaden its applicability and impact. Investigating the influence of different region proposal methods on RAVL’s performance is crucial for optimizing its accuracy and efficiency. A thorough comparison with other state-of-the-art spurious correlation mitigation techniques using a standardized benchmark would provide strong validation. Furthermore, research on developing more sophisticated region-aware loss functions could further improve robustness and lead to better disentanglement of spurious and genuine correlations. Finally, applying RAVL to more diverse real-world datasets, especially those with substantial class imbalance, would enhance the generalizability of the proposed method and highlight its real-world effectiveness.
More visual insights#
More on figures

🔼 This figure shows the results of comparing RAVL with other methods for discovering spurious correlations. The x-axis represents the strength of the spurious correlation, and the y-axis shows the precision@10. The figure demonstrates that RAVL significantly outperforms other methods across various correlation strengths and datasets (synthetic and real-world). Error bars represent 95% confidence intervals.
read the caption
Figure 2: RAVL accurately identifies spurious correlations. Using our evaluation settings, we show that RAVL consistently outperforms prior methods in discovering learned spurious correlations between image features and textual attributes. Here, we provide Precision@10 metrics for a CLIP-RN50 model fine-tuned on synthetic data (129 settings) and real-world data (171 settings).

🔼 This figure shows two examples of spurious correlations found by RAVL in two different pre-trained vision-language models. The first example shows that a CLIP (ViT-B/16) model trained for scene classification has learned to associate the presence of text-based retail signage with fast food restaurants. The second example shows that a PubMedCLIP (ResNet-50) model trained for chest X-ray classification has learned to associate the presence of metal clips with cardiomegaly. The zero-shot accuracy is significantly affected by the presence or absence of these spurious features.
read the caption
Figure 3: RAVL surfaces spurious correlations in off-the-shelf VLMs. RAVL identifies a spurious correlation learned by CLIP ViT-B/16 between the presence of text-based retail signage and the class label fast food restaurant in a scene classification task. RAVL also surfaces a spurious correlation learned by PubMedCLIP ResNet-50 between metal clips (found in clothing) and the class label cardiomegaly (a heart condition) on a chest X-ray classification task.

🔼 This figure illustrates the two stages of the RAVL approach. Stage 1 (Discovery) focuses on identifying spurious correlations between image features and textual attributes using a region-level clustering approach. Stage 2 (Mitigation) addresses these spurious correlations by introducing a novel region-aware loss function that encourages the VLM to focus on relevant regions and ignore spurious relationships during fine-tuning. The example shows a situation where the model incorrectly associates butterflies with flowers, highlighting the problem of spurious correlations that RAVL aims to address.
read the caption
Figure 1: Region-aware Vision-Language learning (RAVL). RAVL takes a fine-grained perspective on VLM robustness by discovering and mitigating spurious correlations using local image features.

🔼 This figure presents the results of a large-scale evaluation comparing RAVL’s performance against other methods in discovering spurious correlations. The experiment involved 654 fine-tuned vision-language models across synthetic and real-world datasets, varying the strength of the learned spurious correlation. The metric used for comparison was Precision@10, demonstrating that RAVL significantly outperforms existing methods in discovering spurious correlations.
read the caption
Figure 2: RAVL accurately identifies spurious correlations. Using our evaluation settings, we show that RAVL consistently outperforms prior methods in discovering learned spurious correlations between image features and textual attributes. Here, we provide Precision@10 metrics for a CLIP RN50 model fine-tuned on synthetic data (129 settings) and real-world data (171 settings).

