TL;DR#
Current skill-based learning in robotics struggles with adapting learned skills to unseen contexts, hindering real-world applications. Existing approaches heavily rely on extensive, context-specific training data, making them impractical for dynamic environments and varied user demands. This limits the generalizability and adaptability of robotic systems.
The proposed LLM-based Skill Diffusion (LDuS) framework directly addresses this challenge. LDuS leverages a large language model (LLM) to translate natural language contexts into loss functions, guiding the generation of skill trajectories using a diffusion model. A sequential in-painting technique enhances trajectory robustness, while iterative refinement ensures alignment with the context. Experiments show that LDuS successfully adapts to various context types, significantly outperforming existing methods in zero-shot settings.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework for zero-shot policy adaptation in robotics, addressing a critical limitation in current skill-based learning methods. Its use of LLMs to guide skill diffusion opens exciting avenues for research into more robust and adaptable AI systems and will likely influence future work in the field. The demonstrated adaptability to diverse contexts, including different specification levels, multi-modality and temporal conditions is highly significant.
Visual Insights#
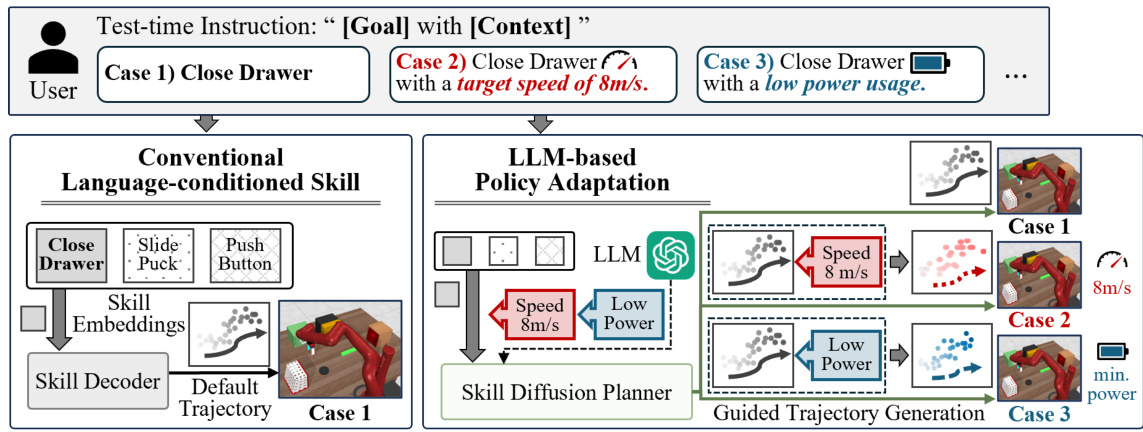
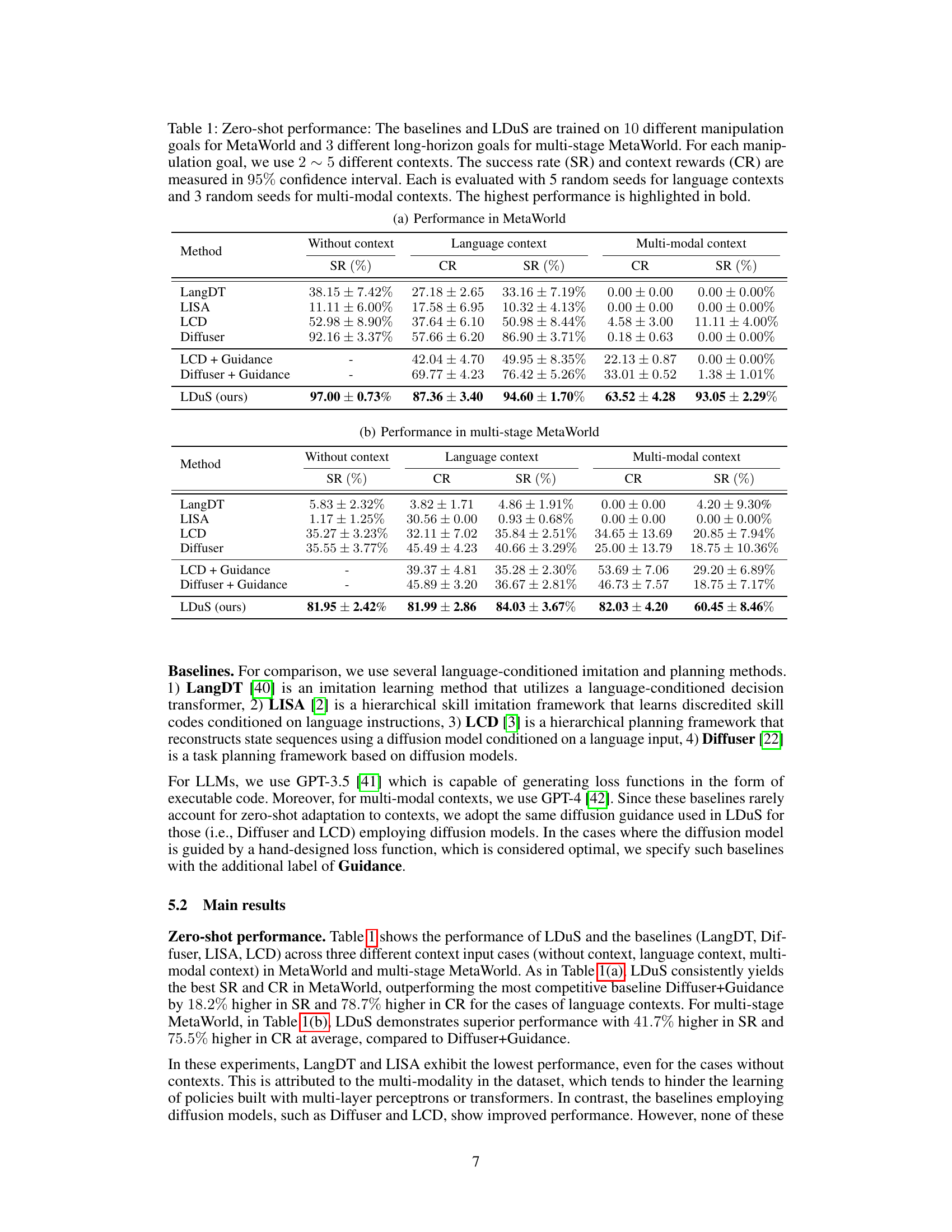
🔼 This figure illustrates the difference between conventional language-conditioned skill approaches and the proposed LLM-based policy adaptation method (LDuS) for zero-shot policy adaptation. In the conventional approach, the system only receives the task goal (e.g., ‘Close Drawer’), and its performance is limited. LDuS, however, uses an LLM to process both the goal and additional context (e.g., ‘with a target speed of 8 m/s’, ‘with low power usage’), enabling the generation of trajectories adapted to various contextual requirements in a zero-shot manner (without explicit training on those contexts). The figure visually represents how LDuS handles the different contexts, demonstrating superior adaptability compared to conventional methods.
read the caption
