↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Human Mesh Recovery (HMR) aims to reconstruct a 3D human mesh from a single image. Existing methods often train a regression model and then fine-tune it at test time, but this approach may not be optimal. A key challenge lies in the difference between training and test-time objectives, hindering effective learning. This paper introduces a novel meta-learning approach to address these challenges. The proposed method incorporates test-time optimization into the training process, effectively creating a model more adaptable to test-time optimization. It introduces a dual-network architecture that unifies the training and test-time objectives, improving learning efficiency and robustness.
The researchers’ approach leverages meta-learning to perform test-time optimization on each training sample before the actual training optimization. This results in meta-parameters which are ideal for test-time optimization. To address the discrepancy between training and test objectives, a dual-network architecture is introduced. This dual network uses an auxiliary network to provide pseudo ground-truth data during test-time optimization, thereby aligning training and test-time objectives. Extensive experiments demonstrate that the method significantly outperforms existing approaches in terms of accuracy and generalization, showcasing the benefits of the proposed meta-learning strategy and the dual-network architecture. The improved performance is validated through extensive experiments on multiple datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves human mesh recovery (HMR) accuracy by integrating test-time optimization into the training process. This novel approach addresses limitations of existing methods by unifying training and test-time objectives, leading to improved model generalization and performance on unseen data. This work opens up new research avenues in meta-learning and model adaptation for computer vision tasks, with potential applications in various fields like AR/VR and animation.
Visual Insights#

This figure illustrates the dual-network meta-learning approach for Human Mesh Recovery (HMR). It shows how test-time optimization is integrated into the training process. The main network (fw) and an auxiliary network (fu) are used. For each image in a batch, test-time optimization is performed to update the main network’s parameters. These updated parameters, along with the auxiliary network’s output (pseudo ground truth SMPL meshes), are then used in a training optimization step to update both networks’ parameters. This process leads to the generation of meta-parameters (wmeta and umeta) that are effective for test-time optimization.

This table presents a quantitative comparison of the proposed method with several state-of-the-art approaches on two benchmark datasets for 3D human pose estimation: 3DPW and Human3.6M. The comparison is based on three evaluation metrics: MPJPE, PA-MPJPE, and PVE. The table also shows results using two different 2D joint detectors (OpenPose and RSN), highlighting the impact of the quality of input data on the performance.
In-depth insights#
Dual Network HMR#
The concept of “Dual Network HMR” suggests a human mesh recovery (HMR) system using two networks: a main regression network and an auxiliary network. The main network estimates the 3D human mesh directly from input images, while the auxiliary network generates pseudo ground truth SMPL meshes. This dual-network setup unifies training and test-time objectives, addressing a common problem in HMR where test-time optimization starts from a possibly suboptimal point. By integrating test-time optimization into training and leveraging the auxiliary network’s pseudo ground truth, the system achieves a meta-learning effect. This approach results in a more robust and accurate HMR system, surpassing traditional regression and optimization-based methods. The effectiveness of this approach is validated by experiments showing improved quantitative and qualitative mesh recovery, particularly in challenging scenarios. The meta-learning aspect allows for adaptation to individual test samples with limited data, while the dual-network architecture addresses the discrepancy between training and test-time objectives.
Meta-Learning HMR#