🔼 This figure shows two examples of spurious correlations discovered by RAVL in off-the-shelf vision-language models. The left column shows the model and task. The middle column visualizes the spurious features identified by RAVL. The right column displays the zero-shot accuracy for images with and without the identified features. For the CLIP ViT-B/16 model, the spurious correlation is between text-based retail signage and the class label ‘fast food restaurant.’ For the PubMedCLIP ResNet-50 model, the spurious correlation is between metal clips and the class label ‘cardiomegaly.’
read the caption
Figure 3: RAVL surfaces spurious correlations in off-the-shelf VLMs. RAVL identifies a spurious correlation learned by CLIP ViT-B/16 between the presence of text-based retail signage and the class label fast food restaurant in a scene classification task. RAVL also surfaces a spurious correlation learned by PubMedCLIP ResNet-50 between metal clips (found in clothing) and the class label cardiomegaly (a heart condition) on a chest X-ray classification task.
More on tables
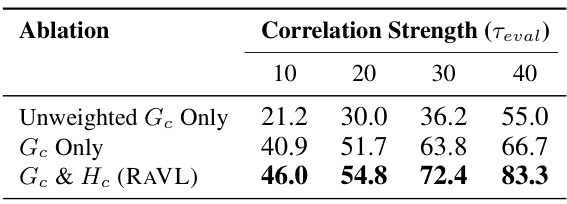
🔼 This table presents the ablation study results evaluating the contribution of cluster performance gap and influence score to the accuracy of spurious correlation discovery. The ablation study uses a CLIP-RN50 model, fine-tuned on real-world data (171 settings), and measures Precision@10 for different combinations of metrics, showing that using both the cluster performance gap and influence score (RAVL) yields significantly better results than using either metric alone or an unweighted version of the performance gap.
read the caption
Table 2: Ablations show the utility of the cluster performance gap and influence metrics. We report Precision@10 metrics for a CLIP-RN50 model fine-tuned on real-world data (171 settings).
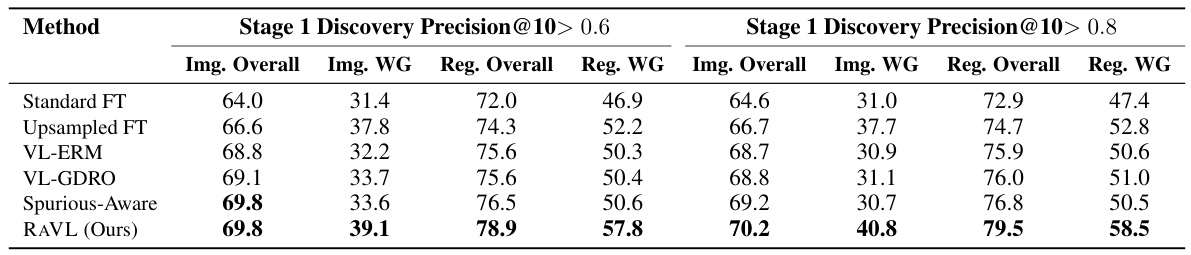
🔼 This table presents the results of the RAVL mitigation stage, showing the performance improvements over various baseline methods. It focuses on real-world evaluation settings and compares image and region-level performance in overall and worst-group scenarios, highlighting RAVL’s effectiveness in mitigating spurious correlations. The performance is categorized based on the success rate of the discovery phase (Stage 1) in terms of Precision@10, indicating that the effectiveness of mitigation relies on successful identification of spurious features.
read the caption
Table 3: RAVL effectively mitigates spurious correlations. Here, we report mean Image Overall, Image Worst-Group (Img. WG), Region Overall, and Region Worst-Group (Reg. WG) metrics across our real-world evaluation settings. Since performance of mitigation methods is dependent on the results of Stage 1, we report metrics across settings where Stage 1 Precision@10 > 0.6 and Stage 1 Precision@10 > 0.8.
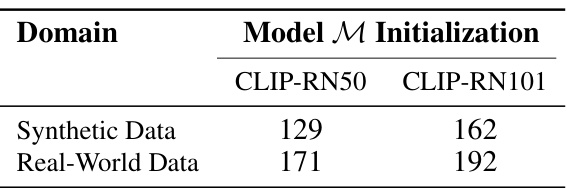
🔼 This table presents the number of evaluation settings used in the paper’s experiments. These settings are categorized by data domain (synthetic or real-world) and the model initialization used (CLIP-RN50 or CLIP-RN101). The numbers indicate how many distinct experimental configurations were used for each category.
read the caption
Table 4: Evaluation settings. We evaluate our approach on 654 settings, divided across 2 data domains and 2 model initializations.

🔼 This table presents the results of the RAVL mitigation stage, comparing its performance against other methods in reducing spurious correlations. It shows the average image and region classification accuracy (overall and worst-group) across real-world datasets. Results are broken down by whether the discovery stage (Stage 1) of RAVL achieved a Precision@10 above 0.6 or 0.8, indicating the impact of successful spurious correlation detection on the mitigation’s effectiveness.
read the caption
Table 3: RAVL effectively mitigates spurious correlations. Here, we report mean Image Overall, Image Worst-Group (Img. WG), Region Overall, and Region Worst-Group (Reg. WG) metrics across our real-world evaluation settings. Since performance of mitigation methods is dependent on the results of Stage 1, we report metrics across settings where Stage 1 Precision@10> 0.6 and Stage 1 Precision@10>0.8.

🔼 This table presents the results of the RAVL method’s ability to mitigate spurious correlations in real-world settings. It compares RAVL’s performance against other methods (standard fine-tuning, upsampled fine-tuning, VL-ERM, VL-GDRO, and Spurious-Aware) across two sets of evaluation scenarios: one where the precision@10 score in Stage 1 (correlation discovery) is above 0.6 and another where it’s above 0.8. The metrics reported are image overall accuracy, image worst-group accuracy, region overall accuracy, and region worst-group accuracy. Higher values indicate better performance. The worst-group metrics assess performance on the most challenging subgroups of data, highlighting the robustness of the method.
read the caption
Table 3: RAVL effectively mitigates spurious correlations. Here, we report mean Image Overall, Image Worst-Group (Img. WG), Region Overall, and Region Worst-Group (Reg. WG) metrics across our real-world evaluation settings. Since performance of mitigation methods is dependent on the results of Stage 1, we report metrics across settings where Stage 1 Precision@10 > 0.6 and Stage 1 Precision@10 > 0.8.
Full paper#



