Figure 1: Zero-shot policy adaptation to contexts: In case 1, the instruction includes only the task goal. In cases 2 and 3, the instruction is supplemented by the task goal with the context. Conventional language-conditioned skill approaches struggle to generate trajectories well aligned with the contexts, and typically succeed only for instructions as in case 1. Conversely, our LLM-based policy adaptation approach effectively adapts to the contexts in a zero-shot manner across all cases.

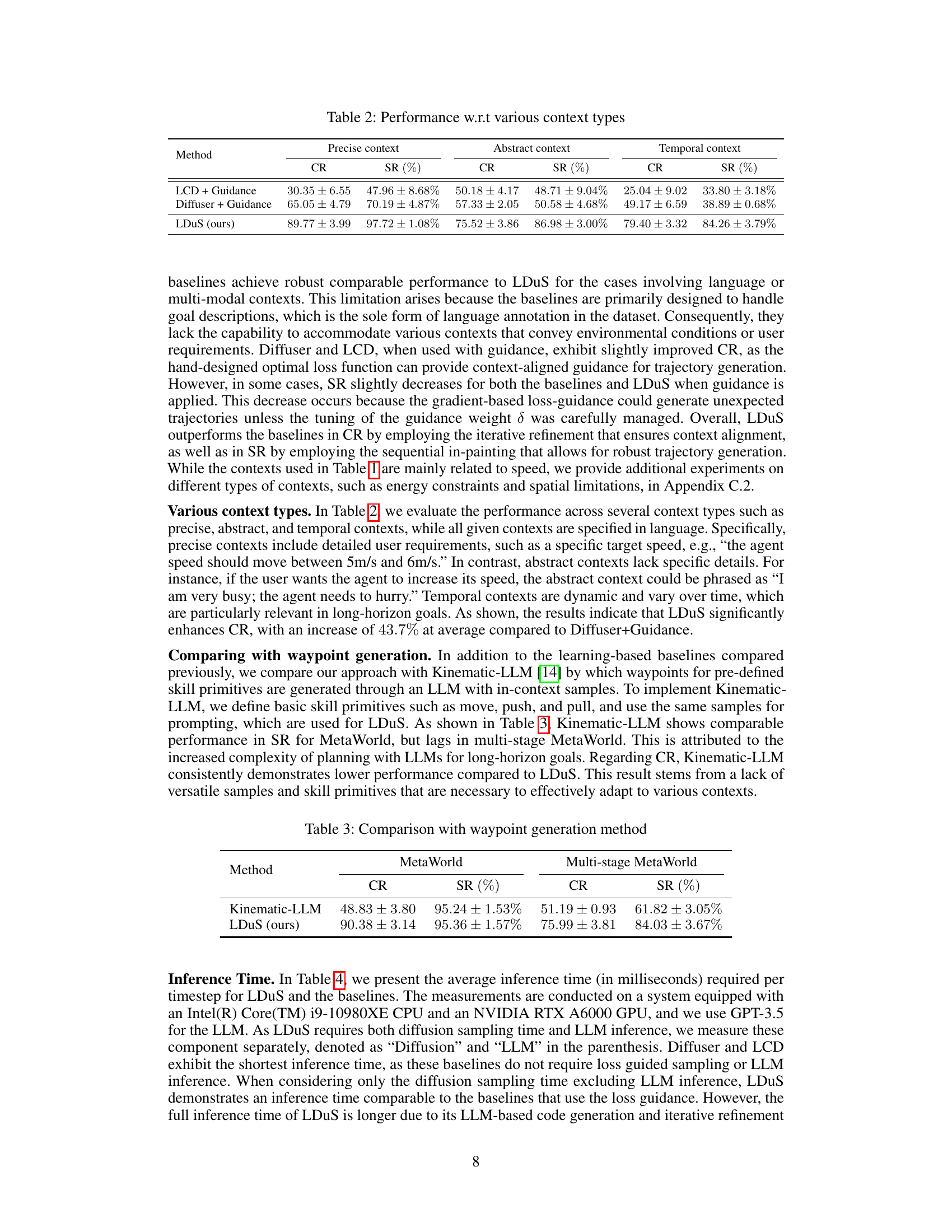
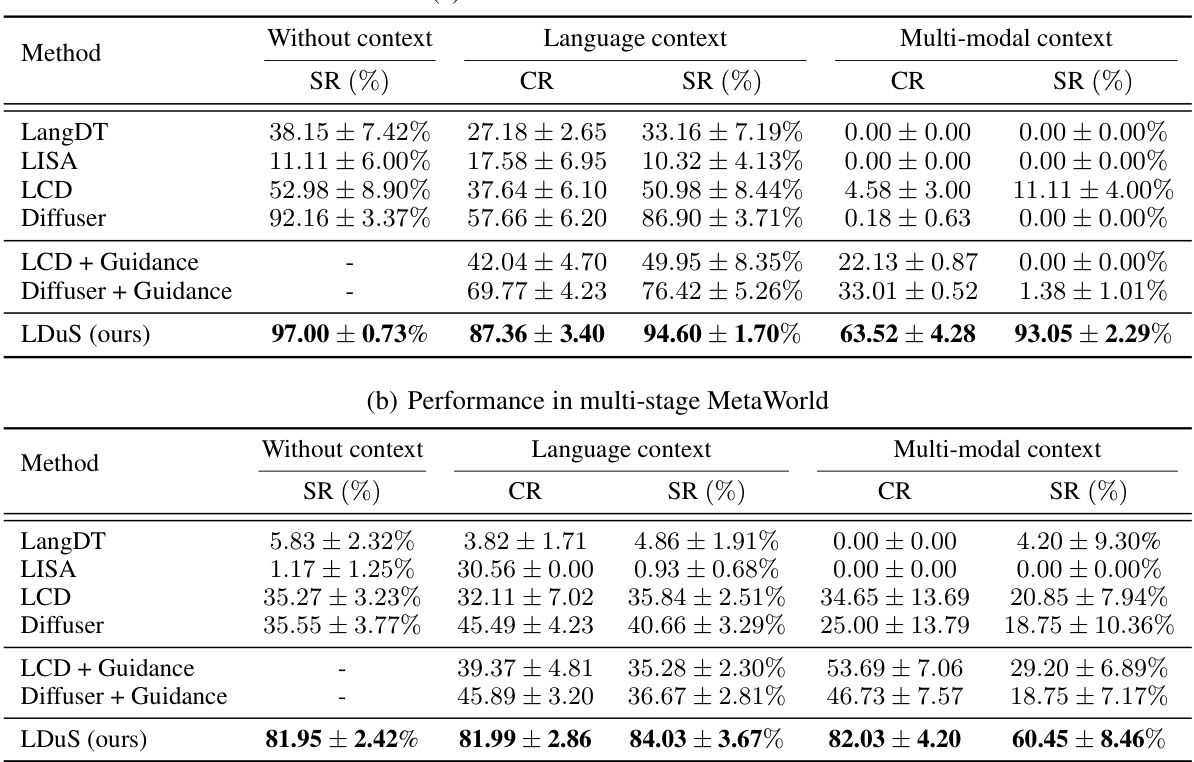
🔼 This table presents a comparison of the zero-shot performance of the proposed LDuS framework against several baselines across different manipulation tasks in two environments: MetaWorld and Multi-stage MetaWorld. The performance is evaluated under three conditions: without context, with language context, and with multi-modal context. The table shows the success rate (SR) and context reward (CR) for each method, with the best performance highlighted in bold. The results demonstrate LDuS’s superior zero-shot adaptability to various contexts.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.