Meta-learning applied to Human Mesh Recovery (HMR) represents a significant advancement. Instead of solely relying on a pre-trained model for 3D mesh prediction from a single image, meta-learning HMR incorporates test-time optimization into the training process itself. This innovative approach involves performing a step of test-time optimization for each sample within the training batch. The result is a meta-model whose parameters are inherently well-suited for test-time refinement, leading to superior accuracy compared to methods which solely optimize a pre-trained model. Furthermore, by addressing the discrepancy between training and test-time objectives through techniques like dual-network architectures, meta-learning HMR enhances the effectiveness of the meta-learning process. This results in state-of-the-art performance, surpassing both regression-based and optimization-based HMR techniques. The approach is particularly promising because of its ability to adapt effectively to individual test samples, achieving high accuracy without requiring excessive computations during inference.
Test-Time Optimization#
The concept of ‘Test-Time Optimization’ (TTO) within the context of human mesh recovery is a significant advancement. It addresses the limitation of traditional regression methods by incorporating a further optimization step at the inference stage. Instead of relying solely on a pre-trained model’s output, TTO refines the mesh parameters for each individual test image. This iterative process, inspired by meta-learning, allows for a better adaptation to specific image characteristics and a more accurate final mesh. However, a key challenge is that the pre-trained model may not provide an optimal starting point for the TTO process. Therefore, this paper cleverly proposes integrating TTO into the training phase itself, leading to a meta-model better suited to test-time refinement. This is where a dual-network architecture comes into play, unifying training and test-time objectives to further enhance performance. The results strongly suggest that this novel combination of meta-learning and dual-networks outperforms traditional regression-based and optimization-based methods, showing the power of leveraging test-time optimization effectively during the training process.
Unified Objectives#
The concept of “Unified Objectives” in a human mesh recovery (HMR) system is crucial because the training and testing phases often have mismatched goals. Training typically uses ground-truth data, allowing for direct comparison between predicted and actual meshes. Testing, however, lacks this ground truth, relying on indirect measures like 2D joint reprojection error. This discrepancy hinders effective meta-learning, as test-time optimization might not align with the training objectives. A dual-network architecture is a potential solution. One network can generate pseudo ground-truth data for test-time optimization, while the other performs the actual mesh regression. This alignment of training and test-time objectives with pseudo ground-truth data is essential for robust meta-learning and improved generalization in HMR models. The success of this unification hinges on the auxiliary network effectively generating realistic pseudo ground-truth meshes that appropriately guide test-time refinement without introducing significant artifacts.
Future of HMR#
The future of Human Mesh Recovery (HMR) is bright, driven by several key trends. Improved accuracy and robustness will be achieved through the use of more sophisticated deep learning architectures, larger and more diverse training datasets, and innovative loss functions that better capture the nuances of human pose and shape. Real-time performance will be crucial for widespread adoption in applications like AR/VR, requiring efficient model compression and hardware acceleration techniques. Integration with other computer vision tasks will enable more holistic understanding of human behavior, potentially incorporating techniques from action recognition, human-object interaction and 3D scene understanding. Generalization to diverse scenarios will involve incorporating more realistic factors like clothing, occlusion, and varied lighting conditions, potentially utilizing techniques from generative modeling. Finally, ethical considerations around privacy and bias will require ongoing research and development of fair and responsible HMR systems.
More visual insights#
More on figures