In-depth insights#
LLM-Based Adaptation#
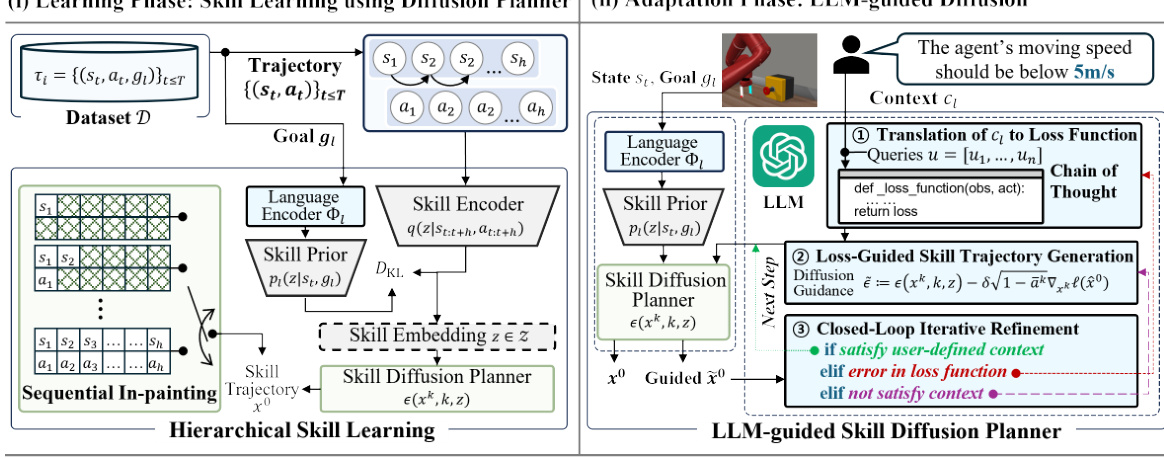
The concept of ‘LLM-Based Adaptation’ in the context of this research paper centers on using large language models (LLMs) to enhance the adaptability of skill-based policies to unseen contexts. This is a significant departure from traditional methods, which often struggle with zero-shot adaptation. The core idea is to leverage the code generation capabilities of LLMs to dynamically create loss functions that guide a skill diffusion model. This allows for controlled trajectory generation tailored to specific contexts described in natural language. Zero-shot adaptability is key; the system can handle diverse contexts (e.g., varying speed or energy constraints) without retraining. The iterative refinement process, where the LLM validates and refines the generated trajectories, is crucial for ensuring alignment with the desired context. This methodology demonstrates a powerful synergy between LLMs and diffusion models, opening up new possibilities for flexible and robust robotic control.
Skill Diffusion Model#
A skill diffusion model is a powerful technique for generating diverse and controllable skill trajectories. It leverages the principles of diffusion models, which iteratively add noise to data until it becomes pure noise, then reverse this process to generate new samples. In the context of skill learning, the model learns to map states and goals to a distribution over trajectories, allowing for the generation of trajectories adapted to various contexts. The incorporation of a sequential in-painting technique enhances robustness and controllability by sequentially conditioning the trajectory generation on past state-action pairs. This approach enables efficient exploration of the skill space and allows for nuanced adjustments to the generated trajectories based on task demands and changing environmental conditions. By conditioning the diffusion process on contextual information, it exhibits the remarkable ability to adapt to various contexts with zero-shot learning. The integration of a large language model (LLM) to translate language contexts into loss functions, further enhances its versatility by allowing for more complex and human-understandable control over the generated skill trajectories. This framework provides a promising solution for tasks requiring zero-shot adaptation to novel environments and user specifications.
Zero-Shot Learning#
Zero-shot learning (ZSL) aims to enable models to recognize or classify unseen classes during inference, without requiring any training data for these classes. This is a significant challenge in machine learning, as it deviates from traditional supervised learning paradigms that rely on labeled examples. The core idea behind ZSL lies in leveraging auxiliary information about unseen classes, such as semantic descriptions or visual attributes, to bridge the gap between seen and unseen data. Different approaches employ techniques like semantic embedding, attribute prediction, or generative models to represent unseen classes and transfer knowledge from seen classes. While ZSL presents significant potential for scalability and efficiency, it also faces inherent challenges, including the hubness problem, where some seen classes become overly influential in predicting unseen classes, and the data bias issue, where the distribution of seen and unseen classes may differ. Despite these challenges, recent advancements in deep learning, particularly those involving large language models and diffusion models, have led to substantial progress, enabling more accurate and robust zero-shot classification and generalization. Further research in ZSL remains crucial to address the limitations and achieve more reliable and widely applicable performance.
Iterative Refinement#
Iterative refinement, in the context of this research paper, is a crucial mechanism for ensuring the alignment between generated skill trajectories and user-specified contexts. This iterative process leverages a large language model (LLM) to act as a self-critic, continuously evaluating and refining the output of the skill diffusion planner. The closed-loop nature of this refinement is key: the LLM validates the generated trajectories, identifying discrepancies between the trajectories and the desired context provided in natural language. If mismatches are detected, the LLM provides feedback, either refining the loss function guiding the trajectory generation or flagging for further refinement cycles. This iterative approach is vital because LLMs are not always perfect in translating language instructions into precise loss functions. The refinement process helps mitigate the inherent ambiguity and imperfections in this translation step, leading to more robust and contextually accurate skill trajectories. Therefore, iterative refinement is not just a supplementary step, but a core component ensuring the zero-shot adaptability and high performance of the LLM-based skill diffusion framework.
Future Work#
The paper’s core contribution lies in introducing LDuS, a novel LLM-based framework enabling zero-shot policy adaptation. Future work could focus on enhancing LDuS’s robustness and efficiency. This could involve exploring more efficient LLMs for loss function generation, potentially through model distillation or fine-tuning, and refining the iterative refinement process. Another avenue for improvement would be investigating more sophisticated loss functions that better capture nuanced contextual information. Expanding the range of contexts and tasks LDuS can handle is crucial for broader applicability, demanding exploration beyond robotic manipulation to other domains like embodied AI. Finally, a rigorous exploration of the theoretical underpinnings of LLM-guided diffusion, including investigating the impact of different LLMs and loss function designs on the quality and robustness of generated trajectories, is needed to further solidify the framework’s foundations.
More visual insights#
More on figures
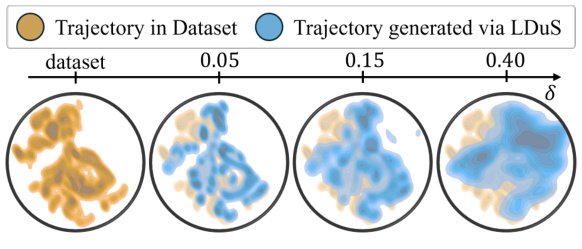
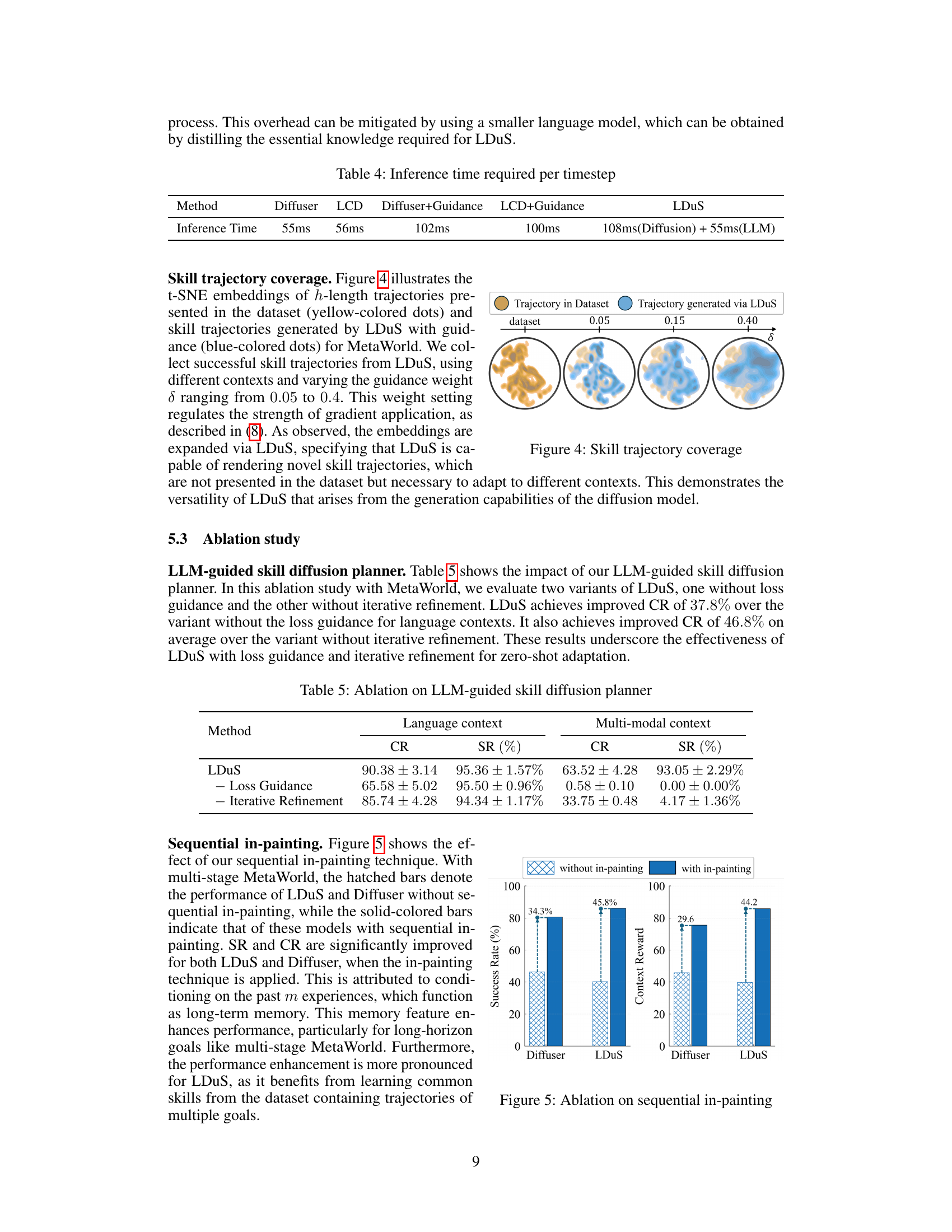
🔼 This figure visualizes the t-SNE embeddings of h-length trajectories from the dataset and skill trajectories generated by LDuS with guidance, using different contexts and varying the guidance weight δ ranging from 0.05 to 0.4. The embeddings are expanded via LDuS, showing that LDuS can generate novel skill trajectories that were not in the original dataset but are necessary for adapting to different contexts. This demonstrates the versatility of LDuS in its ability to generate trajectories in response to various contexts.