This figure compares the qualitative results of the proposed method against two state-of-the-art methods (CLIFF and ReFit) on several examples. It shows input images and the 3D human mesh estimations of each method, with novel views showing the accuracy from different angles. The ground truth meshes are shown in green for comparison. The different colors highlight the variation in results between the different approaches.

This figure shows the impact of the number of optimization steps during the inference phase on the performance of the proposed method and EFT. The plots (a) and (b) illustrate that the proposed method consistently improves with more optimization steps, unlike EFT which shows initial improvement followed by degradation. Plot (c) demonstrates the faster convergence of the proposed method compared to EFT.

This figure illustrates the dual-network meta-learning HMR method. It shows two networks (main and auxiliary) with the same architecture but different parameters. The process begins with test-time optimization on each image in a batch, updating the main network’s parameters. This is followed by a training optimization step that uses the updated parameters from all images in the batch. This dual-network approach unifies training and testing objectives by generating pseudo SMPLs. These pseudo SMPLs are utilized in the test-time loss to supervise the learning of ‘Estimated SMPL Inner,’ while the ground truth SMPLs are employed in the training loss to supervise the ‘Estimated SMPL Outer’. The resulting meta-parameters (wmeta and umeta) are then used for human mesh recovery at test time.
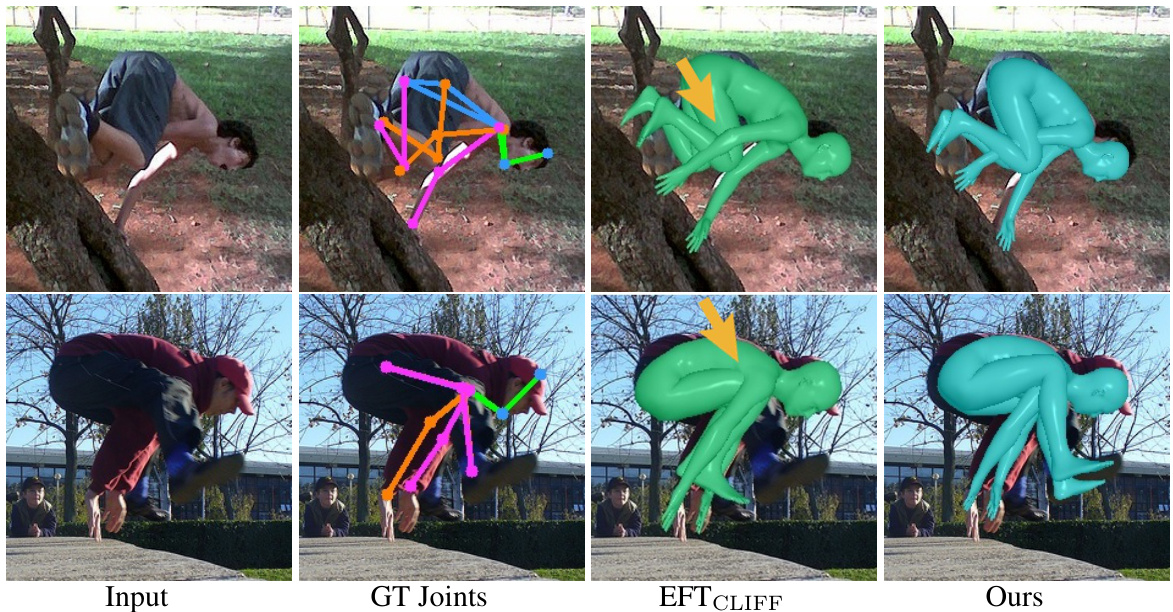
This figure presents a qualitative comparison of the proposed method’s performance against state-of-the-art approaches (CLIFF and Refit) on human mesh recovery. It uses HRNet-W48 as the backbone network for all three methods. The comparison includes both standard views and novel viewpoints, to assess the robustness of the approaches. The color-coding in the novel views highlights the differences between the ground truth, CLIFF, Refit and the proposed method’s results.

This figure illustrates the dual-network meta-learning HMR method. It shows how a main HMR regression network (fw) and an auxiliary network (fu) are used together. The test-time optimization is performed individually for each image in a batch, updating fw. Then, training optimization is performed using the results of the test-time optimization to further update both networks. The auxiliary network (fu) generates pseudo SMPLs used in the training and test losses, while GT SMPLs are used in the training loss. The final meta-parameters (wmeta and umeta) are used for inference.

This figure shows a series of images demonstrating the stepwise process of test-time optimization. Each column represents a different step in the optimization process, starting from an initial guess (Step 0) and progressing towards a refined estimate (Final). The results show the progressive refinement of the 3D human mesh estimation over several steps of test-time optimization, and illustrates how the initial estimates are progressively corrected to better align with the input image data, demonstrating the effectiveness of this method.

This figure compares the qualitative results of the proposed method with several state-of-the-art methods on Human Mesh Recovery. It shows the input image and the 3D human mesh estimations produced by different methods. The goal is to visually demonstrate the performance differences between the approaches in terms of accuracy and detail in reconstructing the human mesh. The methods being compared are HybrIK [32], NIKI [31], ProPose [13], ReFit [59], CLIFF [33], EFTCLIFF, and the proposed method. Two versions of the proposed method are shown, one using OpenPose and the other using RSN for 2D joint detection.

This figure presents a qualitative comparison of the proposed method’s performance against several state-of-the-art (SOTA) human mesh recovery methods. It shows the input images and the 3D mesh recovery results from various methods, including HybrIK, NIKI, ProPose, ReFit, CLIFF, EFTCLIFF and the authors’ method using two different 2D joint detectors (OpenPose and RSN). The visualization allows for a direct comparison of the mesh accuracy and fidelity of the different approaches, highlighting the strengths and weaknesses of each method in terms of accuracy and robustness.

This figure compares the qualitative results of the proposed method with two state-of-the-art methods (CLIFF and ReFit) on several examples. The input images are shown along with the 3D mesh reconstruction results from each method, including novel views to better assess the accuracy of the mesh generation. Different colors represent different methods for easy comparison. The ground truth is shown in green.