read the caption
Figure 4: Skill trajectory coverage

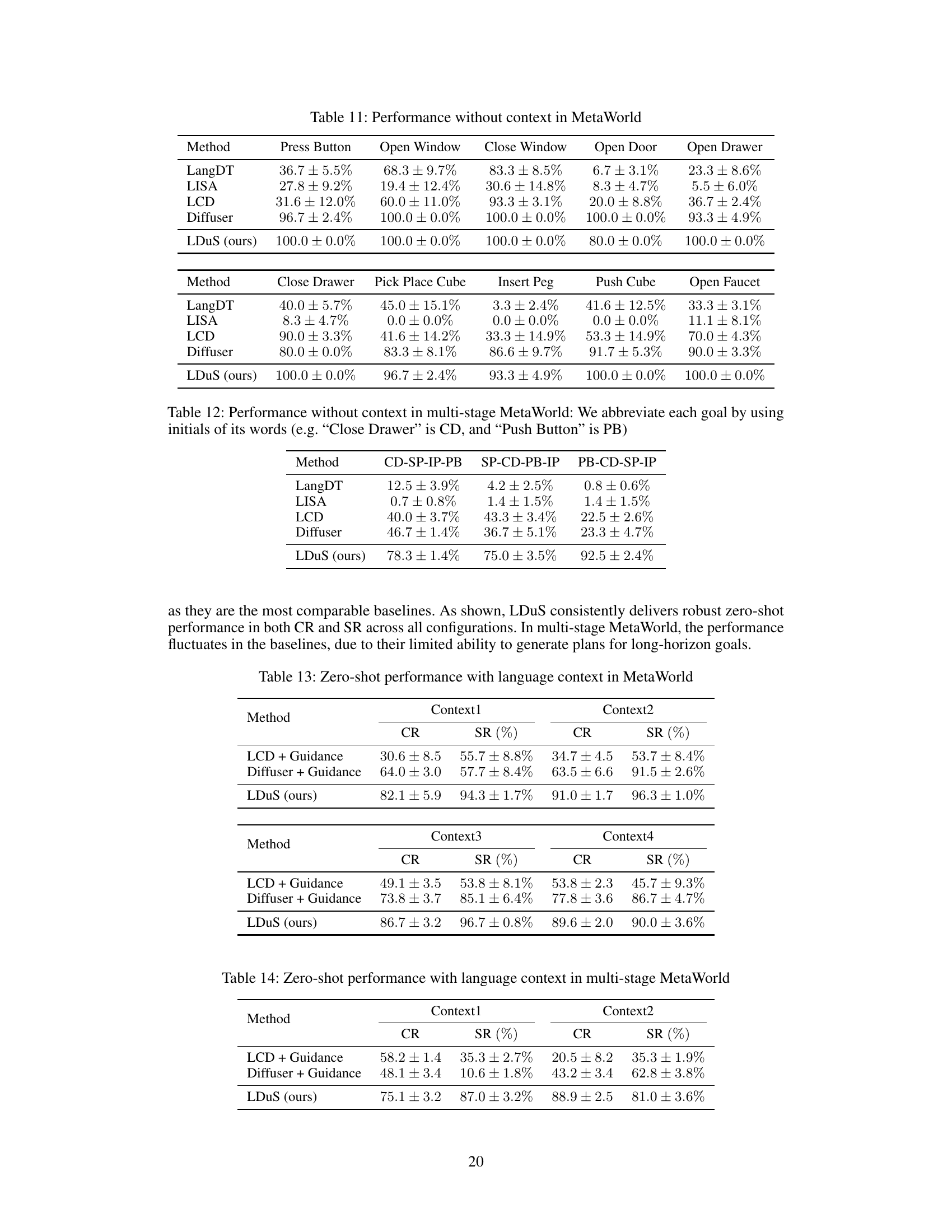
🔼 The figure shows the ablation study on sequential in-painting. It compares the performance of LDuS and Diffuser with and without sequential in-painting on multi-stage MetaWorld. The results demonstrate that sequential in-painting significantly improves both success rate and context reward, especially for LDuS, which benefits from learning common skills from the dataset.
read the caption
Figure 5: Ablation on sequential in-painting

🔼 This figure illustrates the limitations of conventional language-conditioned skill approaches in adapting to various contexts and highlights the effectiveness of the proposed LLM-based policy adaptation framework (LDuS) in handling zero-shot policy adaptation to unseen contexts.
read the caption
Figure 1: Zero-shot policy adaptation to contexts: In case 1, the instruction includes only the task goal. In cases 2 and 3, the instruction is supplemented by the task goal with the context. Conventional language-conditioned skill approaches struggle to generate trajectories well aligned with the contexts, and typically succeed only for instructions as in case 1. Conversely, our LLM-based policy adaptation approach effectively adapts to the contexts in a zero-shot manner across all cases.
More on tables
🔼 This table presents a comparison of the proposed LDuS method against several baseline methods for zero-shot policy adaptation in robotic manipulation tasks. The results are shown for two different environments (MetaWorld and Multi-stage MetaWorld) and three different context types (no context, language context, multi-modal context). The performance is evaluated using two metrics: Success Rate (SR) and Context Reward (CR), with the best performance for each setting highlighted in bold. The table also indicates the number of random seeds used for each experiment.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.
🔼 This table presents the zero-shot performance comparison between the proposed LDuS method and several baselines across different experimental settings. The baselines include LangDT, LISA, LCD, and Diffuser, each with and without guidance. The experiments are conducted on two different MetaWorld environments: the standard MetaWorld with 10 manipulation tasks and the multi-stage MetaWorld with 3 long-horizon tasks. The results are shown for three context conditions: without context, language context, and multi-modal context. The success rate (SR) and context reward (CR) are reported with 95% confidence intervals, based on multiple random seeds for each condition. The highest performance in each setting is highlighted in bold.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.

🔼 This table presents the results of the experiments conducted to evaluate the performance of LDuS and the baselines across various context types. The context types include precise context, abstract context, and temporal context. For each context type, the table shows the average context reward (CR) and success rate (SR) for each method. The results demonstrate the effectiveness of LDuS in adapting to diverse contexts, outperforming the baselines in terms of both CR and SR across all context types.
read the caption
Table 2: Performance w.r.t various context types

🔼 This table compares the performance of LDuS with Kinematic-LLM, a waypoint generation method, on MetaWorld and Multi-stage MetaWorld. It shows that LDuS significantly outperforms Kinematic-LLM in terms of Context Reward (CR) and maintains a comparable success rate (SR) in MetaWorld, while demonstrating superior performance in both metrics on the more complex Multi-stage MetaWorld.
read the caption
Table 3: Comparison with waypoint generation method

🔼 This table presents the zero-shot performance comparison between LDuS and several baselines across different manipulation tasks (MetaWorld and multi-stage MetaWorld). The performance is evaluated under three conditions: without context, with language context, and with multi-modal context. The metrics used are success rate (SR) and context reward (CR), both measured with 95% confidence intervals. The table highlights the superior performance of LDuS in zero-shot adaptation.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.

🔼 This table presents the zero-shot performance comparison of the proposed LDuS framework against several baselines across different contexts (without context, language context, multi-modal context) and for two different benchmark environments (MetaWorld and multi-stage MetaWorld). The performance metrics are Success Rate (SR) and Context Reward (CR), both reported with 95% confidence intervals and averaged across multiple random seeds for each condition. The table highlights the superior performance of LDuS in most zero-shot settings.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2~5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.
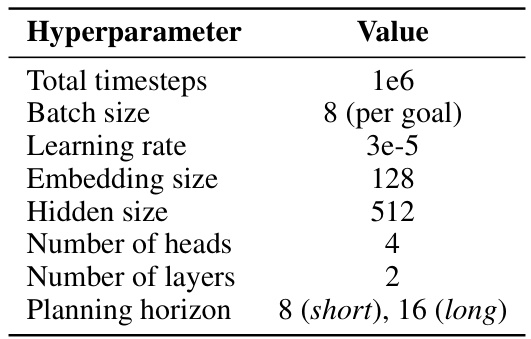
🔼 This table shows the hyperparameter settings used for training the LangDT model. It includes the total number of training timesteps, batch size, learning rate, embedding size, hidden size, number of attention heads, number of layers, and the planning horizon for both short (MetaWorld) and long (multi-stage MetaWorld) horizon tasks.
read the caption
Table 6: Hyperparameter settings for LangDT

🔼 This table presents a comparison of the zero-shot performance of the proposed LDuS framework against several baselines on two MetaWorld environments: the standard MetaWorld with 10 manipulation tasks and a multi-stage version with 3 long-horizon tasks. The performance is evaluated under three conditions: without context, language context, and multi-modal context. The metrics used are Success Rate (SR) and Context Reward (CR), both calculated with 95% confidence intervals. The best-performing method for each condition is highlighted in bold. The table showcases LDuS’s superior performance across various contexts compared to the baseline models.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.

🔼 This table presents the zero-shot performance results of the proposed LDuS method and several baselines across different contexts (without context, language context, multi-modal context) on two MetaWorld environments (MetaWorld and multi-stage MetaWorld). The performance is evaluated using Success Rate (SR) and Context Rewards (CR), with confidence intervals provided. The table highlights the superior performance of LDuS in zero-shot adaptation across various contexts.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.

🔼 This table presents the zero-shot performance comparison of LDuS against several baselines across different manipulation tasks (MetaWorld and Multi-stage MetaWorld). It shows the success rate (SR) and context reward (CR) for each method under three conditions: without context, with language context, and with multi-modal context. The results highlight LDuS’s superior performance in zero-shot adaptation to various contexts.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.

🔼 This table presents the zero-shot performance comparison of the proposed LDuS method against several baselines across different contexts (without context, language context, multi-modal context) on two MetaWorld environments (standard MetaWorld and multi-stage MetaWorld). The performance is measured using success rate (SR) and context reward (CR), with confidence intervals reported. The table highlights the superior performance of LDuS in zero-shot adaptation to various contexts.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.