This figure compares the qualitative results of the proposed method with two state-of-the-art methods, CLIFF and ReFit. It visually demonstrates the superiority of the proposed method by presenting both original images and the 3D human mesh recovery results from each method. Different color schemes are used to easily distinguish results generated by different methods, with a clear indication of the ground truth for each example.

This figure illustrates the dual-network meta-learning framework for Human Mesh Recovery (HMR). It shows two networks: a main HMR regression network (fw) and an auxiliary network (fu). The process begins with test-time optimization for each image in a batch, updating fw’s parameters. Then, training optimization is performed, updating both networks’ parameters based on results from the test-time optimization. This process generates meta-parameters (wmeta and umeta). The auxiliary network (fu) creates pseudo SMPL (Surface-based Mannequin Parameterized Linear) meshes, used in the loss function to supervise the learning of the inner SMPL meshes. The ground-truth SMPL meshes are used to supervise the outer SMPL mesh, providing a unified objective for both training and testing phases.
More on tables

This table presents a quantitative comparison of the proposed method with other state-of-the-art methods on two benchmark datasets, 3DPW and Human3.6M. The performance is evaluated using three metrics: MPJPE, PA-MPJPE, and PVE. The table shows results for different backbone networks (Res-50 and HR-W48) and indicates whether OpenPose or RSN was used for 2D joint detection.

This table presents the ablation study results to show the effects of integrating test-time optimization into training and using an auxiliary network. The models are trained on the COCO dataset and evaluated on the 3DPW dataset. The table shows the performance (MPJPE and PA-MPJPE) under different settings: with and without test-time optimization (meta-learning), and with and without the auxiliary network. The results indicate that both meta-learning and the auxiliary network contribute to improved performance.

This table presents a quantitative comparison of the proposed method (OursCLIFF) and the baseline method (EFTCLIFF) on the LSP-Extended dataset. The comparison focuses on the 2D loss, a metric reflecting the accuracy of 2D joint prediction. A lower 2D loss indicates better performance. The results show that OursCLIFF achieves a lower 2D loss than EFTCLIFF, indicating superior accuracy in 2D joint estimation on the LSP-Extended dataset. This demonstrates that the proposed method’s improvements in 3D human mesh recovery also translate to better 2D joint predictions.

This table presents a quantitative comparison of the proposed method (OursCLIFF) and the baseline method (EFT_CLIFF) on the Human3.6M dataset. It reports the mean per joint position error (MPJPE) and the Procrustes aligned MPJPE (PA-MPJPE), both lower values indicating better performance. The results demonstrate that the proposed method achieves lower errors, suggesting improved accuracy in 3D human mesh recovery.

This table presents a quantitative comparison of the proposed method with other state-of-the-art approaches for 3D human mesh recovery on two benchmark datasets: 3DPW and Human3.6M. The results are evaluated using three metrics: MPJPE, PA-MPJPE, and PVE. Two variants of the proposed method are included, one using 2D joints detected by OpenPose and another using 2D joints detected by RSN.

This table presents an ablation study on the impact of different learning rates used in the proposed method. It shows the MPJPE, PA-MPJPE, and PVE results for various combinations of test-time and training learning rates. The gray row highlights the default setting used, and hyphens indicate unstable training runs.

This table presents the ablation study of using pseudo SMPLs in the proposed method. By comparing the results with and without using pseudo SMPLs, it demonstrates the effectiveness of incorporating pseudo SMPLs in enhancing the overall performance of the model.

This table presents an ablation study to evaluate the impact of meta-learning and the auxiliary network on the performance of the proposed method. The models were trained on the COCO dataset and tested on the 3DPW dataset. The results show the MPJPE and PA-MPJPE metrics for different model configurations, demonstrating the beneficial effects of incorporating test-time optimization into the training process and using a dual-network architecture.

This table presents a quantitative comparison of the proposed method with other state-of-the-art (SOTA) methods for human mesh recovery on two benchmark datasets: 3DPW and Human3.6M. The comparison uses three common evaluation metrics: Mean Per Joint Position Error (MPJPE), Procrustes-aligned MPJPE (PA-MPJPE), and Mean Per-vertex Error (PVE). The table also shows results using 2D joint detections from two different methods, OpenPose and RSN, indicated by ‘+’ and ‘*’ respectively. This allows for analyzing the impact of the accuracy of 2D joint detection on performance.
Full paper#



