🔼 This table presents the zero-shot performance comparison of the proposed LDuS method against several baselines across different manipulation tasks in two environments (MetaWorld and Multi-stage MetaWorld). The performance is evaluated under three conditions: without context, with language context, and with multi-modal context. The metrics used are Success Rate (SR) and Context Reward (CR), both reported with 95% confidence intervals. The best-performing method is highlighted in bold for each scenario.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.
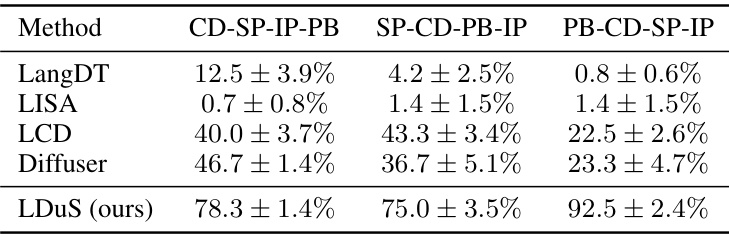
🔼 This table presents the results of a zero-shot experiment conducted on a multi-stage MetaWorld environment. The experiment evaluates the performance of several methods (LangDT, LISA, LCD, Diffuser, and LDuS) on three different long-horizon manipulation tasks without providing any contextual information. Each method’s success rate (SR) and context rewards (CR) are shown for each task. The goal names are abbreviated using their initials (e.g., CD for Close Drawer, PB for Push Button).
read the caption
Table 12: Performance without context in multi-stage MetaWorld: We abbreviate each goal by using initials of its words (e.g. “Close Drawer” is CD, and “Push Button” is PB)
🔼 This table presents the results of a zero-shot policy adaptation experiment comparing the performance of the proposed LDuS method against several baselines. The experiment evaluates performance across different manipulation tasks in two MetaWorld environments: a standard version and a multi-stage version with longer horizon goals. Results are presented for three context conditions: without context, with language context, and with multimodal context. Success rate (SR) and context reward (CR) are reported with 95% confidence intervals and the best performing method is highlighted in bold for each condition.
read the caption
Table 1: Zero-shot performance: The baselines and LDuS are trained on 10 different manipulation goals for MetaWorld and 3 different long-horizon goals for multi-stage MetaWorld. For each manipulation goal, we use 2 ~ 5 different contexts. The success rate (SR) and context rewards (CR) are measured in 95% confidence interval. Each is evaluated with 5 random seeds for language contexts and 3 random seeds for multi-modal contexts. The highest performance is highlighted in bold.

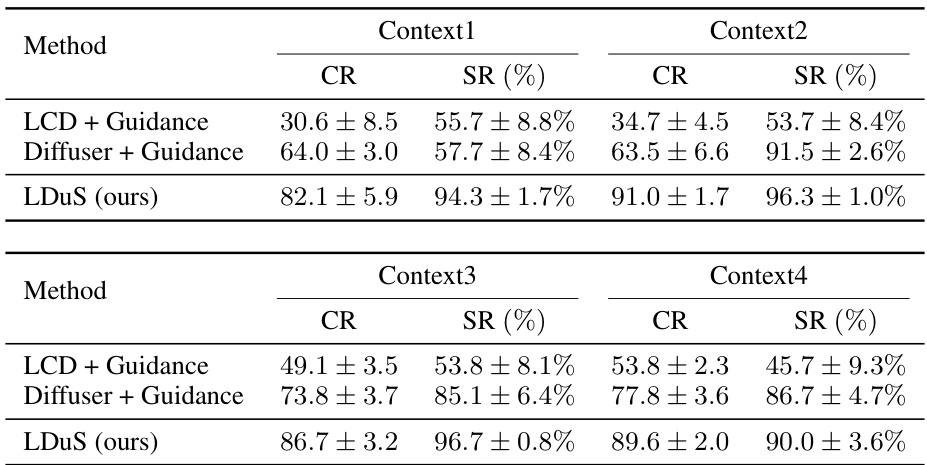
🔼 This table presents the results of a zero-shot policy adaptation experiment on multi-stage MetaWorld tasks. It compares the performance of LDuS against several baselines (LCD + Guidance, Diffuser + Guidance) across two different language contexts (Context1 and Context2). The performance is measured using two metrics: Contextual Reward (CR) and Success Rate (SR). The table highlights the superior performance of LDuS in adapting to unseen contexts specified in language, demonstrating the effectiveness of the proposed LLM-based framework.
read the caption
Table 14: Zero-shot performance with language context in multi-stage MetaWorld

🔼 This table presents the results of additional experiments evaluating LDuS and baseline methods under two different context types: energy constraints and spatial constraints. The experiments were conducted on a single task within the MetaWorld environment. For the energy constraint, the agent aimed to minimize energy consumption by reducing acceleration and deceleration. The spatial constraint involved maintaining the agent’s position within specified boundaries. The table displays the Context Rewards (CR) and Success Rates (SR) for each method under both context types.
read the caption
Table 15: Zero-shot performance with energy and spatial context in MetaWorld
Full paper#